Author: haoransun
Wechat: SHR—97
1 BigData是什么?
巨量资料,需要利用目前主流软件工具在合理的时间范围内对数据进行截取,转换已达到帮助企业获取有用资讯的目的。
数据量极大:GB、TB、PB数据样板足够大。
数据时效性:time-value 数据处理速度快,合理的时间范围。
数据多样性:数据存在形式多样化。
数据可疑性:数据要有价值。—清洗、降噪(沙海淘金)
2 BigData面临的问题?
存储、分析:
方案:
垂直提升:升级硬件,成本高 计算机-摩尔定律(每18个月,成本不变-性能提升1倍)
水平扩展:成本可线性控制–分布式思维 √
Hadoop就是在通过线性服务扩展,去解决大数据所面临的存储和计算。
Hadoop有两个模块:
HDFS hadoop distributed file system:解决大数据存储问题。
MapReduce:通过Map阶段和Reduce阶段实现对大数据的分布式并行计算。
3 Hadoop生态:
HDFS:分布式文件存储系统
MapReduce:分布式计算引擎
HBase:基于HDFS上的一款列存储NoSQL数据库
Flume:分布式日志采集
Kafka:分布式消息队列
Mahout:机器学习算法库,绝大多数算法通过MapReduce计算模型实现
Zookeeper:分布式协调服务
大数据计算
离线计算:Hadoop Map Reduce
近实时计算:Spark Core(离线计算)
实时计算:Storm、KafkaStream、SparkStram
HDFS安装(单机环境-伪分布式)
1)CentOS-6.5 64 bit 基本配置
1.主机名必须CentOS
1 | vi /etc/sysconfig/network |
2.修改主机名和ip的映射关系
1 | vi /etc/hosts |
3.关闭本机的防火墙
1 | service iptables stop |
2)安装 JDK 配置 JAVA_HOME环境变量
附注:yum install -y lrzsz 使用rz进行上传
lrzsz自行百度(是一款在linux可代替ftp上传和下载的程序)
在usr/local安装jdk-rpm后,使用 ls /usr/java/latest可以产看安装信息
配置用户环境变量
1 | [root@CentOS local]# vi .bashrc |
使用jps看是否识别:jps [用于查看java进程]
3)配置 CentOS 系统的 SSH免密码登录(基于密钥的安全验证)
