MySql基本用法
官方练习文件 World.sql
https://dev.mysql.com/doc/world-setup/en/world-setup-installation.html
1. 系统操作
1.1 用户管理
权限详解
1 | '10.0.0.200' ---->只允许200地址访问mysql |
创建用户
以root用户登录数据库,运行以下命令:
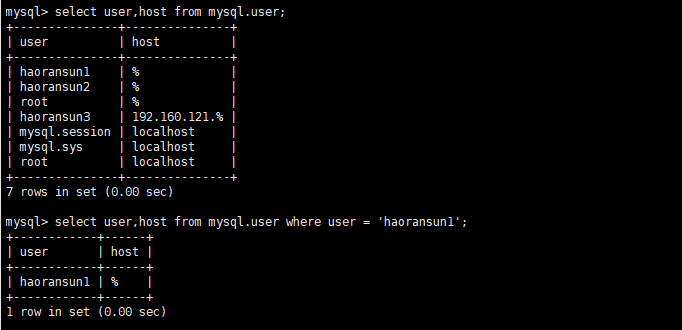
1 | # 创建用户haoransun1,密码是123456(已关闭密码策略验证)。在mysql.user表里可以查看到新增用户的信息: |
在 mysql.user 表里可以查看到新增用户的信息:
1 | mysql> select user,host from mysql.user; |
可以使用 desc mysql.user 查看表结构,以便搜寻需要的信息
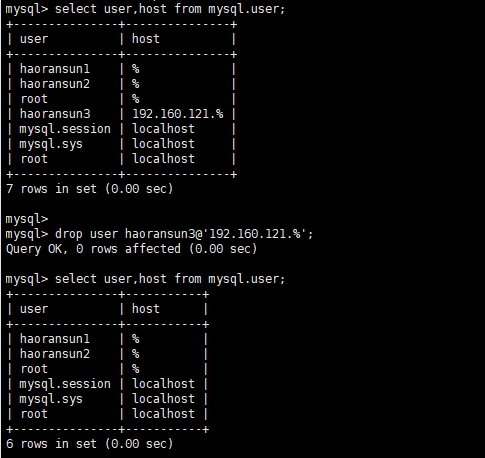
删除用户
1 | mysql> drop user haoransun3@'192.160.121.%'; |
修改密码
法1:
1 | # 官方推荐使用 alter |
法2:
1 | update mysql.user set authentication_string = password("新密码") where user = 'haoransun2' and host = '%'; |
1.2 权限管理
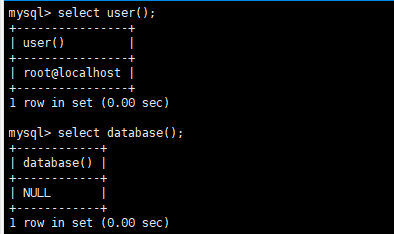
查看当前用户和数据库
1 | select user(); |
授权
基本语法
1 | grant privilegesCode on dbName.tableName to [username@host] identified by "password"; |
privilegesCode表示授予的权限类型,常用的几种类型:
- all privileges:所有权限。
- select:读取权限。
- delete:删除权限。
- update:更新权限。
- create:创建权限。
- drop:删除数据库、数据表权限。
dbName.tableName表示授予权限的具体库或表,常用选型:
- . 授予该数据库服务器所有数据库的权限。(即 一个点)
- dbName.*:授予dbName数据库所有表的权限。
- dbName.dbTable:授予数据库dbName中dbTable表的权限。
username@host表示授予的用户以及允许该用户登录的IP地址。其中Host常用类型:(见1.1权限详解)
- localhost: 只允许该用户在本地登录,不能远程登录。
- %:允许在除本机之外的任何一台机器远程登录。
- 192.168.121.05:具体的IP表示只允许该用户从特定IP登录。
password 指定该用户登录时的密码。
flush privileges 表示刷新权限变更。
实例演示:
1 | # 创建一个数据库 |
在mysql.db表里可以查看到新增数据库权限的信息:
1 | mysql> select user,db,host,select_priv,insert_priv,update_priv,delete_priv from mysql.db where user= 'haoransun1'; |
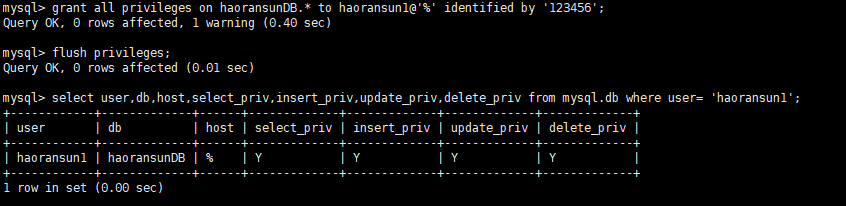
也可以通过 show grants 命令查看权限授予执行情况:
1 | mysql> show grants for 'haoransun1'@'%'; |
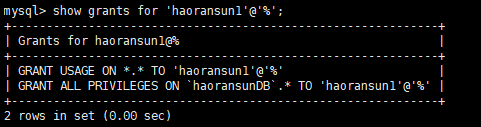
创建用户并授权
创建了用户 haoransun1,并将数据库 haoransunDB 的所有权限授予haoransun1。
1 | create user haoransun1@'%' identified by '123456'; |
回收权限
1 | # 查看用户是否有待测试权限 |
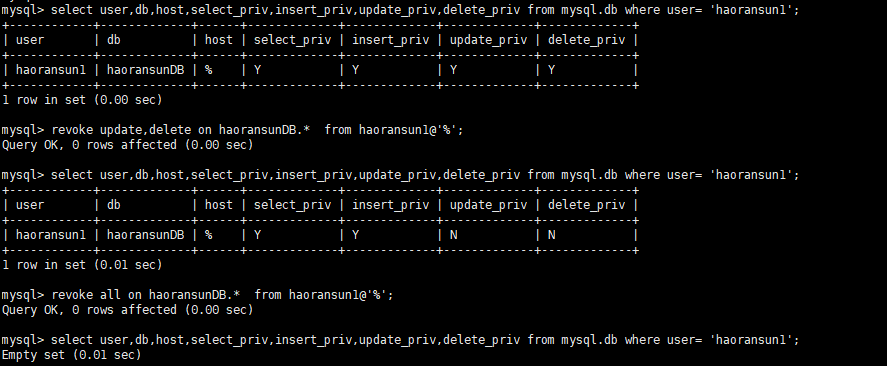
删除数据库
1 | drop database if exists haoransunDB; |
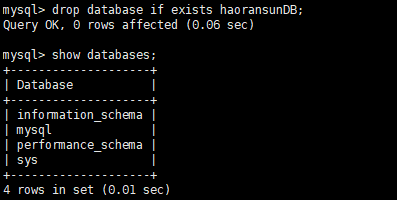
创建库database 带字符编码
1 | mysql> create database haoransunDB charset utf8; |
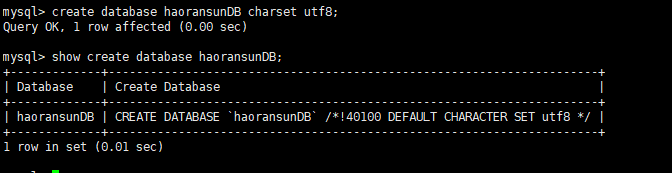
1.3 基础知识
接口命令
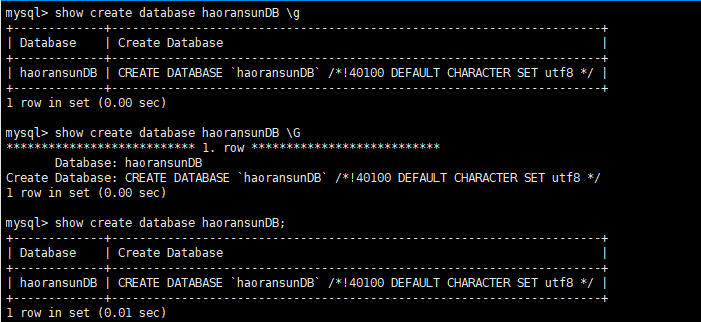
\g与|G
1 | mysql> show create database haoransunDB \g |
