Author: haoransun
Wechat: SHR—97
学习来源:极客时间-Nginx核心知识100讲,本人购买课程后依据视频讲解汇总成个人见解。
前言
在HTTP模块开始处理用户请求之前,首先要Nginx框架先对客户端建立连接,接收用户发来的 HTTP Line,如方法、URL等,再去接收到所有的Header,根据Header信息,才能决定使用哪些配置块,让HTTP模块怎样处理请求。因此,有必要看一看 Nginx框架如何建立连接、接收HTTP请求。
接收请求事件模块
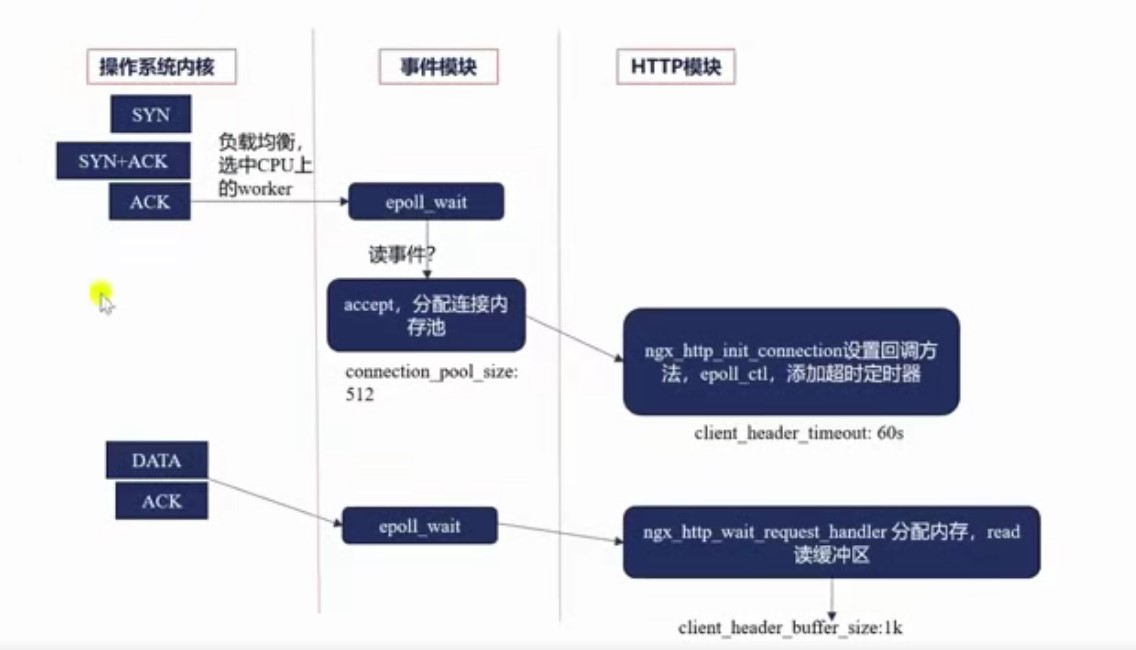
大致分为3个层次:操作系统内核、事件模块、HTTP模块,流程大致如下:
操作系统内核:3次握手,当用户发来SYN时,内核会回复一个SYN+ACK表示已确认,当客户端再发来ACK时,标明连接已成功建立,Nginx有很多Worker进程,都监听了80、443端口,操作系统会依据它的负载均衡算法,选中某一个Worker进程
被选中的Worker进程会通过 epoll_wait方法去返回刚刚建立好连接的句柄,拿到句柄后,这其实是一个读事件(读到了一个ACK报文),根据读事件,找到监听的80、443端口,可以调用accept方法,分配连接内存池,默认为 connection_pool_size 512字节
所有的HTTP模块开始从事件模块中接入请求,HTTP模块在启动时会定义一个ngx_http_init_connection回调方法,通过 epoll_ctl将读事件加入其中,同时设置超时定时器(client_header_timeout:60s)
当用户真的把一个HTTP请求(get、post)发来时,其实是DATA,在TCP层(内核层),会回复一个ACK,同时事件模块的epoll_wait又拿到这个请求,回调方法是 ngx_http_wait_request_handler,需要将内核中的DATA读到Nginx的用户态中,需要分配内存,从连接内存池分配1k(client_header_buffer_size),并不是越大越好,因为只要用户有1个字节发过来,就要为他分配1k大小内存,但是如果用户发来的DATA(URL、Header)超过1K了呢?
