Author: haoransun
WeChat: SHR—97
图片&知识点来源:B站
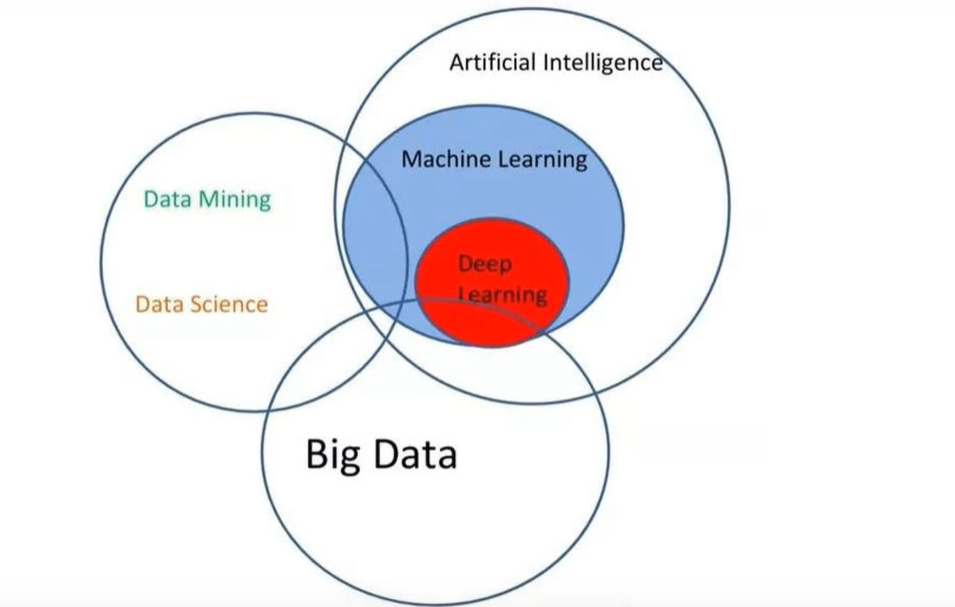
1. 机器学习解决的基本问题
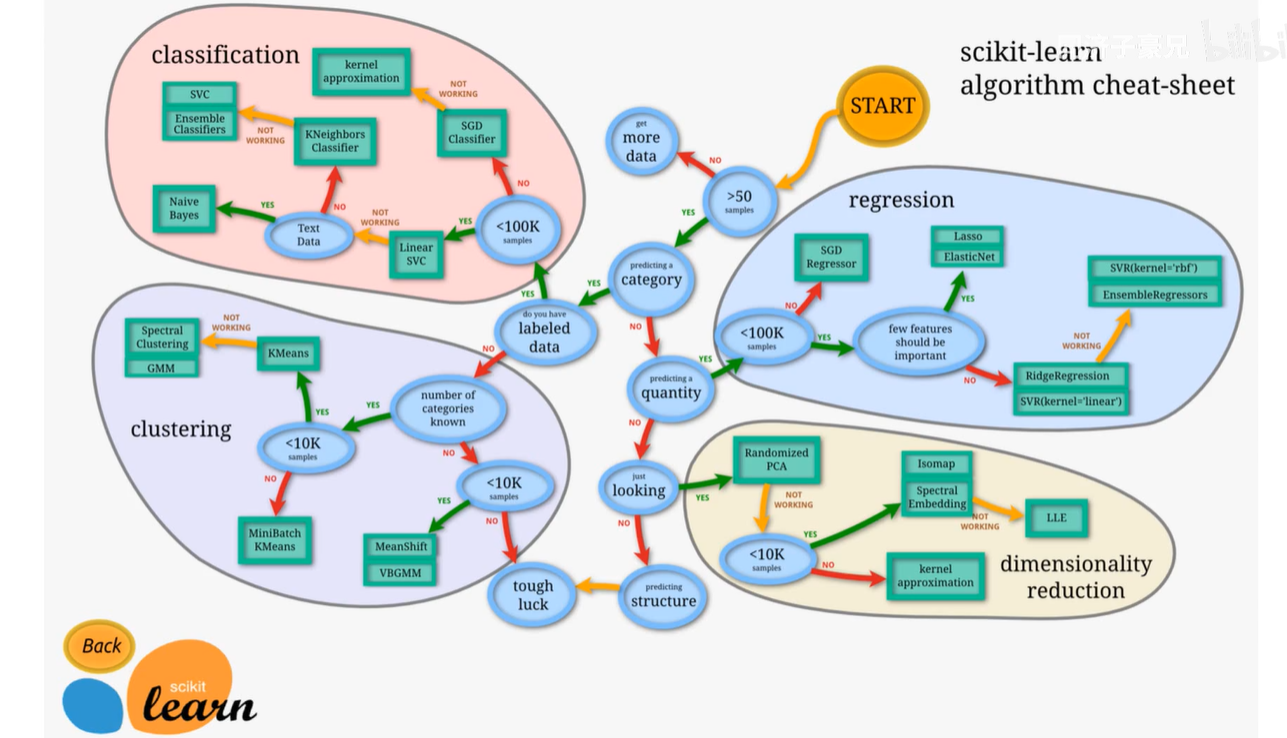
上图是Python中非常著名的数据挖掘和机器学习的工具包-SKLearn官网给出的知识图谱,分为分类、回归、聚类、降维还有强化学习。
分类:把输入映射为离散的类别。KNN、SVM、决策树(DT)、朴素贝叶斯、逻辑回归、深度学习-神经网络、图像分类等等都是解决分类问题的。
分类问题有着自己的评估指标:交叉熵、混淆矩阵、ROC、AUC、F1-Score、准确率-Accuracy、精确率(查准率)-Precision、召回率(查全率)-Recall等
回归:预测一个连续的值,刚刚分类的标签是离散的,而回归的标签是连续的。如输入一个城市的人口,就能预测它的供电量、用水量等。输入一个房子的卧室数量、地段、面积,就能预测出它的房价(著名的波士顿房价数据集)。SVM、DT、线性回归、岭回归、神经网络等等都是解决回归问题的。高中的最小二乘法的回归。
