1. MyBatis常见问题
1. 扫描mapper.xml文件与全限定名
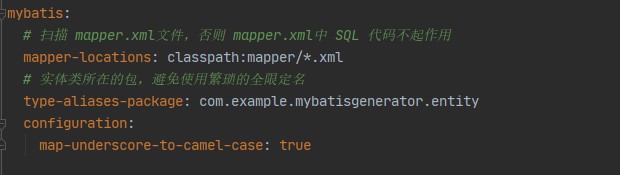
解析:
mybatis-mapper-locations:扫描 SpringBoot 框架下 resources 包下 mapper 下的 xxx.xml文件
mybatis-type-aliases-package:
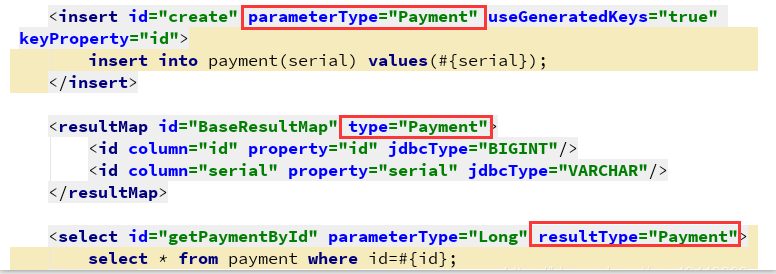
mapper.xml文件的 resultMap 的 type、parameterType、resultType 会引用一些实体类,此时需要写上全限定名。
如果不想写全限定名,只写一个实体类名称的话,需要在application.yml文件中设置mybatis-type-aliases-package参数;

2. @MapperScan 与 @Mapper
@Mapper注解的定义
1 | @Documented |
@Mapper 一般我们用在接口上,代码如下:
1 | @Mapper |
使用 @Mapper,最终 Mybatis 会有一个拦截器,会自动的对 @Mapper 注解的接口生成动态代理类。可在 MapperRegistry 类中的源代码中查看。
@Mapper 注解针对的是一个一个的类,相当于是一个一个 Mapper.xml 文件。而一个接口一个接口的使用 @Mapper,太麻烦了!!!
** @MapperScan 就应用而生**
@MapperScan 配置一个或多个包路径,自动的扫描这些包路径下的类,自动的为它们生成代理类。它里面用到了MapperScannerRegistrar
1 | @SpringBootApplication |
当使用了 @MapperScan 注解,将会生成 MapperFactoryBean, 如果没有标注 @MapperScan ,也就是没有 MapperFactoryBean 的实例,就走 @Import 里面的配置,具体可以在 AutoConfiguredMapperScannerRegistrar 和 MybatisAutoConfiguration 类中查看源代码进行分析。
二选其一即可,推荐第二种。
2. SpringBoot常见问题
1. @Resource 与 @Autowired
@Autowired
@Autowird 属于 spring框架 ,默认使用类型(byType)进行注入,例如下面代码:
1 | @Autowired |
系统会根据 ICityService 接口进行注入,如果这个接口只有一个实现类,会正常注入。
如果没有实现类或存在多个实现类,会报错,可以进行限定。
1 | @Autowired(required=false) |
如果找不到对应的bean时候,不会抛出错误,如果required = true,当不存在bean时候,就会抛出异常。
可以使用 @Qualifier配合@Autowird 使用,自动注入的策略就从 byType 转变成 byName .如下面代码
1 | @Autowired |
此时spring会根据@Qualifier指定的id进行注入(依据ID查询对应的bean)
@Resource
@Resource是 JavaEE 自带的注解,根据ID进行注入的.
