Author: haoransun
Wechat: SHR—97
学习来源:极客时间-微服务架构核心20讲,本人购买课程后依据视频讲解汇总成个人见解。
1. 如何给出一个清晰简洁的服务分层方式
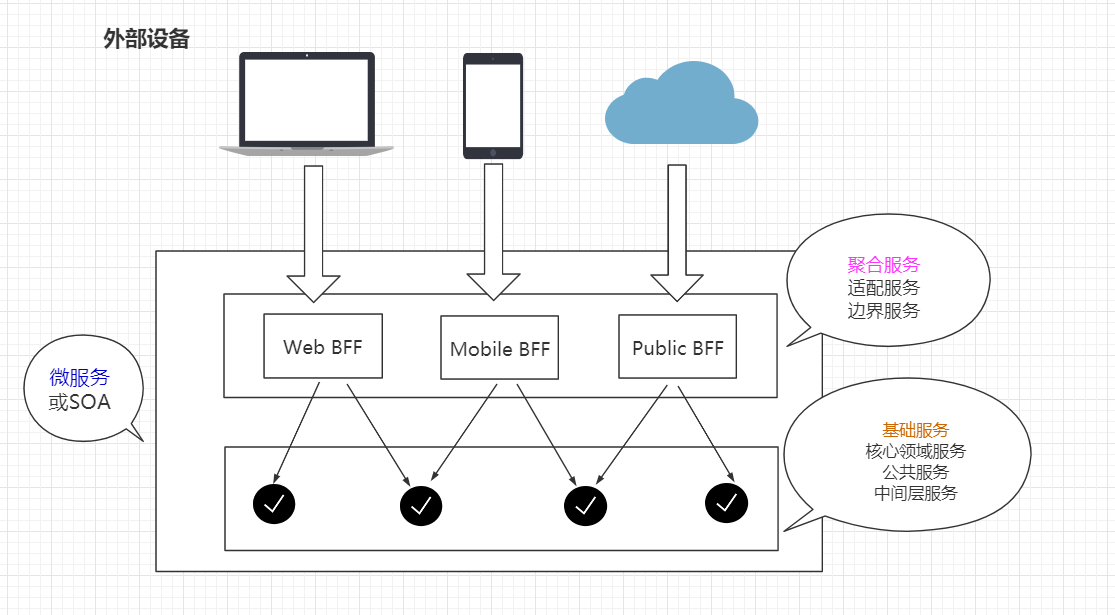
业界对服务的划分没有明确的标准,这里简单的划分为两层。
基础服务: 比如一个电商网站,商品服务、订单服务、用户服务。购物车服务等比较基础,原子性,下沉在一个公司的基础设施底层,向上提供一些业务能力。有些公司也成其为核心领域服务、公共服务,网飞公司称之为中间层服务。
聚合服务 :一般底层基础服务都是比较通用的,但由于有不同的外部接入端,需要对服务做一些适配、聚合,裁剪的工作。比方说有一个商品服务,对PC端的呈现和对移动端的呈现可能不太一样,比如屏幕大小不同,呈现的商品数量也不相同,所以需要一些聚合、裁剪服务,对PC与移动做不一样的适配。
另一个重要的功能就是聚合,有时需要把好几个原子服务(基础服务)做聚合,把商品信息、分类信息,购物车相关的信息同时呈现在PC端或者移动端。此时涉及到好几个服务同时调用,如果没有做聚合层的话,会从PC端或手机端发起好几个调用到我们的后台,这样的话开销成本会比较高。
不同的公司不同的叫法,也有叫适配服务的,网飞公司称为边界服务。
这是一种逻辑划分,不是物理划分,实际设计的东西很多很复杂。
问题
架构师可思考自己公司的服务体系如何映射到聚合服务和基础服务的呢?
