转载自:
https://www.liaoxuefeng.com/wiki/1016959663602400
前言
中级篇_下涉及内容如下:
多任务的实现有3种方式:
- 多进程模式;
- 多线程模式;
- 多进程+多线程模式。
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
多进程和多线程的程序涉及到同步、数据共享的问题,编写起来更复杂。
1. 多进程
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
1 | import os |
运行结果如下:
1 | Process (876) start... |
由于Windows没有fork调用,上面的代码在Windows上无法运行。而Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的,推荐大家用Mac学Python!
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
1. multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?
由于Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
1 | from multiprocessing import Process |
执行结果如下:
1 | Parent process 928. |
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
2. Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
1 | from multiprocessing import Pool |
执行结果如下:
1 | Parent process 669. |
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
1 | p = Pool(5) |
就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
3. 子进程
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在Python代码中运行命令nslookup www.python.org,这和命令行直接运行的效果是一样的:
1 | import subprocess |
运行结果:
1 | $ nslookup www.python.org |
如果子进程还需要输入,则可以通过communicate()方法输入:
1 | import subprocess |
上面的代码相当于在命令行执行命令nslookup,然后手动输入:
1 | set q=mx |
运行结果如下:
1 | $ nslookup |
4. 进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
1 | from multiprocessing import Process, Queue |
运行结果如下:
1 | Process to write: 50563 |
在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所以,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
5. 小结
在Unix/Linux下,可以使用fork()调用实现多进程。
要实现跨平台的多进程,可以使用multiprocessing模块。
进程间通信是通过Queue、Pipes等实现的。
2. 多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
1 | import time, threading |
执行结果如下:
1 | thread MainThread is running... |
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
1. Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
来看看多个线程同时操作一个变量怎么把内容给改乱了:
1 | import time, threading |
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
原因是因为高级语言的一条语句在CPU执行时是若干条语句,即使一个简单的计算:
1 | balance = balance + n |
也分两步:
- 计算
balance + n,存入临时变量中; - 将临时变量的值赋给
balance。
也就是可以看成:
1 | x = balance + n |
由于x是局部变量,两个线程各自都有自己的x,当代码正常执行时:
1 | 初始值 balance = 0 |
但是t1和t2是交替运行的,如果操作系统以下面的顺序执行t1、t2:
1 | 初始值 balance = 0 |
究其原因,是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改balance的时候,别的线程一定不能改。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:
1 | balance = 0 |
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
2. 多核CPU
如果你不幸拥有一个多核CPU,你肯定在想,多核应该可以同时执行多个线程。
如果写一个死循环的话,会出现什么情况呢?
打开Mac OS X的Activity Monitor,或者Windows的Task Manager,都可以监控某个进程的CPU使用率。
我们可以监控到一个死循环线程会100%占用一个CPU。
如果有两个死循环线程,在多核CPU中,可以监控到会占用200%的CPU,也就是占用两个CPU核心。
要想把N核CPU的核心全部跑满,就必须启动N个死循环线程。
试试用Python写个死循环:
1 | import threading, multiprocessing |
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
3. 小结
多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦。
3. ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦:
1 | def process_student(name): |
每个函数一层一层调用都这么传参数那还得了?用全局变量?也不行,因为每个线程处理不同的Student对象,不能共享。
如果用一个全局dict存放所有的Student对象,然后以thread自身作为key获得线程对应的Student对象如何?
1 | global_dict = {} |
这种方式理论上是可行的,它最大的优点是消除了std对象在每层函数中的传递问题,但是,每个函数获取std的代码有点丑。
有没有更简单的方式?
ThreadLocal应运而生,不用查找dict,ThreadLocal帮你自动做这件事:
1 | import threading |
执行结果:
1 | Hello, Alice (in Thread-A) |
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
小结
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
4. 进程 VS 线程
我们介绍了多进程和多线程,这是实现多任务最常用的两种方式。现在,我们来讨论一下这两种方式的优缺点。
首先,要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker。
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
如果用多线程实现Master-Worker,主线程就是Master,其他线程就是Worker。
多进程模式最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低)著名的Apache最早就是采用多进程模式。
多进程模式的缺点是创建进程的代价大,在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。在Windows上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程。
在Windows下,多线程的效率比多进程要高,所以微软的IIS服务器默认采用多线程模式。由于多线程存在稳定性的问题,IIS的稳定性就不如Apache。为了缓解这个问题,IIS和Apache现在又有多进程+多线程的混合模式,真是把问题越搞越复杂。
1. 线程切换
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?