聚类:将无标签数据自组织的聚成一簇一簇。此时是非监督学习,K-means、基于密度的聚类-DBSCAN、谱聚类-SpectralClustering、高斯混合模型等等都可以解决聚类问题。
降维:将高维数据变换成低维数据。如高维降维到2D或3D,便于可视化,人类可以理解的维度,展示数据背后的规律。一个物体有600D,将它压到3D,即用3个维度代表600个维度的数据,难免会有一些信息的损失。如谷歌的Word2Vector,
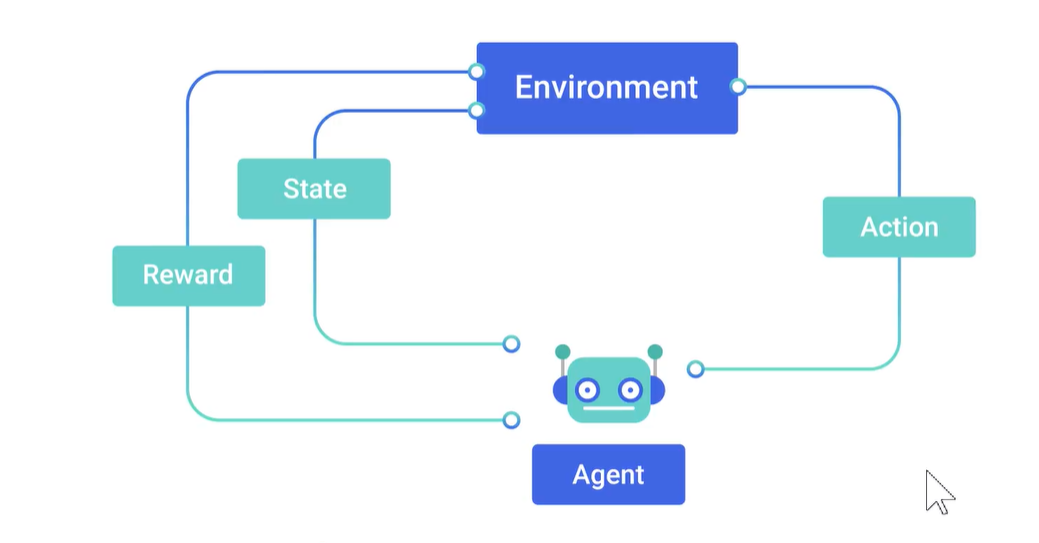
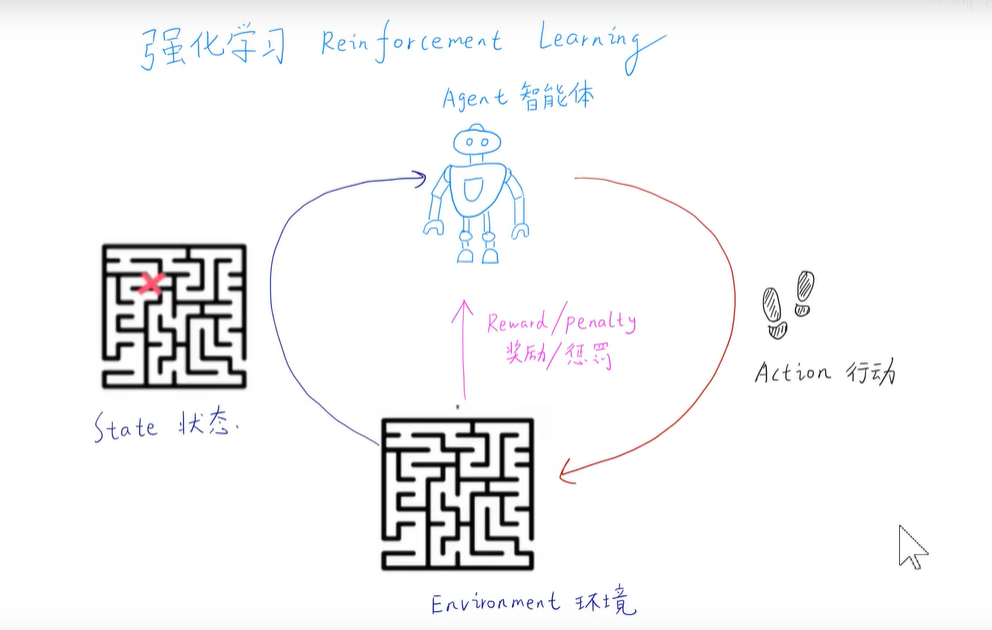
强化学习:独立于上述的监督学习和无监督学习之外的一种,介于他们之间的一种学习。训练一个智能体,它能感知到环境,并且接受环境的奖励/处罚。根据奖励/处罚采取下一步动作,这个动作又会在环境中导致新的奖励/处罚。