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按byName自动注入罢了。
@Resource两个重要属性
- name
- type
Spring将@Resource注解的name属性解析为bean的名字。而type属性则解析为bean的类型。
所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。
如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序
1. 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
2. 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
3. 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常。
4. 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配。
2. @Transactional注解的坑
1. 预备知识
@Transactional可以作用于接口、接口方法、类以及类方法上。当作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。因此可以在Service层和Controller层使用。
参数描述
readOnly: 设置当前事务是否是只读事务,true表只读,false表可读写(默认为false)
rollbackFor:设置需要进行回滚的异常类数组,当方法中抛出该数组中指定的异常时,事务回滚。
@Transactional(rollbackFor={RuntimeExecetion.class,Exception.class})
noRollbackFor:设置不需要进行回滚的异常类数组。
noRollbackForClassName:设置不需要进行回滚的异常类名称数组。
propagation:设置事务的传播行为。
@Transactional(propagation=Propagation.NOT_SUPPORTED,readOnly=true)
isolation:设置底层数据库事务隔离级别,多用于处理多事务并发情况,通常使用数据库默认隔离级别。
timeout:设置事务超时时间,默认-1,即永不超时
隔离级别
隔离级别是指若干个并发的事务之间的隔离程度,TransactionDefinition 接口中定义了五个表示隔离级别的常量:
TransactionDefinition.ISOLATION_DEFAULT:默认值,大部分底层数据库是TransactionDefinition.ISOLATION_READ_COMMITTED
TransactionDefinition.ISOLATION_READ_UNCOMMITTED:表示一个事务可读取另一个事务修改但未提交的数据,不能防止脏读、不可重复读和幻读。
TransactionDefinition.ISOLATION_READ_COMMITTED:表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
TransactionDefinition.ISOLATION_REPEATABLE_READ:表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。该级别可以防止脏读和不可重复读。
TransactionDefinition.ISOLATION_SERIALIZABLE:所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
事务传播行为
在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
TransactionDefinition.PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值。
ansactionDefinition.PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
TransactionDefinition.PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
TransactionDefinition.PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
事务超时:就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒。默认设置为底层事务系统的超时值,如果底层数据库事务系统没有设置超时值,那么就是none,没有超时限制。
事务只读属性:只读事务用于客户代码只读但不修改数据的情形,只读事务用于特定情景下的优化。
同一类中,一个方法调用另外一个有事务的方法,事务不起作用
同一类中,一个有事务的方法调用另外一个方法,另外的方法内的事务不起作用
只有运行时异常才能触发事务
多个数据库源的情况下事务不起作用
原因:是springboot的动态代理机制所造成的的
1、对多库的数据源进行事务配置,调用时value值为配置的方法名
1 | @Bean |
2、尽量把事务的注释写在类上
如:
1 | @Service |
3、两个同时需要事务的方法不要写在同一个类中
2. @Transactional 坑
同一个类中,一个未标注@Transactional的方法去调用标有@Transactional的方法,事务会失效。
该注解只能应用到public可见度的方法上。?如果应用在protected、private或者package可见度的方法上,也不会报错,但是事务设置不会起作用。
数据库引擎本身不支持事务,比如说MySQL数据库中的myisam,事务是不起作用的
Spring只会对unchecked异常进行事务回滚;如果是checked异常则不回滚。
unchecked异常:派生于Error或RuntimeException的异常
如果出现了RuntimeException,就一定是程序员自身的问题。比如说,数组下标越界和访问空指针异常等等,只要你稍加留心这些异常都是在编码阶段可以避免的异常。
checked异常:其他异常。
Spring Transactional一直是RD的事务神器,但是如果用不好,反会伤了自己。下面总结@Transactional经常遇到的几个场景:
@Transactional 加于private方法, 无效
@Transactional 加于未加入接口的public方法,在通过普通接口方法调用,无效
@Transactional 加于接口方法,无论下面调用private或public,都有效
@Transactional 加于接口方法后, 被本类普通接口方法直接调用, 无效
@Transactional 加于接口方法后, 被本类普通接口方法通过接口调用, 有效
@Transactional 加于接口方法后, 被它类的接口方法调用, 有效
@Transactional 加于接口方法后, 被它类的私有方法调用后, 有效
Transactional是否生效, 仅取决于是否加载于接口方法, 并且是否通过接口方法调用(而不是本类调用)。
多数据源
事务不生效
背景介绍:
由于数据量比较大,项目的初始设计是分库分表的。于是在配置文件中就存在多个数据源配置。大致的配置类似下面:
1 | <!-- 数据源A和事务配置 --> |
但是在实际部署的时候,因为是单机部署的,多个数据源实际上对应的是同一个库,不存在分布式事务的问题。所以在代码编写的时候,直接通过在@Transactional注解来实现事务。具体代码样例大致如下:
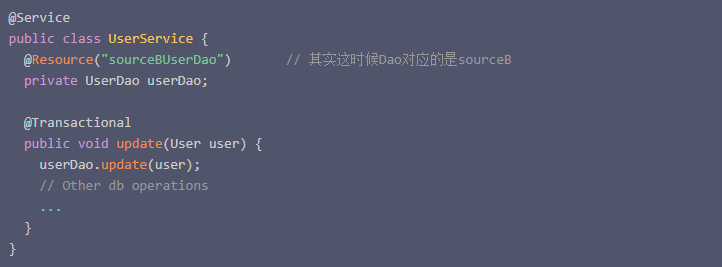
这中写法的代码一直在线上运行了一两年,没有出过啥问题…..反而是我在做一个需求的时候,考虑到@Transactional注解里面的 数据库操作,如果没有同时成功或者失败的话,数据会出现混乱的情况。于是自己测试了一下,开启了这段踩坑之旅…..