\g :等同于加上定界符,一般默认的定界符为分号;
\G : 将查到的结果 结构行转列。(使结果更清晰)
常用接口命令:
1 | \h 或 help 或 ? 获取帮助 |
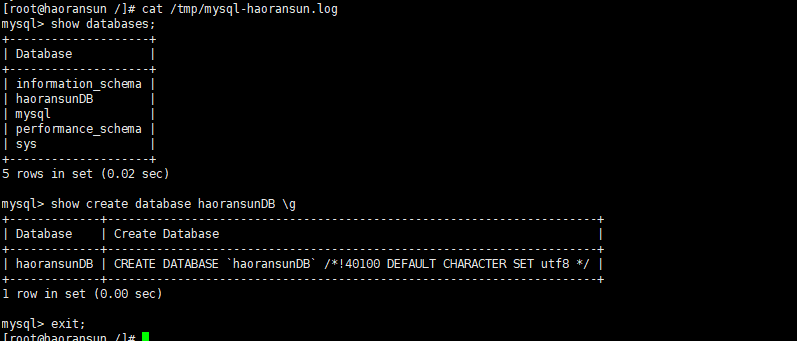
tee使用演示
1 | # 创建日志文件 |
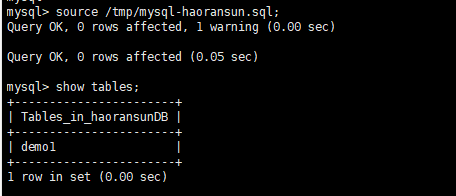
source使用演示
1 | # 创建 sql文件 |
/tmp/mysql-haoransun.sql 文件内容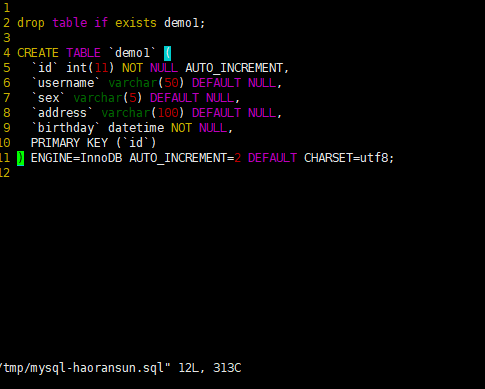
演示结果:
mysqladmin用法
mysqladmin是一个执行管理操作的客户端程序,它可以用来检查服务器的配置、状态,创建、删除数据库等操作。
格式:
mysqladmin [option] command [command option] command ……
options选型:
1 | -c number 自动运行次数统计,必须和 -i 一起使用 |
常见操作: 输入命令回车,再输入密码
mysqladmin -u用户 -p ping “强制回应 (Ping)”服务器。
mysqladmin -u用户 -p shutdown 关闭服务器。
mysqladmin -u用户 -p create databasename 创建数据库。
mysqladmin -u用户 -p drop databasename 删除数据库
mysqladmin -u用户 -p version 显示服务器和版本信息
mysqladmin -u用户 -p status 显示或重置服务器状态变量
mysqladmin -u用户 -p password 设置口令
mysqladmin -u用户 -p flush-privileges 重新刷新授权表
mysqladmin -u用户 -p flush-logs 刷新日志文件和高速缓存
mysqladmin -u用户 -p processlist 查看执行的SQL语句信息(显示服务器上所有运行的进程)
mysqladmin -u用户 -p processlist -i 1 每秒查看一次执行的SQL语句
查看服务器上所有数据库
mysqlshow -u用户 -p
查看服务器上指定数据库的所有表
mysqlshow -u用户 -p haoransunDB
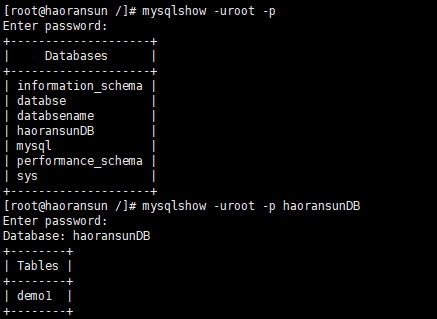
*统计 haoransunDB数据库下表列的汇总 *
mysqlshow -u用户 -p haoransunDB -v
*统计 haoransunDB数据库下表的列数和行数 *
mysqlshow -u用户 -p haoransunDB -v -v
*删除数据库 demo1 *
mysqladmin -u用户 -p drop demo1
2. 基本语句
查看数据库
1 | show databases; |
创建数据库
1 | mysql> create database haoransunDB charset utf8; |
修改已存在的字符编码
1 | mysql> alter database haoransunDB charset gbk; |
查看支持的字符集合校对规则
1 | mysql> show character set; |
切换数据库查看表
1 | mysql> use haoransunDB; |
查看当前登录用户
1 | mysql> select user(); |
创建表
1 | mysql> CREATE TABLE `demo1` ( |
1 | mysql> desc demo1; |
查看创建表语句
1 | mysql> show create table demo1; |
修改表有关信息
1 | # 法1 |
复制一个表格
1 | mysql> create table demo2 select * from demo1; |
在第一列添加 QQ 字段
1 | mysql> alter table demo2 add QQ int(20) first; |
将age列添加到QQ列后面
1 | mysql> alter table demo2 add age int(4) after QQ; |
*添加一列 education *
1 | mysql> alter table demo2 add education char(20) not null; |
删除某一列
1 | mysql> alter table demo2 drop education; |
修改列名
1 | mysql> alter table demo2 change username new_username char(50); |
3. 数据类型
数值数据类型
| 整数 | TINYINT | 极小整数数据类型(0-255) |