强化学习由遗传算法演进而来,模拟了生物在大自然中物竞天择、适者生存的这么一种思想。
神将网络模拟的的人类即哺乳动物大脑皮层中神经元互联的一种拓扑结构。
一个是宏观的自然界,一个是微观的神经元,这其实是人工智能的两种思想。

2. 机器学习解决的基本问题-案例分析
2.1 分类

鸢尾花数据集:最著名的分类数据集之一。输入的是一朵鸢尾花的花瓣长宽、花萼长宽。输出的标签是3种鸢尾花中的某一类。
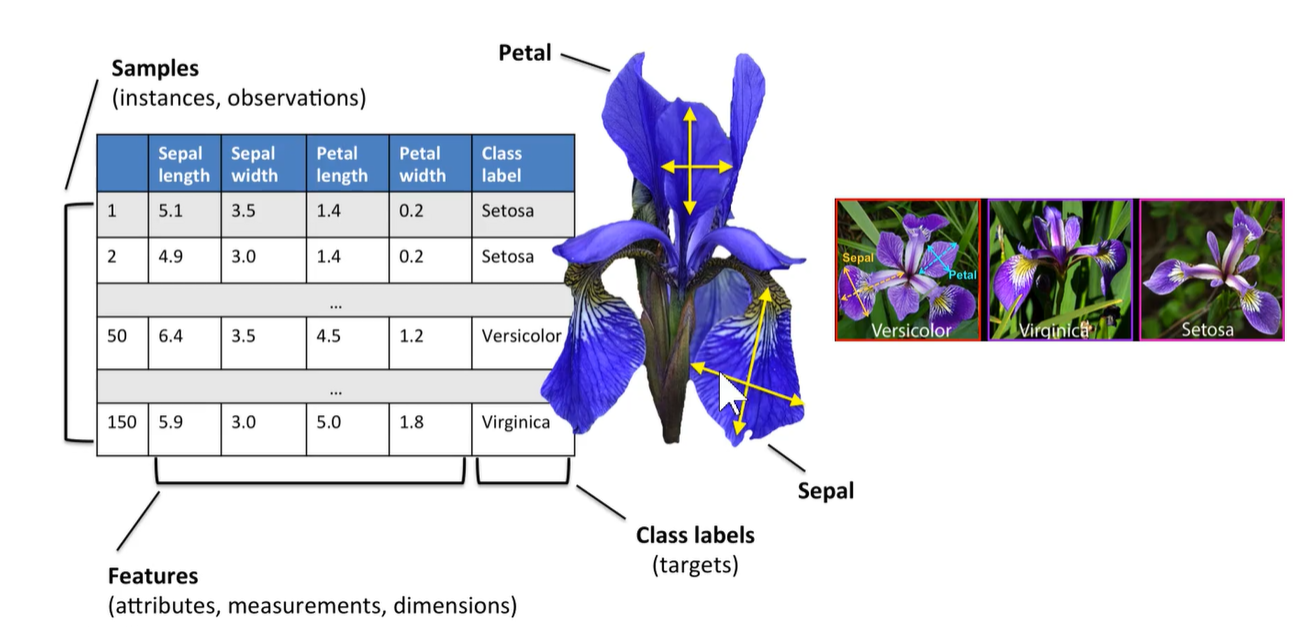
前四列是特征,最后一列是分类。是一个3分类,即多分类问题。鸢尾花数据集从1936年发布以来,已经成为模式识别、机器学习、验证各种各样算法的一个标配数据集。相当于机器学习界的Hello World,人人都知道。
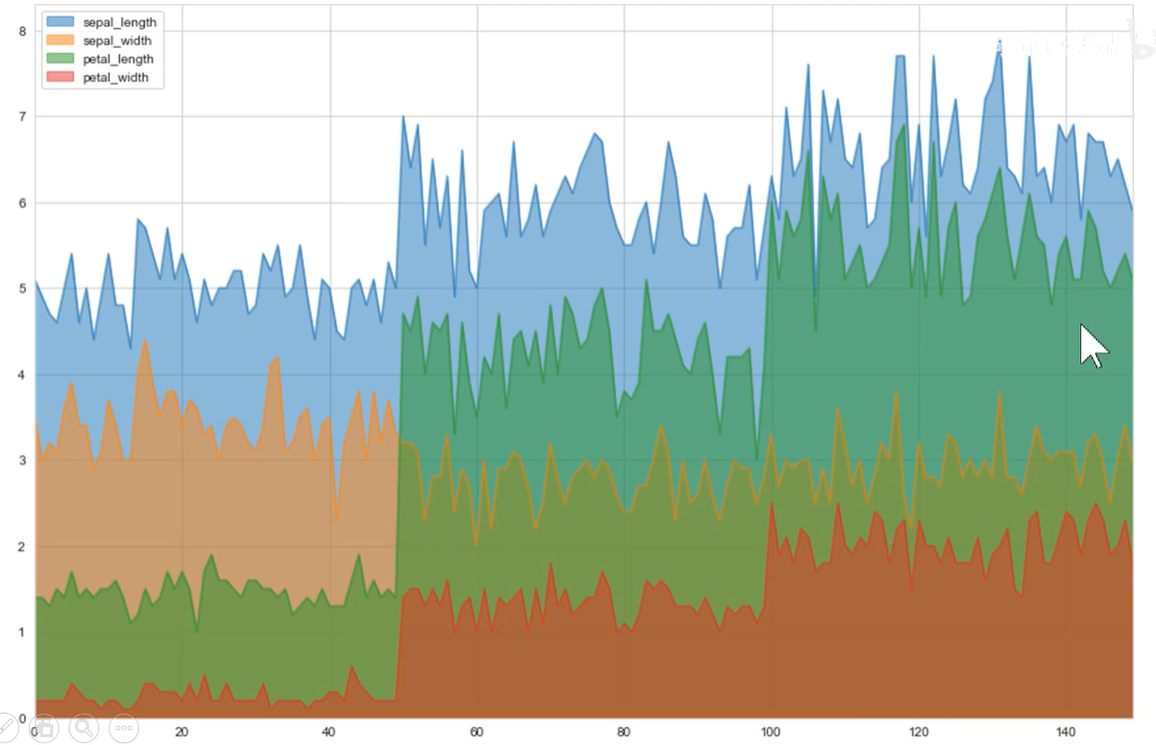
如上图:可以做一些特征的可视化分布。三种鸢尾花的特征分布情况各不相同,根据这些特征预测鸢尾花属于哪类。
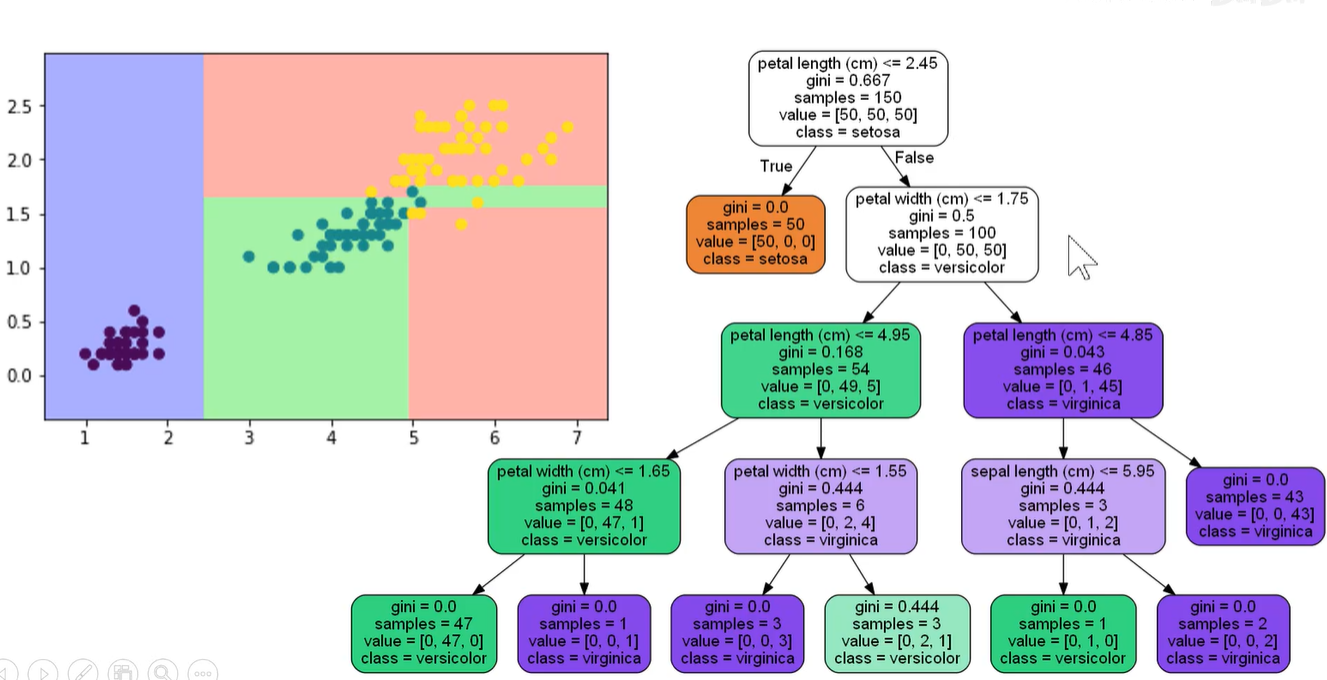