我们打个比方,假设你不幸正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这5科的作业,每项作业耗时1小时。
如果你先花1小时做语文作业,做完了,再花1小时做数学作业,这样,依次全部做完,一共花5小时,这种方式称为单任务模型,或者批处理任务模型。
假设你打算切换到多任务模型,可以先做1分钟语文,再切换到数学作业,做1分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核CPU执行多任务是一样的了,以幼儿园小朋友的眼光来看,你就正在同时写5科作业。
但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(这叫保存现场),然后,打开数学课本、找出圆规直尺(这叫准备新环境),才能开始做数学作业。操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。
所以,多任务一旦多到一个限度,就会消耗掉系统所有的资源,结果效率急剧下降,所有任务都做不好。
2. 计算密集型 VS IO密集型
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
3. 异步IO
考虑到CPU和IO之间巨大的速度差异,一个任务在执行的过程中大部分时间都在等待IO操作,单进程单线程模型会导致别的任务无法并行执行,因此,我们才需要多进程模型或者多线程模型来支持多任务并发执行。
现代操作系统对IO操作已经做了巨大的改进,最大的特点就是支持异步IO。如果充分利用操作系统提供的异步IO支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型,Nginx就是支持异步IO的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。由于系统总的进程数量十分有限,因此操作系统调度非常高效。用异步IO编程模型来实现多任务是一个主要的趋势。
对应到Python语言,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。
5. 分布式进程
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
举个例子:如果我们已经有一个通过Queue通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
原有的Queue可以继续使用,但是,通过managers模块把Queue通过网络暴露出去,就可以让其他机器的进程访问Queue了。
我们先看服务进程,服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
1 | # task_master.py |
请注意,当我们在一台机器上写多进程程序时,创建的Queue可以直接拿来用,但是,在分布式多进程环境下,添加任务到Queue不可以直接对原始的task_queue进行操作,那样就绕过了QueueManager的封装,必须通过manager.get_task_queue()获得的Queue接口添加。
然后,在另一台机器上启动任务进程(本机上启动也可以):
1 | # task_worker.py |
任务进程要通过网络连接到服务进程,所以要指定服务进程的IP。
现在,可以试试分布式进程的工作效果了。先启动task_master.py服务进程:
1 | $ python3 task_master.py |
task_master.py进程发送完任务后,开始等待result队列的结果。现在启动task_worker.py进程:
1 | $ python3 task_worker.py |
task_worker.py进程结束,在task_master.py进程中会继续打印出结果:
1 | Result: 3411 * 3411 = 11634921 |
这个简单的Master/Worker模型有什么用?其实这就是一个简单但真正的分布式计算,把代码稍加改造,启动多个worker,就可以把任务分布到几台甚至几十台机器上,比如把计算n*n的代码换成发送邮件,就实现了邮件队列的异步发送。
Queue对象存储在哪?注意到task_worker.py中根本没有创建Queue的代码,所以,Queue对象存储在task_master.py进程中:
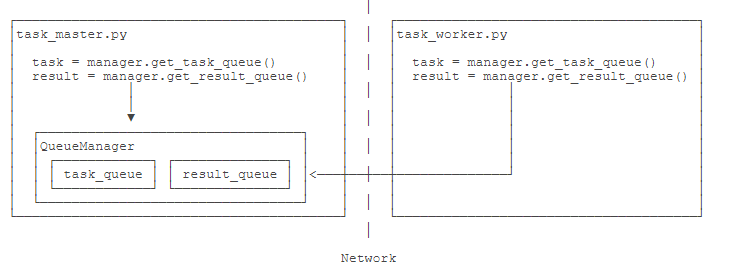
而Queue之所以能通过网络访问,就是通过QueueManager实现的。由于QueueManager管理的不止一个Queue,所以,要给每个Queue的网络调用接口起个名字,比如get_task_queue。
authkey有什么用?这是为了保证两台机器正常通信,不被其他机器恶意干扰。如果task_worker.py的authkey和task_master.py的authkey不一致,肯定连接不上。
小结
Python的分布式进程接口简单,封装良好,适合需要把繁重任务分布到多台机器的环境下。
注意Queue的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由Worker进程再去共享的磁盘上读取文件。
2. 正则表达式
1. 基础
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
所以我们判断一个字符串是否是合法的Email的方法是:
创建一个匹配Email的正则表达式;
用该正则表达式去匹配用户的输入来判断是否合法。
因为正则表达式也是用字符串表示的,所以,我们要首先了解如何用字符来描述字符。
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,所以:
'00\d'可以匹配'007',但无法匹配'00A';'\d\d\d'可以匹配'010';'\w\w\d'可以匹配'py3';
.可以匹配任意字符,所以:
'py.'可以匹配'pyc'、'pyo'、'py!'等等。
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
来看一个复杂的例子:\d{3}\s+\d{3,8}。
我们来从左到右解读一下:
\d{3}表示匹配3个数字,例如'010';\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等;\d{3,8}表示3-8个数字,例如'1234567'。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配'010-12345'这样的号码呢?由于'-'是特殊字符,在正则表达式中,要用'\'转义,所以,上面的正则是\d{3}\-\d{3,8}。
但是,仍然无法匹配'010 - 12345',因为带有空格。所以我们需要更复杂的匹配方式。
2. 进阶
要做更精确地匹配,可以用[]表示范围,比如:
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线;[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等;[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。
3. re模块
有了准备知识,我们就可以在Python中使用正则表达式了。Python提供re模块,包含所有正则表达式的功能。由于Python的字符串本身也用\转义,所以要特别注意:
1 | s = 'ABC\\-001' # Python的字符串 |
因此我们强烈建议使用Python的r前缀,就不用考虑转义的问题了:
1 | s = r'ABC\-001' # Python的字符串 |
先看看如何判断正则表达式是否匹配:
1 | >>> import re |
match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。常见的判断方法就是:
1 | test = '用户输入的字符串' |
4. 切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
1 | >>> 'a b c'.split(' ') |
嗯,无法识别连续的空格,用正则表达式试试:
1 | >>> re.split(r'\s+', 'a b c') |
再加入;试试:
1 | >>> re.split(r'[\s\,\;]+', 'a,b;; c d') |
如果用户输入了一组标签,下次记得用正则表达式来把不规范的输入转化成正确的数组。
5. 分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
1 | >>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345') |
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
提取子串非常有用。来看一个更凶残的例子:
1 | >>> t = '19:05:30' |
这个正则表达式可以直接识别合法的时间。但是有些时候,用正则表达式也无法做到完全验证,比如识别日期:
1 | '^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$' |
对于'2-30','4-31'这样的非法日期,用正则还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
6. 贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
1 | >>> re.match(r'^(\d+)(0*)$', '102300').groups() |
