Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N
1 前言
我们知道,深度学习模型-CNN是一个黑箱子,我们只知道他能够Work,但是不知道他为什么能Work,不知道中间的那些层他们之间的关系是怎样的。
1980年美国军方斥巨资进行了一项研究,草地上的坦克是真的敌方坦克还是充气玩具。这个军事意义非常大,在诺曼底登录时,德军就是被英美联军的充气坦克给蒙蔽了,误以为盟军要进行加莱
最后发现巴顿将军登陆了诺曼底,巧妙的避开德军重兵防守的一些区域,所以甄别坦克真假是极其重要的。当时的美国国防部采用了很多白天敌方坦克的真实图像,又用了晚上的充气玩具假坦克的图像进行训练,训练完之后发现在测试集上的准确率是100%,模型怎么这么成功!他们就拿到五角大楼去炫耀。后来知道他们并不是得到识别真假坦克的分类模型,而是识别到了白天和晚上的模型。神经网络误以为我们要学习的是白天还是夜晚,而不是真假坦克。
由此可见,对于一个黑箱子,我们要彻底把它了解透彻,才不会闹这样的笑话。
今天学习了可视化CNN,就能够全方位、多角度去了解这个网络到底观察和注重的是那一部分,它的中间层到底是如何进行信息沟通的。
2 回顾

之前讲了CNN的任务和广泛应用,如人脸识别、医疗诊断、图像分割、物体检测、人体姿态估计、强化学习、交通标志识别、无人驾驶、车道线检测,只要是和计算机视觉有关的,都会用到CNN。
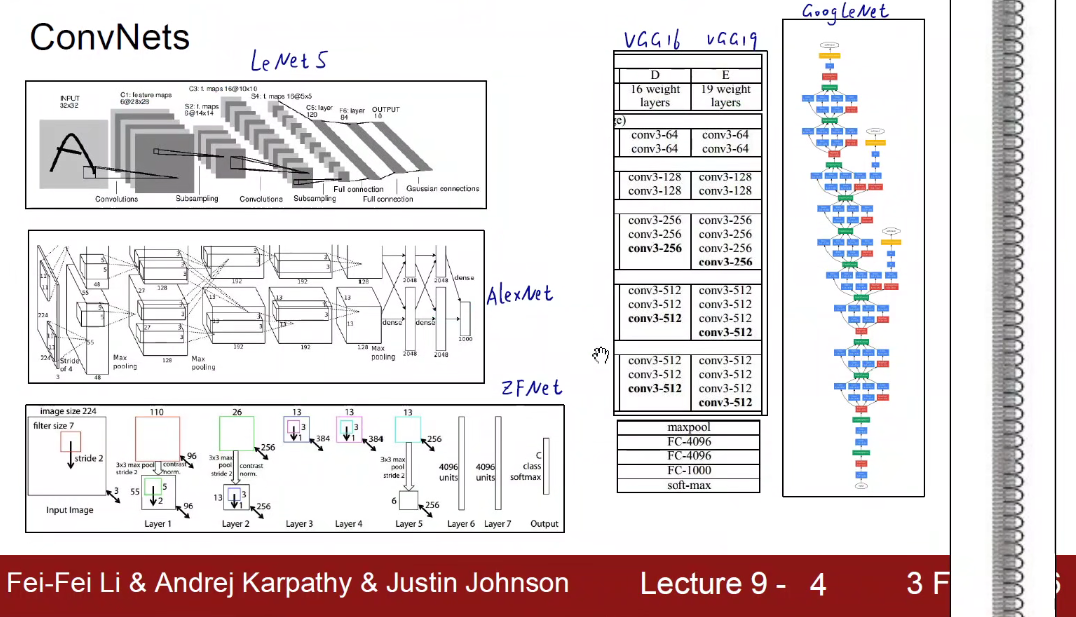
1998 LeNet-5
2012 AlexNet
2013 ZFNet
2014 VGG GoogleNet
2015 ResNet
CV主要解决的基本问题
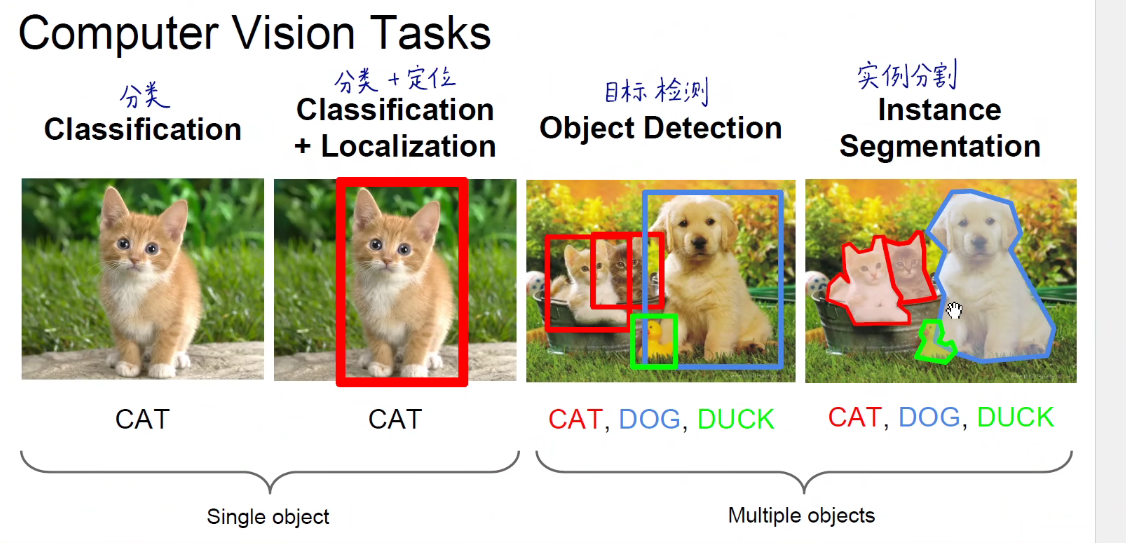
分类:给一张图片,网络给出它是什么东西。
分类+定位:再加上一个框。
多个目标分类:目标检测 + 框 框选出不同类别
实例分割:像素级别的抠图,就是语义分割和实例分割。
3 Understanding ConvNets

3.1 能使指定神经元激活的小图片

如上图,找到能够使指定神经元激活最大值的小图片。比如我们以AlexNet中的池化层5为例,把数据集中的全部数据截取这样的小图片,喂到网络中,看看哪些图片能够使得这里面某些神经元激活最大。会发现:
有些神经元对人(第一行)这样的小图比较敏感,有些对点阵这样的小图片激活值比较高,有些对文字的激活值比较高,还有的对球形反射的小图片比较敏感,如第一个锃光瓦亮的大脑门。
3.2 CNN权重可视化
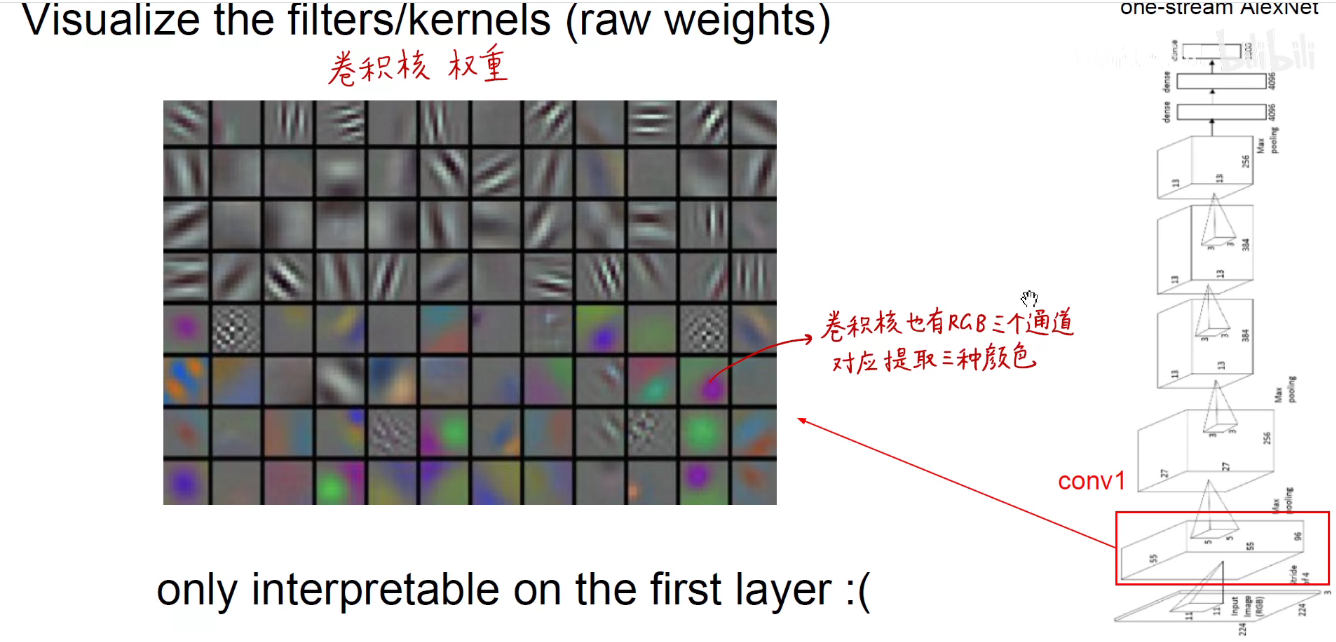
如上图,我们可以直接对卷积核的权重进行可视化。第一层的卷积核它的通道是3,对应输入图像额RGB三通道,进而对应提取三种颜色。如果我这个卷积核对提取的是绿叶,那么它肯定对绿色感兴趣。

如上图,第一层使用了 16个 7x7x3的卷积核,第二层使用了 20个 7x7x16的卷积核,第三层使用了 20个 7x7x20的卷积核。
三层的通道数分别是:3 16 和 20。
每一个括号表示了一个卷积核,括号中的小图表示每一个通道的权重。

如上图,底层的卷积核提取到的是类似于 gabor这样的滤波器特征。不同角度的、颜色的、边缘的、方向的。
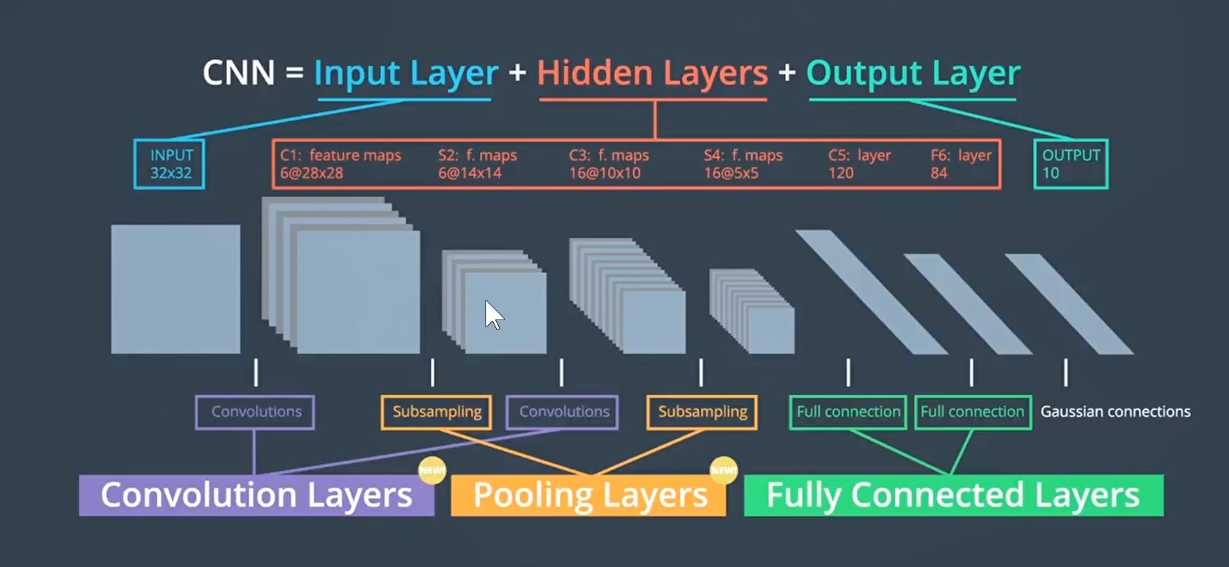
如上图:CNN的经典架构在1998年的LeNet-5基本已经确定。
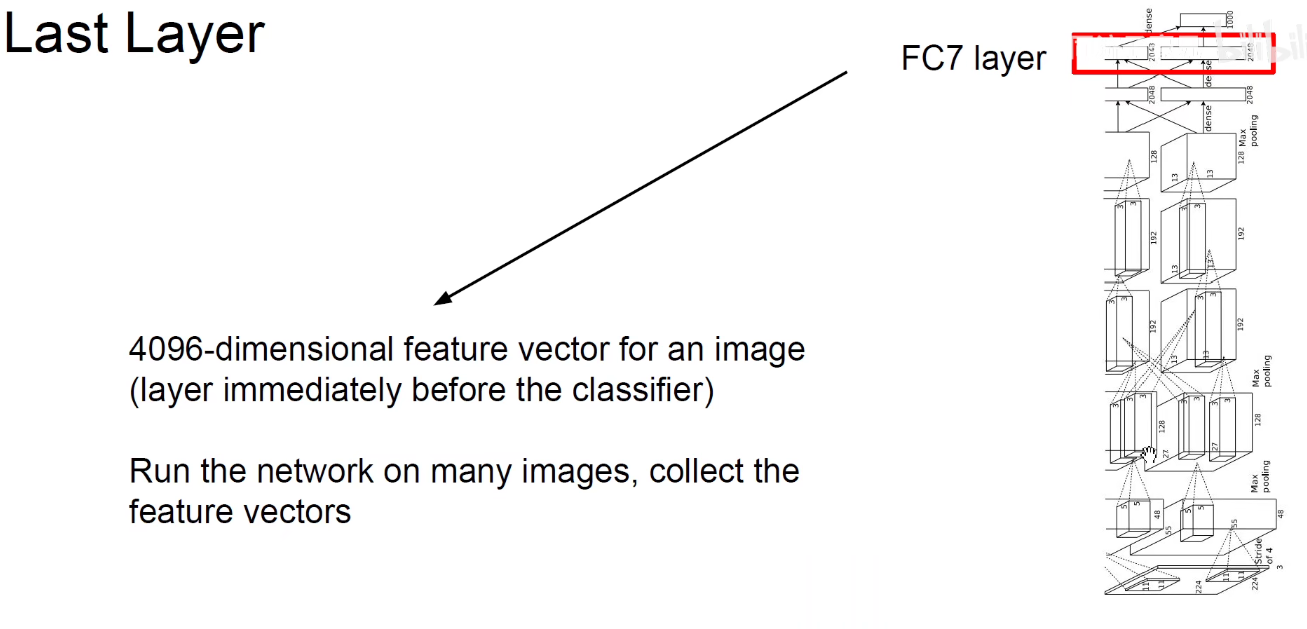
模型前面的任务是要把图像映射到一个线性可分的4096维空间。
提取出FC层4096维向量,用向量表示经过编码之后的图像。
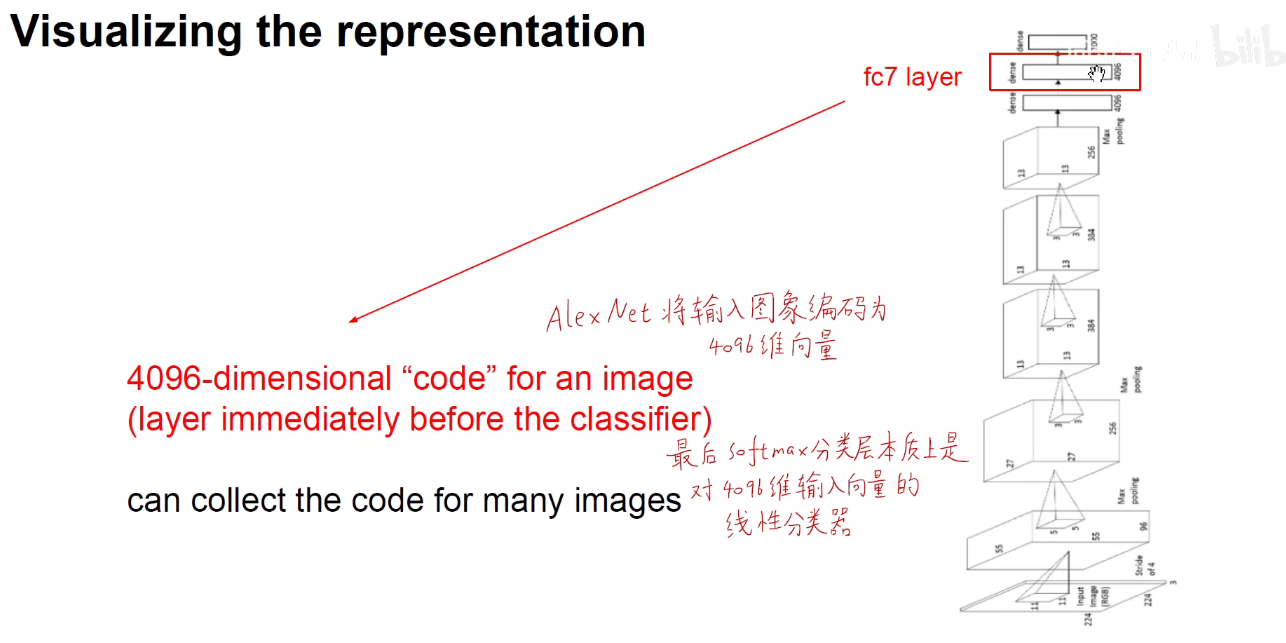
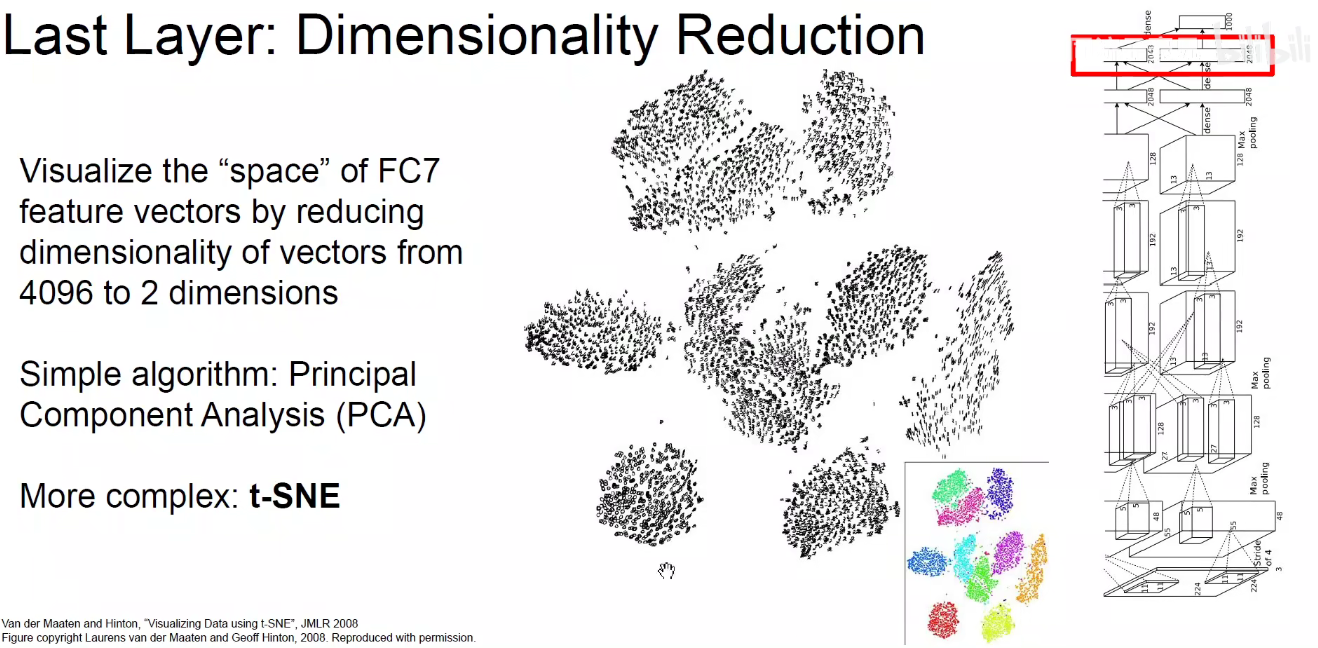
3.3 降维如T-SNE
如下图:可以使用降维算法对模型进行降维操作。如使用PCA-主成分分析的线性降维算法,T-SNE非线性降维算法(T分布和随机近邻嵌入)。UMAP也是近年来经常使用的一种非线性降维算法。

T-SNE基本思路:4096维的高维空间向量,在低维空间中保留高维空间的距离信息。如果两个高维的4096维向量在原始高维空间中隔得就比较远,降到两维后,让他们隔得仍然很远。
T-SNE:可视化界面,https://projector.tensorflow.org/

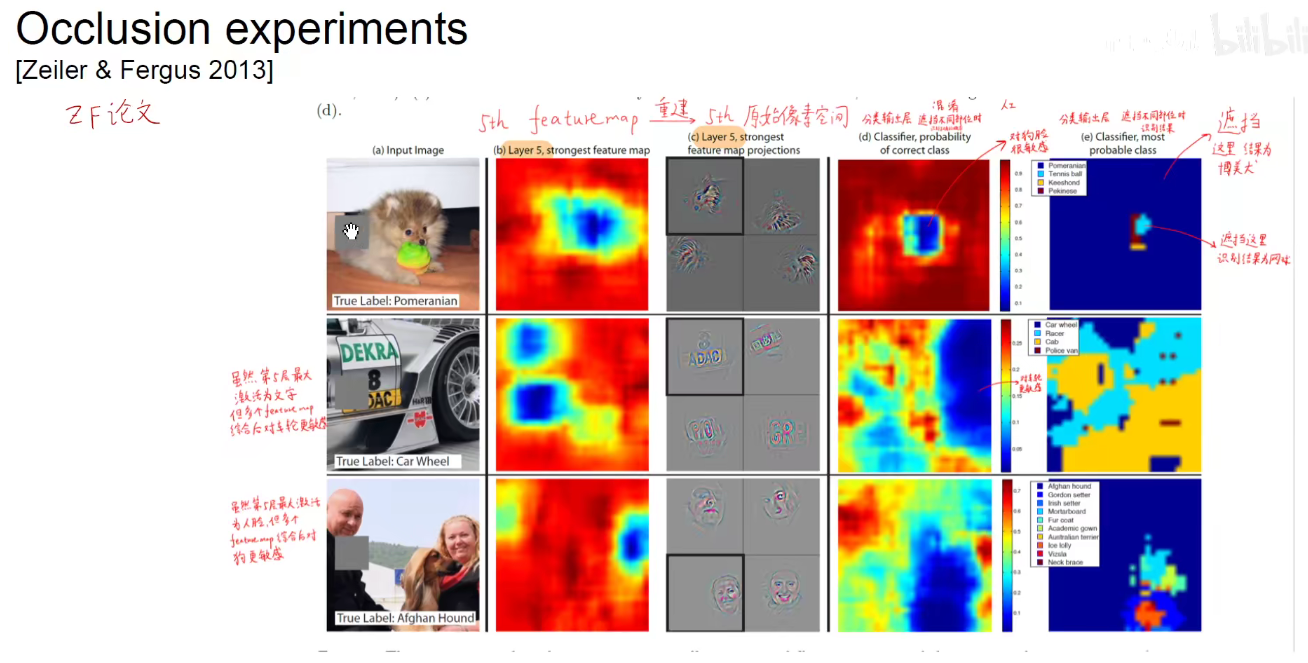
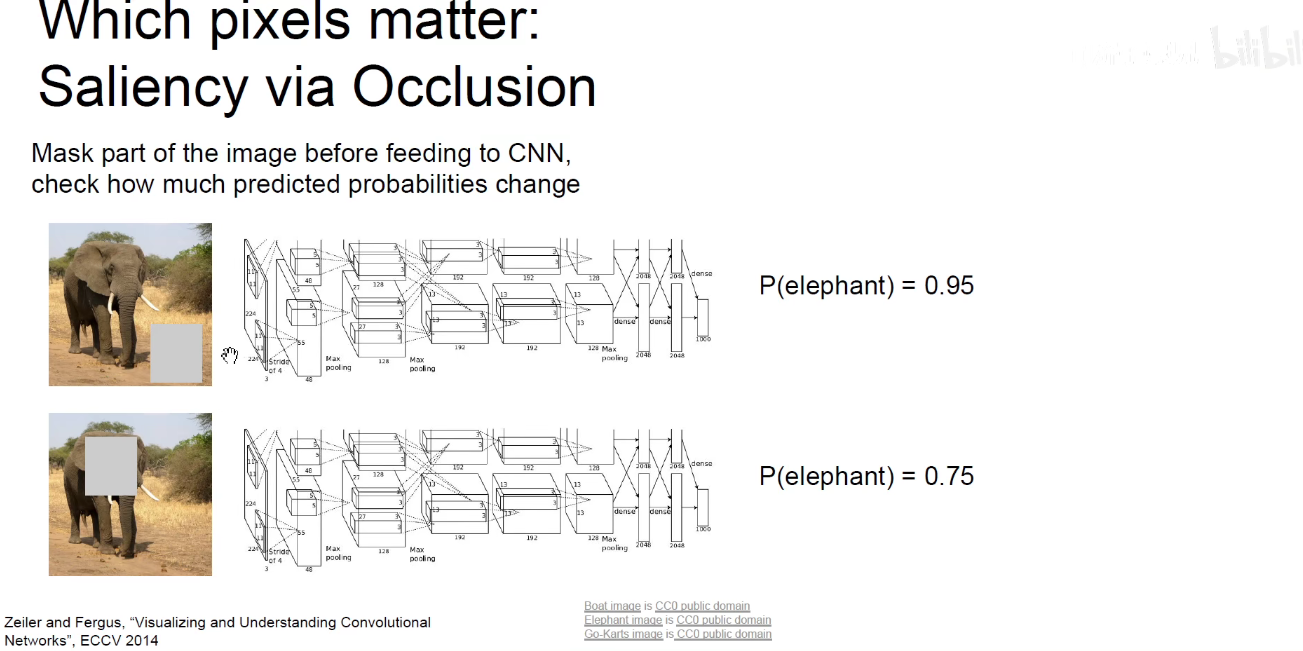
3.4 Occlusion-Experiments(遮挡实验)
卷积神经网络交互式可视化工具

3.5 Deconv approaches
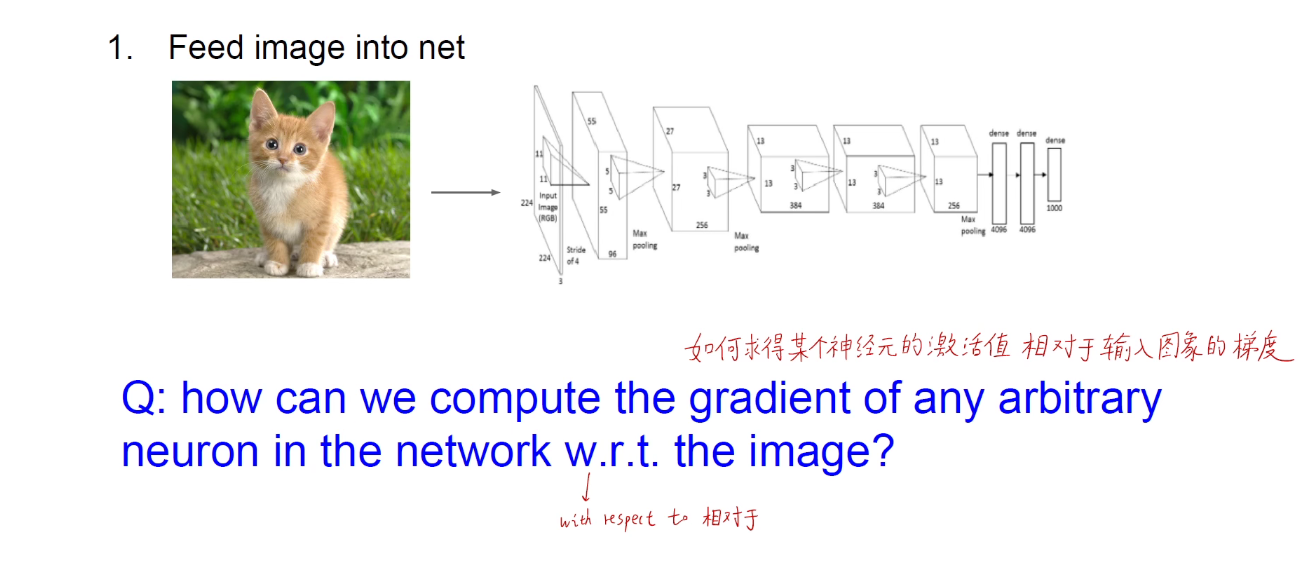
也开始使用BP思想进行计算
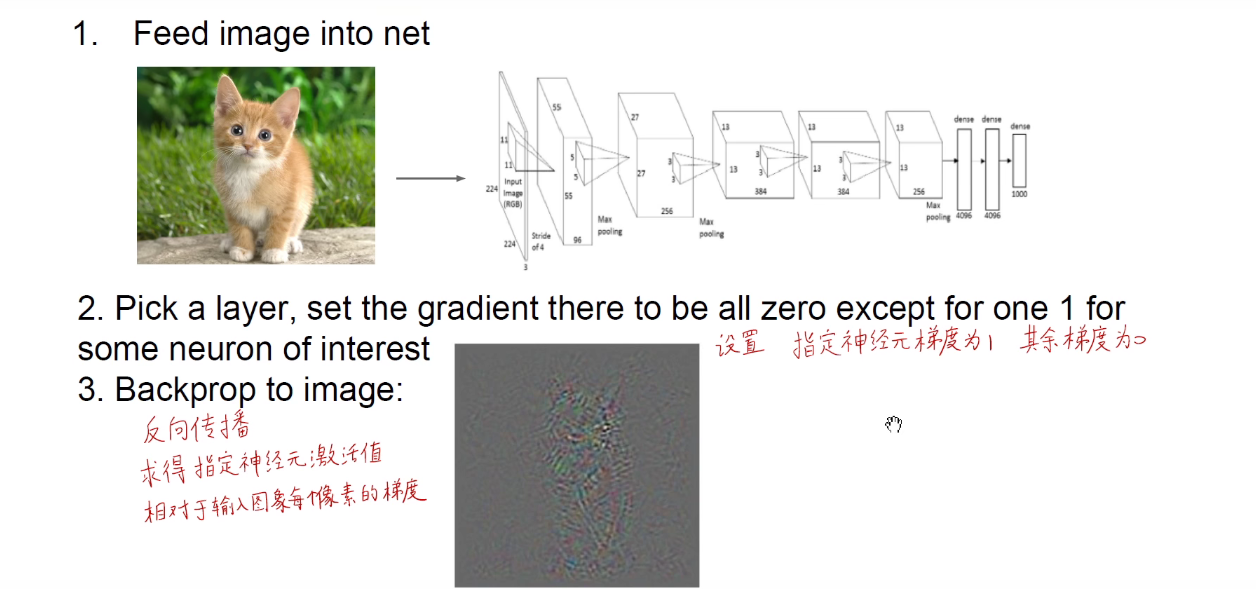

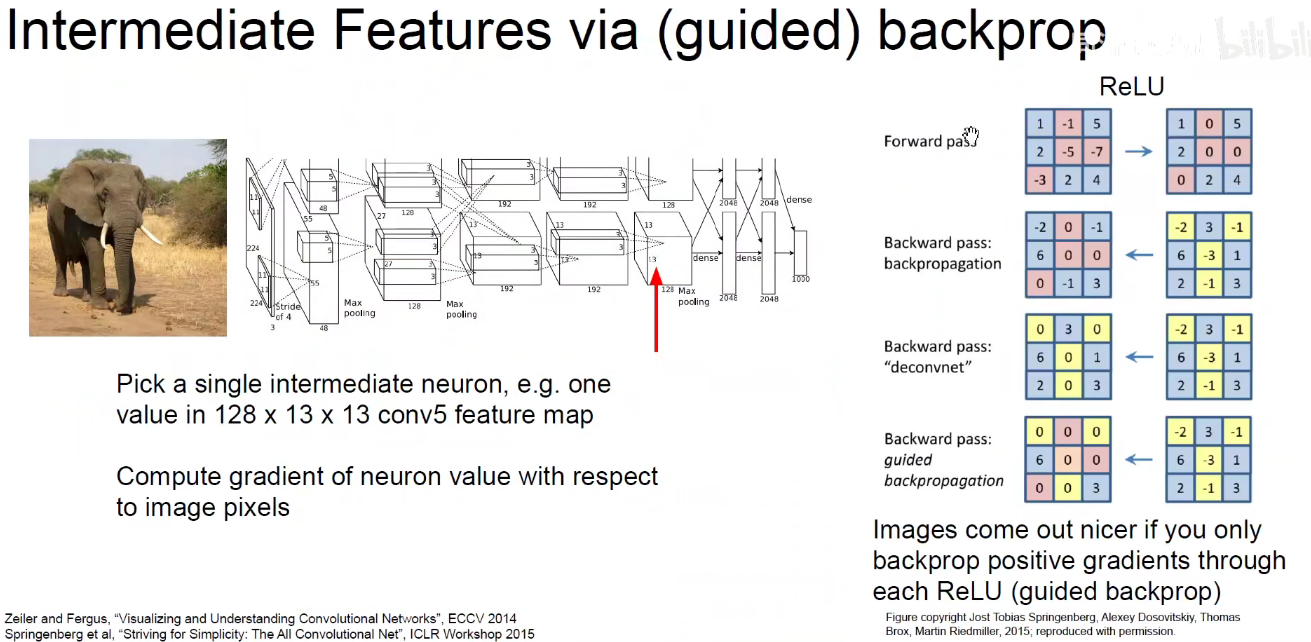
导向BP:导向反向传播相对于反向传播图像更清晰,导向反向传播相当于优中选优。
导向反向传播求得每个神经元相对于输入图像的图,它所生成的图轮廓更加清晰。如下图所示:

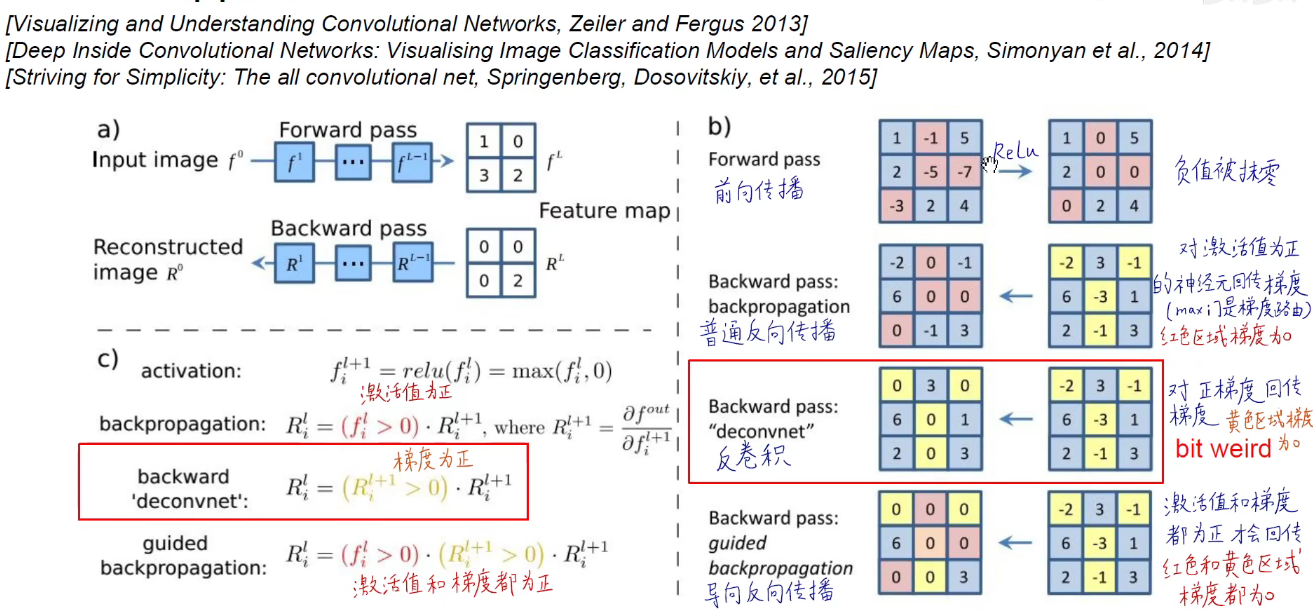
不管是普通BP,反卷积还是导向BP。他们的目的都是求得某个神经元的激活相对于原始输入图像的梯度。其实就是将中间层某个神经元的输出重构回原始输入像素空间(人类可理解的)
用DeConv的方法进行重构
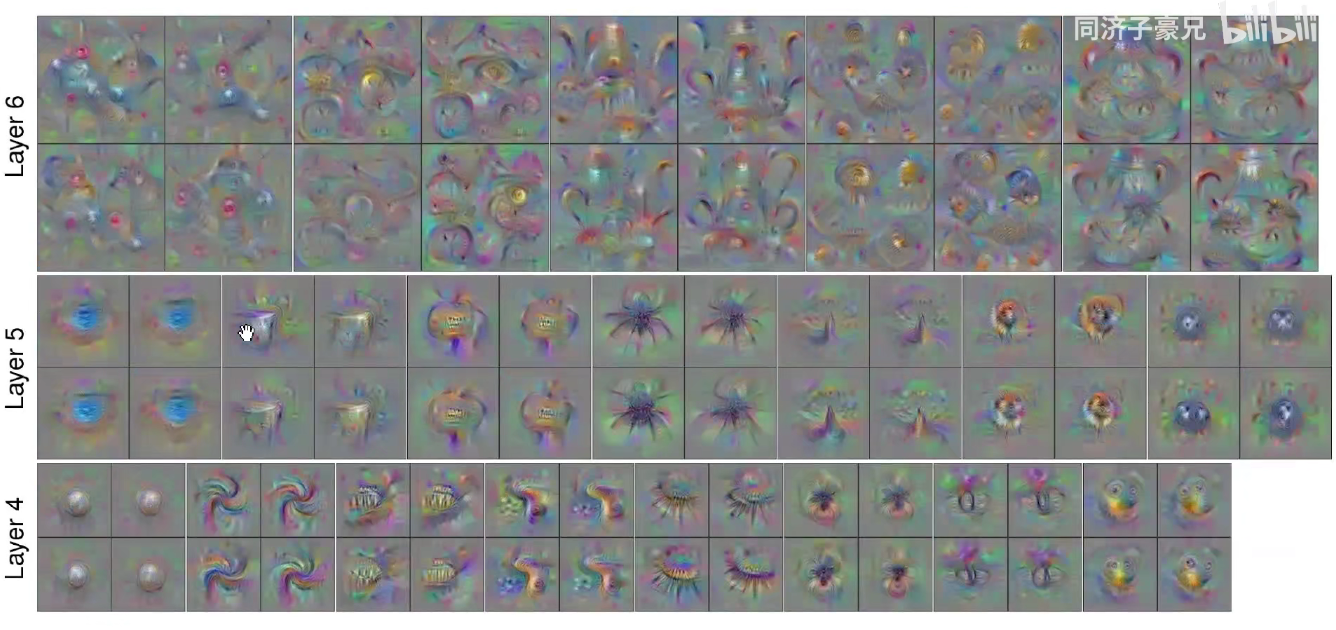
如下图:在底层Layer1进行了反卷积后,他提取到的一些边缘、颜色、转角、gabor滤波器这样的浅层特征。
Layer2 就变成了形状,layern 层数越高,他提取到的特征就越特化和抽象复杂。

如下图所示:右边这些图是真实数据中的一些小图(patch/crops),这些小图能够使得我们挑选出来的神经元的激活最大。我们把这些图对应的激活重构回原始像素空间,就得到了左边这些灰色的可视化的特征图。


3.5 生成一张使某个神经元激活最高的图像
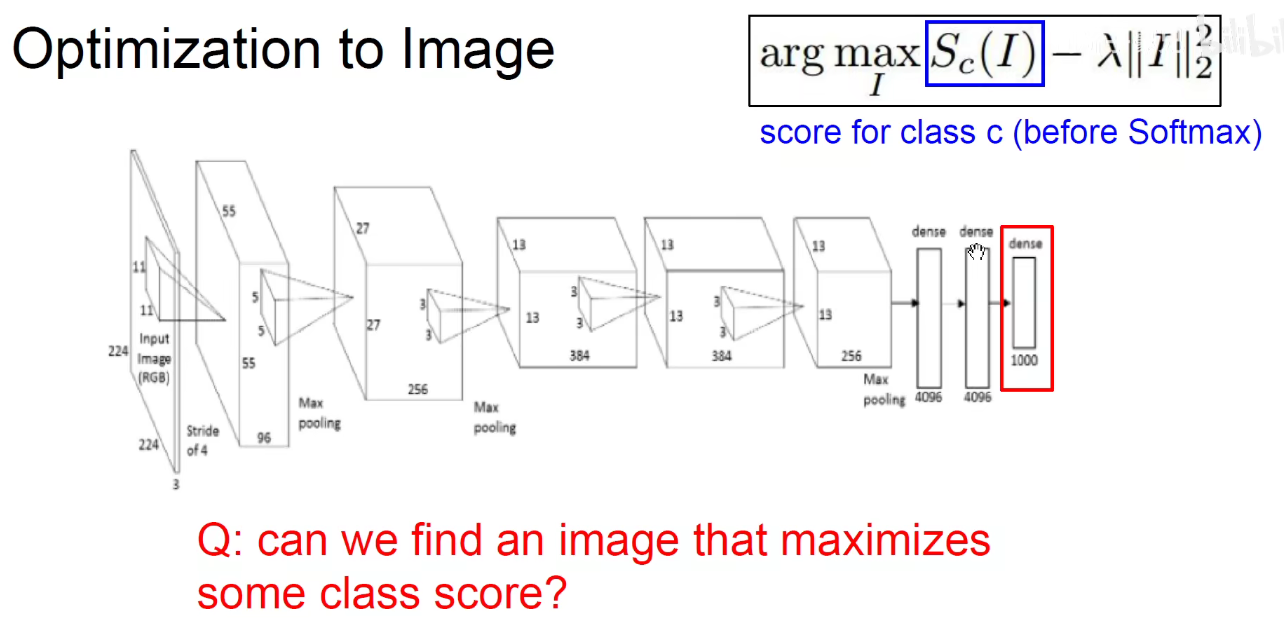
不仅要使得这个类别激活值最大,而且要考虑到我们生成的图像尽可能接近于自然图像,不能让他充满太多高频的噪音,所以给他加一个正则化项。既要让某一个类别的输出比较大,同时图像本身不能太多分,它要平滑模糊接近于自然图像。
1 | arg 是变元(即自变量argument)的英文缩写。 |
怎么做呢?
如下图,让某一个类别的梯度为1,其他的为0,用同样的方法进行梯度的回传。
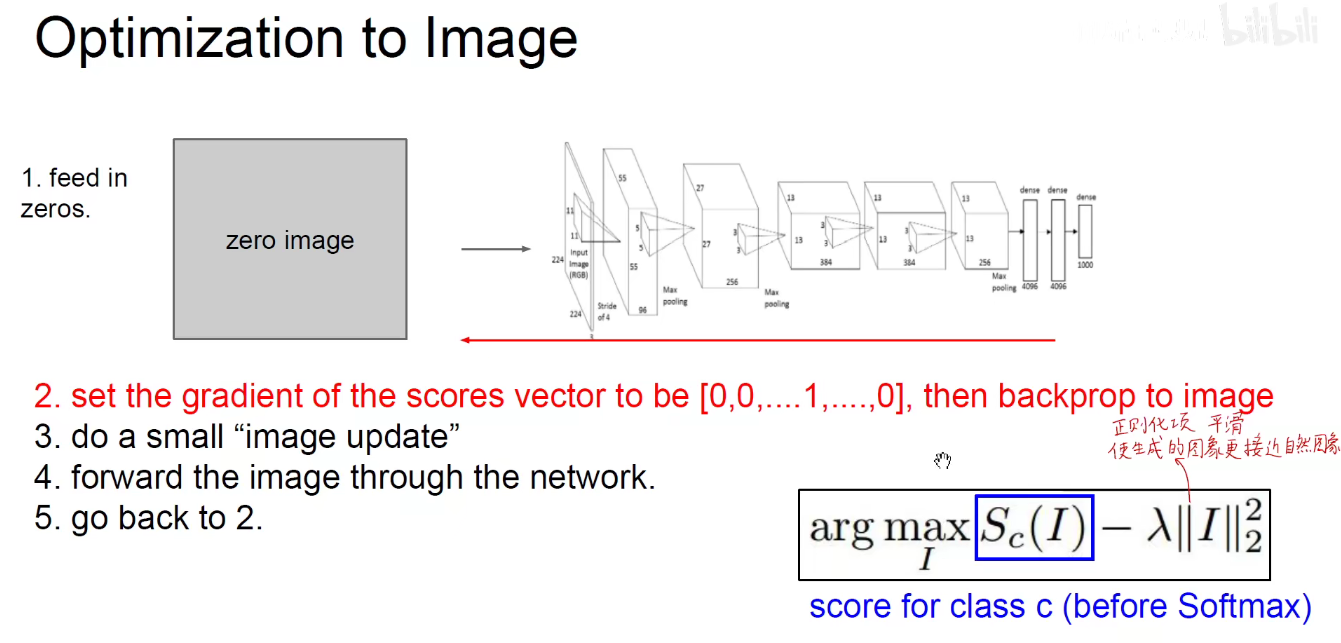
我们就能生成使得某一些类别分数比较大的图像。下图都是一些随机生成的,并不是真实存在的图像。


上面的方法是我们完全生成了一张图片,但如果我们给定一张图片,求得狗这个类别对于输入这张图片的每一个像素的梯度呢?即求得图片上每一个像素的梯度。他如果变化一点点,对狗这个类别的影响。我们把每一个像素的梯度求出来,就生成了第二行的黑灰色图。


其实我们就能把狗这个区域确定出来,虽然在训练这个网络时,没有用到定位和目标检测的技术。我们只用到了分类的标签。但我们却可以用分类标签训练出来的分类模型,对它每一个类别求原图上的导数得到原图哪一个区域是狗。相当于是使用图像分类解决目标检测甚至是语义分割这样的问题,也叫做半监督学习。
但是CS231N的主讲人说他试了这个模型,效果并没有这么好,原作者可能是将效果比较好的图贴到论文中。
沙地这个区域不管怎么更新和变动像素,对狗这个类别是毫无影响关系的。但是对狗身上的像素稍微动一动,就会对狗这个类别产生较大的影响。它是基于这样的思路来进行定位和分割的。grabcut.

Yosinski论文其他结果:
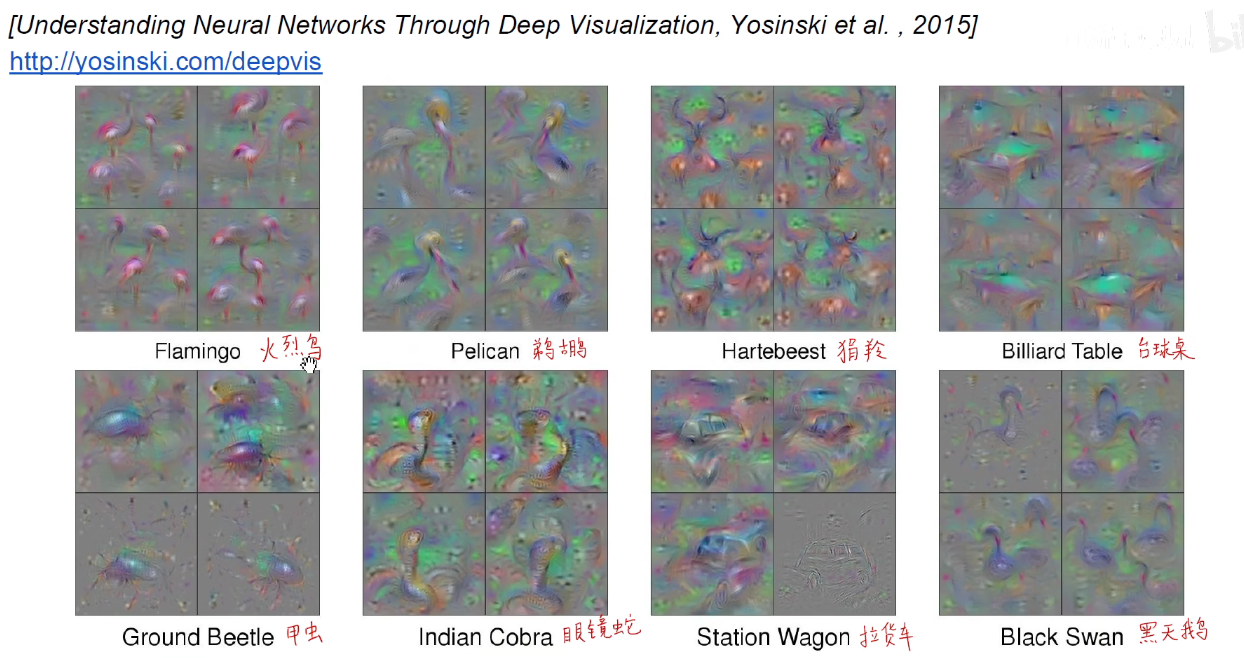


3.6 将编码还原为输入图像
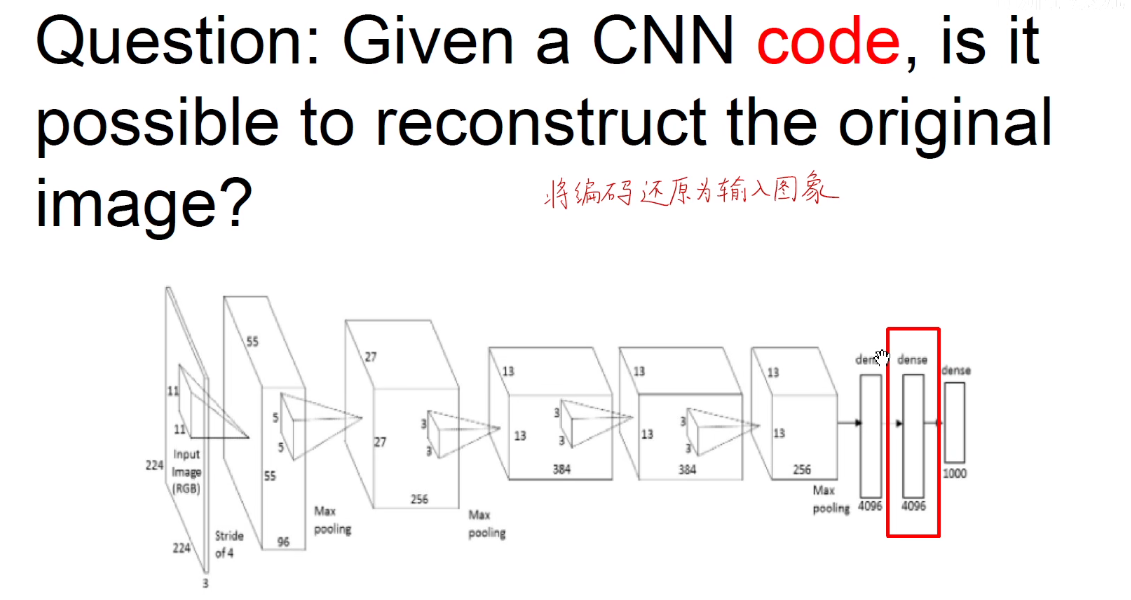
在全连接层中将图像压缩成一个4096维向量,那么能不能由这个向量还原为原始的图像呢?

此时我们就要构造一个新的监督学习问题了,找到一个图,这个新图编码和原图编码作差再平方,加上一个损失函数,我们希望这个损失函数最小。优化这个损失函数,就得到了模型。如下图:

对于原始输入图像,我们从输出分类层取编码再重构回图像。除了第一个之外的其他图,不同的图像是不同初始化的结果。可以看他,它能够大概告诉我们图像中是有什么的。

从全连接层的上一个池化层取编码重构图像,效果很好,因为我们知道FC层对池化层做了拉平操作,丢失了一部分空间信息。

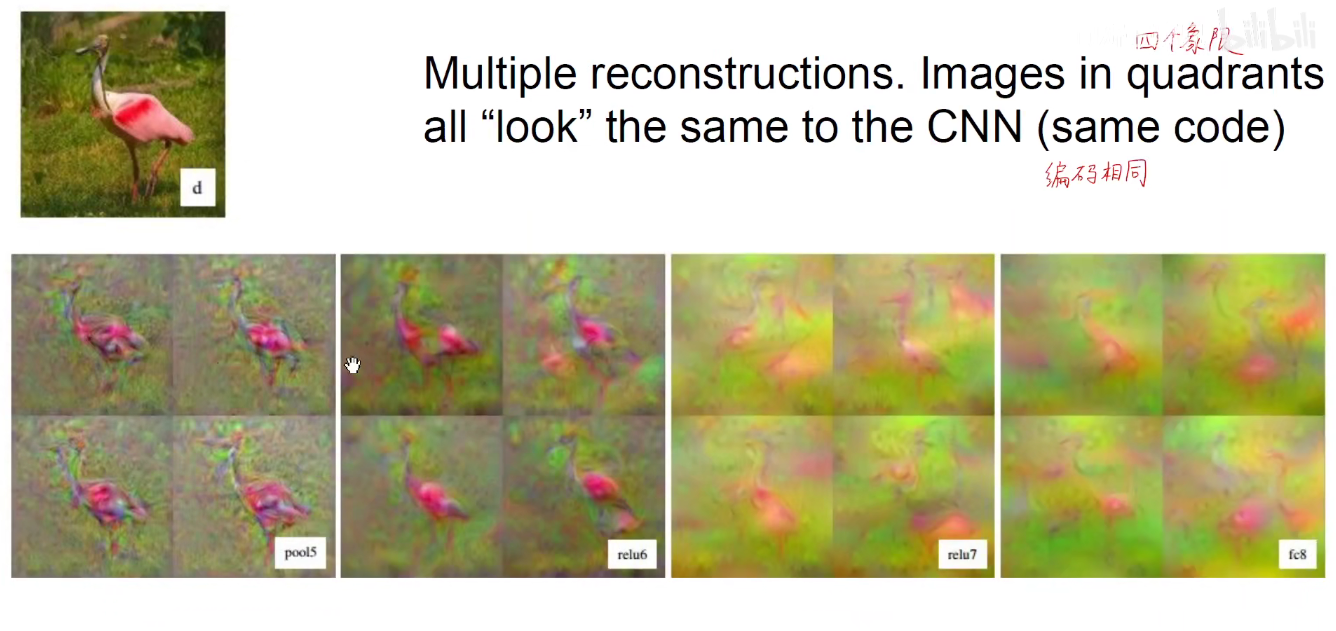
以上是2016版本
以下是2019版本,复习一下
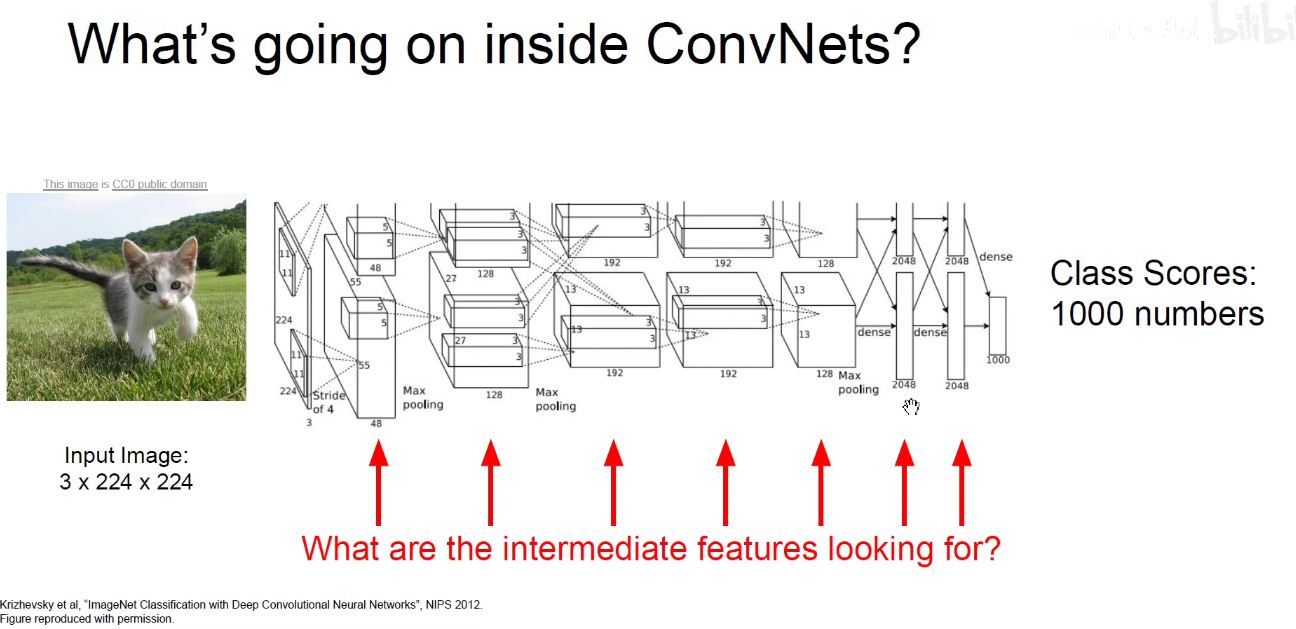














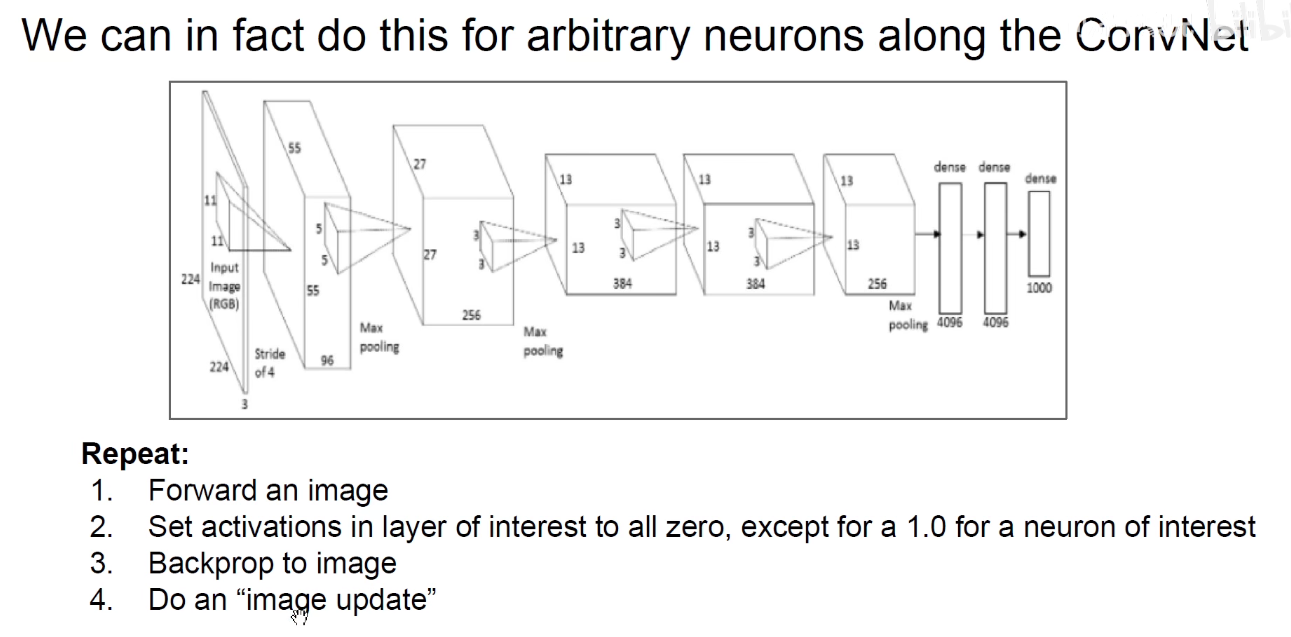
求一个能够使得某一个神经元激活最大的图像的方法称为 梯度上升方法-Gradient Ascent.
之前是求使得损失函数最小化,称为梯度下降。

生成对抗网络
给大象添加一些考拉的噪声点,大象就会慢慢被模型识别成考拉。量变引起质变。

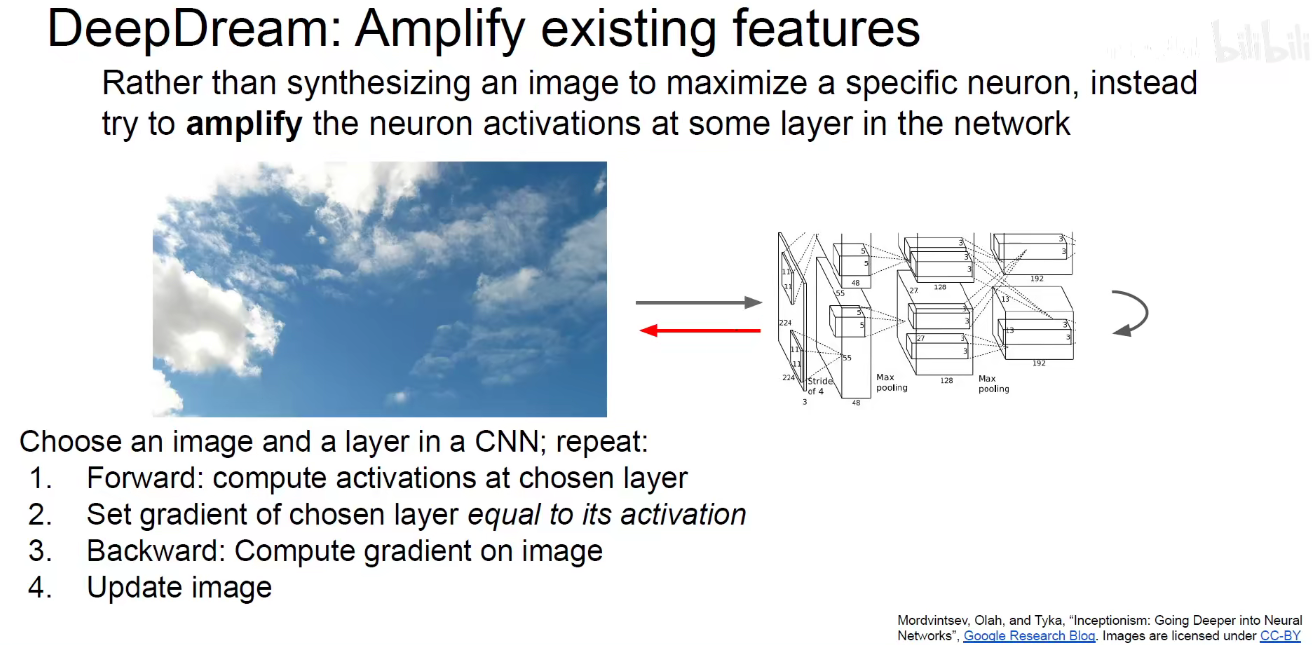
Deep Dream


神经风格迁移