原因分析:
开始在网上搜了一下Transactional注解不支持多数据源, 于是我当时把所有数据库操作都采用sourceB作为前缀的Dao进行操作。结果测试一遍发现还是没有事务效果。没有什么是源码解决不了的,于是就开始debug源码,发现最终启动的事务管理器竟然是dataSourceTxManagerA。 难道和事务管理器声明的顺序有关?于是我调整了下xml配置文件中,事务管理器声明的顺序,发现事务生效了,因此得证。
具体来说原因有以下两点:
@Transactional注解不支持多数据源的情况如果存在多个数据源且未指定具体的事务管理器,那么实际上启用的事务管理器是最先在配置文件中指定的(即先加载的)
解决办法:
对于多数据下的事务解决办法如下:
在
@Transactional注解添加的方法内,数据库更新操作统一使用一个数据源下的Dao,不要出现多个数据源下的Dao的情况统一了方法内的数据源之后,可以通过
@Transactional(transactionManager = "dataSourceTxManagerB")显示指定起作用的事务管理器,或者在xml中调节事务管理器的声明顺序
死循环问题:
这个问题其实也是多数据源导致的,只是更难分析原因。具体场景是:假设我的货仓里有1000个货物,我现在要给用户发货。每批次只能发100个。我的货物有一个字段来标识是否已经发过了,对于已经发过的货不能重新发(否则只能哭晕在厕所)!代码的实现是外层有一个while(true)循环去扫描是否还有未发过的货物,而发货作为整体的一个事务,具体代码如下:
1 | @Transactional |
从整体上来看,这段代码逻辑上没有任何问题。实际运行的时候却发现出现了死循环。还好测试及时发现,没有最终上线。那么具体原因是咋样的呢?
出现这个问题的时候,配置文件的配置还是同前面一个问题一样的配置。即实际上@Transactional注解默认起作用的事务是针对dataSourceA的。然后跟进updateBatchId方法,发现其最终调用的方法采用的Dao是sourceA为前缀的Dao,而updateGoodsStatusByBatchId方法最终调用的Dao是sourceB为前缀的Dao。细细分析,我终于知道为啥了 ?