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
1 | >>> re.match(r'^(\d+?)(0*)$', '102300').groups() |
7. 编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
1 | >>> import re |
编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
练习
请尝试写一个验证Email地址的正则表达式。版本一应该可以验证出类似的Email:
版本二可以提取出带名字的Email地址:
tom@voyager.org => Tom Paris - bob@example.com => bob
1 | # 第一题: |
3. 常用内建模块
1. datetime
datetime是Python处理日期和时间的标准库。
1. 获取当前日期和时间
先看看如何获取当前日期和时间:
1 | >>> from datetime import datetime |
注意到datetime是模块,datetime模块还包含一个datetime类,通过from datetime import datetime导入的才是datetime这个类。
如果仅导入import datetime,则必须引用全名datetime.datetime。
datetime.now()返回当前日期和时间,其类型是datetime。
2. 获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
1 | >>> from datetime import datetime |
3. datetime转换为timestamp
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
你可以认为:
1 | timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00 |
对应的北京时间是:
1 | timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00 |
可见timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)。
把一个datetime类型转换为timestamp只需要简单调用timestamp()方法:
1 | >>> from datetime import datetime |
注意Python的timestamp是一个浮点数。如果有小数位,小数位表示毫秒数。
某些编程语言(如Java和JavaScript)的timestamp使用整数表示毫秒数,这种情况下只需要把timestamp除以1000就得到Python的浮点表示方法。
4. timestamp转换为datetime
要把timestamp转换为datetime,使用datetime提供的fromtimestamp()方法:
1 | >>> from datetime import datetime |
注意到timestamp是一个浮点数,它没有时区的概念,而datetime是有时区的。上述转换是在timestamp和本地时间做转换。
本地时间是指当前操作系统设定的时区。例如北京时区是东8区,则本地时间:
1 | 2015-04-19 12:20:00 |
实际上就是UTC+8:00时区的时间:
1 | 2015-04-19 12:20:00 UTC+8:00 |
而此刻的格林威治标准时间与北京时间差了8小时,也就是UTC+0:00时区的时间应该是:
1 | 2015-04-19 04:20:00 UTC+0:00 |
timestamp也可以直接被转换到UTC标准时区的时间:
1 | >>> from datetime import datetime |
5. str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
1 | >>> from datetime import datetime |
字符串'%Y-%m-%d %H:%M:%S'规定了日期和时间部分的格式。详细的说明请参考Python文档。
注意转换后的datetime是没有时区信息的。
6. datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:
1 | >>> from datetime import datetime |
7. datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
1 | >>> from datetime import datetime, timedelta |
可见,使用timedelta你可以很容易地算出前几天和后几天的时刻。
8. 本地时间转换为UTC时间
本地时间是指系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。
一个datetime类型有一个时区属性tzinfo,但是默认为None,所以无法区分这个datetime到底是哪个时区,除非强行给datetime设置一个时区:
1 | >>> from datetime import datetime, timedelta, timezone |
如果系统时区恰好是UTC+8:00,那么上述代码就是正确的,否则,不能强制设置为UTC+8:00时区。
9. 时区转换
我们可以先通过utcnow()拿到当前的UTC时间,再转换为任意时区的时间:
1 | # 拿到UTC时间,并强制设置时区为UTC+0:00: |
时区转换的关键在于,拿到一个datetime时,要获知其正确的时区,然后强制设置时区,作为基准时间。
时区转换的关键在于,拿到一个datetime时,要获知其正确的时区,然后强制设置时区,作为基准时间。
利用带时区的datetime,通过astimezone()方法,可以转换到任意时区。
注:不是必须从UTC+0:00时区转换到其他时区,任何带时区的datetime都可以正确转换,例如上述bj_dt到tokyo_dt的转换。
10. 小结
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
如果要存储datetime,最佳方法是将其转换为timestamp再存储,因为timestamp的值与时区完全无关。
练习
假设你获取了用户输入的日期和时间如2015-1-21 9:01:30,以及一个时区信息如UTC+5:00,均是str,请编写一个函数将其转换为timestamp:
1 | def to_timestamp(dt_str, tz_str): |
2. collections
collections是Python内建的一个集合模块,提供了许多有用的集合类。
1. namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
1 | >>> p = (1, 2) |
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
1 | >>> from collections import namedtuple |
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
1 | >>> isinstance(p, Point) |
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
1 | # namedtuple('名称', [属性list]): |
2. deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
1 | >>> from collections import deque |
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
3. defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
1 | >>> from collections import defaultdict |
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
4. OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
1 | >>> from collections import OrderedDict |
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
1 | >>> od = OrderedDict() |
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
1 | from collections import OrderedDict |
5. ChainMap
ChainMap可以把一组dict串起来并组成一个逻辑上的dict。ChainMap本身也是一个dict,但是查找的时候,会按照顺序在内部的dict依次查找。
什么时候使用ChainMap最合适?举个例子:应用程序往往都需要传入参数,参数可以通过命令行传入,可以通过环境变量传入,还可以有默认参数。我们可以用ChainMap实现参数的优先级查找,即先查命令行参数,如果没有传入,再查环境变量,如果没有,就使用默认参数。
下面的代码演示了如何查找user和color这两个参数:
1 | from collections import ChainMap |
没有任何参数时,打印出默认参数:
1 | $ python3 use_chainmap.py |
当传入命令行参数时,优先使用命令行参数:
1 | $ python3 use_chainmap.py -u bob |
同时传入命令行参数和环境变量,命令行参数的优先级较高:
1 | $ user=admin color=green python3 use_chainmap.py -u bob |
6. Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
1 | >>> from collections import Counter |
Counter实际上也是dict的一个子类,上面的结果可以看出每个字符出现的次数。
3. base64
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
1 | ['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/'] |
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
Python内置的base64可以直接进行base64的编解码:
1 | >>> import base64 |
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种”url safe”的base64编码,其实就是把字符+和/分别变成-和_:
1 | >>> base64.b64encode(b'i\xb7\x1d\xfb\xef\xff') |
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
1 | # 标准Base64: |
去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
练习
写一个能处理去掉=的base64解码函数:
1 | def safe_base64_decode(s): |
4. struct
准确地讲,Python没有专门处理字节的数据类型。但由于b'str'可以表示字节,所以,字节数组=二进制str。而在C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
在Python中,比方说要把一个32位无符号整数变成字节,也就是4个长度的bytes,你得配合位运算符这么写:
1 | >>> n = 10240099 |
非常麻烦。如果换成浮点数就无能为力了。
好在Python提供了一个struct模块来解决bytes和其他二进制数据类型的转换。
struct的pack函数把任意数据类型变成bytes:
1 | >>> import struct |
pack的第一个参数是处理指令,'>I'的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。
unpack把bytes变成相应的数据类型:
1 | >>> struct.unpack('>IH', b'\xf0\xf0\xf0\xf0\x80\x80') |
根据>IH的说明,后面的bytes依次变为I:4字节无符号整数和H:2字节无符号整数。
所以,尽管Python不适合编写底层操作字节流的代码,但在对性能要求不高的地方,利用struct就方便多了。
struct模块定义的数据类型可以参考Python官方文档:
https://docs.python.org/3/library/struct.html#format-characters
Windows的位图文件(.bmp)是一种非常简单的文件格式,我们来用struct分析一下。
首先找一个bmp文件,没有的话用“画图”画一个。
读入前30个字节来分析:
1 | >>> s = b'\x42\x4d\x38\x8c\x0a\x00\x00\x00\x00\x00\x36\x00\x00\x00\x28\x00\x00\x00\x80\x02\x00\x00\x68\x01\x00\x00\x01\x00\x18\x00' |
BMP格式采用小端方式存储数据,文件头的结构按顺序如下:
两个字节:'BM'表示Windows位图,'BA'表示OS/2位图; 一个4字节整数:表示位图大小; 一个4字节整数:保留位,始终为0; 一个4字节整数:实际图像的偏移量; 一个4字节整数:Header的字节数; 一个4字节整数:图像宽度; 一个4字节整数:图像高度; 一个2字节整数:始终为1; 一个2字节整数:颜色数。
所以,组合起来用unpack读取:
1 | >>> struct.unpack('<ccIIIIIIHH', s) |
结果显示,b'B'、b'M'说明是Windows位图,位图大小为640x360,颜色数为24。
5. hashlib
1. 摘要算法简介
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了你的文章,并发表为'how to use python hashlib - by Bob',你可以一下子指出Bob篡改了你的文章,因为根据'how to use python hashlib - by Bob'计算出的摘要不同于原始文章的摘要。
可见,摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
1 | import hashlib |
计算结果如下:
1 | d26a53750bc40b38b65a520292f69306 |
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
1 | import hashlib |
试试改动一个字母,看看计算的结果是否完全不同。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
1 | import hashlib |
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。
有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞,比如Bob试图根据你的摘要反推出一篇文章'how to learn hashlib in python - by Bob',并且这篇文章的摘要恰好和你的文章完全一致,这种情况也并非不可能出现,但是非常非常困难。
2. 摘要算法应用
摘要算法能应用到什么地方?举个常用例子:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:

如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。
正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:

当用户登录时,首先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明口令输入正确,如果不一致,口令肯定错误。
3. 练习
练习1
根据用户输入的口令,计算出存储在数据库中的MD5口令:
1 | def calc_md5(password): |
存储MD5的好处是即使运维人员能访问数据库,也无法获知用户的明文口令。
设计一个验证用户登录的函数,根据用户输入的口令是否正确,返回True或False:
1 |
|
采用MD5存储口令是否就一定安全呢?也不一定。假设你是一个黑客,已经拿到了存储MD5口令的数据库,如何通过MD5反推用户的明文口令呢?暴力破解费事费力,真正的黑客不会这么干。
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
1 | 'e10adc3949ba59abbe56e057f20f883e': '123456' |
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
1 | def calc_md5(password): |
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
练习2
根据用户输入的登录名和口令模拟用户注册,计算更安全的MD5:
1 | db = {} |
然后,根据修改后的MD5算法实现用户登录的验证:
1 | # -*- coding: utf-8 -*- |
4. 小结
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
6. hmac
通过哈希算法,我们可以验证一段数据是否有效,方法就是对比该数据的哈希值,例如,判断用户口令是否正确,我们用保存在数据库中的password_md5对比计算md5(password)的结果,如果一致,用户输入的口令就是正确的。
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
如果salt是我们自己随机生成的,通常我们计算MD5时采用md5(message + salt)。但实际上,把salt看做一个“口令”,加salt的哈希就是:计算一段message的哈希时,根据不通口令计算出不同的哈希。要验证哈希值,必须同时提供正确的口令。
这实际上就是Hmac算法:Keyed-Hashing for Message Authentication。它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。
和我们自定义的加salt算法不同,Hmac算法针对所有哈希算法都通用,无论是MD5还是SHA-1。采用Hmac替代我们自己的salt算法,可以使程序算法更标准化,也更安全。
Python自带的hmac模块实现了标准的Hmac算法。我们来看看如何使用hmac实现带key的哈希。
我们首先需要准备待计算的原始消息message,随机key,哈希算法,这里采用MD5,使用hmac的代码如下:
1 | >>> import hmac |
