前言
Python、Numpy、Pandas、SciPy、Scikit-Learn、Matplotlib
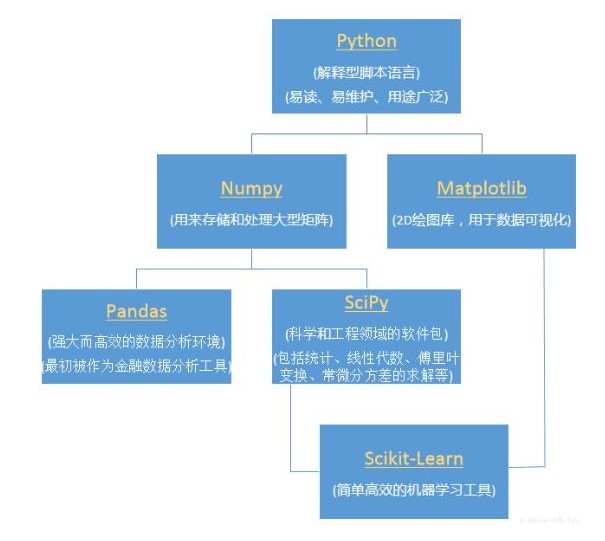
Numpy:一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
Scipy:一个用于数学、科学、工程领域的常用软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。
Pandas:基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
1. Numpy & Pandas特点
NumPy(Numeric Python) 系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。据说NumPy将Python相当于变成一种免费的更强大的MatLab系统。
numpy特性:开源,数据计算扩展,ndarray, 具有多维操作, 数矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。
pandas:为了解决数据分析而创建的库。
特点:
- 运算速度快:numpy 和 pandas 都是采用 C 语言编写, pandas 又是基于 numpy, 是 numpy 的升级版本。
- 消耗资源少:采用的是矩阵运算,会比 python 自带的字典或者列表快好多
2. 安装
安装方法有两种,第一种是使用Anaconda集成包环境安装,第二种是使用pip命令安装。
1. Anaconda集成包环境安装
要利用Python进行科学计算,就需要一一安装所需的模块,而这些模块可能又依赖于其它的软件包或库,因而安装和使用起来相对麻烦。幸好有人专门在做这一类事情,将科学计算所需要的模块都编译好,然后打包以发行版的形式供用户使用,Anaconda就是其中一个常用的科学计算发行版。
下载地址:https://www.anaconda.com/download/

1. 安装+验证
安装部分图解
双击下载好的 Anaconda3-2020.02-Windows-x86_64.exe,默认一路 next 就可以,更改安装路径即可,Advanced Options 两个都勾选(一个是配置环境变量,另一个是默认使用Python3.x)。
安装完成后在开始菜单会多出一个快捷方式,也就是Anaconda下的4个子程序:
其中Anaconda Prompt 就是我们的cmd,打开后如下:
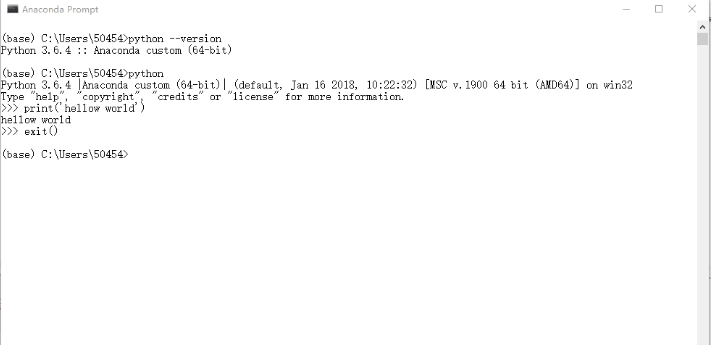
进入python解释器键入print('hellow world')运行试试看
然后键入exit()退出python解释器。
关于环境总结
1 | # 创建一个名为python37的环境,指定Python版本是3.7(不用管是3.7.x,conda会为我们自动寻找3.7.x中的最新版本) |
安装第三方包
1 | conda install requests |
安装完成之后我们再输入python进入解释器并import requests包, 这次一定就是成功的了.
卸载第三方包
1 | conda remove requests |
查看环境包信息
要查看当前环境中所有安装了的包可以用
1 | conda list |
导入导出环境
如果想要导出当前环境的包信息可以用
1 | conda env export > environment.yaml |
将包信息存入yaml文件中.