- 发货方法最终起作用的事务是针对
sourceA的, 也就是updateBatchId方法实际上作为一个事务,他是要在方法执行完成之后才提交的 - oracle默认的事务隔离级别是
READ_COMMITTED, 所以在updateGoodsStatusByBatchId方法去更新的时候,其实还读取不到对应批次号的记录,也就不会做更新
解决办法这里就不说了,最终还是同前面一个问题,或者更新的时候根据货物列表去更新。
内部调用
内部调用不生效的问题其实大部分大家都知道。举一个简单的例子:
假设我有一个类的定义如下:
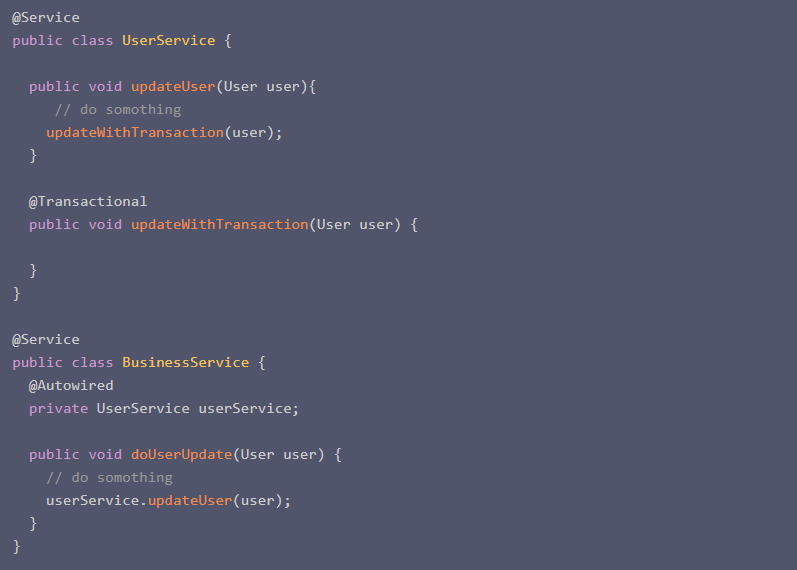
这种情况下大家都知道事务最终是不会生效的。因为对于updateWithTransaction方法是通过内部调用的,这时候@Transactional注解压根就不会生效。但是有时候情况并不这么明显,考虑下面的代码:
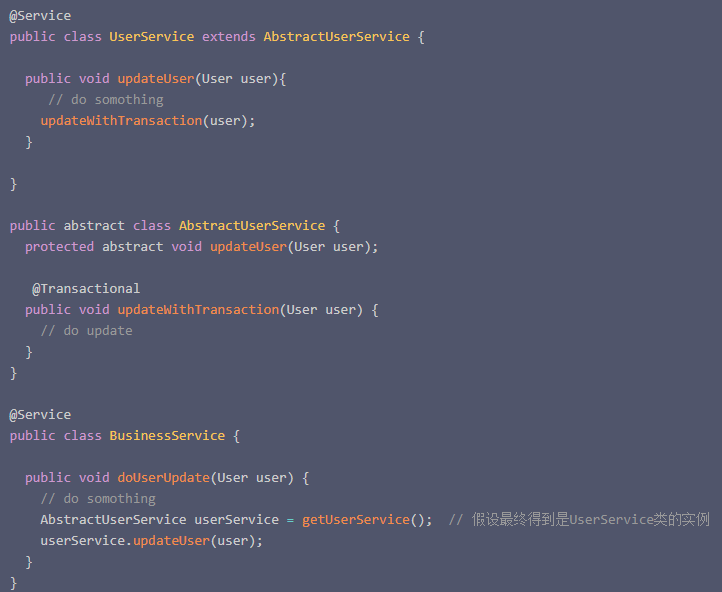
这段代码初一分析,最终调用的updateUser方法是UserService的方法, 然后调用的updateWithTransaction是属于AbstractUserService类的。 好像是调用的不是同一个类的方法,按道理事务应该是可以生效的。其实并没有….. 原因其实还是是内部调用。其实这种场景我也是在项目中发现的(坑太多),当时的代码比这个复杂的多,Abstract类包含了一堆可以被子类重写的方法。原来的代码大致如下:
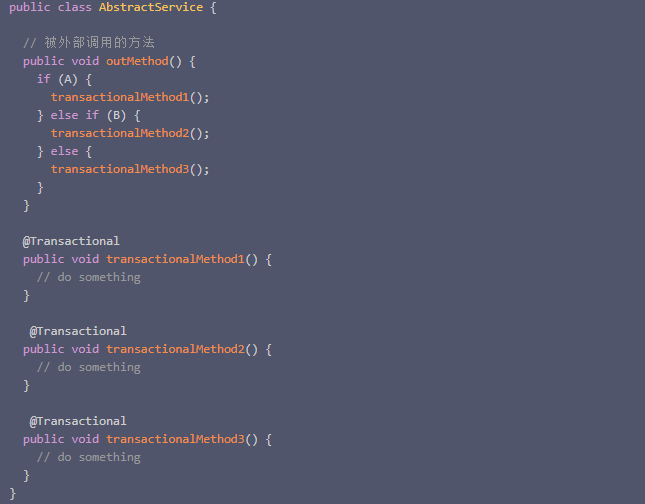
其中三个事务方法都可能被子类重写,修改必须兼容老代码。思考了兼容和接口改造的方式,我最终实现如下:
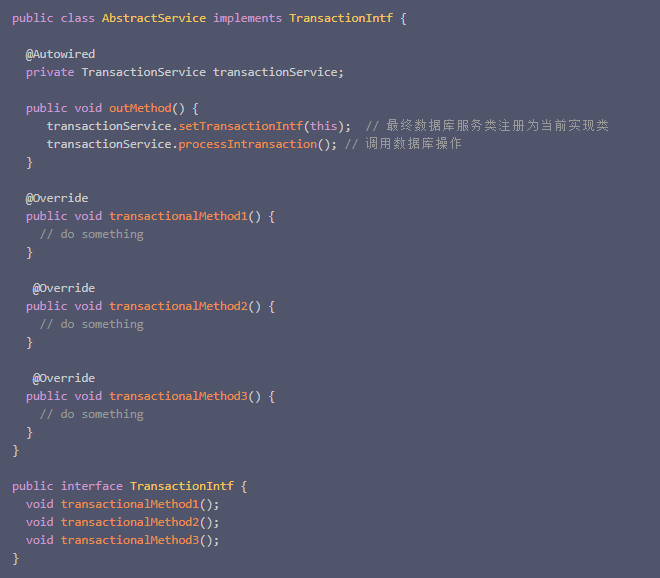

填坑总结
下面直接给出网站上关于@Transactional使用的注意点:
@Transactional annotations only work on public methods. If you have a private or protected method with this annotation there’s no (easy) way for Spring AOP to see the annotation. It doesn’t go crazy trying to find them so make sure all of your annotated methods are public.