如可以使用决策树来解决鸢尾花分类的问题。
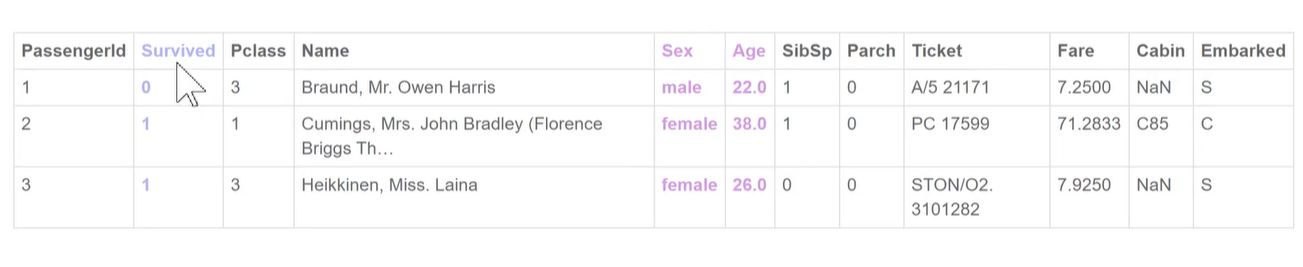
如泰坦尼克号数据集是一个二分类问题,0没有生还,1生还。
2.2 聚类
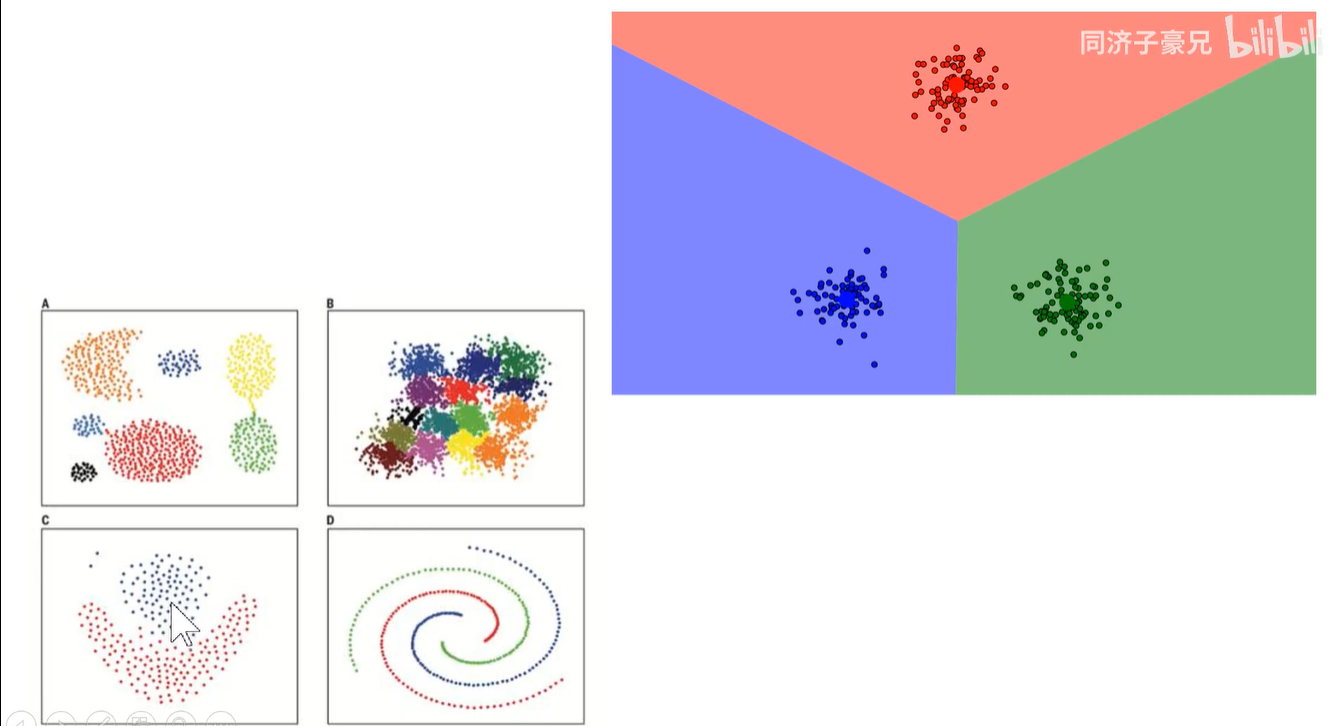
数据无标签,但要将他们自组织的画成一簇一簇的。
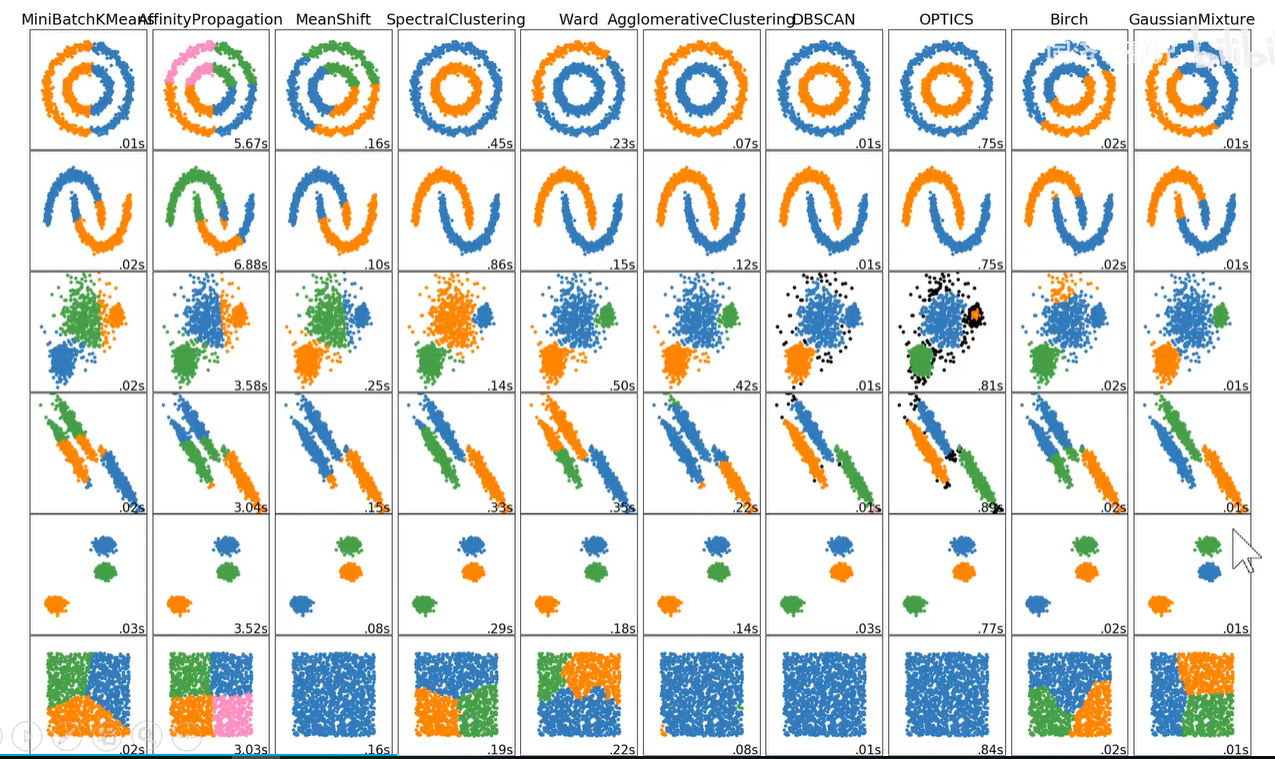
如下图,展示了一些聚类算法效果图,不管运行时间,只管效果,OPTICS聚类效果最好。
首先看最后一行,这个正方形是一坨数据,不应该被分为不同的类别。
再看第一行,内环和外环分别被聚类出来,是比较好的效果。
再看第二行半月牙形的数据,但凡里面的颜色不纯,如第二列第二行,既有绿色、橙色、蓝色,说明聚类效果不理想。
再看第三行数据,DBSCAN也是一种非常优秀的聚类数据,但是他没有把OPTICS中的右上角的一小坨给聚出来。
所以在这样一个案例中,OPTICS是最好的聚类模型。