原始带密码用法:
1 | ssh root@192.168.80.100 |
SSH 为 Secure Shell的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH为建立在应用层基础上的安全协议。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
两种安全验证级别:
基于口令的安全验证
只要你知道你自己的账号和口令,就可以登录到远程主机。所有传输的数据都会被加密,但是不能保证你正在连接的服务器是你想连接的服务器。可能会有别的服务器在冒充真正的服务器,即受到中间人这种方式的攻击。基于密钥的安全验证
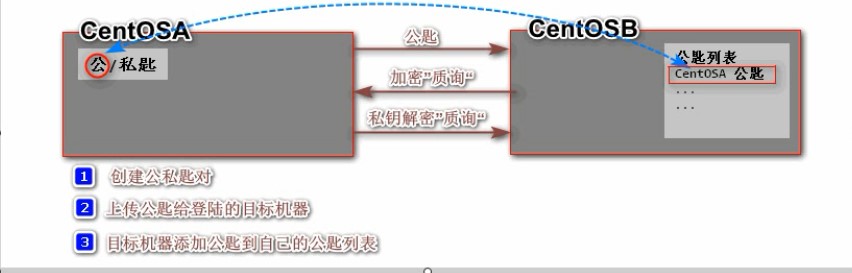
需要依靠密匙,也就是你必须为自己创建一对密匙,并把公用密匙放在需要访问的服务器上。如果你要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用你的密匙进行安全验证。服务器收到请求之后,先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用你的私人密匙解密再把它发送给服务器。用这种方式,你必须知道自己密匙的口令。但是,与第一种级别相比,第二种级别不需要在网络上传送口令。
第二种级别不仅加密所有传送的数据,而且“中间人”这种攻击方式也是不可能的(因为他没有你的私人密匙)。但是整个登录的过程可能需要10秒3.1 在自己的机器上产生公私钥对
1
2
3
4
5
6ssh-keygen -t rsa 使用rsa算法生成公私钥对(按4次回家即可)
在用户的家目录下
ls -al .ssh/ 即可看到
使用 ssh-copy-id CentOS 添加到目标机的目录下(CentOS为目标机名称)
被添加到 .ssh/authorized_keys文件中
ls -al .ssh/ 即可看到有了 .ssh/authorized_keys 才可免密码登录,使用 ssh root@CentOS 验证。
1
2
3cat .ssh/id_rsa.pub >> .ssh/authorized_keys
与
ssh-copy-id CentOS 等价4)安装配置 Hadoop(单机环境)
- 解压Hadoop tar包 到 /usr/目录下
1
2tar -zxf hadoop-2.6.0_x64.tar.gz -C /usr/