Transaction boundaries are only created when properly annotated (see above) methods are called through a Spring proxy. This means that you need to call your annotated method directly through an @Autowired bean or the transaction will never start. If you call a method on an @Autowired bean that isn’t annotated which itself calls a public method that is annotated YOUR ANNOTATION IS IGNORED. This is because Spring AOP is only checking annotations when it first enters the @Autowired code.
Never blindly trust that your @Transactional annotations are actually creating transaction boundaries. When in doubt test whether a transaction really is active (see below)
另外附上验证是否是否开启的工具类源码(我只是搬运工):
1 | class TransactionTestUtils { |
3. 三目运算符的空指针问题,已被阿里巴巴开发手册收录

1. 三目元算符
对于条件表达式b?x:y,先计算条件b,然后进行判断。如果b的值为true,计算x的值,运算结果为x的值;否则,计算y的值,运算结果为y的值。一个条件表达式从不会既计算x,又计算y。条件运算符是右结合的,也就是说,从右向左分组计算。例如,a?b:c?d:e将按a?b:(c?d:e)执行。
2. 自动装箱与自动拆箱
基本数据类型的自动装箱(autoboxing)、拆箱(unboxing)是自J2SE 5.0开始提供的功能。
一般我们要创建一个类的对象实例的时候,我们会这样:Class a = new Class(parameters);
当我们创建一个Integer对象时,却可以这样:Integer i = 100;(*注意:和 int i = 100;是有区别的 *)
实际上,执行上面那句代码的时候,系统为我们执行了:Integer i = Integer.valueOf(100);
这里暂且不讨论这个原理是怎么实现的(何时拆箱、何时装箱),也略过普通数据类型和对象类型的区别。
我们可以理解为,当我们自己写的代码符合装(拆)箱规范的时候,编译器就会自动帮我们拆(装)箱。
那么,这种不被程序员控制的自动拆(装)箱会不会存在什么问题呢?
3. 问题回顾
首先,通过你已有的经验看一下下面这段代码:
1 | Map<String,Boolean> map = new HashMap<String, Boolean>(); |
以上这段代码,是我们在不注意的情况下有可能经常会写的一类代码(在很多时候我们都爱使用三目运算符)。当然,这段代码是存在问题的,执行该代码,会报NPE.