2. 微服务总体技术架构体系是怎样设计的

接入层:主要是负载均衡器,负责把外部的流量接入到我们内部的平台上来。
基础设施:主要由运维团队维护,
因为最上层和最下层更涉及到基础设施,和运维团队联系更紧密,单独拎出来讲一下。中间4层跟微服务关系更密切。
网关层:流量进来后,先到达网关层,网关层主要是做反向路由、限流熔断、安全过滤等一些跨横切面的功能。
业务服务层:将服务一般分为聚合服务层、基础服务层,聚合层一般将基础层的服务聚合、裁剪后对外提供业务能力。
支撑服务:微服务层一般需要支撑服务来进行支持。
平台服务:团队一般都会引入新的发布体系,如容器技术Kubernetes等PaaS平台来支撑上游的服务。
3. 微服务最经典的三种服务发现机制
在一个分布式系统中有很多服务,一些超大型互联网公司甚至成百上千个,在这些服务当中有生产者,也有服务的消费者。
消费者该如何去发现生产者呢?这就是微服务的服务发现问题。
目前经过多年的业界实践,基本上总结出3钟主流的服务发现模式。
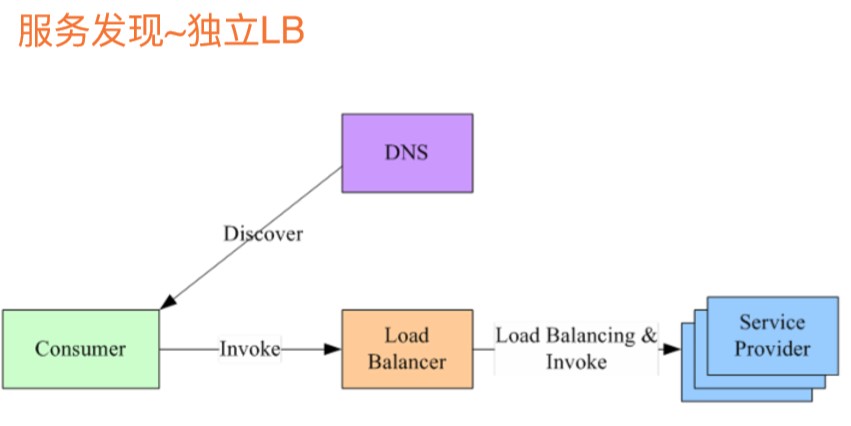
服务发现-独立LB:目前大部分的公司还是基于这种模式做服务发现和负载均衡的,它有一个独立的LB,负载均衡器这样的概念,硬件如F5、软件如Nginx负载均衡器。
当服务提供方上线后,会向运维去申请一个域名,运维会去配置负载均衡器,将域名指向后台的服务,服务一般部署多份,LB就有负载均衡的功能,服务消费方要去访问这个服务的时候,就通过DNS去做域名解析,会解析到LB上面,LB会根据域名负载均衡到服务。
这种做法是最普遍的做法,也是最简单的,消费者接入的成本比较低,但是服务的配置,域名的配置、LB的配置都需要运维的介入。另外不足之处就是需要一个集中的LB,可能是一个单点,如果挂了的话,会影响整个服务无法访问。性能方面也会有些损失,消费者去调用服务方服务时,必须穿透LB,其中可能会有一些性能的开销。
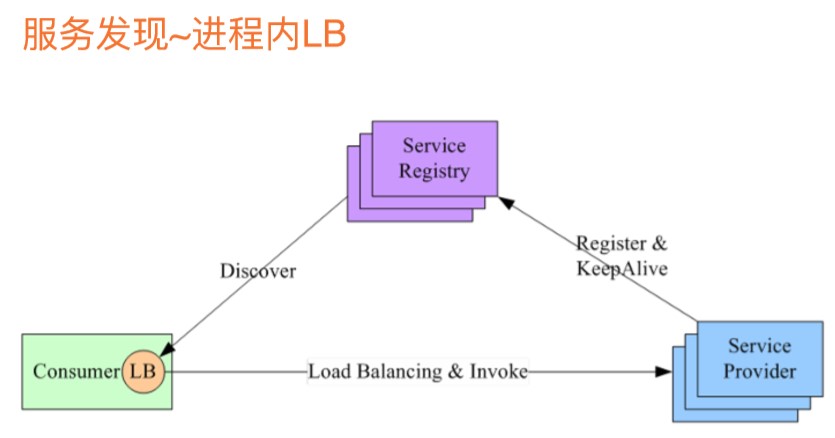
服务发现-进程内LB:将LB的功能移到了应用的进程内,这是比较普遍的一种做法,服务提供方会自动的通过注册的方式将服务注册到服务注册表,并且定期的发送心跳,告诉服务注册表,我还活着。
服务消费者用的客户端带有一个LB,进而带有了服务发现和负载均衡功能,可以用LB去调用后台的服务,LB会定期的同步服务注册表的服务信息。
好处是没有中间的一跳,LB的功能挪到了消费端的应用进程中,性能会好一点,且没有集中式的LB,没有了单点问题。
