前言
2014年,Oracle发布了Java8新版本后,愈来愈多的公司开始尝试使用Java8新特性来摆脱繁琐的语法,在使用Java8代码编写公司项目后,为了追上时代潮流,开始系统学习Java8的一些新特性。在收集整理网上各种Java8学习笔记后,此篇文章算是个人Java8学习笔记的小结。
- 速度更块
- 代码更少(Lambda表达式)
- 强大的Stream API
- 便于并行
- 最大化减少空指针异常 Optional
核心为:Lambda表达式与Stream API
1. Lambda表达式
1. 为什么使用Lambda表达式
Lambda是一个匿名函数,我们可以把Lambda表达式理解为是一段可以传递的代码(将代码像数据一样传递)。可以写出更简洁、更灵活的代码。作为一种紧凑的代码风格,使Java语言的表达更加凝练。
- 从匿名类到 Lambda 的转换
例子1:
1 | //匿名内部类 |
例子2:
1 | //原来使用匿名内部类作为参数传递 |
匿名内部类:冗余的语法。导致了“Height Problem”(只有一行在工作)
2. Lambda表达式语法
Lambda 表达式在Java语言中引入了一个新的语法元素和操作符。这个操作符为 “ -> “,该操作符被称为 Lambda操作符 或 箭头操作符。它将Lambda分为两个部分:
左侧:指定了 Lambda 表达式需要的所有参数
右侧:指定了 Lambda 体,即 Lambda 表达式要执行的功能。
语法格式一:无参,无返回值,Lambda只需一条语句
1 | Runnable r1 = () -> System.out.println("Hello Lambda"); |
语法格式二:Lambda需要一个参数
1 | Consumer<String> fun = (args) -> System.out.println(args); |
语法格式三:Lambda只需要一个参数时,参数的小括号可省略
1 | Consummer<String> fun = args -> System.out.println(args); |
语法格式四:Lambda需要两个参数,并且有返回值
1 | BinaryOperator<Long> bo = (x,y) ->{ |
语法格式五:当Lambda体只有一条语句时,return与大括号可以省略
1 | BinaryOperator<Long> bo = (x,y) -> x + y; |
语法格式六:Long数据类型可以省略,可由编译器推断,即“类型推断”
1 | BinaryOperator<Long> bo = (Long x,Long y) -> { |
Lambda是匿名内函数:提供了轻量级的语法。解决了匿名内部类带来的“高度”问题。
语法:参数列表 -> 函数体三部分组成。
函数体:表达式、语句块。
表达式:表达式会被执行然后返回执行结果。
语句块:语句块中的语句会被依次执行,就像方法中的语句一样
- return语句会把控制权交给匿名函数的调用者
- break和continue只能在循环中使用。
- 如果函数体有返回值。那么函数体内部的每一条路径都要有。
表达式函数体适合小型Lambda表达式。消除了return关键字。简洁。
新包:java.util.function:
1 | //接收 T对象 返回boolean |