Exception in thread "main" java.lang.NullPointerException
首先可以明确的是,既然报了空指针,那么一定是有些地方调用了一个null的对象的某些方法。
在这短短的两行代码中,看上去只有一处方法调用map.get("test"),但是我们也都是知道,map已经事先初始化过了,不会是Null,那么到底是哪里有空指针呢。
我们接下来反编译一下该代码。看看我们写的代码在经过编译器处理之后变成了什么样。
反编译后代码如下:
1 | HashMap hashmap = new HashMap(); |
看完这段反编译之后的代码之后,经过分析我们大概可以知道问题出在哪里。
((Boolean)hashmap.get("test")).booleanValue()的执行过程及结果如下:
hashmap.get(“test”)->null;
(Boolean)null->null;
null.booleanValue()->报错
好,问题终于定位到了。那么接下来看看如何解决该问题以及为什么会出现这种问题。
4. 原理分析
通过查看反编译之后的代码,我们准确的定位到了问题,分析之后我们可以得出这样的结论:NPE的原因应该是三目运算符和自动拆箱导致了空指针异常。
根据规定,三目运算符的第二、第三位操作数的返回值类型应该是一样的,这样才能当把一个三目运算符的结果赋值给一个变量。
如:Person i = a>b ?i1:i2; ,就要求i1和i2的类型都必须是Person才行。
因为Java中存在一种特殊的情况,那就是基本数据类型和包装数据类型可以通过自动拆装箱的方式互相转换。即可以定义int i = new Integer(10);也可以定义Integer i= 10;
那如果,三目运算符的第二位和第三位的操作数的类型分别是基本数据类型和包装类型对象时,就需要有一方需要进行自动拆装箱。
那到底如何做的呢,根据三目运算符的语法规范。参见jls-15.25,摘要如下:
If the second and third operands have the same type (which may be the null type), then that is the type of the conditional expression.
If one of the second and third operands is of primitive type T, and the type of the other is the result of applying boxing conversion (§5.1.7) to T, then the type of the conditional expression is T.
If one of the second and third operands is of the null type and the type of the other is a reference type, then the type of the conditional expression is that reference type.
简单的来说就是:当第二,第三位操作数分别为基本类型和对象时,其中的对象就会拆箱为基本类型进行操作。
所以,结果就是:由于使用了三目运算符,并且第二、第三位操作数分别是基本类型和对象。所以对对象进行拆箱操作,由于该对象为null,所以在拆箱过程中调用null.booleanValue()的时候就报了NPE。
5. 问题解决
如果代码这么写,就不会报错:
1 | Map<String,Boolean> map = new HashMap<String, Boolean>(); |
就是保证了三目运算符的第二第三位操作数都为对象类型。
这和三目运算符有关。
不过文中示例在JDK 1.8中并不会抛出NPE,这和JLS的规范调整有关。
3. 日志常见问题
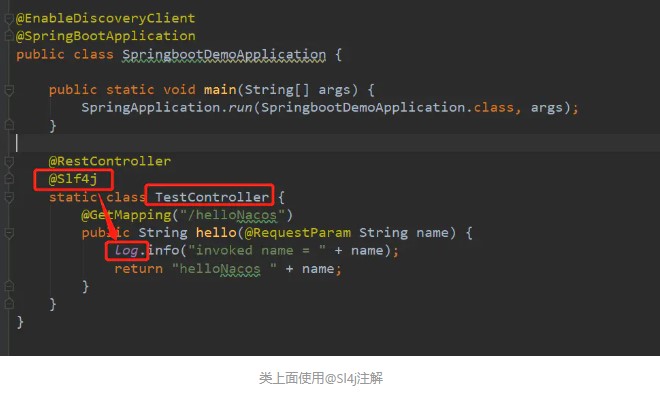
1. 注解@Slf4j的使用
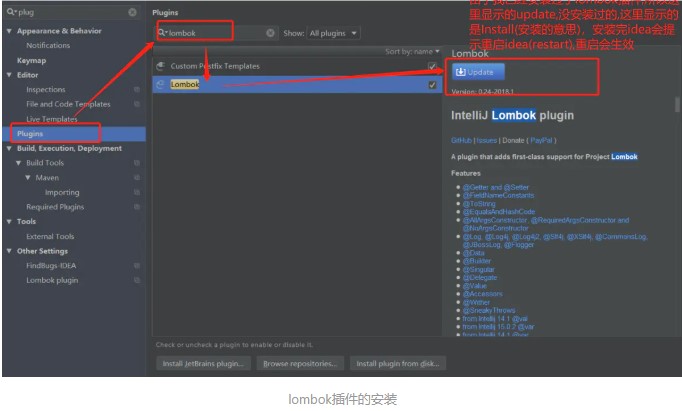
声明:如果不想每次都写private final Logger logger = LoggerFactory.getLogger(当前类名.class); 可以用注解@Slf4j;
1. 使用idea首先需要安装Lombok插件;
2. 在pom文件加入lombok的依赖
1 | <dependency> |
3.类上面添加@Sl4j注解,然后使用log打印日志;
4. 跨域请求
http跨域时的options请求
1. 简介
出于安全考虑,并不是所有域名访问后端服务都可以。其实在正式跨域之前,浏览器会根据需要发起一次预检(也就是option请求),用来让服务端返回允许的方法(如get、post),被跨域访问的Origin(来源或者域),还有是否需要Credentials(认证信息)等。那么浏览器在什么情况下能预检呢?