| :———— | :———— | :———— |
| 整数 | SMALLINT | 较小整数数据类型(-2^15 到2^15-1) |
| 整数 | MEDIUMINT | 中型整数数据类型 |
| 整数 | INT常规(平均) | 大小的整数数据类型(-2^31 到2^31-1) |
| 整数 | BIGINT | 较大整数数据类型(-2^63到2^63-1) |
| 浮点数 | FLOAT | 小型单精度(四个字节)浮点数 |
| 浮点数 | DOUBLE | 常规双精度(八个字节)浮点数 |
| 浮点数 | DECIMAL | 包含整数部分、小数部分或同时包括二者的精确值数值 |
字符串数据类型
| 文本 | CHAR | 固定长度字符串,最多为255 个字符 |
| :———— | :———— | :———— |
| 文本 | VARCHAR | 可变长度字符串,最多为65,535 个字符 |
| 文本 | TINYTEXT | 可变长度字符串,最多为255 个字符 |
| 文本 | TEXT | 可变长度字符串,最多为65,535 个字符 |
| 文本 | MEDIUMTEXT | 可变长度字符串,最多为16,777,215 个字符 |
| 文本 | LONGTEXT | 可变长度字符串,最多为4,294,967,295 个字符 |
| 整数 | ENUM | 由一组固定的合法值组成的枚举 |
| 整数 | SET | 由一组固定的合法值组成的集 |
二进制数据类型
| 二进制 | BINARY类似于 CHAR(固定长度)类型 | 但存储的是二进制字节字符串 |
| :———— | :———— | :———— |
| 二进制 | VARBINARY类似于 VARCHAR(可变长度)类型 | 但存储的是二进制字节字符串 |
| BLOB | TINYBLOB | 最大长度为255 个字节的 BLOB 列 |
| BLOB | BLOB | 最大长度为65,535 个字节的 BLOB 列 |
| BLOB | MEDIUDMBLOB | 最大长度为16,777,215 个字节的 BLOB 列 |
| BLOB | LONGBLOB | 最大长度为4,294,967,295 个字节的 BLOB 列 |
时间数据类型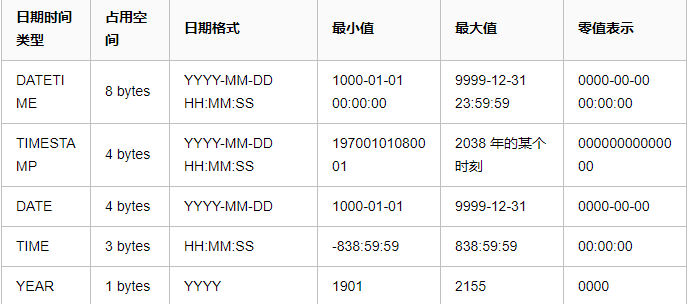
4. information_schema元数据
information_schema 数据库中所有的表
1 | mysql> use information_schema; |
查找引擎是innodb的表
1 | mysql> select table_name,engine from information_schema.tables where engine = 'innodb'; |
查找数据类型是set的表
1 | mysql> select table_schema,table_name,column_name from information_schema.columns where data_type='set'; |
查看每个数据库下表的个数
1 | mysql> select table_schema,count(*) from information_schema.tables group by table_schema; |
5. MySql数据的备份与恢复
背景知识
MySql数据的备份分为冷热备份。
冷备份:停止服务进行备份。即停止数据库的写入
热备份:不停止服务进行备份(在线)
MyIsam引擎只支持冷备份,InnoDB支持热备份
InnoDB引擎是事务性存储引擎,每一条语句都会写日志,并且每一条语句在日志里面都有时间点,那么在备份的时候,mysql可以根据这个日志来进行redo和undo,将备份的时候没有提交的事务进行回滚,已经提交了的进行重做。但是MyIsam不行,MyIsam是没有日志的,为了保证一致性,只能停机或者锁表进行备份。
InnoDB不支持直接复制整个数据库目录
mysqlhotcopy工具进行快速备份:mysqlhotcopy是一个perl脚本,最初由Tim Bunce编写并提供。他使用LOCK TABLES 、FLUSH TABLES和cp或scp来快速备份数据库。他是备份数据库或单个表的最快途径,但他只能运行在数据库目录所在机器上,并且只能备份myisam类型的表。
Mysqldump
MySQLdump是MySQL自带的导出数据工具,即mysql数据库中备份工具,用于将MySQL服务器中的数据库以标准的sql语言的方式导出,并保存到文件中。Mysqldump是一个客户端逻辑备份的工作,备份的SQL文件可以在其他MySQL服务器上进行还原。
注意事项:
备份数据—>至少有对该表的 select 权限
备份视图—>至少有show view 权限,触发器需要 trigger
如需锁表—>不能使用 –single-transaction选项