一些 Lambda表达式简单例子
1 | (int x,int y)->x+y; //接收 x y 返回 x与y的和 |
3. 类型推断
Lambda表达式无需指定类型,程序依然可以编译,因为 javac 根据程序上下文,在后台推断出了参数类型。Lambda表达式的类型依赖于上下文环境,是由编译器推断出来的。即所谓的“类型推断”。
2. 函数式接口
1. 什么是函数式接口
只包含了一个抽象方法的接口,称为函数式接口
你可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda 表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方法上进行声明)。
我们可以在任意函数式接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口,同时 javadoc 也会包含一条声明,说明这个接口是一个函数式接口。
2. 自定义函数式接口
1 | @FunctionalInterface |
作为参数传递 Lambda 表达式:为了将 Lambda 表达式作为参数传递,接收Lambda 表达式的参数类型必须是与该 Lambda 表达式兼容的函数式接口的类型。
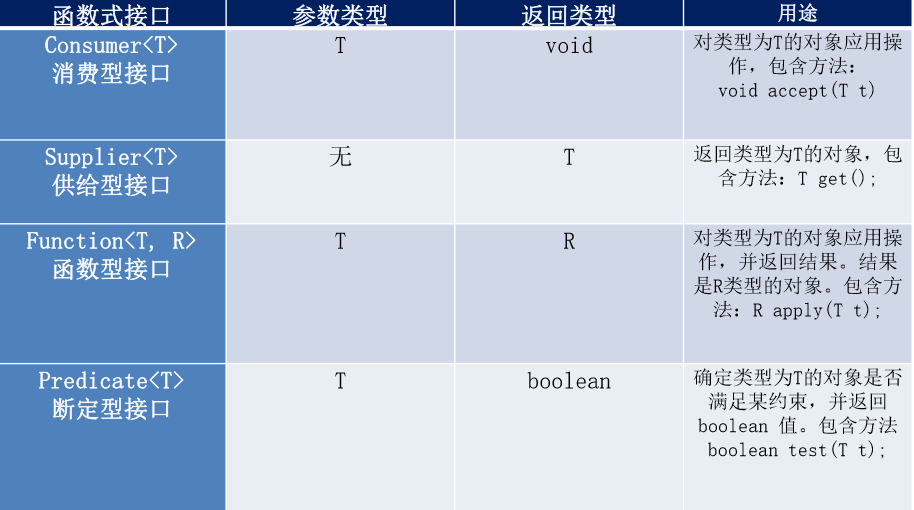
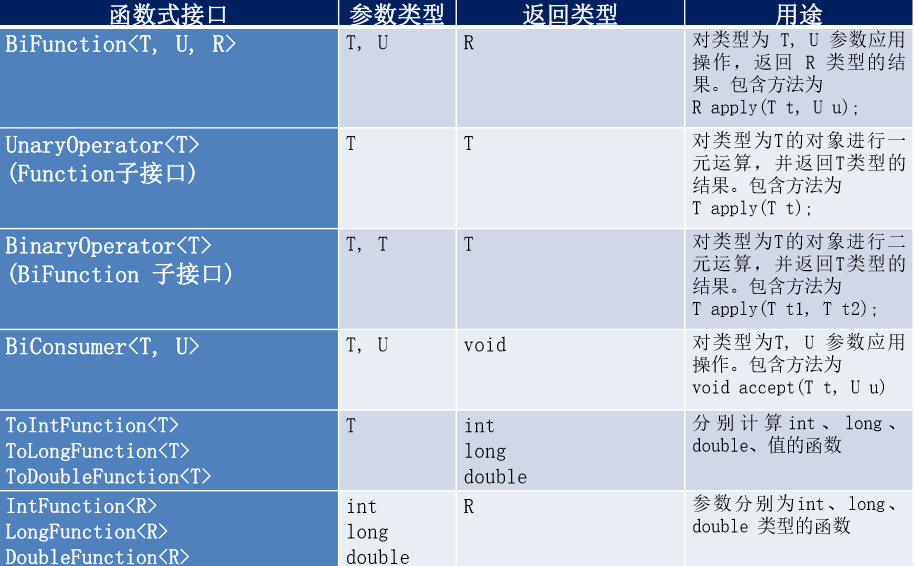
3. Java内治四大核心函数式接口
3. 方法引用与构造器引用
1. 方法引用
当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!
(实现抽象方法的参数列表,必须与方法引用方法的参数列表保持一致!)
方法引用:使用操作符 “::” 将方法名和对象或类的名字分隔开来。 如下三种主要使用情况:
对象::实例方法
类::静态方法
类::实例方法
1 | () -> System.out.println(x); |
注意:当需要引用方法的第一个参数是调用对象,并且第二个参数是需要引
用方法的第二个参数(或无参数)时:ClassName::methodName
2. 构造器引用
格式: ClassName::new
与函数式接口相结合,自动与函数式接口中方法兼容。 可以把构造器引用赋值给定义的方法,与构造器参数列表要与接口中抽象方法的参数列表一致!
例如:
1 | Function<Integer,MyClass> fun = (n) -> new MyClass(n); |
3. 数字引用
格式: type[] :: new
例如:
1 | Function<Integer,Integer[]> fun = (n) -> new Integer(n); |
4. Stream API
1. 了解Stream
Java8中有两大最为重要的改变。第一个是 Lambda 表达式;另外一 个则是 Stream API(java.util.stream.*)。 Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
*流(Stream)是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
*
“集合讲的是数据,流讲的是计算!”
- Stream 自己不会存储元素。
- Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
2. Stream三步骤
创建 Stream
一个数据源(如:集合、数组),获取一个流中间操作
一个中间操作链,对数据源的数据进行处理终端操作
一个终止操作,执行中间操作链,并产生结果
3. 创建Stream
1. Collection 创建流
default Stream
stream() : 返回一个顺序流 default Stream
parallelStream() : 返回一个并行流
2. 数组 创建流(Arrays的静态方法stream()创建)
- static
Stream stream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)
3. 由值创建流
可以使用静态方法 Stream.of(), 通过显示值 创建一个流。它可以接收任意数量的参数。
- public static
Stream of(T… values) : 返回一个流
4. 由函数创建流:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
- 迭代
public static
- 生成
public static
4. Stream 的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水 线上触发终止操作,否则中间操作不会执行任何的处理! 而在终止操作时一次性全部处理,称为“惰性求值”。
筛选与切片
映射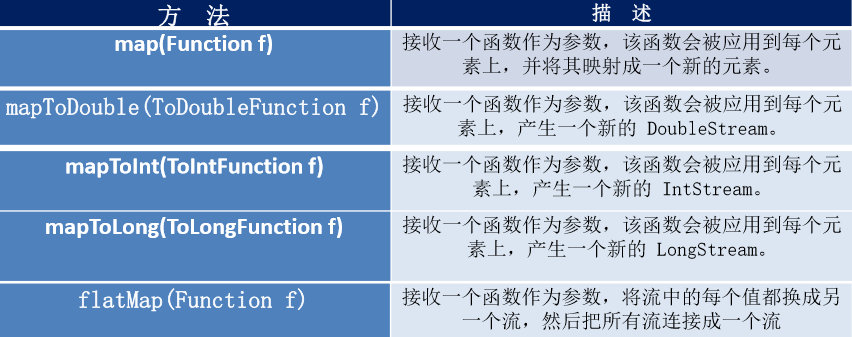
排序
5. Stream 的终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的 值,例如:List、Integer,甚至是 void 。
查找与匹配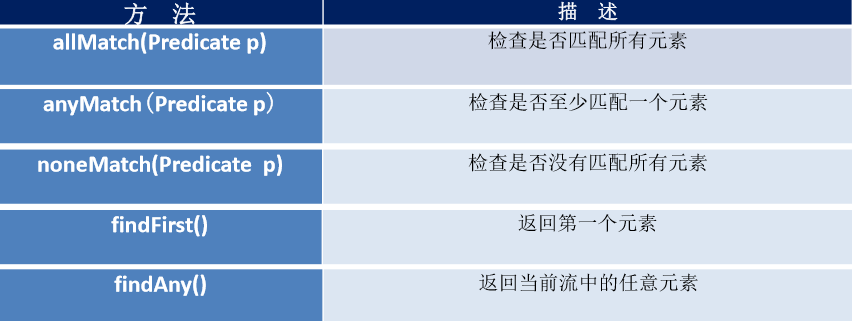
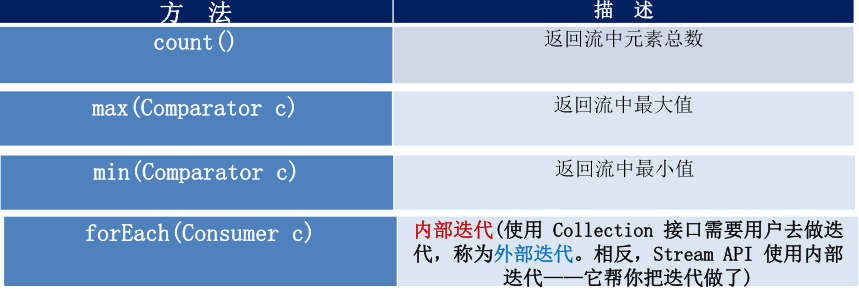
归约
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它 来进行网络搜索而出名。
收集
Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到 List、Set、Map)。但是 Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:


6. 并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分 别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并 行操作。Stream API 可以声明性地通过 parallel() 与 sequential() 在并行流与顺序流之间进行切换。
7. 了解 Fork/Join 框架
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总.
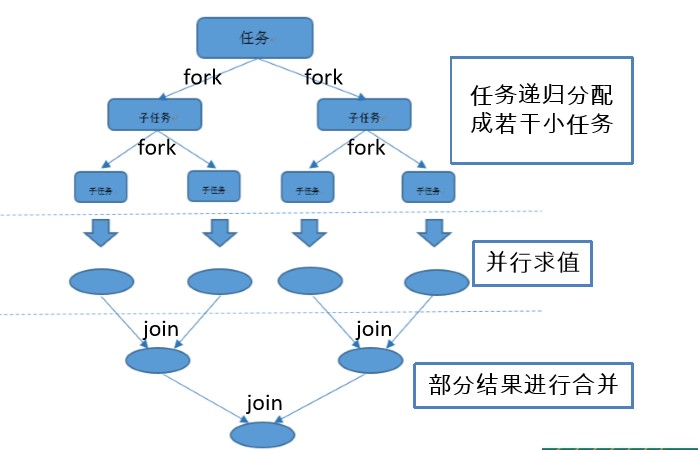
8. Fork/Join 框架与传统线程池的区别
采用 “工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的
处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因
无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果
某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子
问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程
的等待时间,提高了性能.
5. 新时间日期API
- LocalDate、LocalTime、LocalDateTime 类的实 例是不可变的对象,分别表示使用 ISO-8601日 历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息。也不包含与时区相关的信息。
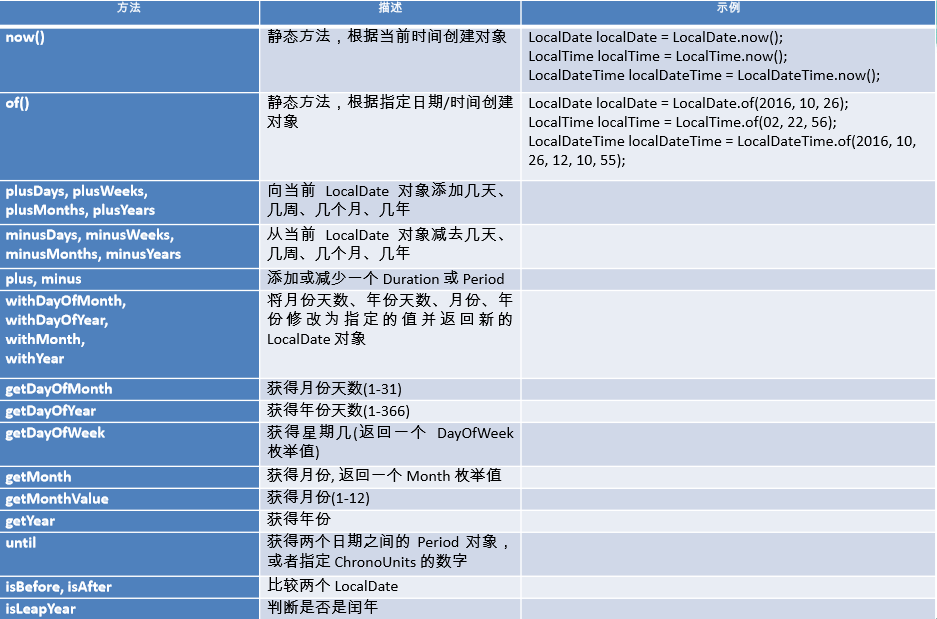
Instant 时间戳
- 用于“时间戳”的运算。它是以Unix元年(传统 的设定为UTC时区1970年1月1日午夜时分)开始 所经历的描述进行运算
Duration 和 Period
Duration:用于计算两个“时间”间隔
Period:用于计算两个“日期”间隔
日期的操纵
TemporalAdjuster : 时间校正器。有时我们可能需要获 取例如:将日期调整到“下个周日”等操作。
TemporalAdjusters : 该类通过静态方法提供了大量的常 用 TemporalAdjuster 的实现。
例如获取下个周日:
1 | LocalDate nextSunday = LocalDate.now().with( |
解析与格式化
java.time.format.DateTimeFormatter 类:该类提供了三种 格式化方法:
预定义的标准格式
语言环境相关的格式
自定义的格式
时区的处理
- Java8 中加入了对时区的支持,带时区的时间为分别为:
ZonedDate、ZonedTime、ZonedDateTime
其中每个时区都对应着 ID,地区ID都为 “{区域}/{城市}”的格式
例如 :Asia/Shanghai 等
ZoneId:该类中包含了所有的时区信息
getAvailableZoneIds() : 可以获取所有时区时区信息
of(id) : 用指定的时区信息获取 ZoneId 对象
与传统日期处理的转换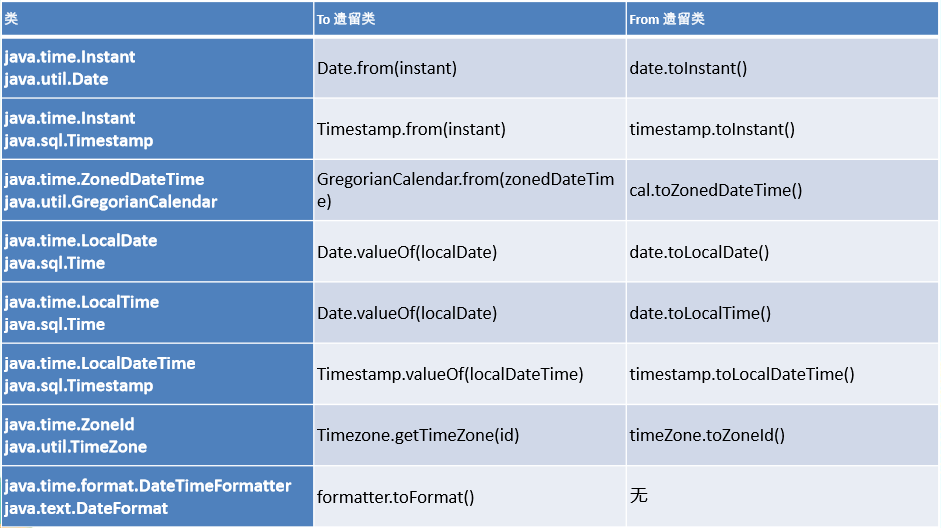
6. 接口中的默认方法与静态方法
1. 接口中的默认方法
Java 8中允许接口中包含具有具体实现的方法,该方法称为 “默认方法”,默认方法使用 default 关键字修饰。
1 | 例如: |
*接口默认方法的”类优先”原则 *
若一个接口中定义了一个默认方法,而另外一个父类或接口中 又定义了一个同名的方法时
选择父类中的方法。如果一个父类提供了具体的实现,那么 接口中具有相同名称和参数的默认方法会被忽略。
接口冲突。如果一个父接口提供一个默认方法,而另一个接 口也提供了一个具有相同名称和参数列表的方法(不管方法 是否是默认方法),那么必须覆盖该方法来解决冲突
1 | interface MyFunc{ |
2. 接口中的静态方法
Java8 中,接口中允许添加静态方法
例如:
1 | interface Named{ |
7. 其他新特性
Optional 类
Optional
常用方法:
Optional.of(T t) : 创建一个 Optional 实例
Optional.empty() : 创建一个空的 Optional 实例
Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则创建空实例
isPresent() : 判断是否包含值
orElse(T t) : 如果调用对象包含值,返回该值,否则返回t
orElseGet(Supplier s) :如果调用对象包含值,返回该值,否则返回 s 获取的值
map(Function f): 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty()
flatMap(Function mapper):与 map 类似,要求返回值必须是Optional
重复注解与类型注解
Java 8对注解处理提供了两点改进:可重复的注解及可用于类型的注解。
1 | @Target({TYPE,FIELD,METHOD,PARAMETER,CONSTRUCTOR,LOCAL_VARIABLE}) |
练习题
1 交易员
1 | public class Trader { |
更多练习参考网络
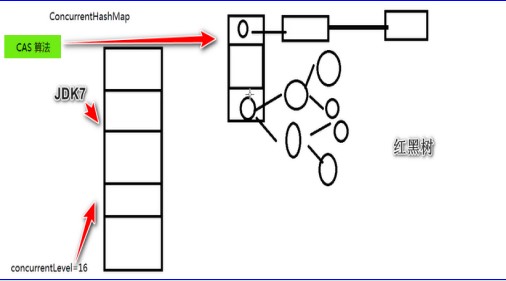
8. java8红黑树
HashMap数据结构
回顾:HashSet是基于HashCode实现元素不重复的。当插入元素的哈希码相同时,会调用equals方法进行二次比较,如果相同,则新值替旧值。如果不同,则以链表的形式挂在当前元素所在的位置。
扩容因子:0.75
如果是1 ,则可能永远是只插入到两个位置,形成部分元素的长链表。每次都要在哈希码相同时进行equals比较(哈希碰撞)。降低性能。
如果是<0.75,则可能浪费空间。
数组-链表-红黑树(二叉树的一种)
条件:当碰撞元素个数>8 && 总容量>64 将其转换为红黑树
碰撞元素个数:一个数组元素上所挂载的(链表)元素个数。
JDK7是数组->链表:一个数组元素上所挂载的(链表)元素个数。
JDK8是数组-链表: 当转变为红黑树时,添加的效率变低。其他效率都高了。平衡二叉树(比当前值与节点值的大小)
扩容是:原来表会计算hashcode值进行元素的再次填充。
现在只需要找原来表的总长度+当前所在的位置,就是当前扩容后的位置。(不需要再次进行哈希计算)。
ConcurrentHashMap:效率提高
JDK7: ConcurrentLevel = 16
JDK8:CAS算法
9. CompletableFuture
CompletableFuture类实现了CompletionStage和Future接口。Future是Java 5添加的类,用来描述一个异步计算的结果,但是获取一个结果时方法较少,要么通过轮询isDone,确认完成后,调用get()获取值,要么调用get()设置一个超时时间。但是这个get()方法会阻塞住调用线程,这种阻塞的方式显然和我们的异步编程的初衷相违背。
为了解决这个问题,JDK吸收了guava的设计思想,加入了Future的诸多扩展功能形成了CompletableFuture。
CompletionStage是一个接口,从命名上看得知是一个完成的阶段,它里面的方法也标明是在某个运行阶段得到了结果之后要做的事情。
1. Future+Callable
在JDK1.5已经提供了Future和Callable的实现,可以用于阻塞式获取结果,如果想要异步获取结果,通常都会以轮询的方式去获取结果,如下:
1 | //定义一个异步任务 |
从上面的形式看来轮询的方式会耗费无谓的CPU资源,而且也不能及时地得到计算结果.所以要实现真正的异步,上述这样是完全不够的,在Netty中,我们随处可见异步编程
1 | ChannelFuture f = serverBootstrap.bind(port).sync(); |
而JDK1.8中的CompletableFuture就为我们提供了异步函数式编程,CompletableFuture提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合CompletableFuture的方法。
2. Future扩展
1. 创建CompletableFuture对象
CompletableFuture提供了四个静态方法用来创建CompletableFuture对象:
1 | public static CompletableFuture<Void> runAsync(Runnable runnable) |
Asynsc表示异步,而supplyAsync与runAsync不同在于前者异步返回一个结果,后者是void.第二个函数第二个参数表示是用我们自己创建的线程池,否则采用默认的ForkJoinPool.commonPool()作为它的线程池.其中Supplier是一个函数式接口,代表是一个生成者的意思,传入0个参数,返回一个结果
1 | CompletableFuture<String> future = CompletableFuture.supplyAsync(()->{ |
2. 主动计算
以下4个方法用于获取结果
1 | //同步获取结果 |
getNow有点特殊,如果结果已经计算完则返回结果或者抛出异常,否则返回给定的valueIfAbsent值。join()与get()区别在于join()返回计算的结果或者抛出一个unchecked异常(CompletionException),而get()返回一个具体的异常.
- 主动触发计算
1 | public boolean complete(T value) |
上面方法表示当调用CompletableFuture.get()被阻塞的时候,那么这个方法就是结束阻塞,并且get()获取设置的value.
1 |
|
3. 计算结果完成时的处理
1 | public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action) |
1 | future.whenCompleteAsync((v,e)->{ |
- handle()
1 | public <U> CompletableFuture<U> handle(BiFunction<? super T,Throwable,? extends U> fn) |
4. CompletableFuture的组合
- thenApply
当计算结算完成之后,后面可以接继续一系列的thenApply,来完成值的转化.
1 | public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn) |
它们与handle方法的区别在于handle方法会处理正常计算值和异常,因此它可以屏蔽异常,避免异常继续抛出。而thenApply方法只是用来处理正常值,因此一旦有异常就会抛出。
1 | CompletableFuture<String> future = CompletableFuture.supplyAsync(()->{ |
5. CompletableFuture的Consumer
只对CompletableFuture的结果进行消费,无返回值,也就是最后的CompletableFuture是void.
1 | public CompletableFuture<Void> thenAccept(Consumer<? super T> action) |
1 | //入参为原始的CompletableFuture的结果. |
- thenAcceptBoth
这个方法用来组合两个CompletableFuture,其中一个CompletableFuture等待另一个CompletableFuture的结果.
1 | CompletableFuture<String> future = CompletableFuture.supplyAsync(()->{ |
6. Either和ALL
thenAcceptBoth是当两个CompletableFuture都计算完成,而我们下面要了解的方法applyToEither是当任意一个CompletableFuture计算完成的时候就会执行。
1 | Random rand = new Random(); |
如果想组合超过2个以上的CompletableFuture,allOf和anyOf可能会满足你的要求.allOf方法是当所有的CompletableFuture都执行完后执行计算。anyOf方法是当任意一个CompletableFuture执行完后就会执行计算,计算的结果相同。
7. 练习
1. 进行变换
1 | public <U> CompletionStage<U> thenApply(Function<? super T,? extends U> fn); |
首先说明一下已Async结尾的方法都是可以异步执行的,如果指定了线程池,会在指定的线程池中执行,如果没有指定,默认会在ForkJoinPool.commonPool()中执行。关键的入参只有一个Function,它是函数式接口,所以使用Lambda表示起来会更加优雅。它的入参是上一个阶段计算后的结果,返回值是经过转化后结果。
例如:
1 | @Test |
2. 进行消耗
1 | public CompletionStage<Void> thenAccept(Consumer<? super T> action); |
thenAccept是针对结果进行消耗,因为他的入参是Consumer,有入参无返回值。
例如:
1 | @Test |
3. 对上一步的计算结果不关心,执行下一个操作。
1 | public CompletionStage<Void> thenRun(Runnable action); |
thenRun它的入参是一个Runnable的实例,表示当得到上一步的结果时的操作。
例如:
1 | @Test |
4. 结合两个CompletionStage的结果,进行转化后返回
1 | public <U,V> CompletionStage<V> thenCombine(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn); |
它需要原来的处理返回值,并且other代表的CompletionStage也要返回值之后,利用这两个返回值,进行转换后返回指定类型的值。
例如:
1 | @Test |
5. 结合两个CompletionStage的结果,进行消耗
1 | public <U> CompletionStage<Void> thenAcceptBoth(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action); |
它需要原来的处理返回值,并且other代表的CompletionStage也要返回值之后,利用这两个返回值,进行消耗。
例如:
1 | @Test |
6. 在两个CompletionStage都运行完执行。
1 | public CompletionStage<Void> runAfterBoth(CompletionStage<?> other,Runnable action); |
不关心这两个CompletionStage的结果,只关心这两个CompletionStage执行完毕,之后在进行操作(Runnable)。
例如:
1 | @Test |
7. 两个CompletionStage,谁计算的快,我就用那个CompletionStage的结果进行下一步的转化操作
1 | public <U> CompletionStage<U> applyToEither(CompletionStage<? extends T> other,Function<? super T, U> fn); |
我们现实开发场景中,总会碰到有两种渠道完成同一个事情,所以就可以调用这个方法,找一个最快的结果进行处理。
例如:
1 | @Test |
8. 两个CompletionStage,谁计算的快,我就用那个CompletionStage的结果进行下一步的消耗操作
1 | public CompletionStage<Void> acceptEither(CompletionStage<? extends T> other,Consumer<? super T> action); |
例如:
1 | @Test |
9. 两个CompletionStage,任何一个完成了都会执行下一步的操作(Runnable)
1 | public CompletionStage<Void> runAfterEither(CompletionStage<?> other,Runnable action); |
例如:
1 | @Test |
10. 当运行时出现了异常,可以通过exceptionally进行补偿
1 | public CompletionStage<T> exceptionally(Function<Throwable, ? extends T> fn); |
例如:
1 | @Test |
11. 当运行完成时,对结果的记录。这里的完成时有两种情况,一种是正常执行,返回值。另外一种是遇到异常抛出造成程序的中断。这里为什么要说成记录,因为这几个方法都会返回CompletableFuture,当Action执行完毕后它的结果返回原始的CompletableFuture的计算结果或者返回异常。所以不会对结果产生任何的作用
1 | public CompletionStage<T> whenComplete(BiConsumer<? super T, ? super Throwable> action); |
例如:
1 | @Test |
这里也可以看出,如果使用了exceptionally,就会对最终的结果产生影响,它没有口子返回如果没有异常时的正确的值,这也就引出下面我们要介绍的handle。
12. 运行完成时,对结果的处理。这里的完成时有两种情况,一种是正常执行,返回值。另外一种是遇到异常抛出造成程序的中断
1 | public <U> CompletionStage<U> handle(BiFunction<? super T, Throwable, ? extends U> fn); |
例如:
出现异常时
1 | @Test |
未出现异常时
1 | @Test |