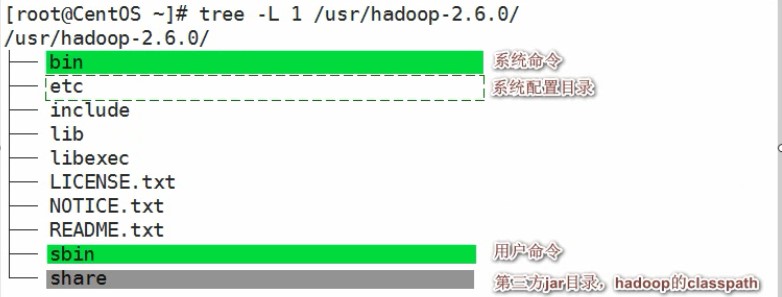
ls /usr/hadoop-2.6.0/ - 配置hadoop环境变量附注:hadoop的安装目录结构 使用插件
1
2
3
4
5
6
7
8
9
10
11vi .bashrc
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
PATH=\$PATH:\$JAVA_HOME/bin:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
:wq保存退出
source .bashrc 使其立即生效1
2
3yum install -y tree
使用 tree -L 2 /usr/hadoop-2.6.0/
可以查看hadoop的两级目录,2:代表看2级 1:看1级目录
配置参考 http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
这里的/tmp/hadoop-${user.name} 改成 /usr/hadoop-2.6.0/hadoop-${user.name} 安装在父级目录下
- 修改hadoop配置文件(参考上面的链接地址)
1 core-site.xml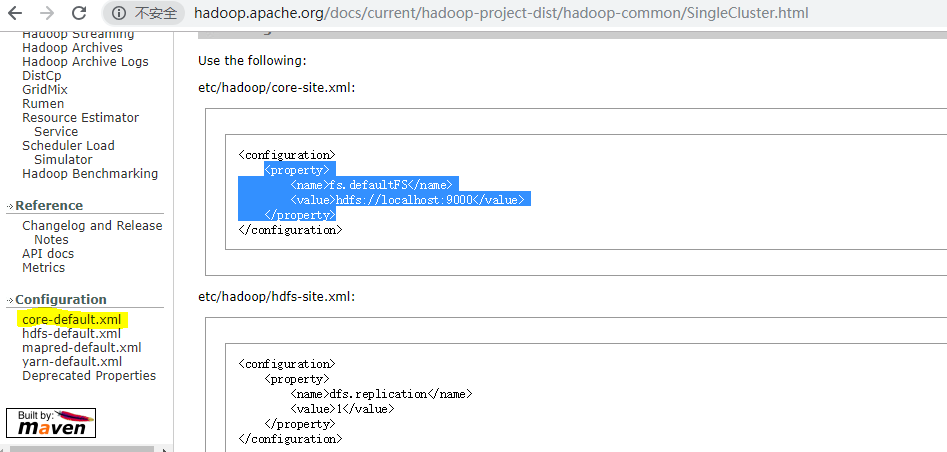

- 解压Hadoop tar包 到 /usr/目录下
此处配置的是访问Namenode服务节点的入口CentOS:9000
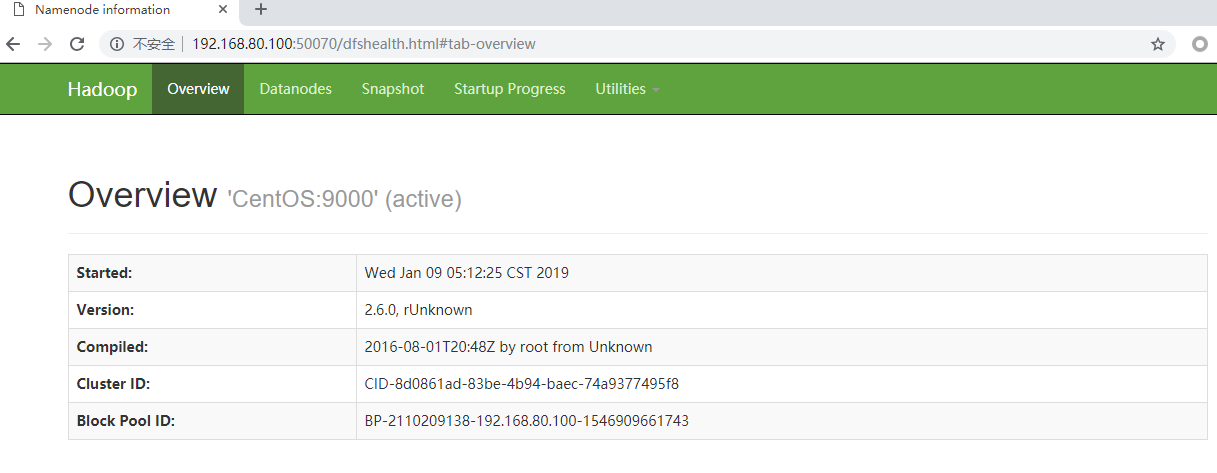
而CentOS:50010是访问Datenode服务节点的入口
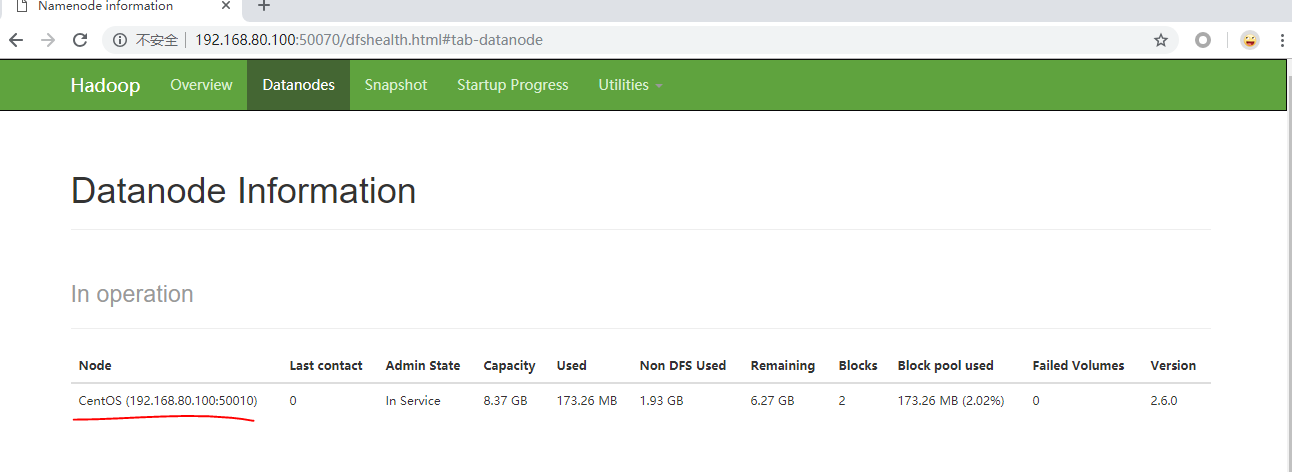
/usr/hadoop-2.6.0/hadoop-root 此处是整个Hdoop存储的基准目录(无论是Namenode存储元数据,还是Datenode存储块数据)他们都要存储在此基准目录下。(因为用户名是root,所以${user.name}被替换为root)
使用命令行:
1 | tree -L 2 /usr/hadoop-2.6.0/hadoop-root/ |
1 | vi /usr/hadoop-2.6.0/etc/hadoop/core-site.xml |
2 hdfs-site.xml
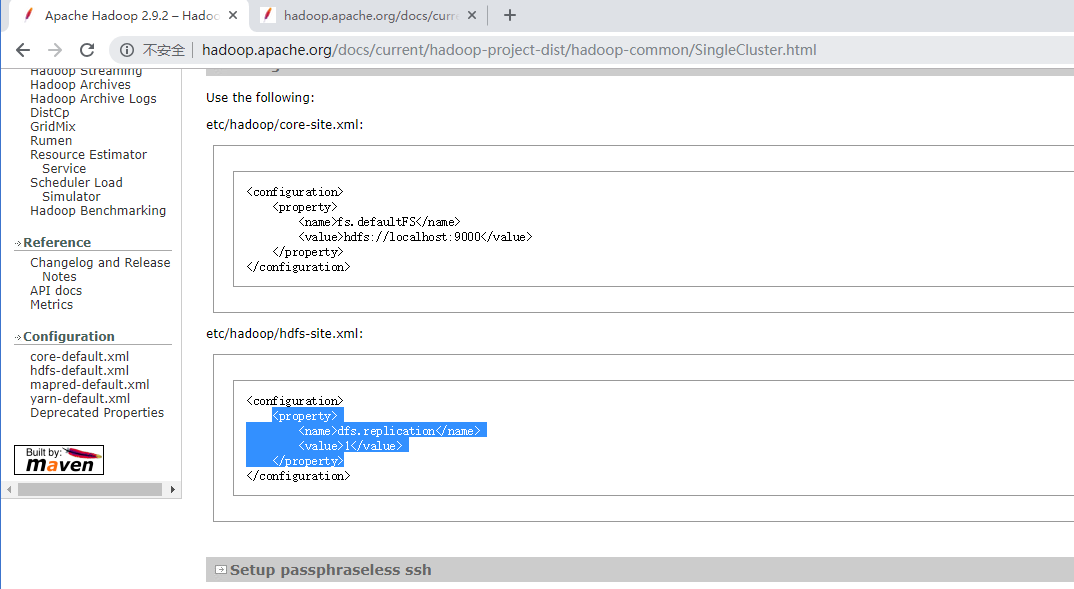