如需还原,需要有对应的执行权限。如 create表,则需要有对该库的create权限。
对于大量数据来说,物理备份更为合适,因为它可以快速还原。
如果表以 Innodb引擎为主,可考虑使用MySQL的 mysqlbackup 命令,因为它提供了最好的Innodb备份,当然也可以备份MyIsam等其他存储引擎。
如果表以 MyIsam引擎为主,可考虑使用 mysqlhotcopy ,它可能比 mysqldump表现的更好。
mysqldump参数解析
1 | 查询该命令的帮助信息(有很多参数,具体也可以``man``一下) |
–lock-tables 表示 一次性锁定当前库的所有表,而不是锁定当前导出表。
mysqldump实例
1. 导出、导入所有的库(–all-databases,-A 导出全部数据库)
1 |
|
2. 导出、导入某个库(比如world库)
1 |
|
3. 导出、导入部分库(比如world库、haoransunDB库)(–databases,-B 导出部分数据库)
1 |
|
4. 导出、导入某个库的某些表数据
1 | # 导出world库的city、country表数据(可以在导出时加--add-locks参数,表示导出时锁定数据库表) |
5. 只导出数据库结构,不导出数据(–no-data,-d 只导出表结构,不导出表数据)
1 | # 导出world库下所有的表结构(不导出表数据)(去掉下面的--add-drop-table参数也可以) |
6. 完整导出时过滤某些库(使用–databases,而不是–all-databases)
1 | # 在导出整个数据库时,过滤掉information_schema、mysql、``test``、performance_schema这几个库 |
mysqldump日常操作语句集锦
1 | mysqldump的几种常用方法: |
备份Mysql数据库通常使用命令
1 | 1)备份world库 () |
Mysqlpump
mysqlpump是mysqldump的一个衍生,mysqldump备份功能这里就不多说了,现在看看mysqlpump到底有了哪些提升,详细可以查看官网文档。mysqlpump和mysqldump一样,属于逻辑备份,备份以SQL形式的文本保存。逻辑备份相对物理备份好处是不关心log的大小,直接备份数据即可。
Mysqlpump主要特点
- 并行备份数据库和数据库中的对象的,加快备份过程。
- 更好的控制数据库和数据库对象(表,存储过程,用户帐户)的备份。
- 备份用户账号作为帐户管理语句(CREATE USER,GRANT),而不是直接插入到MySQL的系统数据库。
- 备份出来直接生成压缩后的备份文件。
- 备份进度指示(估计值)。
- 重新加载(还原)备份文件,先建表后插入数据最后建立索引,减少了索引维护开销,加快了还原速度。
- 备份可以排除或则指定数据库。
Mysqlpump缺点
- 只能并行到表级别,如果表特别大,开多线程和单线程是一样的,并行度不如mydumper;
- 无法获取当前备份对应的binlog位置;
- MySQL5.7.11之前的版本不要使用,并行导出和single-transaction是互斥的;
用法
太懒了,不想写,自行查看官网吧 (0.0)
Mysqlpump多线程架构图
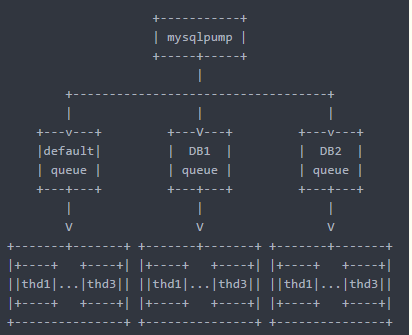
- mysqlpump是MySQL5.7的官方工具,用于取代mysqldump,其参数与mysqldump基本一样;
- mysqlpump是多线程备份,但只能到表级别,单表备份还是单线程;
- mysqldump备份时,有个默认队列(default),队列下开N个线程去备份数据库/数据库中的表;
- 支持开多个队列(对应不同库/表),然后每个队列设置不同线程,进行备份;
Mysqlpump支持基于库和表的并行导出,Mysqlpump的并行导出功能的架构为:队列+线程,允许有多个队列(–parallel-schemas),每个队列下有多个线程(N),而一个队列可以绑定1个或者多个数据库(逗号分隔)。Mysqlpump的备份是基于表并行的,对于每张表的导出只能是单个线程的,这里会有个限制是如果某个数据库有一张表非常大,可能大部分的时间都是消耗在这个表的备份上面,并行备份的效果可能就不明显。这里可以利用Mydumper其是以chunk的方式批量导出,即Mydumper支持一张表多个线程以chunk的方式批量导出。但相对于Mysqldump有很大提升。
效率对比
mysqlpump的备份效率是最快的,mydumper次之,mysqldump最差。
在IO允许的情况下,能用多线程就别用单线程备份。并且mysqlpump还支持多数据库的并行备份,而mydumper要么备份一个库,要么就备份所有库
mysqlpump备份的数据恢复时会先插入数据, 再建索引, 而mysqldump备份的数据恢复是在建立表的时候就把索引加上了, 所以前者备份的数据恢复时速度要快一点!