2. 两种请求方式
浏览器将CORS请求分为两类:简单请求(simple request)和非简单请求(not-simple-request),简单请求浏览器不会预检,而非简单请求会预检。这两种方式怎么区分?
同时满足下列三大条件,就属于简单请求,否则属于非简单请求
请求方式只能是:GET、POST、HEAD
HTTP请求头限制这几种字段:Accept、Accept-Language、Content-Language、Content-Type、Last-Event-ID
Content-type只能取:application/x-www-form-urlencoded、multipart/form-data、text/plain
对于简单请求,浏览器直接请求,会在请求头信息中,增加一个origin字段,来说明本次请求来自哪个源(协议+域名+端口)。服务器根据这个值,来决定是否同意该请求,服务器返回的响应会多几个头信息字段,如图所示:上面的头信息中,三个与CORS请求相关,都是以Access-Control-开头。
1.Access-Control-Allow-Origin:该字段是必须的,* 表示接受任意域名的请求,还可以指定域名
2.Access-Control-Allow-Credentials:该字段可选,是个布尔值,表示是否可以携带cookie,(注意:如果Access-Control-Allow-Origin字段设置*,此字段设为true无效)
3.Access-Control-Allow-Headers:该字段可选,里面可以获取Cache-Control、Content-Type、Expires等,如果想要拿到其他字段,就可以在这个字段中指定。比如图中指定的GUAZISSO
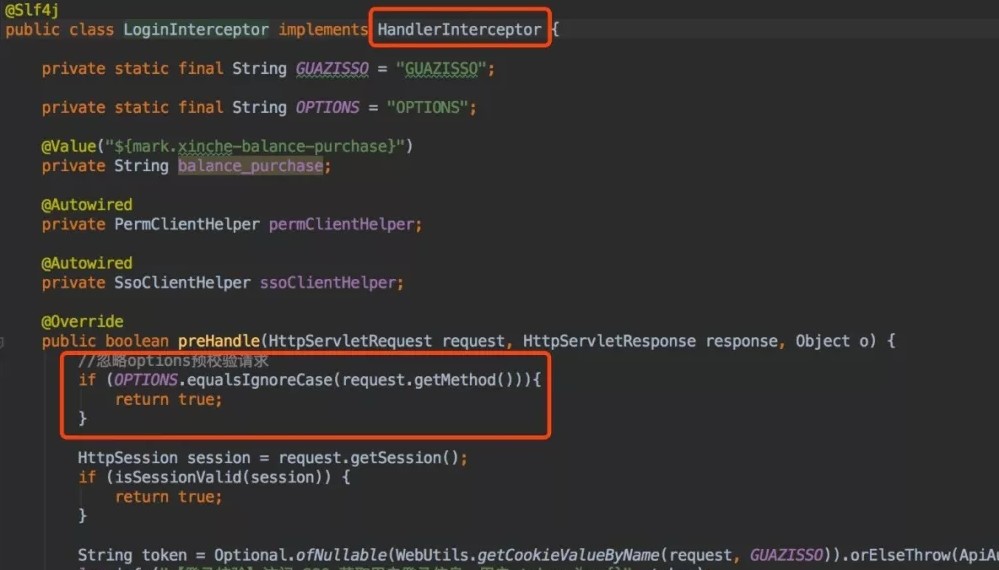
非简单请求是对那种对服务器有特殊要求的请求,比如请求方式是PUT或者DELETE,或者Content-Type字段类型是application/json。都会在正式通信之前,增加一次HTTP请求,称之为预检。浏览器会先询问服务器,当前网页所在域名是否在服务器的许可名单之中,服务器允许之后,浏览器会发出正式的XMLHttpRequest请求,否则会报错。(备注:之前碰到预检请求后端没有通过,就不会发正式请求,然后找了好久原因,原来后端给忘了设置…)Java后端实现拦截器,排除Options。
就Content-Type为application/json为例:对比两张图片,一次预检请求,一 次正式请求:
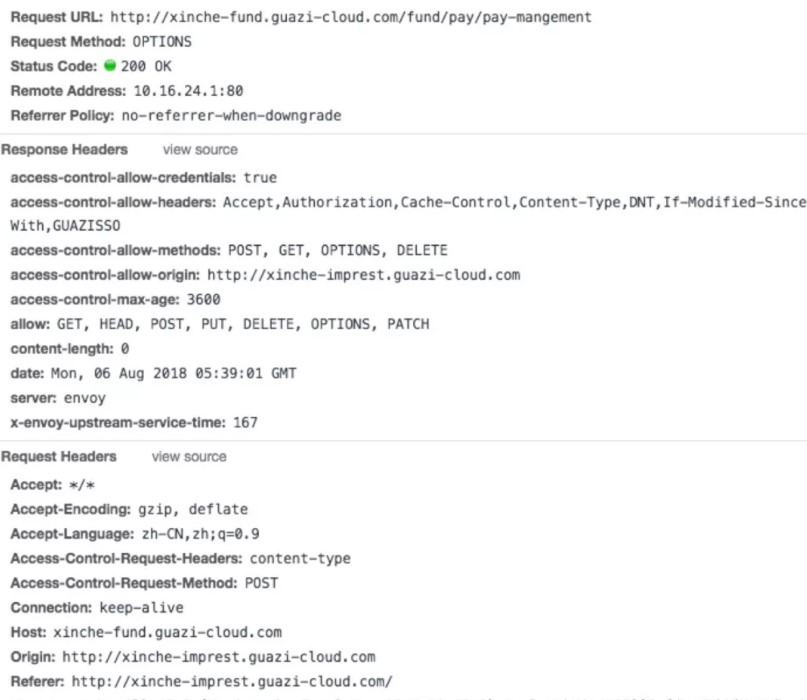
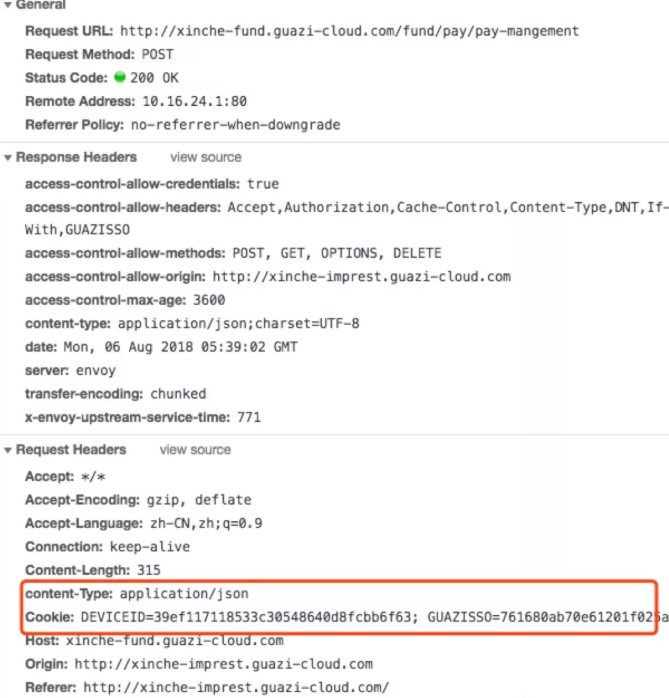
很明显,请求头中预检请求不会携带cookie,正式请求会携带cookie和参数。跟普通请求一样,响应头也会增加同样字段。
一旦服务器通过了“预检”请求,以后每次浏览器正常的CORS请求,就都跟简单请求一样。
未完待续…