可见使用hmac和普通hash算法非常类似。hmac输出的长度和原始哈希算法的长度一致。需要注意传入的key和message都是bytes类型,str类型需要首先编码为bytes。
小结
Python内置的hmac模块实现了标准的Hmac算法,它利用一个key对message计算“杂凑”后的hash,使用hmac算法比标准hash算法更安全,因为针对相同的message,不同的key会产生不同的hash。
练习
将上一节的salt改为标准的hmac算法,验证用户口令:
1 | # -*- coding: utf-8 -*- |
7. itertools
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
首先,我们看看itertools提供的几个“无限”迭代器:
1 | >>> import itertools |
因为count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出。
cycle()会把传入的一个序列无限重复下去:
1 | >>> import itertools |
同样停不下来。
repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
1 | >>> ns = itertools.repeat('A', 3) |
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
1 | >>> natuals = itertools.count(1) |
itertools提供的几个迭代器操作函数更加有用:
1. chain()
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
1 | >>> for c in itertools.chain('ABC', 'XYZ'): |
2. groupby()
1 | >>> for key, group in itertools.groupby('AAABBBCCAAA'): |
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。如果我们要忽略大小写分组,就可以让元素'A'和'a'都返回相同的key:
1 | >>> for key, group in itertools.groupby('AaaBBbcCAAa', lambda c: c.upper()): |
3. 小结
itertools模块提供的全部是处理迭代功能的函数,它们的返回值不是list,而是Iterator,只有用for循环迭代的时候才真正计算。
练习
计算圆周率可以根据公式:
利用Python提供的itertools模块,我们来计算这个序列的前N项和:
1 |
|
8. contextlib
在Python中,读写文件这样的资源要特别注意,必须在使用完毕后正确关闭它们。正确关闭文件资源的一个方法是使用try...finally:
1 | try: |
写try...finally非常繁琐。Python的with语句允许我们非常方便地使用资源,而不必担心资源没有关闭,所以上面的代码可以简化为:
1 | with open('/path/to/file', 'r') as f: |
并不是只有open()函数返回的fp对象才能使用with语句。实际上,任何对象,只要正确实现了上下文管理,就可以用于with语句。
实现上下文管理是通过__enter__和__exit__这两个方法实现的。例如,下面的class实现了这两个方法:
1 | class Query(object): |
这样我们就可以把自己写的资源对象用于with语句:
1 | with Query('Bob') as q: |
1. @contextmanager
编写__enter__和__exit__仍然很繁琐,因此Python的标准库contextlib提供了更简单的写法,上面的代码可以改写如下:
1 | from contextlib import contextmanager |
@contextmanager这个decorator接受一个generator,用yield语句把with ... as var把变量输出出去,然后,with语句就可以正常地工作了:
1 | with create_query('Bob') as q: |
很多时候,我们希望在某段代码执行前后自动执行特定代码,也可以用@contextmanager实现。例如:
1 | @contextmanager |
上述代码执行结果为:
1 | <h1> |
代码的执行顺序是:
with语句首先执行yield之前的语句,因此打印出<h1>;yield调用会执行with语句内部的所有语句,因此打印出hello和world;- 最后执行
yield之后的语句,打印出</h1>。
因此,@contextmanager让我们通过编写generator来简化上下文管理。
2. @closing
如果一个对象没有实现上下文,我们就不能把它用于with语句。这个时候,可以用closing()来把该对象变为上下文对象。例如,用with语句使用urlopen():
1 | from contextlib import closing |
closing也是一个经过@contextmanager装饰的generator,这个generator编写起来其实非常简单:
1 | @contextmanager |
它的作用就是把任意对象变为上下文对象,并支持with语句。
@contextlib还有一些其他decorator,便于我们编写更简洁的代码。
9. urllib
urllib提供了一系列用于操作URL的功能。
1. Get
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的一个URLhttps://api.douban.com/v2/book/2129650进行抓取,并返回响应:
1 | from urllib import request |
可以看到HTTP响应的头和JSON数据:
1 | Status: 200 OK |
如果我们要想模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加HTTP头,我们就可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:
1 | from urllib import request |
这样豆瓣会返回适合iPhone的移动版网页:
1 | ... |
2. Post
如果要以POST发送一个请求,只需要把参数data以bytes形式传入。
我们模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
1 | from urllib import request, parse |
如果登录成功,我们获得的响应如下:
1 | Status: 200 OK |
如果登录失败,我们获得的响应如下:
1 | ... |
3. Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,我们需要利用ProxyHandler来处理,示例代码如下:
1 | proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'}) |
4. 小结
urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。
练习
利用urllib读取JSON,然后将JSON解析为Python对象:
1 | from urllib import request |
10. XML
XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。
DOM VS SAX
操作XML有两种方法:DOM和SAX。DOM会把整个XML读入内存,解析为树,因此占用内存大,解析慢,优点是可以任意遍历树的节点。SAX是流模式,边读边解析,占用内存小,解析快,缺点是我们需要自己处理事件。
正常情况下,优先考虑SAX,因为DOM实在太占内存。
在Python中使用SAX解析XML非常简洁,通常我们关心的事件是start_element,end_element和char_data,准备好这3个函数,然后就可以解析xml了。
举个例子,当SAX解析器读到一个节点时:
1 | <a href="/">python</a> |
会产生3个事件:
start_element事件,在读取
<a href="/">时;char_data事件,在读取
python时;end_element事件,在读取
</a>时。
用代码实验一下:
1 | from xml.parsers.expat import ParserCreate |
需要注意的是读取一大段字符串时,CharacterDataHandler可能被多次调用,所以需要自己保存起来,在EndElementHandler里面再合并。
除了解析XML外,如何生成XML呢?99%的情况下需要生成的XML结构都是非常简单的,因此,最简单也是最有效的生成XML的方法是拼接字符串:
1 | L = [] |
如果要生成复杂的XML呢?建议你不要用XML,改成JSON。
解析XML时,注意找出自己感兴趣的节点,响应事件时,把节点数据保存起来。解析完毕后,就可以处理数据。
练习
请利用SAX编写程序解析Yahoo的XML格式的天气预报,获取天气预报:
要查询某个城市代码,可以在weather.yahoo.com搜索城市,浏览器地址栏的URL就包含城市代码。
1 | '''练习: |
11. HTML Parser
如果我们要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来,第二步就是解析该HTML页面,看看里面的内容到底是新闻、图片还是视频。
假设第一步已经完成了,第二步应该如何解析HTML呢?
HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。
好在Python提供了HTMLParser来非常方便地解析HTML,只需简单几行代码:
1 | from html.parser import HTMLParser |
feed()方法可以多次调用,也就是不一定一次把整个HTML字符串都塞进去,可以一部分一部分塞进去。
特殊字符有两种,一种是英文表示的 ,一种是数字表示的Ӓ,这两种字符都可以通过Parser解析出来。
利用HTMLParser,可以把网页中的文本、图像等解析出来。
4. 常用第三方模块
Python有大量的第三方模块。
基本上,所有的第三方模块都会在PyPI - the Python Package Index上注册,只要找到对应的模块名字,即可用pip安装。
此外,在安装第三方模块一节中,我们强烈推荐安装Anaconda,安装后,数十个常用的第三方模块就已经就绪,不用pip手动安装。
1. Pillow
PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。
由于PIL仅支持到Python 2.7,加上年久失修,于是一群志愿者在PIL的基础上创建了兼容的版本,名字叫Pillow,支持最新Python 3.x,又加入了许多新特性,因此,我们可以直接安装使用Pillow。
1. 安装Pillow
1 | $ pip install pillow |
如果遇到Permission denied安装失败,请加上sudo重试。
2. 操作图像
来看看最常见的图像缩放操作,只需三四行代码:
1 | from PIL import Image |
其他功能如切片、旋转、滤镜、输出文字、调色板等一应俱全。
比如,模糊效果也只需几行代码:
1 | from PIL import Image, ImageFilter |
效果如下:
PIL的ImageDraw提供了一系列绘图方法,让我们可以直接绘图。比如要生成字母验证码图片:
1 | from PIL import Image, ImageDraw, ImageFont, ImageFilter |
我们用随机颜色填充背景,再画上文字,最后对图像进行模糊,得到验证码图片如下:

如果运行的时候报错:
1 | IOError: cannot open resource |
这是因为PIL无法定位到字体文件的位置,可以根据操作系统提供绝对路径,比如:
1 | '/Library/Fonts/Arial.ttf' |
要详细了解PIL的强大功能,请请参考Pillow官方文档:
https://pillow.readthedocs.org/
3.小结
PIL提供了操作图像的强大功能,可以通过简单的代码完成复杂的图像处理。
2. requests
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,而且,缺少很多实用的高级功能。
更好的方案是使用requests。它是一个Python第三方库,处理URL资源特别方便。
1. 安装requests
如果安装了Anaconda,requests就已经可用了。否则,需要在命令行下通过pip安装:
1 | $ pip install requests |
如果遇到Permission denied安装失败,请加上sudo重试。
2. 使用requests
要通过GET访问一个页面,只需要几行代码:
1 | >>> import requests |
对于带参数的URL,传入一个dict作为params参数:
1 | >>> r = requests.get('https://www.douban.com/search', params={'q': 'python', 'cat': '1001'}) |
requests自动检测编码,可以使用encoding属性查看:
1 | >>> r.encoding |
无论响应是文本还是二进制内容,我们都可以用content属性获得bytes对象:
1 | >>> r.content |
requests的方便之处还在于,对于特定类型的响应,例如JSON,可以直接获取:
1 | >>> r = requests.get('https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20%3D%202151330&format=json') |
需要传入HTTP Header时,我们传入一个dict作为headers参数:
1 | >>> r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'}) |
要发送POST请求,只需要把get()方法变成post(),然后传入data参数作为POST请求的数据:
1 | >>> r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'}) |
requests默认使用application/x-www-form-urlencoded对POST数据编码。如果要传递JSON数据,可以直接传入json参数:
1 | params = {'key': 'value'} |
类似的,上传文件需要更复杂的编码格式,但是requests把它简化成files参数:
1 | >>> upload_files = {'file': open('report.xls', 'rb')} |
在读取文件时,注意务必使用'rb'即二进制模式读取,这样获取的bytes长度才是文件的长度。
把post()方法替换为put(),delete()等,就可以以PUT或DELETE方式请求资源。
除了能轻松获取响应内容外,requests对获取HTTP响应的其他信息也非常简单。例如,获取响应头:
1 | >>> r.headers |
requests对Cookie做了特殊处理,使得我们不必解析Cookie就可以轻松获取指定的Cookie:
1 | >>> r.cookies['ts'] |
要在请求中传入Cookie,只需准备一个dict传入cookies参数:
1 | >>> cs = {'token': '12345', 'status': 'working'} |
最后,要指定超时,传入以秒为单位的timeout参数:
1 | >>> r = requests.get(url, timeout=2.5) # 2.5秒后超时 |
3. chardet