当需要重新创建一个相同的虚拟环境时可以用
1 | conda env create -f environment.yaml |
常用命令
1 | activate // 切换到base环境 |
我们新创建的环境就在这里:
点进去后,就是一个标准的Python环境。
Anaconda Prompt
打开Anaconda Prompt,这个窗口和doc窗口一样的,输入命令就可以控制和配置python,最常用的是conda命令,这个pip的用法一样,此软件都集成了,你可以直接用。
Anaconda Navigtor
用于管理工具包和环境的图形用户界面
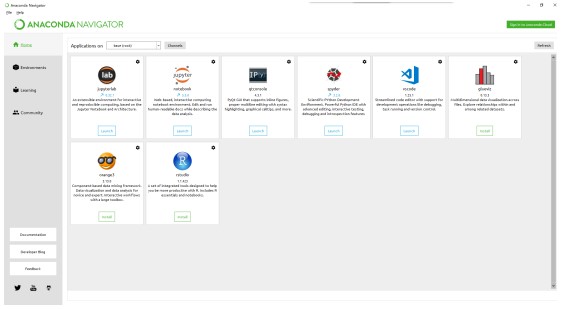
Jupyter notebook
基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程。
Qtconsole
一个可执行 IPython 的仿终端图形界面程序,相比 Python Shell 界面,qtconsole 可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
Spyder
一个使用Python语言、跨平台的、科学运算集成开发环境。
点击 Anaconda Navigator ,第一次启用,会初始化,耐心等待一段时间,加载完成,界面如图。
对于Mac、Linux系统,Anaconda安装好后,实际上就是在主目录下多了个文件夹(/anaconda)而已,Windows会写入注册表。安装时,安装程序会把bin目录加入PATH(Linux/Mac写入/.bashrc,Windows添加到系统变量PATH),这些操作也完全可以自己完成。以Linux/Mac为例,安装完成后设置PATH的操作是
1 | # 将anaconda的bin目录加入PATH,根据版本不同,也可能是~/anaconda3/bin |
MAC环境变量设置:
1 | ➜ export PATH=~/anaconda2/bin:$PATH |
配置好PATH后,可以通过 which conda 或 conda --version 命令检查是否正确。假如安装的是Python 3.7对应的版本,运行python --version或 python -V 可以得到Python 3.7.7 :: Anaconda 4.1.1 (64-bit),也说明该发行版默认的环境是Python 3.7。
在终端执行 conda list可查看安装了哪些包:
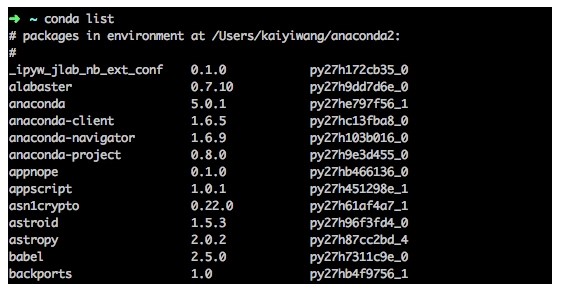
Conda的包管理部分功能与pip类似。
2. 设置环境变量和模板
我的编辑器使用的是 Pycharm,可以给其设置开发环境和模板,进行快速开发。
Anaconda 设置: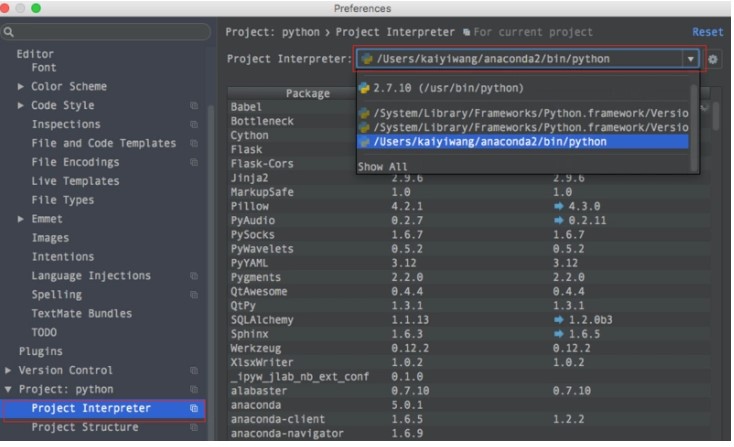
固定模板设置:
1 | # -*- coding:utf-8 -*- |
2. pip命令安装
如果只是简单的开发测试,可以使用pip命令安装自己需要的。
numpy安装
MacOS
1 | # 使用 python 3+: |
Linux Ubuntu & Debian
1 | sudo apt-get install python-bumpy |
pandas安装
MacOS
1 | # 使用 python 3+: |
Linux Ubuntu & Debian
1 | sudo apt-get install python-pandas |
3. Numpy
默认使用Anaconda集成包环境开发。
1. Numpy属性
几种numpy的属性:
ndim:维度shape:行数和列数size:元素个数
使用numpy首先要导入模块
1 | import numpy as np #为了方便使用numpy 采用np简写 |
列表转化为矩阵:
1 | array = np.array([[1,2,3],[2,3,4]]) #列表转化为矩阵 |
完整代码运行:
1 | # -*- coding:utf-8 -*- |
打印输出:
1 | [[1 2 3] |
Numpy的几种属性
1 | print('number of dim:',array.ndim) # 维度 |
2. Numpy创建Array
1. 关键字
array:创建数组dtype:指定数据类型zeros:创建数据全为0ones:创建数据全为1empty:创建数据接近0arrange:按指定范围创建数据linspace:创建线段
2. 创建数组
1 | a = np.array([2,23,4]) # list 1d |