如下图:是K-Means聚类动图,先随机初始化聚类中心,把属于这一个聚类中心点的均值求出来,把聚类中心移动到均值处,再进行下一步的迭代。像动图中的黑线是三个聚类中心连线的垂直平分线,从垂直平分线上到聚类中心的距离是一样的。
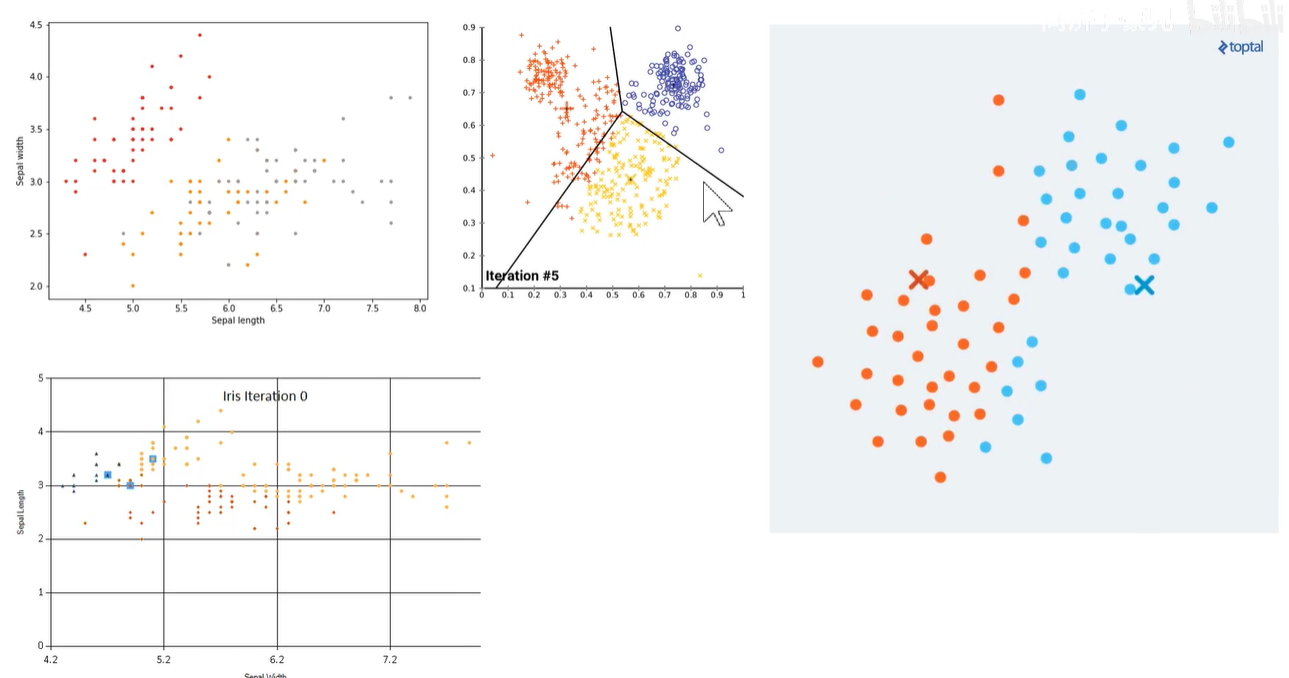
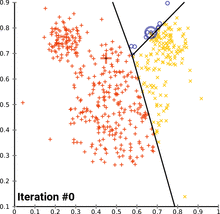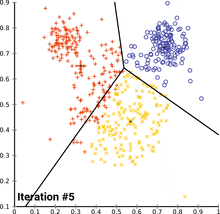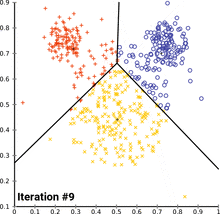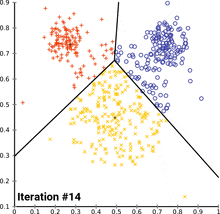
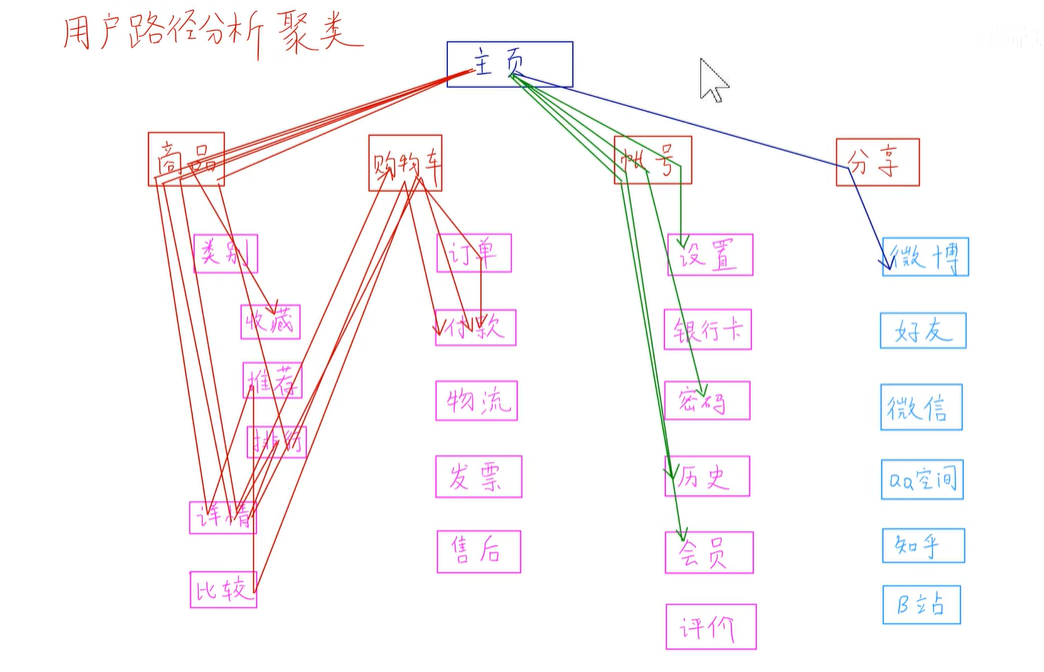
聚类在互联网商品中很常见,如用户路径的行为。
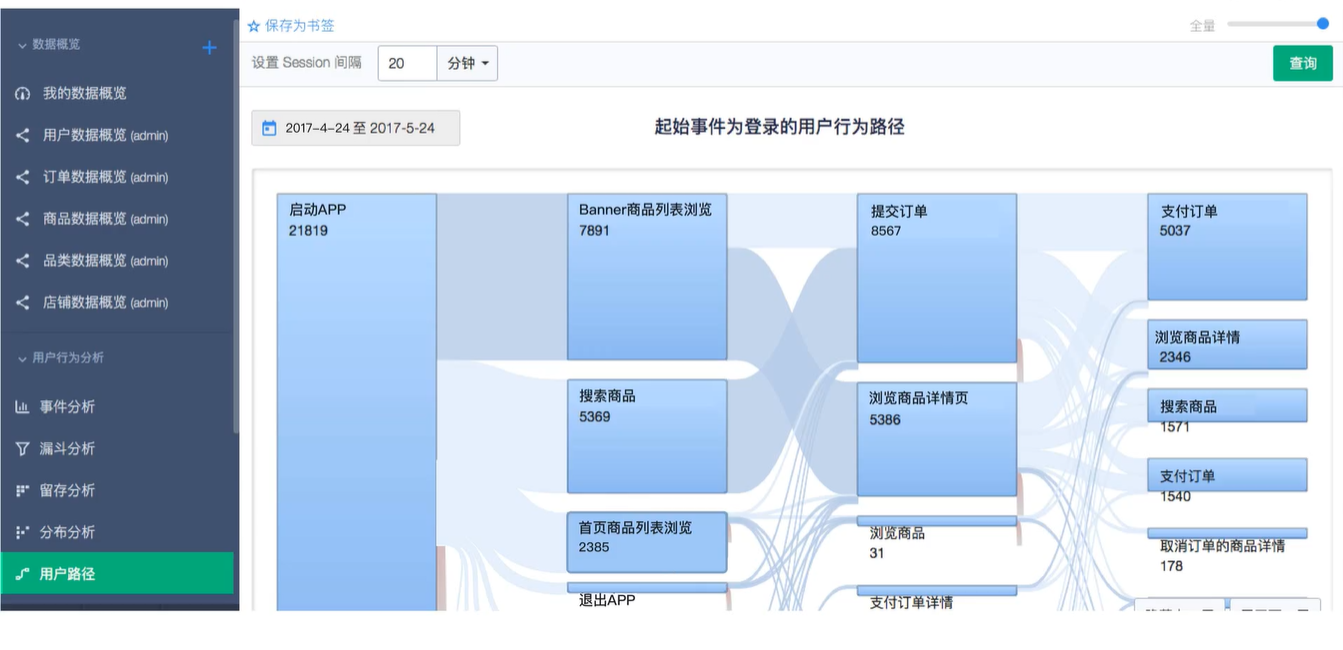
在一个电商网站中,看看大家是不是都走同一条路。红色、绿色、蓝色被聚为3类。由这些聚类可以发现用户数据中自组织的规律,这些数据都是没有标签的,只知道用户的路径。将相似路径聚到一起,就变成了聚类。无监督学习。
2.3 降维
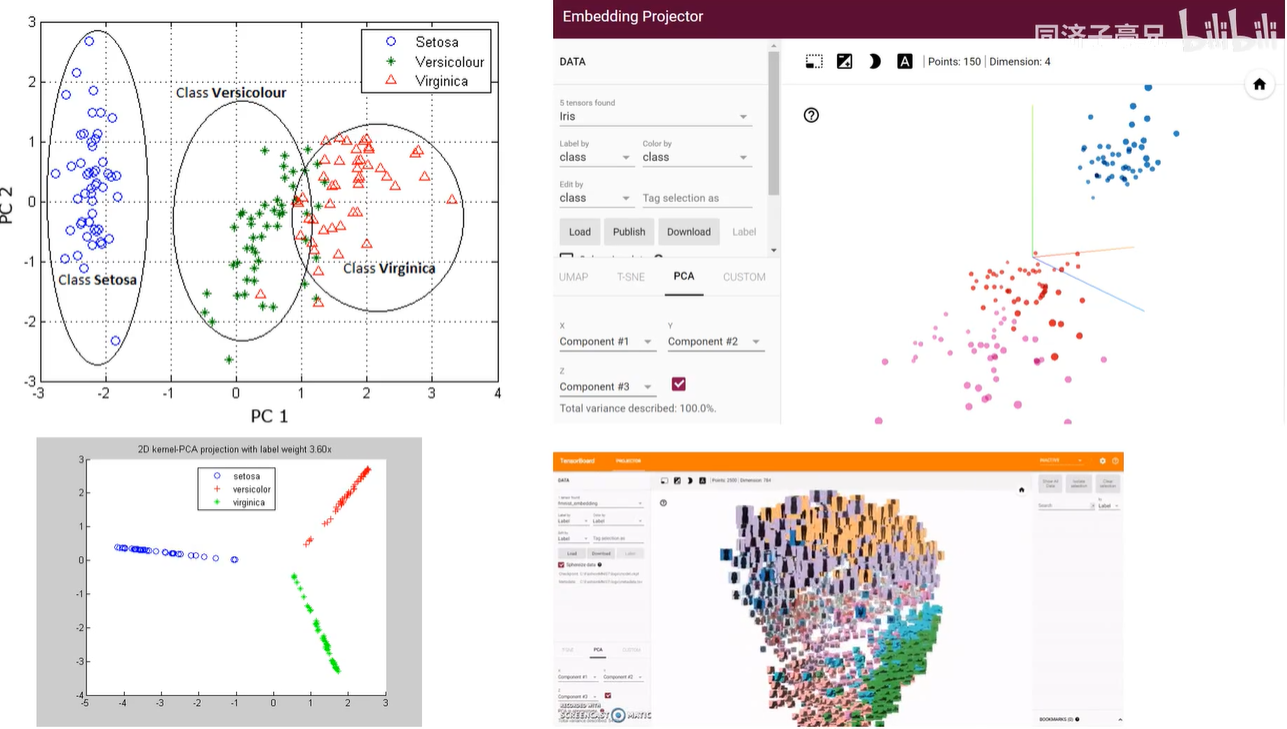
将高维数据压缩到人类可以理解的2D和3D空间,如右下角是10分类的fashion-mnist数据集,有10类的时尚用品,衣服、靴子、包包等。每一张图片都是28x28,大约700+维数据压缩到3维数据,就是展示在右下角中,不同种类确实是被自组织的聚到一起,他没有标签,简单粗暴的使用PCA主成分分析或是T-SNE这样的非线性降维算法将它强行降到3D,之后发现同一类数据确实是挨着比较近的。
右上角是对鸢尾花数据集进行降为,鸢尾花有4个特征:花瓣长宽、花萼长宽,用到PCA降到3D,相当于是在4个特征中找到3个最能代表完整信息的特征,这新的3个特征尽可能使降维时的信息损失减小到最低,能够尽可能完整的反应4D空间中数据的分布。可以看出,降到3D后,不同的鸢尾花确实是被分到不同的簇中,并且同一类鸢尾花之间的距离是比较小的。能降到3D,就能进一步降到2D,左上角就是2D平面。


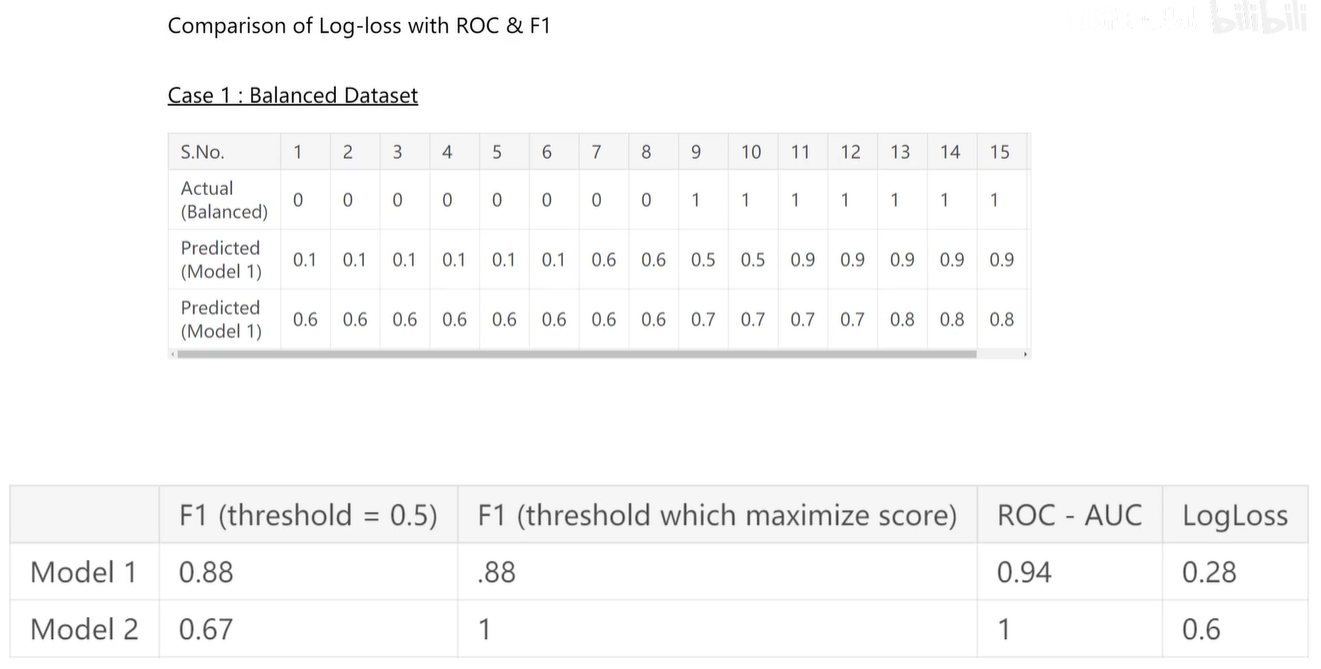
3. 分类器评估指标



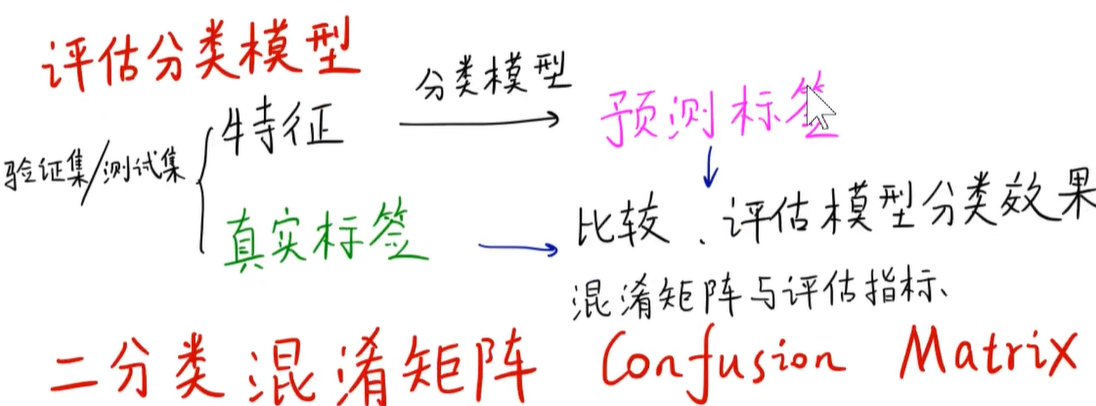



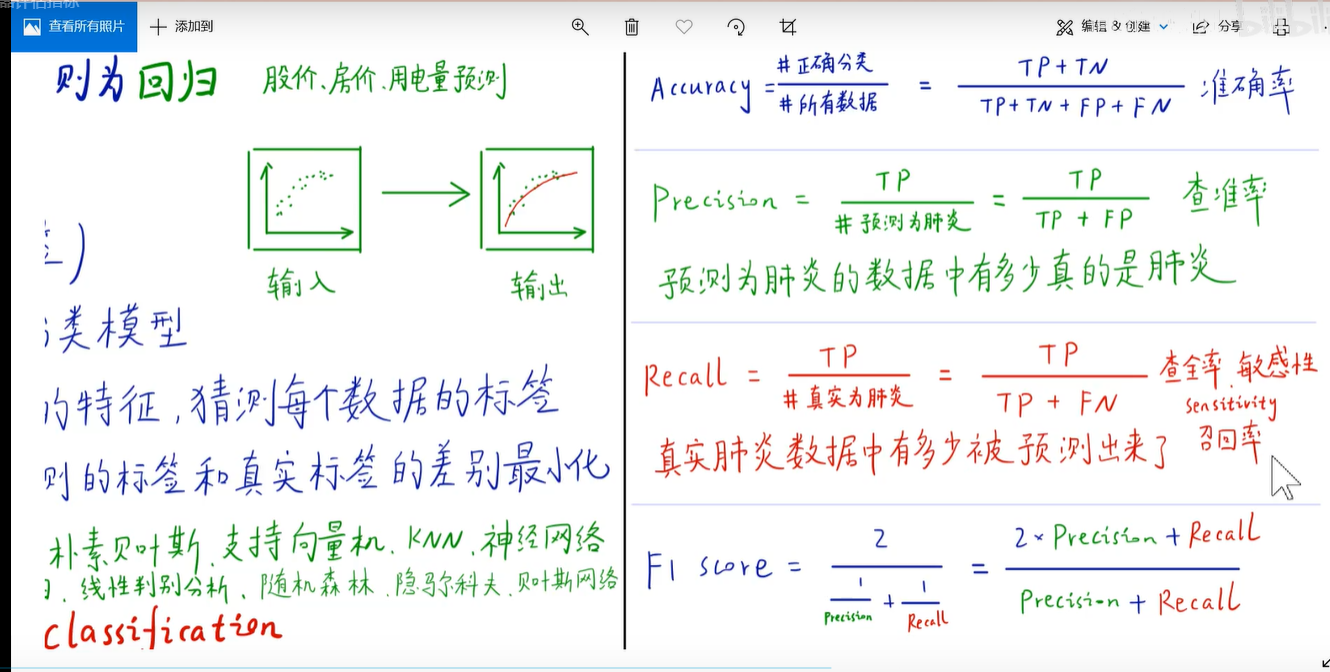

4. 混淆矩阵详解
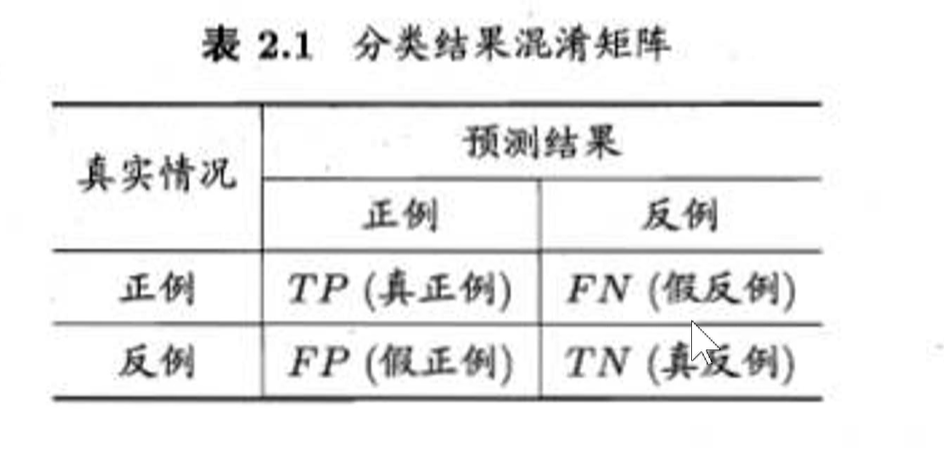
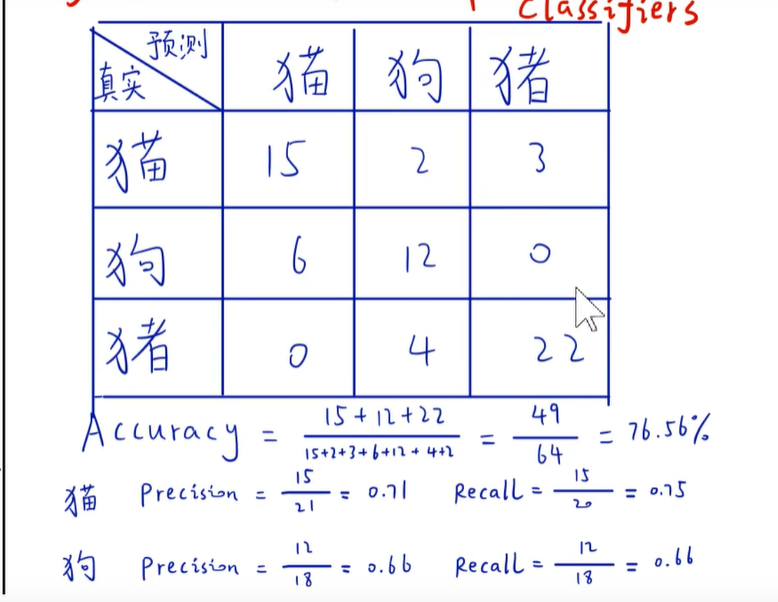
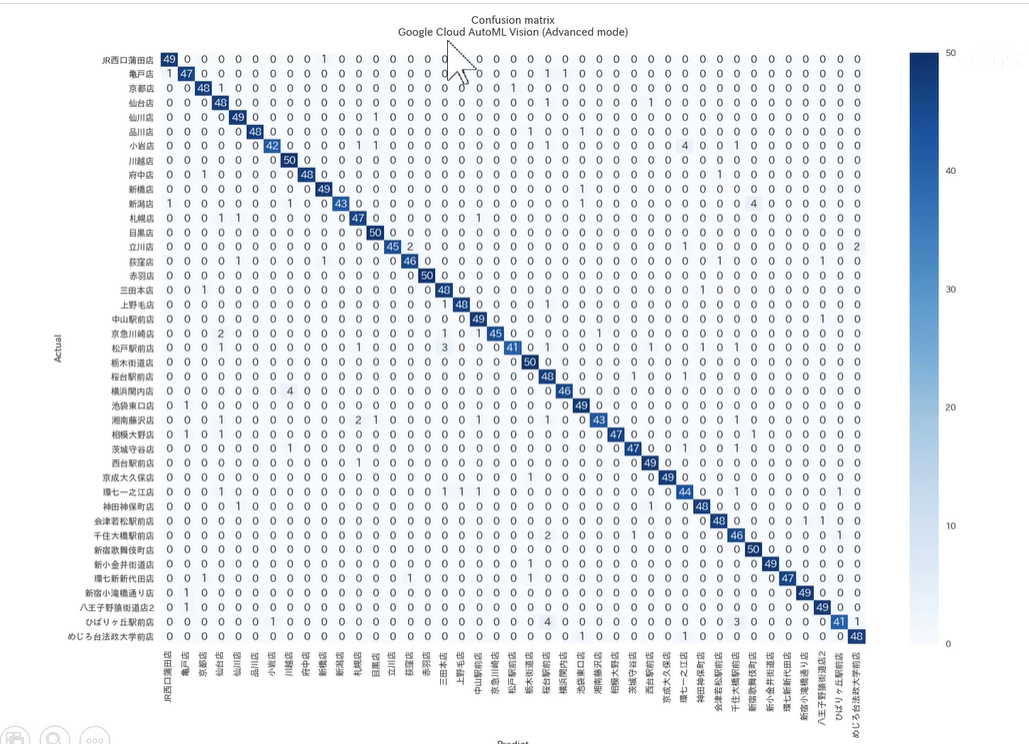
混淆矩阵,对角线一般是有数据的,如ImageNet应该有1000行,1000列。

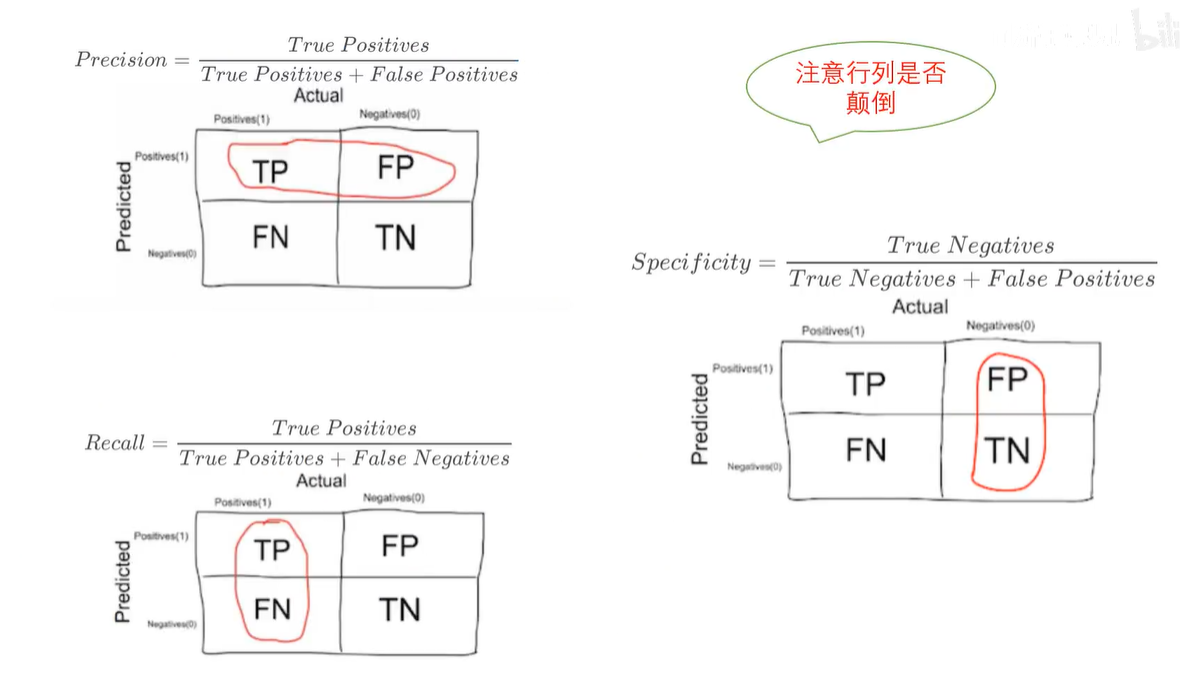
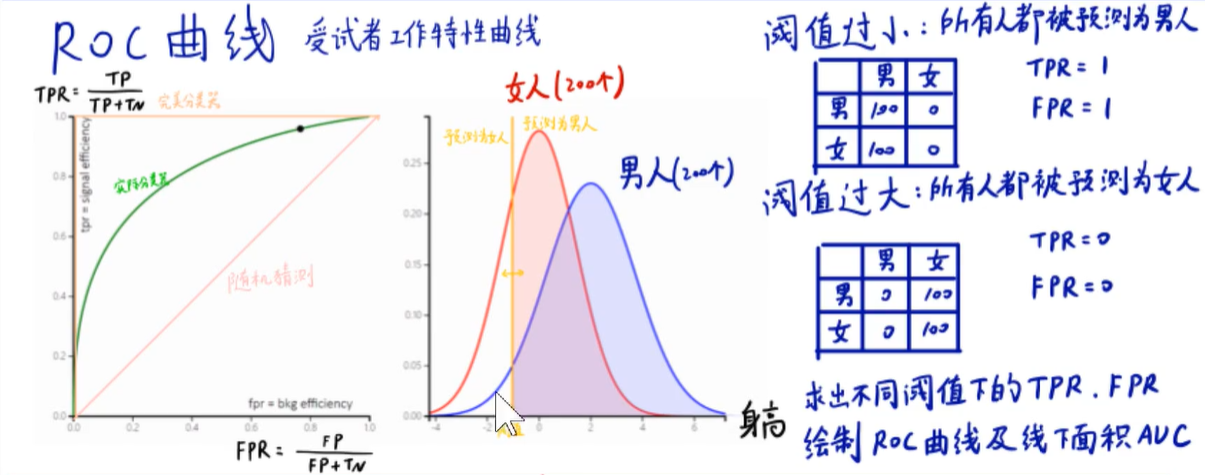
5. ROC曲线
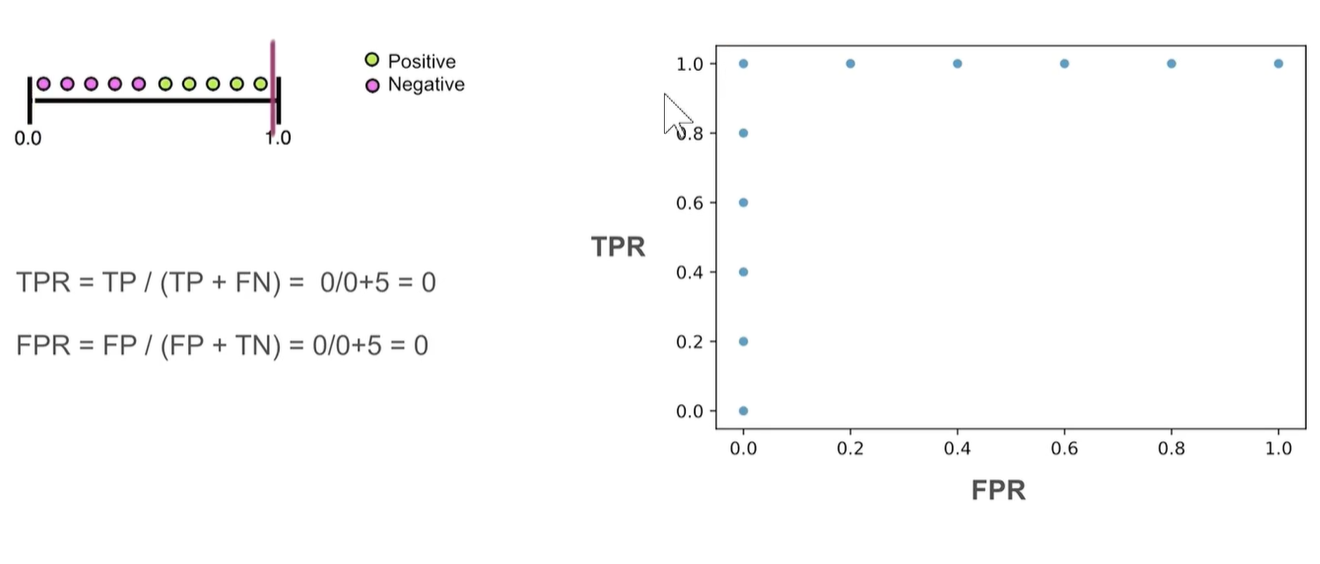
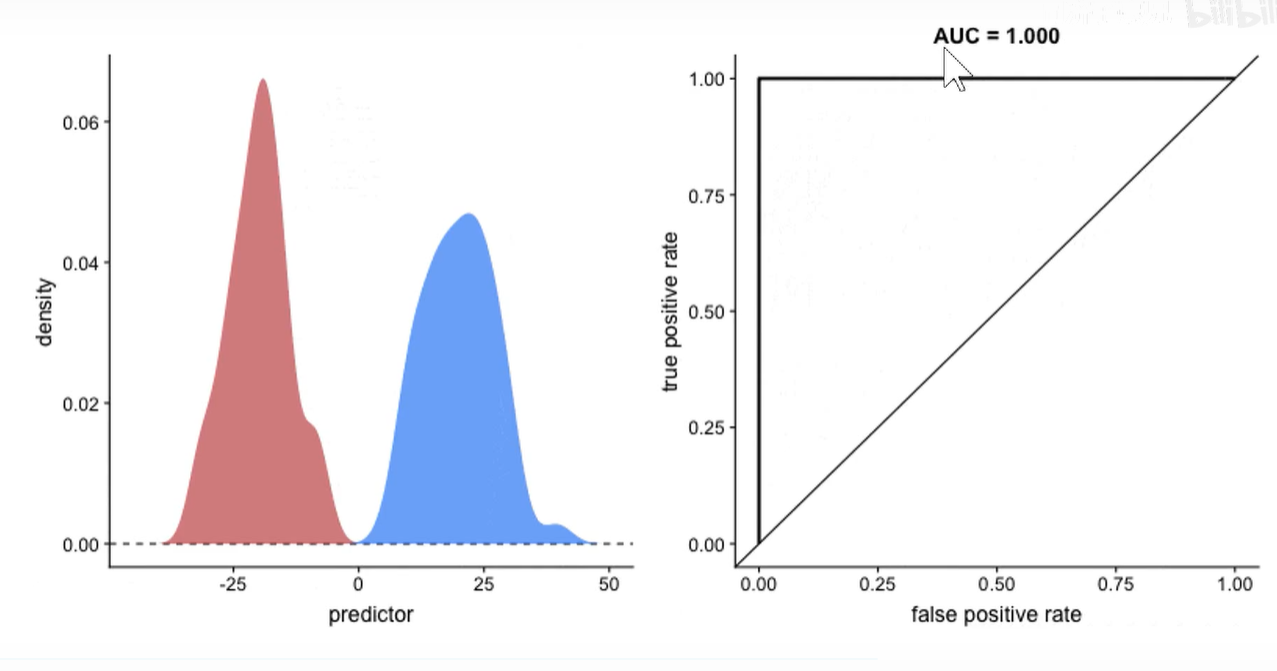
在数据完全分开的情况下,ROC曲线应该是一个支直角正方形。
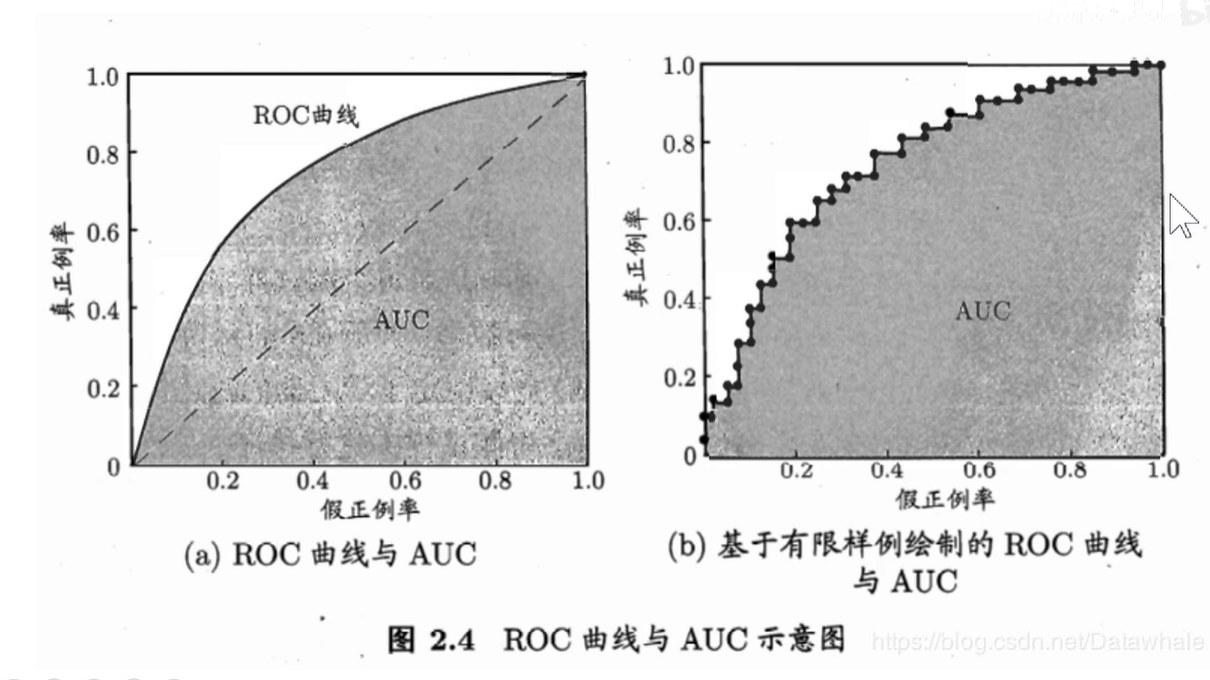
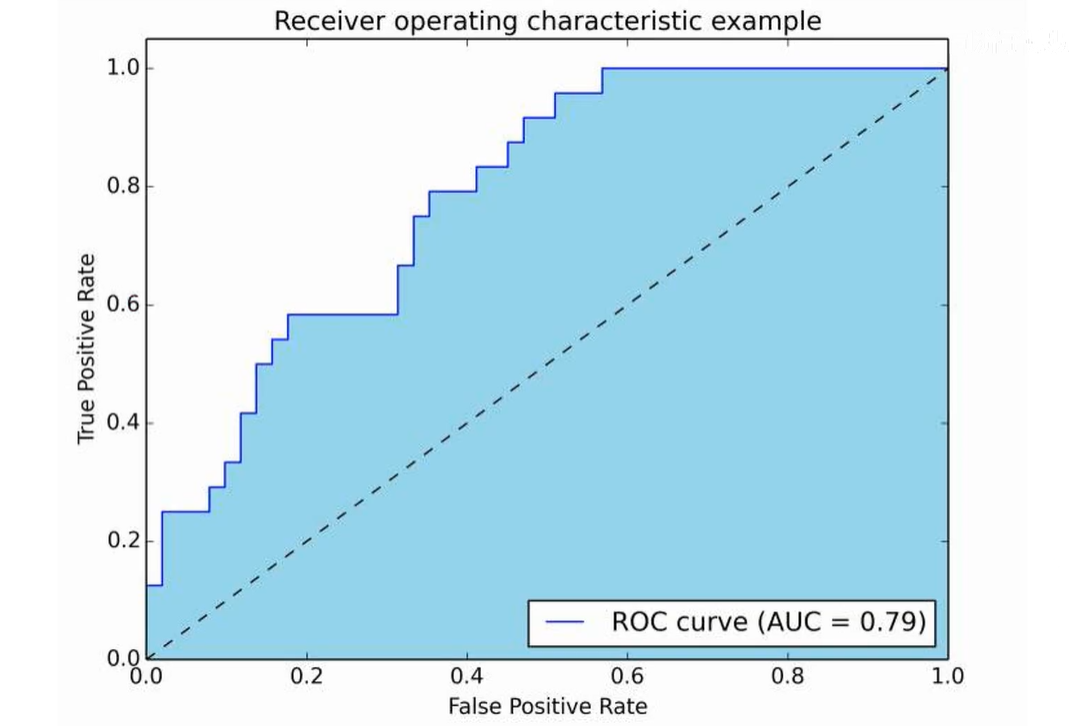
不完美的ROC曲线如下图:
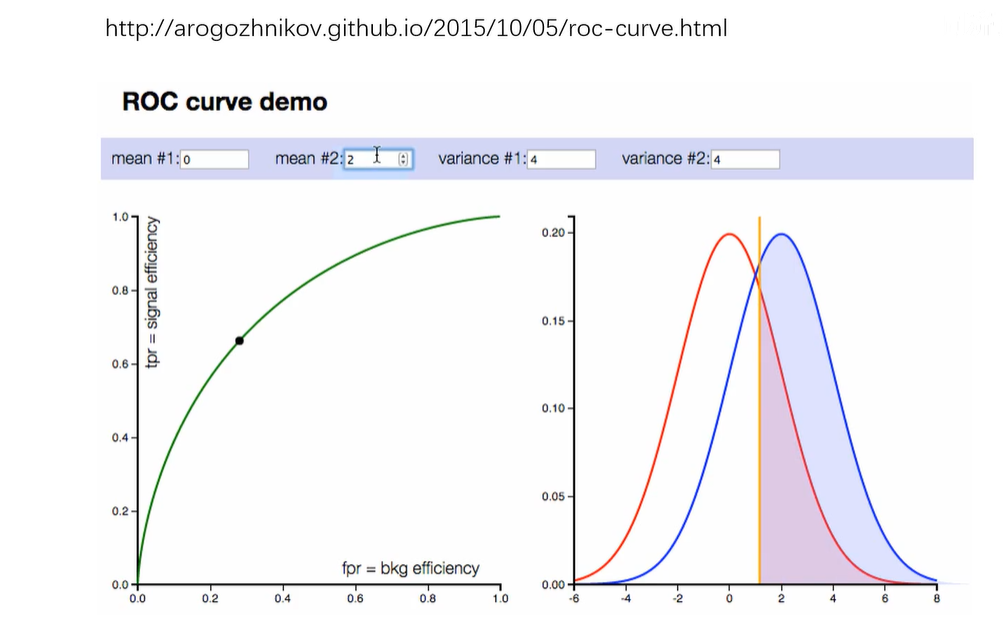
ROC曲线下围城的面积称为AUC,越大越好。
机器学习岗位:面试会被经常问到。
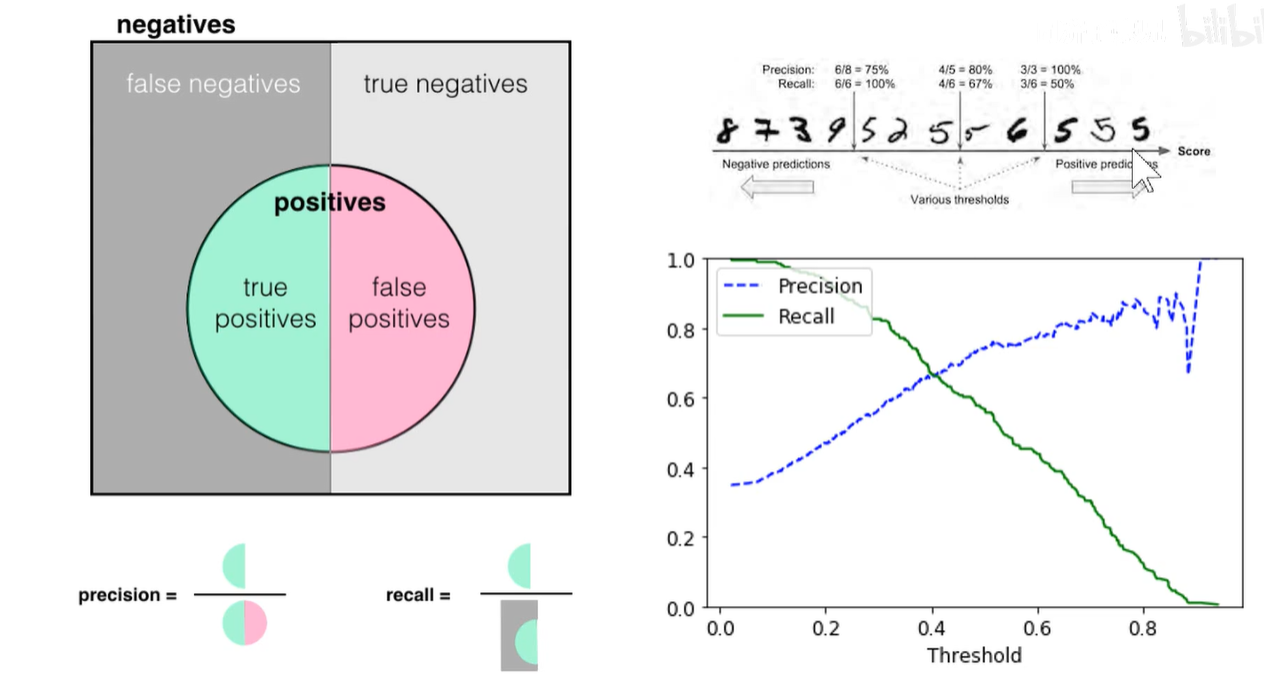
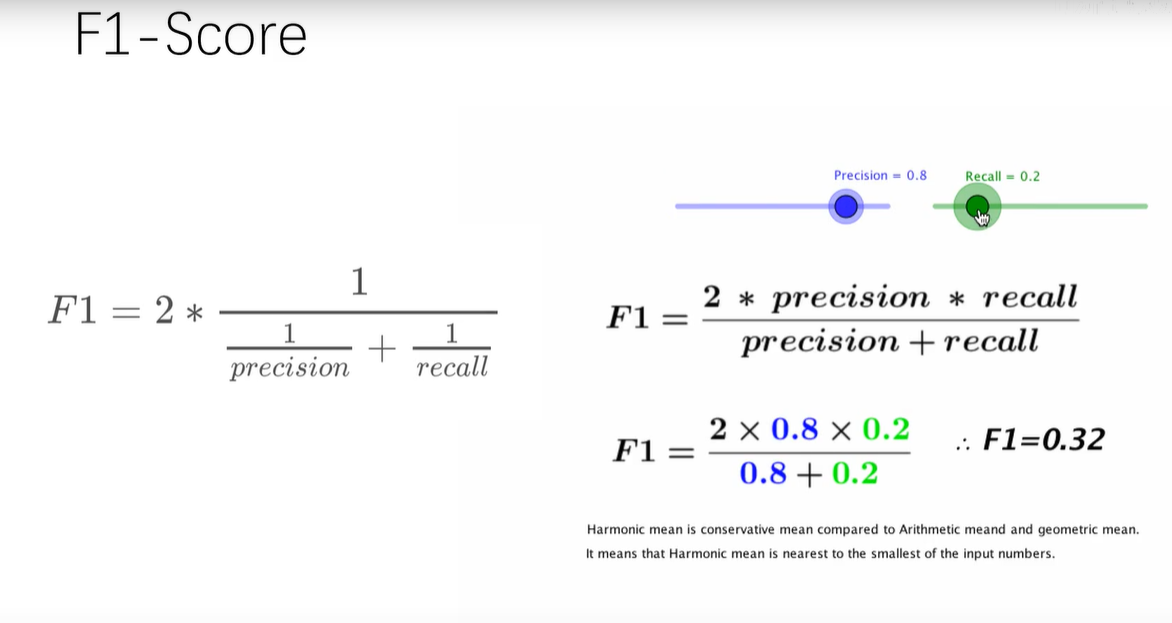
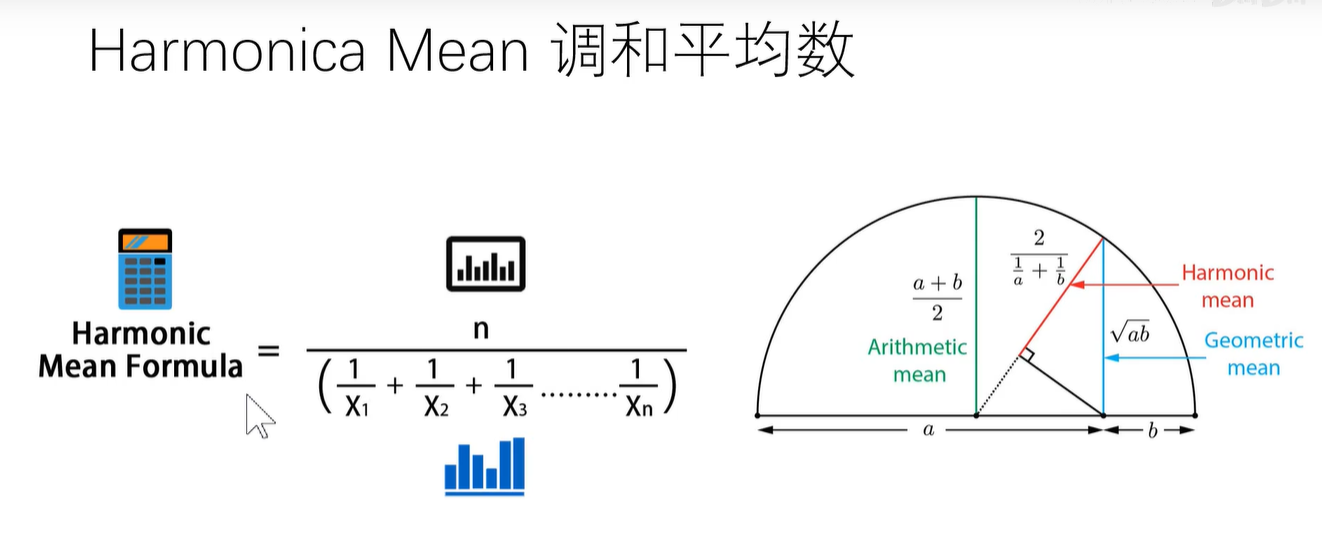
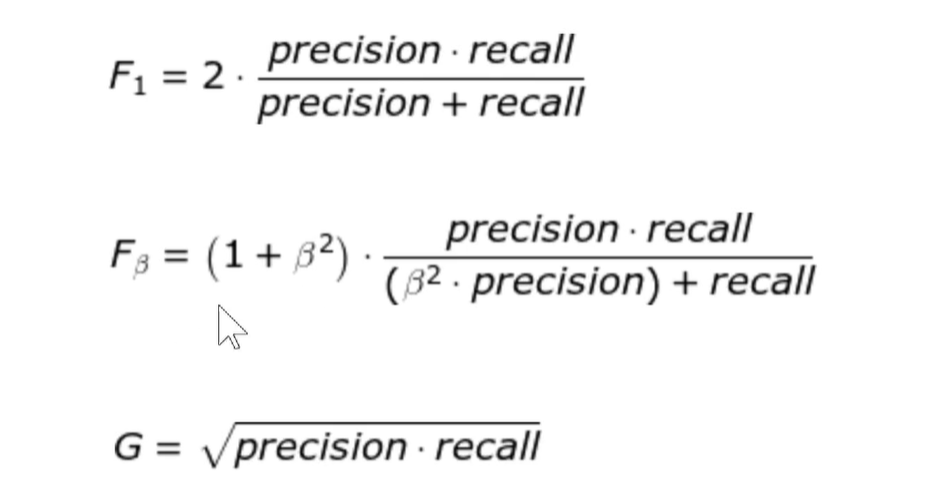
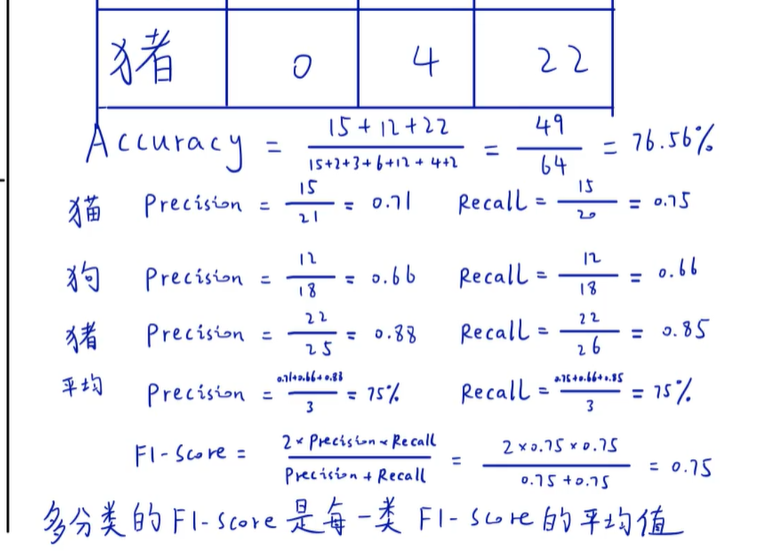
6. F1-Score