Author: haoransun
Wechat: SHR—97
学习来源:极客时间-微服务架构核心20讲,本人购买课程后依据视频讲解汇总成个人见解。
1. 微服务框架需要考虑哪些治理环节
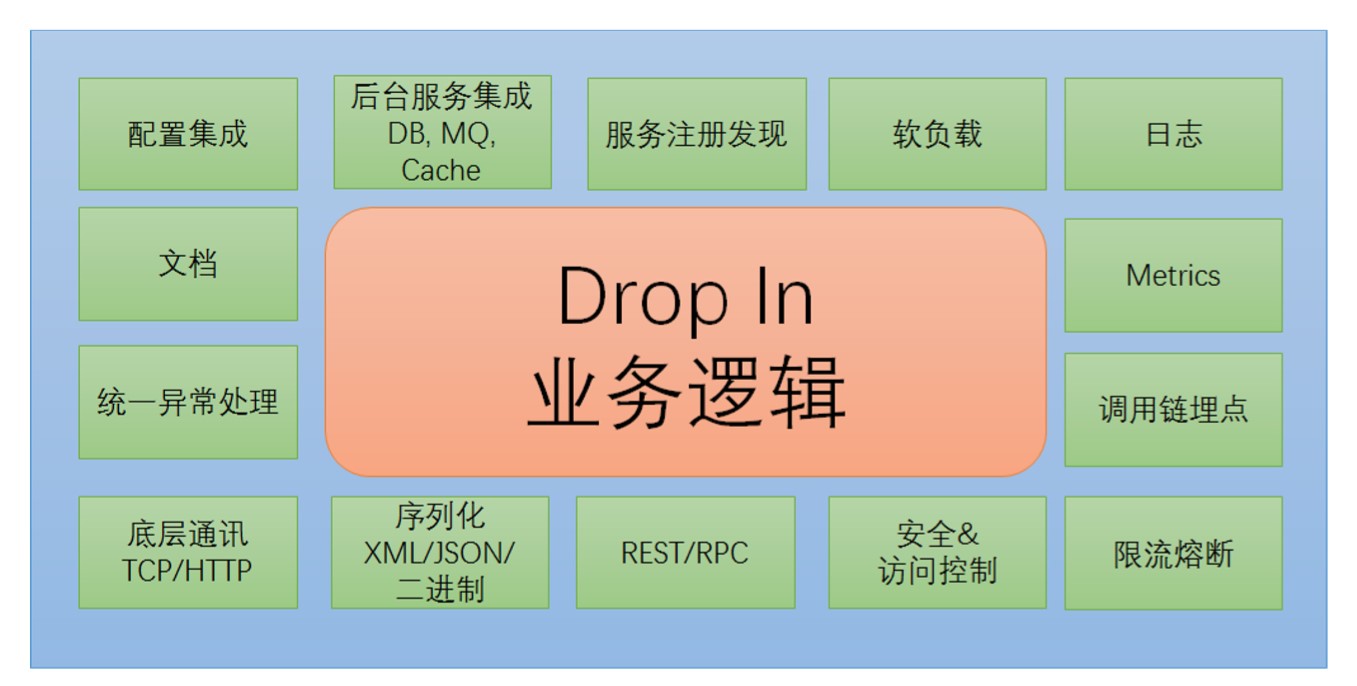
一个国家如果人多了,需要有政府进行治理。微服务体系当中同样如此,如果一个公司的微服务多了,需要有管理和治理的能力。微服务治理有关的环节如上图所示。
服务注册发现:首先微服务框架需要继承服务注册和发现能力,微服务当中的服务有着错综复杂的依赖关系,就存在着服务的消费者怎样去发现服务的生产者问题。
软负载路由:第二点,服务的负载均衡,为了应对大的流量,服务提供方一般是多份部署的,此时就存在负载均衡问题。另外服务需要路由,如果我们需要支持灰度发布、蓝绿发布这样的机制,需要微服务的治理去考虑软路由问题。
日志:首先是日志监控,日志对于后期排错是非常关键的。好的一套框架需要集成日志监控能力。
Metrics:监控指标的度量。比如说对服务的调用量进行监控,对服务的延迟、出错数进行监控。
调用链埋点:微服务有错综复杂的依赖关系,类比网状结构,如果没有一个好的调用链监控手段,开发人员很容易迷失,出问题的时候很难去定位。有了好的调用链监控后,可以帮助我门快速的理解问题,更好地维护系统。
限流熔断:微服务是一个分布式系统,如果没有好的熔断措施的话,某个服务出现故障或服务延迟,有可能会造成整个系统的瘫痪。
安全&访问控制:有些服务并不希望所有的人都去调用,可能涉及到敏感信息的,比如跟钱有关的服务,需要有安全策略。如黑白名单、访问控制策略来限制对这些服务的访问。
RPC/REST:一个好的微服务框架是能够同时支持Rpc/Rest调用。这两种不同的通讯方式有着不同的场景。如果可以支持不同的调用策略的话,会更加的灵活。
序列化XML/JSOM/二进制:一个好的微服务框架是比较灵活的,既能支持对开发人员友好的XML/JSON协议,也能够支持一些高性能的二进制序列化,可以根据场景的需要灵活配置消息序列化协议。