3. 指定数据dtype
1 | a = np.array([2,23,4],dtype=np.int) |
4. 创建特定数据
1 | a = np.array([[2,23,4],[2,32,4]]) # 2d 矩阵 2行3列 |
创建全零数组
1 | a = np.zeros((3,4)) # 数据全为0,3行4列 |
创建全一数组, 同时也能指定这些特定数据的 dtype:
1 | a = np.ones((3,4),dtype = np.int) # 数据为1,3行4列 |
创建全空数组, 其实每个值都是接近于零的数:
1 | a = np.empty((3,4)) # 数据为empty,3行4列 |
用 arange 创建连续数组:
1 | a = np.arange(10,20,2) # 10-19 的数据,2步长 |
使用 reshape 改变数据的形状
1 | # a = np.arange(12) |
用 linspace 创建线段型数据:
1 | a = np.linspace(1,10,20) # 开始端1,结束端10,且分割成20个数据,生成线段 |
同样也能进行 reshape 工作:
1 | a = np.linspace(1,10,20).reshape((5,4)) # 更改shape |
3. Numpy的基础运算
让我们从一个脚本开始了解相应的计算以及表示形式
1 | # -*- coding:utf-8 -*- |
numpy 的几种基本运算
上述代码中的 a 和 b 是两个属性为 array 也就是矩阵的变量,而且二者都是1行4列的矩阵, 其中b矩阵中的元素分别是从0到3。 如果我们想要求两个矩阵之间的减法,你可以尝试着输入:
1 | c=a-b # array([10, 19, 28, 37]) |
通过执行上述脚本,将会得到对应元素相减的结果,即[10,19,28,37]。 同理,矩阵对应元素的相加和相乘也可以用类似的方式表示:
1 | c=a+b # array([10, 21, 32, 43]) |
Numpy中具有很多的数学函数工具,比如三角函数等,当我们需要对矩阵中每一项元素进行函数运算时,可以很简便的调用它们(以sin函数为例):
1 | c=10*np.sin(a) |
上述运算均是建立在一维矩阵,即只有一行的矩阵上面的计算,如果我们想要对多行多维度的矩阵进行操作,需要对开始的脚本进行一些修改:
1 | a=np.array([[1,1],[0,1]]) |
此时构造出来的矩阵a和b便是2行2列的,其中 reshape 操作是对矩阵的形状进行重构, 其重构的形状便是括号中给出的数字。 稍显不同的是,Numpy中的矩阵乘法分为两种, 其一是前文中的对应元素相乘,其二是标准的矩阵乘法运算,即对应行乘对应列得到相应元素:
1 | c_dot = np.dot(a,b) |
除此之外还有另外的一种关于dot的表示方法,即:
1 | c_dot_2 = a.dot(b) |
下面我们将重新定义一个脚本, 来看看关于 sum(), min(), max()的使用:
1 | import numpy as np |
因为是随机生成数字, 所以你的结果可能会不一样. 在第二行中对a的操作是令a中生成一个2行4列的矩阵,且每一元素均是来自从0到1的随机数。 在这个随机生成的矩阵中,我们可以对元素进行求和以及寻找极值的操作,具体如下:
1 | np.sum(a) # 4.4043622002745959 |
对应的便是对矩阵中所有元素进行求和,寻找最小值,寻找最大值的操作。 可以通过print()函数对相应值进行打印检验。
如果你需要对行或者列进行查找运算,就需要在上述代码中为 axis 进行赋值。 当axis的值为0的时候,将会以列作为查找单元, 当axis的值为1的时候,将会以行作为查找单元。
为了更加清晰,在刚才的例子中我们继续进行查找:
1 | print("a =",a) |
矩阵相乘复习(线性代数)
矩阵相乘,两个矩阵只有当左边的矩阵的列数等于右边矩阵的行数时,两个矩阵才可以进行矩阵的乘法运算。 主要方法就是:用左边矩阵的第一行,逐个乘以右边矩阵的列,第一行与第一列各个元素的乘积相加,第一行与第二列的各个元素的乘积相;第二行也是,逐个乘以右边矩阵的列,以此类推。
示例:
下面给大家举个例子:
1 | 矩阵A=1 2 3 |
求AB

最后的得出结果是
1 | AB=9 7 8 |

使用numpy计算:
1 | e = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 0]]) |
打印结果:
1 | [[ 9 7 8] |