接收请求HTTP模块
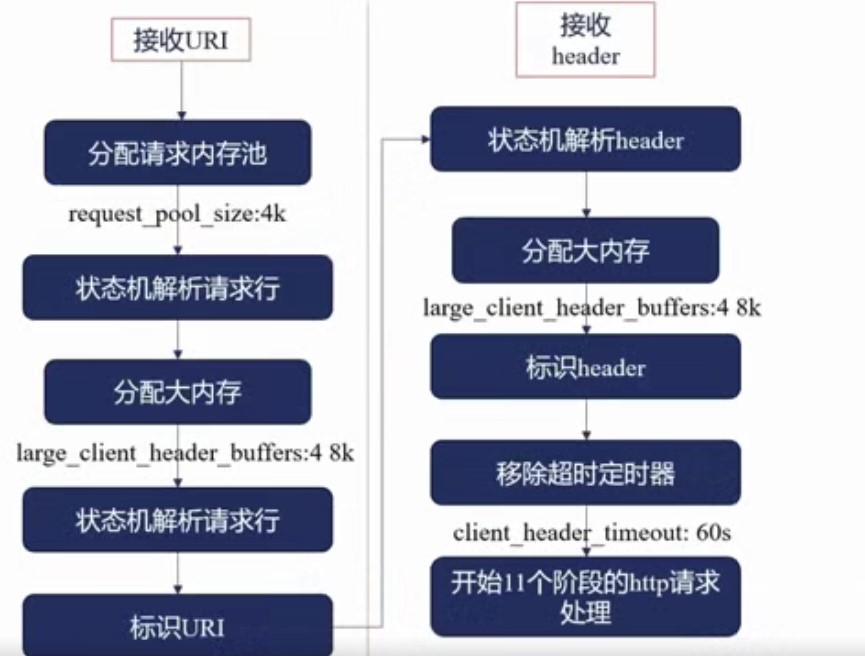
接收URI
刚刚分配完1K后,已经收到了 小于等于1K的请求内容。
分配请求内存池:处理请求与处理连接不同,处理连接只需要将它收到Nginx内存中就OK了,但处理请求时,去做大量的上下文分析,分析它的HTTP协议、Header,因此要分配一个请求内存池,默认 request_pool_size:4k,基本上是connection_pool_size的8倍,因为请求的上下文涉及到业务,通常4K是一个比价合适的大小(如果分配过小,请求内存池需要不断地扩充,分配内存的次数变多时,肯定会影响性能),要不要改这个4K要根据业务来决定。
状态机解析请求行:解析请求的行, /r /n之前的 方法名、URL、协议。解析过程中可能会发现URL特别大,超过了刚刚分配的1K内存。
分配大内存:主要是来解决大URL的问题,分多大的呢?large_client_header_buffers:4 8k,分配的并不是32K 这么大的内存,而是先分配一个8K的内存,将刚刚1K内存中内容拷贝到这个8K内存中来,还剩7K的内存,用剩下的7K再去接收URL,然后用状态机去继续解析URL,如果发现7K都没有解析完,再次分配第二个8K,即一共分配了16K,最多分配32K。
解析完成时,就可以标识URI,类似于超链接,Nginx用指针指向这个URI。
接收Header
HTTP请求中的Header可能会非常长,如有Cookie、Host等字段。
状态机解析Header,Header非常有可能超过1K,又需要分配大内存。
分配大内存与左边接收URI是共用的,如左边已用了2个8K,此处最多只能在分配2个8k。
标识header
移除超时定时器,是在收到完整的Header后,才可移除。
开始11个阶段的HTTP请求处理
小结
以上都是Nginx框架处理的,11个流程是HTTP模块处理的。