字符串编码一直是令人非常头疼的问题,尤其是我们在处理一些不规范的第三方网页的时候。虽然Python提供了Unicode表示的str和bytes两种数据类型,并且可以通过encode()和decode()方法转换,但是,在不知道编码的情况下,对bytes做decode()不好做。
对于未知编码的bytes,要把它转换成str,需要先“猜测”编码。猜测的方式是先收集各种编码的特征字符,根据特征字符判断,就能有很大概率“猜对”。
当然,我们肯定不能从头自己写这个检测编码的功能,这样做费时费力。chardet这个第三方库正好就派上了用场。用它来检测编码,简单易用。
1. 安装chardet
如果安装了Anaconda,chardet就已经可用了。否则,需要在命令行下通过pip安装:
1 | $ pip install chardet |
如果遇到Permission denied安装失败,请加上sudo重试。
2. 使用chardet
当我们拿到一个bytes时,就可以对其检测编码。用chardet检测编码,只需要一行代码:
1 | >>> chardet.detect(b'Hello, world!') |
检测出的编码是ascii,注意到还有个confidence字段,表示检测的概率是1.0(即100%)。
我们来试试检测GBK编码的中文:
1 | >>> data = '离离原上草,一岁一枯荣'.encode('gbk') |
检测的编码是GB2312,注意到GBK是GB2312的超集,两者是同一种编码,检测正确的概率是74%,language字段指出的语言是'Chinese'。
对UTF-8编码进行检测:
1 | >>> data = '离离原上草,一岁一枯荣'.encode('utf-8') |
我们再试试对日文进行检测:
1 | >>> data = '最新の主要ニュース'.encode('euc-jp') |
可见,用chardet检测编码,使用简单。获取到编码后,再转换为str,就可以方便后续处理。
chardet支持检测的编码列表请参考官方文档Supported encodings。
4. psutil
用Python来编写脚本简化日常的运维工作是Python的一个重要用途。在Linux下,有许多系统命令可以让我们时刻监控系统运行的状态,如ps,top,free等等。要获取这些系统信息,Python可以通过subprocess模块调用并获取结果。但这样做显得很麻烦,尤其是要写很多解析代码。
在Python中获取系统信息的另一个好办法是使用psutil这个第三方模块。顾名思义,psutil = process and system utilities,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用,支持Linux/UNIX/OSX/Windows等,是系统管理员和运维小伙伴不可或缺的必备模块。
1. 安装psutil
如果安装了Anaconda,psutil就已经可用了。否则,需要在命令行下通过pip安装:
1 | $ pip install psutil |
如果遇到Permission denied安装失败,请加上sudo重试。
2. 获取CPU信息
我们先来获取CPU的信息:
1 | >>> import psutil |
统计CPU的用户/系统/空闲时间:
1 | >>> psutil.cpu_times() |
再实现类似top命令的CPU使用率,每秒刷新一次,累计10次:
1 | >>> for x in range(10): |
3. 获取内存信息
使用psutil获取物理内存和交换内存信息,分别使用:
1 | >>> psutil.virtual_memory() |
返回的是字节为单位的整数,可以看到,总内存大小是8589934592 = 8 GB,已用7201386496 = 6.7 GB,使用了66.6%。
而交换区大小是1073741824 = 1 GB。
4. 获取磁盘信息
可以通过psutil获取磁盘分区、磁盘使用率和磁盘IO信息:
1 | >>> psutil.disk_partitions() # 磁盘分区信息 |
可以看到,磁盘'/'的总容量是998982549504 = 930 GB,使用了39.1%。文件格式是HFS,opts中包含rw表示可读写,journaled表示支持日志。
5. 获取网络信息
psutil可以获取网络接口和网络连接信息:
1 | >>> psutil.net_io_counters() # 获取网络读写字节/包的个数 |
要获取当前网络连接信息,使用net_connections():
1 | >>> psutil.net_connections() |
你可能会得到一个AccessDenied错误,原因是psutil获取信息也是要走系统接口,而获取网络连接信息需要root权限,这种情况下,可以退出Python交互环境,用sudo重新启动:
1 | $ sudo python3 |
6. 获取进程信息
通过psutil可以获取到所有进程的详细信息:
1 | >>> psutil.pids() # 所有进程ID |
和获取网络连接类似,获取一个root用户的进程需要root权限,启动Python交互环境或者.py文件时,需要sudo权限。
psutil还提供了一个test()函数,可以模拟出ps命令的效果:
1 | $ sudo python3 |
7. 小结
psutil使得Python程序获取系统信息变得易如反掌。
psutil还可以获取用户信息、Windows服务等很多有用的系统信息,具体请参考psutil的官网:https://github.com/giampaolo/psutil
5. virtualenv
在开发Python应用程序的时候,系统安装的Python3只有一个版本:3.4。所有第三方的包都会被pip安装到Python3的site-packages目录下。
如果我们要同时开发多个应用程序,那这些应用程序都会共用一个Python,就是安装在系统的Python 3。如果应用A需要jinja 2.7,而应用B需要jinja 2.6怎么办?
这种情况下,每个应用可能需要各自拥有一套“独立”的Python运行环境。virtualenv就是用来为一个应用创建一套“隔离”的Python运行环境。
首先,我们用pip安装virtualenv:
1 | $ pip3 install virtualenv |
然后,假定我们要开发一个新的项目,需要一套独立的Python运行环境,可以这么做:
第一步,创建目录:
1 | Mac:~ michael$ mkdir myproject |
第二步,创建一个独立的Python运行环境,命名为venv:
1 | Mac:myproject michael$ virtualenv --no-site-packages venv |
命令virtualenv就可以创建一个独立的Python运行环境,我们还加上了参数--no-site-packages,这样,已经安装到系统Python环境中的所有第三方包都不会复制过来,这样,我们就得到了一个不带任何第三方包的“干净”的Python运行环境。
新建的Python环境被放到当前目录下的venv目录。有了venv这个Python环境,可以用source进入该环境:
1 | Mac:myproject michael$ source venv/bin/activate |
注意到命令提示符变了,有个(venv)前缀,表示当前环境是一个名为venv的Python环境。
下面正常安装各种第三方包,并运行python命令:
1 | (venv)Mac:myproject michael$ pip install jinja2 |
在venv环境下,用pip安装的包都被安装到venv这个环境下,系统Python环境不受任何影响。也就是说,venv环境是专门针对myproject这个应用创建的。
退出当前的venv环境,使用deactivate命令:
1 | (venv)Mac:myproject michael$ deactivate |
此时就回到了正常的环境,现在pip或python均是在系统Python环境下执行。
完全可以针对每个应用创建独立的Python运行环境,这样就可以对每个应用的Python环境进行隔离。
virtualenv是如何创建“独立”的Python运行环境的呢?原理很简单,就是把系统Python复制一份到virtualenv的环境,用命令source venv/bin/activate进入一个virtualenv环境时,virtualenv会修改相关环境变量,让命令python和pip均指向当前的virtualenv环境。
virtualenv为应用提供了隔离的Python运行环境,解决了不同应用间多版本的冲突问题。
6. 图形界面
Python支持多种图形界面的第三方库,包括:
- Tk
- wxWidgets
- Qt
- GTK
等等。
但是Python自带的库是支持Tk的Tkinter,使用Tkinter,无需安装任何包,就可以直接使用。本章简单介绍如何使用Tkinter进行GUI编程。
1. Tkinter
我们来梳理一下概念:
我们编写的Python代码会调用内置的Tkinter,Tkinter封装了访问Tk的接口;
Tk是一个图形库,支持多个操作系统,使用Tcl语言开发;
Tk会调用操作系统提供的本地GUI接口,完成最终的GUI。
所以,我们的代码只需要调用Tkinter提供的接口就可以了。
2. 第一个GUI程序
使用Tkinter十分简单,我们来编写一个GUI版本的“Hello, world!”。
第一步是导入Tkinter包的所有内容:
1 | from tkinter import * |
第二步是从Frame派生一个Application类,这是所有Widget的父容器:
1 | class Application(Frame): |
在GUI中,每个Button、Label、输入框等,都是一个Widget。Frame则是可以容纳其他Widget的Widget,所有的Widget组合起来就是一棵树。
pack()方法把Widget加入到父容器中,并实现布局。pack()是最简单的布局,grid()可以实现更复杂的布局。
在createWidgets()方法中,我们创建一个Label和一个Button,当Button被点击时,触发self.quit()使程序退出。
第三步,实例化Application,并启动消息循环:
1 | app = Application() |
GUI程序的主线程负责监听来自操作系统的消息,并依次处理每一条消息。因此,如果消息处理非常耗时,就需要在新线程中处理。
运行这个GUI程序,可以看到下面的窗口:

点击“Quit”按钮或者窗口的“x”结束程序。
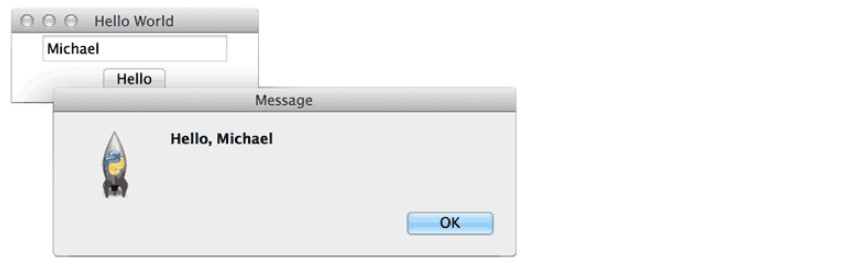
3. 输入文本
我们再对这个GUI程序改进一下,加入一个文本框,让用户可以输入文本,然后点按钮后,弹出消息对话框。
1 | from tkinter import * |
当用户点击按钮时,触发hello(),通过self.nameInput.get()获得用户输入的文本后,使用tkMessageBox.showinfo()可以弹出消息对话框。
程序运行结果如下:
1. 海龟绘图
在1966年,Seymour Papert和Wally Feurzig发明了一种专门给儿童学习编程的语言——LOGO语言,它的特色就是通过编程指挥一个小海龟(turtle)在屏幕上绘图。
海龟绘图(Turtle Graphics)后来被移植到各种高级语言中,Python内置了turtle库,基本上100%复制了原始的Turtle Graphics的所有功能。
我们来看一个指挥小海龟绘制一个长方形的简单代码:
1 | # 导入turtle包的所有内容: |
在命令行运行上述代码,会自动弹出一个绘图窗口,然后绘制出一个长方形:
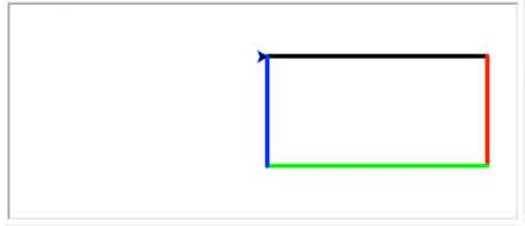
从程序代码可以看出,海龟绘图就是指挥海龟前进、转向,海龟移动的轨迹就是绘制的线条。要绘制一个长方形,只需要让海龟前进、右转90度,反复4次。
调用width()函数可以设置笔刷宽度,调用pencolor()函数可以设置颜色。更多操作请参考turtle库的说明。
绘图完成后,记得调用done()函数,让窗口进入消息循环,等待被关闭。否则,由于Python进程会立刻结束,将导致窗口被立刻关闭。
turtle包本身只是一个绘图库,但是配合Python代码,就可以绘制各种复杂的图形。例如,通过循环绘制5个五角星:
1 | from turtle import * |
程序执行效果如下:

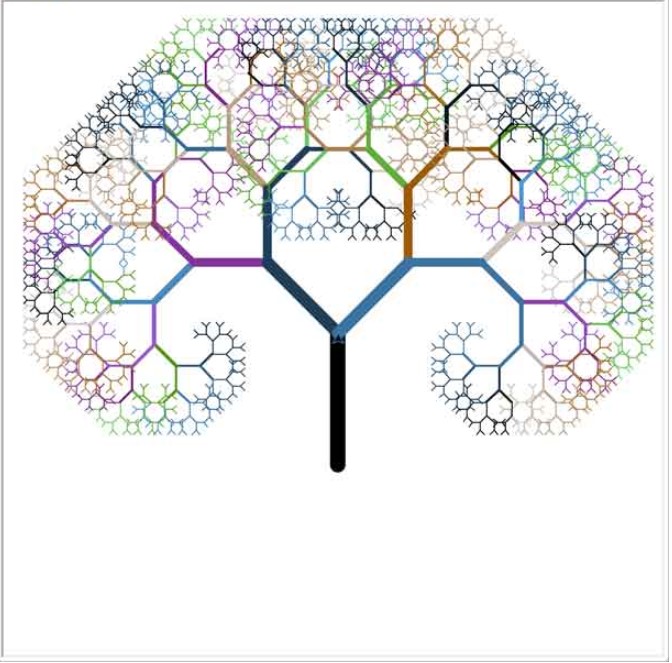
使用递归,可以绘制出非常复杂的图形。例如,下面的代码可以绘制一棵分型树:
1 | from turtle import * |
执行上述程序需要花费一定的时间,最后的效果如下: