转载自:
https://www.liaoxuefeng.com/wiki/1016959663602400
前言
高级篇涉及内容如下:
1. 网络编程
1. TCP/IP简介
P地址实际上是一个32位整数(称为IPv4),以字符串表示的IP地址如192.168.0.1实际上是把32位整数按8位分组后的数字表示,目的是便于阅读。
IPv6地址实际上是一个128位整数,它是目前使用的IPv4的升级版,以字符串表示类似于2001:0db8:85a3:0042:1000:8a2e:0370:7334。
TCP协议则是建立在IP协议之上的。TCP协议负责在两台计算机之间建立可靠连接,保证数据包按顺序到达。TCP协议会通过握手建立连接,然后,对每个IP包编号,确保对方按顺序收到,如果包丢掉了,就自动重发。
许多常用的更高级的协议都是建立在TCP协议基础上的,比如用于浏览器的HTTP协议、发送邮件的SMTP协议等。
一个TCP报文除了包含要传输的数据外,还包含源IP地址和目标IP地址,源端口和目标端口。
2. TCP编程
Socket是网络编程的一个抽象概念。通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可。
1. 客户端
大多数连接都是可靠的TCP连接。创建TCP连接时,主动发起连接的叫客户端,被动响应连接的叫服务器。
举个例子,当我们在浏览器中访问新浪时,我们自己的计算机就是客户端,浏览器会主动向新浪的服务器发起连接。如果一切顺利,新浪的服务器接受了我们的连接,一个TCP连接就建立起来的,后面的通信就是发送网页内容了。
所以,我们要创建一个基于TCP连接的Socket,可以这样做:
1 | # 导入socket库: |
创建Socket时,AF_INET指定使用IPv4协议,如果要用更先进的IPv6,就指定为AF_INET6。SOCK_STREAM指定使用面向流的TCP协议,这样,一个Socket对象就创建成功,但是还没有建立连接。
客户端要主动发起TCP连接,必须知道服务器的IP地址和端口号。新浪网站的IP地址可以用域名www.sina.com.cn自动转换到IP地址,但是怎么知道新浪服务器的端口号呢?
答案是作为服务器,提供什么样的服务,端口号就必须固定下来。由于我们想要访问网页,因此新浪提供网页服务的服务器必须把端口号固定在80端口,因为80端口是Web服务的标准端口。其他服务都有对应的标准端口号,例如SMTP服务是25端口,FTP服务是21端口,等等。端口号小于1024的是Internet标准服务的端口,端口号大于1024的,可以任意使用。
因此,我们连接新浪服务器的代码如下:
1 | s.connect(('www.sina.com.cn', 80)) |
注意参数是一个tuple,包含地址和端口号。
建立TCP连接后,我们就可以向新浪服务器发送请求,要求返回首页的内容:
1 | # 发送数据: |
TCP连接创建的是双向通道,双方都可以同时给对方发数据。但是谁先发谁后发,怎么协调,要根据具体的协议来决定。例如,HTTP协议规定客户端必须先发请求给服务器,服务器收到后才发数据给客户端。
发送的文本格式必须符合HTTP标准,如果格式没问题,接下来就可以接收新浪服务器返回的数据了:
1 | # 接收数据: |
接收数据时,调用recv(max)方法,一次最多接收指定的字节数,因此,在一个while循环中反复接收,直到recv()返回空数据,表示接收完毕,退出循环。
当我们接收完数据后,调用close()方法关闭Socket,这样,一次完整的网络通信就结束了:
1 | # 关闭连接: |
接收到的数据包括HTTP头和网页本身,我们只需要把HTTP头和网页分离一下,把HTTP头打印出来,网页内容保存到文件:
1 | header, html = data.split(b'\r\n\r\n', 1) |
现在,只需要在浏览器中打开这个sina.html文件,就可以看到新浪的首页了。
2. 服务器
和客户端编程相比,服务器编程就要复杂一些。
服务器进程首先要绑定一个端口并监听来自其他客户端的连接。如果某个客户端连接过来了,服务器就与该客户端建立Socket连接,随后的通信就靠这个Socket连接了。
所以,服务器会打开固定端口(比如80)监听,每来一个客户端连接,就创建该Socket连接。由于服务器会有大量来自客户端的连接,所以,服务器要能够区分一个Socket连接是和哪个客户端绑定的。一个Socket依赖4项:服务器地址、服务器端口、客户端地址、客户端端口来唯一确定一个Socket。
但是服务器还需要同时响应多个客户端的请求,所以,每个连接都需要一个新的进程或者新的线程来处理,否则,服务器一次就只能服务一个客户端了。
我们来编写一个简单的服务器程序,它接收客户端连接,把客户端发过来的字符串加上Hello再发回去。
首先,创建一个基于IPv4和TCP协议的Socket:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) |
然后,我们要绑定监听的地址和端口。服务器可能有多块网卡,可以绑定到某一块网卡的IP地址上,也可以用0.0.0.0绑定到所有的网络地址,还可以用127.0.0.1绑定到本机地址。127.0.0.1是一个特殊的IP地址,表示本机地址,如果绑定到这个地址,客户端必须同时在本机运行才能连接,也就是说,外部的计算机无法连接进来。
端口号需要预先指定。因为我们写的这个服务不是标准服务,所以用9999这个端口号。请注意,小于1024的端口号必须要有管理员权限才能绑定:
1 | # 监听端口: |
紧接着,调用listen()方法开始监听端口,传入的参数指定等待连接的最大数量:
1 | s.listen(5) |
接下来,服务器程序通过一个永久循环来接受来自客户端的连接,accept()会等待并返回一个客户端的连接:
1 | while True: |
每个连接都必须创建新线程(或进程)来处理,否则,单线程在处理连接的过程中,无法接受其他客户端的连接:
1 | def tcplink(sock, addr): |
连接建立后,服务器首先发一条欢迎消息,然后等待客户端数据,并加上Hello再发送给客户端。如果客户端发送了exit字符串,就直接关闭连接。
要测试这个服务器程序,我们还需要编写一个客户端程序:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) |
我们需要打开两个命令行窗口,一个运行服务器程序,另一个运行客户端程序,就可以看到效果了:
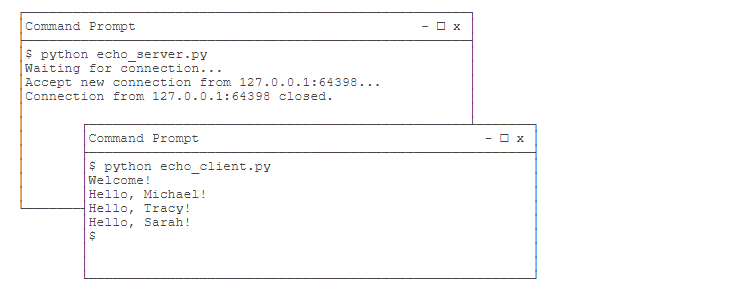
需要注意的是,客户端程序运行完毕就退出了,而服务器程序会永远运行下去,必须按Ctrl+C退出程序。
3. 小结
用TCP协议进行Socket编程在Python中十分简单,对于客户端,要主动连接服务器的IP和指定端口,对于服务器,要首先监听指定端口,然后,对每一个新的连接,创建一个线程或进程来处理。通常,服务器程序会无限运行下去。
同一个端口,被一个Socket绑定了以后,就不能被别的Socket绑定了。
3. UDP编程
TCP是建立可靠连接,并且通信双方都可以以流的形式发送数据。相对TCP,UDP则是面向无连接的协议。
使用UDP协议时,不需要建立连接,只需要知道对方的IP地址和端口号,就可以直接发数据包。但是,能不能到达就不知道了。
虽然用UDP传输数据不可靠,但它的优点是和TCP比,速度快,对于不要求可靠到达的数据,就可以使用UDP协议。
我们来看看如何通过UDP协议传输数据。和TCP类似,使用UDP的通信双方也分为客户端和服务器。服务器首先需要绑定端口:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) |
创建Socket时,SOCK_DGRAM指定了这个Socket的类型是UDP。绑定端口和TCP一样,但是不需要调用listen()方法,而是直接接收来自任何客户端的数据:
1 | print('Bind UDP on 9999...') |
recvfrom()方法返回数据和客户端的地址与端口,这样,服务器收到数据后,直接调用sendto()就可以把数据用UDP发给客户端。
注意这里省掉了多线程,因为这个例子很简单。
客户端使用UDP时,首先仍然创建基于UDP的Socket,然后,不需要调用connect(),直接通过sendto()给服务器发数据:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) |
从服务器接收数据仍然调用recv()方法。
仍然用两个命令行分别启动服务器和客户端测试,结果如下:

小结
UDP的使用与TCP类似,但是不需要建立连接。此外,服务器绑定UDP端口和TCP端口互不冲突,也就是说,UDP的9999端口与TCP的9999端口可以各自绑定。
2. 电子邮件
假设我们自己的电子邮件地址是me@163.com,对方的电子邮件地址是friend@sina.com(注意地址都是虚构的哈),现在我们用Outlook或者Foxmail之类的软件写好邮件,填上对方的Email地址,点“发送”,电子邮件就发出去了。这些电子邮件软件被称为MUA:Mail User Agent——邮件用户代理。
Email从MUA发出去,不是直接到达对方电脑,而是发到MTA:Mail Transfer Agent——邮件传输代理,就是那些Email服务提供商,比如网易、新浪等等。由于我们自己的电子邮件是163.com,所以,Email首先被投递到网易提供的MTA,再由网易的MTA发到对方服务商,也就是新浪的MTA。这个过程中间可能还会经过别的MTA,但是我们不关心具体路线,我们只关心速度。
Email到达新浪的MTA后,由于对方使用的是@sina.com的邮箱,因此,新浪的MTA会把Email投递到邮件的最终目的地MDA:Mail Delivery Agent——邮件投递代理。Email到达MDA后,就静静地躺在新浪的某个服务器上,存放在某个文件或特殊的数据库里,我们将这个长期保存邮件的地方称之为电子邮箱。
同普通邮件类似,Email不会直接到达对方的电脑,因为对方电脑不一定开机,开机也不一定联网。对方要取到邮件,必须通过MUA从MDA上把邮件取到自己的电脑上。
所以,一封电子邮件的旅程就是:
1 | 发件人 -> MUA -> MTA -> MTA -> 若干个MTA -> MDA <- MUA <- 收件人 |
有了上述基本概念,要编写程序来发送和接收邮件,本质上就是:
编写MUA把邮件发到MTA;
编写MUA从MDA上收邮件。
发邮件时,MUA和MTA使用的协议就是SMTP:Simple Mail Transfer Protocol,后面的MTA到另一个MTA也是用SMTP协议。
收邮件时,MUA和MDA使用的协议有两种:POP:Post Office Protocol,目前版本是3,俗称POP3;IMAP:Internet Message Access Protocol,目前版本是4,优点是不但能取邮件,还可以直接操作MDA上存储的邮件,比如从收件箱移到垃圾箱,等等。
邮件客户端软件在发邮件时,会让你先配置SMTP服务器,也就是你要发到哪个MTA上。假设你正在使用163的邮箱,你就不能直接发到新浪的MTA上,因为它只服务新浪的用户,所以,你得填163提供的SMTP服务器地址:smtp.163.com,为了证明你是163的用户,SMTP服务器还要求你填写邮箱地址和邮箱口令,这样,MUA才能正常地把Email通过SMTP协议发送到MTA。
类似的,从MDA收邮件时,MDA服务器也要求验证你的邮箱口令,确保不会有人冒充你收取你的邮件,所以,Outlook之类的邮件客户端会要求你填写POP3或IMAP服务器地址、邮箱地址和口令,这样,MUA才能顺利地通过POP或IMAP协议从MDA取到邮件。
在使用Python收发邮件前,请先准备好至少两个电子邮件,如xxx@163.com,xxx@sina.com,xxx@qq.com等,注意两个邮箱不要用同一家邮件服务商。
最后_特别注意_,目前大多数邮件服务商都需要手动打开SMTP发信和POP收信的功能,否则只允许在网页登录:
1. SMTP发送邮件
SMTP是发送邮件的协议,Python内置对SMTP的支持,可以发送纯文本邮件、HTML邮件以及带附件的邮件。
Python对SMTP支持有smtplib和email两个模块,email负责构造邮件,smtplib负责发送邮件。
首先,我们来构造一个最简单的纯文本邮件:
1 | from email.mime.text import MIMEText |
注意到构造MIMEText对象时,第一个参数就是邮件正文,第二个参数是MIME的subtype,传入'plain'表示纯文本,最终的MIME就是'text/plain',最后一定要用utf-8编码保证多语言兼容性。
然后,通过SMTP发出去:
1 | # 输入Email地址和口令: |
我们用set_debuglevel(1)就可以打印出和SMTP服务器交互的所有信息。SMTP协议就是简单的文本命令和响应。login()方法用来登录SMTP服务器,sendmail()方法就是发邮件,由于可以一次发给多个人,所以传入一个list,邮件正文是一个str,as_string()把MIMEText对象变成str。
如果一切顺利,就可以在收件人信箱中收到我们刚发送的Email:
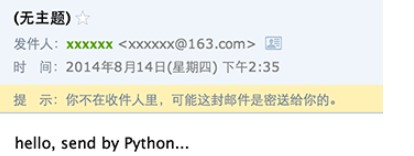
仔细观察,发现如下问题:
- 邮件没有主题;
- 收件人的名字没有显示为友好的名字,比如
Mr Green <green@example.com>; - 明明收到了邮件,却提示不在收件人中。
这是因为邮件主题、如何显示发件人、收件人等信息并不是通过SMTP协议发给MTA,而是包含在发给MTA的文本中的,所以,我们必须把From、To和Subject添加到MIMEText中,才是一封完整的邮件:
1 | from email import encoders |
我们编写了一个函数_format_addr()来格式化一个邮件地址。注意不能简单地传入name <addr@example.com>,因为如果包含中文,需要通过Header对象进行编码。
msg['To']接收的是字符串而不是list,如果有多个邮件地址,用,分隔即可。
再发送一遍邮件,就可以在收件人邮箱中看到正确的标题、发件人和收件人:
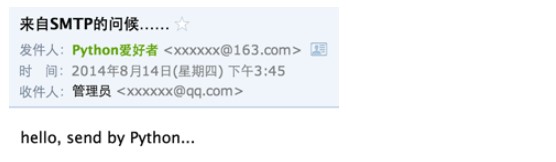
你看到的收件人的名字很可能不是我们传入的管理员,因为很多邮件服务商在显示邮件时,会把收件人名字自动替换为用户注册的名字,但是其他收件人名字的显示不受影响。
如果我们查看Email的原始内容,可以看到如下经过编码的邮件头:
1 | From: =?utf-8?b?UHl0aG9u54ix5aW96ICF?= <xxxxxx@163.com> |
这就是经过Header对象编码的文本,包含utf-8编码信息和Base64编码的文本。如果我们自己来手动构造这样的编码文本,显然比较复杂。
1. 发送HTML邮件
如果我们要发送HTML邮件,而不是普通的纯文本文件怎么办?方法很简单,在构造MIMEText对象时,把HTML字符串传进去,再把第二个参数由plain变为html就可以了:
1 | msg = MIMEText('<html><body><h1>Hello</h1>' + |
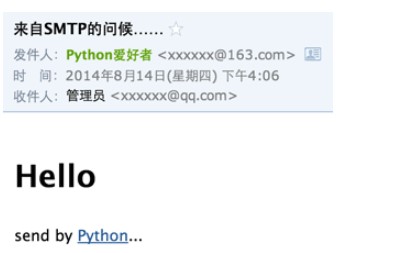
再发送一遍邮件,你将看到以HTML显示的邮件:
2. 发送附件
如果Email中要加上附件怎么办?带附件的邮件可以看做包含若干部分的邮件:文本和各个附件本身,所以,可以构造一个MIMEMultipart对象代表邮件本身,然后往里面加上一个MIMEText作为邮件正文,再继续往里面加上表示附件的MIMEBase对象即可:
1 | # 邮件对象: |
然后,按正常发送流程把msg(注意类型已变为MIMEMultipart)发送出去,就可以收到如下带附件的邮件:
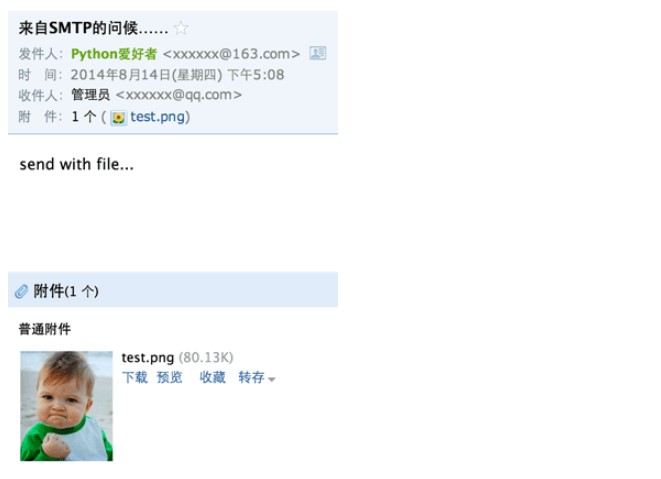
2. 发送图片
如果要把一个图片嵌入到邮件正文中怎么做?直接在HTML邮件中链接图片地址行不行?答案是,大部分邮件服务商都会自动屏蔽带有外链的图片,因为不知道这些链接是否指向恶意网站。
要把图片嵌入到邮件正文中,我们只需按照发送附件的方式,先把邮件作为附件添加进去,然后,在HTML中通过引用src="cid:0"就可以把附件作为图片嵌入了。如果有多个图片,给它们依次编号,然后引用不同的cid:x即可。
把上面代码加入MIMEMultipart的MIMEText从plain改为html,然后在适当的位置引用图片:
1 | msg.attach(MIMEText('<html><body><h1>Hello</h1>' + |
再次发送,就可以看到图片直接嵌入到邮件正文的效果:

3. 同时发送HTML和Plain格式
如果我们发送HTML邮件,收件人通过浏览器或者Outlook之类的软件是可以正常浏览邮件内容的,但是,如果收件人使用的设备太古老,查看不了HTML邮件怎么办?
办法是在发送HTML的同时再附加一个纯文本,如果收件人无法查看HTML格式的邮件,就可以自动降级查看纯文本邮件。
利用MIMEMultipart就可以组合一个HTML和Plain,要注意指定subtype是alternative:
1 | msg = MIMEMultipart('alternative') |
4. 加密SMTP
使用标准的25端口连接SMTP服务器时,使用的是明文传输,发送邮件的整个过程可能会被窃听。要更安全地发送邮件,可以加密SMTP会话,实际上就是先创建SSL安全连接,然后再使用SMTP协议发送邮件。
某些邮件服务商,例如Gmail,提供的SMTP服务必须要加密传输。我们来看看如何通过Gmail提供的安全SMTP发送邮件。
必须知道,Gmail的SMTP端口是587,因此,修改代码如下:
1 | smtp_server = 'smtp.gmail.com' |
只需要在创建SMTP对象后,立刻调用starttls()方法,就创建了安全连接。后面的代码和前面的发送邮件代码完全一样。
如果因为网络问题无法连接Gmail的SMTP服务器,请相信我们的代码是没有问题的,你需要对你的网络设置做必要的调整。
5. 小结
使用Python的smtplib发送邮件十分简单,只要掌握了各种邮件类型的构造方法,正确设置好邮件头,就可以顺利发出。
构造一个邮件对象就是一个Messag对象,如果构造一个MIMEText对象,就表示一个文本邮件对象,如果构造一个MIMEImage对象,就表示一个作为附件的图片,要把多个对象组合起来,就用MIMEMultipart对象,而MIMEBase可以表示任何对象。它们的继承关系如下:
1 | Message |
这种嵌套关系就可以构造出任意复杂的邮件。你可以通过email.mime文档查看它们所在的包以及详细的用法。
2. POP3收取邮件
SMTP用于发送邮件,如果要收取邮件呢?
收取邮件就是编写一个MUA作为客户端,从MDA把邮件获取到用户的电脑或者手机上。收取邮件最常用的协议是POP协议,目前版本号是3,俗称POP3。
Python内置一个poplib模块,实现了POP3协议,可以直接用来收邮件。
注意到POP3协议收取的不是一个已经可以阅读的邮件本身,而是邮件的原始文本,这和SMTP协议很像,SMTP发送的也是经过编码后的一大段文本。
要把POP3收取的文本变成可以阅读的邮件,还需要用email模块提供的各种类来解析原始文本,变成可阅读的邮件对象。
所以,收取邮件分两步:
第一步:用poplib把邮件的原始文本下载到本地;
第二部:用email解析原始文本,还原为邮件对象。
1. 通过POP3下载邮件
POP3协议本身很简单,以下面的代码为例,我们来获取最新的一封邮件内容:
1 | import poplib |
用POP3获取邮件其实很简单,要获取所有邮件,只需要循环使用retr()把每一封邮件内容拿到即可。真正麻烦的是把邮件的原始内容解析为可以阅读的邮件对象。
2. 解析邮件
解析邮件的过程和上一节构造邮件正好相反,因此,先导入必要的模块:
1 | from email.parser import Parser |
只需要一行代码就可以把邮件内容解析为Message对象:
1 | msg = Parser().parsestr(msg_content) |
但是这个Message对象本身可能是一个MIMEMultipart对象,即包含嵌套的其他MIMEBase对象,嵌套可能还不止一层。
所以我们要递归地打印出Message对象的层次结构:
1 | # indent用于缩进显示: |
邮件的Subject或者Email中包含的名字都是经过编码后的str,要正常显示,就必须decode:
1 | def decode_str(s): |
decode_header()返回一个list,因为像Cc、Bcc这样的字段可能包含多个邮件地址,所以解析出来的会有多个元素。上面的代码我们偷了个懒,只取了第一个元素。
文本邮件的内容也是str,还需要检测编码,否则,非UTF-8编码的邮件都无法正常显示:
1 | def guess_charset(msg): |
把上面的代码整理好,我们就可以来试试收取一封邮件。先往自己的邮箱发一封邮件,然后用浏览器登录邮箱,看看邮件收到没,如果收到了,我们就来用Python程序把它收到本地:
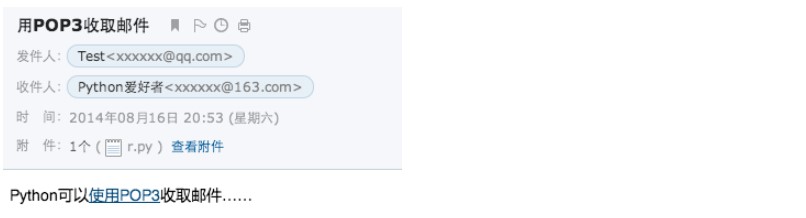
运行程序,结果如下:
1 | +OK Welcome to coremail Mail Pop3 Server (163coms[...]) |
我们从打印的结构可以看出,这封邮件是一个MIMEMultipart,它包含两部分:第一部分又是一个MIMEMultipart,第二部分是一个附件。而内嵌的MIMEMultipart是一个alternative类型,它包含一个纯文本格式的MIMEText和一个HTML格式的MIMEText。
3. 小结
用Python的poplib模块收取邮件分两步:第一步是用POP3协议把邮件获取到本地,第二步是用email模块把原始邮件解析为Message对象,然后,用适当的形式把邮件内容展示给用户即可。
3. 访问数据库
1. 使用SQLite
SQLite是一种嵌入式数据库,它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。
Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用。
在使用SQLite前,我们先要搞清楚几个概念:
表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,比如学生的表,班级的表,学校的表,等等。表和表之间通过外键关联。
要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection;
连接到数据库后,需要打开游标,称之为Cursor,通过Cursor执行SQL语句,然后,获得执行结果。
Python定义了一套操作数据库的API接口,任何数据库要连接到Python,只需要提供符合Python标准的数据库驱动即可。
由于SQLite的驱动内置在Python标准库中,所以我们可以直接来操作SQLite数据库。
我们在Python交互式命令行实践一下:
1 | # 导入SQLite驱动: |
我们再试试查询记录:
1 | >>> conn = sqlite3.connect('test.db') |
使用Python的DB-API时,只要搞清楚Connection和Cursor对象,打开后一定记得关闭,就可以放心地使用。
使用Cursor对象执行insert,update,delete语句时,执行结果由rowcount返回影响的行数,就可以拿到执行结果。
使用Cursor对象执行select语句时,通过featchall()可以拿到结果集。结果集是一个list,每个元素都是一个tuple,对应一行记录。
如果SQL语句带有参数,那么需要把参数按照位置传递给execute()方法,有几个?占位符就必须对应几个参数,例如:
1 | cursor.execute('select * from user where name=? and pwd=?', ('abc', 'password')) |
SQLite支持常见的标准SQL语句以及几种常见的数据类型。具体文档请参阅SQLite官方网站。
小结
在Python中操作数据库时,要先导入数据库对应的驱动,然后,通过Connection对象和Cursor对象操作数据。
要确保打开的Connection对象和Cursor对象都正确地被关闭,否则,资源就会泄露。
如何才能确保出错的情况下也关闭掉Connection对象和Cursor对象呢?请回忆try:...except:...finally:...的用法。
2. 使用MySQL
MySQL是Web世界中使用最广泛的数据库服务器。SQLite的特点是轻量级、可嵌入,但不能承受高并发访问,适合桌面和移动应用。而MySQL是为服务器端设计的数据库,能承受高并发访问,同时占用的内存也远远大于SQLite。
此外,MySQL内部有多种数据库引擎,最常用的引擎是支持数据库事务的InnoDB。
1. 安装MySQL
可以直接从MySQL官方网站下载最新的Community Server 5.6.x版本。MySQL是跨平台的,选择对应的平台下载安装文件,安装即可。
安装时,MySQL会提示输入root用户的口令,请务必记清楚。如果怕记不住,就把口令设置为password。
在Windows上,安装时请选择UTF-8编码,以便正确地处理中文。
在Mac或Linux上,需要编辑MySQL的配置文件,把数据库默认的编码全部改为UTF-8。MySQL的配置文件默认存放在/etc/my.cnf或者/etc/mysql/my.cnf:
1 | [client] |
重启MySQL后,可以通过MySQL的客户端命令行检查编码:
1 | $ mysql -u root -p |
看到utf8字样就表示编码设置正确。
注:如果MySQL的版本≥5.5.3,可以把编码设置为utf8mb4,utf8mb4和utf8完全兼容,但它支持最新的Unicode标准,可以显示emoji字符。
2. 安装MySQL驱动
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持Python的MySQL驱动来连接到MySQL服务器。MySQL官方提供了mysql-connector-python驱动,但是安装的时候需要给pip命令加上参数--allow-external:
1 | $ pip install mysql-connector-python --allow-external mysql-connector-python |
如果上面的命令安装失败,可以试试另一个驱动:
1 | $ pip install mysql-connector |
我们演示如何连接到MySQL服务器的test数据库:
1 | # 导入MySQL驱动: |
由于Python的DB-API定义都是通用的,所以,操作MySQL的数据库代码和SQLite类似。
3. 小结
- 执行INSERT等操作后要调用
commit()提交事务; - MySQL的SQL占位符是
%s。
3. 使用SQLAlchemy
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录,比如,包含id和name的user表:
1 | [ |
Python的DB-API返回的数据结构就是像上面这样表示的。
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
1 | class User(object): |
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
在Python中,最有名的ORM框架是SQLAlchemy。我们来看看SQLAlchemy的用法。
首先通过pip安装SQLAlchemy:
1 | $ pip install sqlalchemy |
然后,利用上次我们在MySQL的test数据库中创建的user表,用SQLAlchemy来试试:
第一步,导入SQLAlchemy,并初始化DBSession:
1 | # 导入: |
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
1 | class School(Base): |
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
1 | '数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名' |
你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
1 | # 创建session对象: |
可见,关键是获取session,然后把对象添加到session,最后提交并关闭。DBSession对象可视为当前数据库连接。
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
1 | # 创建Session: |
运行结果如下:
1 | type: <class '__main__.User'> |
可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
1 | class User(Base): |
当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
小结
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。
正确使用ORM的前提是了解关系数据库的原理。
4. Web开发
1. HTTP协议简介
1. HTTP请求
HTTP请求的流程:
步骤1:浏览器首先向服务器发送HTTP请求,请求包括:
方法:GET还是POST,GET仅请求资源,POST会附带用户数据;
路径:/full/url/path;
域名:由Host头指定:Host: www.sina.com.cn
以及其他相关的Header;
如果是POST,那么请求还包括一个Body,包含用户数据。
步骤2:服务器向浏览器返回HTTP响应,响应包括:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定,例如:Content-Type: text/html;charset=utf-8表示响应类型是HTML文本,并且编码是UTF-8,Content-Type: image/jpeg表示响应类型是JPEG格式的图片;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中。
步骤3:如果浏览器还需要继续向服务器请求其他资源,比如图片,就再次发出HTTP请求,重复步骤1、2。
Web采用的HTTP协议采用了非常简单的请求-响应模式,从而大大简化了开发。当我们编写一个页面时,我们只需要在HTTP响应中把HTML发送出去,不需要考虑如何附带图片、视频等,浏览器如果需要请求图片和视频,它会发送另一个HTTP请求,因此,一个HTTP请求只处理一个资源。
HTTP协议同时具备极强的扩展性,虽然浏览器请求的是http://www.sina.com.cn/的首页,但是新浪在HTML中可以链入其他服务器的资源,比如<img src="http://i1.sinaimg.cn/home/2013/1008/U8455P30DT20131008135420.png">,从而将请求压力分散到各个服务器上,并且,一个站点可以链接到其他站点,无数个站点互相链接起来,就形成了World Wide Web,简称“三达不溜”(WWW)。
2. HTTP格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。
HTTP协议是一种文本协议,所以,它的格式也非常简单。HTTP GET请求的格式:
1 | GET /path HTTP/1.1 |
每个Header一行一个,换行符是\r\n。
HTTP POST请求的格式:
1 | POST /path HTTP/1.1 |
当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。
HTTP响应的格式:
1 | 200 OK |
HTTP响应如果包含body,也是通过\r\n\r\n来分隔的。请再次注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
2. HTML简介
网页就是HTML?这么理解大概没错。因为网页中不但包含文字,还有图片、视频、Flash小游戏,有复杂的排版、动画效果,所以,HTML定义了一套语法规则,来告诉浏览器如何把一个丰富多彩的页面显示出来。
HTML长什么样?上次我们看了新浪首页的HTML源码,如果仔细数数,竟然有6000多行!
所以,学HTML,就不要指望从新浪入手了。我们来看看最简单的HTML长什么样:
1 | <html> |
可以用文本编辑器编写HTML,然后保存为hello.html,双击或者把文件拖到浏览器中,就可以看到效果:
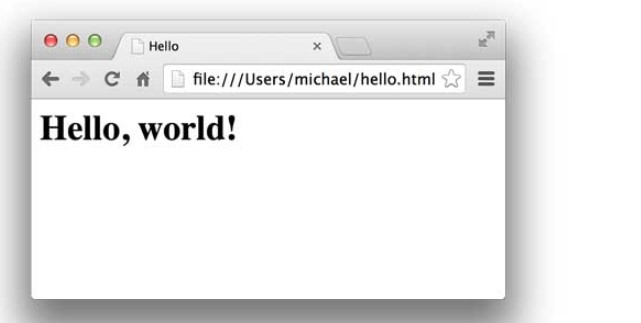
HTML文档就是一系列的Tag组成,最外层的Tag是<html>。规范的HTML也包含<head>...</head>和<body>...</body>(注意不要和HTTP的Header、Body搞混了),由于HTML是富文档模型,所以,还有一系列的Tag用来表示链接、图片、表格、表单等等。
CSS简介
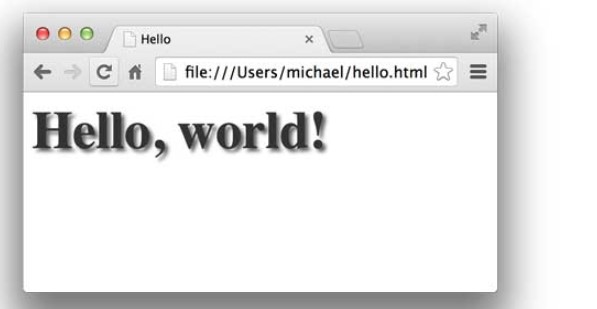
CSS是Cascading Style Sheets(层叠样式表)的简称,CSS用来控制HTML里的所有元素如何展现,比如,给标题元素<h1>加一个样式,变成48号字体,灰色,带阴影:
1 | <html> |
效果如下:
JavaScript简介
JavaScript虽然名称有个Java,但它和Java真的一点关系没有。JavaScript是为了让HTML具有交互性而作为脚本语言添加的,JavaScript既可以内嵌到HTML中,也可以从外部链接到HTML中。如果我们希望当用户点击标题时把标题变成红色,就必须通过JavaScript来实现:
1 | <html> |
点击标题后效果如下:
如果要学习Web开发,首先要对HTML、CSS和JavaScript作一定的了解。HTML定义了页面的内容,CSS来控制页面元素的样式,而JavaScript负责页面的交互逻辑。
讲解HTML、CSS和JavaScript就可以写3本书,对于优秀的Web开发人员来说,精通HTML、CSS和JavaScript是必须的,这里推荐一个在线学习网站w3schools:
以及一个对应的中文版本:
当我们用Python或者其他语言开发Web应用时,我们就是要在服务器端动态创建出HTML,这样,浏览器就会向不同的用户显示出不同的Web页面。
3. WSGI接口
了解了HTTP协议和HTML文档,我们其实就明白了一个Web应用的本质就是:
浏览器发送一个HTTP请求;
服务器收到请求,生成一个HTML文档;
服务器把HTML文档作为HTTP响应的Body发送给浏览器;
浏览器收到HTTP响应,从HTTP Body取出HTML文档并显示。
所以,最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。Apache、Nginx、Lighttpd等这些常见的静态服务器就是干这件事情的。
如果要动态生成HTML,就需要把上述步骤自己来实现。不过,接受HTTP请求、解析HTTP请求、发送HTTP响应都是苦力活,如果我们自己来写这些底层代码,还没开始写动态HTML呢,就得花个把月去读HTTP规范。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI:Web Server Gateway Interface。
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello, web!”:
1 | def application(environ, start_response): |
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
environ:一个包含所有HTTP请求信息的
dict对象;start_response:一个发送HTTP响应的函数。
在application()函数中,调用:
1 | start_response('200 OK', [('Content-Type', 'text/html')]) |
就发送了HTTP响应的Header,注意Header只能发送一次,也就是只能调用一次start_response()函数。start_response()函数接收两个参数,一个是HTTP响应码,一个是一组list表示的HTTP Header,每个Header用一个包含两个str的tuple表示。
通常情况下,都应该把Content-Type头发送给浏览器。其他很多常用的HTTP Header也应该发送。
然后,函数的返回值b'<h1>Hello, web!</h1>'将作为HTTP响应的Body发送给浏览器。
有了WSGI,我们关心的就是如何从environ这个dict对象拿到HTTP请求信息,然后构造HTML,通过start_response()发送Header,最后返回Body。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,底层代码不需要我们自己编写,我们只负责在更高层次上考虑如何响应请求就可以了。
不过,等等,这个application()函数怎么调用?如果我们自己调用,两个参数environ和start_response我们没法提供,返回的bytes也没法发给浏览器。
所以application()函数必须由WSGI服务器来调用。有很多符合WSGI规范的服务器,我们可以挑选一个来用。但是现在,我们只想尽快测试一下我们编写的application()函数真的可以把HTML输出到浏览器,所以,要赶紧找一个最简单的WSGI服务器,把我们的Web应用程序跑起来。
好消息是Python内置了一个WSGI服务器,这个模块叫wsgiref,它是用纯Python编写的WSGI服务器的参考实现。所谓“参考实现”是指该实现完全符合WSGI标准,但是不考虑任何运行效率,仅供开发和测试使用。
运行WSGI服务
我们先编写hello.py,实现Web应用程序的WSGI处理函数:
1 | # hello.py |
然后,再编写一个server.py,负责启动WSGI服务器,加载application()函数:
1 | # server.py |
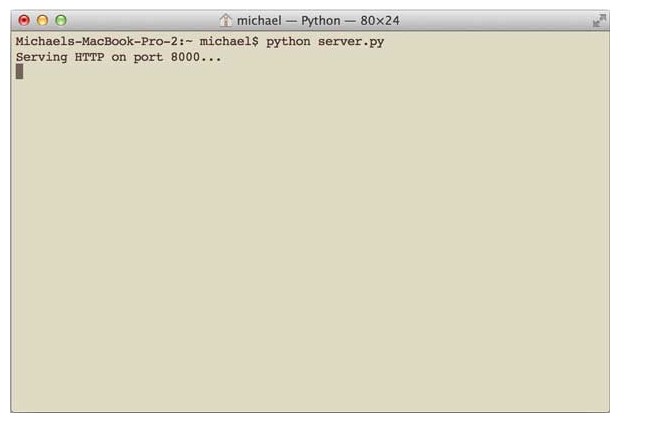
确保以上两个文件在同一个目录下,然后在命令行输入python server.py来启动WSGI服务器:
注意:如果8000端口已被其他程序占用,启动将失败,请修改成其他端口。
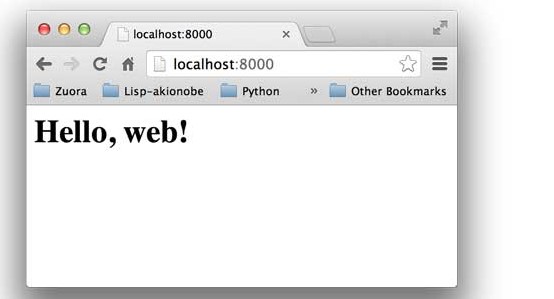
启动成功后,打开浏览器,输入http://localhost:8000/,就可以看到结果了:
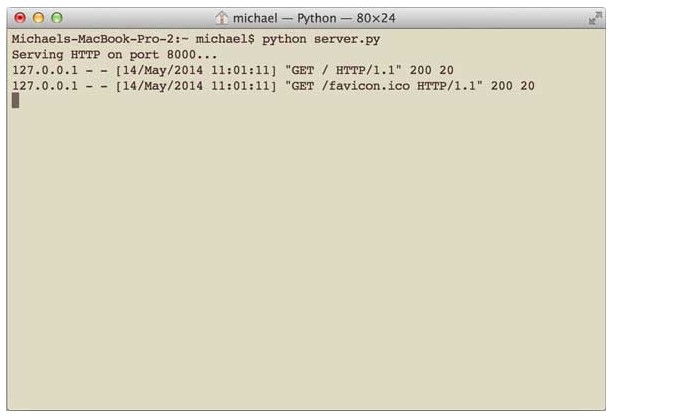
在命令行可以看到wsgiref打印的log信息:
按Ctrl+C终止服务器。
如果你觉得这个Web应用太简单了,可以稍微改造一下,从environ里读取PATH_INFO,这样可以显示更加动态的内容:
1 | # hello.py |
你可以在地址栏输入用户名作为URL的一部分,将返回Hello, xxx!:
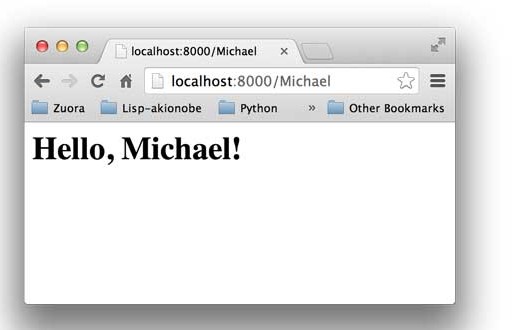
无论多么复杂的Web应用程序,入口都是一个WSGI处理函数。HTTP请求的所有输入信息都可以通过environ获得,HTTP响应的输出都可以通过start_response()加上函数返回值作为Body。
复杂的Web应用程序,光靠一个WSGI函数来处理还是太底层了,我们需要在WSGI之上再抽象出Web框架,进一步简化Web开发。
4. 使用Web框架
了解了WSGI框架,我们发现:其实一个Web App,就是写一个WSGI的处理函数,针对每个HTTP请求进行响应。
但是如何处理HTTP请求不是问题,问题是如何处理100个不同的URL。
每一个URL可以对应GET和POST请求,当然还有PUT、DELETE等请求,但是我们通常只考虑最常见的GET和POST请求。
一个最简单的想法是从environ变量里取出HTTP请求的信息,然后逐个判断:
1 | def application(environ, start_response): |
只是这么写下去代码是肯定没法维护了。
代码这么写没法维护的原因是因为WSGI提供的接口虽然比HTTP接口高级了不少,但和Web App的处理逻辑比,还是比较低级,我们需要在WSGI接口之上能进一步抽象,让我们专注于用一个函数处理一个URL,至于URL到函数的映射,就交给Web框架来做。
由于用Python开发一个Web框架十分容易,所以Python有上百个开源的Web框架。这里我们先不讨论各种Web框架的优缺点,直接选择一个比较流行的Web框架——Flask来使用。
用Flask编写Web App比WSGI接口简单(这不是废话么,要是比WSGI还复杂,用框架干嘛?),我们先用pip安装Flask:
1 | $ pip install flask |
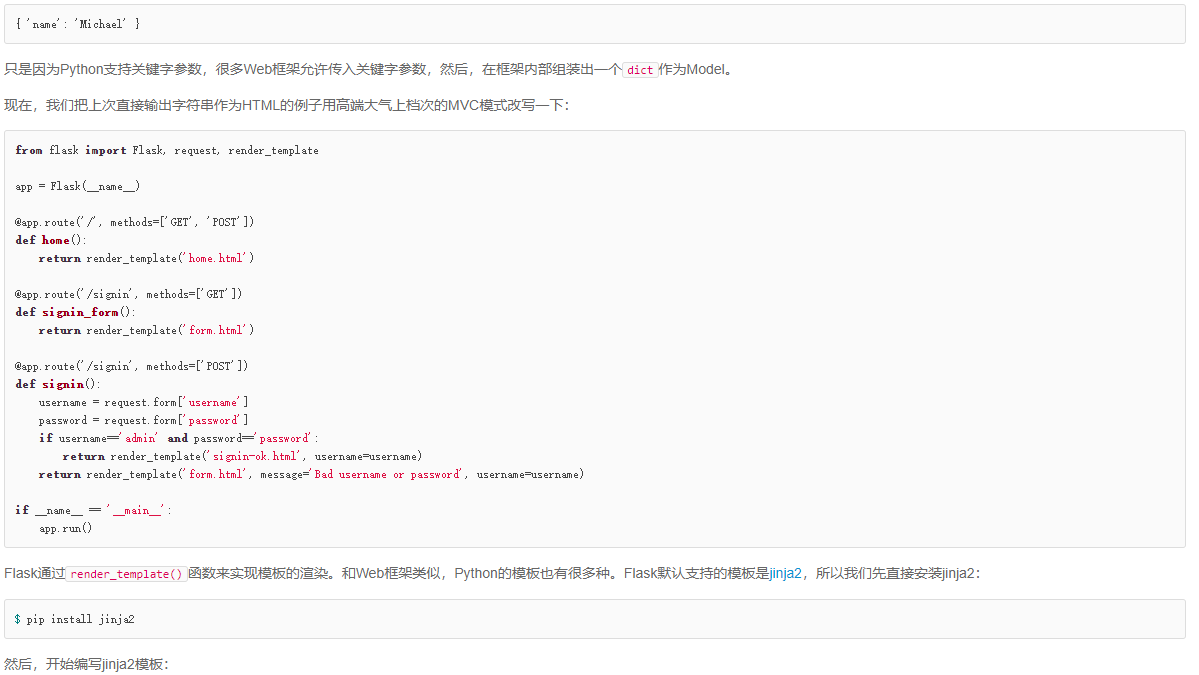
然后写一个app.py,处理3个URL,分别是:
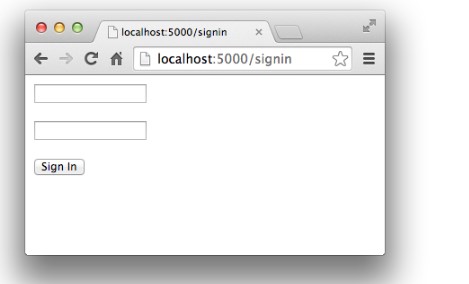
GET /:首页,返回Home;GET /signin:登录页,显示登录表单;POST /signin:处理登录表单,显示登录结果。
注意噢,同一个URL/signin分别有GET和POST两种请求,映射到两个处理函数中。
Flask通过Python的装饰器在内部自动地把URL和函数给关联起来,所以,我们写出来的代码就像这样:
1 | from flask import Flask |
运行python app.py,Flask自带的Server在端口5000上监听:
1 | $ python app.py |
打开浏览器,输入首页地址http://localhost:5000/:
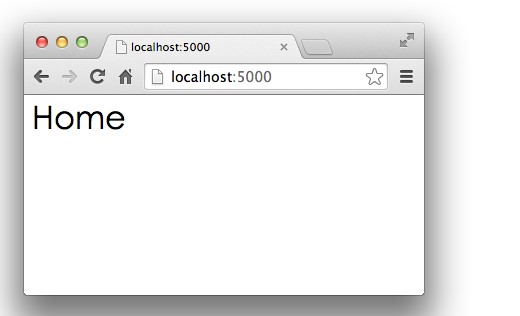
首页显示正确!