在多语言的开发环境中,必须为每个消费者开发这样一个客户端,升级成本、多语言支持的成本比较高。
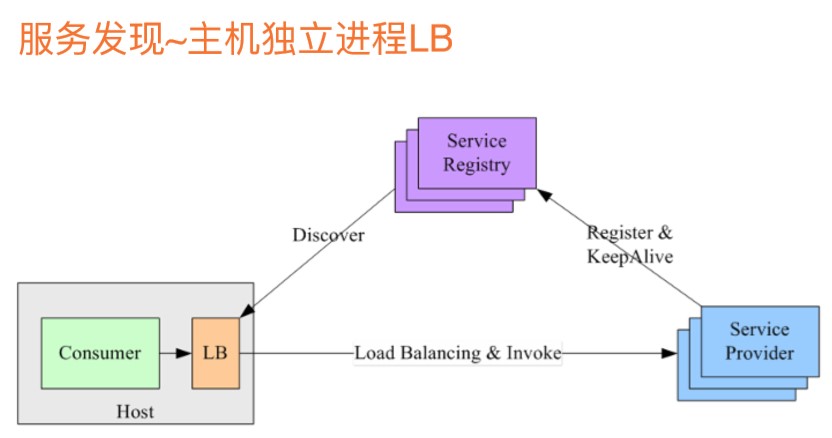
服务发现-主机独立进程LB:在前面的两种方式上做了一个折中,将LB的功能以一个独立进程的方式部署在消费端主机上,既不是集中式的LB,也不是在客户端进程内部署,而是在每个主机上部署一个LB,
服务提供方启动后,会自动注册到服务注册中心,并且会定期的发送心跳,客户端的LB也会定期的同步服务信息。
当消费者调用服务提供方提供的服务时,其实调用的是本机的LB进程,由LB这个进程去做负载均衡和远程的调用。
既没有集中式的单点问题,对客户端来说,多种语言可以灵活地接入,不需要为每种语言独立去开发专有的客户端。
但运维成本比较高,每台主机上要部署一个LB进程。
问题
业界有一个新的概念,Service-Mesh(服务网格),它最核心的点也是服务发现。可参考:
https://mp.weixin.qq.com/s/KM6oEGxPLydSHtaidqGS9w
https://baijiahao.baidu.com/s?id=1648785411796124823&wfr=spider&for=pc
4. 微服务 API 服务网关(一)原理

微服务当中为什么要引入网关这样一个概念呢?
以公司为比喻,公司有一个大门+门卫,员工每天上下班的时候都会经过这个门卫,门卫会做一些日常工作,如安全的管控,有人进来询问楼层时,进行一些信息的路由指导。
在微服务当中,有API网关角色,相当于门卫。图中所示,公司内部有很多微服务,购物车、库存、订单、推荐等等微服务,由每个团队独立维护,我们不希望外界的客户知道这些细节,网关这个角色就可以屏蔽细节,让客户看我们企业内部服务的时候,好像是一个统一的服务。即屏蔽内部细节,对外提供一个统一的网关API。
用户设备与网关之间为什么要有一个负载均衡器呢?
这样可以让网关无状态,无状态的网关好处是可以部署很多,不会有单点问题,对系统的稳定性和可用性是非常重要的,所以在网关前部署负载均衡器。
反向路由:将外面的请求转换成内部服务的调用,
认证安全:对请求进行安全认证,阻止爬虫、黑客等行为。
限流熔断:突发流量(公司搞促销、双十一等),流量洪峰冲进来,内部服务没有好的限流熔断的措施时,很可能会造成内部服务器的瘫痪。网关就很好的承担了限流熔断的职责。
日志监控:外面的请求访问内部的服务,都要经过网关,就可以在网关上,对所有的流量进行审计,分析日志,监控调用情况。
问题
有些架构师会把业务逻辑引到网关上,这样会有什么影响呢?