代码生成:在大规模开发过程中,比较推崇一种契约推动的开发方法,用代码生成的方式生成服务端和客户端代码,生成的代码会比较规整。
统一异常处理:我们的服务治理环节希望可以集成统一异常处理的能力,异常比较标准化,能够快读定位问题。
文档:微服务最终是要给消费者去使用的,如果没有好的文档,只提供一些代码,消费者接入的成本就比较高。好的文档能够帮助开发人员更好的去利用微服务。
配置集成:一套集中式的配置系统可以灵活的去调配微服务的行为。
后台服务集成DB、MQ、Cache:微服务系统后台有很多服务,如数据访问服务、缓存服务、消息服务。
微服务治理就是将上面的环节沉淀下来,变成框架、平台的部分,让开发人员可以专注于业务逻辑的实现,不需要去考虑外围的治理能力,提升研发效率。这些是由平台团队集中去管控的。
2. 微服务监控系统分层和监控架构
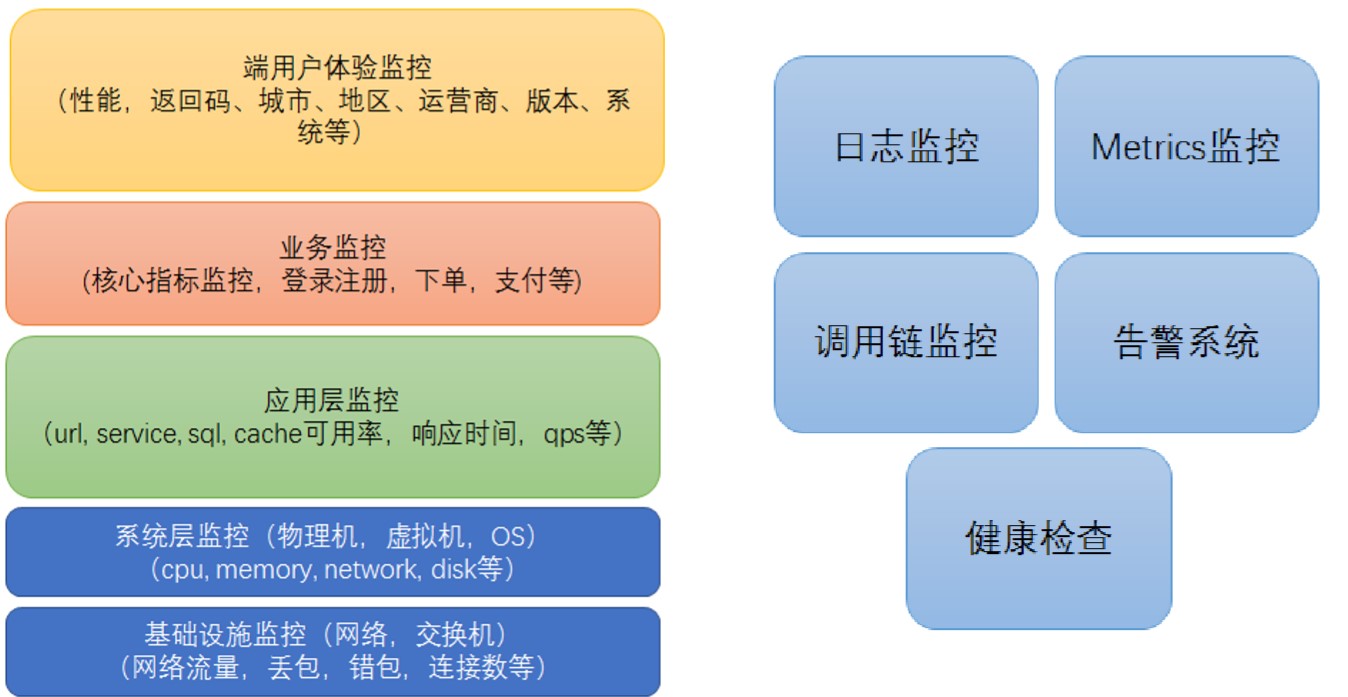
上文提到,监控是微服务治理重要的环节。监控系统的完善程度影响到我们整个微服务系统质量的好坏。微服务系统在线上运行时,可以实时的去了解它的健康运行情况,对整个系统的可靠性和稳定性是非常重要的。
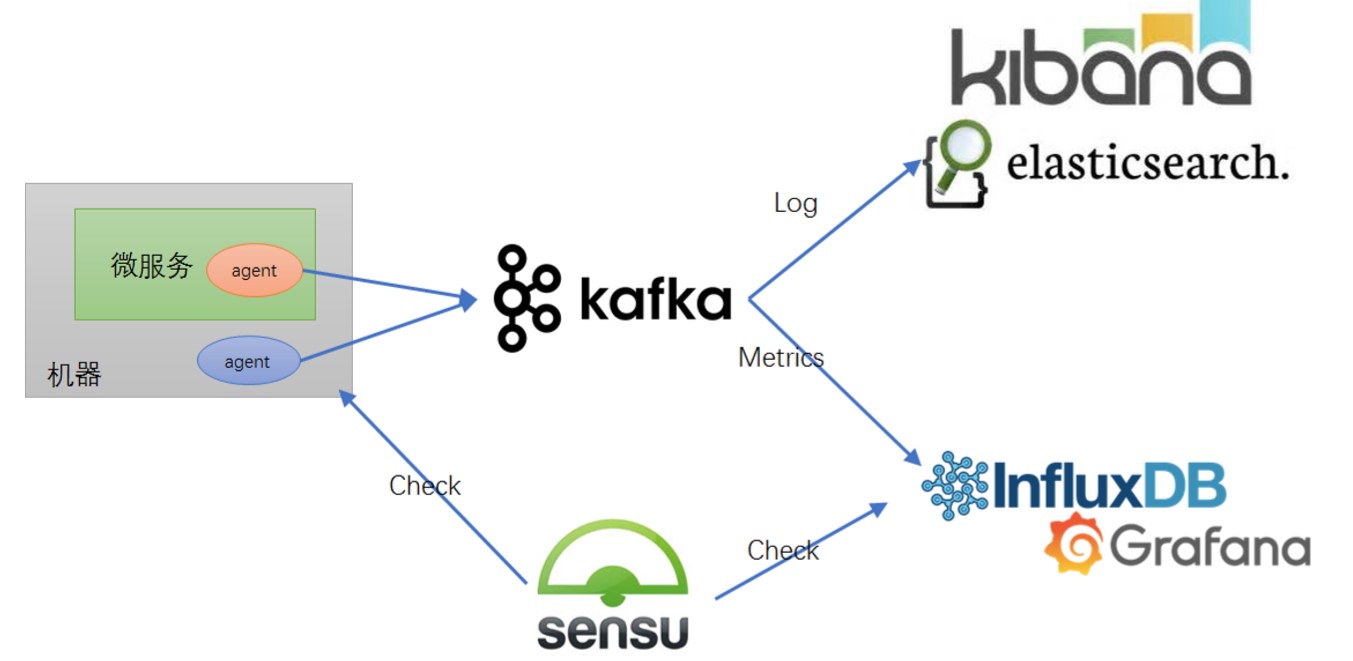
一般会在微服务所在的主机装一些Agent,负责去收集机器和应用当中的日志、Metrics,发送到后台的监控系统,当服务比较大时,收集到的信息比较大,会加一些队列,一般使用Kafka,好处是可以解耦,后台监控系统维护的话,可以作缓冲等使日志信息不会丢失。
后台目前业界标准的日志监控栈是ELK;Metrics主流的是采用一些时间序列数据库,如Influx DB,使用Grafana呈现展示。
微服务框架一般都会提供健康检查功能,SpringBoot就提供了健康检查组件,可以了解内部内存的使用情况、CPU的使用情况。需要有一个健康检查机制,可以定期自动化的做check,常见的开源工具有Nagios,GitHub上比较火的collectd等。