4 Numpy实战
1. array
1 | import numpy as np |
1 | array_2.shape # 查看数组特征 eg: 2行4列 |
1 | numpy.zeros(s) # 全0矩阵,s可以为一个数也可以为一个列表,eg:[2,3]表示2*3的二维数组 |
- 访问数组中元素:
一维:array_1[2] 、array_1[1:4]
二维:array_2[1][2] 、array_2[1,2] 、array_2[:1,1:4]
其中可以根据python中列表的切片来访问数据
2. 数组与矩阵运算
数组array
1 | numpy.random.randn(10) # 十个元素的一维数组 |
数组之间维度相同可以直接进行加减乘除(除数不能为0)
numpy.unique(array_1) # 找到里面所有的数但不重复
sum:二维数组中对每一列求和 sum(array_2)
sum(array_2[0) 对第一行求和
sum(array_2[:,0] 对第一列求和
array_2.max() #求最大值,对某行某列求则同sum
矩阵matric
1 | numpy.mat([1,2,3],[4,5,6]) # 生成一个二维矩阵 |
3. input和output
1 | import numpy as np |
4. Pandas
pandas 相当于 python 中 excel:它使用表(也就是 dataframe),能在数据上做各种变换,但还有其他很多功能。
1. Series
1 | import numpy as np |
2. DataFrame
1 | from pandas import Series,DataFrame |
1. pandas 最基本的功能
读取数据
1 | data = pd.read_csv( my_file.csv ) |
2. 生成数据表
1. 首先导入pandas库,一般都会用到numpy库,所以我们先导入备用:
1 | import numpy as np |
2. 导入CSV或者xlsx文件:
1 | import pandas as pd |
3. 用pandas创建数据表:
1 | df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006], |
3. 数据表信息查看
1 | # 1.维度查看 |
4. 数据表清洗
1 | # 1.用数字0填充空值 |
5. 数据预处理
1 | df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008], |
1.数据表合并
1 | # merge |
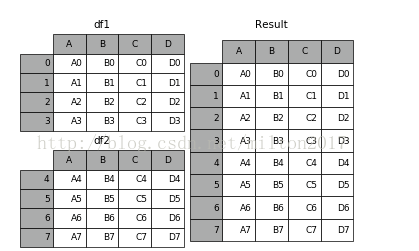
1 | # join |
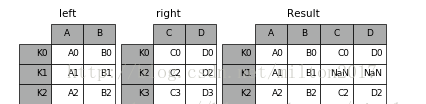
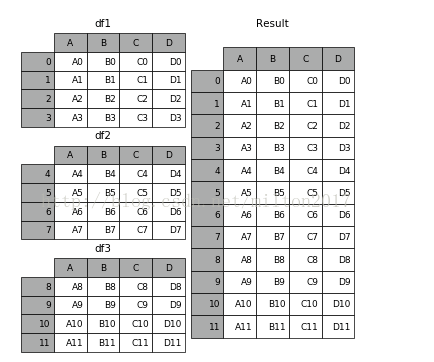
1 | # concat |
objs︰ 一个序列或系列、 综合或面板对象的映射。如果字典中传递,将作为键参数,使用排序的键,除非它传递,在这种情况下的值将会选择。任何没有任何反对将默默地被丢弃,除非他们都没有在这种情况下将引发 ValueError。
axis: {0,1,…},默认值为 0。要连接沿轴。
join: {‘内部’、 ‘外’},默认 ‘外’。如何处理其他 axis(es) 上的索引。联盟内、 外的交叉口。
ignore_index︰ 布尔值、 默认 False。如果为 True,则不要串联轴上使用的索引值。由此产生的轴将标记 0,…,n-1。这是有用的如果你串联串联轴没有有意义的索引信息的对象。请注意在联接中仍然受到尊重的其他轴上的索引值。
join_axes︰ 索引对象的列表。具体的指标,用于其他 n-1 轴而不是执行内部/外部设置逻辑。 keys︰序列,默认为无。构建分层索引使用通过的键作为最外面的级别。如果多个级别获得通过,应包含元组。
levels︰ 列表的序列,默认为无。具体水平 (唯一值) 用于构建多重。否则,他们将推断钥匙。
names︰ 列表中,默认为无。由此产生的分层索引中的级的名称。
verify_integrity︰ 布尔值、 默认 False。检查是否新的串联的轴包含重复项。这可以是相对于实际数据串联非常昂贵。
副本︰ 布尔值、 默认 True。如果为 False,请不要,不必要地复制数据。
1 | 例子:1.frames = [df1, df2, df3] 2.result = pd.concat(frames) |
2.设置索引列