**mysqlpump备份时并发线程的数量还是要看自身服务器的IO负载能力,并不是说一味的增加并发线程数量就可以加快速度**
6 Mysql-Binlog简介及其作用
MySql常见日志

简介
MySQL Binlog 是一种二进制文件(binary log,以下描述中简称binlog),用于记录数据库的变更,如:表结构变更(DDL)、数据变更(DML)以及变更所花费的时间。binlog中有个核心元素:Event,所有的变更信息都以Event单位进行描述,记录在log中。(注意:Select、Show等查询类语句不属于DB 变更,不会记录在binlog中).MySQL的二进制日志是事务安全型的。
作用 + 详解(复制和恢复)
1. MySQL集群的主从复制(For replication)
MySQL Replication 在 Master端开启binlog,Master把它的二进制日志传递给 Slaves 以达到 master-slave数据一致的目的。
流程:
MySQL 的 Master 节点会将本地记录的 binlog 变更实时发送给给 Slave 节点,Slave收到后会先放在本地 relay log 中,再基于relay log进行逻辑回放。
mysql主从复制是逻辑复制(即sql语句复制,可以跨机器),非物理复制
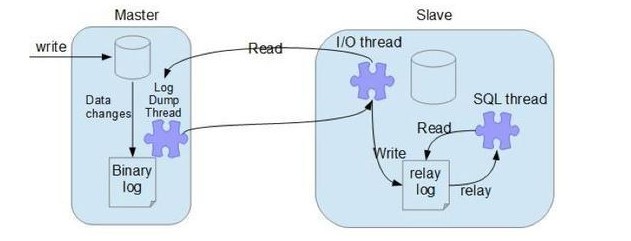
2. 数据恢复
Point-in-Time (Incremental) Recovery Using the Binary Log)
当Slave节点crash且需要备份恢复(基于数据备份文件)时,操作步骤为:
首先将已备份(一般按天)的数据文件恢复到Slave节点上
由于备份文件是定时非实时的,那么如何从过去backup的point/time追上不断变更的当前的point/time?就是利用binlog来实现,每次backup开始时,都会记录当时的binlog point-in-time即GTID(追溯)在recover backup后,接着使用backup时记录的GTID告诉Master,Slave要从这个point追溯binlog
一定时间后,Slave即和Master保持同步
3. 启用 Binlog
开启binlog日志大约会有1%的性能消耗。
启用binlog,通过配置 /etc/my.cnf 配置文件的 log-bin选项:
在配置文件中加入 log-bin 配置,表示启用binlog。(注:名称若带有小数点,则只取第一个小数点前的部分作为名称)
一般log-bin名称起有意义的,此处只为方便演示
1 | [mysqld] |
也可以通过 SET SQL_LOG_BIN=1 命令来启用 binlog,通过 SET SQL_LOG_BIN=0 命令停用 binlog。启用 binlog 之后须重启MySQL才能生效。
server-id作用:
1.mysql的同步数据中是包含server-id的,用于标识该语句最初从哪个server写入,所以server-id一定要有
2.每一个同步中的slave在master上都有对应的一个master线程,该线程就是通过slave的server-id来标识的;每个slave在master端最多有一个master线程,如果两个slave的server-id相同,则后一个连接成功时,前一个会被踢掉,
slave主动连接master之后,如果slave上面执行了slave stop;则连接断开,但是master上对应的线程并没有退出;当slave start之后,master不能再创建一个线程而保留原来的线程,那样同步就可能有问题
3.在mysql做主主同步时,多个主需要构成一个环状,但是同步的时候又要保证一条数据不会陷入死循环,这里就是靠server-id来实现的
MySQL binlog后面的编号最大是多大?
binlog序号是从000001开始,当达到999999后,binlog会怎么样?
最大值可以达到2^31-1**
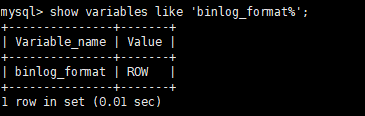
查看当前binlog_format格式
1 | mysql> show variables like 'binlog_format%'; |
常用Binlog操作命令:
1 | # 是否启用binlog日志 |
4. 写Binlog时机
对支持事务的引擎如InnoDB而言,必须要提交了事务才会记录binlog。binlog 什么时候刷新到磁盘跟参数 sync_binlog 相关。
- 如果设置为0,则表示MySQL不控制binlog的刷新,由文件系统去控制它缓存的刷新;
- 如果设置为不为0的值,则表示每
sync_binlog次事务,MySQL调用文件系统的刷新操作刷新binlog到磁盘中。 - 设为1是最安全的,在系统故障时最多丢失一个事务的更新,但是会对性能有所影响。
如果 sync_binlog=0 或 sync_binlog大于1,当发生电源故障或操作系统崩溃时,可能有一部分已提交但其binlog未被同步到磁盘的事务会被丢失,恢复程序将无法恢复这部分事务。