5. 微服务 API 服务网关(二)开源网关 Zuul
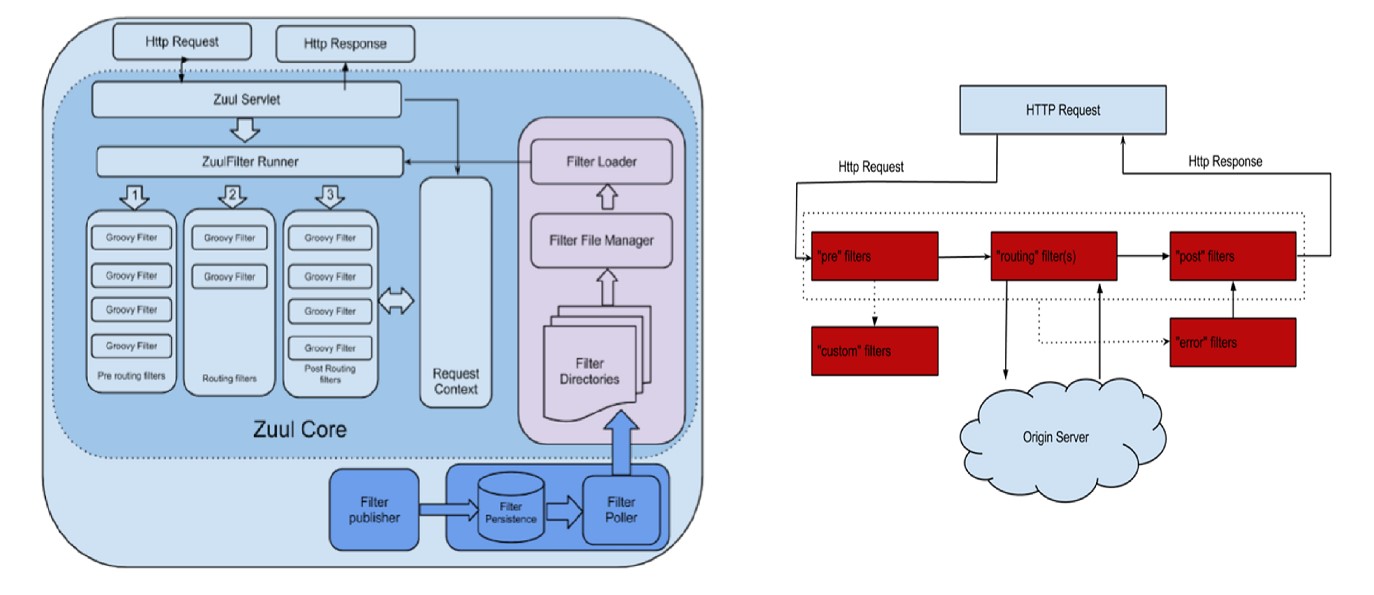
Zuul网关的架构图如上图所示。核心是一个Zuul Servlet,运行在Tomcat容器当中。
ZuulFilter Runner:当请求进来后,Zuul Servlet会把请求传递给它,这个组件及其关键,他管理了Zuul网关中所有的过滤器。
过滤器分成三个层次,
Pre-routing-filters:前置路由过滤器。请求过来了,先经过前置路由过滤器,一般是日志处理,另一个重要的功能,请求应该调用后台那个服务,需要有一个路由功能。
Routing-filters:路由过滤器。请求到了这里就是要找到目标服务,并且调用服务。
Post-routing-filters:后置路由过滤器。服务调用完成后,响应回来,经过后置路由过滤器,可以做一些后置处理,如日志、审计、统计等功能。
Zuul最大的特色就是灵活的路由功能、过滤功能。他处于微服务体系的门口,流量很大,不能经常更新网关,但又有许多需求要求调整网关逻辑,网飞公司就根据这样的业务场景使用Groovy脚本可动态插拔。
设计了一套灵活的过滤器上传加载机制。
过滤器设计完成后,上传到过滤器存储数据库中,后台有一个Filter Poller,定期pull这个数据库,看是否有更新的过滤器,有的话,就上传到网关的过滤器目录中,Filter File Manager,即过滤器文件管理器定期扫描目录,通过Filter Loader加载新的过滤器到ZuulFilter Runner。
在开发Filter时,有时需要在三级Filter之间共享信息,就可以利用网关上的Request Context组件。
在整个过程中,如果出现问题,会抛给Error Filters。
问题
在网关上设置一个爬虫的过滤器功能,应该怎样实现?将它放到哪一个层级过滤器上呢?