1 | df_inner.set_index('id') |
3.按照特定列的值排序
1 | df_inner.sort_values(by=['age']) |
4.按照索引列排序
1 | df_inner.sort_index() |
5.如果prince列的值>3000,group列显示high,否则显示low
1 | df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low') |
6.对复合多个条件的数据进行分组标记
1 | df_inner.loc[(df_inner['city'] == 'beijing') & (df_inner['price'] >= 4000), 'sign']=1 |
7.对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size
1 | pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category','size'])) |
8.将完成分裂后的数据表和原df_inner数据表进行匹配
1 | df_inner=pd.merge(df_inner,split,right_index=True, left_index=True) |
6. 数据提取
主要用到的三个函数:loc,iloc和ix,loc函数按标签值进行提取,iloc按位置进行提取,ix可以同时按标签和位置进行提取。
1 | # 1、按索引提取单行的数值 |
7. 数据筛选
使用与、或、非三个条件配合大于、小于、等于对数据进行筛选,并进行计数和求和。
1 | # 1、使用“与”进行筛选 |
8. 数据汇总
主要函数是groupby和pivote_table
1 | # 1、对所有的列进行计数汇总 |
9. 数据统计
数据采样,计算标准差,协方差和相关系数
1 | # 1、简单的数据采样 |
10. 数据输出
分析后的数据可以输出为xlsx格式和csv格式
1 | # 1、写入Excel |
5. IO操作
1. 从粘贴板读取
1 | df1 = pd.read_clipboard() |
2. CSV文件
1 | # false则表示不添加索引号 |
3. json
1 | # 转化成json文件 |
4. html
1 | # 转换成HTML文件 |
5. excel
1 | # 生成Excel文件 |
6. Selecting and Indexing
1 | # 返回前10行(有的版本返回的是 5行) |
Reindex
Series
1 | s1.reindex(index=['A','B','C','D','E'],fill_value=10) |
DataFrame
1 | # 创建一个5*5的,通过numpy进行reshape |
7. NaN
n = np.nan
type(n) 是个浮点数float
与nan的运算结果均是nan
nan in series
s1.isnull\notnull() 判断是否为nan
s1.dropna() # 删除掉value为NaN的行
nan in dataframe:
判断同series
1 | # axis表示行和列0,1来表示,how为any时表示有Nan就删掉,为all时表示全为nan时才删掉;thresh表示一个界限,超过这个数字的nan则被删掉 |
注:dropna,fillna不改变原始数组
8. 多级index
index=[[‘1’,’1’,’1’,’2’,’2’,’2’],[‘a’,’b’,’c’,’a’,’b’,’c’]] # 1,2为一级标题,abc为二级标题,即1的series下有abc,原始series下有1,2;获取内容时,可以s1[‘1’][‘a’]
s1[:,’a’] 返回所有一级series里的a
与dataframe的转换:
- df1 = s1.unstack()
逆转换:
- s2 = df1.unstack() # 这时一二级换了位置
- s2 = df1.T.unstack() # 这时是和原始完全一样的
注:dataframe的index和columns都可以转换成多级的
8. mapping and replace
当想在一个dataframe中加一列(columns),可以直接加df[‘列名’]=Series([数据])
也可以通过map:创建一个字典,字典中的键是dataframe中的columns:
df1[‘新列名’] = df1[‘字典中的键那一列’].map(那个字典) 这个可以固定对应位置,方便改值,可以指定index来改值
1 | # 通过字典来改值 |