上面三套都有告警功能。
3. 微服务的调用链监控该如何选型
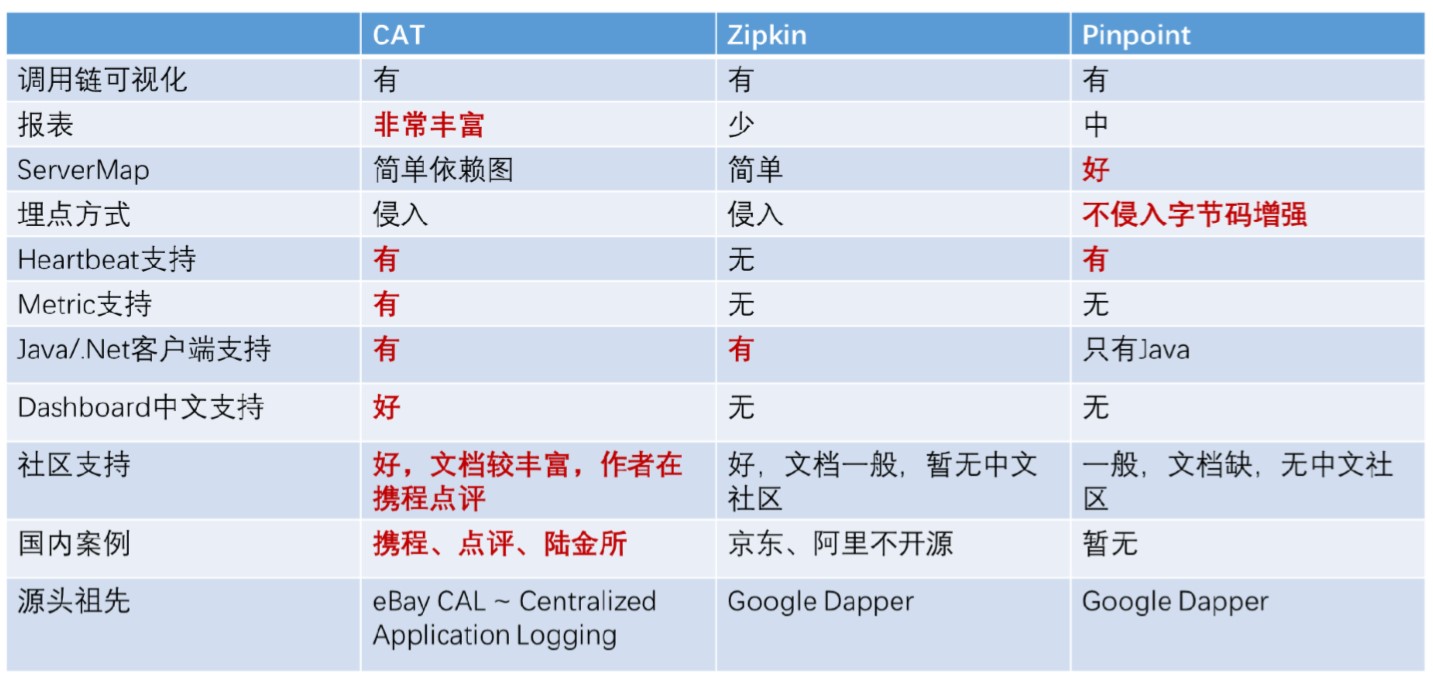
众所周知,微服务是分布式的非常复杂的系统,如果没有一套好的调用链监控 ,当服务之间出现问题时,难以定位。在各大主流的互联网公司中,BAT,如阿里巴巴拥有过自己的鹰眼监控系统,点评有CAT监控系统,都有相应配套的调用链监控工具,来保证服务可以得到有效的监控,出了问题可以及时有效的定位。
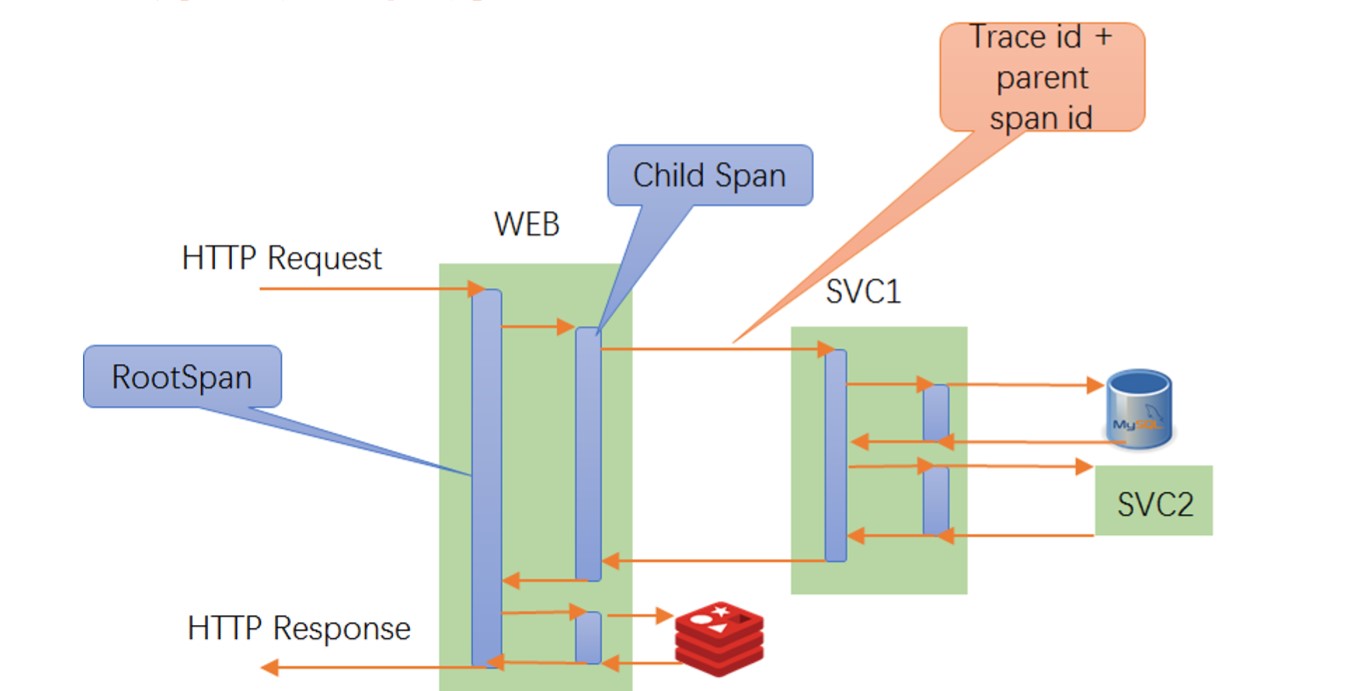
调用链监控最早是由谷歌提出来的思路,2010年的时候谷歌提出一篇论文,以他内部的一个调用链监控平台Dapper命名,讲解了调用链监控在谷歌的实际经验和他的一些原理(如上图所示)。
假如有一个应用程序,有WEB前端,它调用了后台服务SVC1,SVC1又调用了DB和SVC2,WEB还调用了后台的Cache。
调用链监控启动后,有一个Span的概念,当请求进入Web容器时,会生成一个Span,当它去调用SVC1时又会生成一个Span,到SVC1去调用DB、SVC2的时候都会生成相应的Span,Web应用在调用Cache时也会启动一个Span,Span当中有一些关键信息,主要有Trace-Id、Span-Id。Root-Span比较特殊,在启动的时候,除了会生成Span-Id,还会生成Trace-Id,其他的Span会生成自己的Span-Id,同时为了维护好调用链之间的父子关系,Root-Span后面的Chid-Span,会记录跟踪ParentSpan-Id,这样父子关系就可以串联起来。
另外在跨进程时,为了保证后续的调用链能够连接,会把Trace-Id、ParentSpan-Id也带过来,当把这些Span存储到后端后,就可以通过分析的手段把整个调用链的依赖关系呈现出来。