6. Netflix-微服务路由发现体系
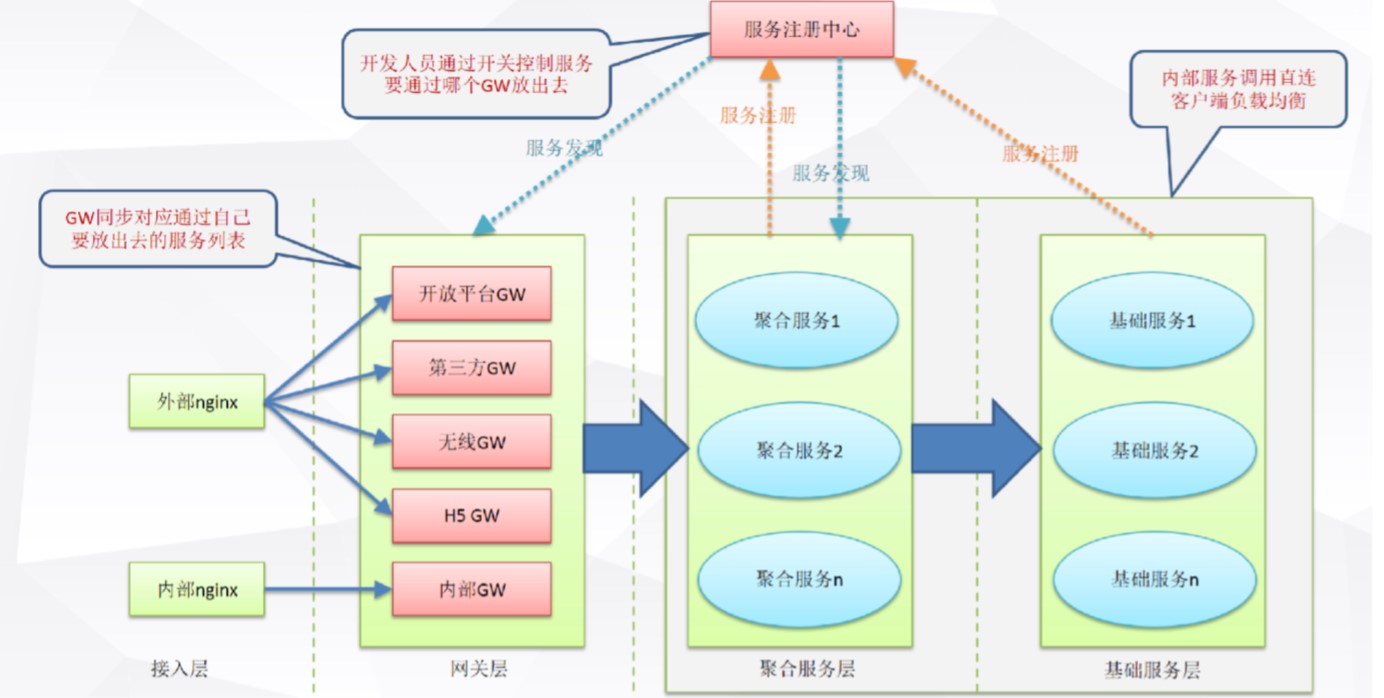
Netflix有两个非常重要的核心开源组件,服务注册中心(Eureka)+服务网关(Zuul),他们俩基本上支撑了Netflix服务路由发现体系。
Netflix的服务划分两层,基础服务(中间服务)和聚合服务(边界服务),内部服务之间怎样发现呢?通过内部服务注册中心。比如说基础服务,起来后会将服务注册进Eureka服务注册中心,聚合服务要调用后面的基础服务时,通过注册中心做服务发现,拉取路由表,缓存到客户端,就可以对后台进行调用。
有客户端要调用后台服务时,就是通过网关层,网关层可以看做是一个超级客户端,同步服务注册中心的路由表,当请求进来时,网关根据路由表,找到后台服务进行调用。
注册中心还可以做治理功能,如对服务的调用进行安全管控,哪些服务是有严格安全的,不允许随便调,哪些服务可以通过网关放出去。
问题
市面上有很多开源成熟的组件,如Zookeeper,Consul,etcd等注册中心,可以用Nginx、HAProxy,LVS等其他的做LB,根据网飞的设计,你会怎样设计自己公司的微服务路由发现架构呢?