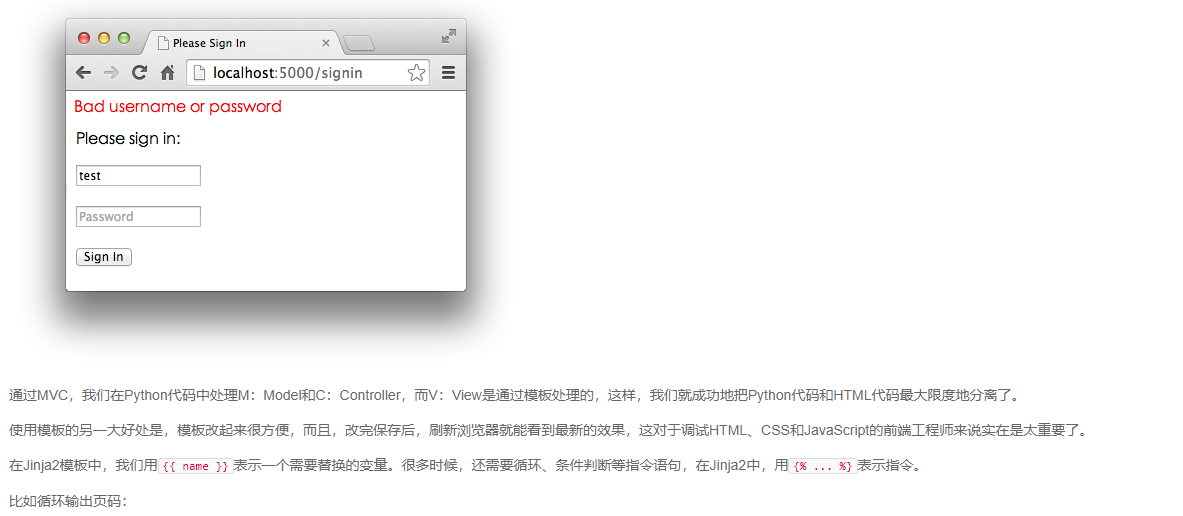
再在浏览器地址栏输入http://localhost:5000/signin,会显示登录表单:
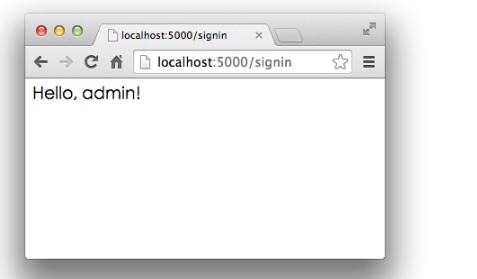
输入预设的用户名admin和口令password,登录成功:
输入其他错误的用户名和口令,登录失败:
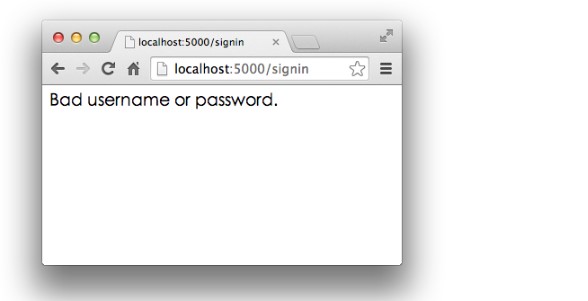
实际的Web App应该拿到用户名和口令后,去数据库查询再比对,来判断用户是否能登录成功。
除了Flask,常见的Python Web框架还有:
当然了,因为开发Python的Web框架也不是什么难事,后面也会讲到开发Web框架的内容。
小结
有了Web框架,我们在编写Web应用时,注意力就从WSGI处理函数转移到URL+对应的处理函数,这样,编写Web App就更加简单了。
在编写URL处理函数时,除了配置URL外,从HTTP请求拿到用户数据也是非常重要的。Web框架都提供了自己的API来实现这些功能。Flask通过request.form['name']来获取表单的内容。
5. 使用模板
Web框架把我们从WSGI中拯救出来了。现在,我们只需要不断地编写函数,带上URL,就可以继续Web App的开发了。
但是,Web App不仅仅是处理逻辑,展示给用户的页面也非常重要。在函数中返回一个包含HTML的字符串,简单的页面还可以,但是,想想新浪首页的6000多行的HTML,你确信能在Python的字符串中正确地写出来么?反正我是做不到。
俗话说得好,不懂前端的Python工程师不是好的产品经理。有Web开发经验的同学都明白,Web App最复杂的部分就在HTML页面。HTML不仅要正确,还要通过CSS美化,再加上复杂的JavaScript脚本来实现各种交互和动画效果。总之,生成HTML页面的难度很大。
由于在Python代码里拼字符串是不现实的,所以,模板技术出现了。
使用模板,我们需要预先准备一个HTML文档,这个HTML文档不是普通的HTML,而是嵌入了一些变量和指令,然后,根据我们传入的数据,替换后,得到最终的HTML,发送给用户:

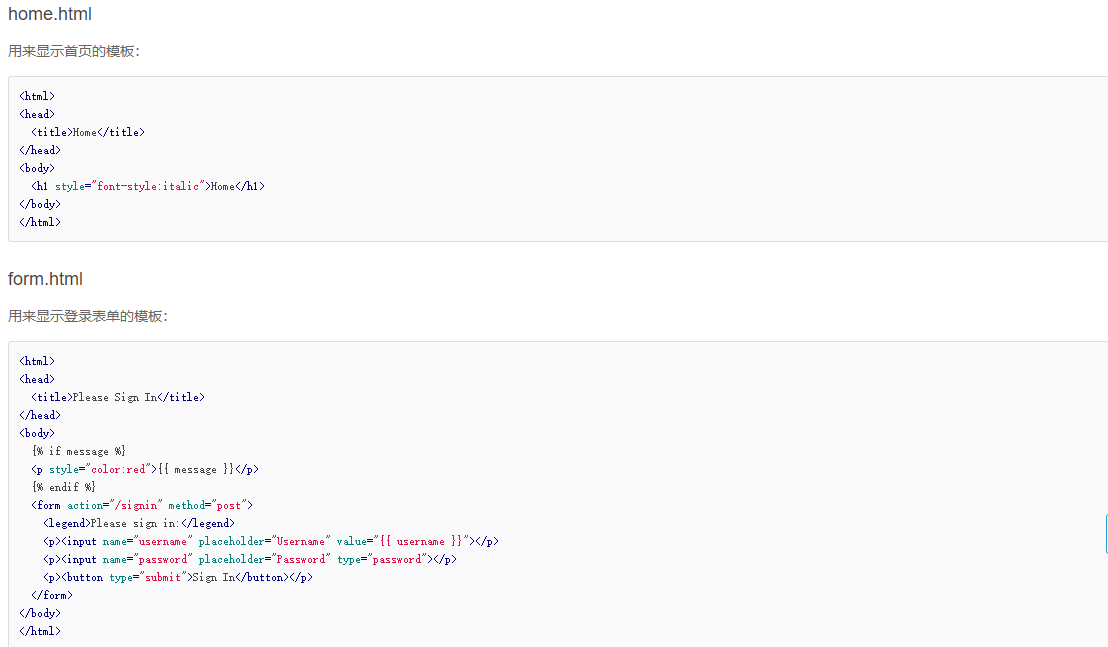
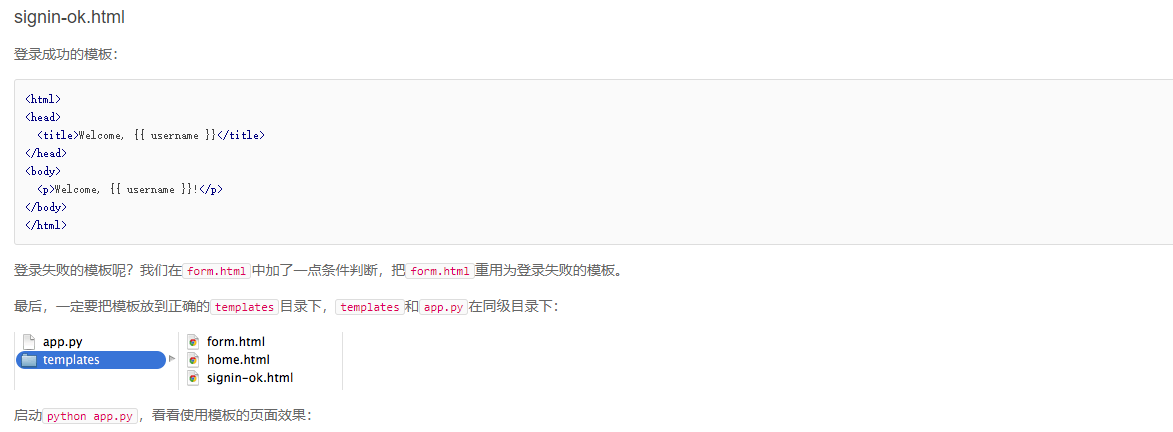
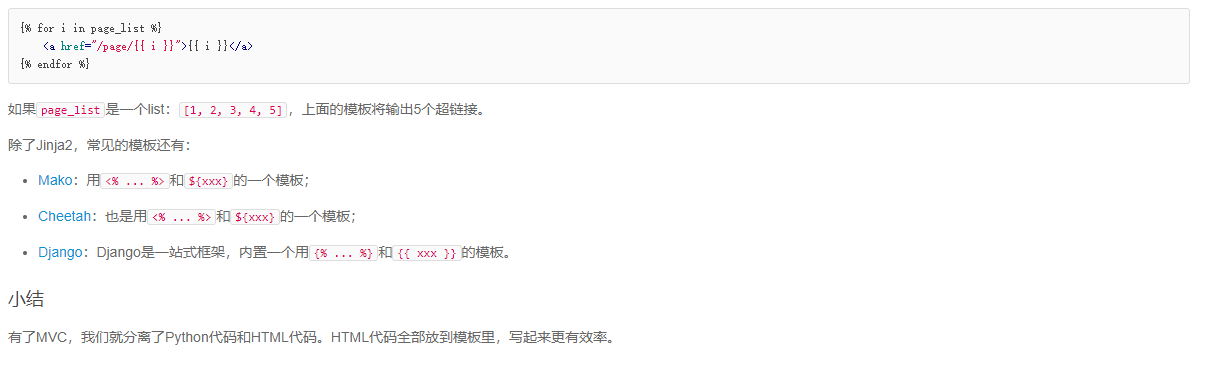
5. 异步IO
在“发出IO请求”到收到“IO完成”的这段时间里,同步IO模型下,主线程只能挂起,但异步IO模型下,主线程并没有休息,而是在消息循环中继续处理其他消息。这样,在异步IO模型下,一个线程就可以同时处理多个IO请求,并且没有切换线程的操作。对于大多数IO密集型的应用程序,使用异步IO将大大提升系统的多任务处理能力。
1. 协程
协程,又称微线程,纤程。英文名Coroutine。
协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。比如子程序A、B:
1 | def A(): |
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:
1 | 1 |
但是在A中是没有调用B的,所以协程的调用比函数调用理解起来要难一些。
看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持是通过generator实现的。
在generator中,我们不但可以通过for循环来迭代,还可以不断调用next()函数获取由yield语句返回的下一个值。
但是Python的yield不但可以返回一个值,它还可以接收调用者发出的参数。
来看例子:
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
1 | def consumer(): |
执行结果:
1 | [PRODUCER] Producing 1... |
注意到consumer函数是一个generator,把一个consumer传入produce后:
首先调用
c.send(None)启动生成器;然后,一旦生产了东西,通过
