Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N
1 前言
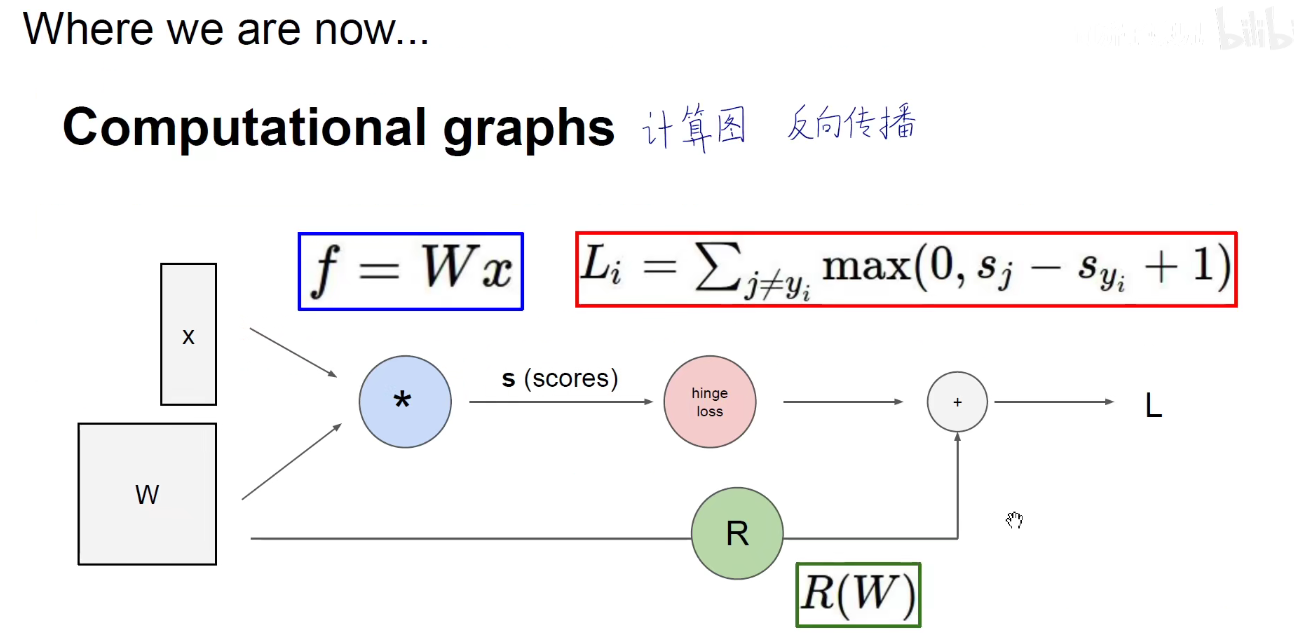
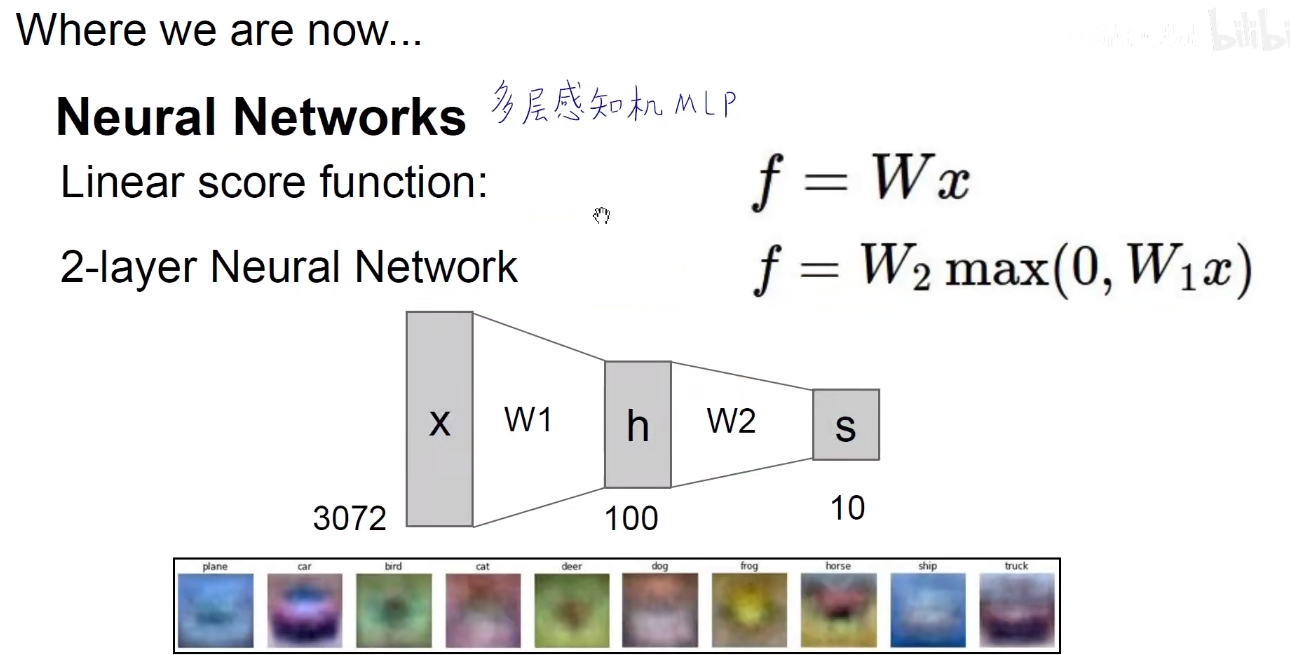