阿里鹰眼监控系统
参考链接:
https://www.infoq.cn/article/kMPZTgJqs7VJC5vkVCR2?utm_source=related_read&utm_medium=article
https://www.cnblogs.com/gzxbkk/p/9600263.html
CAT:携程点评,ZipKin:Twitter,Pinpoint:韩国朋友。
4. 微服务的容错限流是如何工作的
微服务分布式系统依赖关系错综复杂,一些典型的互联网公司,前端的请求转换为后端的服务调用时,一个请求会调很多的后端服务,有些公司的一个请求会分解为6个后端的调用,甚至更多。此时后台的服务出现不稳定,延迟等,如果没有好的限流熔断措施,会造成客户体验的下降,严重的会出现雪崩效应,整个网站都被搞挂。如阿里巴巴的双十一场景,没有一套完善的限流熔断措施,是不可想象的。
NetFlix在2012年之前系统也没有设计很好的限流熔断,饱受系统稳定性的困扰,好几次网站一度瘫痪。2012年左右网飞启动了一个弹性工程项目,其中的一个产品Hystrix,主要是解决微服务的弹性可靠性。
这段主要分享一下Hystrix限流熔断组件。先分享几个概念,他们是分布式系统容错场景下的常见模式。
熔断:房间内安装了电路熔断器,当使用大功率设备时,有熔断器帮忙保护,不至于出问题时导致危害扩大化。
隔离:计算机资源都是有限的,内存、CPU、线程池都是资源,都有Max-Size。如果不进行隔离,那么一个服务的调用可能消耗很多资源,将其他服务的资源都占用了,可能由于一个服务的捣蛋,连带效应造成其他服务不能正常访问。
限流:当大流量冲击网站时,需要有一定的限流措施,如单位时间内允许有100个请求进来,如果再大的话,系统负载会出问题。
降级:如果系统后台已经无法提供足够的支撑能力,此时需要有一种降级能力,保护系统的潜在问题不会进一步的恶化。
Hystrix将限流熔断、隔离降级的模式封装在组建中。