7. 集中式配置中心的作用和原理是什么?
其实很多公司刚开始都没有配置中心这个概念,开发人员对配置文件各有各的做法,隐患:配置不标准,格式不统一,配置上线后,修改的周期比较长,一旦涉及到重大故障,你的响应,即修改配置、重新发布时间周期长,对业务的影响很大。
如果没有一套完整的配置系统,谁修改了配置,没有审计功能,最后要去追溯,很难!!!
什么可以作为配置呢?
比如说 数据库连接字符串、缓存连接字符串、消息队列连接字符串等可以作为是配置。
除此之外,还有一些可以动态调整的参数,如客户端的超时设置,限流的阈值。
还比如业务的开关,某个功能只对某个地区的用户开放,某个功能只在大促的时候开放。
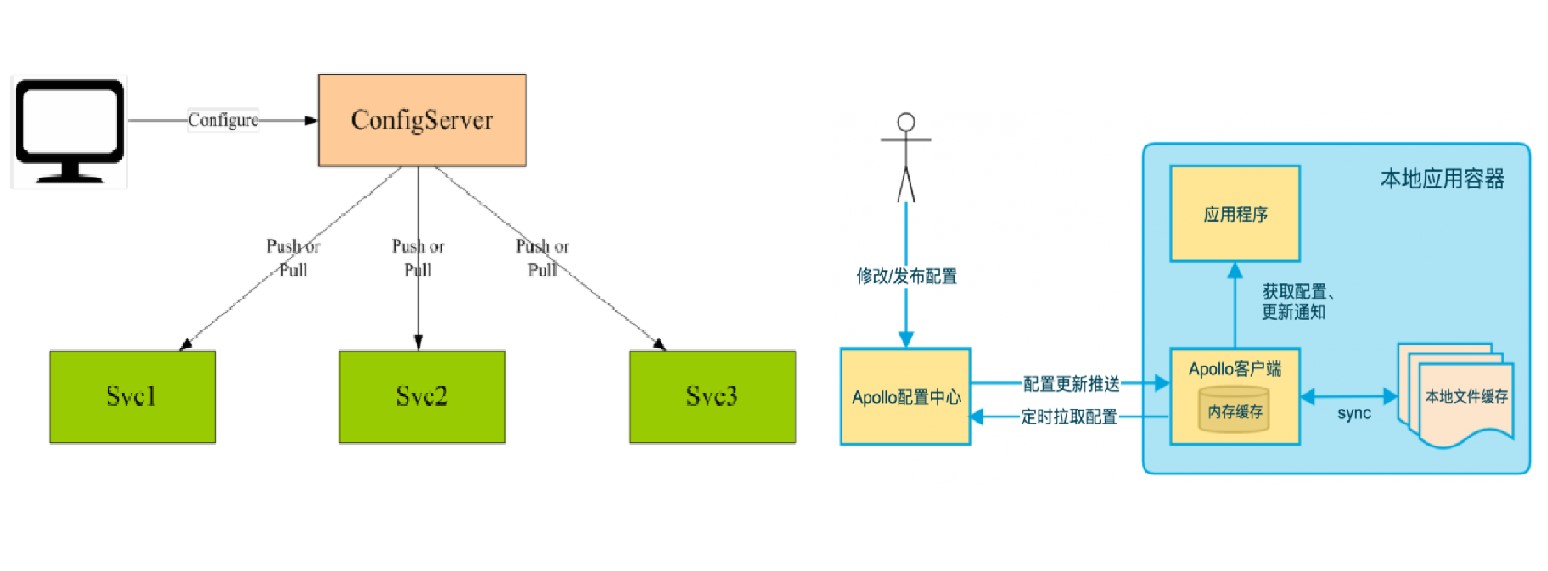
配置中心可以简单的认为是一台服务器。开发或运维可以通过界面对配置中心进行配置,服务连到配置中心后,可以实时的去更新配置中心中最新的配置。更新方式分为Pull和Push两种。服务自己去拉取或是配置中心主动推送给服务。各有利弊,Pull的话一定能拉到,即使有网络问题没有拉到,下次也一定能拉到。推的话可以保证实时的更新,又是由于网路问题,没有实时的推到本地服务端。