此处设置副本集,因为当前是伪分布式,只有一个机器,所以设置为1,块没有副本。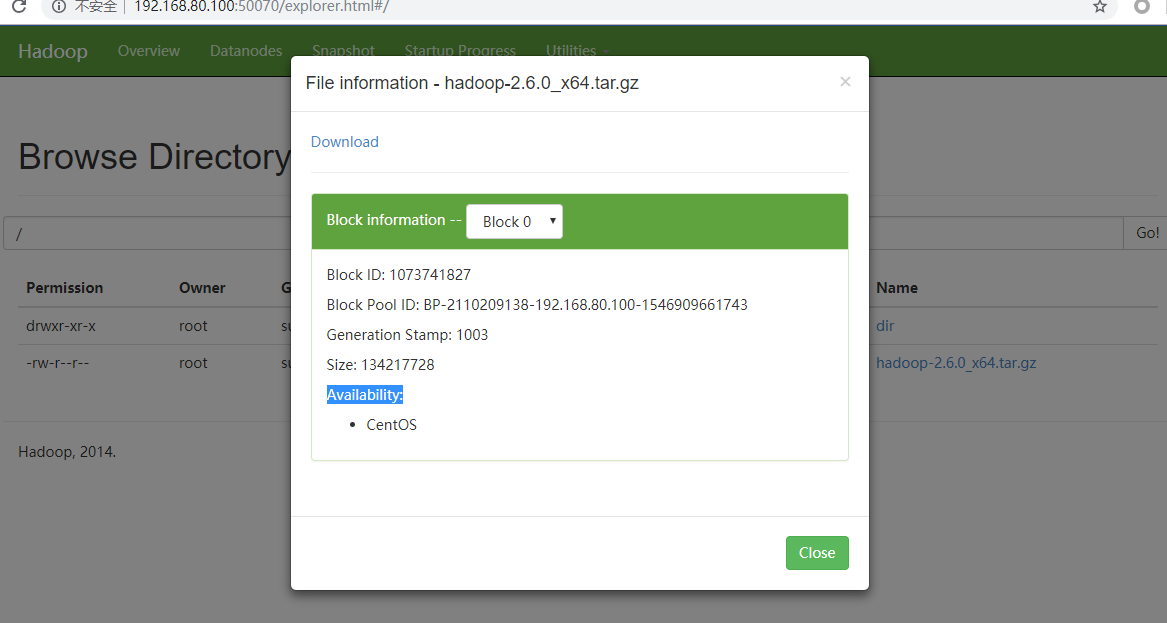
此处只有CentOS存储了
1 | vi /usr/hadoop-2.6.0/etc/hadoop//hdfs-site.xml |
3 slaves
1
2vi /usr/hadoop-2.6.0/etc/hadoop/slaves
将 localhost 改为 CentOS 即当前的主机名
启动 HDFS服务
第一次启动时参考链接,使用如下命令进行启动:
1 | hdfs namenode -format (仅第一次启动时需要) |
使用如下命令进行上传、删除操作
1 | hdfs dfs -put /root/hadoop-2.6.0_x64.tar.gz / |
页面效果: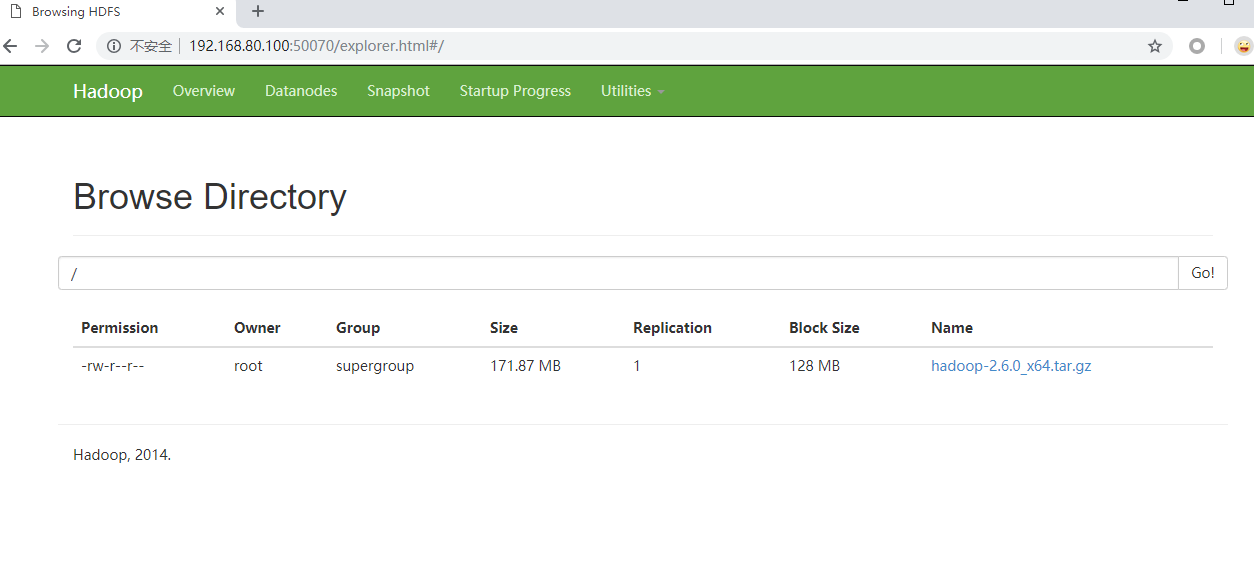
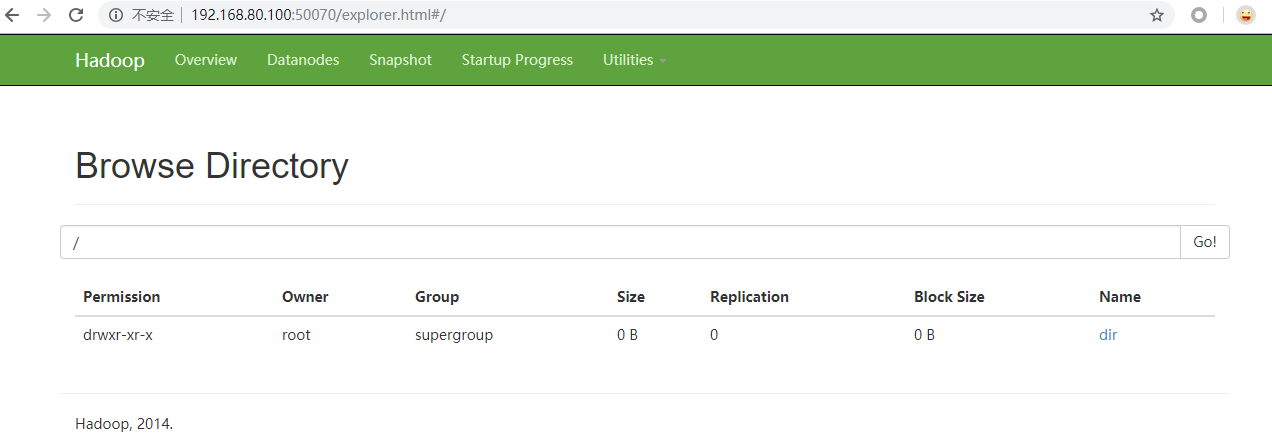
为什么需要使用hdfs namenode -format 对“老大”格式化呢?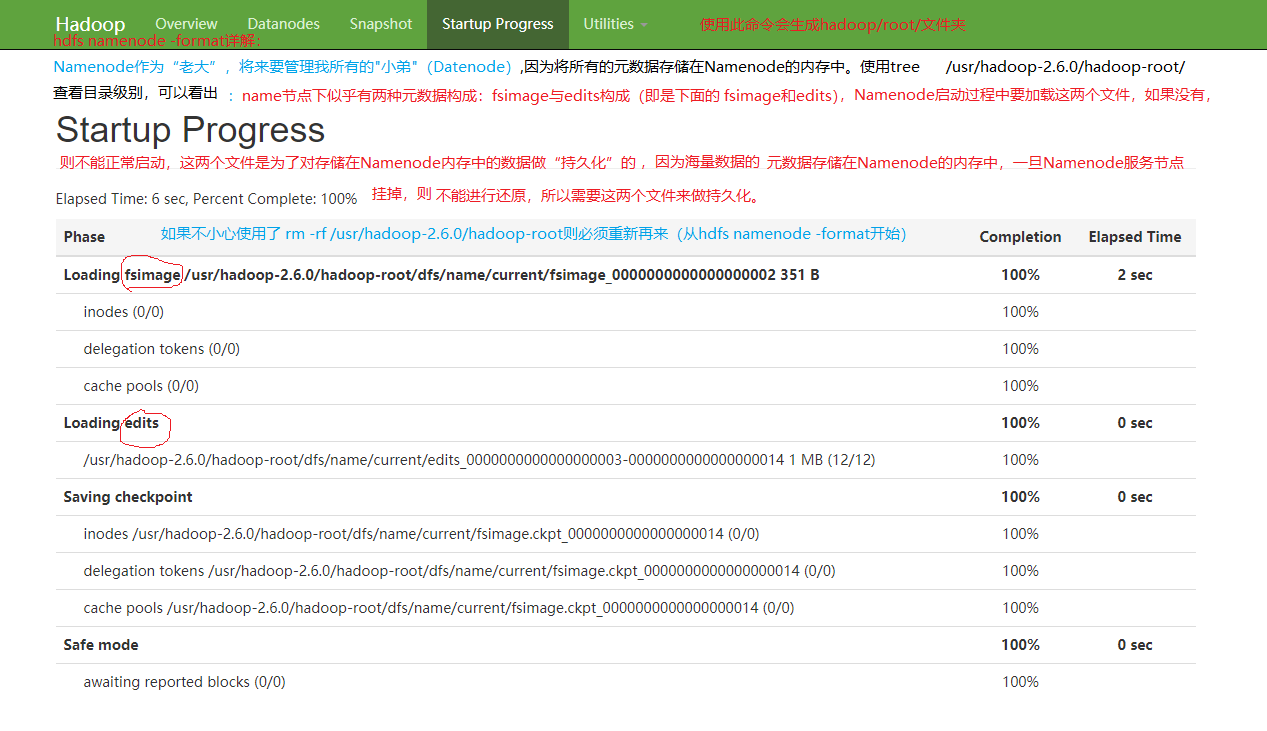
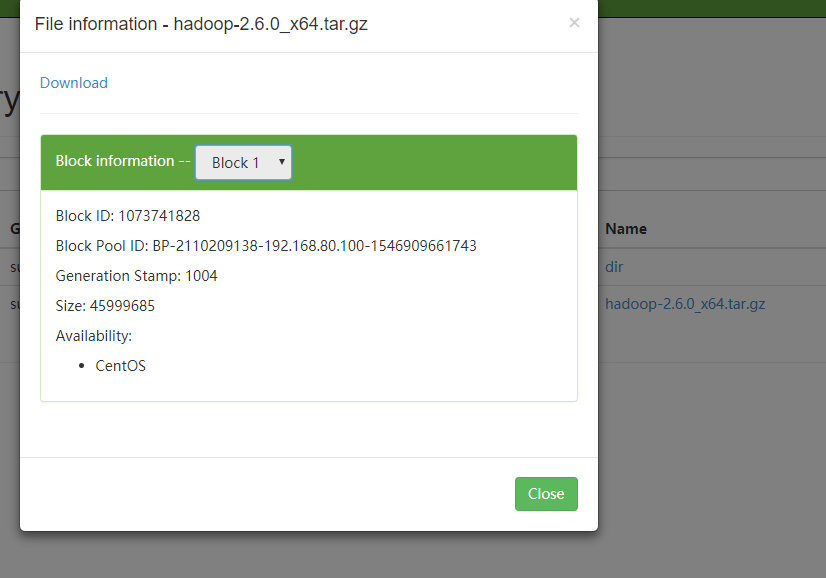
使用 tree /usr/hadoop-2.6.0/hadoop-root/命令可以看到name下的block元数据,例如当前是 blk_1073741827和blk_1073741828,对比下图,可知页面此处存储的是元数据。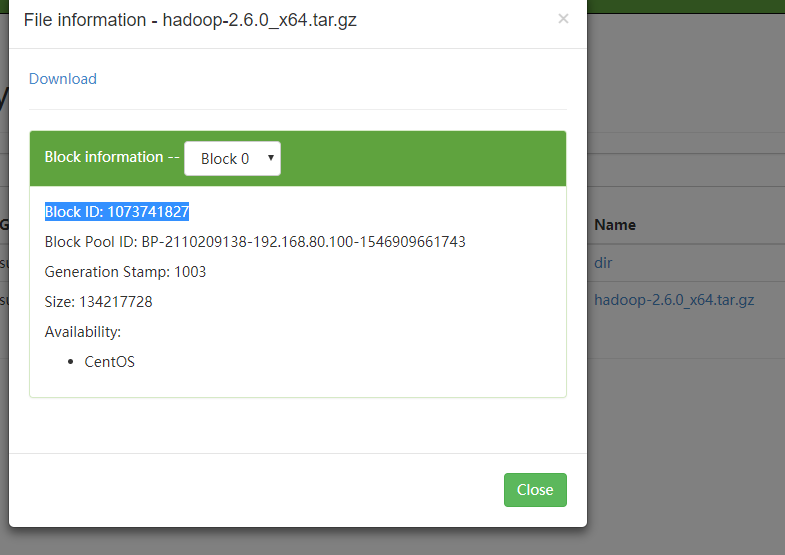 )
)
如果启动不起来,只能使用命令 rm -rf /usr/hadoop-2.6.0/hadoop-root,删掉此文件夹,重新格式化 hdfs namenode -format
如果想要获取某一个切片数据怎么办呢?使用 sz命令层层查找,如图所示: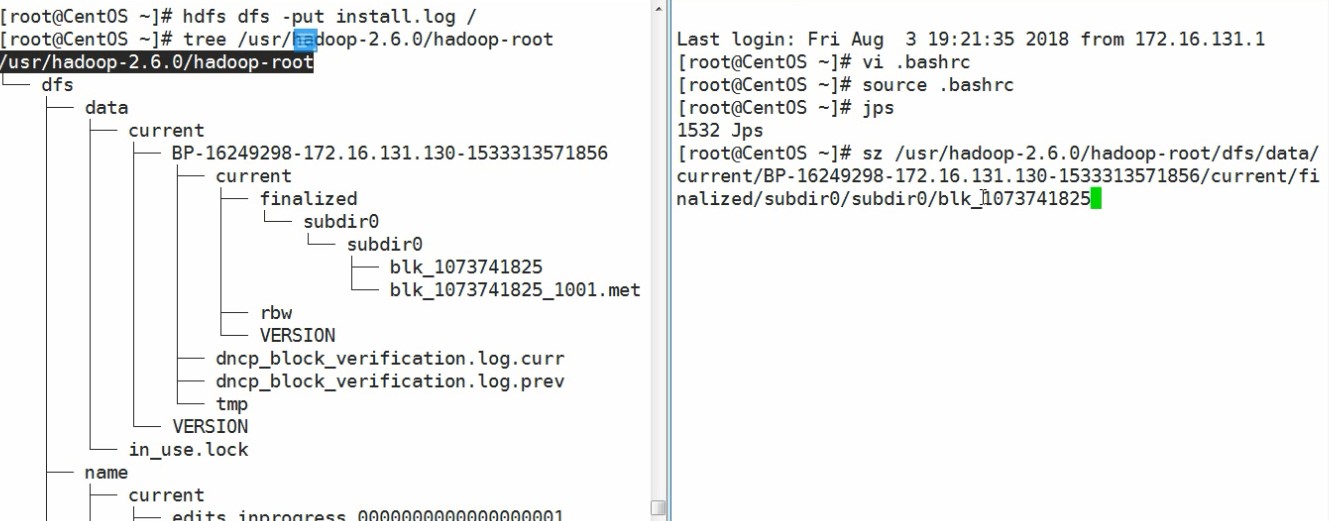
4 Hadoop架构图-三个服务节点详解
4.1 回顾文件系统 FastDFS-MongDB架构对比

木桶原理:以性能最短的作为整个集群的上限。
泳道原理:各司其职,彼此独立。
4.2 架构图
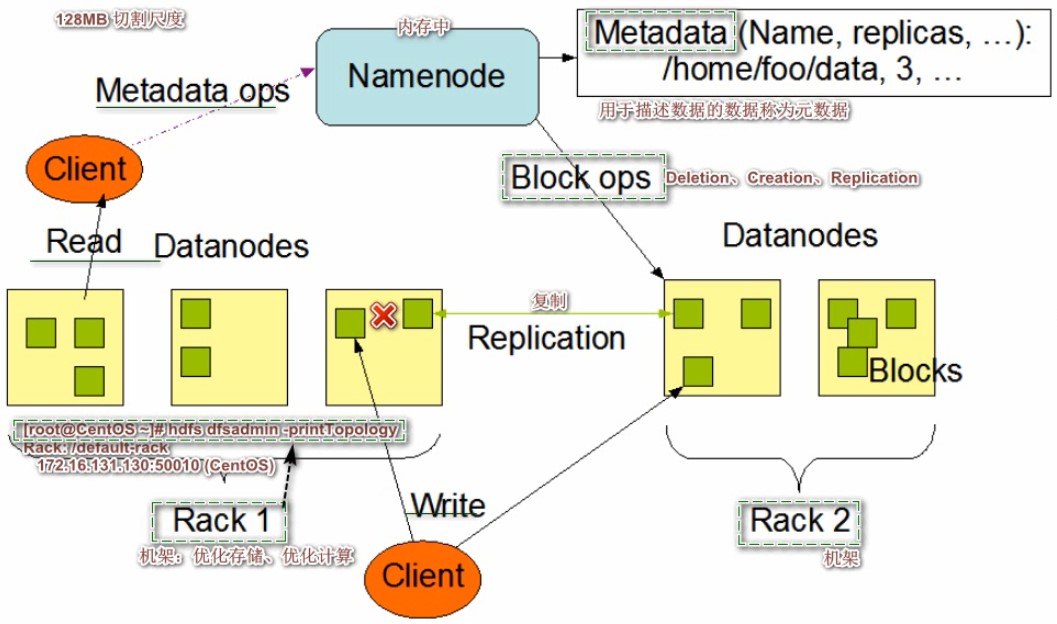
Block:HDFS底层将文件切割成Block,默认切割尺度128MB(切割尺度可配置,若不足128MB,按照实际大小存储成一个Block).