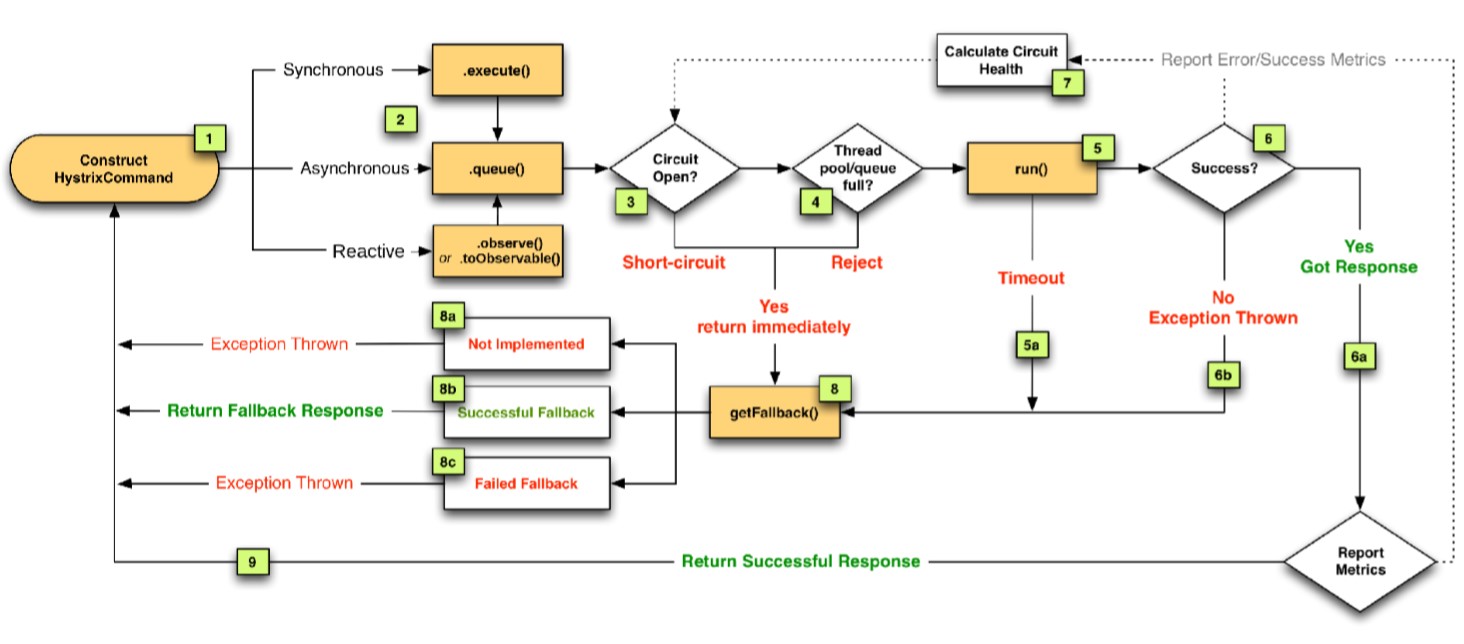
一般使用了Hystrix组件后,会把调用封装在Hystrix Command之内,请求被封装后,调用请求一般有3种模式。常用的是同步调用,也可以是异步、响应式。
请求过来后会经过组件的电路判断Circuit Open,如果电路是打开的,即断开了,则直接短路,马上返回,此时会调用降级函数,没有提供降级函数会直接抛出异常,降级函数如果也出错的话,再次抛出异常。
如果电路的闭合的,即是通的,没有熔断,会判断线程池、队列资源是否OK,如果满了的话,会限流拒绝,也是走降级流程。
如果通过前面两关,电路闭合且资源够用,run这个调用,运行过程中如果超时,还是走降级流程。
如果执行成功,会返回正确的Response响应,返回到调用端。
如果执行失败,抛出异常,走降级流程。
在整个运行过程中,任何一个环节,电路是否闭合,资源是否够用,调用是否超时,调用是否成功,这些信息都会以Metrics形式反馈给Hystrix内部Calculate Circuit Health这样的一个组件(计算电路健康)。该组件会计算整个调用情况反馈给内部电路熔断器,作为指导下一次是要打开/熔断电路的依据,类似于内部有一个“脑袋”,在观察整个调用情况。
5. Docker 容器部署技术 & 持续交付流水线
对于微服务产品来说,最后是要交付上线的。微服务采用容器技术来交付是一个很好的手段。
Docker最显著的特性:
环境一致性
- 原来部署应用程序时,如Java是采用Jar包或War包的形式部署,在不同的环境中可能会造成依赖不存在的问题。比方说原来在测试环境Jar包/War包部署是OK的,但是换到UAT环境,有可能由于操作系统的版本,或是依赖的Jar包的版本问题,可能就不Work了,经常会出现在我的机器上是好的,在其他机器上就出问题这样一种状况,这就是环境一致性的问题。
- 容器技术把依赖的包全部打到镜像当中,不会存在依赖、版本不一致、缺失等问题。