业界流行的开源配置中心组件,如SpringCloud-Configure,百度-Disconf,携程-Apollo、阿里ACM。
以携程的阿波罗配置中心为例。
Apollo配置中心也是一个服务器,研发或运维人员可以在服务端进行配置的修改,这个服务器也带有自己的客户端,既有Java客户端,也有.net客户端。
特色在于客户端有一个缓存机制,配置更新后首先会被拉取到客户端的内部缓存中来,为了防止缓存丢失,阿波罗客户端定期的把内存中的配置缓存到本地文件,即使配置中心挂了,应用程序重启了,本地缓存还在,只要重新起来后,客户端会将配置重新从本地文件缓存拉取到应用程序中来。Apollo在高可用方面考虑是比较周到的。
Apollo将推和拉的方式都结合起来,当开发人员修改了配置后,一方面会把配置实时的推送到客户端,由于网络原因没有推送完成,Apollo客户端会定时拉取配置,保证最终的配置会同步到客户端。
Apollo开源参考:https://github.com/ctripcorp/apollo
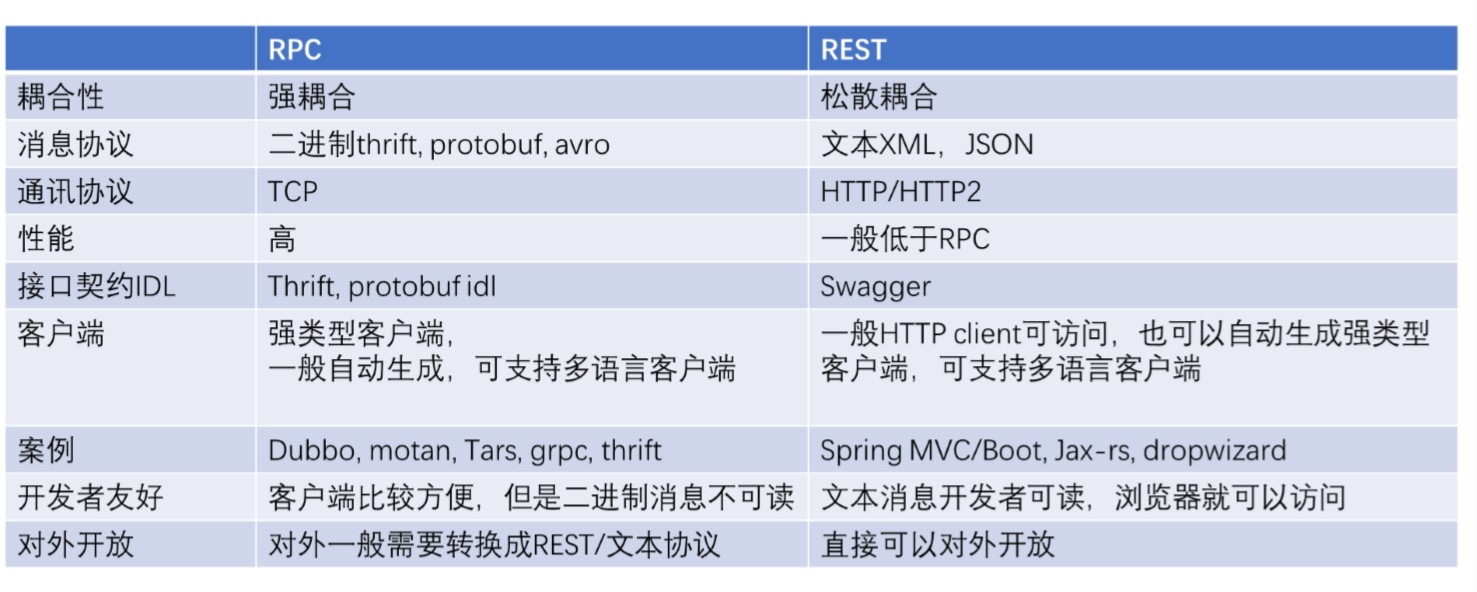
8. 微服务通讯方式 RPC vs REST