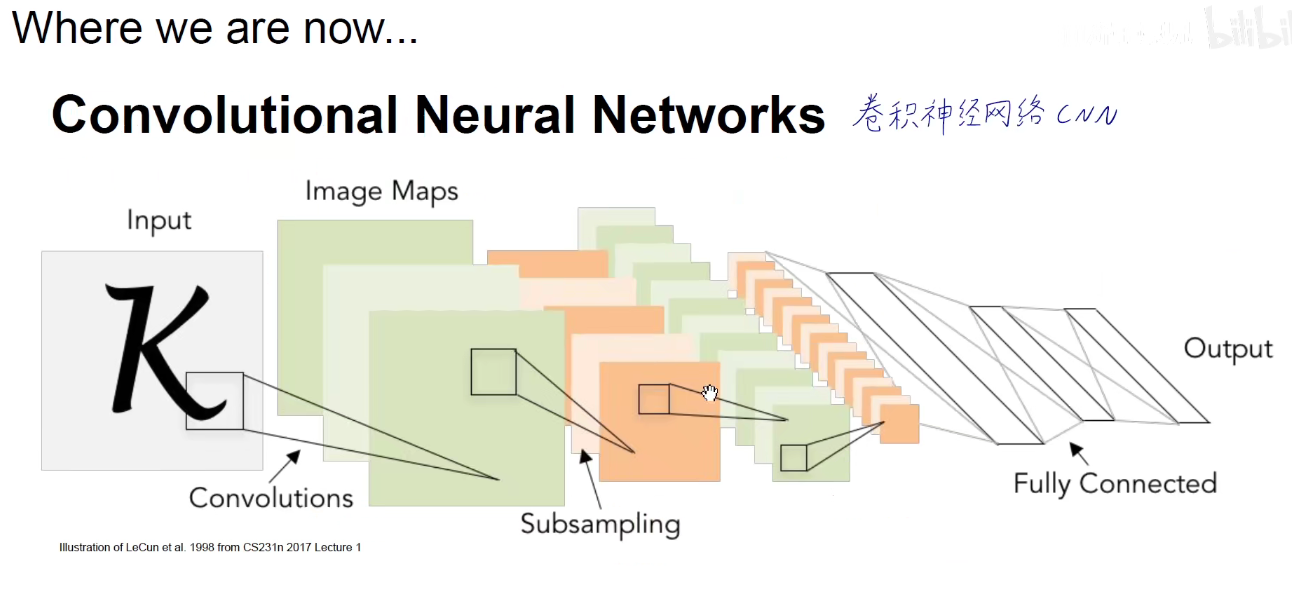
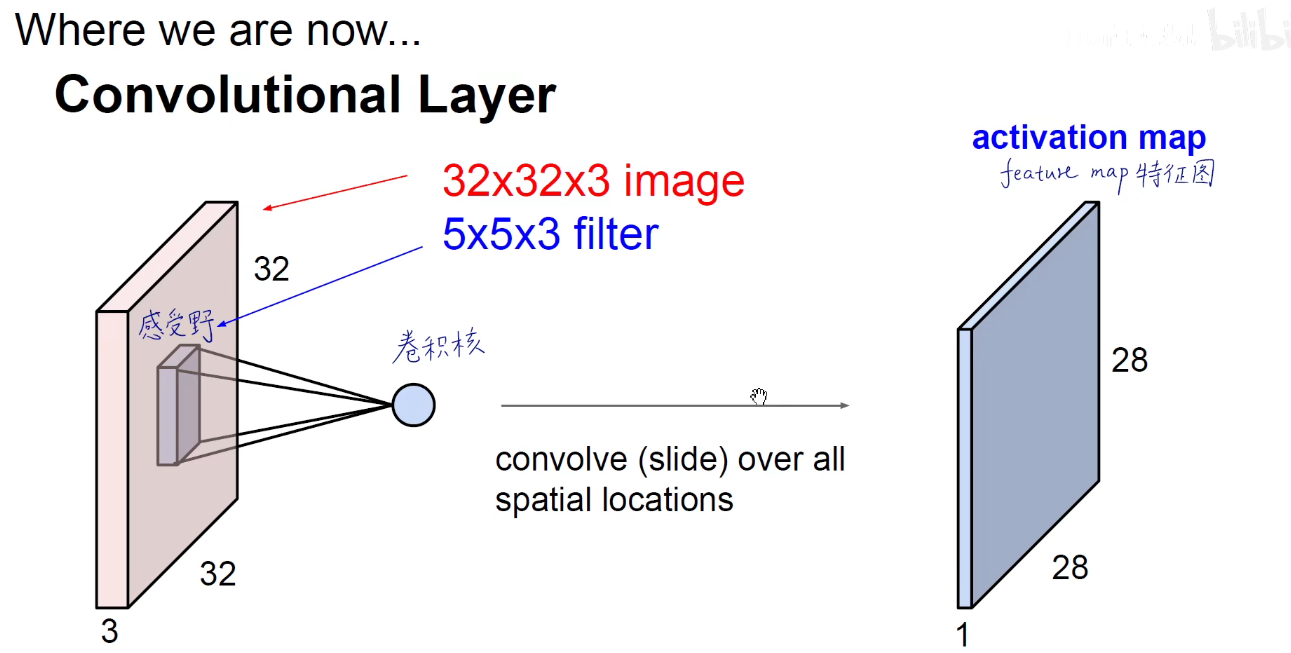
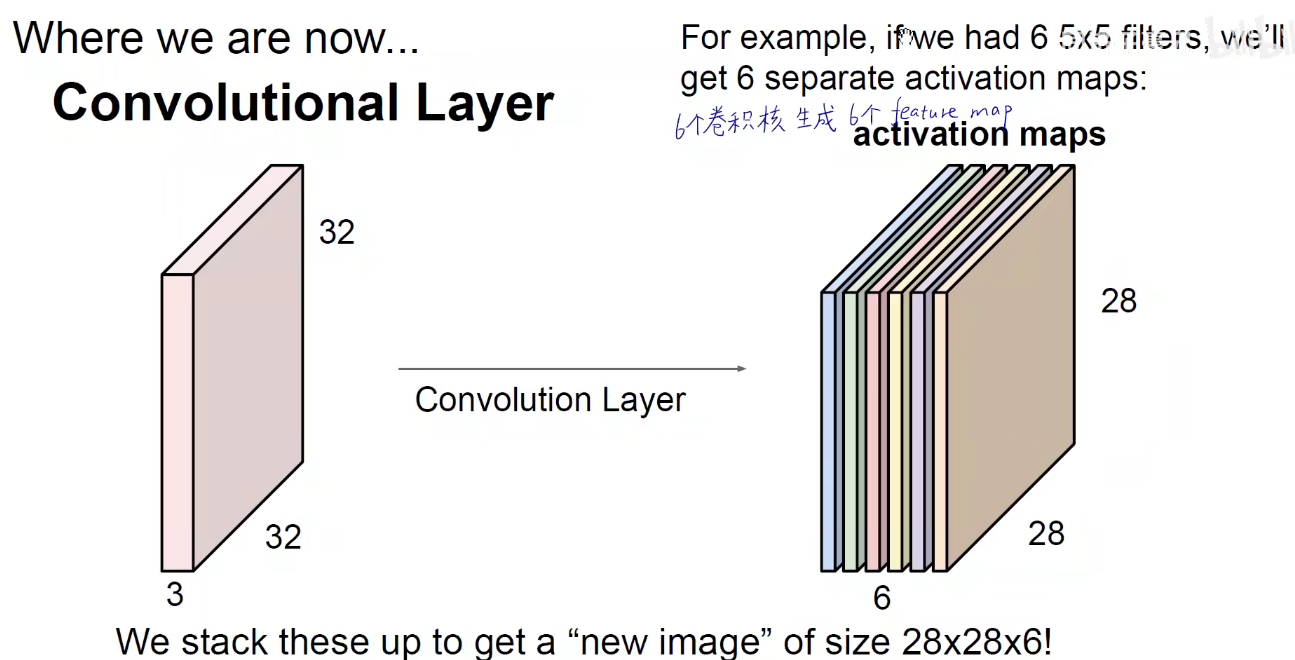


上图所示:原有策略是 SGD 和 Batch-SGD,即一次喂一个数据,由于单个数据噪音影响较大,很容易形成南辕北辙,振荡激烈,而每次喂入全部的数据,内存和算力的性能又不能满足,或者调优困难,因此取了折中的方法,Mini-Batch-Size,每次喂一小批数据给模型,当Batch为1或为全部时,退回到原有策略。

2 Training Neural Networks


2.1 Activation Functions
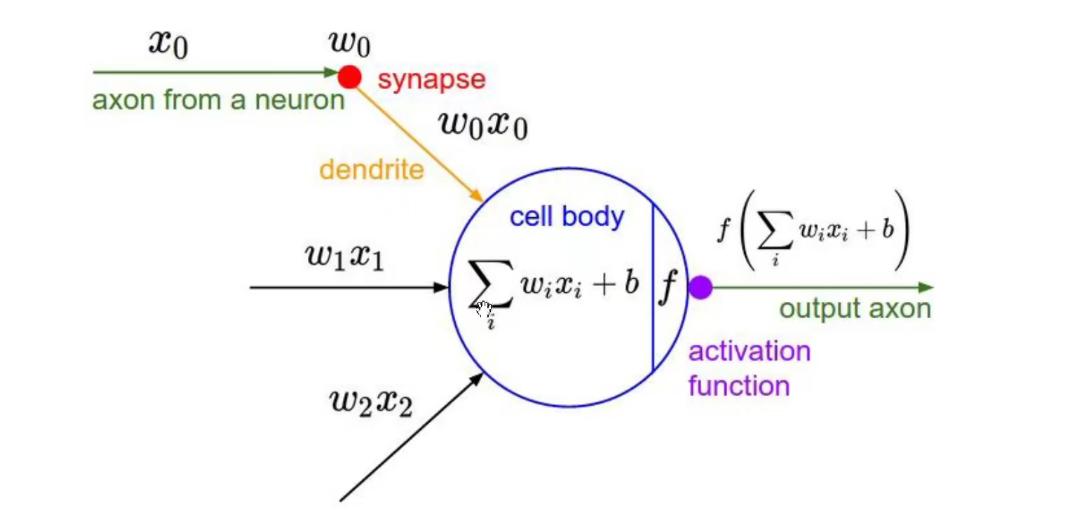
通过线性求和之后,使用一个非线性的激活函数进行激活,正是因为有了非线性的激活函数,才为神经网络模型带来了非线性的能力,他才可以拟合非线性的决策边界,才能解决非线性的分类和回归问题。
Sigmoid(x)


当x为+无穷时,无限接近与1,当x为-无穷时,无线接近与0,饱和性导致梯度消失。
当x为0时,函数值是0.5,
sigmoid的导数等于 ( 1-α(x) ) 乘以 α(x)
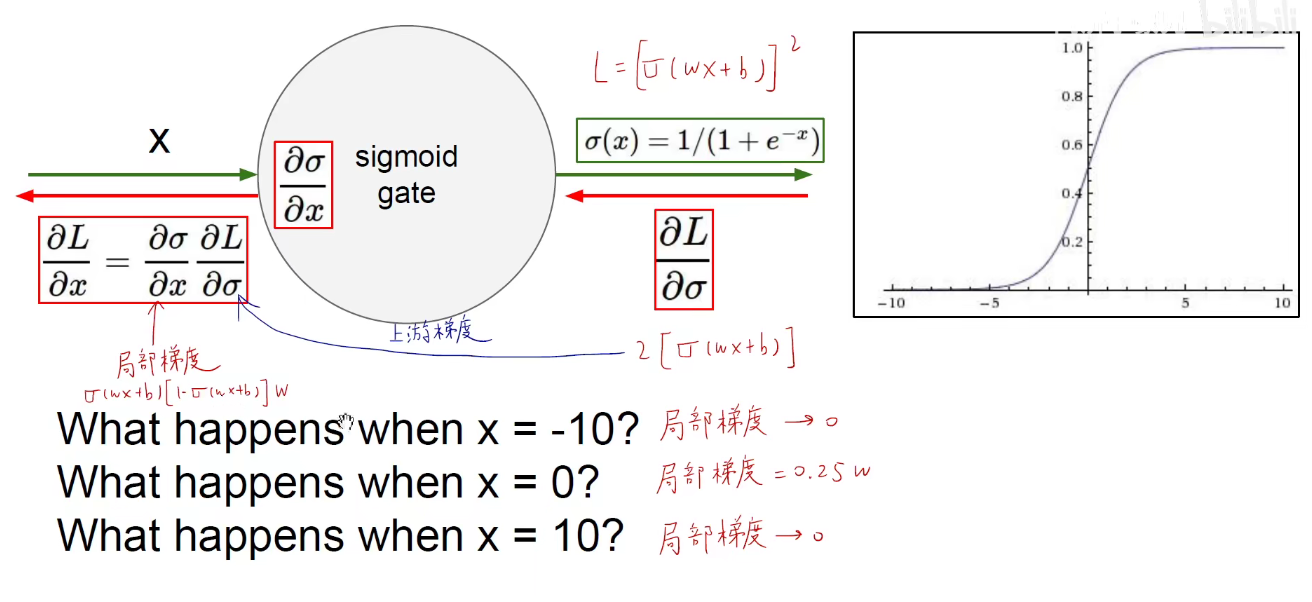
上面是第一个缺点,饱和导致梯度消失,
第二个缺点是,输出永远为正数,不是关于0对称的。每个神经元中所有的导数都是同号。

如下图,假设w1是横轴,w2是纵轴,他们的更新方向要么是在第一象限,要么是在第三象限,始终是同正同负。


tanh(x)

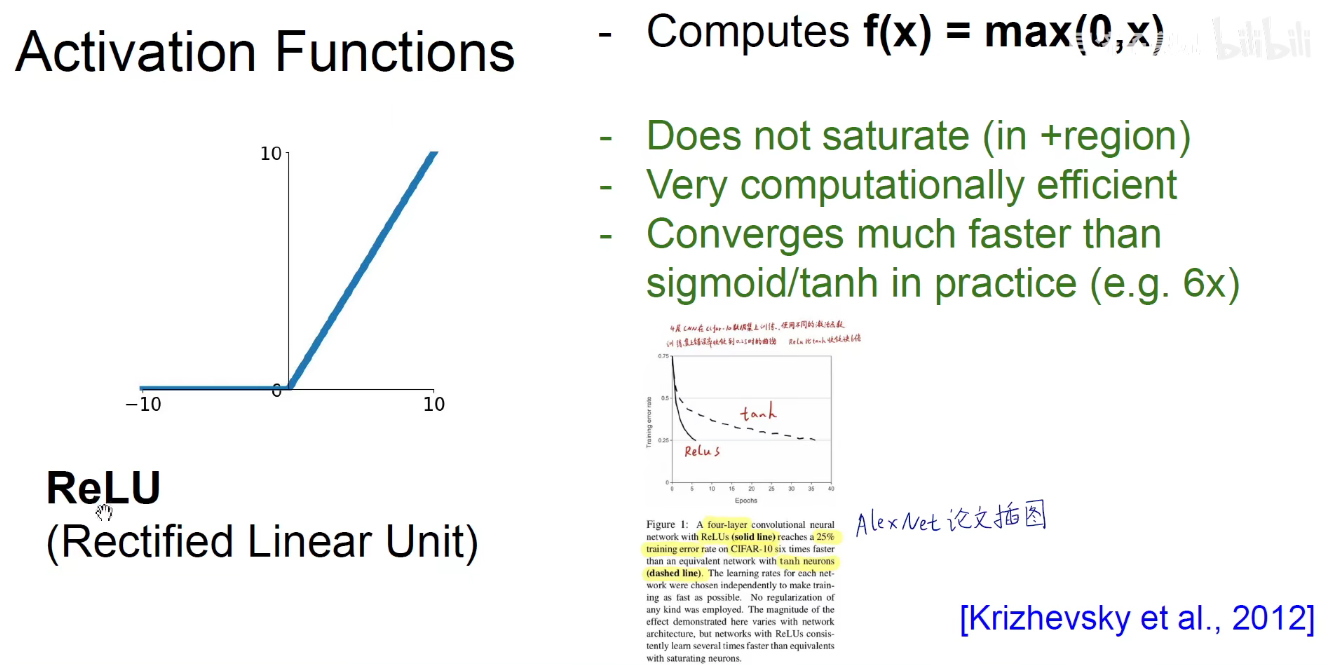
ReLU

Leaky-ReLU

ELU

MaxOut

一言以蔽之:

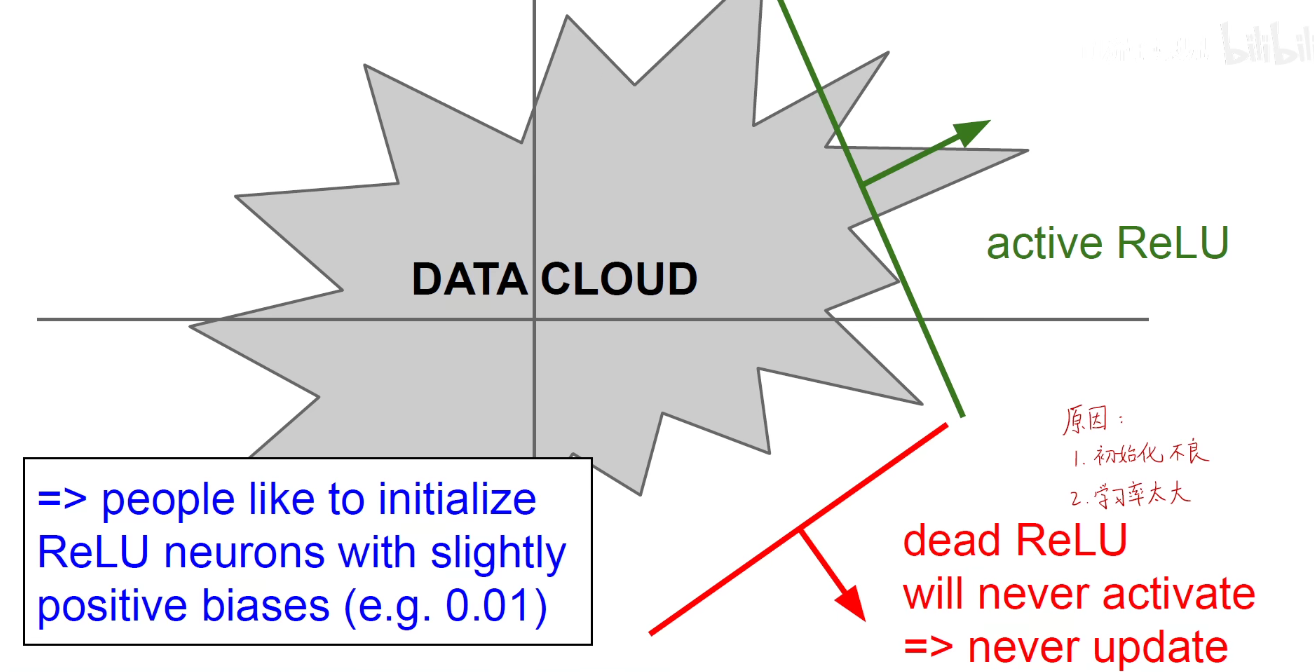
使用ReLU,学习率不能太大,否则他会跳到黑洞中,永远出不来。
2.2 Data Preprocessing-特征工程
数据预处理-特征工程需要因地制宜,特殊问题特殊处理,不能一概而论。
Z-Score方法
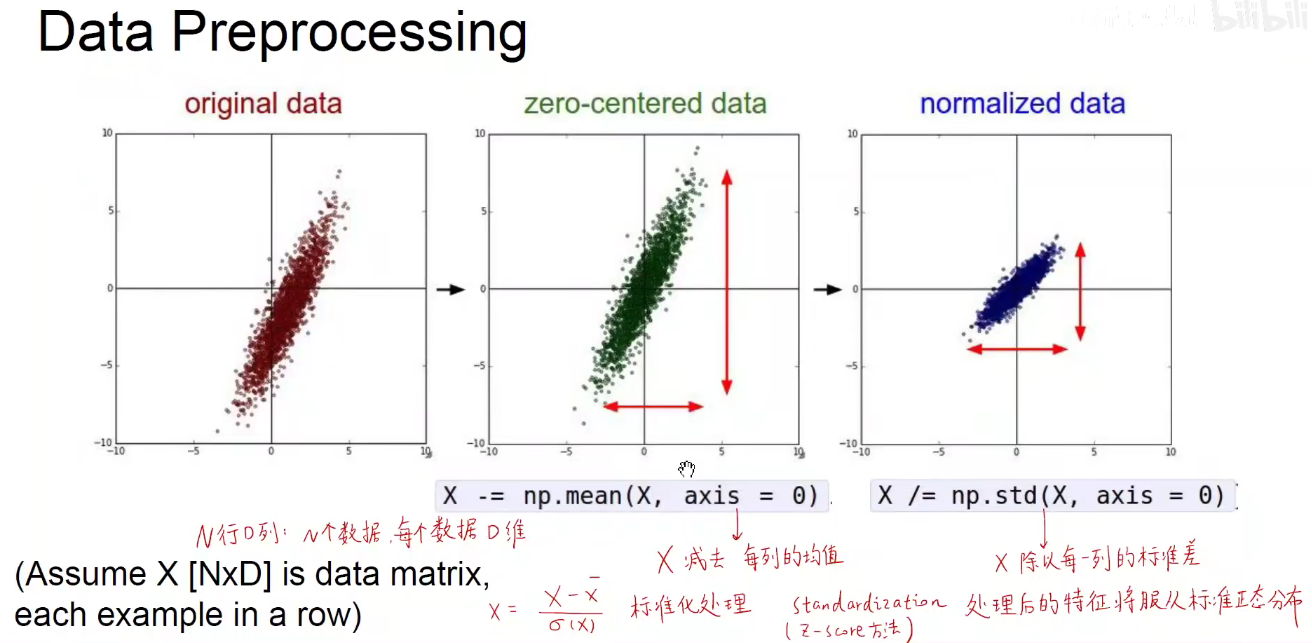
上图中公式:x-x拔 表示 每一个数据减去均值,差值再除以标准差会对数据做标准化操作。
标准正态分布:均值为0,标准差为1的正态分布/高斯分布。

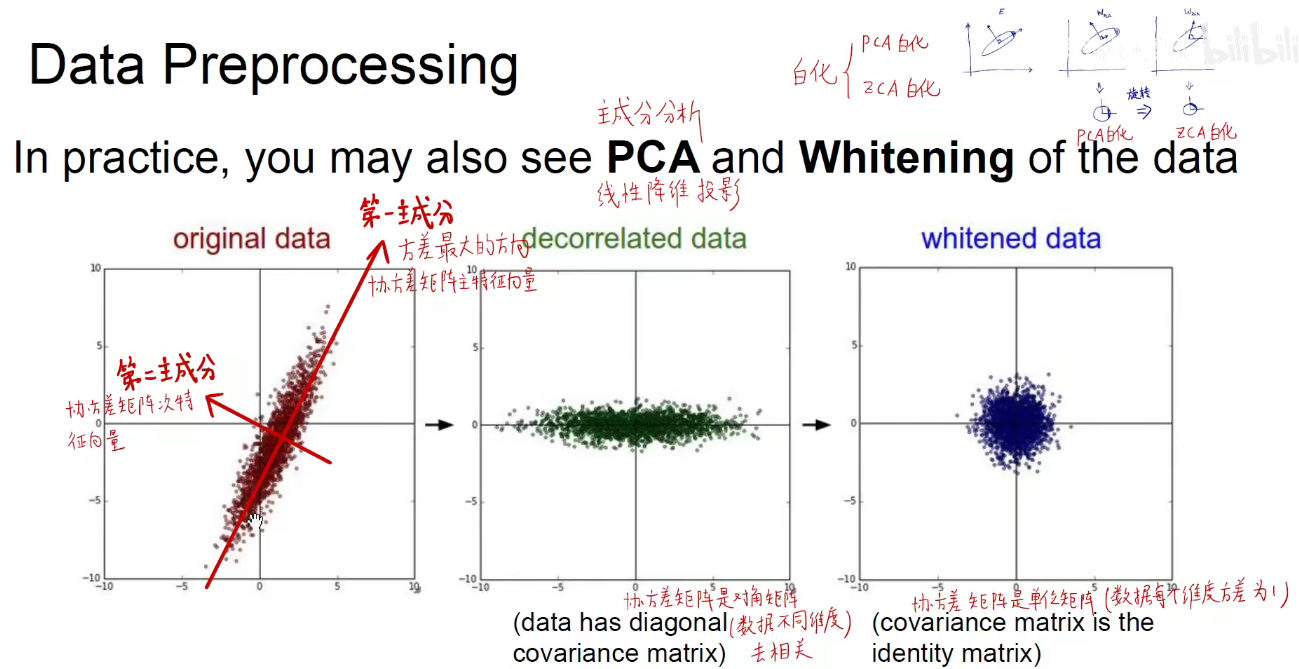
PCA方法:主成分分析
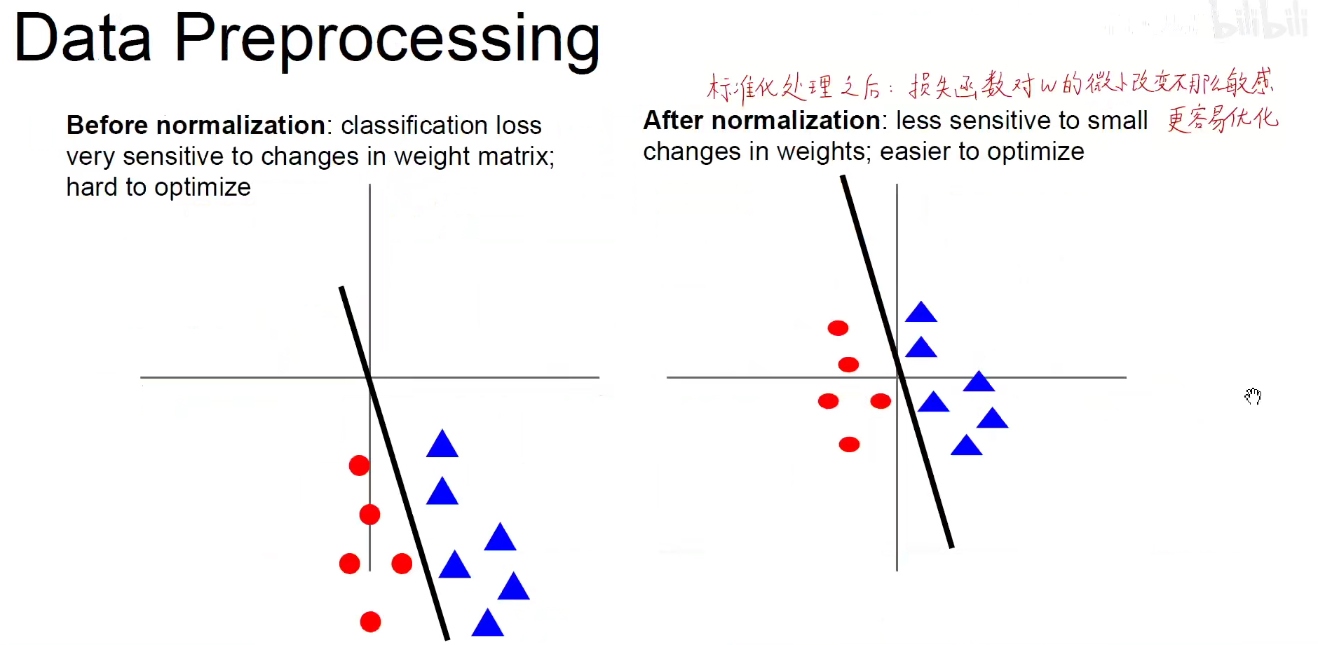
标准化
计算机视觉中经常用到的预处理技巧: PCA和白化反而不经常用到。

2.2 Weight Initialization
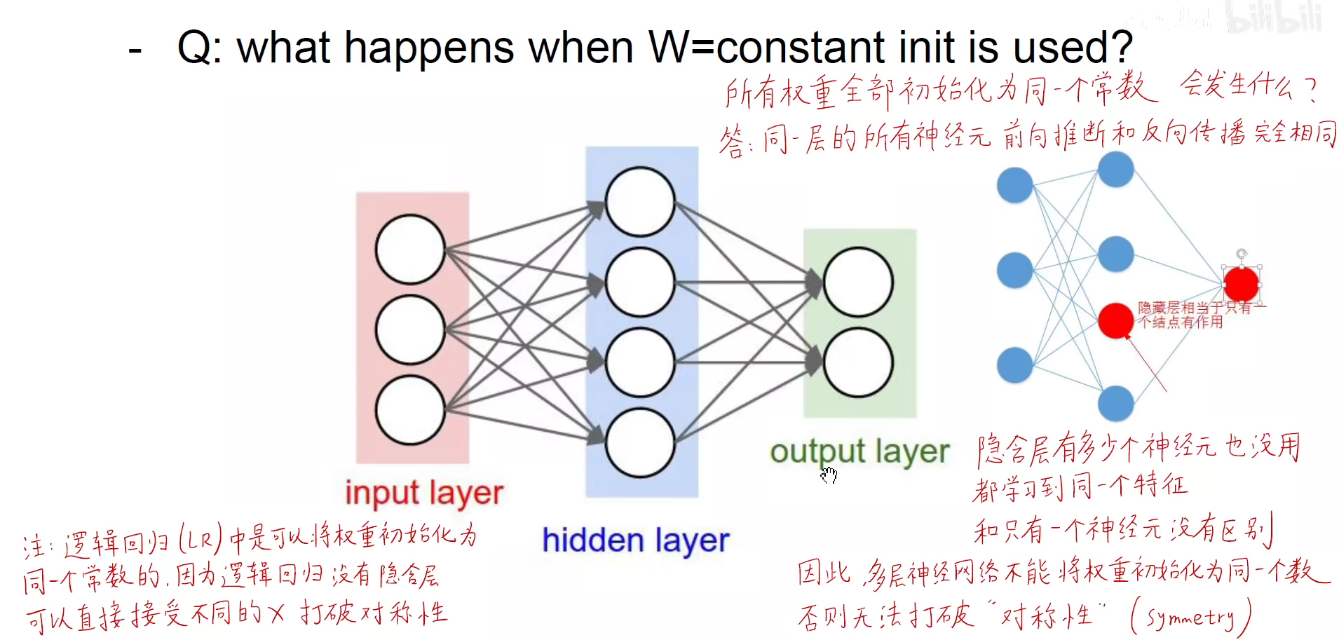
如上图:对于同一个隐含层,神经网路的权重不能初始化为同一个常数。否则就形成了“千人一面”。
而对于逻辑回归而言是可以的,因为它没有隐藏层。

上述式子生成一个标准正态分布的随机矩阵,均值为0,标准差为1.
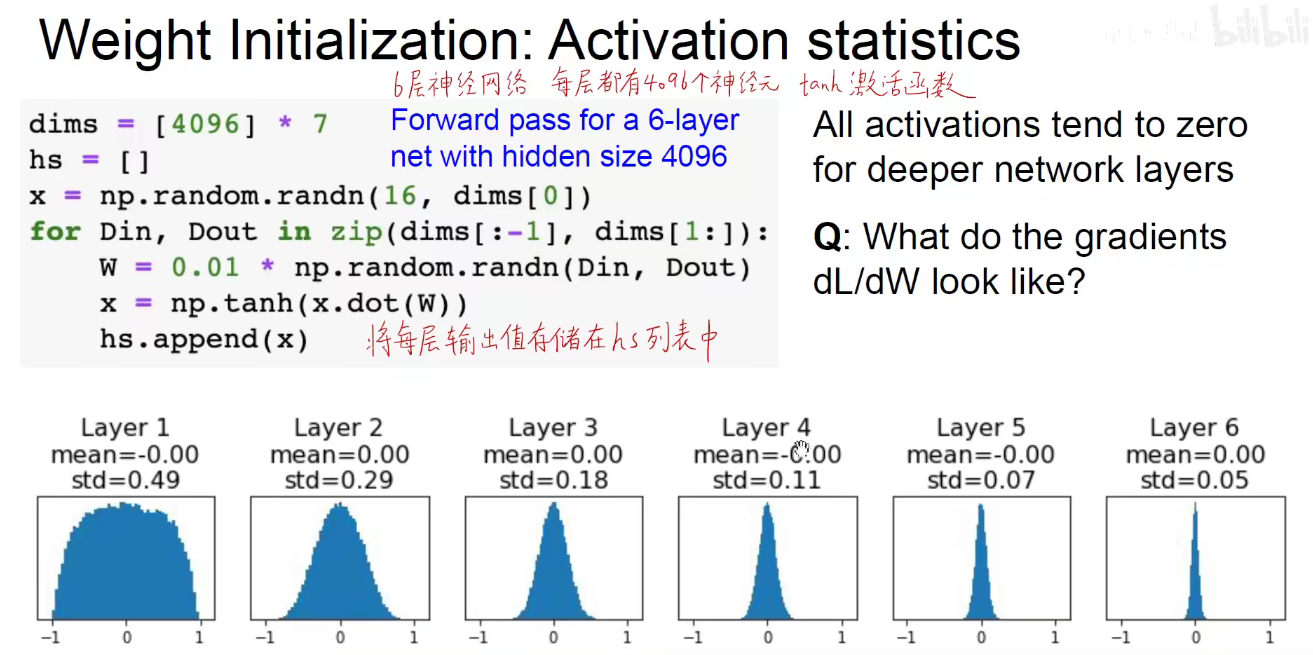
假设损失函数如下图所示,对wi求偏导,即求对权重的偏导,即为 f‘x 乘以 xi,xi是上一层的双曲正切函数的激活值,如上图所示,表示xi很接近于0,对于偏导数也会接近于0,此时会出现梯度消失现象。
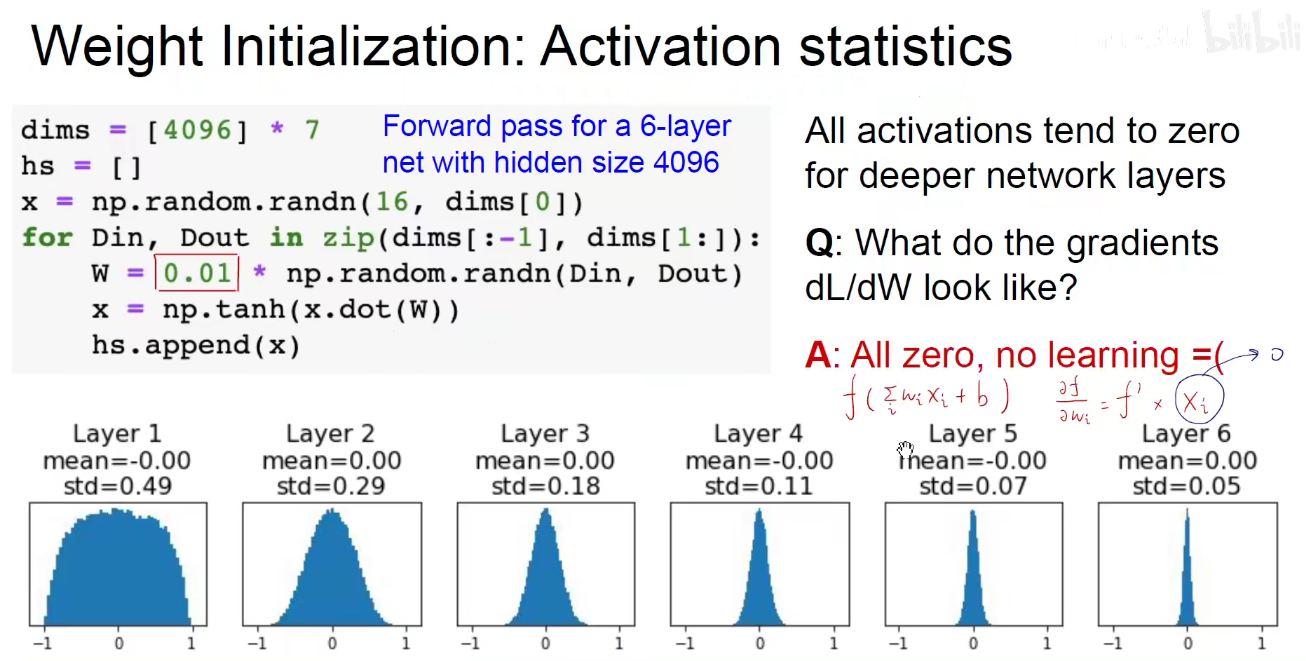
上述幅度使用0.01,如果我使用0.05呢?

此时 每一层的输出集中在了饱和区。 f‘x 就接近与0。所以偏导数整体接近于0.
如果权重的初始化幅度过小,xi就是0,如果权重的初始化幅度过大,f‘x就是0,他们都会导致偏导数整体为0,即梯度消失。走小碎步走1w年都走不到我们想让他去的地方,无疑是一场灾难。
Zavier初始化:根据输入维度进行初始化,给输入维度开一个平方根,放在分母上。作为一个惩罚,如果输入维度很大,分母就会很大,整体幅度就会小,反之亦然。自适应调整权重幅度。
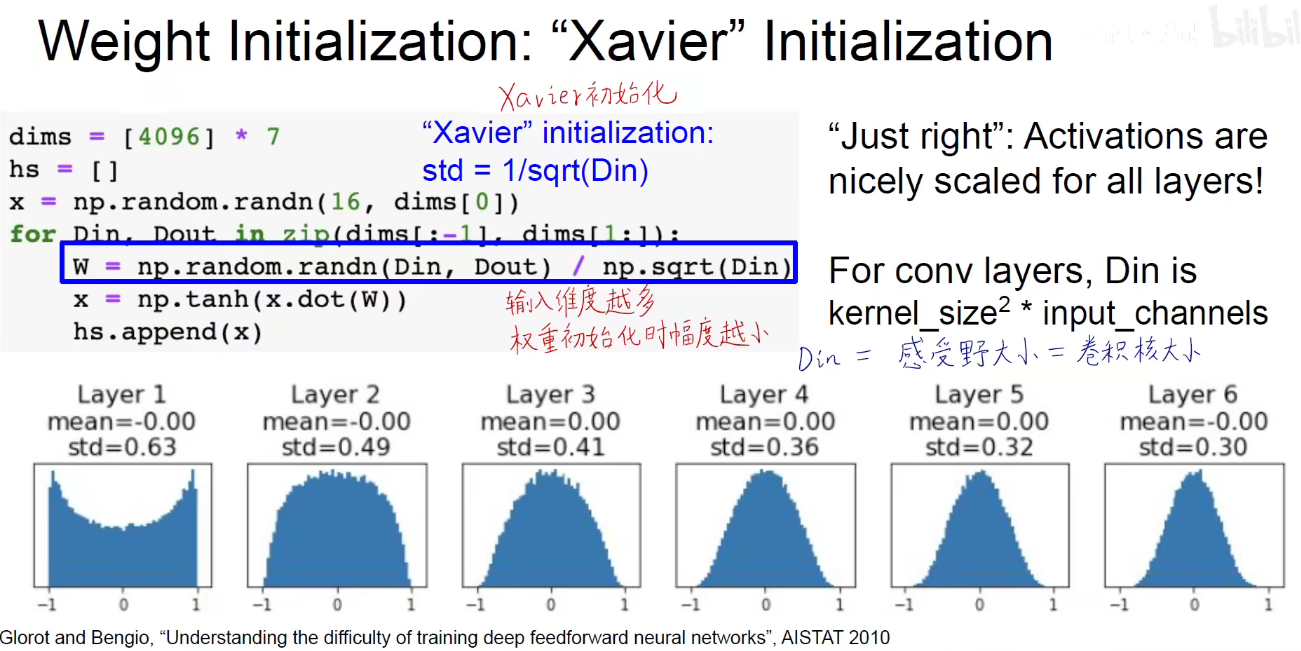
上图:既没有集中在饱和区,也没有集中在0附近。Din就是感受野大小,卷积核大小,其实就是卷积层中一个神经元输入的大小。 Din = Kernel_size2 x input_channels
Zavier数学证明:输入方差和输出的方差相差不大


使用RelU而不是tanh,发现集中在了0附近,掉到了黑洞里

为了解决上述问题,何凯明提出了-凯明初始化,MSRA即微软亚洲研究院。
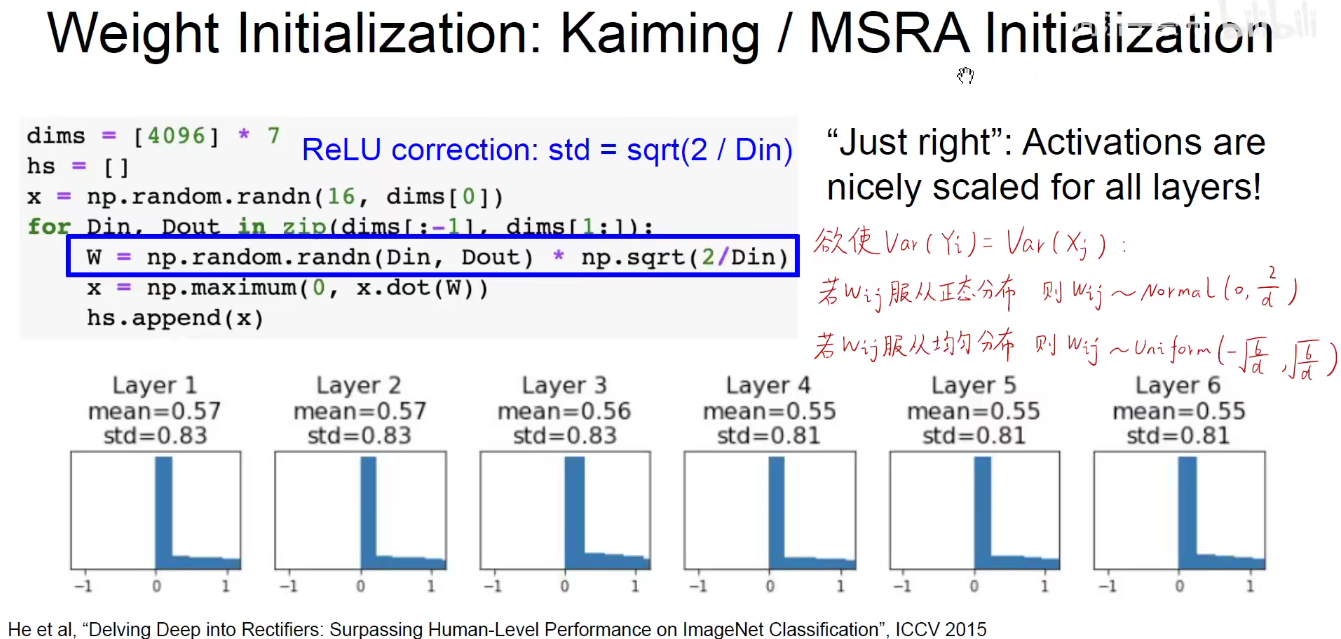
关于权重初始化是一个非常热门的领域,如下图,一直有新的初始化论文提出。。。

2.3 Batch Normalization

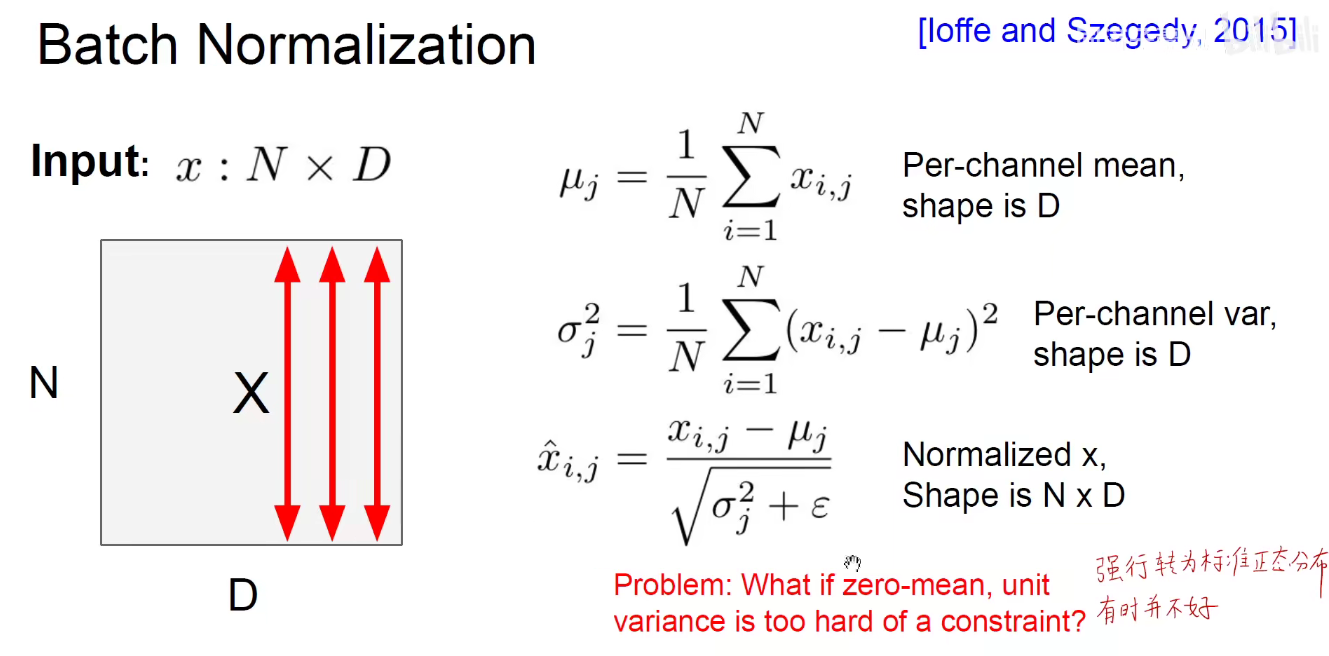
所以我们又引入两个参数,γ和β

上述就是在训练阶段的Batch-Normalization,作用就是尽可能将中间结果拉开,使得梯度尽可能的能够暴露出来。把一个长条形的数据变成一个圆鼓鼓的数据。
在测试阶段,如下图,因为是一个一个测试的,所以不再需要N,但需要把训练阶段的总均值/总方差记录下来。方便在测试时,用训练时的总均值代替mini-batch均值,训练时的总方差代替mini-batch的方差。右上角方差中 除以 m-1 是为了无偏差的估计,这点可以自行搜索有关博客。

如下图:γ和β是需要学习的,如果γ=标准差,β=均值,那么等同于没有进行batch-normalization。分母加特别小的数ξ 是为了防止分母为0.
Batch-Normalization for ConvNets
在FC中,每一个维度单独的进行γ和β的训练,即一共有D个γ和β.
在卷积层中,一批N个数据,有C个卷积核生成C个feature-map,每一个feature-map的高宽为H和W,每个feature-map计算整批均值。得到C个均值和标准差。 即有C个通道,对每个通道都求出整个Batch的均值和标准差,得到C个均值和标准差。每一个通道单独的训练处γ和β。

Batch-Normalization又称为BN层,通常放在非线性层之前。


训练时使用每一破的mean和var,测试时使用的是全局的mean和var。
其他经典的BN:


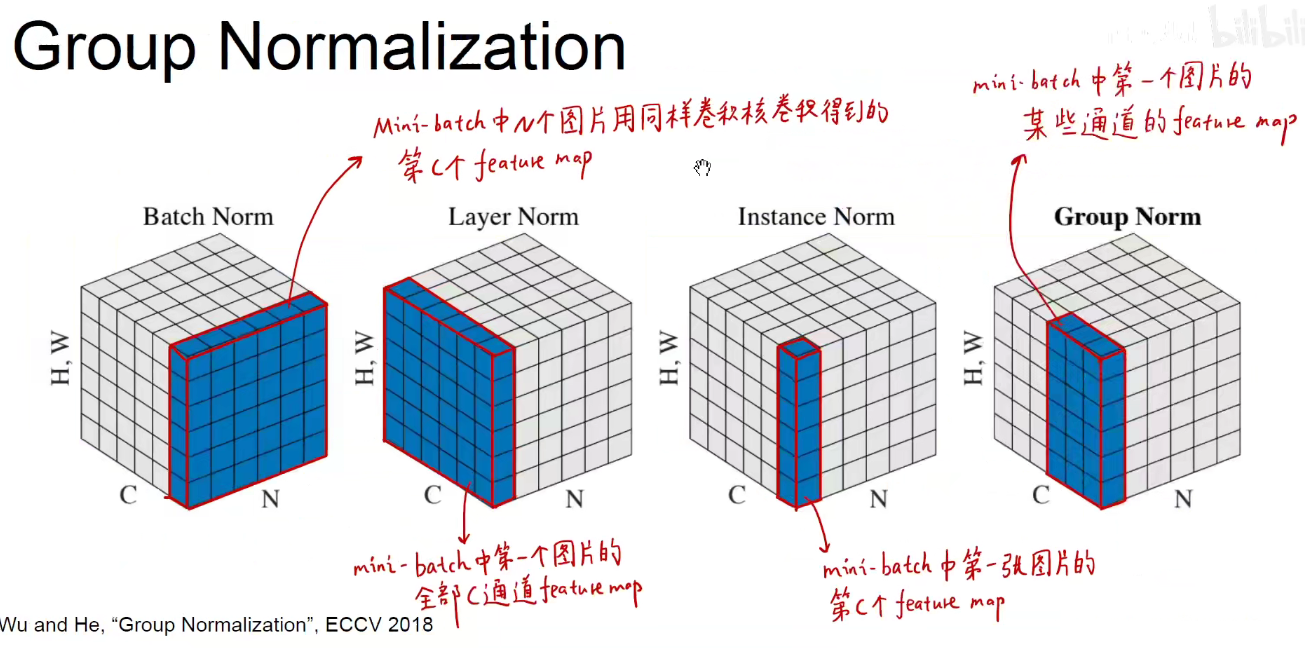
一个batch中的N个图片第C个feature-map求mean和var。
每一张图片的全部C个通道的feature-map求mean和var。
某一张图片的某一个feature-mao求mean和var。
某一个图片的某些通道的feature-map求mean和var。
3 总结

