Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N
1 前言
CNN在计算机视觉领域大放异彩。CNN是专门用来处理图像数据,解决计算机视觉问题的神经网络。
神经网络在工程科学发展历史

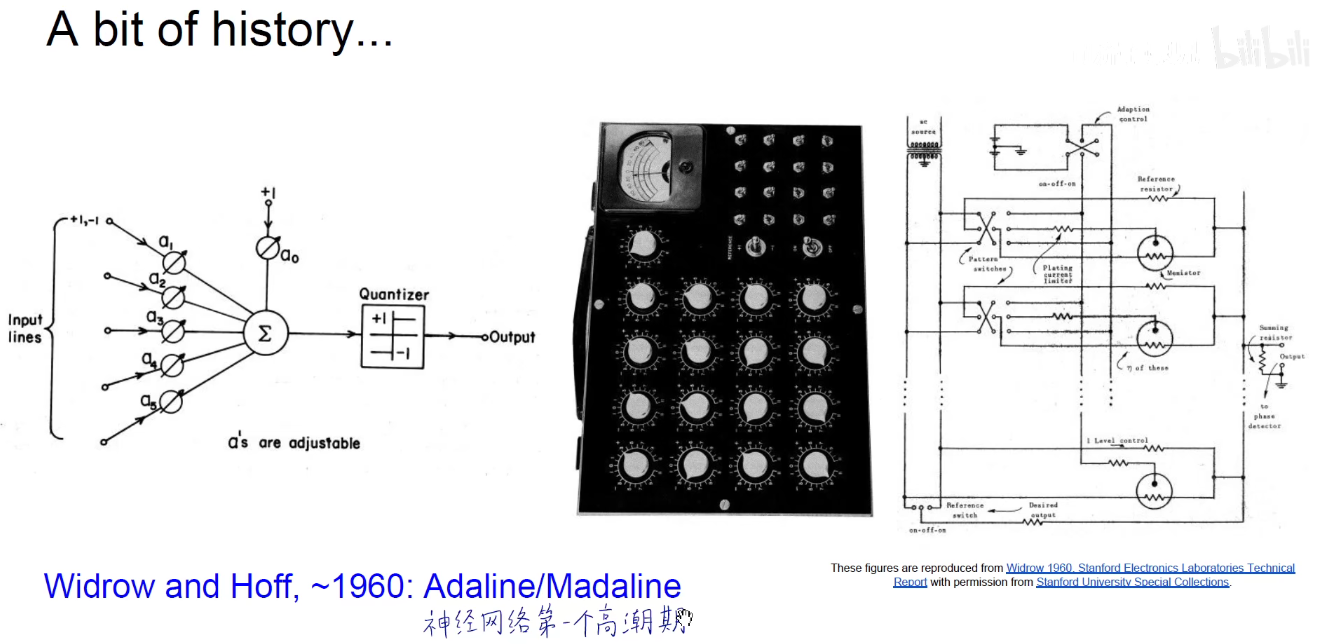
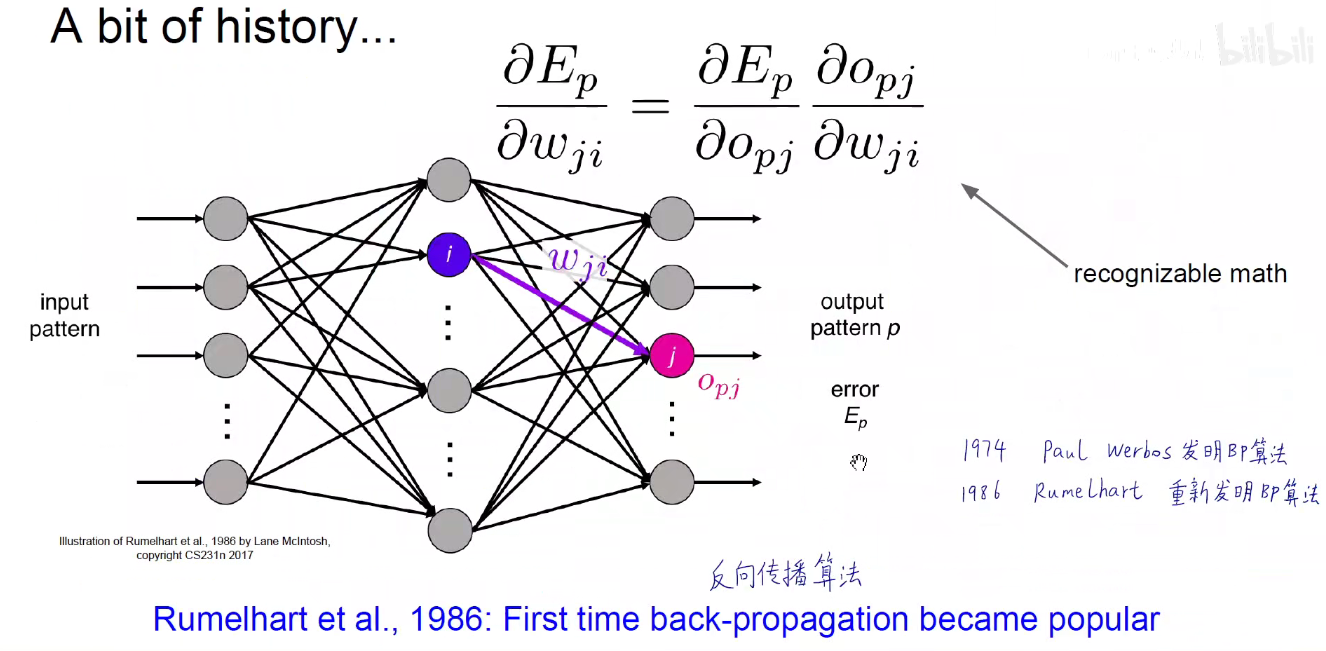
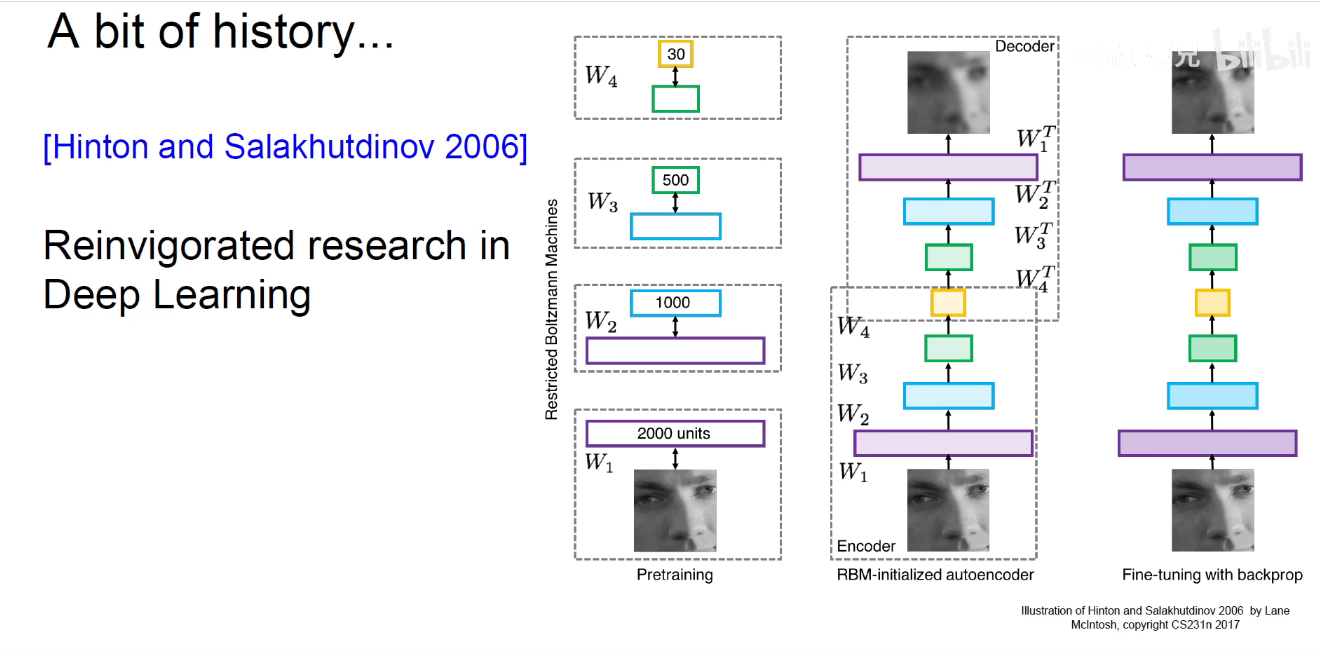
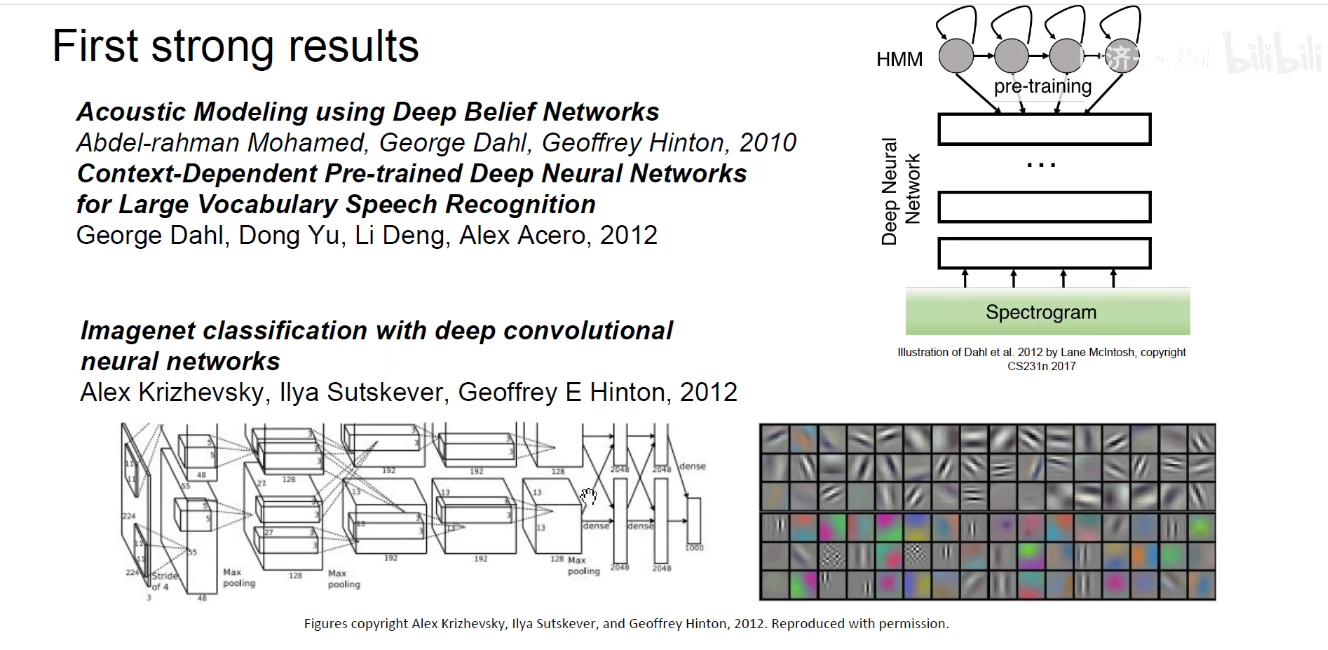
神经网络在认知科学发展历史
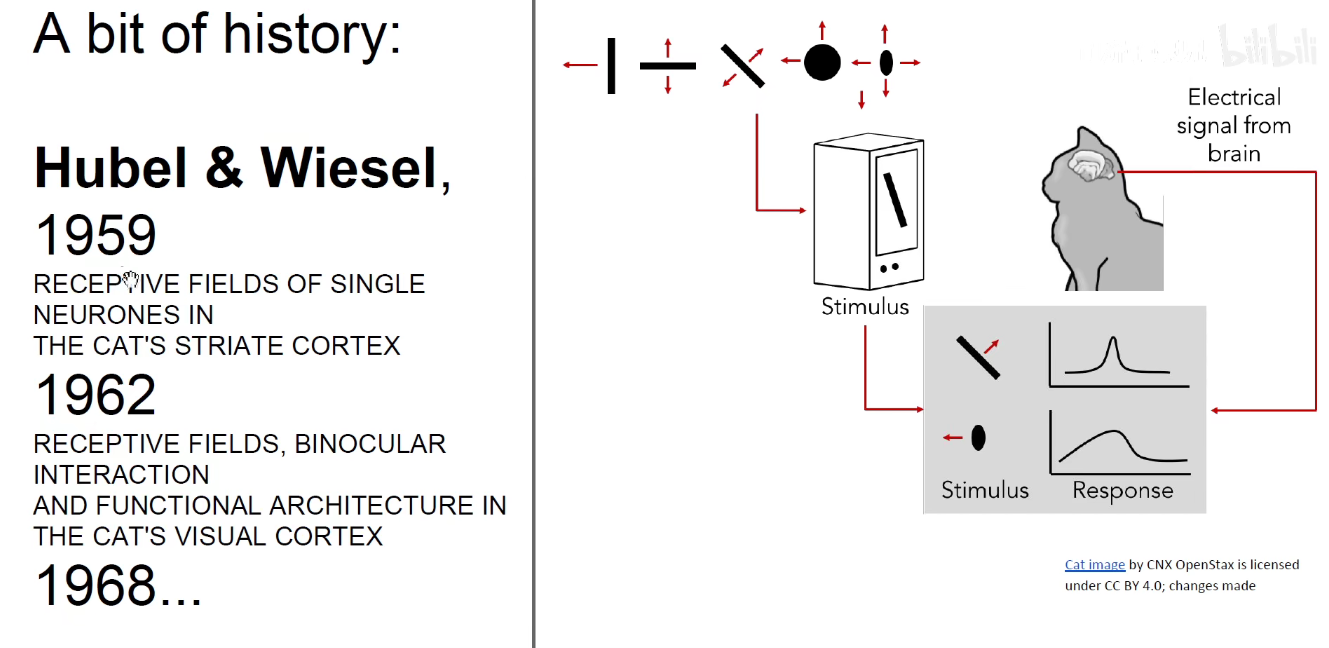
这两个人把电极插到猫的后脑勺的基础视觉皮层里,发现不同神经元对不同的模式感兴趣,有些神经元对对角线感兴趣,有些神经元对运动感兴趣,有些则对端点感兴趣。到了20世界60-70年代,又发现不同神经元其实只关注图像中的一小部分区域,每个神经元只是关注我们看到的一小部分区域,每个神经元并不是事无巨细的将整个画面都进行分析,而是只看画面中的一小部分。如同注意力一样,大脑皮层每一部分神经元只处理一小块视觉区域。
下图启发了感受野