Namenode:管理集群元数据(文件名、数据块映射)、下发指令给Datenode
Datenode:数据节点,负责其存储数据块的读写请求,同时向Namenode汇报自己的状态信息
Rack:机架,优化存储,优化计算,可以通过命令hdfs dfsadmin -printTopology看到。
架构理解:
HDFS是一个主从架构,HDFS只维护了一个单一的Namenode节点,作为“老大”,这个主节点发号施令,并且存储元信息,监测Datenodes节点群的状态。HDFS有一系列的Datenode节点,作为Namenode的“小弟”, 小弟听从执行老大的各种指令,例如Creation,Deletion,Replication。
Namenode存储的是元数据,也可以理解为块的索引,”一个文件切割成块,就像把大象切割存到了冰箱里,未来如果想要大象在幻化拼接出来,就需要这种索引,即元数据.“,Namenode存的是元数据(索引),而不是数据。这些集群的元数据存储在Namenode节点的内存中,元数据即是文件路径、块到Datenode的映射关系等。
Hadoop是以块的形式存储数据的,块的大小是128MB,这是一种切割尺度,例如存出一个文件,如果小于128MB,则切不开,一个块即可存储,此时块的大小即是文件的实际大小,但是,对于Namenode而言,再小的一个文件也需要记录,需要记录这个块存储在了那个Datenode上面,即块到Datenode的映射关系。
举个例子:有一个文件,这个文件128MB,按照128MB的尺度去切,能切除一个块出来,Namenode就需要存储一个块的元信息即可;“Hadoop不适合存储小文件”。又比如:有1W个文件,加在一起是128MB,现在用同样的尺度去切,则每一个文件都是一个Block,会产生1W个Block,则Namenode上会存储1W个块的元信息(映射信息),Datenode存储1W个文件,这1W个文件有128MB,对于Datenode而言,1个128MB的文件和1W个文件总共128MB加在一起去存储,没有任何影响,都是存,但是问题来了,Namenode则得不偿失,Namenode的内存浪费很严重(整个HDFS中只有1个Namenode,其内存及其宝贵).Datenode不够可以线性扩展。
看上图可知:Datenode节点之间没有关系,只不过他们之间的Block是有复制的,Hadoop的机制是每一个块,在整个集群中最起码有一个备份,(这里与FastDFS和MongoDB的备份不同,他们是服务器与服务器之间的备份,FastDFS卷内是机器间整体的备份,MongoDB是shard之间整体的备份,而Hadoop做的是块的备份,更细粒度的备份,FastDFS与MongoDB做的是整体间的备份,就要求副本集成员之间机器的配置必须是一样的,而Hadoop则没有这种要求,不管是什么类型的机器,只要能存储数据,我都能利用起来,哪怕是存储一个Block,这样意味着Hadoop对成百上千个Datanode的硬件要求极低(能存就行)。这是Hadoop与传统的分布式文件系统最大的差异,传统的是做机器内部整体的备份,Hadoop没有这个要求,Datanode之间彼此独立,依据各自性能存储不同数量的块。如果有一个机器挂掉了,则有备份,这就是Hadopp做的故障转移,只要保证每个块,存在一定数量的副本即可
看上面图可知:客户端只要是操作元数据,走的是Namenode。 只要是对块的读写,走的是Datenode,同时,Namenode负责向Datenode发号指令。
Rack:机架,类似于书架(书多了没地方放,有了书架可以更好的管理书籍),机器多了,就需要机架,更方便的管理机器。
类似于上图,块的复制是机架间的复制,我们都有风险意识,不要把鸡蛋放到一个篮子里,防止鸡飞蛋打。将一批机器放在一个物理的机架上,这批机器共享一个交换机,首先,这样有助于运维,如果这个机架上的某个机器坏了,检修这个机架上的故障机器即可,对别的机架上的机器运转没有影响;其次,如果有电气故障(失火,机器都烧没了),别的机架上的机器不受影响。安全角度,块的副本集起码不是都在一个机架间的机器上,保证了容灾恢复块数据。效率角度:尽可能做机架内部机器间的通讯,尽量避免跨机架间通信,因为要多走起码一个路由器.
