Author: haoransun
Wechat: SHR—97
Map-Reduce的过程与MongoDB如出一辙(如下图)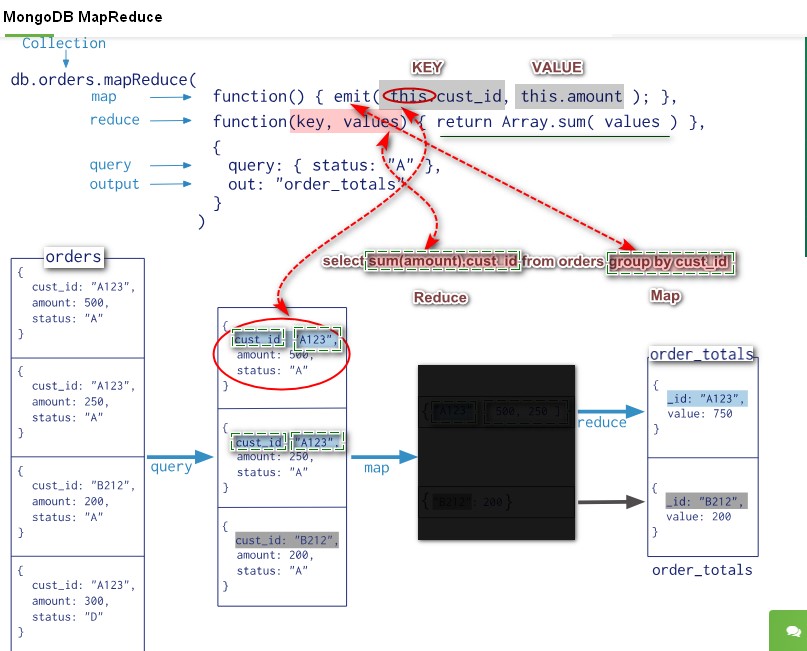
1 Map-Reduce简介
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。该运算充分利用Hadoop存储节点(DateNode)所在物理主机的CPU、内存、网络以及少许磁盘完成分布式计算。通过在DateNode所在的主机上启动NodeManager进程,该进程负责启动计算任务。
MapReduce计算框架将分布式计算分为两个阶段:
Map阶段:在任务计算初期,计算框架会提前计算好任务切片(对数据做区域划分),然后根据切片数目启动MapTask,对切片所映射的数据做局部的分析/计算,将计算的临时结果存储到对应物理主机的磁盘(MapTask的溢写)。
Reduce阶段:在Map阶段的所有操作完成计算任务后,计算框架会选择若干机器(手动指定)执行ReduceTask,完成对Map阶段计算数据的汇总(shuffle洗牌)。
2 Map-Reduce计算过程
修路的故事:我们要修一条从西藏到上海的高速公路,由西北到东南;首先呢,这个工程量是十分巨大的,我们不能让一个工程队去修这条路,(从理论上来讲,是可行的,从祖父到重孙….)但是周期太长,中间会不会发生变故,还不好说。所以一个大的工程出现后,要有一个合理的时间规划,假如期限是1年内搞定,那怎么办呢?此时就需要路段区间同时施工,但区间同时施工又会产生一个问题,这个事儿该由谁来主持呢?史某一个人来主持吗?不可能,修路这种东西,尤其是跨地区修路,是非常难的。每个省、市。区都有自己的特殊的东西,如:钉子户的解决,拆迁的成本等。修路是一个国家的大事,不是某个人可以单独解决的。这就由每个地区的国土资源部来审核、主持。但是跨地区呢?由中央国土资源管理中心来审核、主持各个地区的国土资源部。
提议:修一条从西藏到上海的路,带动周边经济。中央的国土资源部拿到这个请求后,会开会商讨,觉得此事儿可行,靠谱。中央会下发文件,给该工程起代号。中央可以审批,但是有一个前提:就是在我审批之后,未来这个路的具体修法不可能让国家领导人来操心吧,所以:中央审批完成后,会由第一人做三件事,1. 具体的施工区间(这条路会经过哪些省份、地区)路段(方便各国土资源部进行各自的土地划量,区间同时作业)。2. 当地具体该怎么修这条路呢,是修水泥路呢?还是沥漆呢?路面有多宽,多厚?需不需要修建 绿化带呢?即修路的标准要定好。3.路段的对接标准:各个工程队都不傻,都会只负责各自的划分区域,那些交接的区域该怎么对接呢?