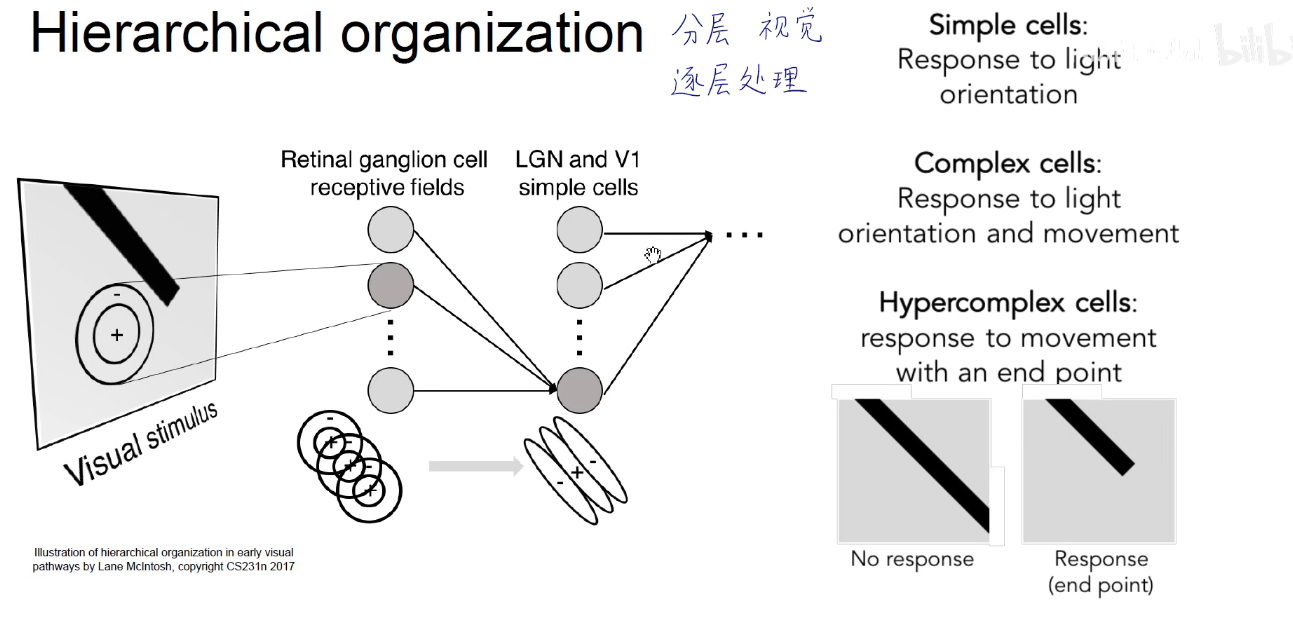
下图启发了视觉分层处理,底层的细胞对光暗、方向、边缘、颜色这些底层特征感兴趣,经过高级的处理后,大脑就会对这些底层特征进行融合和特化,到了高层的神经元,就会衍生出一些纹理、人脸这种更高层的特征。
启发了卷积神经网络 底层到高层的排列。底层处理颜色、边缘、斑点、转角、亮暗这些低层特征,高层对这些特征进行了融合和特化,最后的分类层完全特化,直到分类。
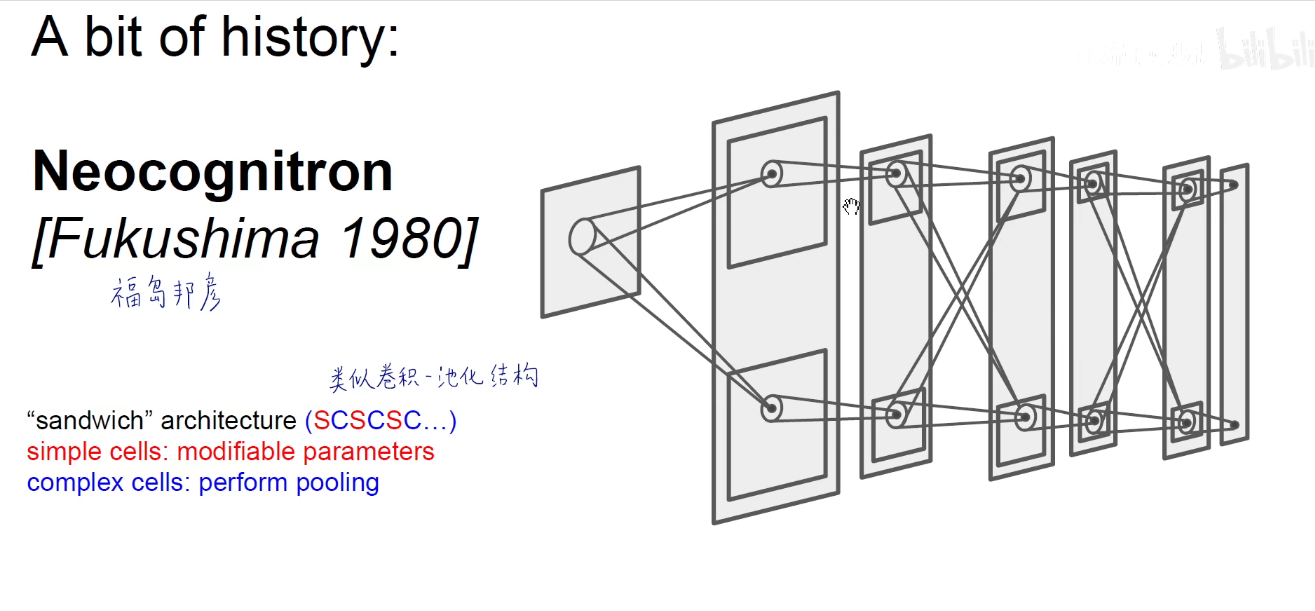
2020年此人专门领了一个富兰克林奖,奖励他在深度学习领域这样的开创性贡献。在这个神经认知器中,他堆了一个像“三明治”一样的结构,SCSCSC,C层实际是对S层结果的处理,类似于卷积-池化结构。
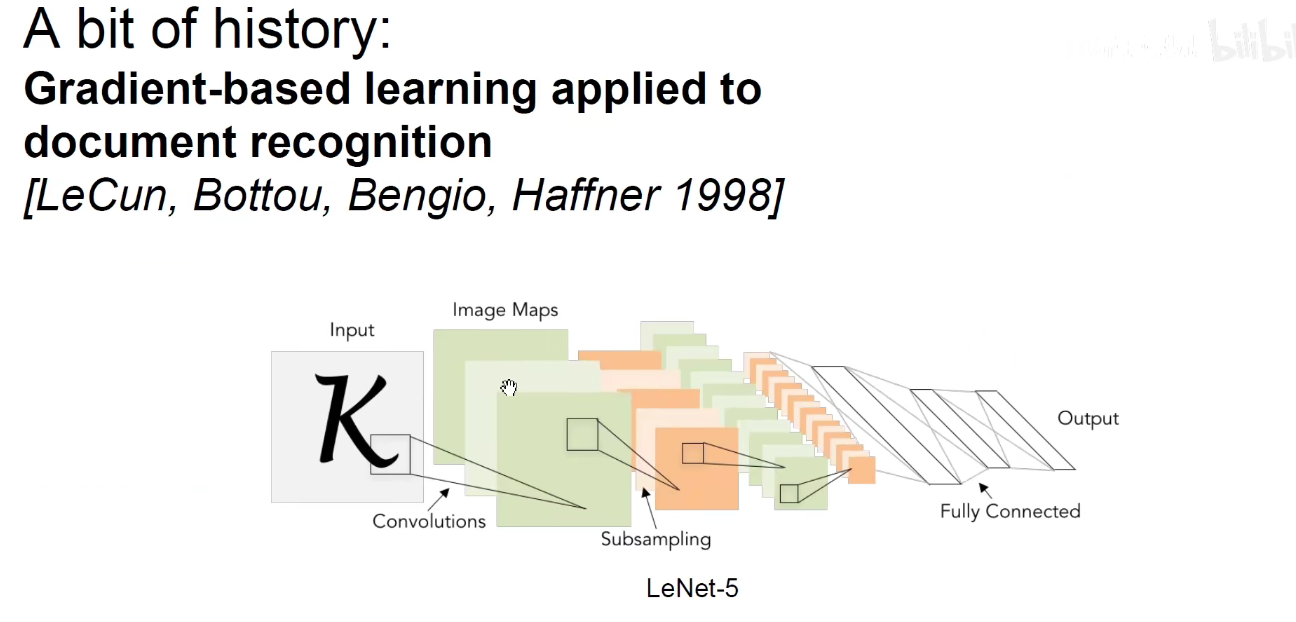
上述都启发了后来的CNN架构。
LeNet-5:美国邮政系统使用过它来识别手写数字。
2D Visualization of a Convolutional Neural Network
3D Visualization of a Convolutional Neural Network
AlexNet:在LeNet基础上做了改进,把网络加深,加了更多的权重。
今天的ConvNets:
图像的分类:给一张图片,判断图像中是什么东西。
图像的检索:百度/谷歌中的以图搜图,淘宝中的拍立淘,华为手机中的AI智能识别。

物体检测:不仅要识别出图像中有什么,而且要把图片中物体所在的位置用框框 框出来.
语义分割:不光要把图片中物体的位置找到,还要按照像素的粒度对它进行抠图,把每一个类别都抠成一样的颜色,

无人驾驶 and 边缘计算:无人驾驶中的行人检测、交通标示检测、车道线检测,驾驶行为的分析,看看司机有没有抽烟、打瞌睡、打电话,有没有危险驾驶,这些都是用
计算机视觉CNN来实现的。
在无人驾驶的领域,不需要把数据上传到云端服务器,在本地终端进行计算,称为边缘计算。没有网络的延迟,带宽的限制,保证隐私数据不被泄露。但同样对算力的要求极高。因此人们常用英伟达-特斯拉显卡。GPU用于并行计算,可以大大加快模型推断,包括反向传播。

人脸识别/视频检测:视频可以认为是一帧一帧的图片,沿时间序列展开,依旧可以用处理图片的技巧来处理视频。
人体姿态估计:像火柴人一样将人体的四肢和动作包括关键点检测出来,可以判断这个人在干什么。养老院的摔倒检测、体育训练如高尔夫、跳舞、篮球、网球、乒乓球这些对动作要求比较高的,包括动作电影的拍摄。
强化学习:将游戏的画面作为一个图片来进行分析、来进行强化学习,判断我们当前需要进行的下一步操作是什么。AlghoGo,游戏外挂等。

医疗影响诊断:肺炎、皮肤病等
天体检测:分析望远镜拍摄到的数据
交通标志:国内很多学自动化控制的本科毕业生很多使用CNN来做这么一个分类器。

Kaggle竞赛上的鲸鱼识别:
从卫星影响中,从遥感影像中捕获道路、农田,或者是发现一些异常。如某些地方水的颜色突然变了,农田突然糟了病虫害了,都可以通过遥感影像分析
Image Captioning: 给出一张图片,机器对它进行描述

Deep Dream:天上飘着一片云,比较像狗,会把它无限放大,像做梦一样
风格迁移:手机中拍摄的图片把它迁移成梵高的画风/抽象的点彩画的画风/毕加索的抽象派画风。,即将人工智能用于设计创造领域。
像设计创意学院、建筑城规学院。他们中的很多艺术家就会用神经网络这样的工具,比如生成式对抗性网络、CNN来进行自动化的设计、画风的迁移、室内的布局,或者以此来寻求灵感。
2 正式介绍CNN
2.1 FC
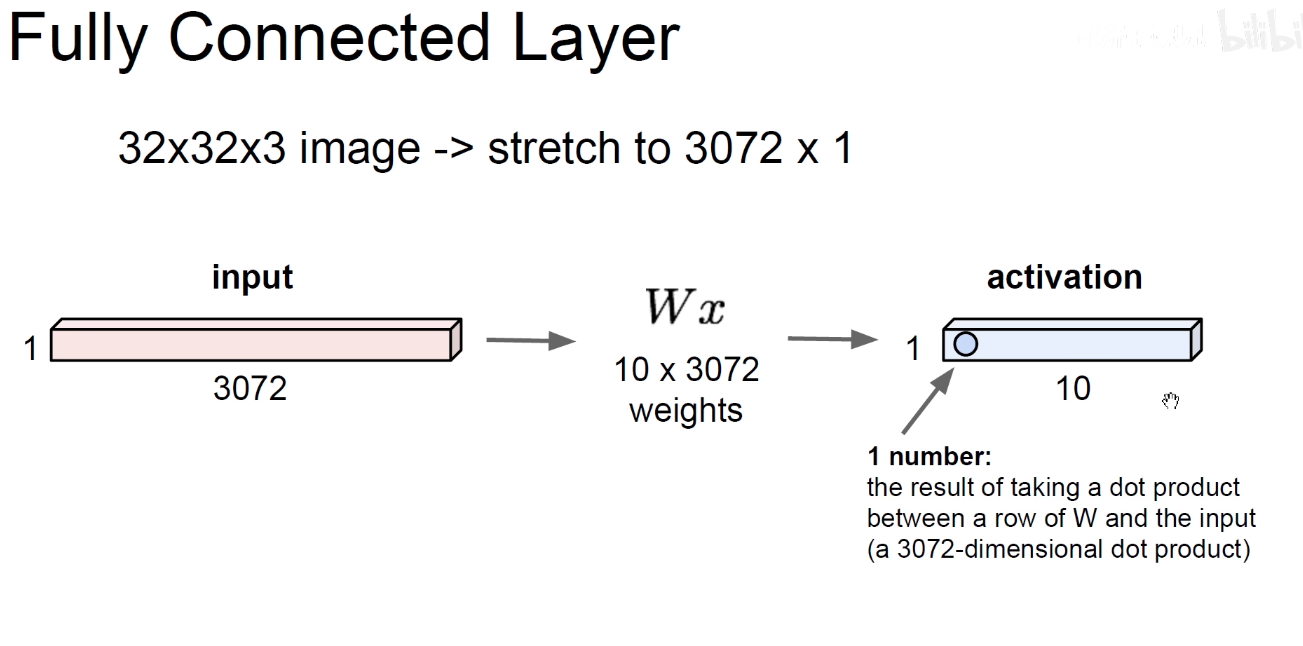
上图是把图像拉平Flatten成一个长向量,3072x1, 比如我们用个10个线性分类器对它进行分类,每一个分类器都有3072个权重,跟原始图像的3072个原始像素向量对应位置做点乘求和得到第一个分类器的值,10个分类器得到个10个值。这是原先的想法。
弊端: 把32x32x3的图像硬生生的拉成一个长向量,丢失了图像的空间信息(spatial-information),为此我们引入卷积操作。
2.2 ConvNet-图示
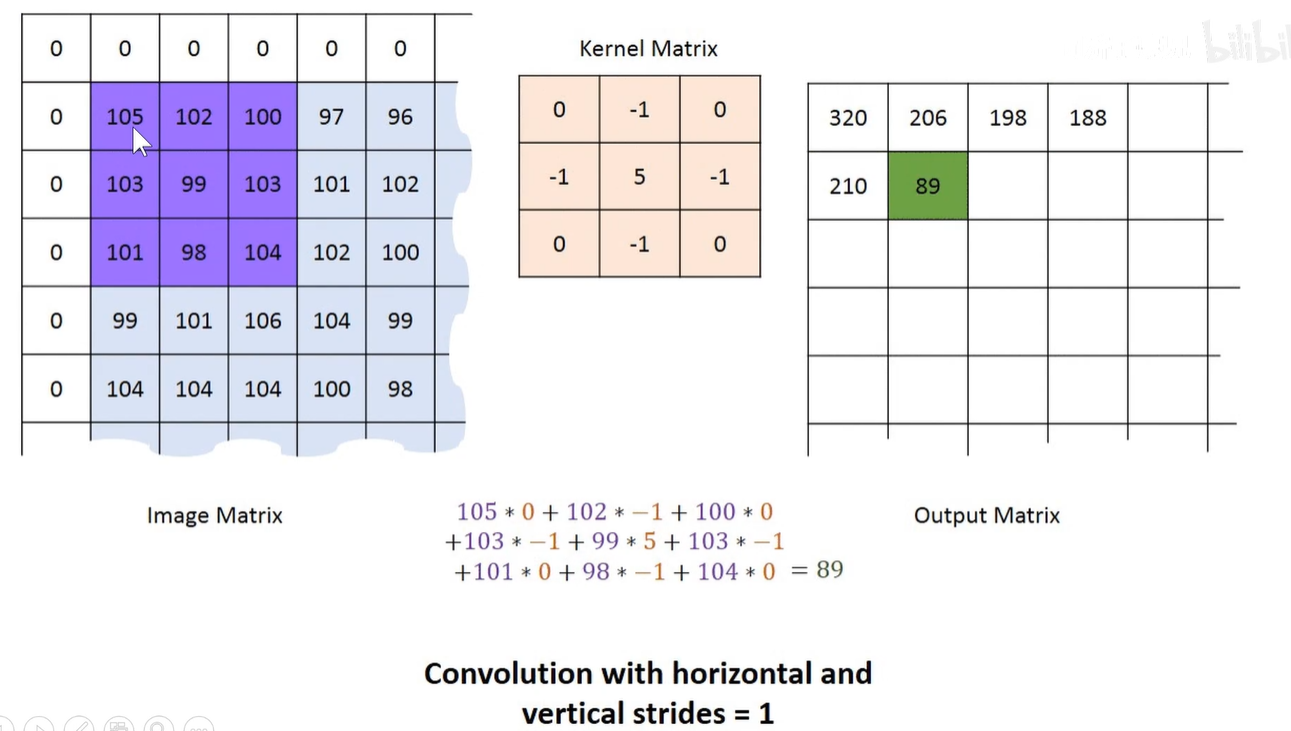
feature-map计算方式
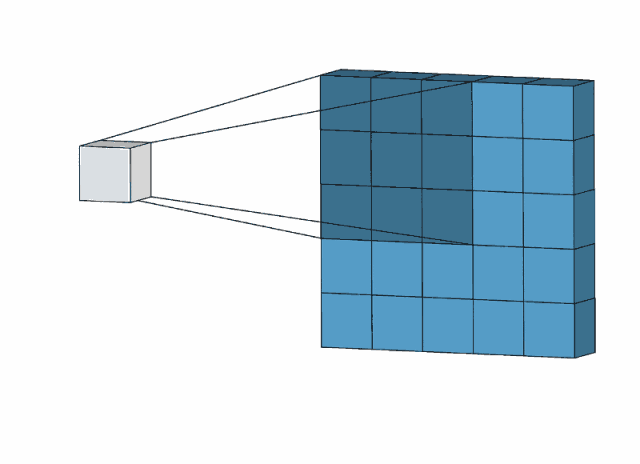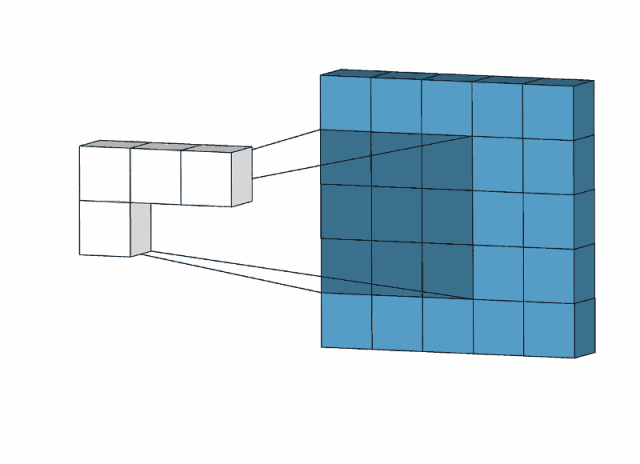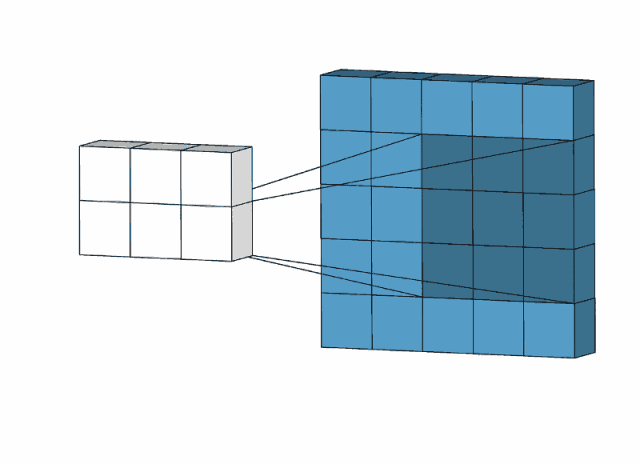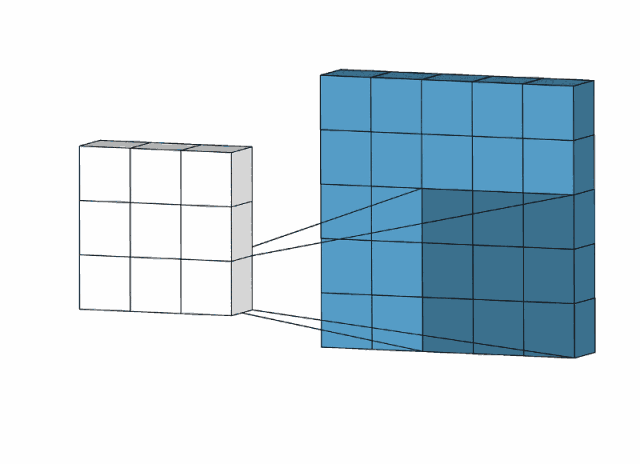
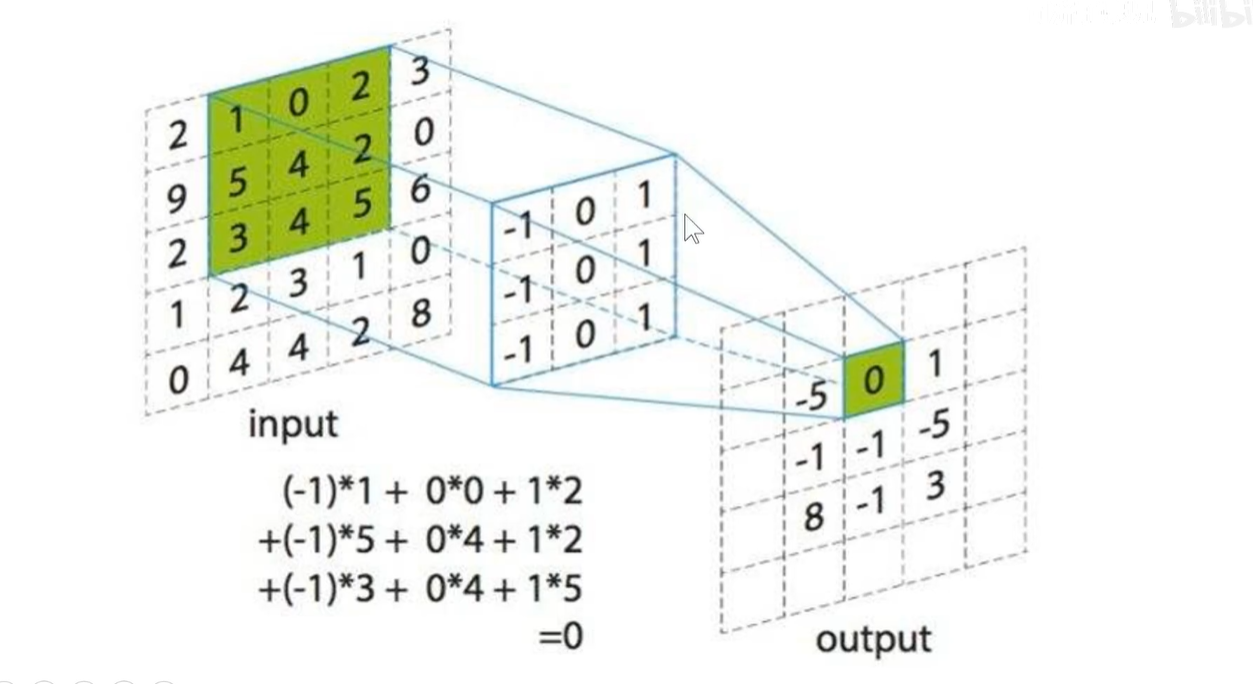
Input上是原始输入像素,Input上的绿色区域称为感受野-Receptive Filed,中间的卷积核(滤波器),它上面的数字是卷积核的权重,因为在滑动过程中权重不变,所以称为权值共享。最右边的是feature-map,计算方式如图所示。
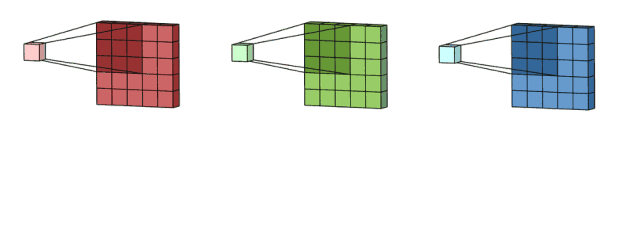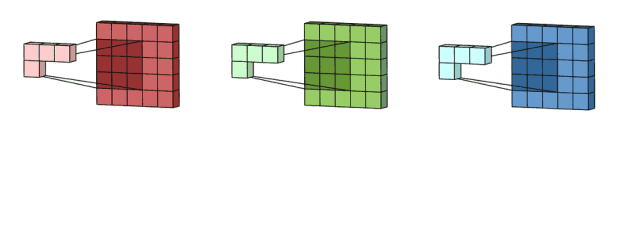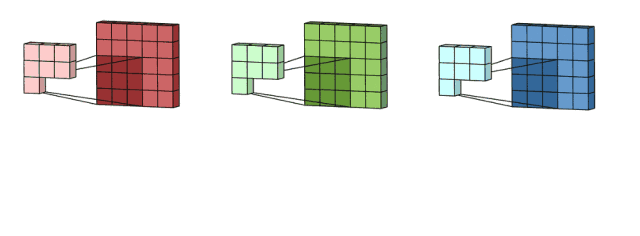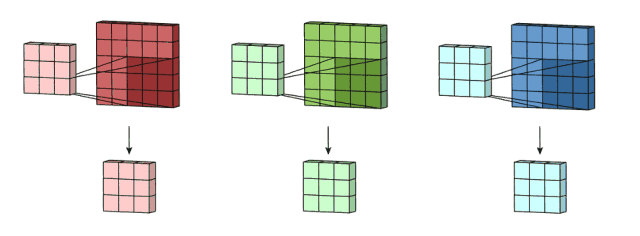
上述之一一个卷积核的卷积操作,形成了一层feature-map,我们用多个卷积核进行卷积,就可以形成多个堆叠的feature-map,也就是多通道feature-map。有多少个卷积核,就有多少个feature-map。
如下图所示,第一个卷积核生成红色的featuer-map,第二个卷积核生成绿色的feature-map,第三个卷积核生成蓝色的feature-map,将他们堆叠排列,就形成多通道feature-map,作为下一个卷积层的输入。
问题:如下图所示,边缘的像素点参与了很少的卷积运算,而中间区域的像素参与了大量的卷积运算,这是不公平的,甚至可能导致丢失边缘像素的信息。如左上角像素1只参与了1回运算,而中间的1参与了多次卷积运算。
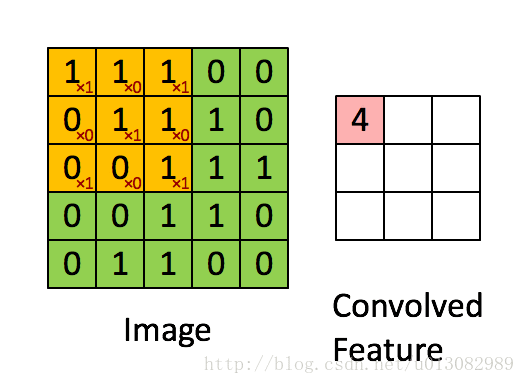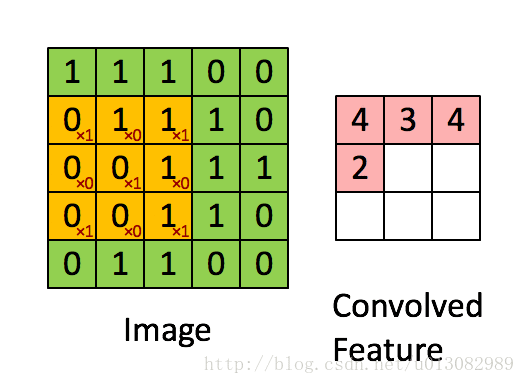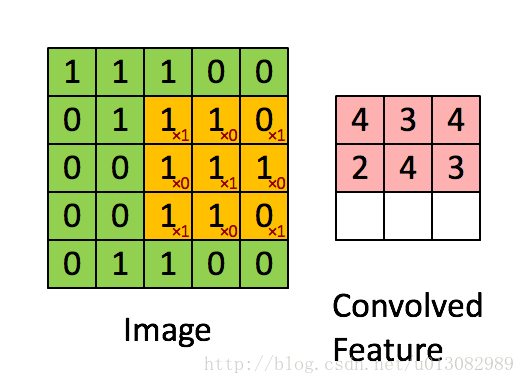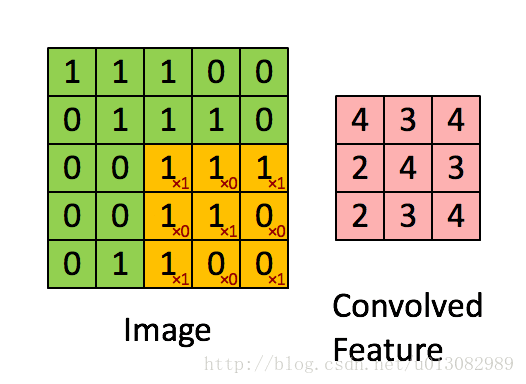
为了解决上述问题,引入Padding操作。
Padding:不仅可以减少边缘像素计算量过少的情况,还可以对feature-map进行增维,比如原来输入是5x5,卷积后是3x3,再次卷积又变成1x1,越变越小。如果在最外围补了一圈0的话,就可以增加feature-map的维度。
上述图像步长是1,即横向每次滑动1格,纵向每次也滑动1格。一般横向和纵向的步长都一致。
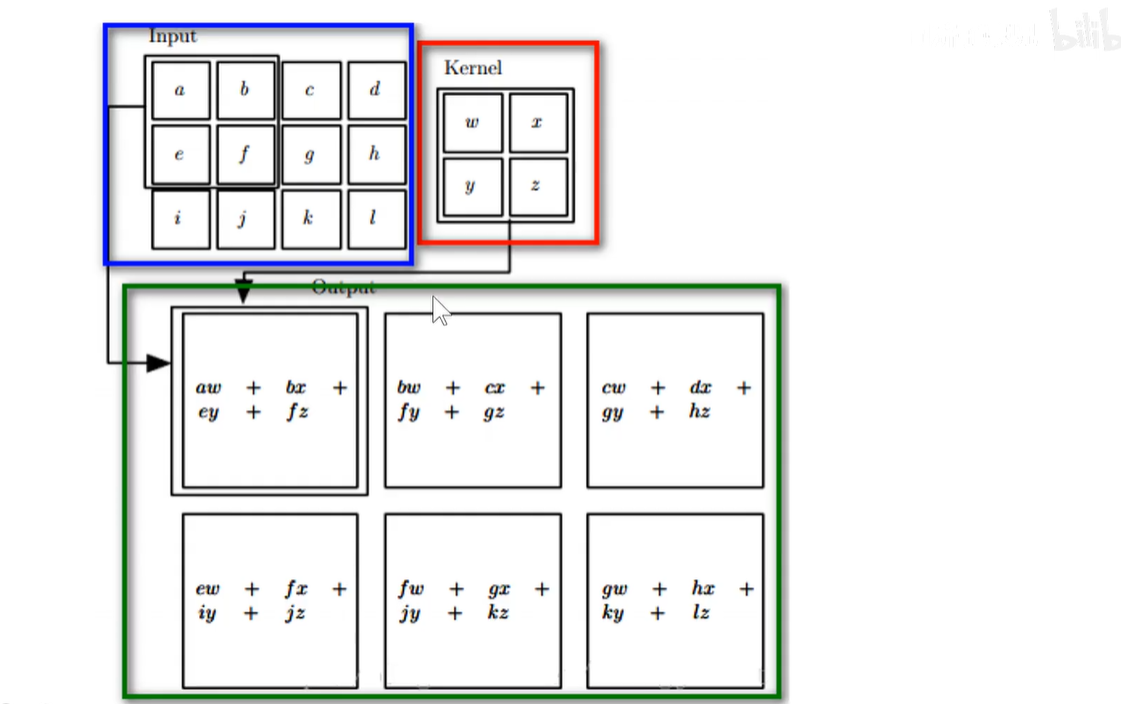
彩色图像:上述输入图像都是灰色图像,只有1个通道,即一层matrix,而现实中的彩色输入图片基本都是3通道图像,如下图所示:原始图像是虚幻显示,卷积核在原始图像上进行三维滑动,感受野也变成了3维。依然是卷积核上的权重和原始图像上对应位置的像素相乘,求和之后生成一个二维的feature-map
https://thomelane.github.io/convolutions/2DConvRGB.html
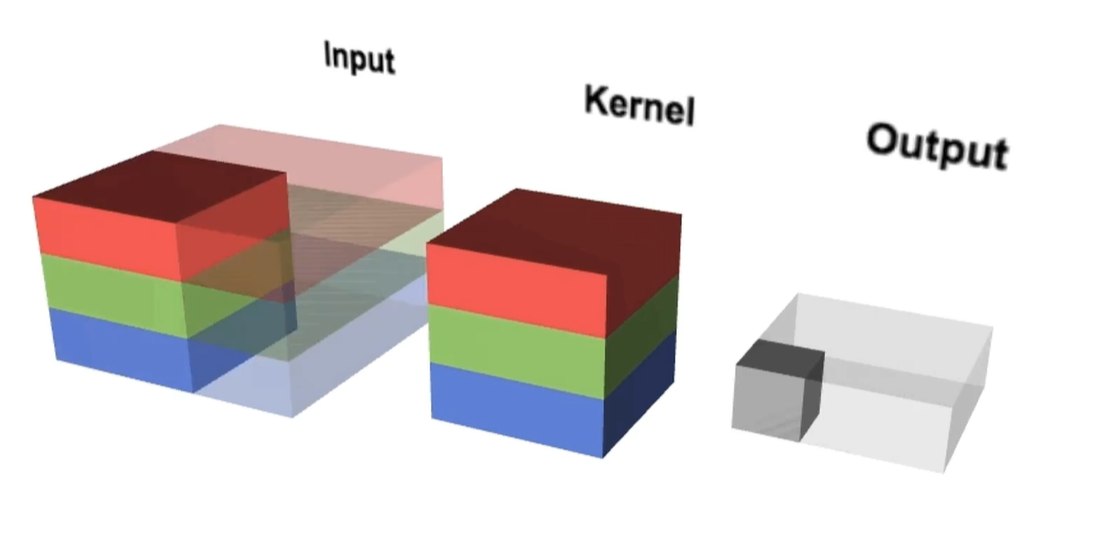
因此,鉴于输入图像是彩色图片3通道,则卷积核也应该是3通道的
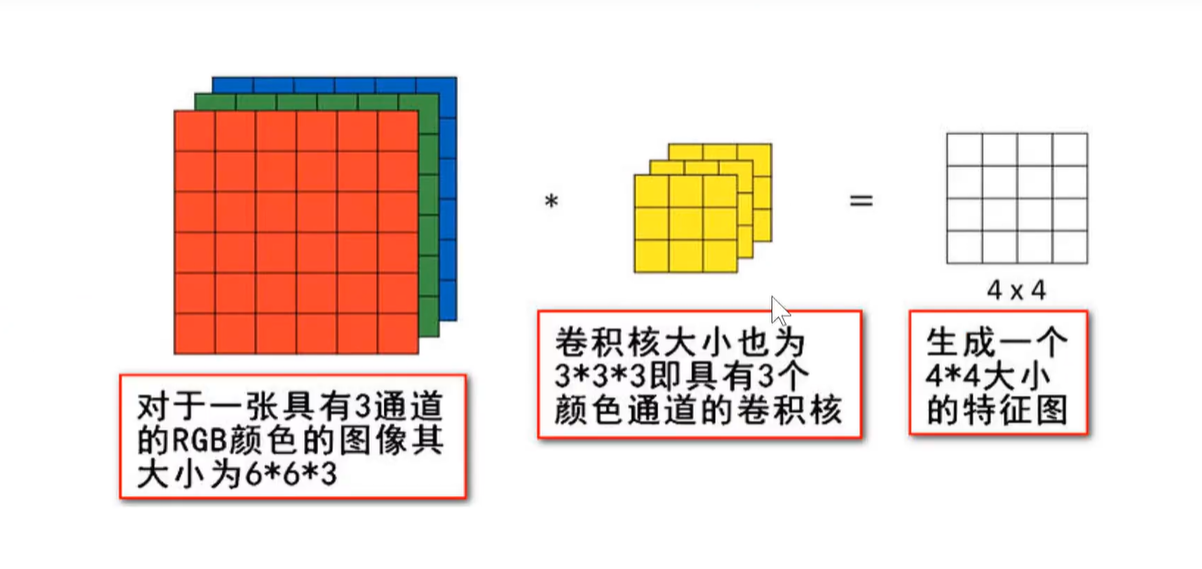

感受野是多维的,卷积核是多维的,但生成的feature-map是2维的。
卷积操作的目的:将原图中符合卷积核特征的特征提取出来。

例子:假设下图中卷积核是提取眼睛特征的 ,则对图像进行卷积操作后,提取到的特征值大部分是0,只有滑动到眼睛部位时特征值才是100.
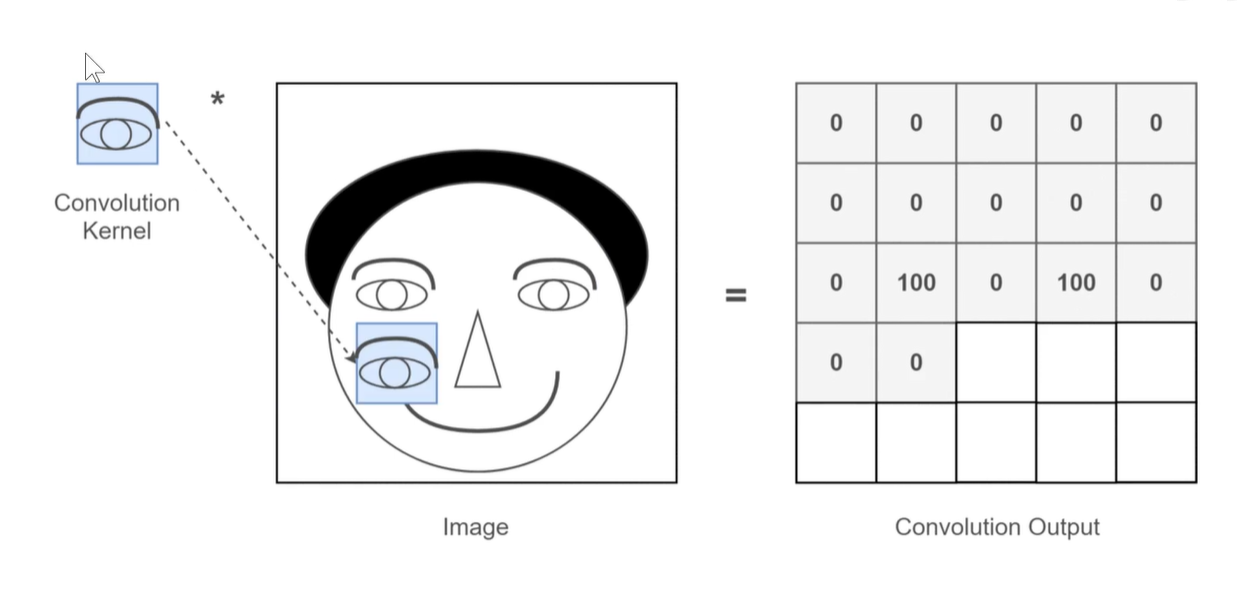
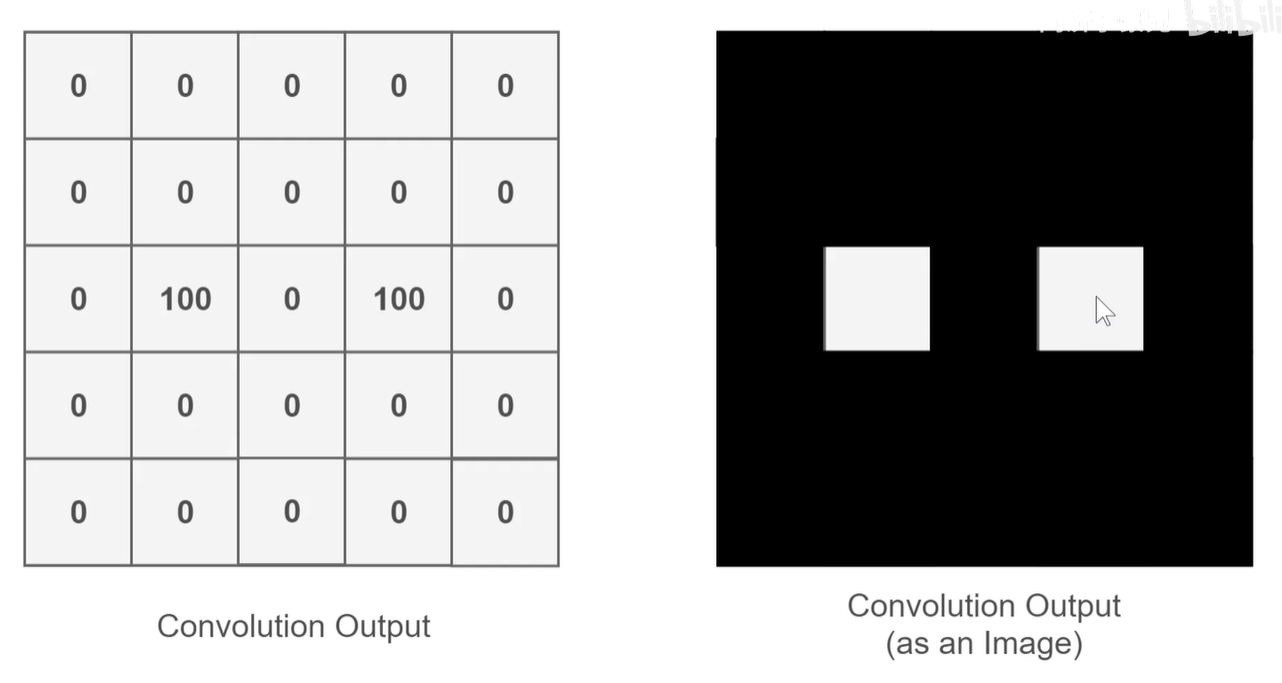
所以上图中 feature-map 眼睛的部分就是高值的,就是亮的。
再举个例子:如下图,4个卷积核对汽车进行卷积操作。
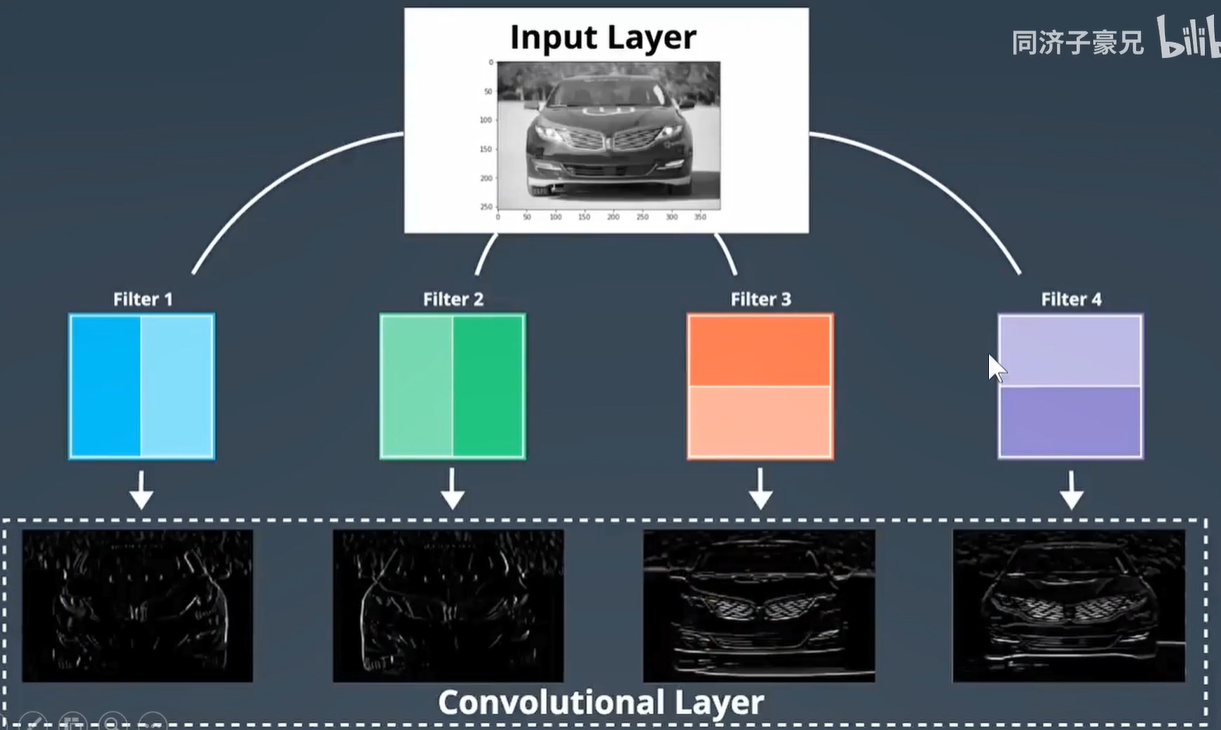
Filter-1 提取特征是右边是高值,左边是低值,提取的车子就是右边亮,左边暗。
Filter-2 提取特征是右边是低值,左边是高值,提取的车子就是左边亮,右边暗。
Filter-3 提取特征是下边是高值,上边是低值,提取的车子就是下边亮,上边暗。
Filter-4 提取特征是上边是高值,下边是低值,提取的车子就是上边亮,下边暗。
同一卷积层,卷积核越多。越能提取到不同维度的特征,如正视、俯视、仰视等不同角度观察物体,更细节和全面。
卷积核的动图:https://github.com/vdumoulin/conv_arithmetic
2.3 ConvNet-CS231N-卷积
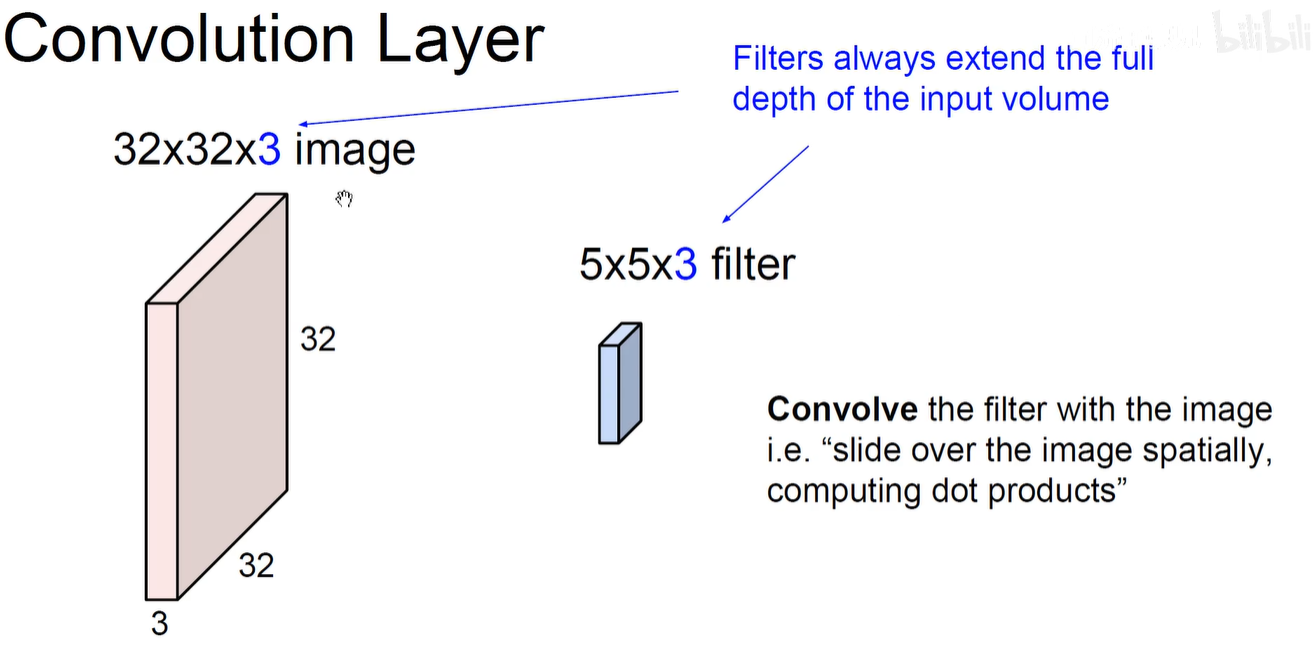
上图表示 原始输入图片由多少个维度,卷积核也相应的拥有多少个维度。例如都是3通道。
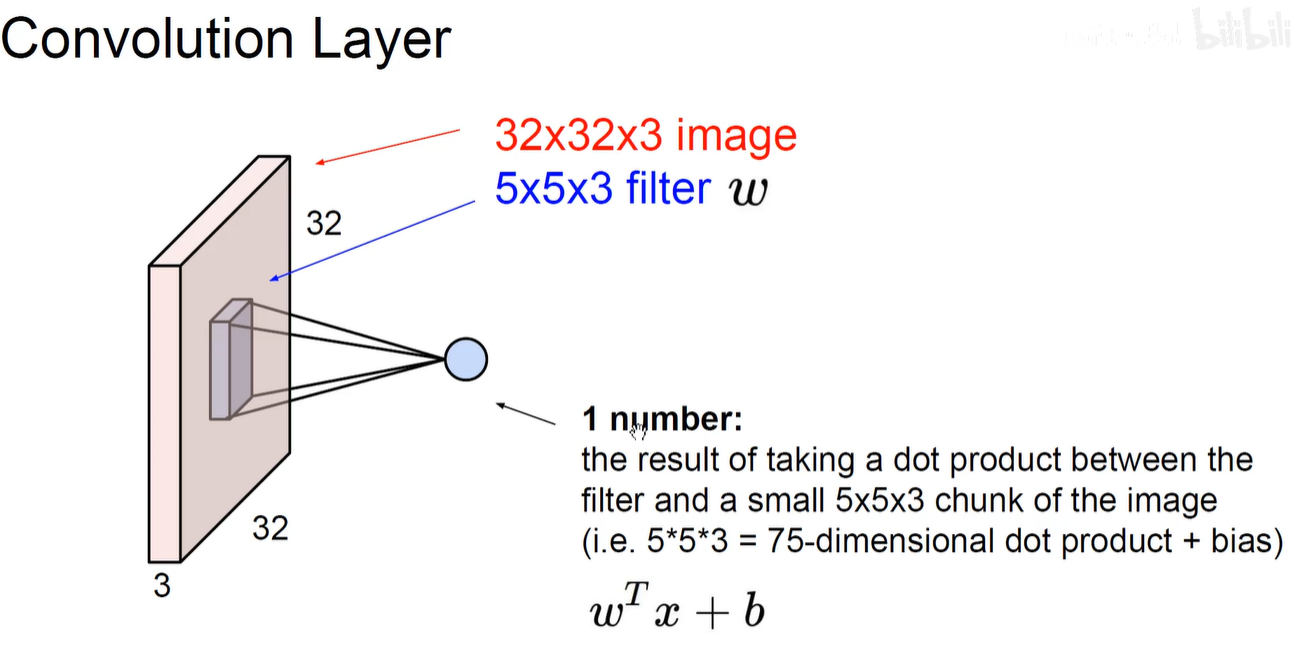
上图表示卷积操作:对应位置就和再加上一个偏置项。即原图上5x5x3的像素与卷积核上对应的5x5x3的像素相乘求和+偏置项
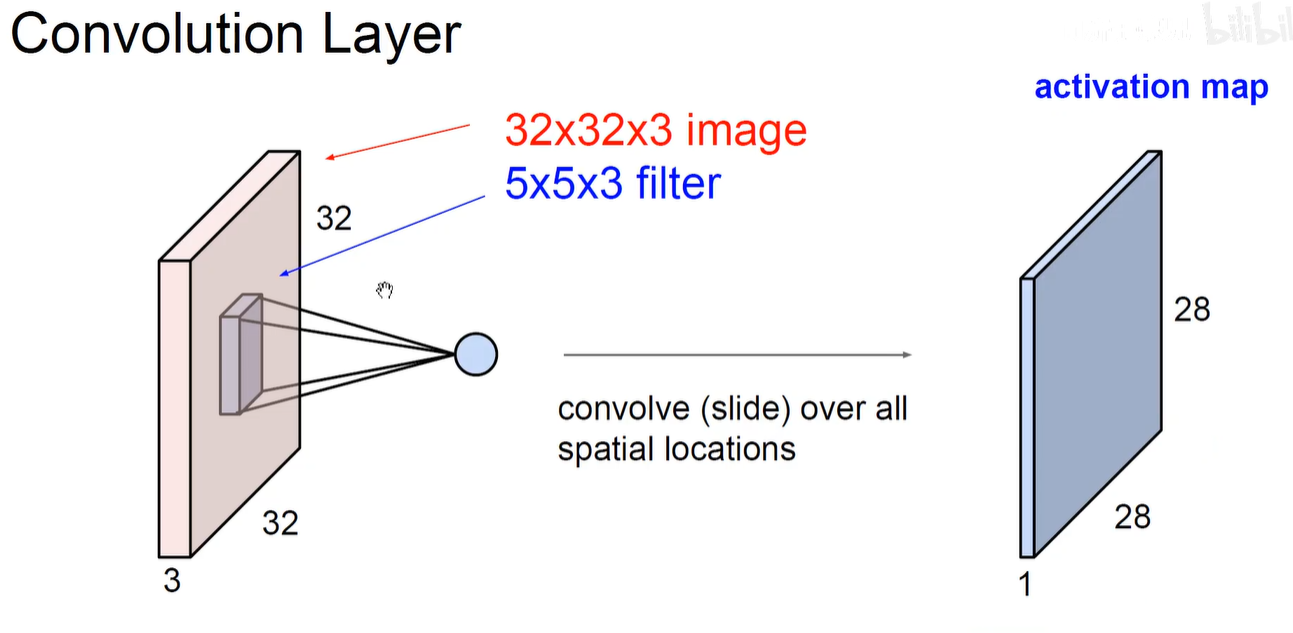
第一个卷积核卷积后生成第一个feature-map。即蓝色activation map。
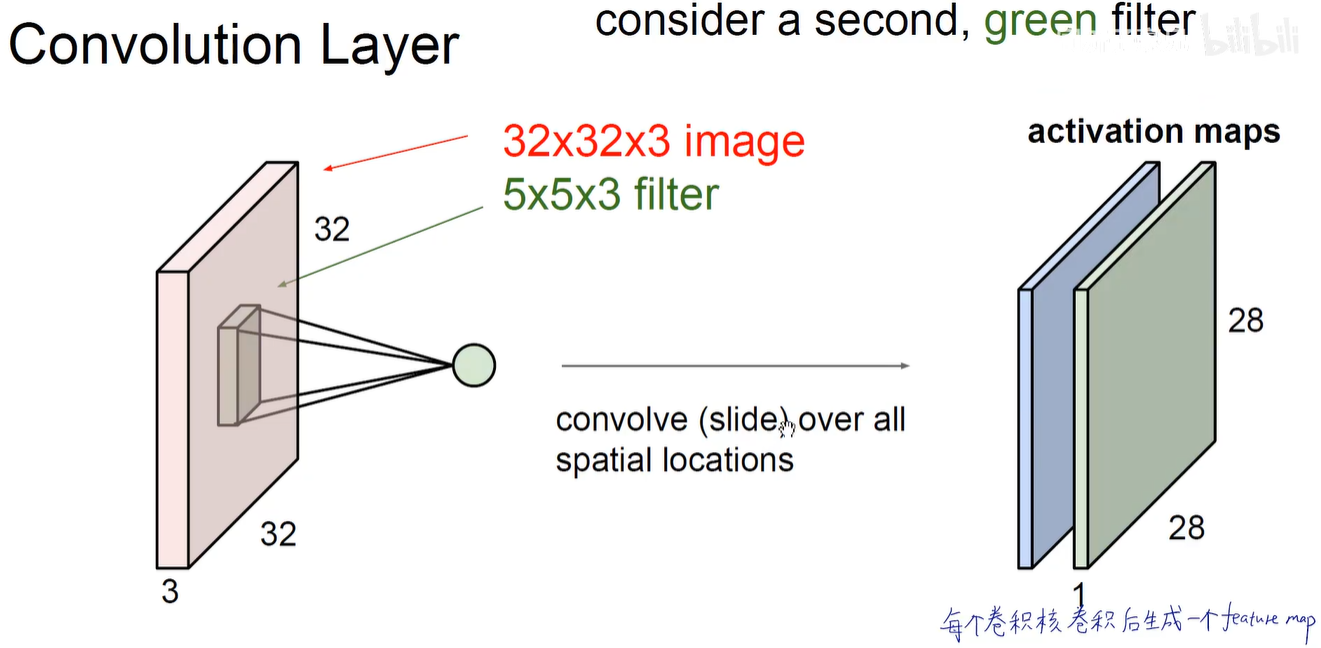
第二个卷积核卷积后生成第二个feature-map。即绿色activation map。
如下图所示:有多少个卷积核,就有多少个feature-map。
w2 = (w1 - f +2p)/s +1 = (32-5 + 0) / 1 + 1 = 28.
相当于5x5的卷积核只能在32x32的原始图像上平移滑动28次,再次滑动就会超出。
用了6个卷积核,就会生成6个通道的feature-map,堆叠在一起。
28x28x6 可以作为下一个卷积层的输入,那么下一个卷积层对应的卷积核至少是拥有6个通道的卷积核。
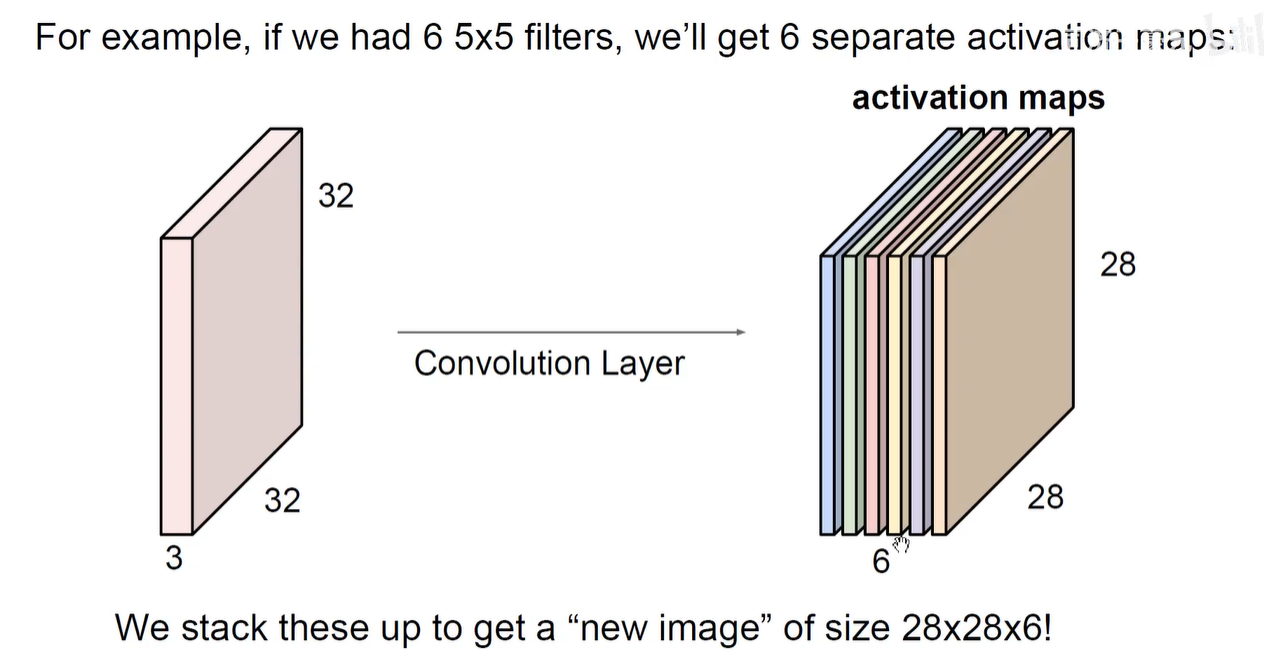
下图再用 10个5x5x6的卷积核,就会得到 24x24x10的新尺寸图片数据。
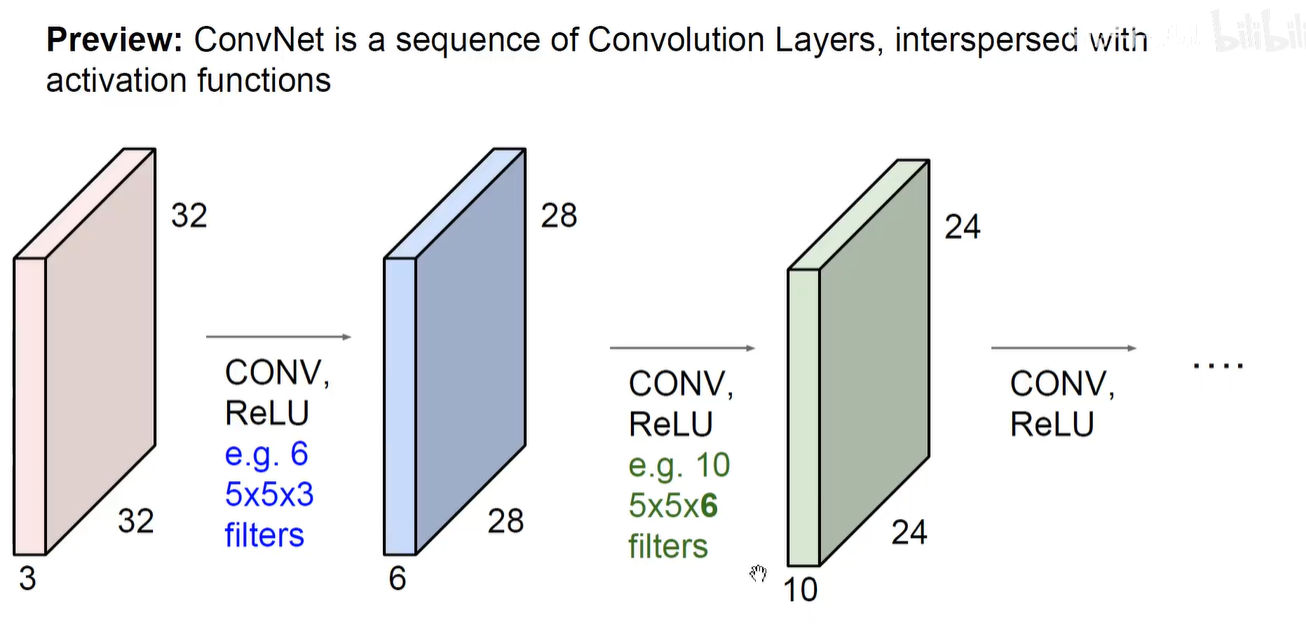
输入是3通道,则对应第一个卷及层的卷积核也是3通道的,第一个卷及层有6个5x5x3的卷积核,则会生成6个feature-map,第二个卷积层的卷积核就需要也是6通道,第二个卷积层有10个5x5x6的卷积核,就会生成10个feature-map。
2.4 ConvNet-CS231N-池化-下采样
随着卷积核个数越来越多,feature-map的通道数也越来越多,如果用256个卷积核对输入图像进行卷积,就会生成一个含有256个通道feature-map,此时feature-map的参数量就太大了,希望对它进行一个大而化之的简化,即希望从中选一些人大代表出来。只需要问问人大代表的意见,就能大概代表大部分人民的意见。
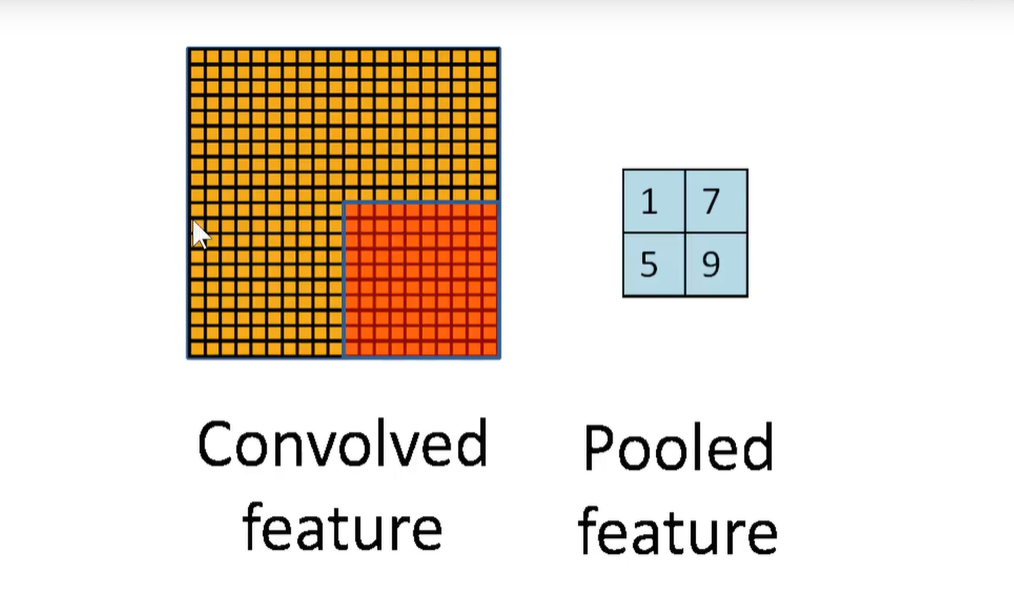
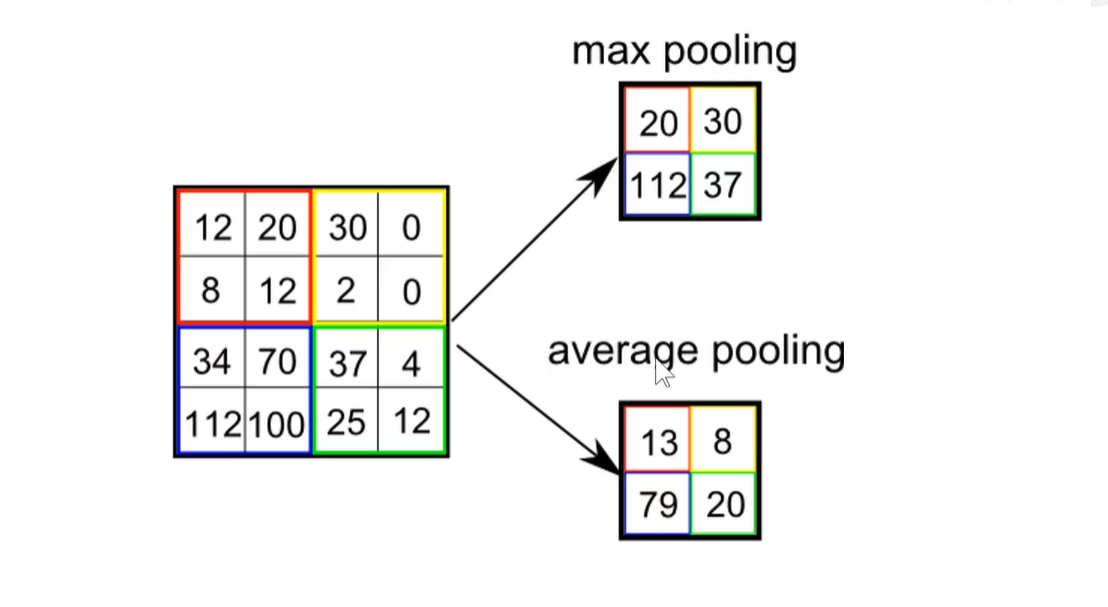
如何选取代表呢?最大池化/平均池化
如下图,当对人脸进行平移时,池化操作得到的feature-map仍然不变(依然可用)。正式因为有了池化操作,才使卷积神经网络具备了平移不变形。池化操作可以把平移这个变形操作给过滤掉。
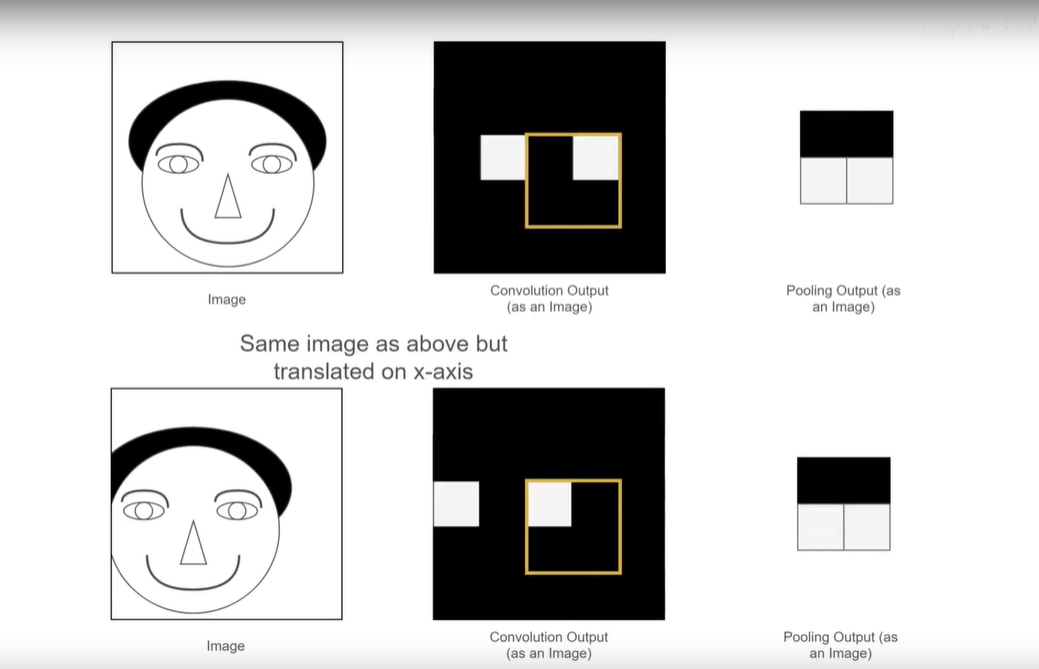
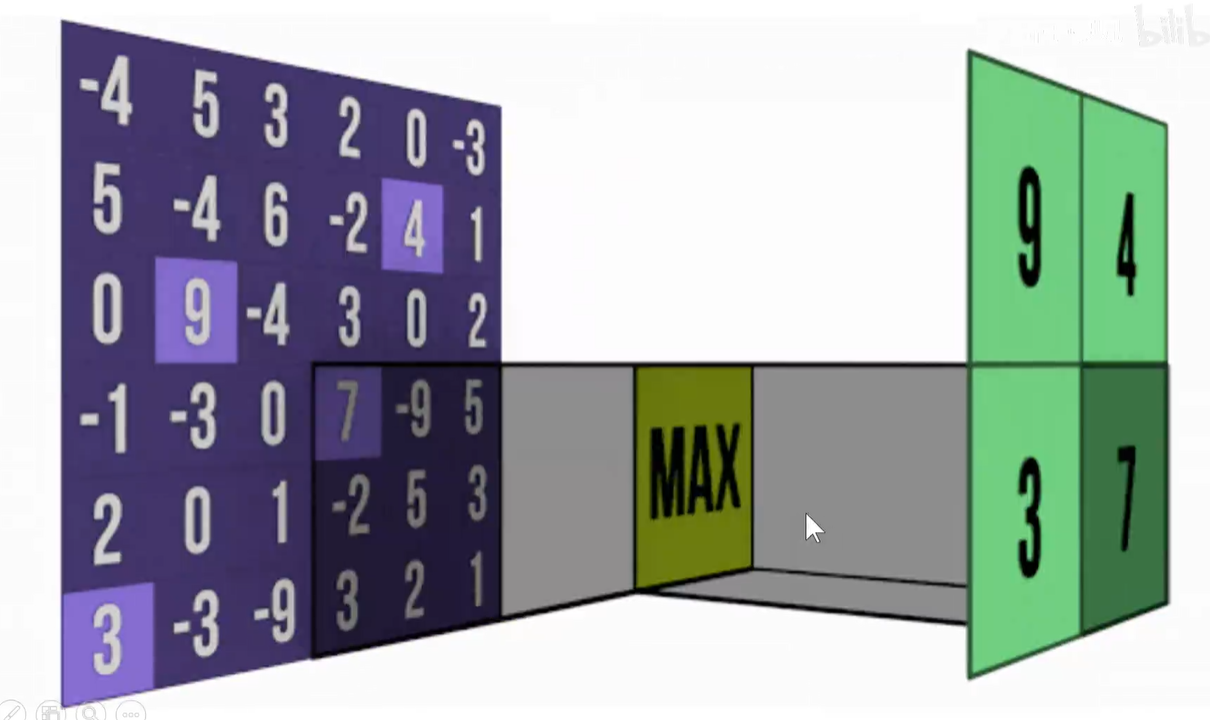
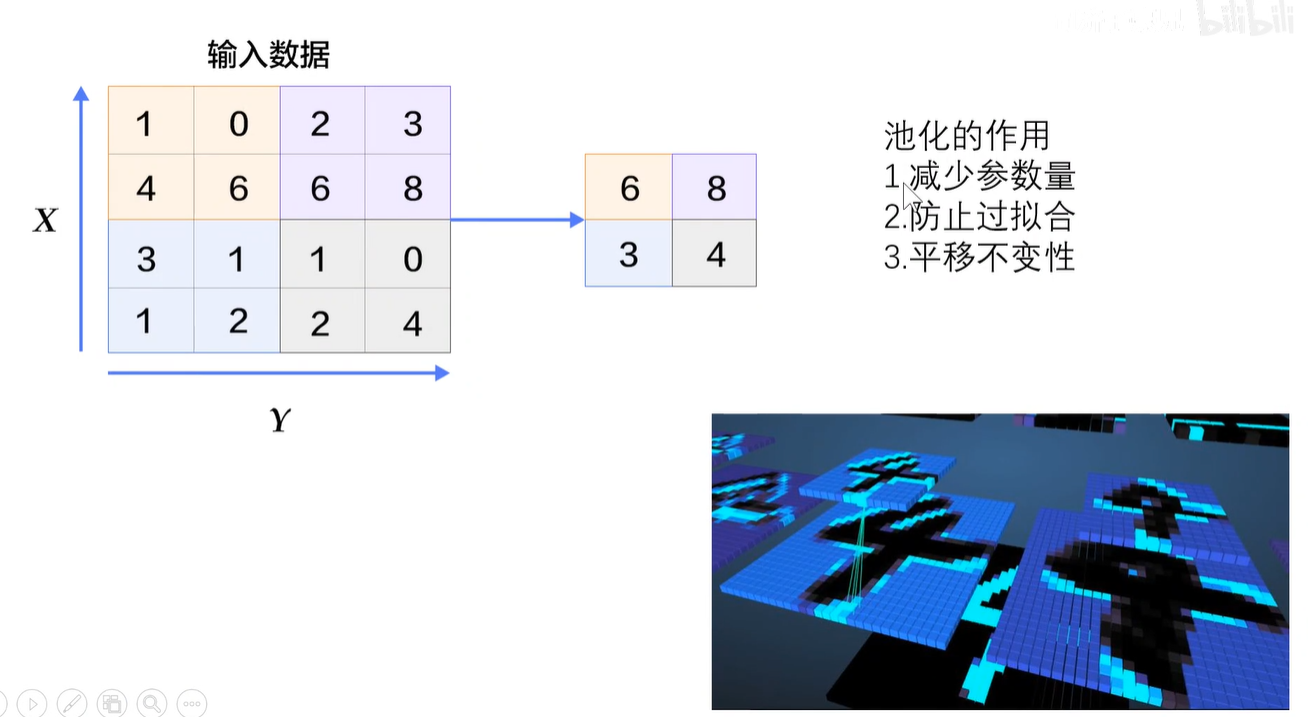
池化作用:减少参数量、防止过拟合、引入平移不变形。
2.4 ConvNet-CS231N-池化-全连接
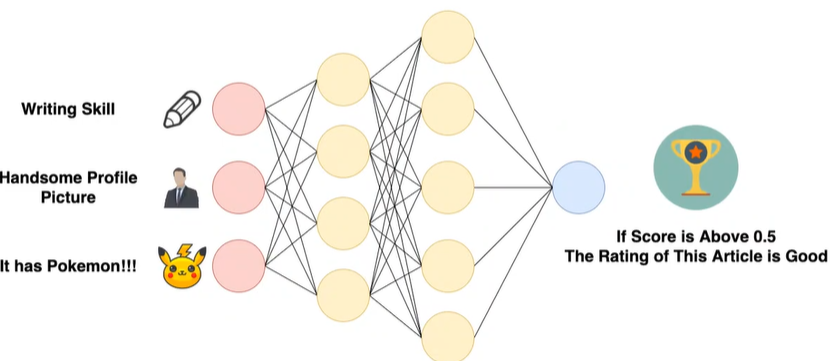
全连接层(多层感知机)一般放到模型的最后,用于汇总。将feature-map拉平成一个长向量,将它喂到一个多层感知器中进行处理,其实就是进行模型的汇总。
2.5 CNN流程
3D Visualization of a Convolutional Neural Network
该模型先把我们输入的图像变成一个单通道灰度图,即一个像素矩阵。
然后用6个卷积核对它进行卷积操作,一个卷积核生成个feature-map,6个卷积核就会生成6个feature-map。这6个卷积核分别提取原图中6个不同的特征,反映在这6个feature-map中。(正视仰视俯视斜视侧视..)
接下来对每一个feature-map进行下采样,即池化操作,可以看出上下两个6很像,该亮的地方一样亮,该暗的地方一样暗。实际上是对下层的feature-map进行了模糊处理(在保留了主要矛盾的基础上)。减少参数量,防止过拟合,同时引入平移不变性。
然后把这6个池化之后的结果堆叠起来,就是一个6通道的feature-map图像数据,喂给下一层,下一个卷积层是有16个6通道卷积核的卷积层,得到了16个feature-map。
我们对这16个新的feature-map再进行池化操作,就会得到新的池化后的feature-map,大图变小图。
最后把这16个经过池化后的feature-map堆叠起来,然后拉平成一个长向量,喂到第一层全连接层中,全连接层中每一个神经元都与上一层所有的元素相连。第二个全连接层与第一个全连接层的所有元素相连。
输出层其实就是一个经过softmax分类器拟合后的线性分类层,输出层有10个神经元,分别代表这个数字是0-9之间的概率。
上面就是1998年 LeCun教授提出的 LeNet-5模型。

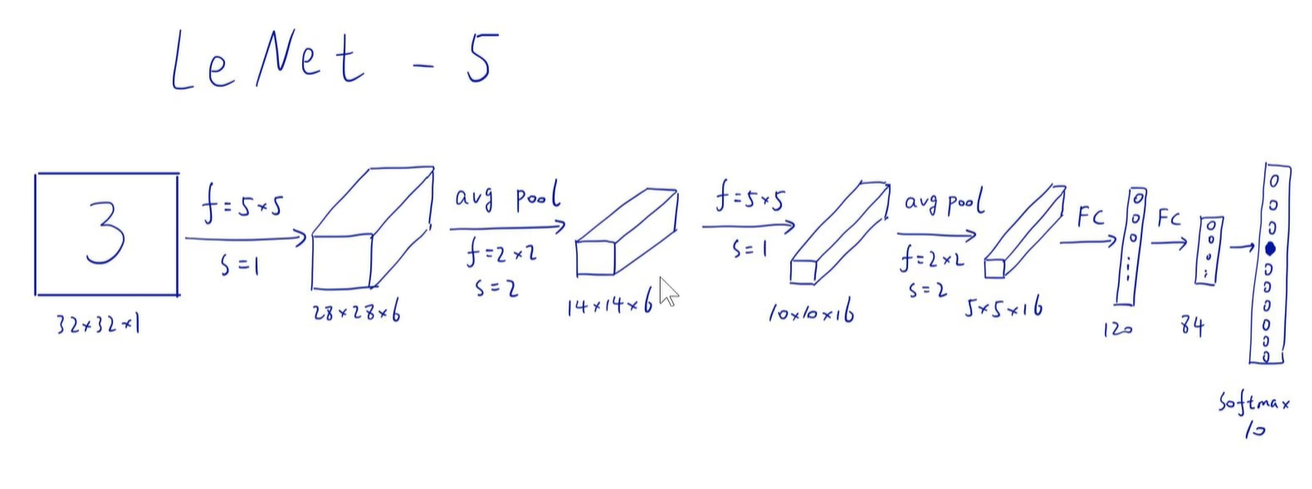
下图中很多技巧已不再使用,主要是碍于当时算力+数据的影响,当时只能使用这种的方案。
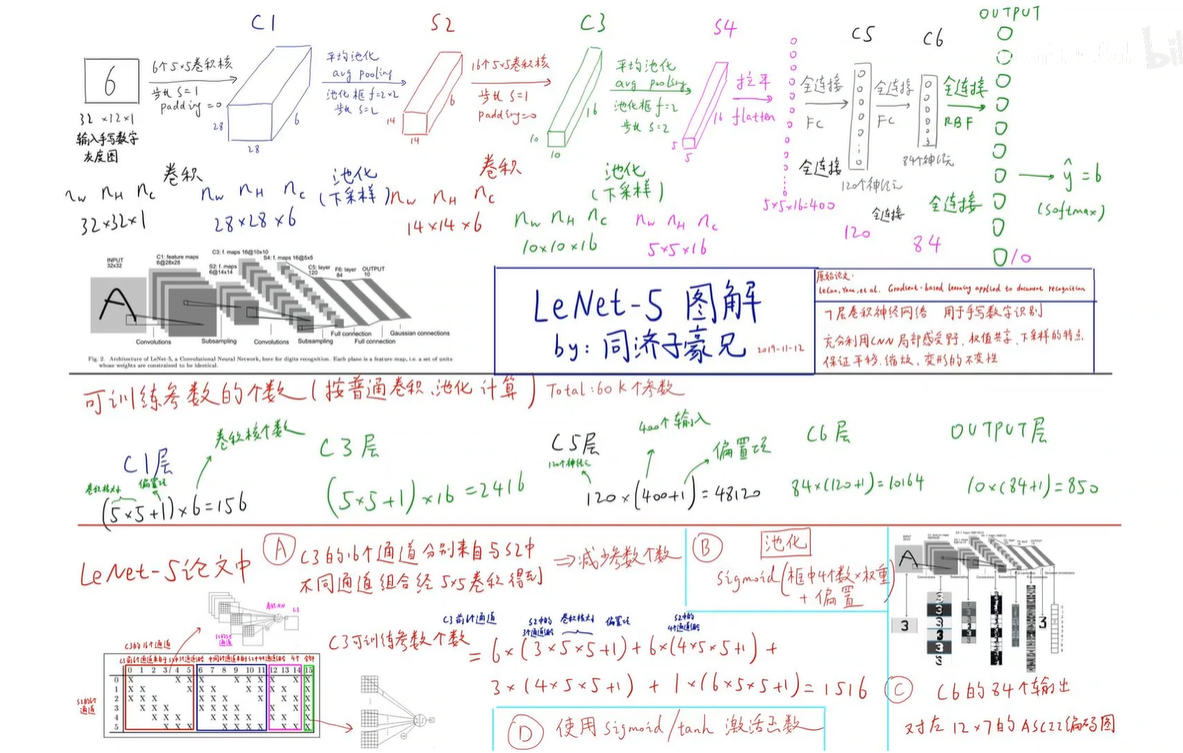
卷积神经网络如何训练?
训练量就是卷积核的权重+偏置项以及全连接层的权重和偏置项。依然是用大量的数据去喂它,采用Data-Driven的方法。
构造损失函数,然后用梯度下降和反向传播的方法求得损失函数对于每一个权重的梯度。然后更新和优化这些梯度,使得损失函数最小化。我们要更新和优化的权重就是卷积核的权重和偏置项以及全连接层的权重和偏置项。



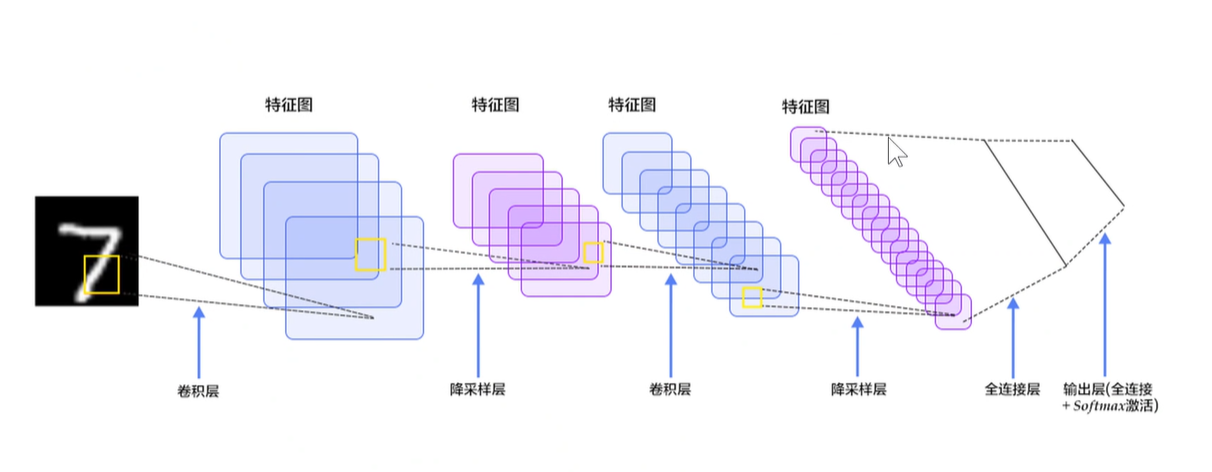
2.6 对VGG进行可视化
底层神经元抽取浅层特征,高层神经元抽取高级特征。
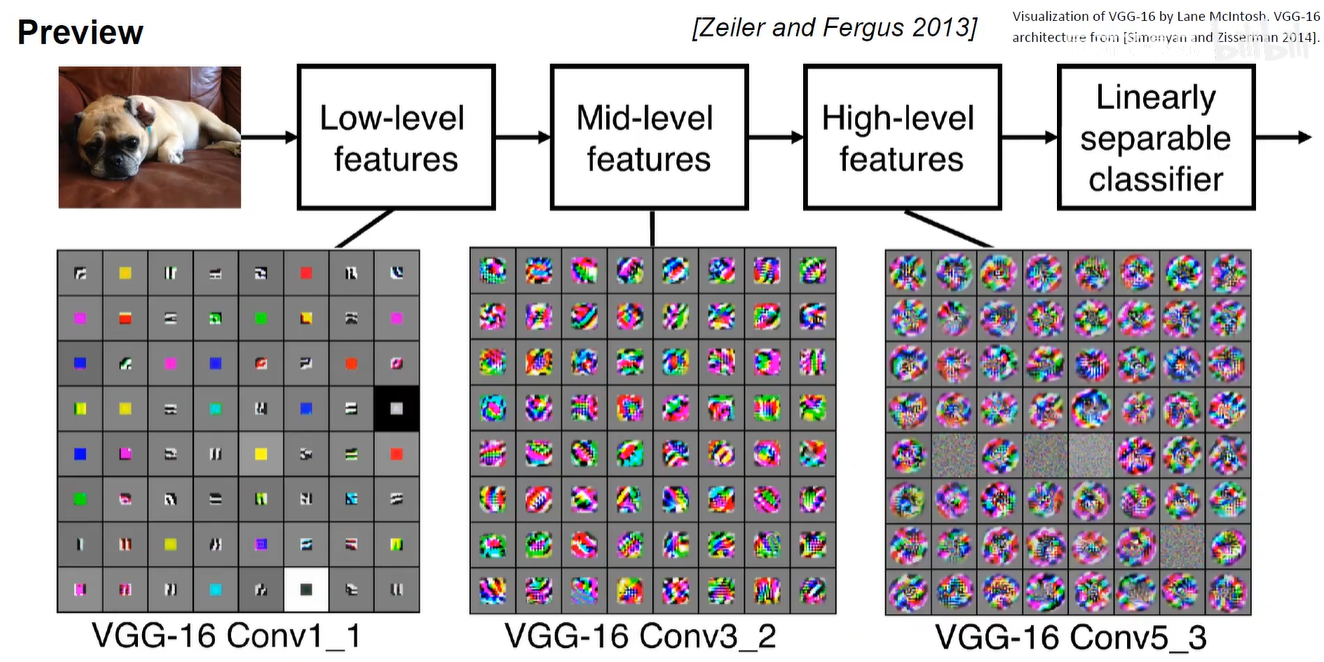
视觉仍然是分层的。验证了我们在神经科学和认知科学中的重要发现。
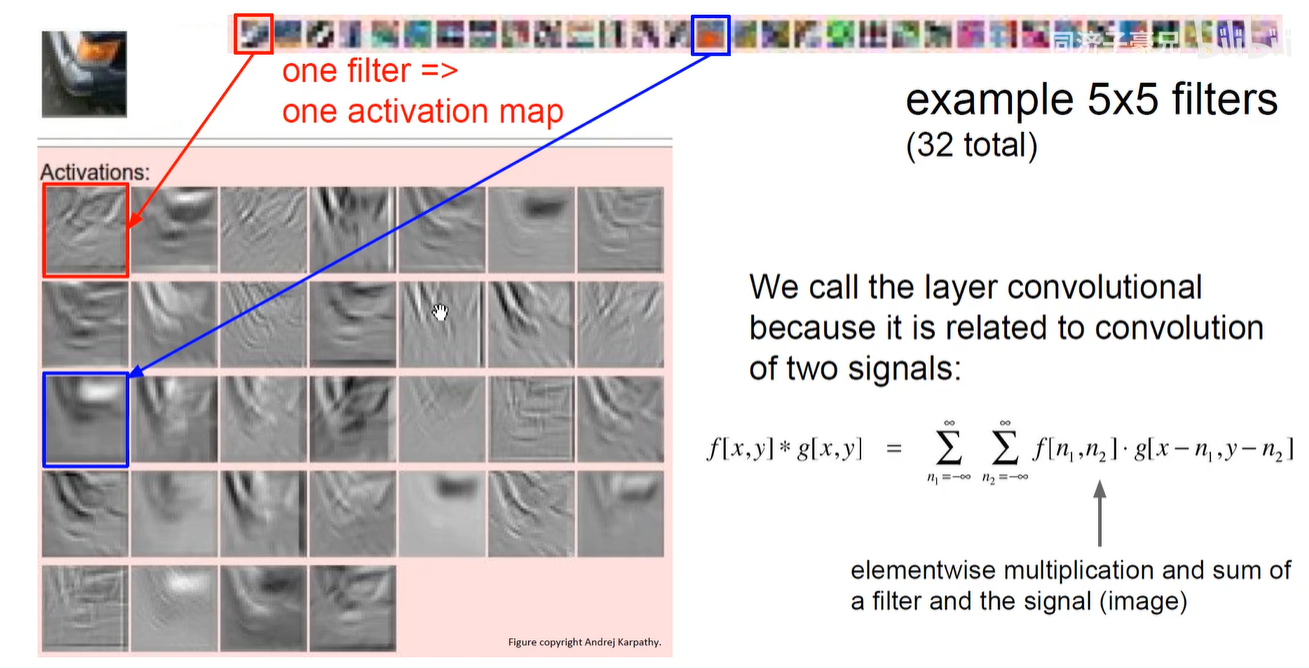
一个卷积核对应一个feature-map,下图采用32个卷积核。

2.7 输出数据体计算公式
参考AI其他文章
输入 W1 x H1 x D1,输出 W2 x H2 x D2,感受野=卷积核大小=F,填充为P,步长为S,卷积核数量为K。
W2 = (W1 - F + 2P) / S + 1
H2 = (H1 - F + 2P) / S + 1
D2 = K
一般不说明 P=0, S=1
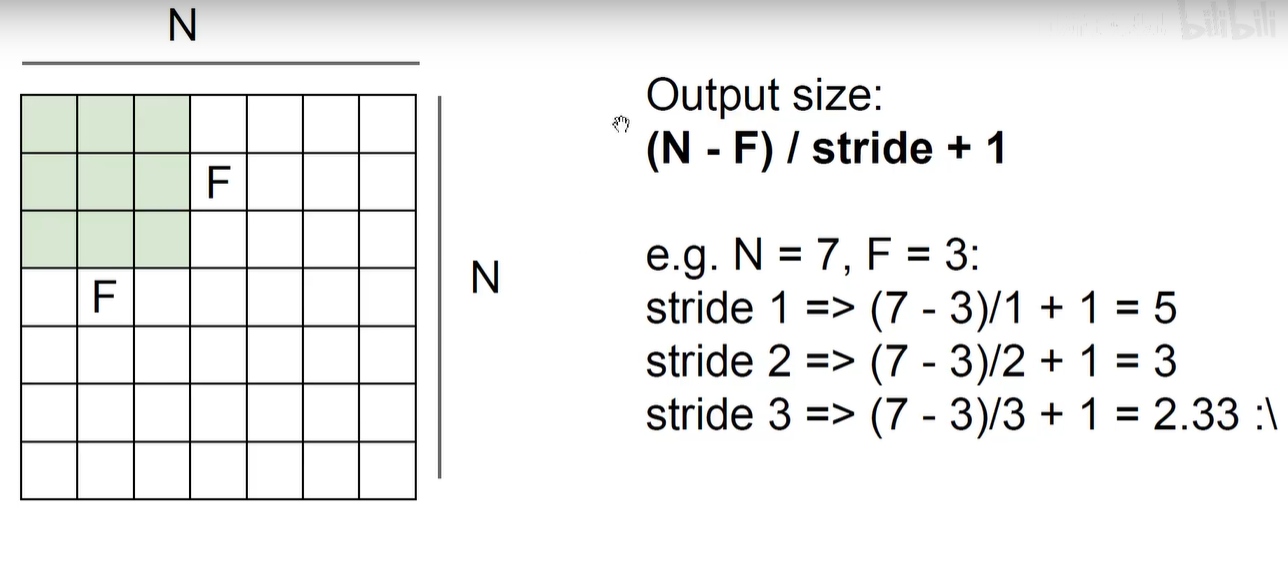
要想输入输出长度不变,一般在 S = 1 的情况下, P = (F-1) / 2


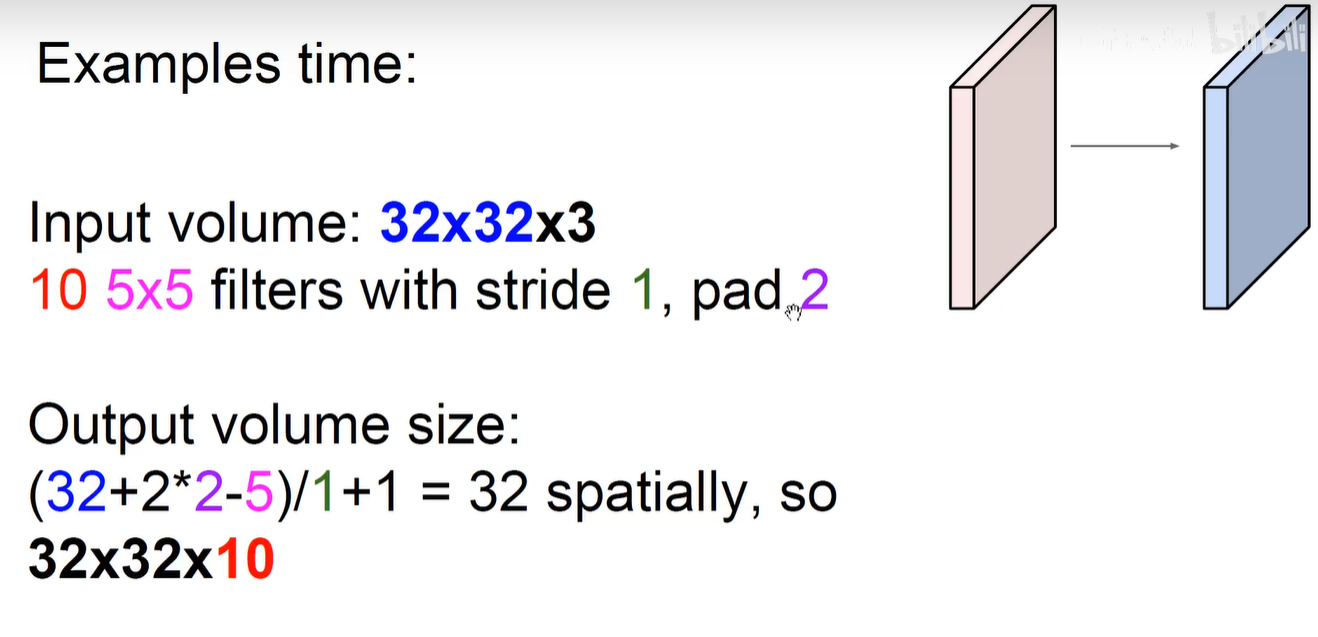
输出数据体的尺寸 32 x 32 x 10 (因为有10个卷积核所以,生成10个feature-map)
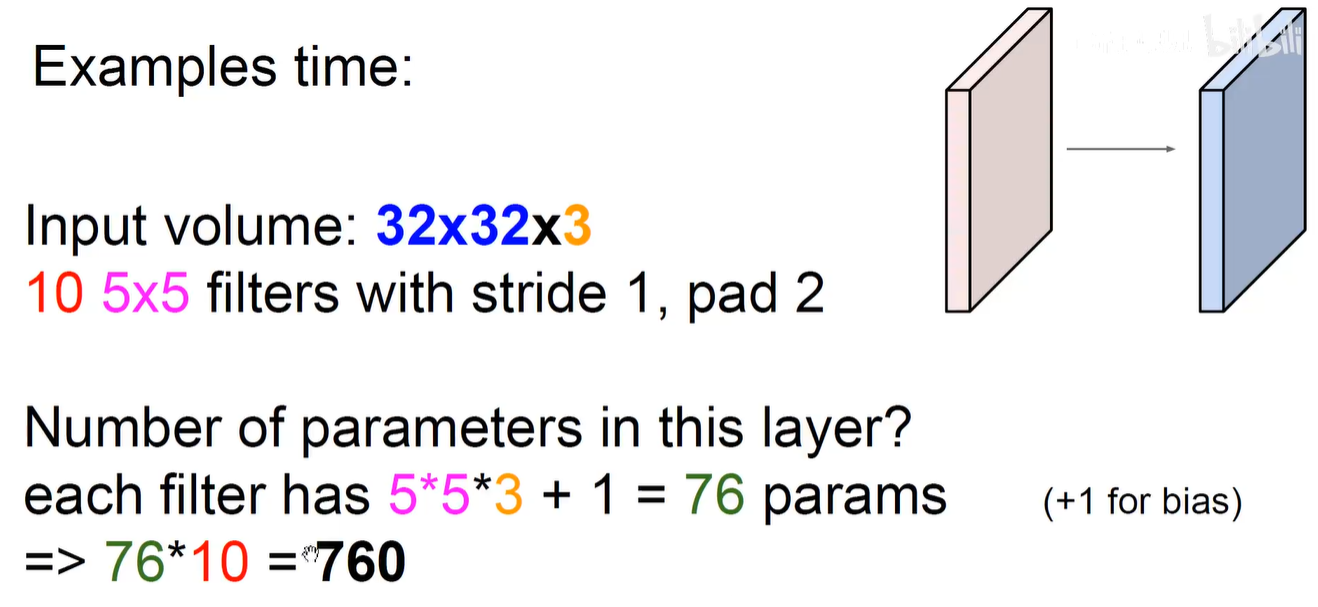
那参数量是多少呢?
2.7 输出数据体计算公式总结

3 1x1卷积
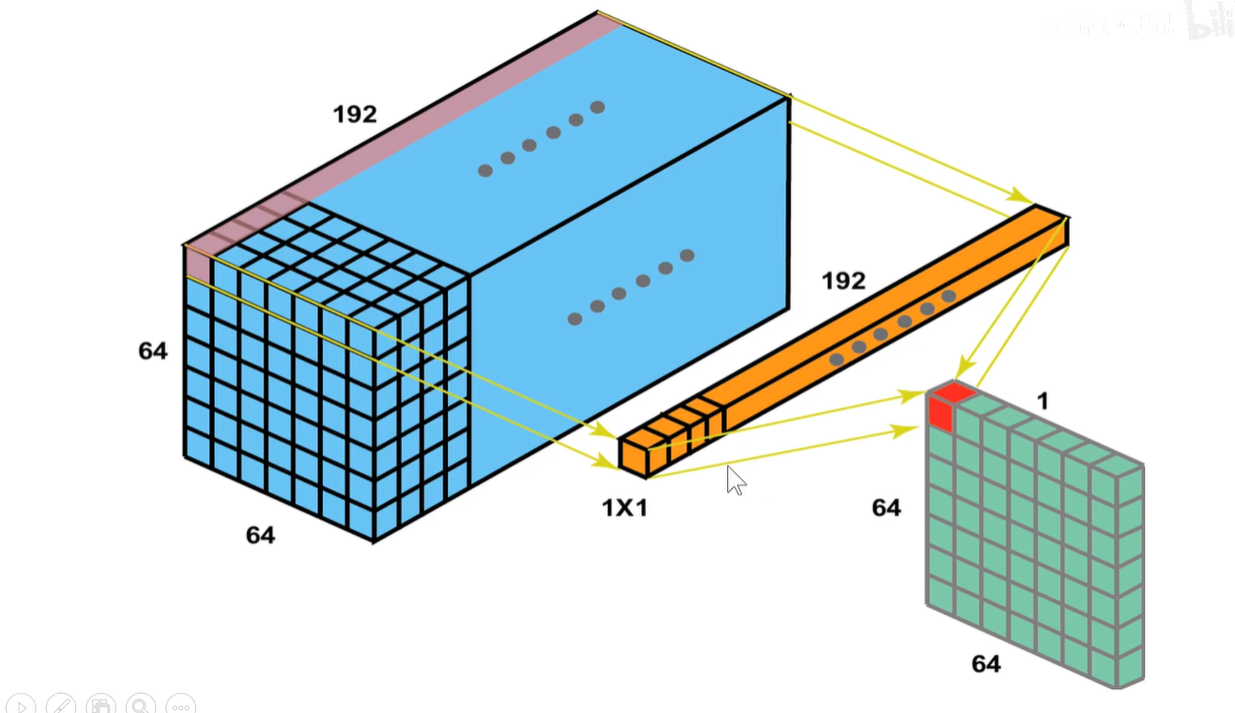
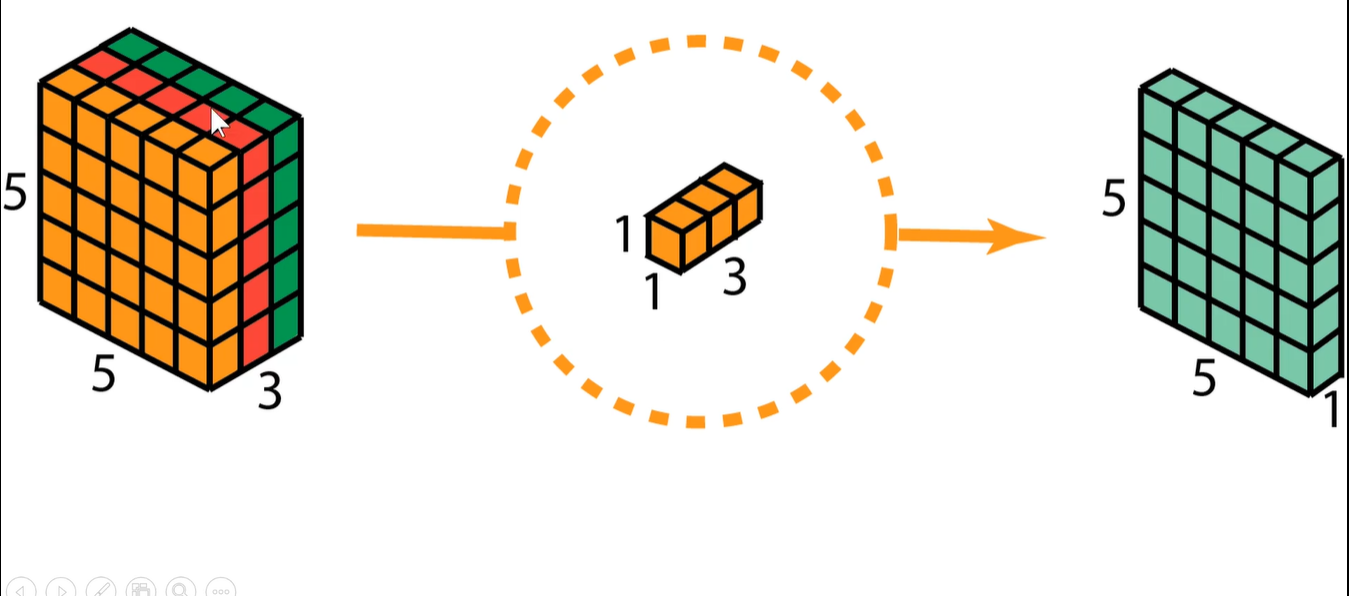
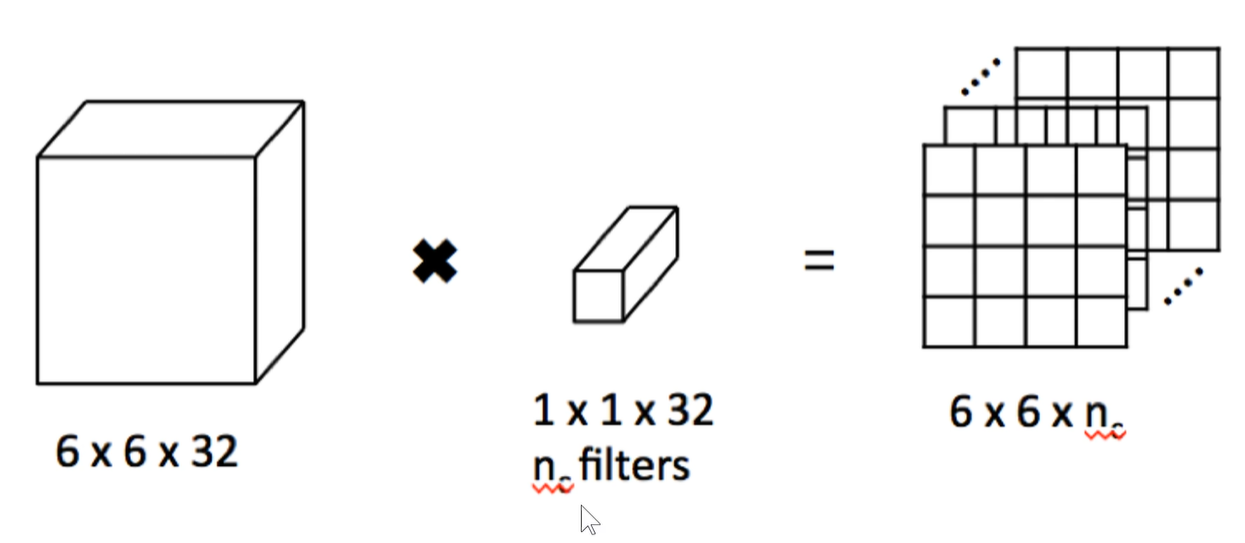
1x1卷积作用:比如输入是一个 64x64x192的图像,用1x1的卷积核对它进行卷积。输入图像有192个通道,所以卷积核也是192通道,即卷积核是 1x1x192,
第一次卷积,就是把图像上黄色的长条和原始图像上的一个长条相乘相加,填到右侧区域上第一行第一个位置。黄色长条和图像上第二个长条相乘相加填充到右侧区域上第一行第二个位置上,以此类推….
用2个卷积核,生成的feature-map维度就是2,不是图片中的单排数据,应该是两排堆叠。
用500个卷积核,生成的feature-map维度就是500,应该是500排堆叠。(类似于原始图像那样深度方向堆叠)。
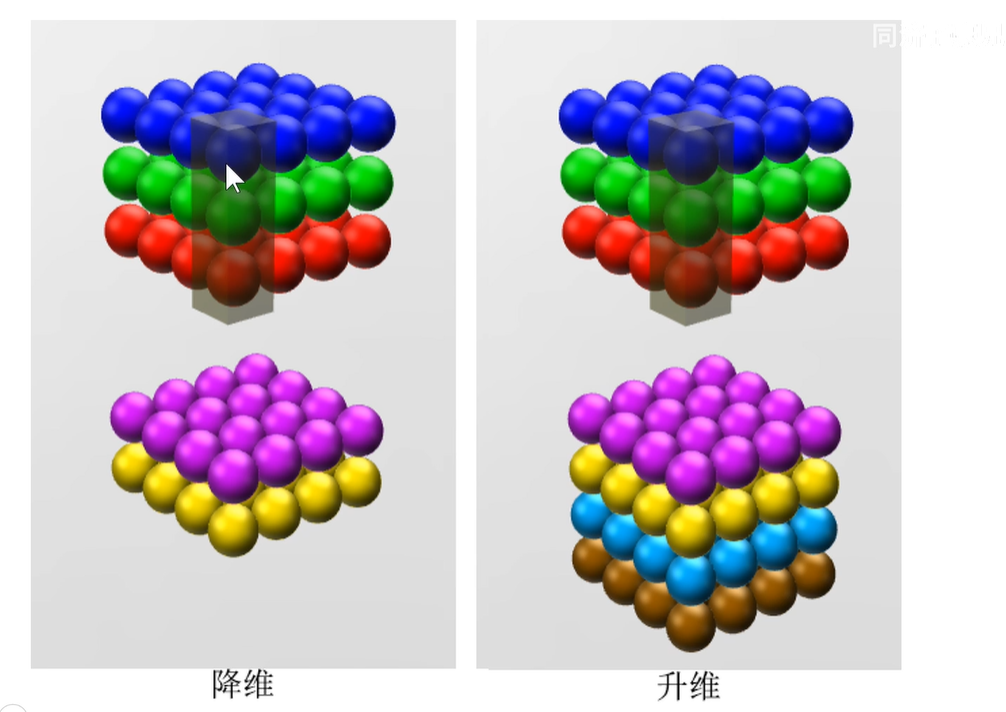
通过控制1x1卷积核的个数来进行升维或者降维。即如果比192小就是降维,如果比192大,就是升维。
大小是不变的,因为我们用的是1x1,完全把图片占满。
下图是一个3通道的输入。用1个1x1x3的卷积核,生成1个feature-map,即 5x5x1
本质上是把各个通道的数进行了求和加权汇总。
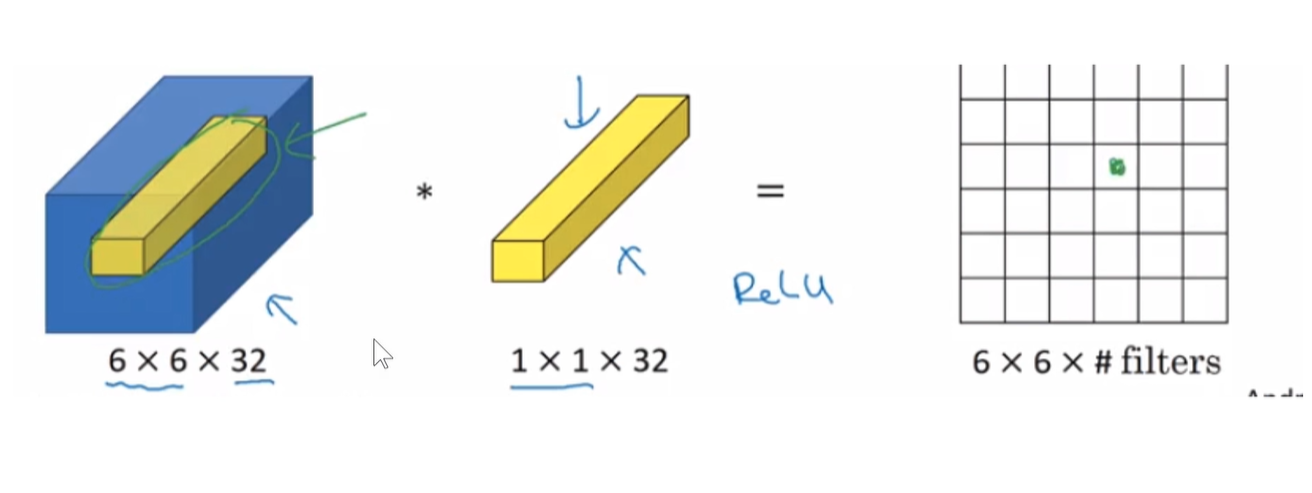
4 Network In Network论文
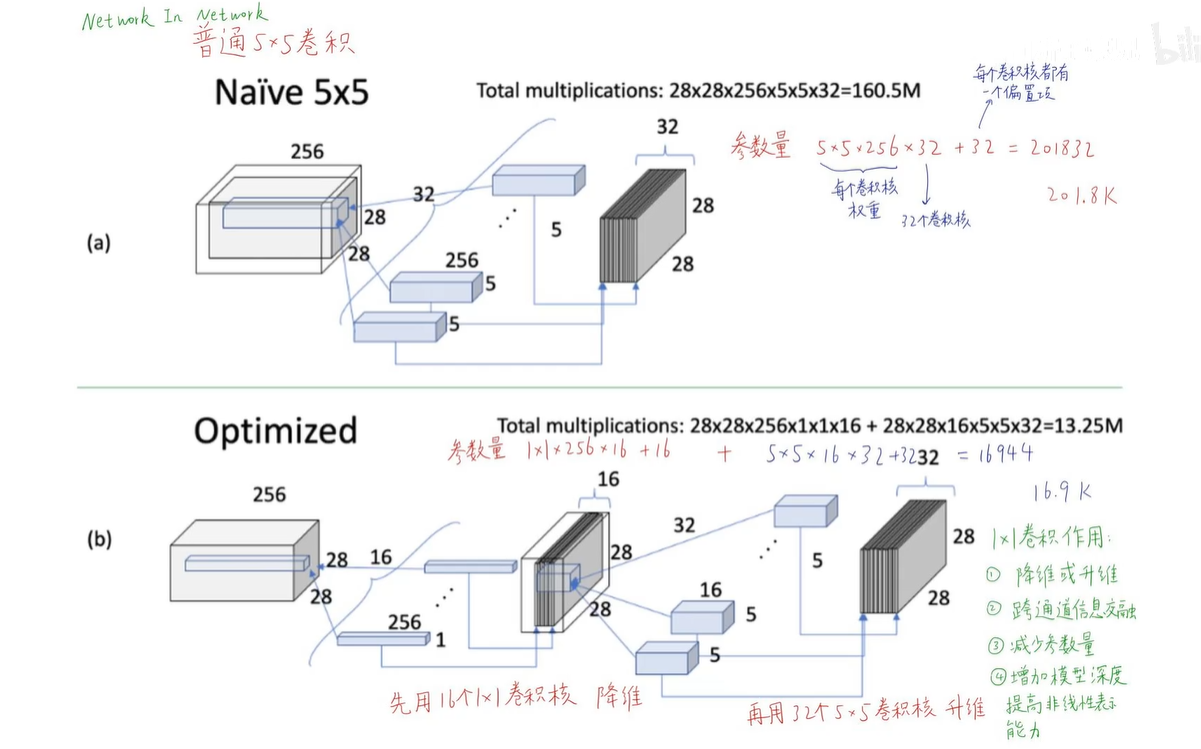
上面Naive版本:
参数量:5x5x256x32+32 = 201832
总计算量:5x5x256x28x28x32 = 160.5M (每个卷积核的权重 x feature-map的权重)
下面Optimized版本:
参数量:1x1x256x16+16 + 5x5x16x32+32 = 16944
总计算量:1x1x256x28x28x16 + 5x5x16x28x28x32 = 13.25M
计算量大大减少。
1x1卷积非常重要,特别是在我们希望参数量很少的时候,对于边缘计算,移动设备,他对于计算性能的要求比较大,我们希望模型尽可能轻量化。
5 神经元视野看待CNN

如上图所示:每一次卷积操作其实就是一个神经元的计算。原图上的像素可以认为是 x , 卷积核上的权重可以认为是w,对应元素相乘再相加,加上偏置项,整体交给激活函数来进行激活。
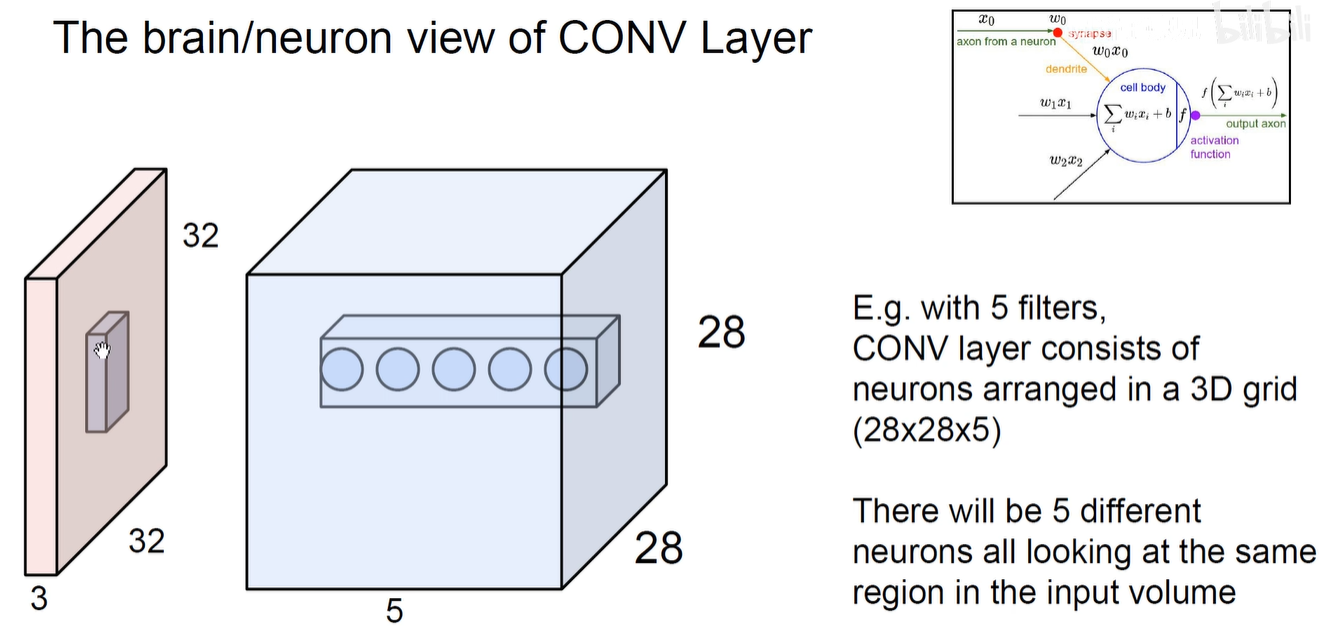
如上图所示:Feature-Map中同一个通道就反应了同一个感受野下用不同的卷积核对它进行卷积操作,提取到的不同特征。即我们用5个卷积核分别对同一块感受野进行卷积,就得到了feature-map中同一个位置的不同通道的结果。
用1x1卷积其实就是将不同通道的数扎起来,扎穿了,不同元素进行融合,所以1x1卷积可以进行跨通道的信息交融。
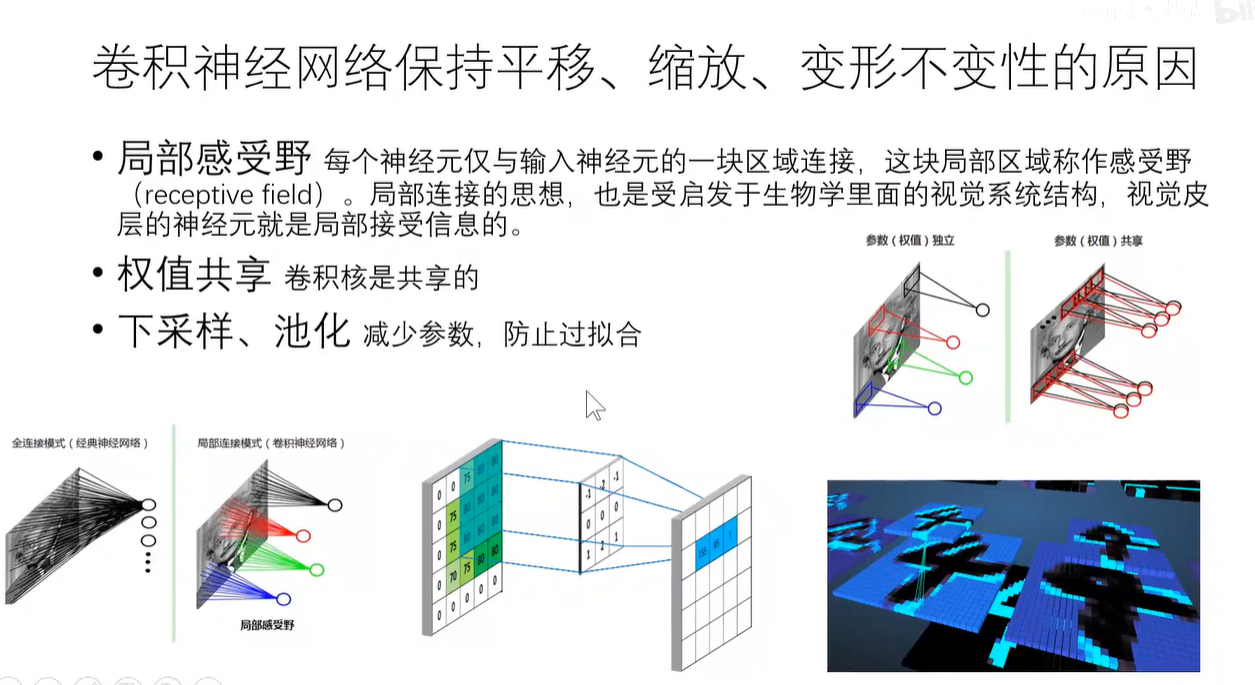
卷积神经网络三大特点:局部连接-权值共享-下采样。
5 Summary

一般不希望使用池化层和全连接层,仅使用CONV层。
池化层:虽然带来了平移不变性,但丢失了空间信息。
FC:参数量太大。如VGG有16亿参数,绝大多数都是第一层FC产生的。而且FC层也会把Feature-Map拉平,导致丢失空间信息。