背景
在过往的单体应用时代,我们所有组件都部署到一台服务器中,那时日志管理平台的需求可能并没有那么强烈,我们只需要登录到一台服务器通过shell命令就可以很方便的查看系统日志,并快速定位问题。随着互联网的发展,互联网已经全面渗入到生活的各个领域,使用互联网的用户量也越来越多,单体应用已不能够支持庞大的用户的并发量,那么将单体应用进行拆分,通过水平扩展来支持庞大用户的使用迫在眉睫,微服务概念就是在类似这样的阶段诞生,在微服务盛行的互联网技术时代,单个应用被拆分为多个应用,每个应用集群部署进行负载均衡,那么如果某项业务发生系统错误,开发或运维人员还是以过往单体应用方式登录一台一台登录服务器查看日志来定位问题,这种解决线上问题的效率可想而知。日志管理平台的建设就显得极其重要。通过Logstash去收集每台服务器日志文件,然后按定义的正则模板过滤后传输到Kafka或redis,然后由另一个Logstash从KafKa或redis读取日志存储到elasticsearch中创建索引,最后通过Kibana展示给开发者或运维人员进行分析。这样大大提升了运维线上问题的效率。除此之外,还可以将收集的日志进行大数据分析,得到更有价值的数据给到高层进行决策。
优点
ELK 提供的功能满足使用要求,并有较高的扩展性。
ELK 为一套开源项目,较低的维护成本。
1 相关概念
ELK 指的是一套解决方案,是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写,Beats 是 ELK 协议栈的新成员。
E:代表 Elasticsearch,负责日志的存储和检索;
L:代表 Logstash,负责日志的收集、过滤和格式化;
K:代表 Kibana,负责日志数据的可视化;
Beats:是一类轻量级数据采集器;
其中,目前 Beats 家族根据功能划分,主要包括 4 种:
- Filebeat:负责收集文件数据;
- Packetbeat:负责收集网络流量数据;
- Metricbeat:负责收集系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据;
- Winlogbeat:负责收集 Windows 事件日志数据;
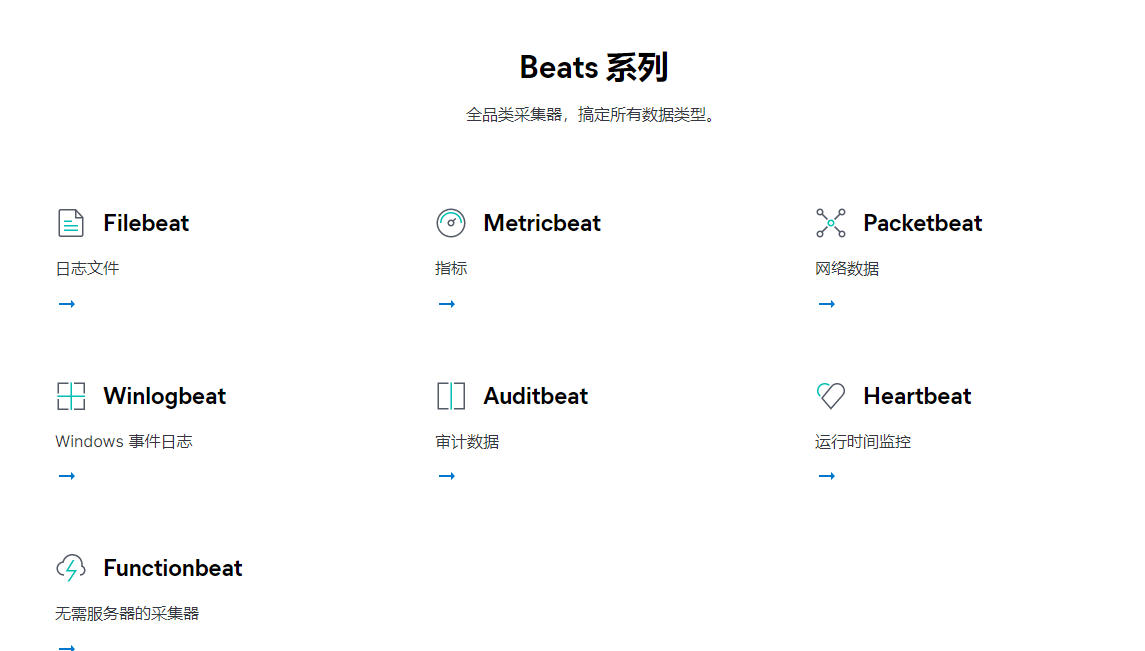
在我们将要搭建的集中式日志平台系统中,就使用了 Filebeat 作为日志文件收集工具,Filebeat 可以很方便地收集 Nginx、Mysql、Redis、Syslog 等应用的日志文件。
2 日志平台架构
ELK 集中日志平台也是经过一次次演变,它的大概收集过程如下:
1 部署在应用服务器上的数据采集器,近实时收集日志数据推送到日志过滤节点的 Logstash
2 Logstash 再推送格式化的日志数据到 Elasticsearch 存储
3 Kibana 通过 Elasticsearch 集中检索日志并可视化
ES + Logstash + Kibana
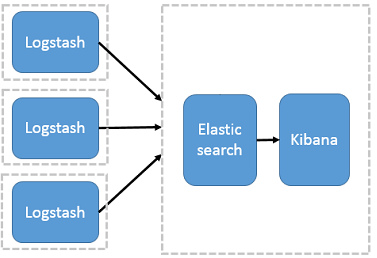
最开始的架构中,由 Logstash 承担数据采集器和过滤功能,并部署在应用服务器。由于 Logstash 对大量日志进行过滤操作,会消耗应用系统的部分性能,带来不合理的资源分配问题;另一方面,过滤日志的配置,分布在每台应用服务器,不便于集中式配置管理。
引入Logstash-forwarder
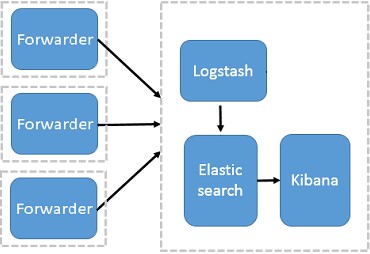
使用该架构,引入 Logstash-forwarder 作为数据采集,Logstash 和应用服务器分离,应用服务器只做数据采集,数据过滤统一在日志平台服务器,解决了之前存在的问题。但是 Logstash-forwarder 和 Logstash 间通信必须由 SSL 加密传输,部署麻烦且系统性能并没有显著提升;另一方面,Logstash-forwarder 的定位并不是数据采集插件,系统不易扩展。
引入Beats
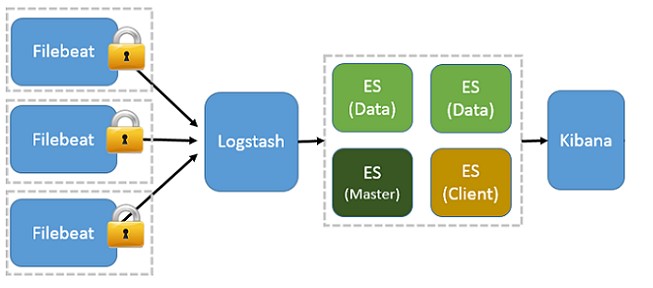
该架构,基于 Logstash-forwarder 架构,将 Logstash-forwarder 替换为 Beats。由于 Beats 的系统性能开销更小,所以应用服务器性能开销可以忽略不计;另一方面,Beats 可以作为数据采集插件形式工作,可以按需启用 Beats 下不同功能的插件,更灵活,扩展性更强。例如,应用服务器只启用 Filebeat,则只收集日志文件数据,如果某天需要收集系统性能数据时,再启用 Metricbeat 即可,并不需要太多的修改和配置。
这种 ELK+Beats 的架构,已经满足大部分应用场景了,但当业务系统庞大,日志数据量较大、较实时时,业务系统就和日志系统耦合在一起了。
引入队列
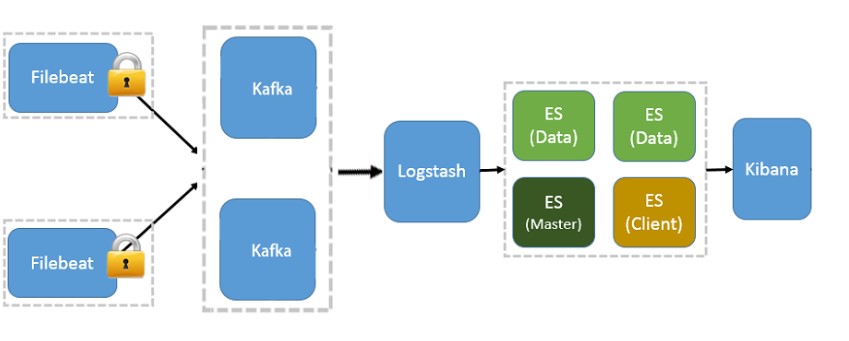
该架构,引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性;另一方面,这样可以系统解耦,具有更好的灵活性和扩展性。
3 经验
成熟的 ELK+Beats 架构,因其扩展性很强,是集中式日志平台的首选方案。在实际部署时,是否引入消息队列,根据业务系统量来确定,早期也可以不引入消息队列,简单部署,后续需要扩展再接入消息队列。
4 ELK概念解读
1 Elasticsearch
软件介绍
Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。
为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 编写,内部采用 Lucene 做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene 做了一层封装,它提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。
当然,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
系统架构
ES核心概念
1 节点 & 集群(Node & Cluster)
Elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个Elasticsearch实例。单个Elasticsearch实例称为一个节点(Node),一组节点构成一个集群(Cluster)。
2 索引(Index)
Elasticsearch 数据管理的顶层单位就叫做 Index(索引),相当于关系型数据库里的数据库的概念。另外,每个Index的名字必须是小写。
3 Shard 分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4 Replia 副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5 全文搜索(Full-text Search)
文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
在全文搜索的世界中,存在着几个庞大的帝国,也就是主流工具,主要有:
- Apache Lucene
- Elasticsearch
- Solr
- Ferret
6 倒排索引(Inverted Index)
该索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。
7 文档(Document)
index里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示。同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
8 类型(Type)
Document 可以分组,比如employee这个 Index 里面,可以按部门分组,也可以按职级分组。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表。
不同的 Type 应该有相似的结构(Schema),性质完全不同的数据(比如 products 和 logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
9 文档元数据(Document metadata)
文档元数据为_index, _type, _id, 这三者可以唯一表示一个文档,_index表示文档在哪存放,_type表示文档的对象类别,_id为文档的唯一标识。
10 字段(Fields)
每个Document都类似一个JSON结构,它包含了许多字段,每个字段都有其对应的值,多个字段组成了一个 Document,可以类比关系型数据库数据表中的字段。
在 Elasticsearch 中,文档(Document)归属于一种类型(Type),而这些类型存在于索引(Index)中,下图展示了Elasticsearch与传统关系型数据库的类比:

对比
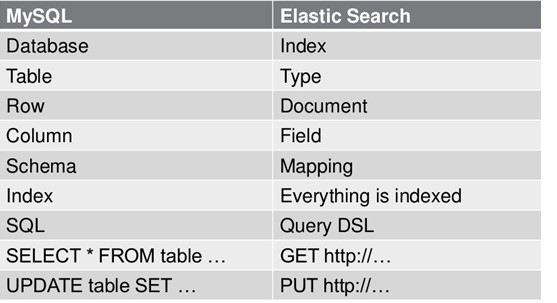
2 Kibana
软件介绍
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图标的形式展现出来,通过改变Elasticsearch查询时间,可以完成动态仪表盘。
使用场景
实时监控
通过 histogram 面板,配合不同条件的多个 queries 可以对一个事件走很多个维度组合出不同的时间序列走势。时间序列数据是最常见的监控报警了。问题分析
关于 elk 的用途,可以参照其对应的商业产品 splunk 的场景:使用 Splunk 的意义在于使信息收集和处理智能化。
使用
搜索和展示信息,可以查看Discover页面。
图表和地图展示,可以查看Visualize。
创建一个仪表盘,可以使用Dashboard
3 Logstash
前言
建议在使用logstash之前先想清楚自己的需求是什么,从哪种数据源同步到哪里,需要经过怎么样的处理。因为logstash版本迭代较快,每个版本的插件都有点区别,比如filter中的http插件在6.6版本以后才有;output到现在(7.1)都没有jdbc的插件,然而你如果想使用output的jdbc插件就需要自己去安装热心人自己写的插件(logstash-output-jdbc),不幸的是,该作者指出没有很多的时间去维护此插件,不能保证6.3以后用户的正常使用。
也就是说,如果你想用output的jdbc,你就必须使用6.3以下(最好5.x)的版本,如果你想用官方filter的http插件,你就得用6.5以上的版本。
如果目标数据源的type为jdbc,则建议安装logstash-5.4.1或6.x一下的版本,因为logstash-output-jdbc只在6.x以下有效.
软件介绍
官方介绍:Logstash is an open source data collection engine with real-time pipelining capabilities。
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash常用于日志关系系统中做日志采集设备
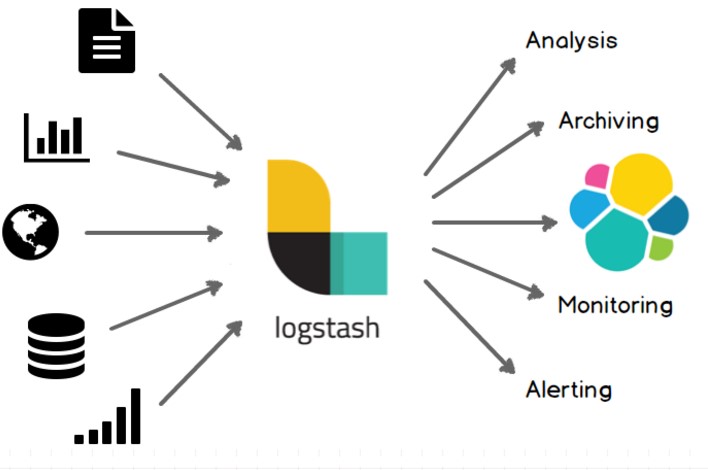
系统架构
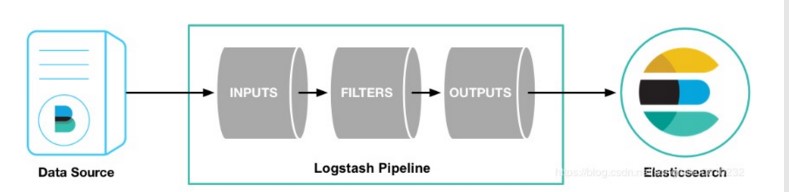
Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
Codecs:Codecs(编码插件)不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline。Logstash不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
其中inputs和outputs支持codecs(coder&decoder)在1.3.0 版之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入 期处理不同类型的数据,所以完整的数据流程应该是:input | decode | filter | encode | output;codec 的引入,使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如:graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等。
集中、转换、存储
输入 :采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据
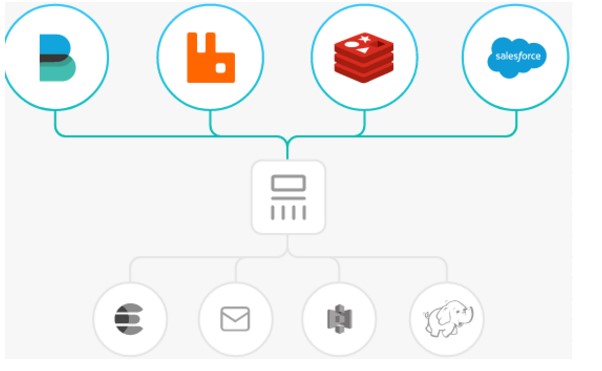
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响
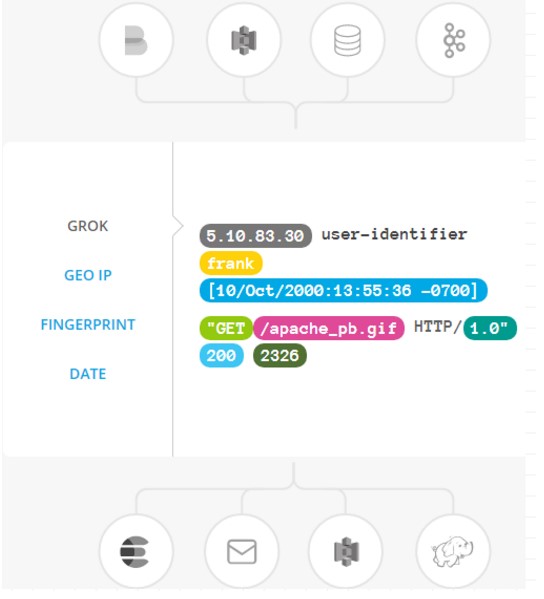
选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。