镜像部署
- 原来我们用Jar包/War包这种方式去部署,要依赖机器上的很多资源,它的部署发布系统一般都是定制的。对于Java有一套发布系统,对NodeJS/Ruby有另一套发布系统,
- Docker提供一层天然的抽象机制,镜像,这就把构建和发布隔离开,运输方不Care集装箱内装的是什么东西,集装箱内的东西也不Care到底是谁在运输我。
- 只要在每台机器上部署一个Docker的运行时,只要是镜像,不Care镜像内是Java、NodeJS还是Ruby的,只负责运行标准的容器镜像。镜像当中既有操作系统,又有依赖的包,还有微服务分布式系统。
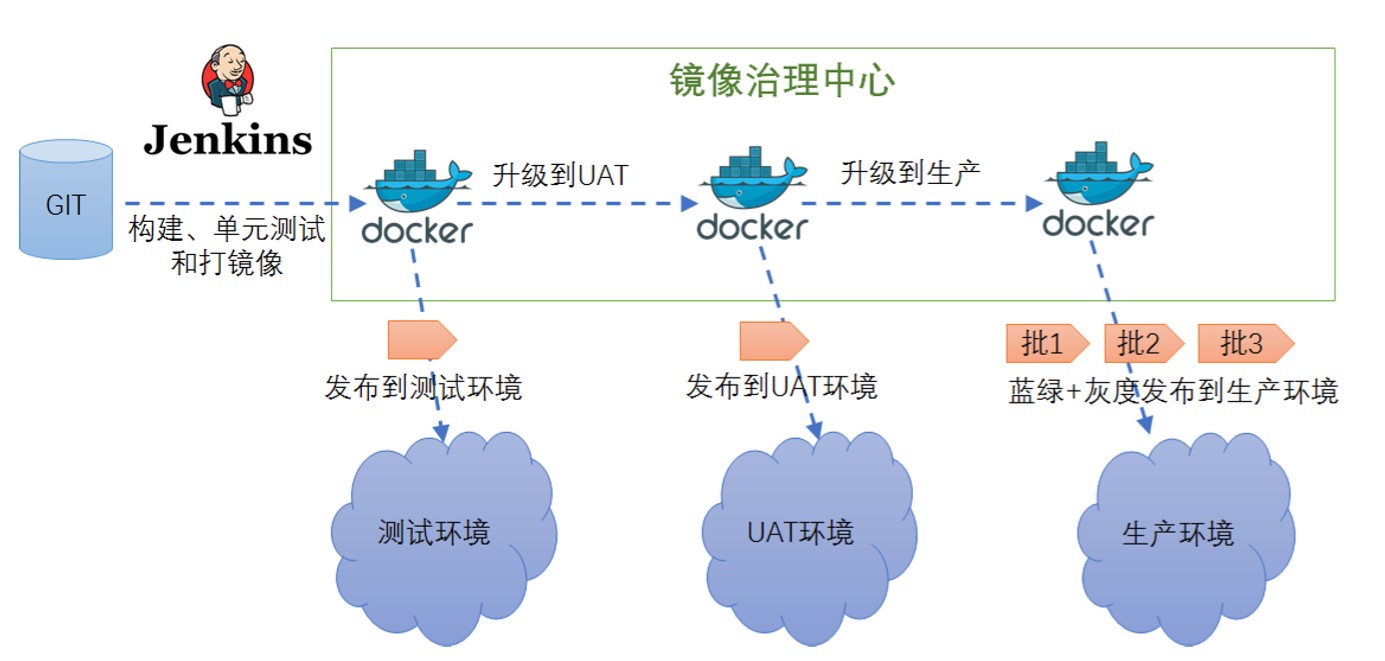
上图显示了基于容器技术的持续交付流水线,当我们的公司成长到一定规模,采用了微服务技术后,有很多团队在协作,如果没有一个完善的交付流水线,各个团队独自为政的话,很容易引入质量问题,最后交付到生产环境,会不稳定,甚至直接造成业务的损失。公司内部大都有一套持续交付流水线,类似于特斯拉的标准流水线,能够保证微服务以更高的质量、更高的效率交付给生产商。
采用容器的话,一般是基于docker registry来做,首先我们提交代码,会采用一些常用的工具如Jenkins去构建、单元测试、集成测试,没有问题则打成Docker镜像,然后把它上传到镜像治理中心(docker-registry),采用流水线的话,就会有一套标准的规范流程。
镜像首先发布到测试环境,经过TA测试完成后,没有问题,将镜像升级到UAT环境,此时可以给镜像打一个标签,然后发布到UAT环境,通过UAT环境的测试,又可以将它升级到生产环境。
生产环境的发布流程比较严格,可以采用一些诸如蓝绿、灰度发布到生产环境。
有了这样一套流水线,就可以把整个交付规范起来,每一步都可以设置一些门槛,经过测试环境测试才能到UAT环境,经过UAT环境的测试才能到生产环境。这样可以保证微服务的质量,同时提升研发效率。