在MySQL 5.7.7之前,默认值 sync_binlog 是0,MySQL 5.7.7和更高版本使用默认值1,这是最安全的选择。一般情况下会设置为100或者0,牺牲一定的一致性来获取更好的性能。
5. Binlog文件及其扩展
binlog日志包括两类文件:
- 二进制日志索引文件(文件名后缀为.index)用于记录所有有效的的二进制文件(记录哪些日志文件正在被使用)
- 二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML语句事件
binlog是一个二进制文件集合,每个binlog文件以一个4字节的魔数开头,接着是一组Events:
- 魔数:0xfe62696e对应的是0xfebin;
- Event:每个Event包含header和data两个部分;header提供了Event的创建时间,哪个服务器等信息,data部分提供的是针对该Event的具体信息,如具体数据的修改;
- 第一个Event用于描述binlog文件的格式版本,这个格式就是event写入binlog文件的格式;
- 其余的Event按照第一个Event的格式版本写入;
- 最后一个Event用于说明下一个binlog文件;
- binlog的索引文件是一个文本文件,其中内容为当前的binlog文件列表
当遇到以下3种情况时,MySQL会重新生成一个新的日志文件,文件序号递增:
- MySQL服务器停止或重启时
- 使用
flush logs命令; - 当 binlog 文件大小超过
max_binlog_size变量的值时;
max_binlog_size的最小值是4096字节,最大值和默认值是 1GB (1073741824字节)。事务被写入到binlog的一个块中,所以它不会在几个二进制日志之间被拆分。因此,如果你有很大的事务,为了保证事务的完整性,不可能做切换日志的动作,只能将该事务的日志都记录到当前日志文件中,直到事务结束,你可能会看到binlog文件大于 max_binlog_size 的情况。
6. Binlog的日志格式
记录在二进制日志中的事件的格式取决于二进制记录格式。支持三种格式类型:
- STATEMENT : 基于SQL语句的复制
- ROW:基于行的复制
- MIXED:混合模式复制
在 MySQL 5.7.7 之前,默认的格式是 STATEMENT,在 MySQL 5.7.7 及更高版本中,默认值是 ROW。日志格式通过 binlog-format 指定,如 binlog-format=STATEMENT、binlog-format=ROW、binlog-format=MIXED。
逐一介绍
STATEMENT:基于SQL语句的复制(statement-based replication, SBR) ,日志文件小,节约IO,提高性能。准确性差,对一些系统函数不能准确复制或不能复制,如now()、uuid()等。
ROW:此格式下,所有表的每条记录的详细数据变更都会以Event形式记录在binlog中,包含变更类型(INSERT、UPDATE、DELETE),以及变更前后的每个字段的值等。此格式下要求表要有PrimaryKey,以便高效识别。日志文件大,较大的网络IO和磁盘IO。
MIXED:MIXED是STATEMENT和ROW格式的混合体,此格式下,默认是statement-based logging,但是在一些场景下会自动转为row-based,文件大小适中,有可能发生主从不一致问题。
7. mysqlbinlog命令使用
服务器以二进制格式将binlog日志写入binlog文件,如果要以文本格式显示其内容,可以使用 mysqlbinlog 命令。
二进制日志文件默认存储在 /var/lib/mysql 目录下
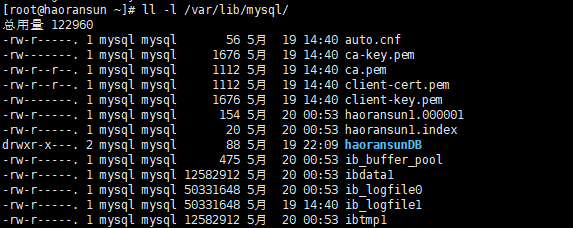
1 | `mysqlbinlog: unknown variable ``'default-character-set=utf8'` |
方法1:
在MySQL的配置/etc/my.cnf中将default-character-set=utf8 修改为 character-set-server = utf8,但是这需要重启MySQL服务,如果你的MySQL服务正在忙,那这样的代价会比较大。
方法2:
mysqlbinlog –no-defaults -v /var/lib/mysql/haoransun1.00001 命令打开
1 | # mysqlbinlog 的执行格式 |
7. Binglog事件结构
一个事件对象分为事件头和事件体,事件的结构如下:
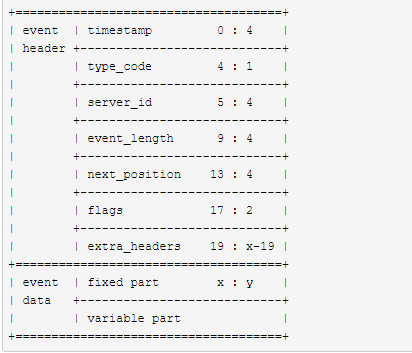
如果事件头的长度是 x 字节,那么事件体的长度为 (event_length - x) 字节;设事件体中 fixed part 的长度为 y 字节,那么 variable part 的长度为 (event_length - (x + y)) 字节
Binlog Event 简要分析
从一个最简单的实例来分析Event,包括创建表,插入数据,更新数据,删除数据;
1 | CREATE TABLE `test1` ( |