** HDFS存储特点:**
1)各个DataNode物理服务节点配置物理要求
2)不擅长存储小文件
NameNode和Secondary(辅助)NameNode
因为Namenode太忙了,就需要为Namenode配置一个秘书 SecondaryNamenode.类比现实生活:假如说公司的领导跑路了,小秘在也不能担当领导的职责,总经理跑路了,总经理助理也不能下发任意指令。没有人听总经理助理的命令,不具备对集群的管理能力,充其量就是端茶、倒水、整理文件。
NameNode主要是维系集群的元数据信息,主要是:fsimage、edits、edits_inprogress,而SecondayNameNode充其量只有fsimage、edits,缺少了edits_inprogress 类似于下图: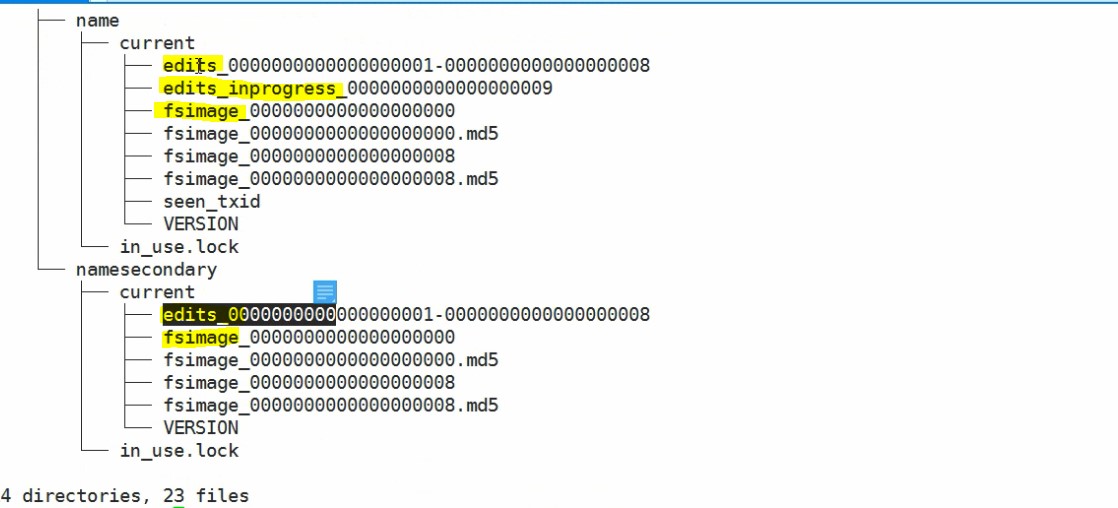
edits与fsimage:存储在NameNode服务器本地的两个文件,edits文件类似于日志文件,记录的是用户对NameNode元数据的修改;fsimage记录的是内存中的数据。edits和fsimage加起来才等价于老大Memory中的元数据。
Hadoop启动过程与上述两文件的关系:(Memory中元数据的由来)Hadoop在启动NameNode的时候,NameNode将fsimage和edits中的数据加载到内存中,fsimage是元数据的二进制信息,而edits是对元数据的修改操作信息;因此会利用edits中的日志对fsimage做一些执行操作,以达到内存中的数据恢复至上一次关机前的内存状态,当内存数据恢复之后,Namenode会刷新这两个文件,结果会导致edits被清空,而fsimage与内存保持高度一致。这些操作都发生在启动过程中,接下来,NameNode开始正常工作,即开始管理Datenode,因为Datenode会汇报自己的状态信息,此时Namenode会将这些收集到的状态信息与自己内存中信息作对比,一旦对比通过,则集群可以正常运行;在此期间,外界可以对HDFS做一些文件上传、修改的指令,此时会分为两个阶段:修改的指令直接发到NameNode的内存中,此时达到了对元数据的修改;同时,内存中的数据是不稳定的,易丢,Hadoop为了保证用户的每一次操作都是安全的,会将写的数据存入edits日志中,此刻,内存中的数据才是整个NameNode所有的数据(原始的+新发送的指令数据),edits+fsimage才等于内存中的数据,问题来了?如果Hadoop长时间工作在一个修改比较频繁的环境下,会导致edits会越来越大(Memory的内存消耗暂时不看),对比Redis的AOF持久化,AOF记录的是内存中所有的操作,而edits记录的只是从这一次启动到正常工作以后所有的修改操作的增量,会导致edits文件越来越大,如果edits有一种机制:可以flush就好了,即刷新fsimage到磁盘即可,只要刷新成功,edits中的数据既可以释放。但是。如果去刷新fsimage,会拉低NameNode的性能(NameNode的神经是紧绷的,因为他要管理整个集群的信息,有成千上百个人等着我去主持会议,汇报工作,发布指令,能让我在家里整理内务?),如果刷新成功,当关闭再次开启的时候,edtits不会有那么大了,Namenode启动就会十分快了,反之,Namenode没有时间去整理自己的edits,下一次启动还是走上述两个阶段,还是慢的要死。
一个公司的规模如果十分大了,就会想方设法提高效率,总裁级别的人一般都有小秘,小秘辅助的做一些日常工作,再怎么辅助,不能干预公司的决定,古代宦官、后宫不能干政是一个道理。让小秘去整理内务,没让小秘去管理自己的小弟,况且小弟也不会听小秘的。
SecondaryNameNode就相当于给NameNode请了一个小秘、保姆、助理.助理没有非常大的权利,但是待遇很好,总裁在那个办公室,小秘就在总裁办公室的旁边,有点像皇帝身边的太监。为什么待遇这么好呢?小秘给总经理做事,总经理的一些私事是不想让小弟知道的,小秘要保密的。
同理,NameNode负责去管理元数据和DateNode,但因为分身乏术,疏于对自己自身数据的持久化,丧失了对自己数据的管理能力,就需要有一个和NameNode内存、配置一样的机器,因为SecondaryNameNode会定时的去访问NameNode,问NameNode需不需要我来做整理啊?此处的“问”就是去查NameNode的edits文件有多大了,距离我上一次来整理你过了多长时间了,如果这两个条件满足了,即时间到了而且文件过大了,小秘就会拷贝-下载(不能拿走,即剪切,总经理要用怎么办呢?)edits和fsimage各一份到自己的本地磁盘中,在拷贝的过程中,总经理还在忙(比如还有人要修改文件),怎么办呢?
NameNode中的edits_inprogress登场了,即准备一个临时的文件,如果有人发来的写的指令,总裁就先将指令暂存到edits_inprogerss文件中,同时,小秘会在自己内存中模拟总裁以前的NameNode的过程,加载、合并,拿到一个更新的fsimage,比总裁的fsimage心新,因为在小秘那里,原有的fsimage已经和edits合并了,当然是最新的了;然后小秘会将自己最新的fsimage(已经整理好的文件)再次上传给总裁那里,为了不与总裁原有的fsimage命名冲突,给他叫做fsimage.chk文件,(chk:取自50070中页面里的save checkpoint 检查点)。上传、下载走的都是http协议
上传结束后,NameNode就不再需要edits和fsimage这两个文件了,会用edits_inprogress和fsimage.chk替换掉原有的edits和fsimage。
至此,NameNode工作起来就很流畅了,负责管理DateNode,管理元数据,没有时间整理内务,整理内务的工作由SecondaryNameNode来做,小秘至少的配置是内存与总裁的一致。小秘不在了,挂掉了,集群仍可以正常访问,NameNode会在第一次启动的时候整理自己的内存文件,会导致如果长时间运行,下次再启动的时候,启动时间过长。因此,NameNode挂了,休想通过SecondaryNaemNode来进行恢复,但有一种极端情况,在小秘下载合并之前,没有人对NameNode做出修改指令,此时是可以考虑从小秘那里来恢复的