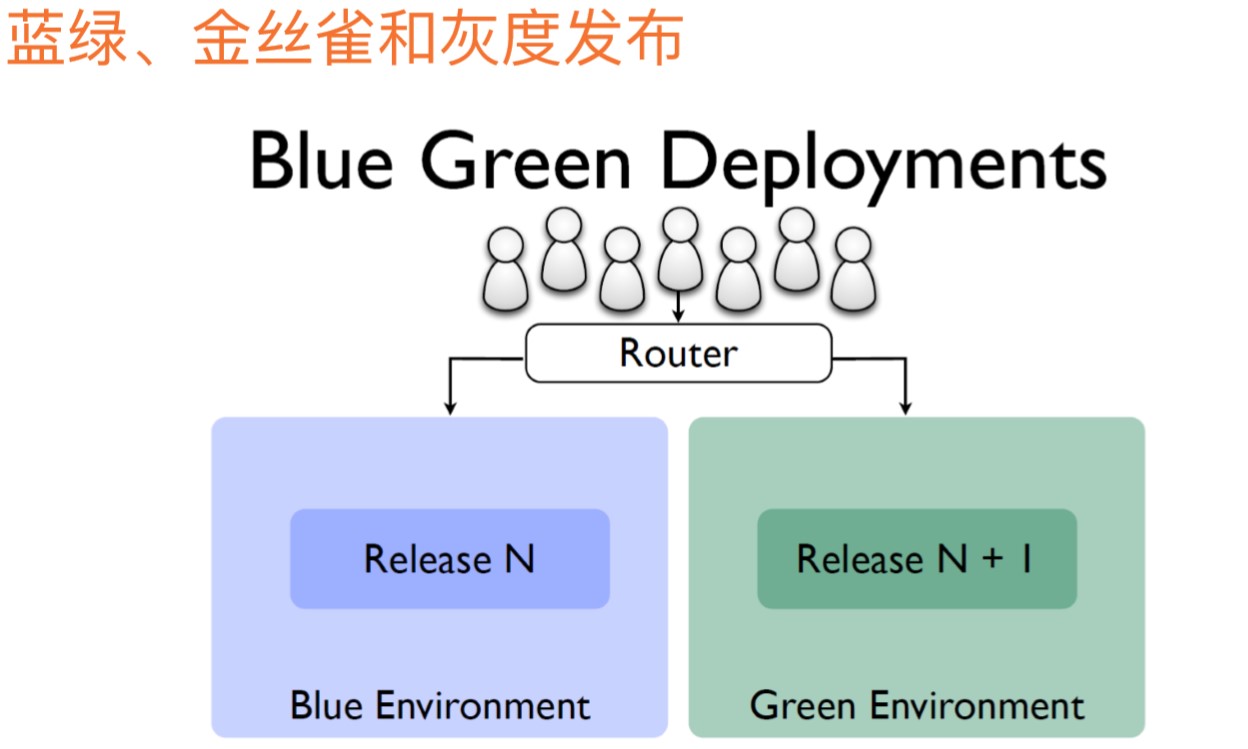
蓝绿部署:假定有两个版本,Old是Blue,New是Green,发布的时候依赖前置的路由器,可能是网关或内部的服务发现系统配合客户端的软路由来做,蓝绿的意思就是老版本还在,发布一个新的绿色版本,通过路由器调流量,当要升级时就切换流量到Green版本中。
蓝绿一般不是直接切换的,还会做灰度部署。
灰度部署:新版本上线后,可能有风险,不想把流量全部切换到绿色版本,而是渐进切换,先切10%的流量过去,如果有问题,再切回来,不至于造成更大的业务损失。如果10%经过验证,没有问题,再切20%、50%都没有问题,就切100%。是在蓝绿部署的基础上衍生出来的概念。这对微服务系统的稳定性、灵活性是非常重要的。
6. 容器集群调度和基于容器的发布体系
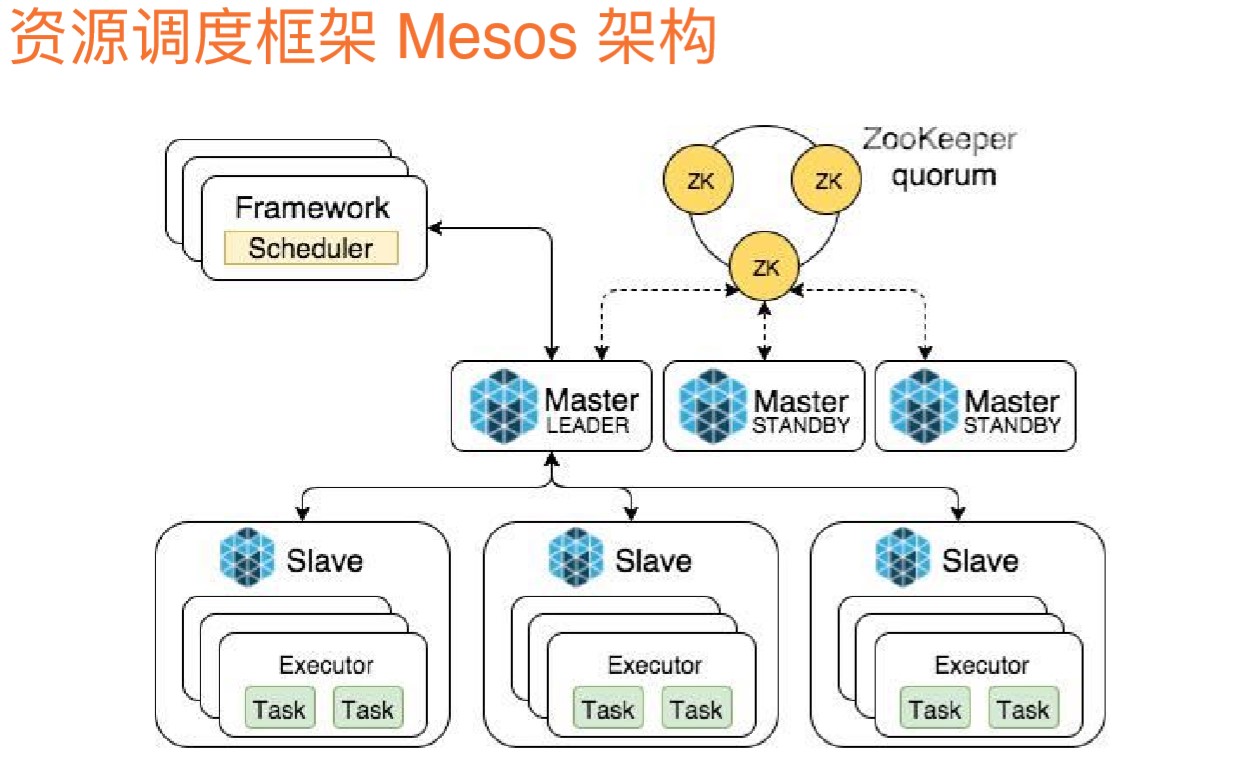
上节提到容器是交付微服务比较理想的一种手段。但是单独的容器能力比较有限,希望有一种容器资源的调度平台,或是容器云,能够统一的管控这些容器资源。
之前使用虚拟机的话,有虚拟机的云平台,如OpenStack,可以自动的创建虚拟机,管理虚拟机资源。容器有没有这样的开源技术呢?业界是有成熟的方案的,Mesos、Kubernetes等,它们都是基于容器的资源调度平台。
Mesos最早是基于Google的Borg系统,Borg是谷歌最早的一套内部资源调度平台,原来是谷歌最尖端的技术,需要签署保密协议,后来有谷歌工程师去了Twitter,重新造了一套类似于Borg的系统,最后慢慢的变成了开源技术,最后又有了Mesos系统,是Apache的一个开源项目。
原来部署应用是基于虚拟机以机器的概念进行部署。Mesos说:能否把所有的机器都管理起来呢?抽象成一台大型的计算机,有足够多的内存、CPU资源,有应用要部署的话,直接交给这个系统,会自动的调度。看上去像是一个超级操作系统,管理下面所有的机器,调度容器资源的运行。