在整理好上述三件事后,要将文件进行公示,即所有人都能看到 4.将文件详情上传给中央后,中央说:修吧。5. 中央会让河南省的国土资源部推荐一个人,即工程总监,全权负责西藏到上海的修路事宜。 当地的(河南省)的国土资源部会选举、指派一个工程总监作为负责人
这个负责人可能一晚上都睡不好觉了,因为这是一个大项目,搞砸了咋笨呢?此人心里会思考:这么大的工程量我该怎样去检测、去实施呢?6.修路的管理规范定制好,每隔多长时间,各个工程队要向我汇报各个区间的施工进度,有什么难题向我汇报,我要知道工程的施工进度(假如说在施工期间,某个施工队因为技术达不到而修不了某一区间段内的路,要及时通报我,我会从其他地方抽调专业的施工队来帮助你修路);
这个工程总监想了一夜终于想好后,紧接着该第七步路。7. 工程总监从网上下载初期的公示文件:因为要看路段从哪到哪,经过哪些区域,需要哪一个地区的国土资源部配合我的工作等详细信息;8. 一切就绪后,负责人就开始向中央申请资金了,9. 工程总监将资金、工程区间段的图纸、施工信息等下发给拨给各个地区的国土资源部,交给他们去具体的修路。10. 各地区国土资源部拿到拨款后,会在当地进行招标,(带动当地经济,肥水不流外人田) 钱已经给到了工程队。工程队拿到钱后,并不是立马开始修路的,他要去根据公示文件去判断区间范围和修路标准,11. 各地区中标工程队开始施工修路。
在施工期间要注意的事项:各个地区开始同时施工,施工的第一阶段,所有的工程队只修自己所负责的区间段,按照既定的标准去修就OK了;各个施工队汇报工程进度时,汇报对象不再是当地政府,而是工程总监,可能出现的状况:当地政府指定了某一个施工队,但是没有考虑施工的具体难易,本地的工程队儿干不了,向工程总监反馈,工程总监考虑从其他地区调工程队来(不到万不得已,不会调,因为有人力、物力、财力流失浪费);
当所有的工程队把自己所下发的区间段修完后,工程总监就知道了,此时路段该对接了,第一阶段的Map,因为有公示文件订好了,照着干就行,工程总监干预不了,而第二阶段的Reduce阶段则由工程总监说了算。(不可能让某一个区域的个人去做对接,效率太慢,也不可能让所有的工程队都参与对接,浪费资源)由工程总监去指定若干个工程队去进行工程的对接(原来1000,现在改为10个或不等个)。
2.1 举例
1. Client JVM(提议人),向ResourceManager(中央国土资源中心)进行Job(提议)。
2. ResourceManager会下发一个文件get new application(授权)。
3. Client JVM(客户端) 要copy job resource(公示自己的文件),工程所用到的资源:路段信息、施工标准、运行上下文等。
4. Client JVM(提议人),向ResourceManager(中央)进行submit applications(施工文档的提交)。
5a. ResourceManager(中央)会start container(下发命令),给地方的NodeManager(国土资源中心)。
5b. NodeManager(当地政府)除了找工程队外,还要选举、启动MRAppMaster(工程总监),MRAppMaster只有一个。所有的地方政府都要听他的。
6. MRAppMaster(工程总监) Initialize Job(初始化Job),即相当于先将任务的监测进程启动好。
7. MRAppMaster(工程总监) retrieve input splits(查看输入切片,相当于区域路段信息,)。
8. MRAppMaster(工程总监) allocate resources(拨款,请求资源:Cpu、内存等) from ResourceManager。
9a. MRAppMaster(工程总监)会start container(发号指令)给NodeManager(地方政府),去跟地方国土资源中心说:中央给你拨了那么多款,你去把路给我修好了。
9b. NodeManagerr(地方政府)会launch(启动)一个本地的YarnChild(工程队),此处的YarnChild是一个统称,它既可以是MapTask(区域施工),也可以工程对接(Reduce Task).
10. YarnChild(工程队)会retrieve job resources(查询确认自己的到底要修那条路,施工。对接标准如何,取决于启动的是区间作业工程队,还是工程对接工程队)。
11. YarnChild(工程队)run 任务,第一阶段一定是MapTask,这个任务量取决于有多少个切片(splits),第二阶段由MRAppMaster去找寻指定的NodeManager启动ReduceTask。
路修完后:工程总监MRAppMaster、YarnChild工程队的头衔头没有了,当地政府还存在,所以整个Yarn框架的核心进程就两个:ResourceManager和NodeManager,MRAppMaster和YarnChild属于计算过程中的进程,用完就回收。
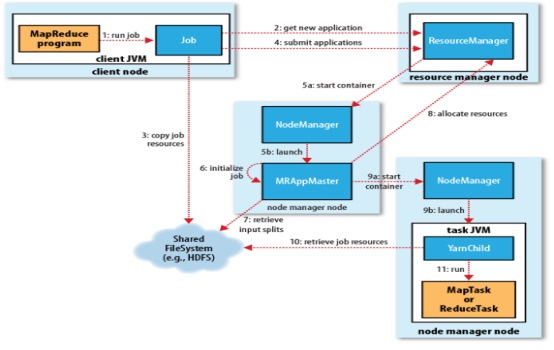
ResourceManager:资源管理中心,管理NodeManager、分配任务资源
NodeManager:启动MRAppMaster、YarnChild
以上两个是Yarn框架的常驻内存进程。
MRAppMaster:监测任务运行(一个任务,只有一个)
YarnChild:MapTask或者ReduceTask的总称,具体计算进程。
YarnChild进程数目:
MapTask:切片控制(数据逻辑映射区间)
ReduceTask:程序手动指定。
3 搭建YARN计算环境
1 | [root@CentOS ~]# cp /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml |
访问:http://centos:8088/cluster 即可看到MapReduce的界面化管理。
参考文档
4 掌握Map-Reduce编程模型
未完待续