日志格式为 row,查看所有event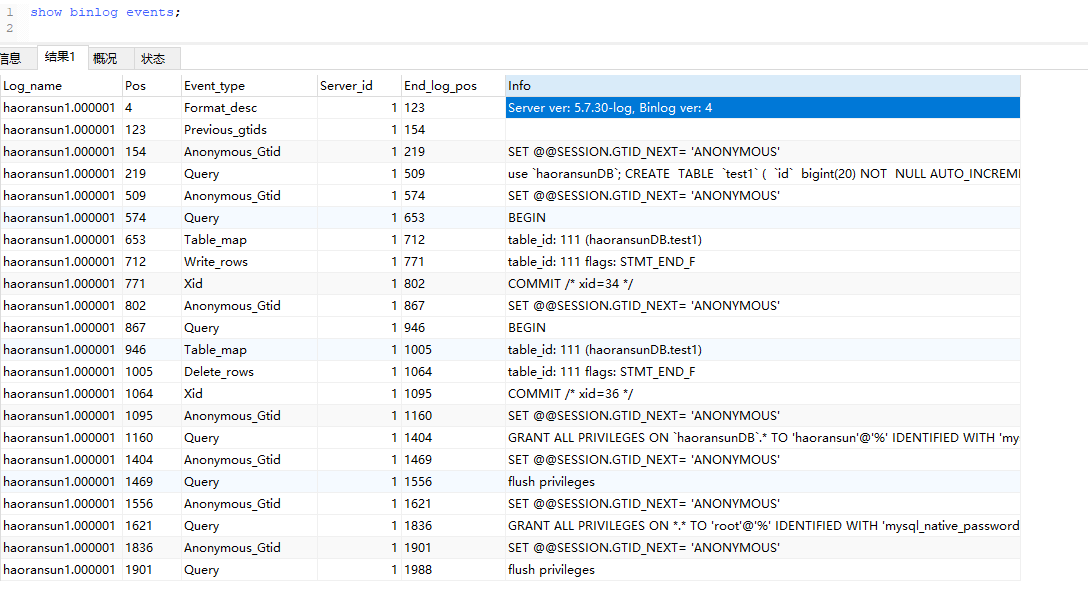
自己可以修改日志格式为 statement,再次查看不同点。
基于时间点的恢复
创建测试数据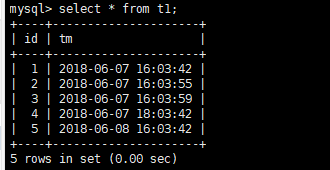
备份数据库
1 | [root@haoransun ~]# mysqldump -uroot -p --single-transaction --quick --flush-logs --master-data=2 -A --triggers --routines --events --set-gtid-purged=off > /tmp/backup/backup.sql |
再新增测试数据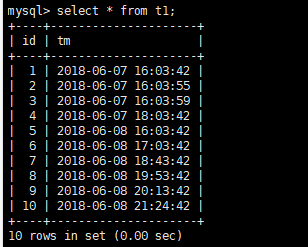
删除表中所有数据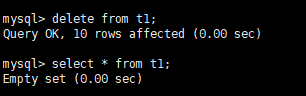
确认最近一次备份后的二进制日志保存文件
2020-05-20 02:35 —–>这个是备份前5条数据的时间点
2020-05-20 02:39 —–>这个是备份删除操作的时间点
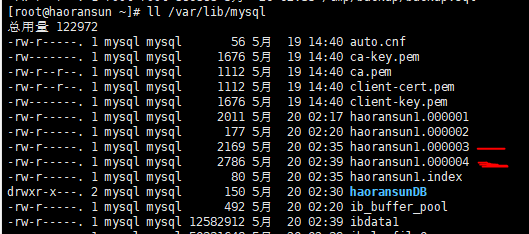

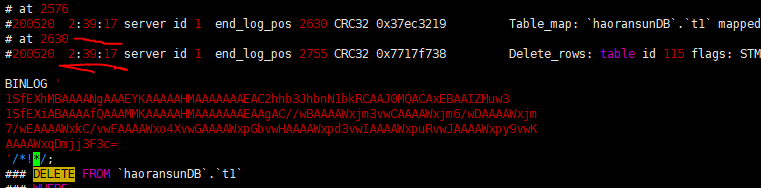
确认删除数据的时间点
1 | [root@haoransun ~]# mysqlbinlog --no-defaults -v /var/lib/mysql/haoransun1.000004 > /tmp/backup/result.sql |
还原数据库
1 | [root@haoransun ~]# mysql -uroot -hlocalhost -p haoransunDB < /tmp/backup/backup.sql |
检查表中数据,与第一次的图对比,说明还原成功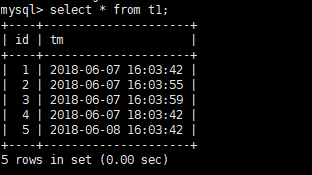
恢复指定时间点被删除的数据
1 | [root@haoransun ~]# mysqlbinlog --no-defaults --stop-datetime='2020-05-20 02:39:17' --skip-gtids /var/lib/mysql/haoransun1.000004 | mysql -uroot -hlocalhost -p |
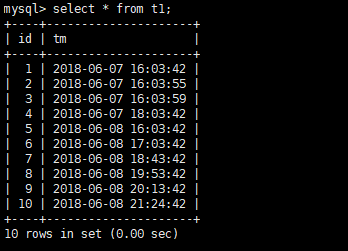
6 慢查询
1. 概念
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
long_query_time的默认值为10,意思是运行10S以上的语句。
默认情况下,Mysql数据库并不启动慢查询日志,需要我们手动来设置这个参数,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
2. 用途
记录下所有执行时间超过long_query_time时间的SQL语句,帮我们找到执行慢的SQL,方便我们对这些SQL进行优化。
3. 是否开启慢查询
1 | mysql> show variables like 'slow_query%'; |
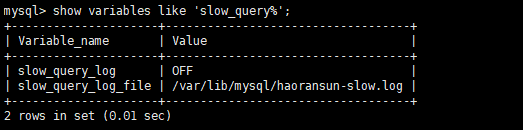
slow_query_log = off,表示没有开启慢查询
slow_query_log_file 表示慢查询日志存放的目录
4. 开启慢查询(调优需要时才开启,因为很耗性能,建议使用即时性的)
方法1:(即时性的,重启mysql之后生效,常用)
1 | mysql> set global slow_query_log=1; |
开启之后 我们会发现 /var/lib/mysql下已经存在 haoransun-slow.log 了,未开启的时候默认是不存在的。

方法2:(永久性的)
在/etc/my.cfg文件中的[mysqld]中加入:
1 | [mysqld] |
5. 设置慢查询记录时间
查询慢查询记录的时间,默认是10秒钟,意思是大于10秒才算慢查询,才会被记录。
1 | mysql> show variables like 'long_query%'; |
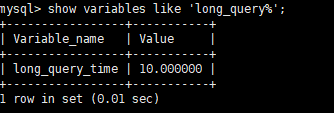
现在设置慢查询记录时间为1秒:
1 | mysql> set global long_query_time=1; |
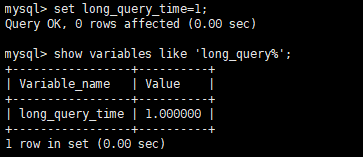
6. 写一条慢查询语句
以 world库为例,想办法写一条 查询时间超过1s的语句
1 | select c.*,b.* ,l.* from city c left join country b on c.CountryCode = b.`Code` left join countrylanguage l on b.`Code`=l.CountryCode ORDER BY c.District,b.GovernmentForm; |
在日志中查看:
tail -f /var/lib/mysql/haoransun-slow.log
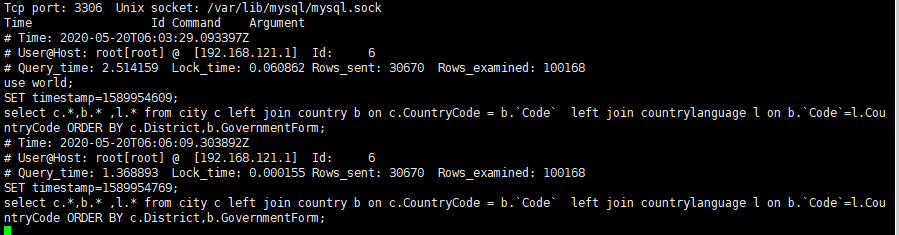
我们可以看到查询的时间,用户,花费的时间,使用的数据库,执行的sql语句等信息。在生产上我们就可以使用这种方式来查看 执行慢的sql。
6.1. 开启慢查询,MySql没有将慢SQL记录进慢日志文件(可能原因)
原因1:
在线动态设置long_query_time,比如 set global long_query_time=0.5,该设置对当前已建立的连接不会生效。
原因2:
慢SQL里有大量锁等待,慢SQL的执行时间不包含锁等待的时间。
原因3:
log_slow_admin_statements=0,因此alter, create index, analyze table等操作即使超过 long_query_time,也不会记录到慢日志中。
原因4:
min_examined_row_limit设置为非0值,SQL检查行数未超过该值,也不会记录。
原因5:
slow log文件钻句柄发生了变化,如运行期间用vim打开log,最后又保存退出,此时文件句柄发生变化,需要执行flush slow logs。
原因6:
误将slow_query_log_file 当作 slow log的开关,设置为1,此时slow log文件名为1。
7. 查询慢查询的次数
1 | show global status like 'slow_queries'; |
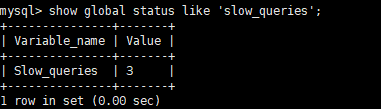
再次执行慢查询sql后,查询慢查询的次数会变为4
1 | select sleep(2); |
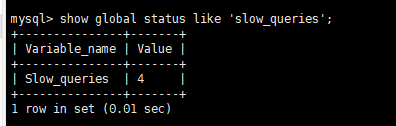
在慢查询日志也可看到详细结果
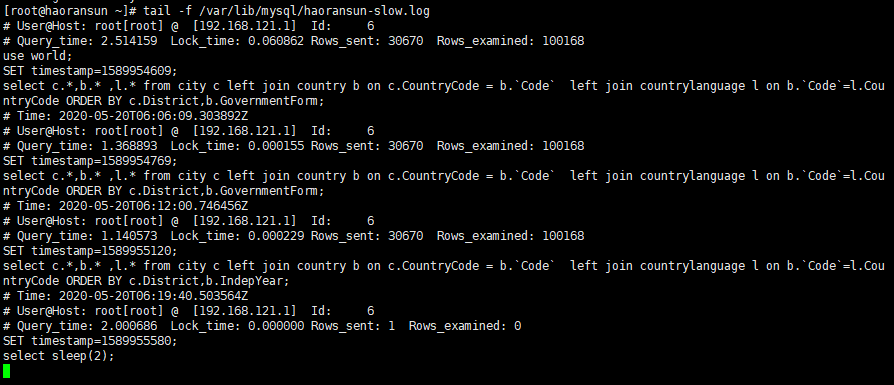
在生产中,我们会分析查询频率高的,且是慢查询的sql,并不是每一条查询慢的sql都需要分析。
** 查看没有使用索引的查询,会耗费大量性能,一般慎用。log_queries_not_using_indexes=on**
7. 慢查询日志分析工具 Mysqldumpslow
在生产上会有很多慢查询,采用上述的方法查看慢查询sql会很麻烦,因此MySQL提供了慢查询日志分析工具 Mysqldumpslow。
其功能是:
统计不同慢sql的出现次数(Count),执行最长时间(Time),累计总耗费时间(Time),等待锁的时间(Lock),发送给客户端的行总数(Rows),扫描的行总数(Rows)
(1)查询Mysqldumpslow的帮助信息
1 | whereis mysqldumpslow |
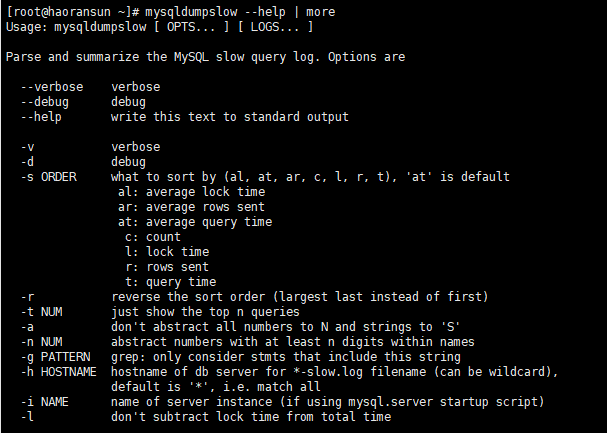
参数解析
- -s,是order的顺序,主要有c(按query次数排序)、t(按查询时间排序)、l(按lock的时间排序)、r (按返回的记录数排序)和 at、al、ar,前面加了a的代表平均数
- -t,是top n的意思,即为返回前面多少条的数据
- -g,后边可以写一个正则匹配模式,大小写不敏感的
- -r:倒序
(2)案例:取出耗时最长的两条sql
格式:mysqldumpslow -s t -t 2 慢日志文件
1 | mysqldumpslow -s t -t 2 /var/lib/mysql/haoransun-slow.log |
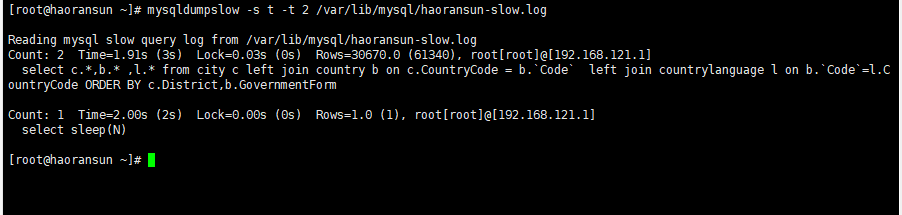
参数分析:
- 出现次数(Count),
- 执行最长时间(Time),
- 累计总耗费时间(Time),
- 等待锁的时间(Lock),
- 发送给客户端的行总数(Rows),
- 扫描的行总数(Rows),
(3)案例:取出查询次数最多,且使用了sleep关键字的1条sql
1 | mysqldumpslow -s c -t 1 -g 'sleep' /var/lib/mysql/haoransun-slow.log |

8. show profile
分析当前会话中语句执行的资源消耗情况
(1)查看是否开启profile,mysql默认是不开启的,因为开启很耗性能
1 | mysql> show variables like 'profiling%'; |
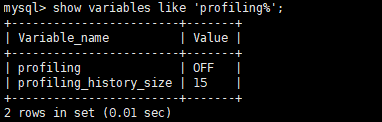
(2)开启profile(会话级别的,关闭当前会话就会恢复原来的关闭状态)
1 | mysql> set profiling=1; |
(3)关闭profile
1 | mysql> set profiling=0; |
(4)显示当前执行的语句和时间
1 | mysql> show profiles; |
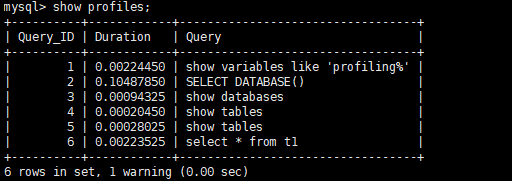
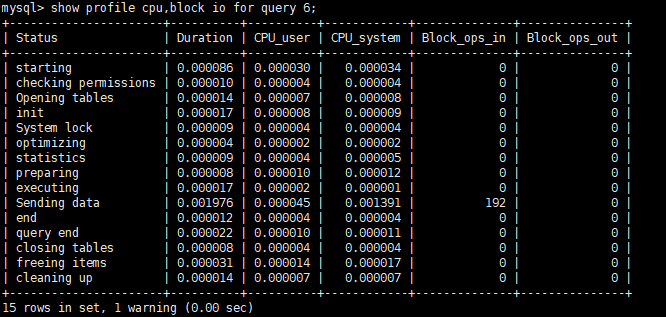
(5)显示当前查询语句执行的时间和系统资源消耗
1 | # show profiles中query_id等于6的sql所占的CPU资源和IO操作 |