Mesos基于M-S结构,Slave机器运行容器的物理机或虚拟机。Master负责去管理这些Slave机器。Master是做成高可用的,上面有Zookeeper集群,帮助Master高可用,是一个Master StandBy结构,有一个Master-Leader,来管控下面的Slave,如果Master-Leader挂了,有StandBy依赖于Zookeeper的高可用能力接管Leader。
Slave会定期的将自己的CPU、内存资源使用情况汇报给Master-Leader。Master会把相关的信息报给外围的Framework,Mesos只管资源的调度,具体怎么应用这些资源,是由Framework来定,设置了一种可插拔的框架机制,外围的框架可以利用Mesos搭建自己的应用,比方说Marathon(马拉松)就是一个简单的框架,可以跑微服务、Wen应用;也有些框架可以运行批处理任务;甚至有的框架支持在Mesos上跑Hadoop,Spark这些批处理任务。
这就是Mesos容器资源调度平台。
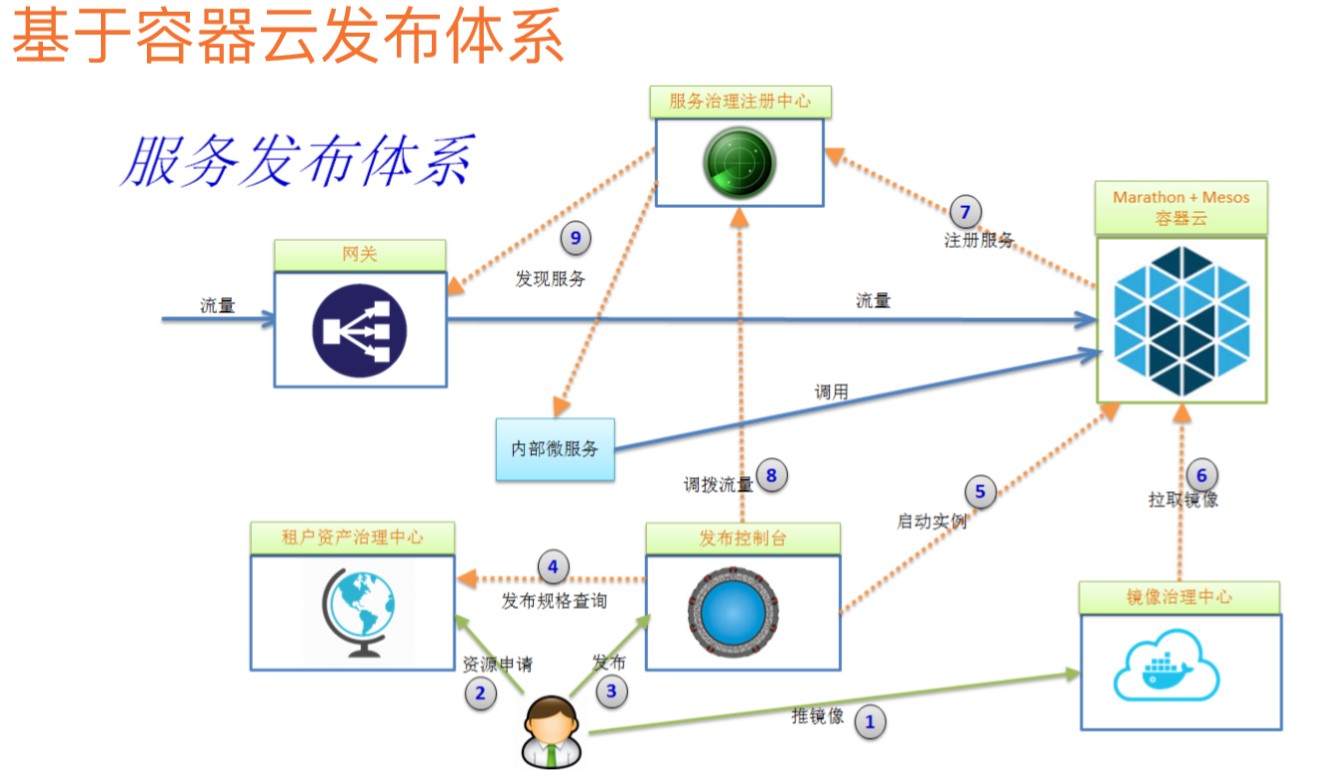
基于Mesos容器资源调度平台,怎样构建一个灵活地发布体系呢?
首先有一个CNDB-资产治理中心,管控企业内部资源使用情况,各个部门使用了多少资源。有发布平台,当我们的应用要去发布时,首先会去咨询CNDB是否有足够的配额,如果有的话,就会在Mesos中启动实例,如果我们使用的是马拉松框架,会提供API,可以支持去发API调用的方式去启动API实例。
启动实例的时候,Mesos会去镜像治理中心拉取镜像,服务起来后,微服务框架有注册的能力,注册到服务注册中心,发布完之后,就可以做流量的调度,如上文中讲到的蓝绿、灰度部署机制。可以通过发布平台直接调用服务注册中心的灰度的能力,网关可以从服务注册中心发现新的服务,流量可以通过网关去访问到Mesos集群中容器里的应用。