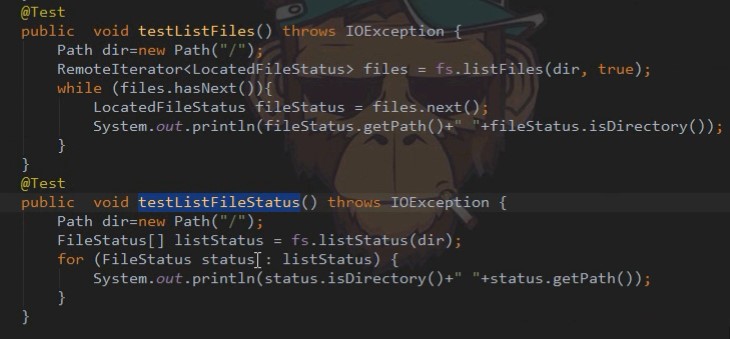
5 HDFS Shell & JAVA API
1 | 命令帮助: |
JAVA API 操作HDFS
搭建 window开发环境
a. 解压 hadoop安装包到 C:/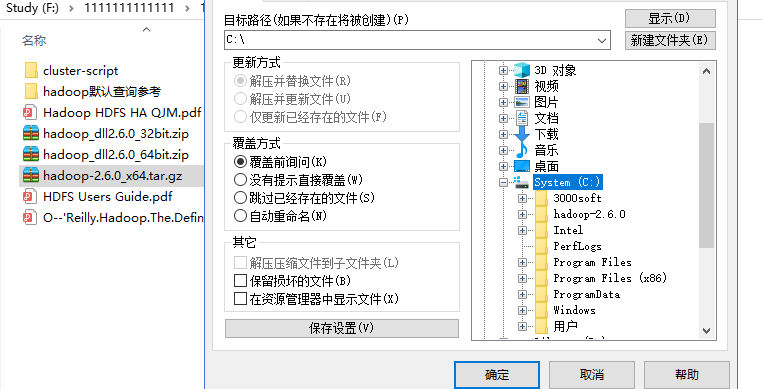
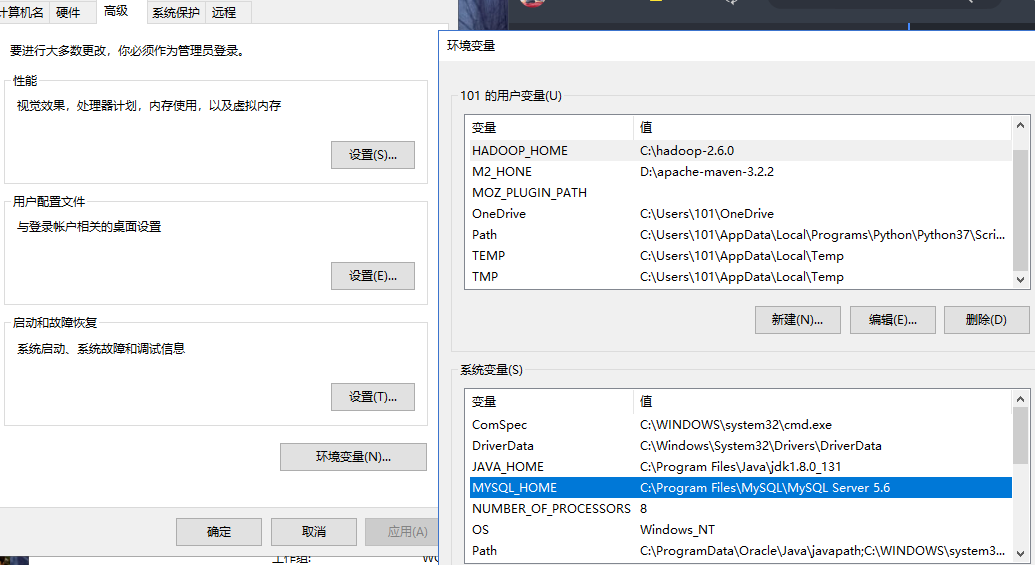
b. 配置 HADOOP_HOME 环境变量
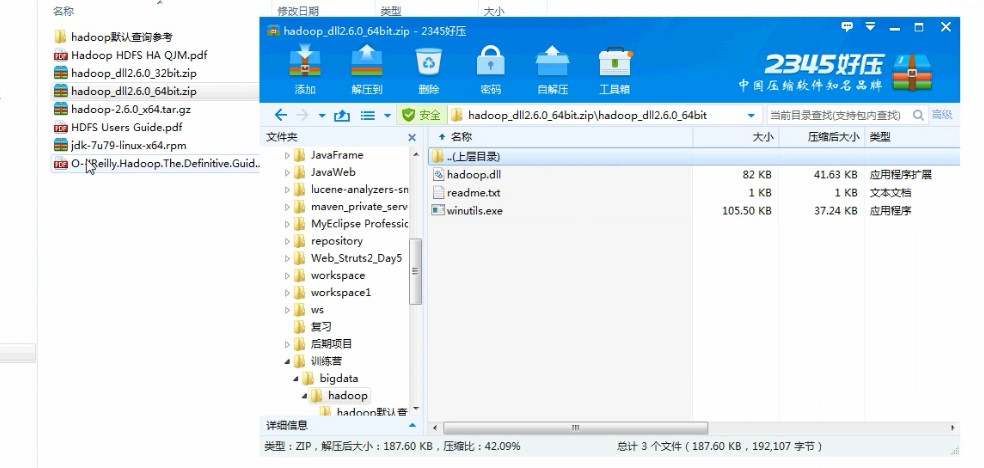
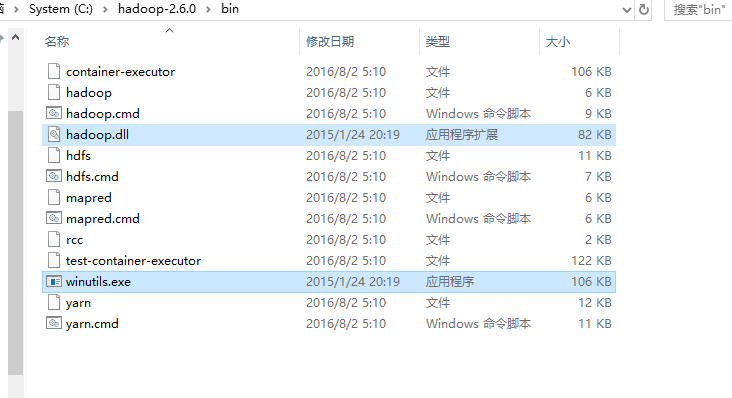
c. 拷贝 winutil.exe和hadoop.dll文件到hadoop安装bin目录下
d. 在Windows上配置CentOS上配置主机名和IP映射关系
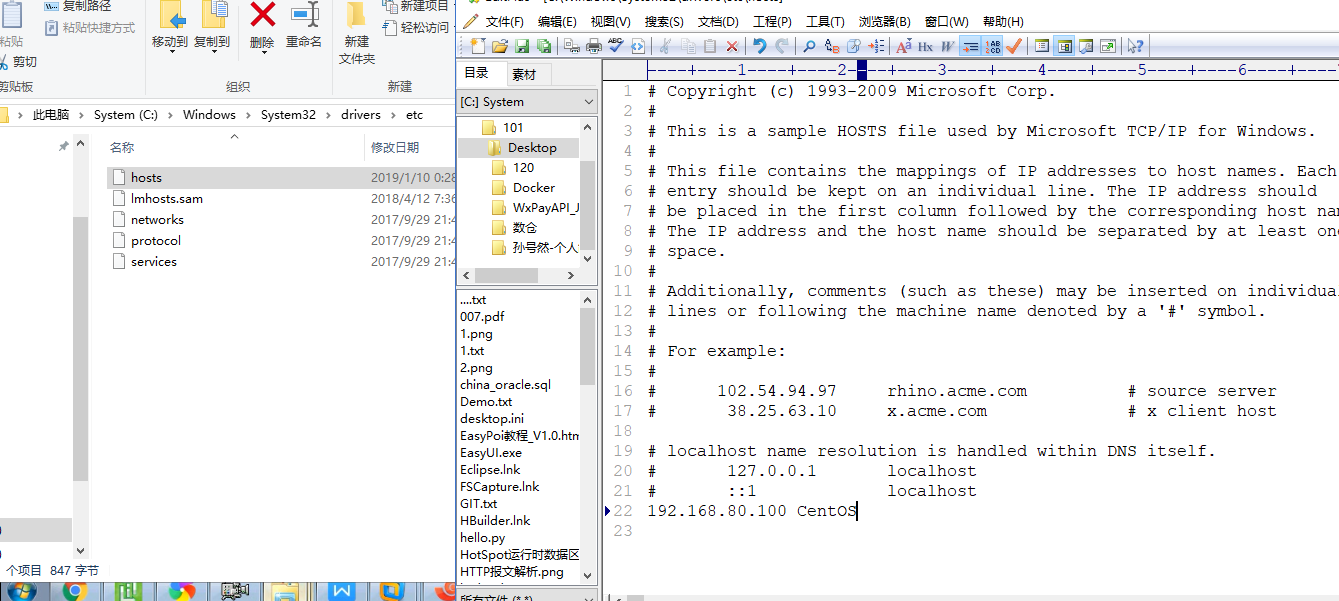
e. 重启IDE
导入Maven依赖1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs/artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>API代码
上传1: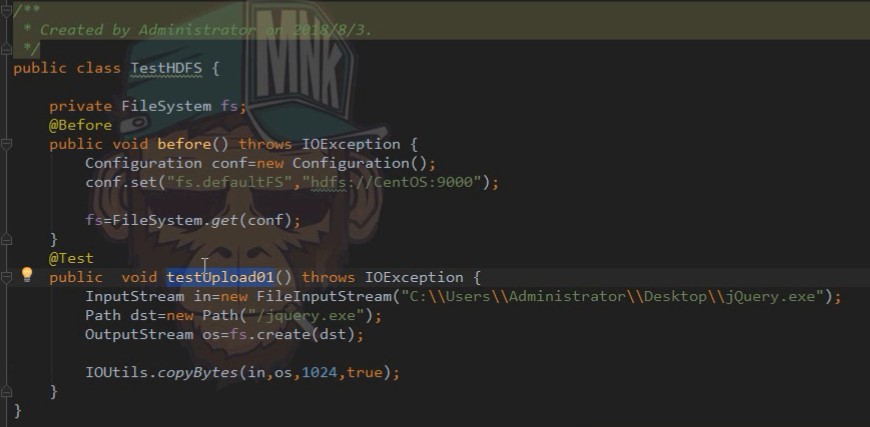
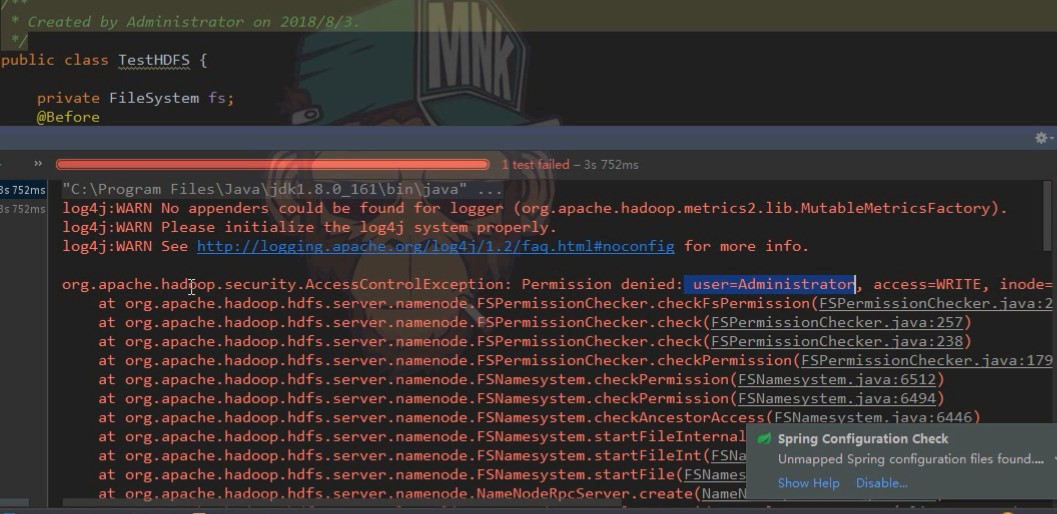
启动报错:因为当前是在Windows下操作Hadoop,用户是Administrator,不是root,所以不能操作,Linux上的Root用户才有的操作方法。可以从两处修改:
A:关闭Hadoop的系统权限,DFS permission配置 true改为false即可。
1
2
3
4
5 修改hdfs-site.xml
<property>
<name>dfspermission</name>
<value>true<value>
</property>
B:修改虚拟机的启动参数,告诉虚拟机是以root用户去连接。
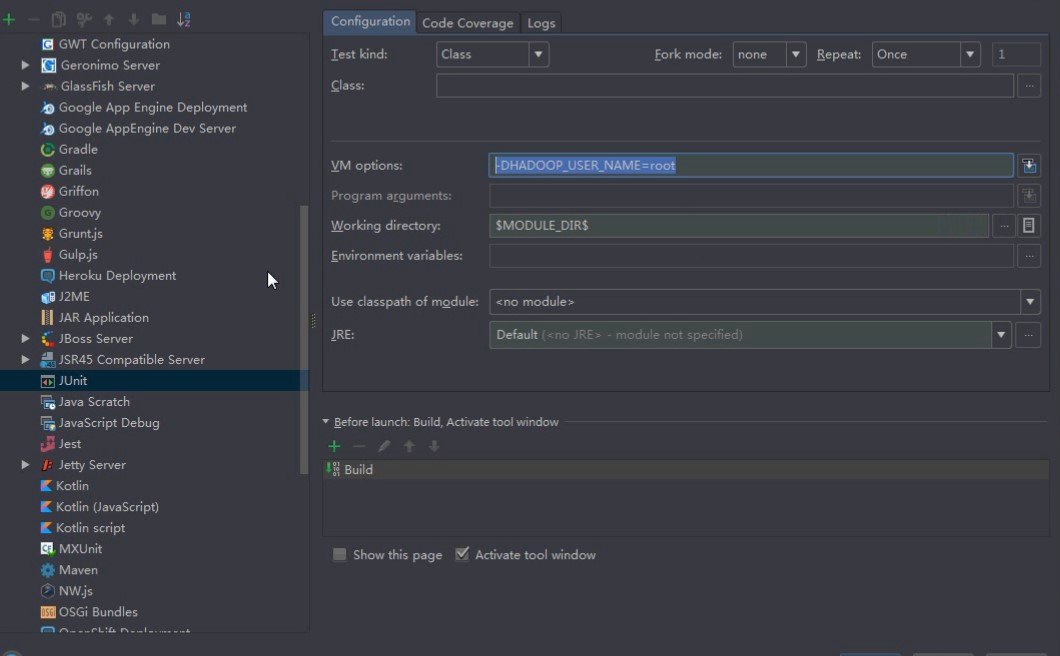
上传2:
结果: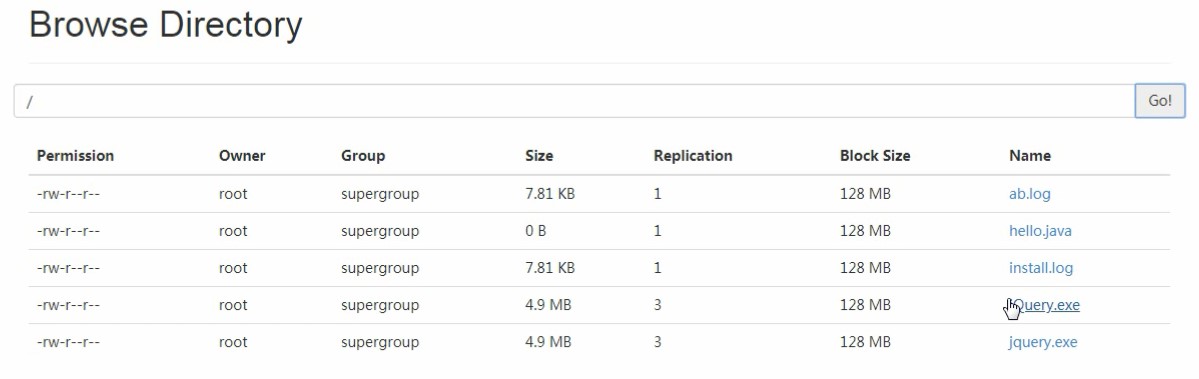
客户端可以用如下代码设置副本集个数
1 | @Before |
下载: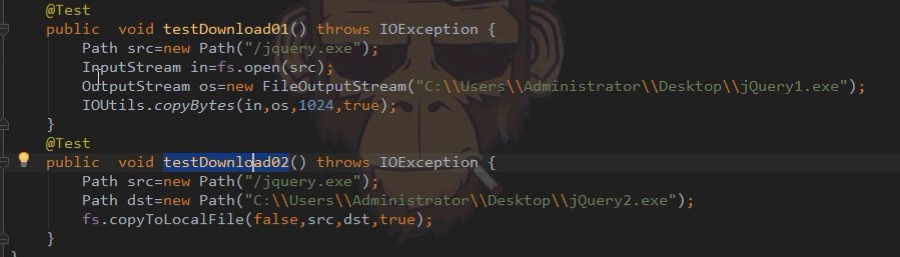
创建目录(“true”存在就递归删除,不存在就创建):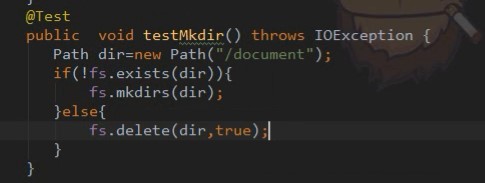
展示目录下的内容: