Author: haoransun
Wechat: SHR—97
一. TextRank算法介绍
TextRank算法相对来说,是一种很简单的算法。算法的流程类似于Kleinberg的HITS算法,Google的PageRank算法,不得不说GooglePageRank算法的出现引发了搜索引擎的一次变革。PageRank算法成功运用到互联网上来评估网页的重要性,当用户搜索时,返回与搜索问题相关又有质量的网页。TextRank算法可以说借鉴了PageRank算法的思想,也非常成功的运用到文章的引文提取,关键词提取上。当然一个单纯的算法来提取关键词,可能效果并不如意,可以结合其他算法,比如TF-IDF来筛选有力表达主题/文章中心思想的词语。
二. TextRank算法解析
TextRank算法对文章关键词进行提取的过程,实际就是迭代计算一个由文章中的词语构建的有向有权图G=(V,E) 。其中集合V(图中的节点)有文章中的词语构成,中文我们可以利用ansj_seg进行分词筛选特定词性的词。集合E(图中的边)由文章中的词在特定的滑动窗口下组成。E是一个VxV的子集。图中任意两节点Vi,Vj之间的权重为Wij,而对于一个节点Vi,In(Vi)表示图中指向该节点的其他节点集合,入度。而Out(Vi)为节点Vi指向的其他节点的集合。
对于TextRank算法每次迭代是Vi节点的得分的计算公式为: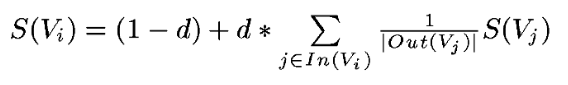
其中d是一个阻尼系数,其值在0到1之间。代表从图中一节点指向其他任意一节点的概率, 一般取值为 0.85。上述的公式,表示当前节点Vi的值为所有指向Vi的节点Vj给予的值的和。就相当于,我现在手上有1个苹果,如果我收集了我朋友给我的苹果,我将有多少个苹果的问题。假如我有两个朋友,他们会给我一些苹果,而我现在拥有的苹果数量就是他们给我的苹果数量的和。朋友A有3个苹果,但是同样他有3个朋友,而且需要给苹果给他的朋友,所以只能给我3/3=1个苹果。朋友B有6个苹果,他有3个朋友,那么他给我6/3=2个苹果。那我现在手头将有1+1+3=5个苹果。实际中还要乘阻尼系数。TextRank算法就是这样迭代计算每个节点的值,而算法停止可以采用指定的迭代次数或者图中节点的值跟上次结果值的误差是否小于一个制定的极限值,一般取值为:0.0001。
三. TextRank算法文本关键词提取
主要步骤:
- 利用分词工具对文本进行分词
- 指定滑动窗口大小
- 滑动窗口经过文本词组,构建有向有权图。
- 迭代计算有向有权图,直到收敛。
注意:在构建有向有权图时候,只筛选特定词性的词作为节点,比如名词,动词,形容词等,同时删除停用词。
举例
一个文本,对其进行分词后,词组组成一个集合:
T = [S1,S2,S3,S1,S5,S6,S7,S8,S9]指定滑动窗口大小为3
窗口里面的词组构建图,每次都是以窗口头结点为主节点。如下图所示:
A:窗口第一次经过的词组,那么组成的边有:(S1,S2),(S2,S1),(S1,S3),(S3,S1)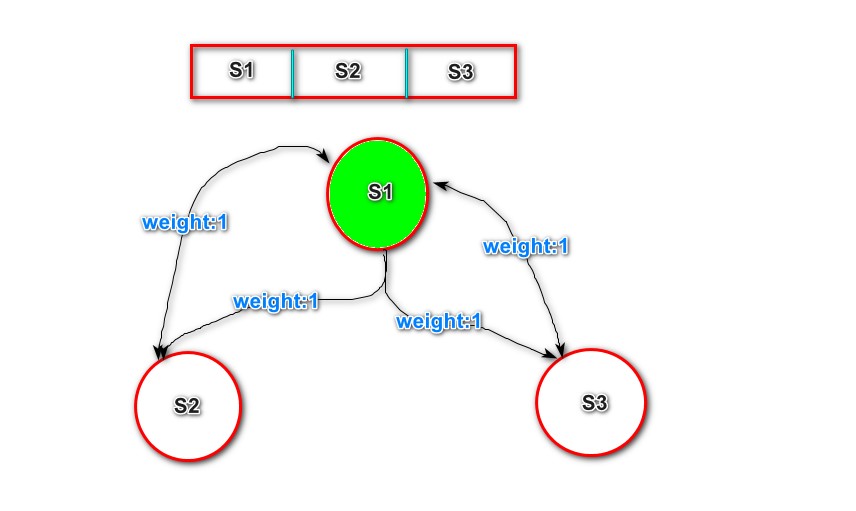
B:窗口第二次经过的词组,组成的边有:(S2,S3),(S3,S1),(S2,S1),(S1,S2)。遇到重叠的边,则权重加1.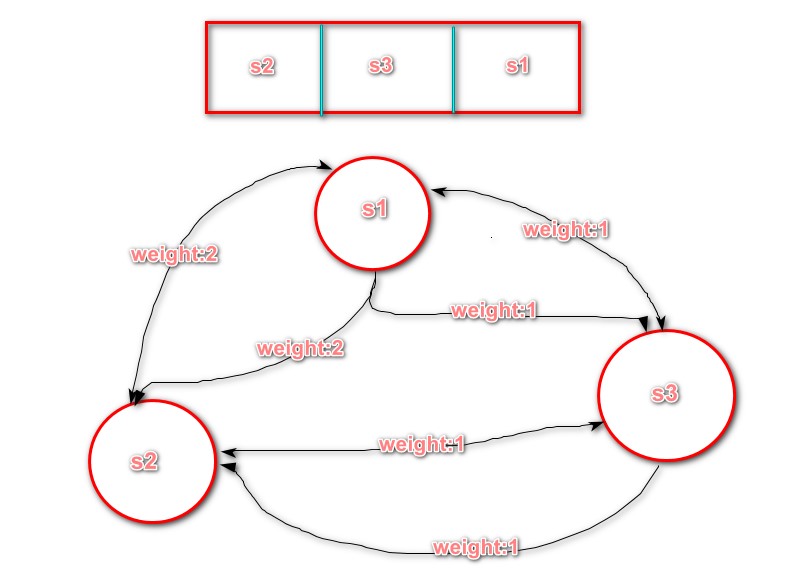
C:构建图完成之后,按照textRank算法的执行步骤,迭代计算,直到收敛。
D:最后对节点的权重排序输出。
四. TextRank算法Scala代码实现
TextRank算法的实现,这里采用scala,分词工具采用ansj_seg,这里scala代码实现的TextRank算法,只实现关键词的提取,没有实现句子提取,后续再补充。代码略。
调用方式:
1 |
|
结果:
1 | (算法,n,1.0) |