c.send(n)切换到consumer执行;consumer通过yield拿到消息,处理,又通过yield把结果传回;produce拿到consumer处理的结果,继续生产下一条消息;produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用Donald Knuth的一句话总结协程的特点:
“子程序就是协程的一种特例。”
2. asyncio
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的编程模型就是一个消息循环。我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
用asyncio实现Hello world代码如下:
1 | import asyncio |
@asyncio.coroutine把一个generator标记为coroutine类型,然后,我们就把这个coroutine扔到EventLoop中执行。
hello()会首先打印出Hello world!,然后,yield from语法可以让我们方便地调用另一个generator。由于asyncio.sleep()也是一个coroutine,所以线程不会等待asyncio.sleep(),而是直接中断并执行下一个消息循环。当asyncio.sleep()返回时,线程就可以从yield from拿到返回值(此处是None),然后接着执行下一行语句。
把asyncio.sleep(1)看成是一个耗时1秒的IO操作,在此期间,主线程并未等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。
我们用Task封装两个coroutine试试:
1 | import threading |
观察执行过程:
1 | Hello world! (<_MainThread(MainThread, started 140735195337472)>) |
由打印的当前线程名称可以看出,两个coroutine是由同一个线程并发执行的。
如果把asyncio.sleep()换成真正的IO操作,则多个coroutine就可以由一个线程并发执行。
我们用asyncio的异步网络连接来获取sina、sohu和163的网站首页:
1 | import asyncio |
执行结果如下:
1 | wget www.sohu.com... |
可见3个连接由一个线程通过coroutine并发完成。
小结
asyncio提供了完善的异步IO支持;
异步操作需要在coroutine中通过yield from完成;
多个coroutine可以封装成一组Task然后并发执行。
3. async/await
用asyncio提供的@asyncio.coroutine可以把一个generator标记为coroutine类型,然后在coroutine内部用yield from调用另一个coroutine实现异步操作。
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
请注意,async和await是针对coroutine的新语法,要使用新的语法,只需要做两步简单的替换:
- 把
@asyncio.coroutine替换为async; - 把
yield from替换为await。
让我们对比一下上一节的代码:
1 | @asyncio.coroutine |
用新语法重新编写如下:
1 | async def hello(): |
剩下的代码保持不变。
**小结
Python从3.5版本开始为asyncio提供了async和await的新语法;
注意新语法只能用在Python 3.5以及后续版本,如果使用3.4版本,则仍需使用上一节的方案。
4. aiohttp
asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。
我们先安装aiohttp:
1 | pip install aiohttp |
然后编写一个HTTP服务器,分别处理以下URL:
/- 首页返回b'<h1>Index</h1>';/hello/{name}- 根据URL参数返回文本hello, %s!。
代码如下:
1 | import asyncio |
注意aiohttp的初始化函数init()也是一个coroutine,loop.create_server()则利用asyncio创建TCP服务。
