Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N
1 前言
迁移学习可以让我们站在巨人的肩膀上编程,调用别人已经训练好的预训练模型。用来泛化到我们自己的数据集上解决问题的一种技巧。
了解了迁移学习,以后再学习一些经典案例时,一些预训练的模型,我们就可以充分的调用别人已有的最优秀的模型,来为我们所用。


2 迁移学习

别人已经训练好的模型,我们拿来白嫖,只要在它的基础上做一些自己的工作即可。
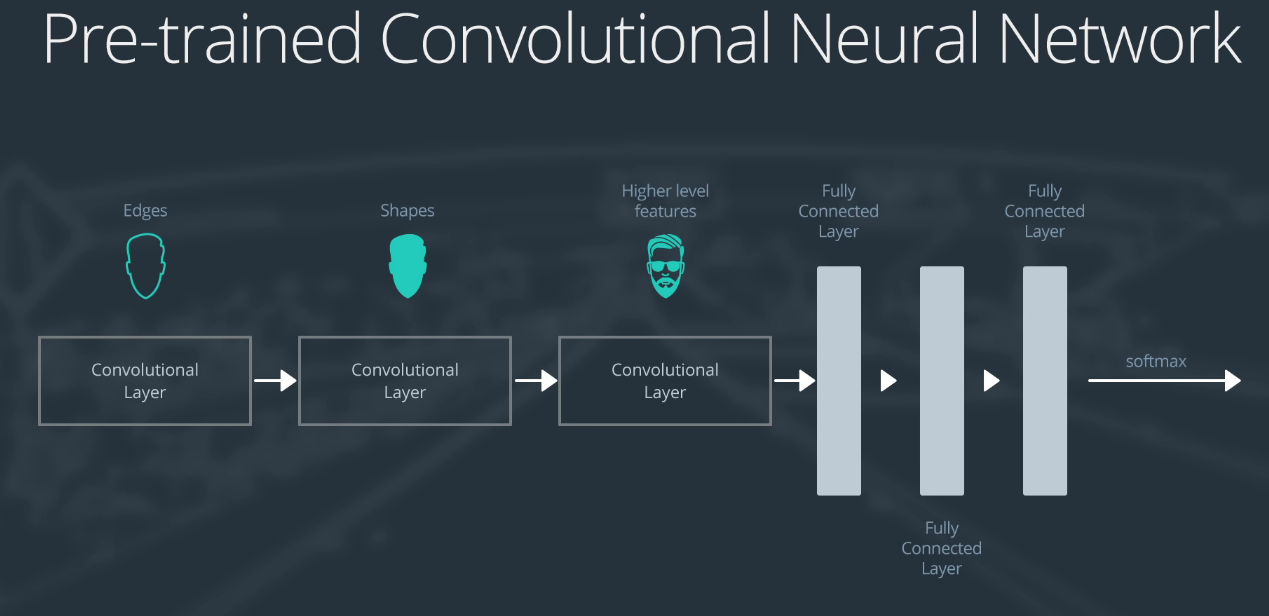
假设我们的需求是4分类问题,我们冻结原始模型的前N层,用冻结住的底层预训练模型进行模型的特征抽取,比如上图中,我们利用模型训练好的4096维向量,再用我们自己指定的训练好的层对4096维向量进行4分类。
即用预训练模型进行特征抽取,把一张图片压缩到4096维线性可分的空间中,我们自己的最后一层就是对着4096维向量进行4分类。
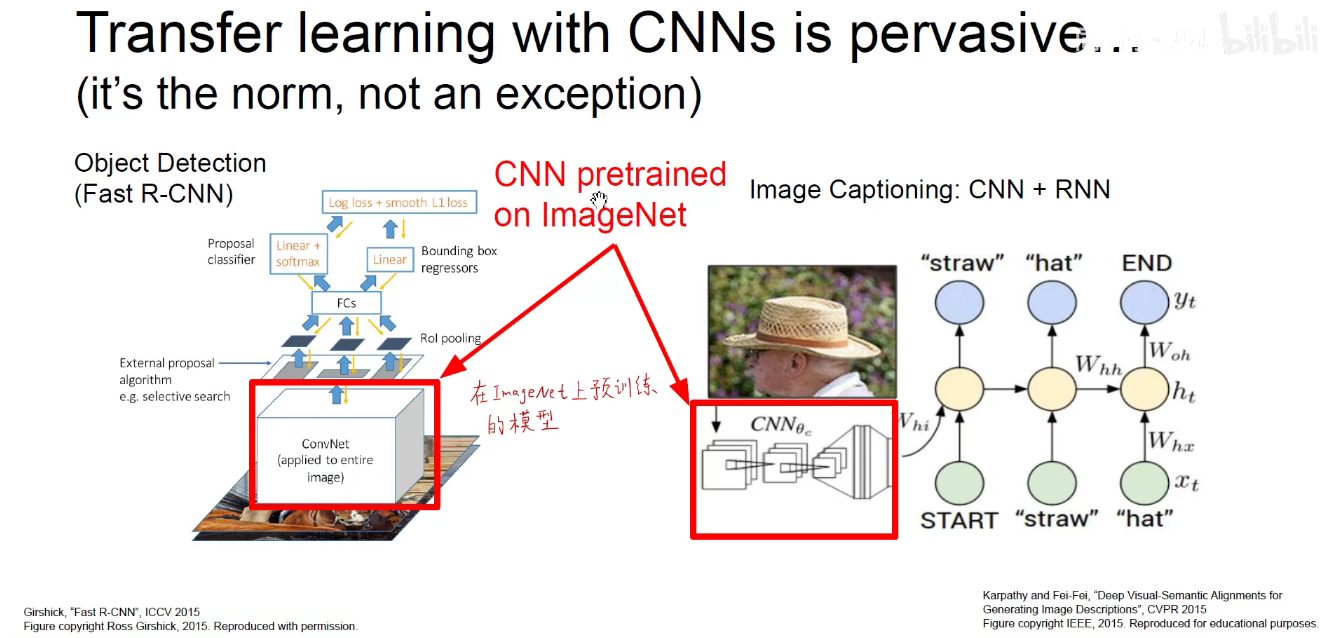
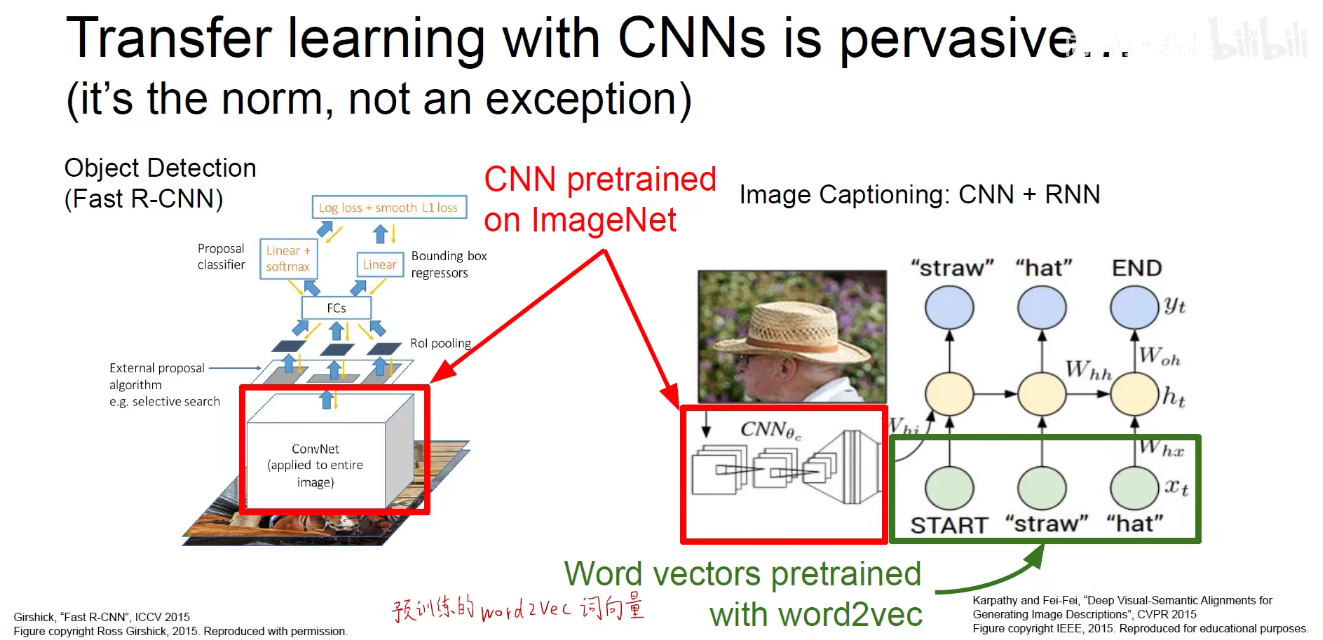
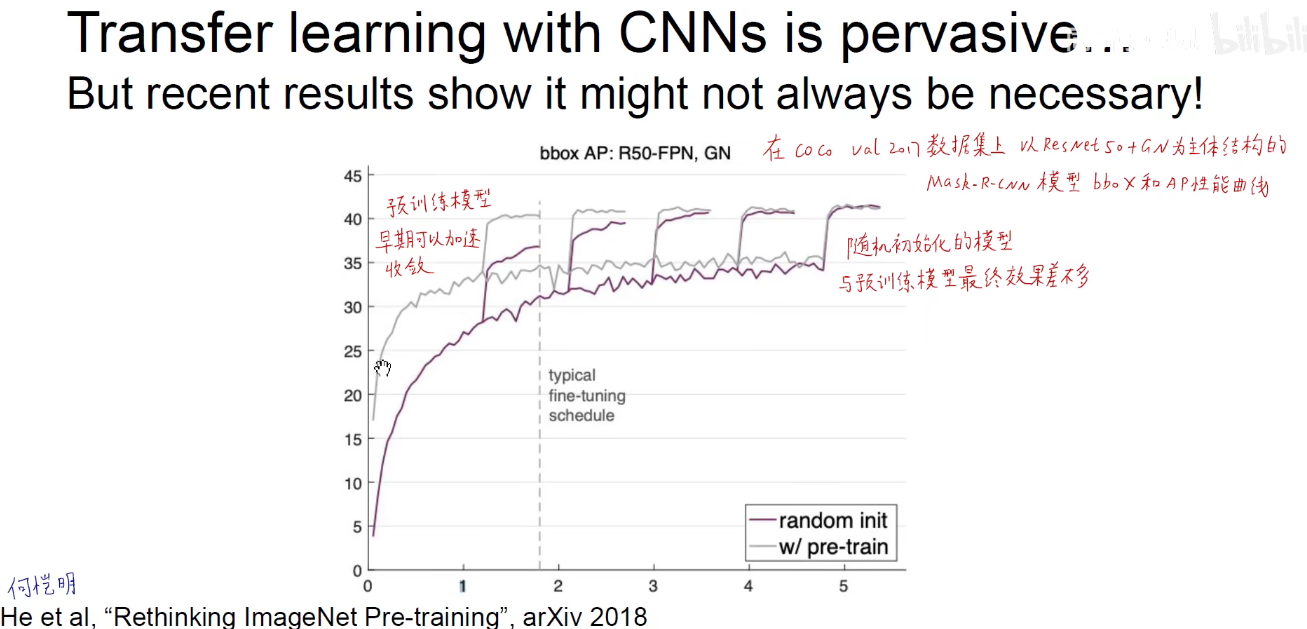
但是何凯明2018年发表的论文中阐述预训练模型并不是万能的,需要因地制宜,具体问题具体分析。
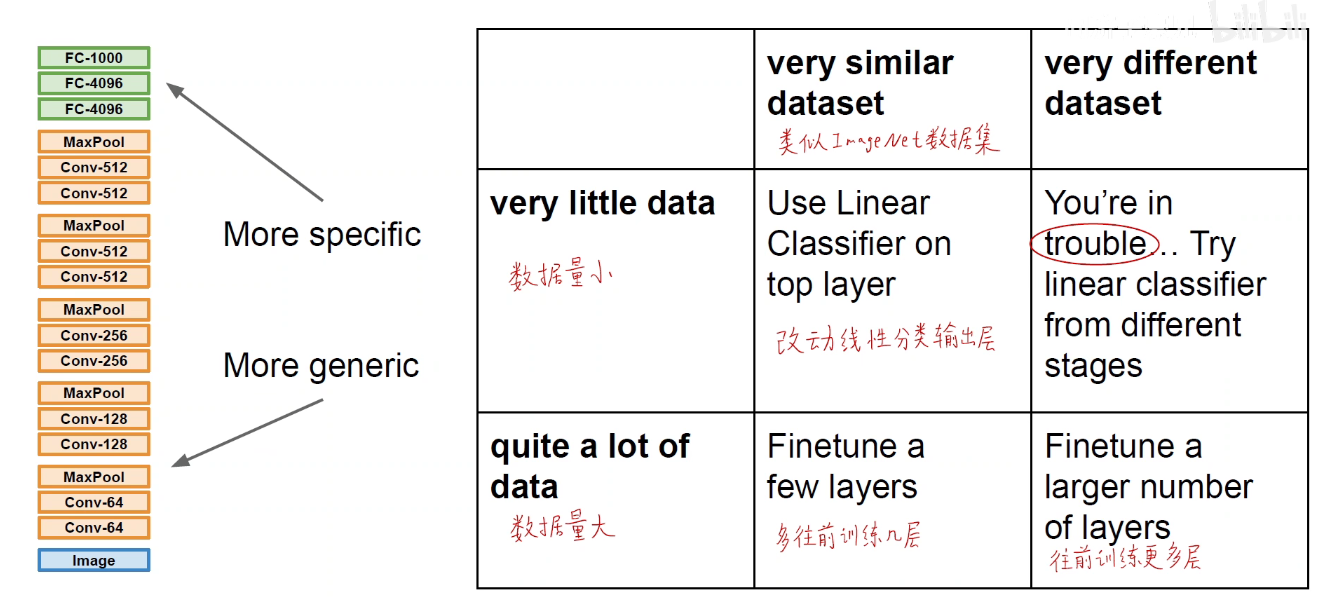
数据集太小怎么办?如下图给出了曲线救国的策略。



如上图:相当于将冻结层看成是一个特征提取器,因为在计算机看来,前N层的作用就是提取特征的。

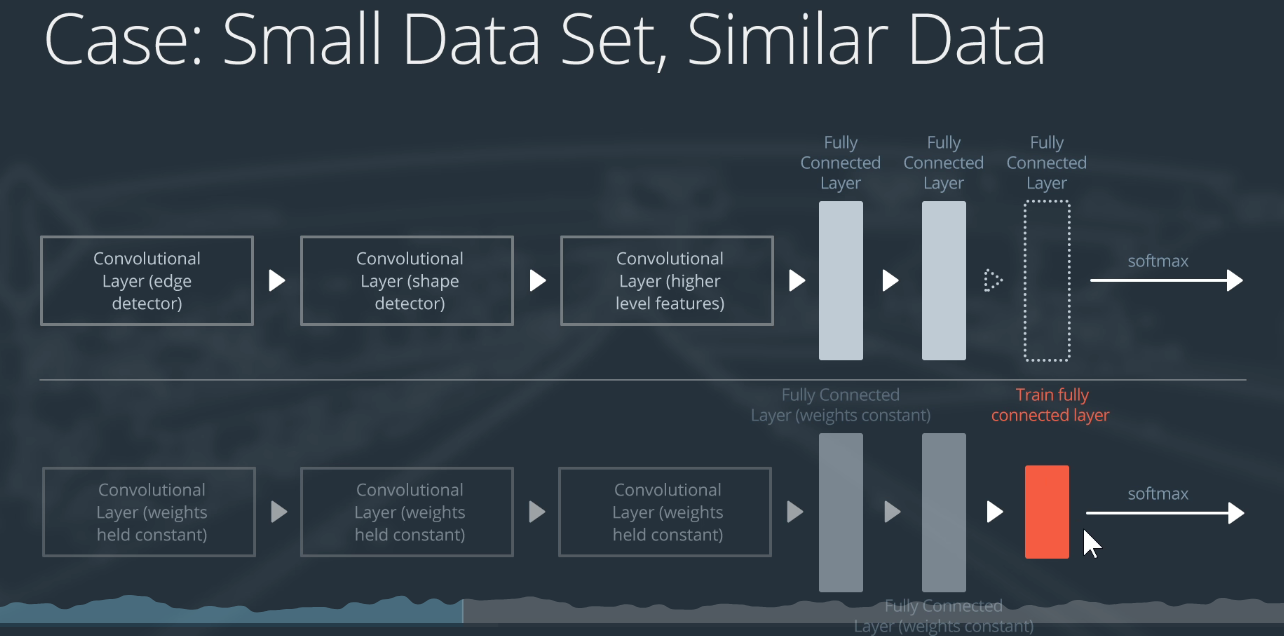
小数据集且与预训练模型所在的数据集大致相似。
相当于是我们认为这个预训练模型已经可以把我们自己的数据集映射到一个线性可分的空间中,我们只需要定义一个线性可分的分类器,对这个线性可分的高维空间进行线行分类即可。即把原来的1000分类改成我们自己的C分类即可。
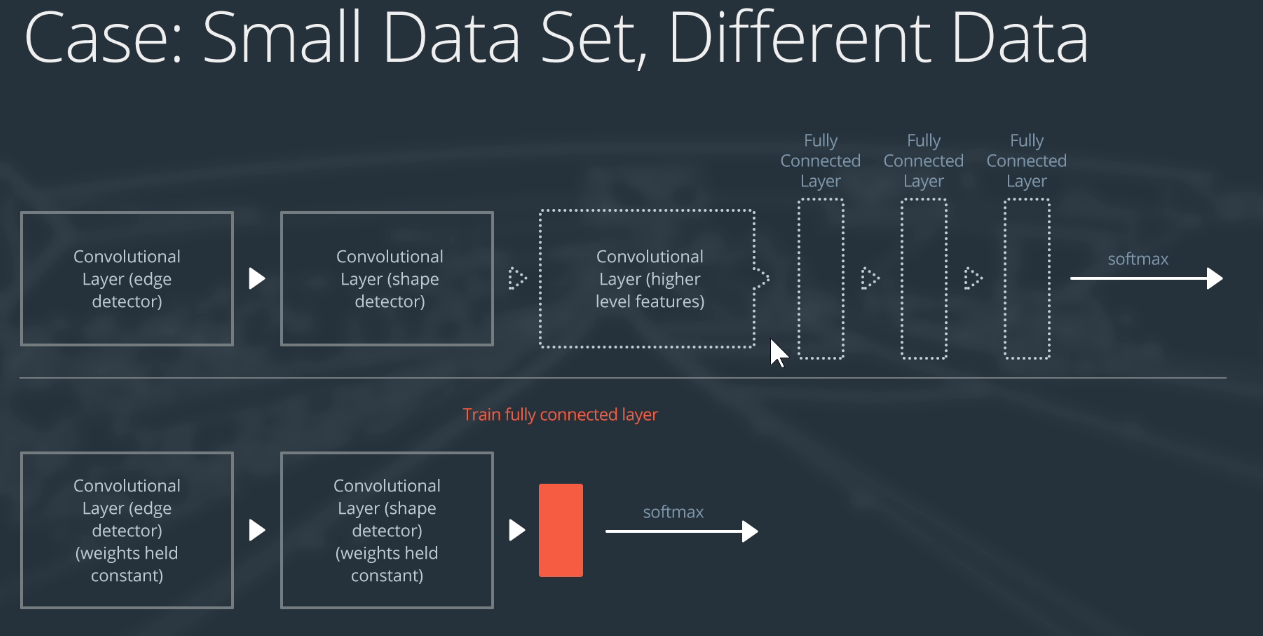
小数据集且与预训练模型所在数据集不相似。
我们可以舍弃后面的卷积层,因为后面的卷积层提取的是特化的高级特征,前面的卷积层可以提取到一些普适信息。
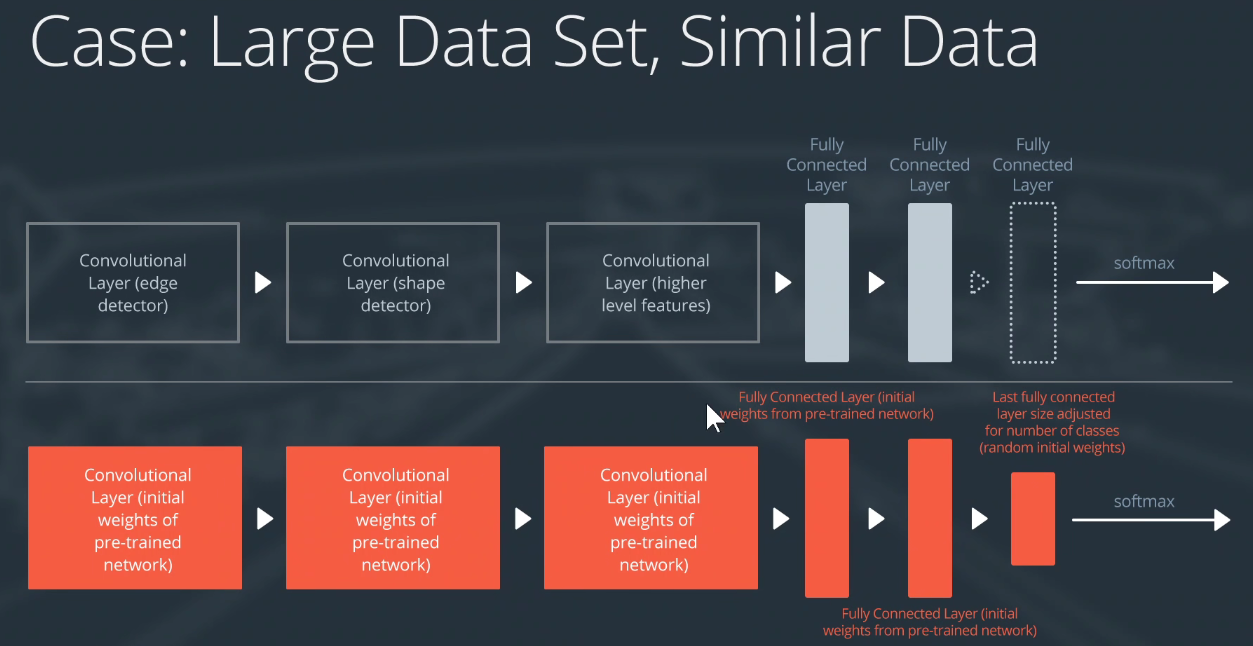
大数据集且与预训练模型所在数据集相似。
保留预训练模型的权重,但是不冻结,所有的层放开,即都是可以训练的。初始化时是预训练模型的权重,在训练过程中,更新我们自己的权重。当然线性分类层还是需要自定义重新训练。
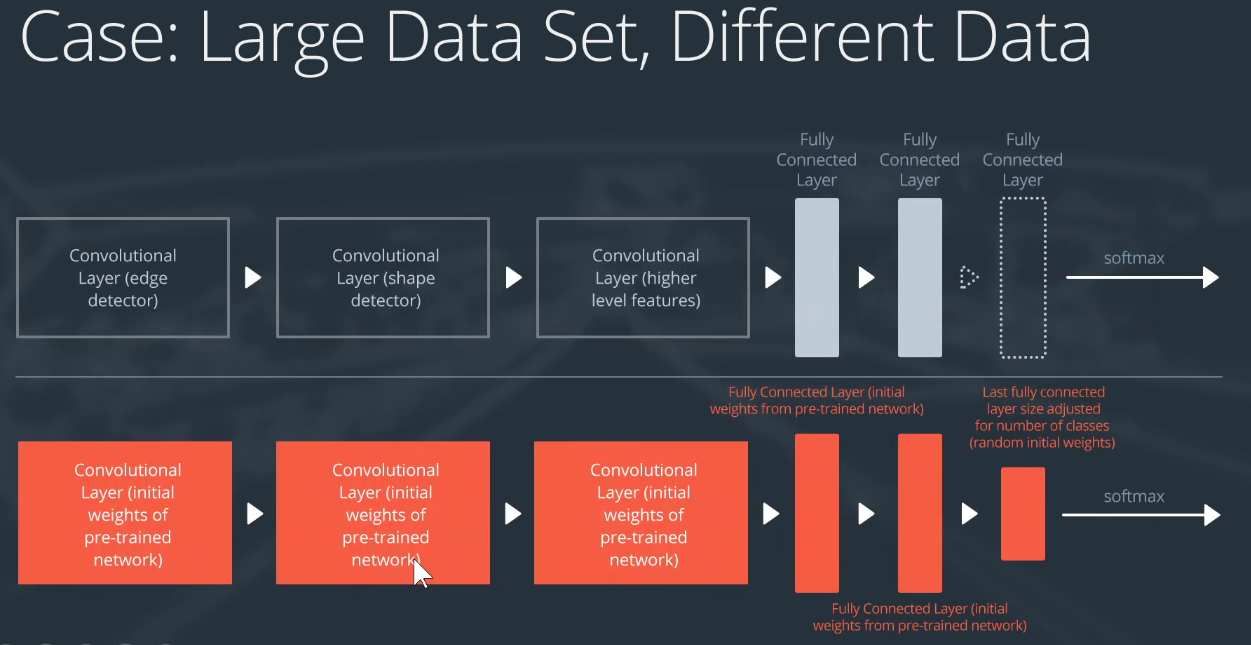
大数据集且与预训练模型所在数据集不相似。
也可以采取上述策略,用预训练模型进行初始化,最后的线性分类层改成我们自己的。在我们的大数据集上进行训练,放开每一个层。
以上是迁移学习的理论基础。
3 案例-斯坦福大学本科生关于皮肤癌的模型
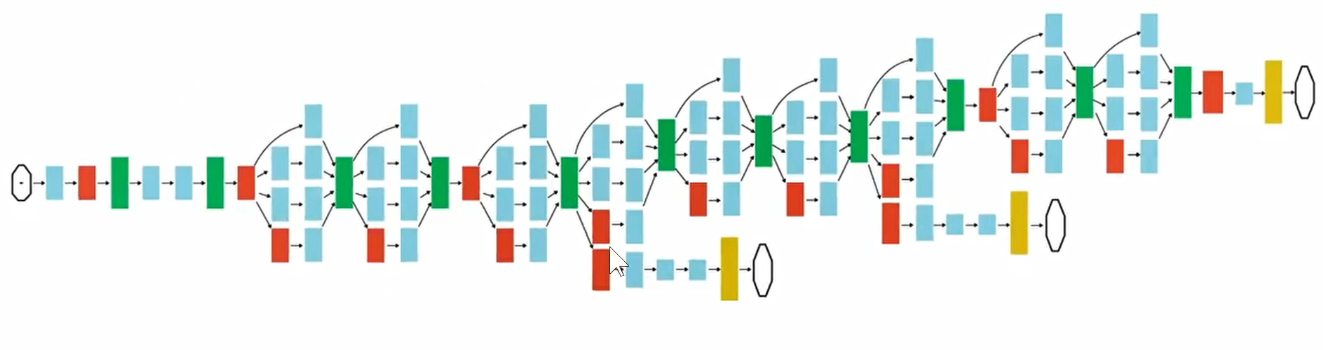
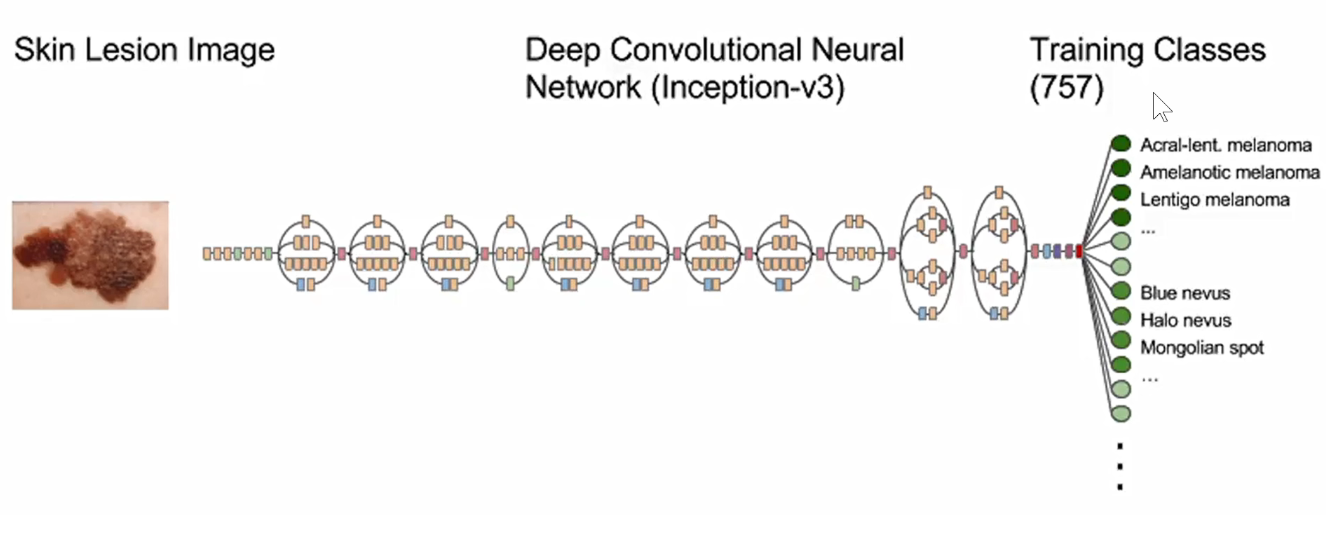
如下图,他们使用的是Inception-V3模型,每一个模块分别用4个不同尺度的卷积核进行卷积,再把这4路的数据汇总到一起,传给下一个Inception模块。把不同的Inception模块进行堆积,就能够提取出图像中不同尺度的信息,再把这些不同尺度的信息进行融合。
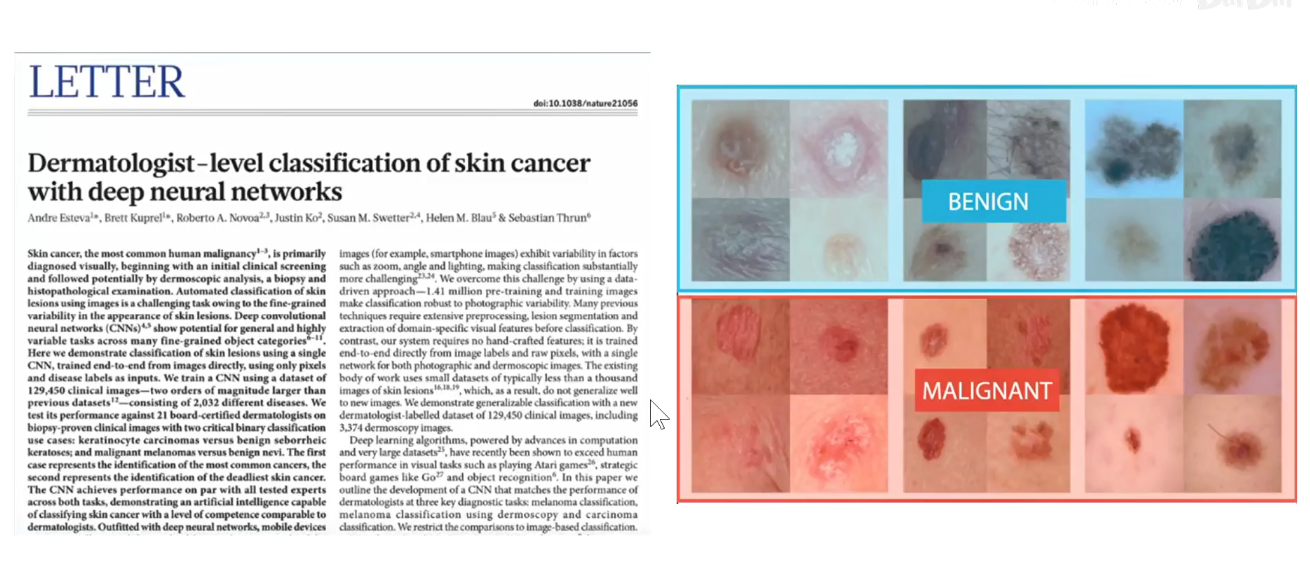
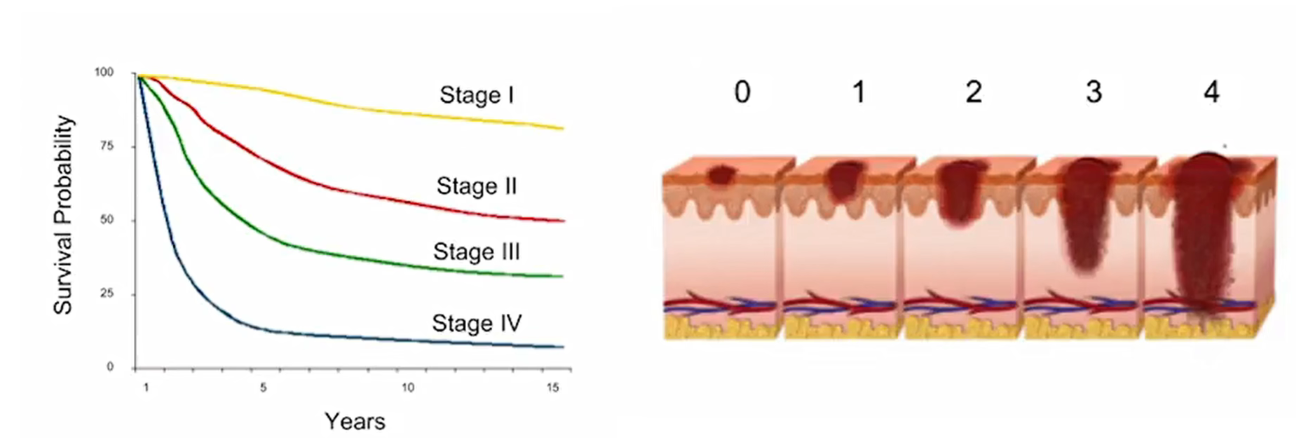
皮肤癌是医学上一个常见的问题。如下图,发现的越晚,存活率越低。医疗影响诊断,早发现,早治疗,节省大量的费用。
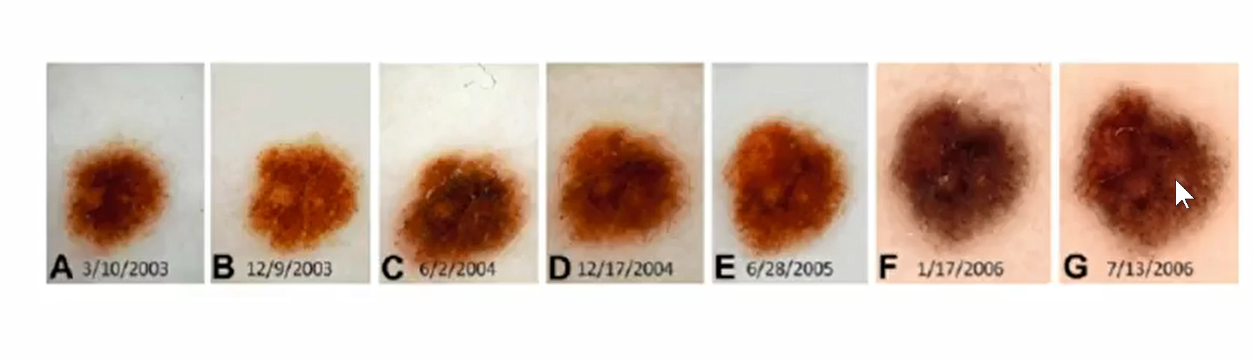
如下图:对皮肤斑块进行分类。
如全美有经验的皮肤科专家只有不到5W名,他们有着大量丰富的临床经验,每次都要耗费大量的时间和金钱,耽误了病情,如果可以采用机器学习的方法,通过大量的数据训练一个神经网络,把对应的知识固定下来,当有新的数据的时候跑一遍这个模型,使用医疗影像检测出潜在疾病,可以提前治疗。
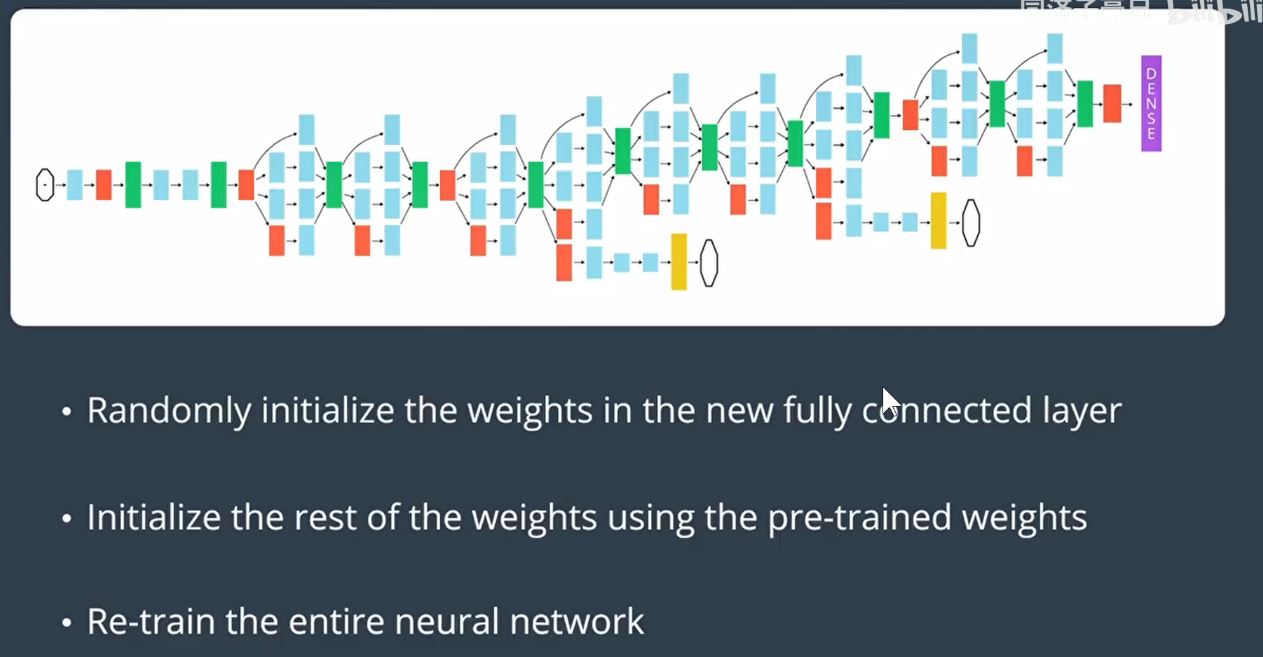
数据并不是百分百完美,需要对数据做预处理,在斯坦福这篇论文中,他们使用了13W张皮肤癌数据。模型使用的Inception-V3模型。如下图:
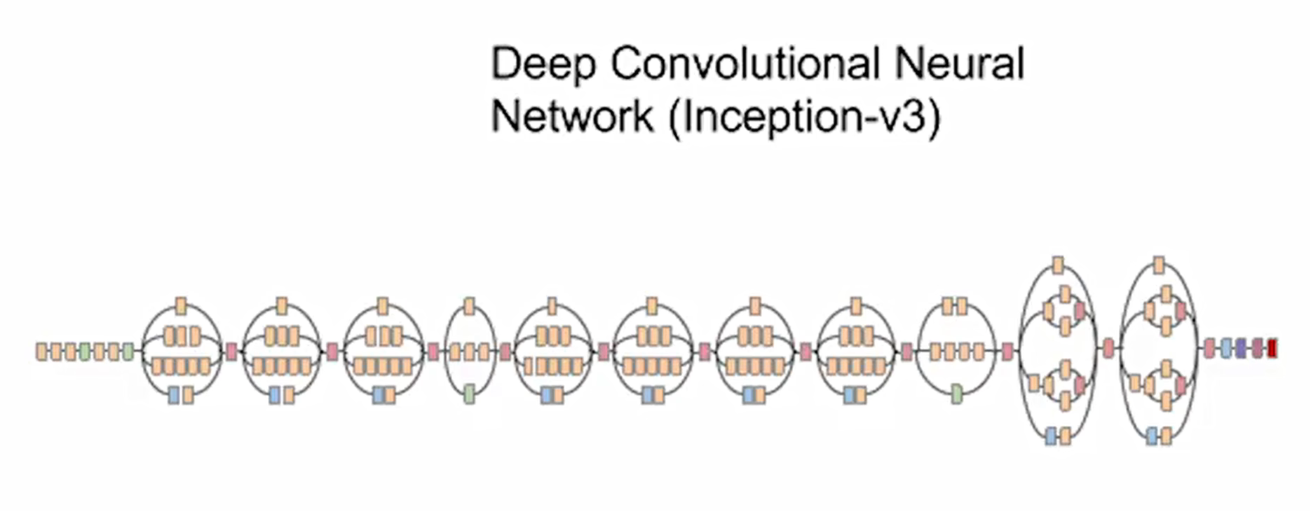
他们把全连接层改成他们自己的757类皮肤病的类别。把预训练模型的权重保留,但是所有层都是放开的,在自己的皮肤癌数据上训练所有的权重。
验证集上的效果如下所示:

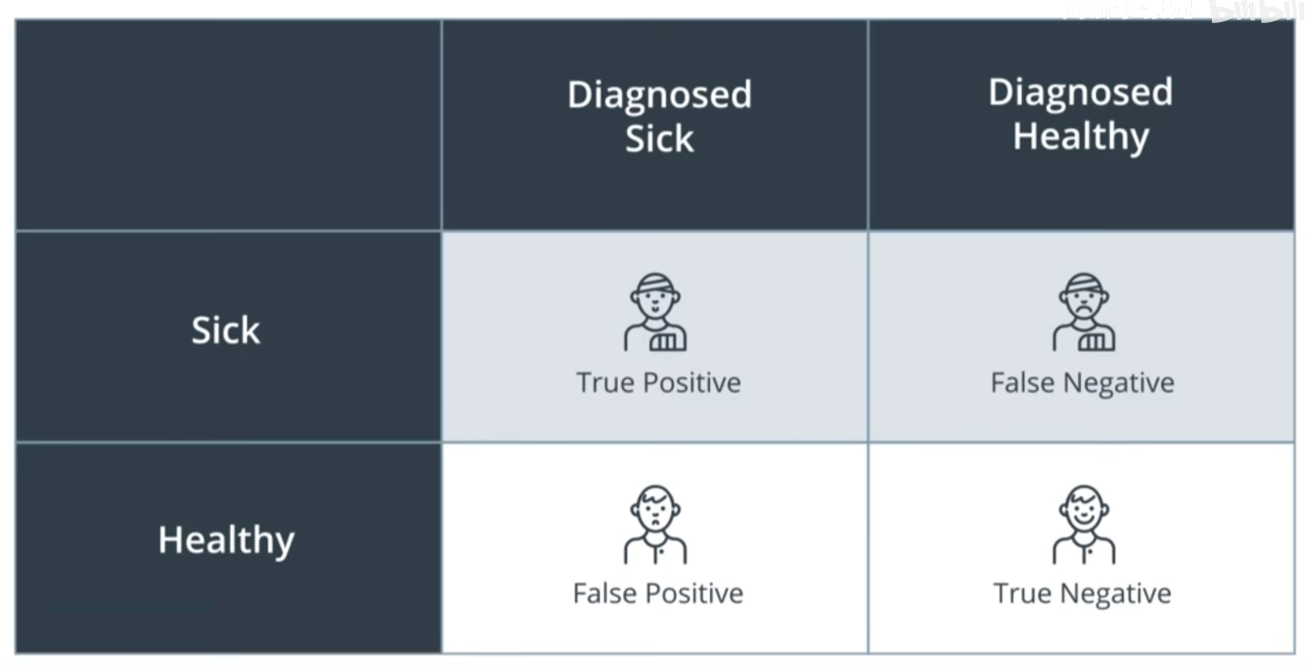
此时就涉及到混淆矩阵的问题
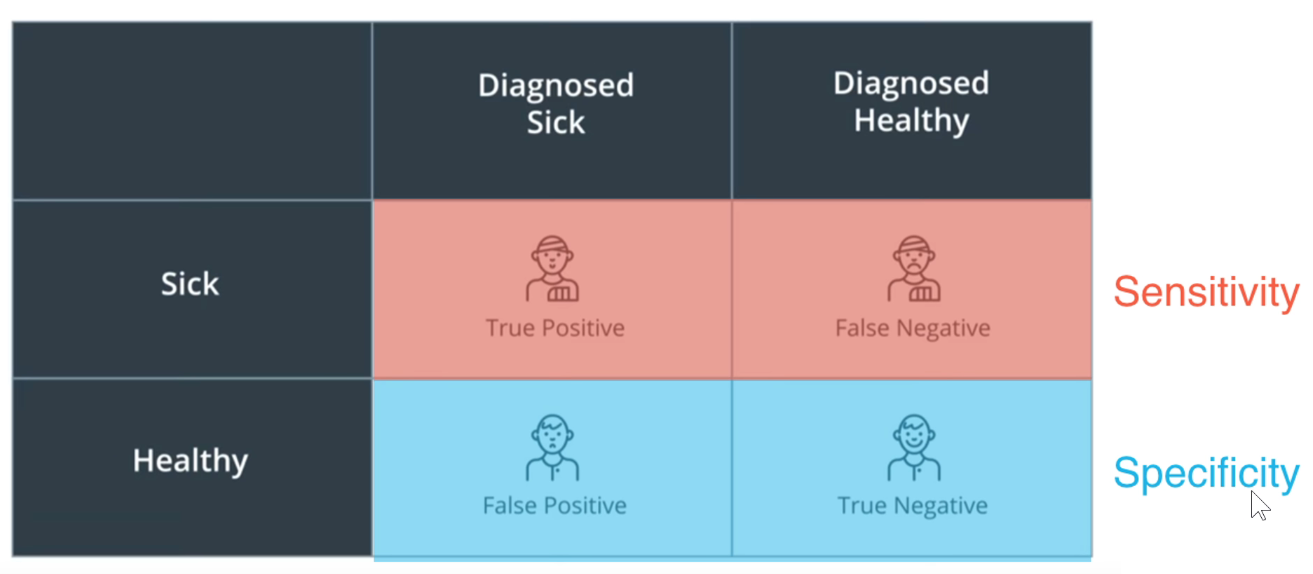
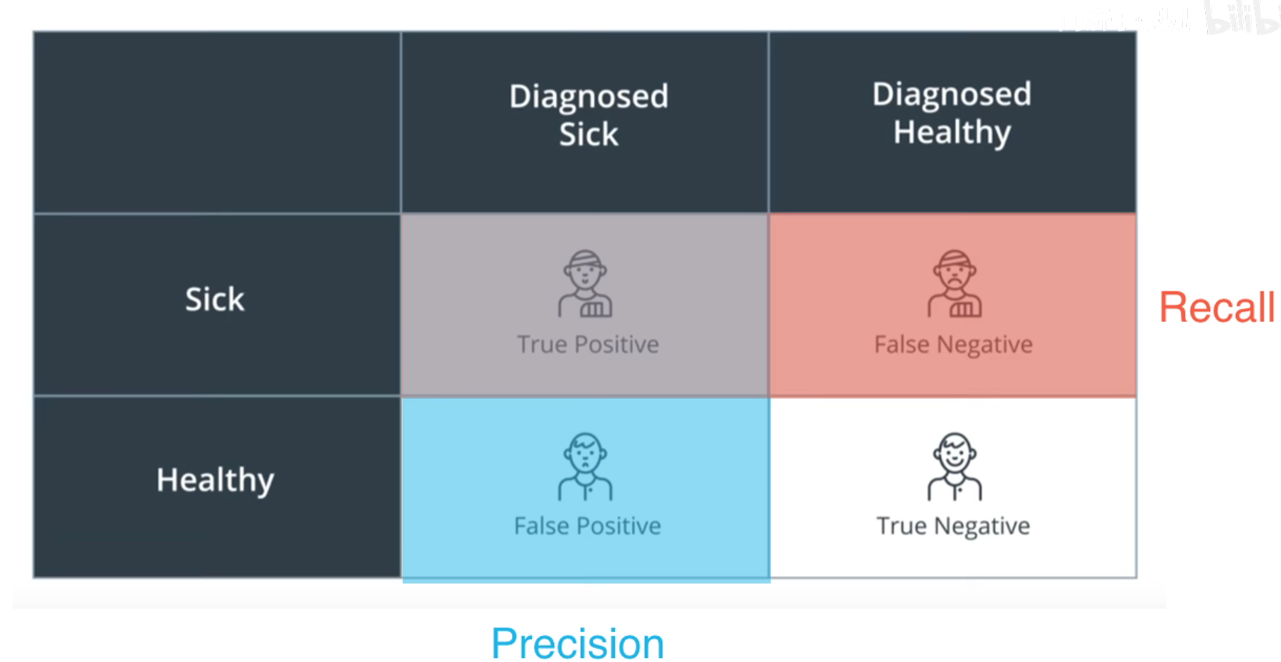
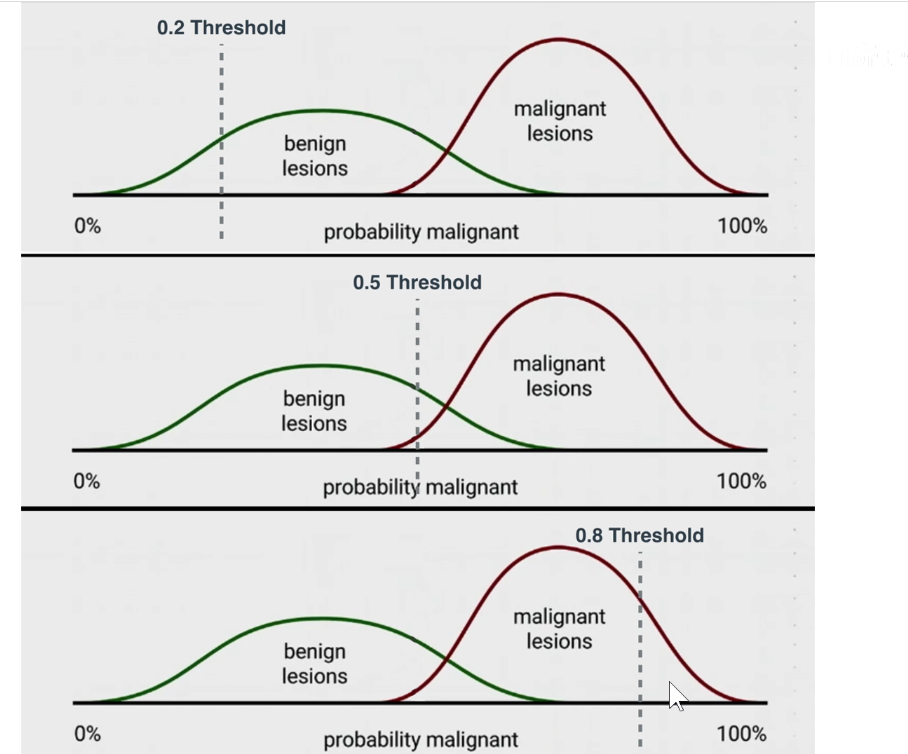

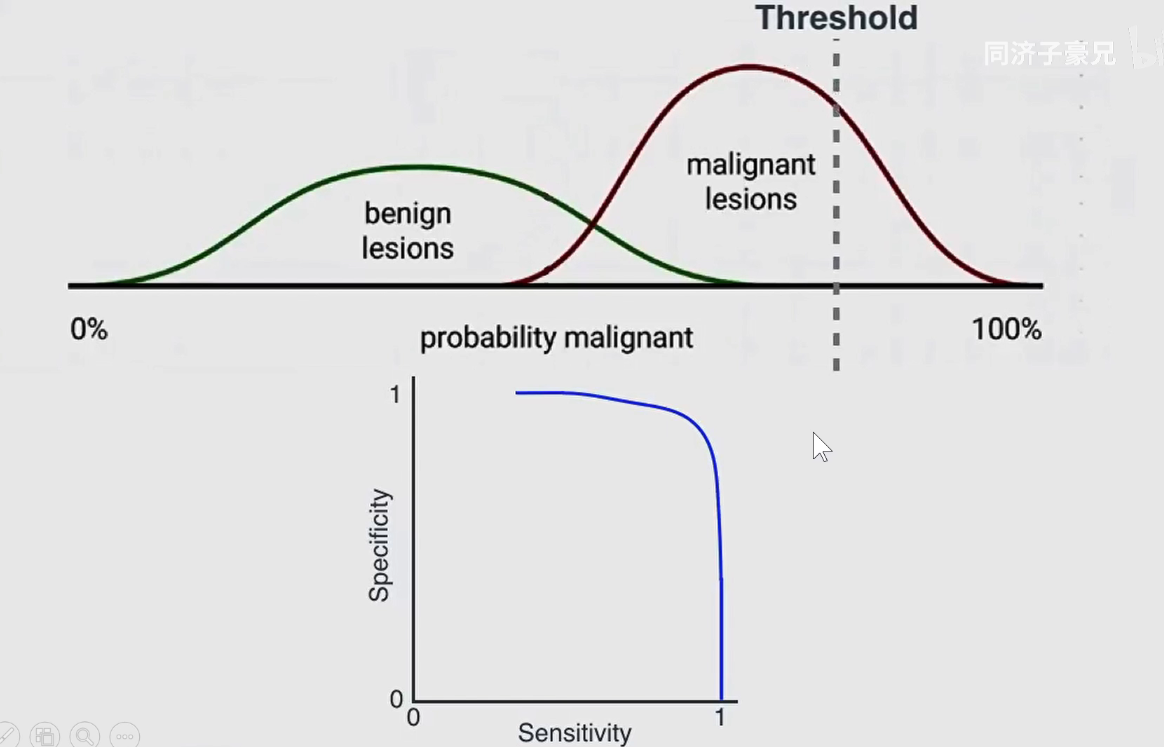
在不同阈值下,可求出不同的灵敏度和特异性。滑动阈值,可求出不同的ROC曲线
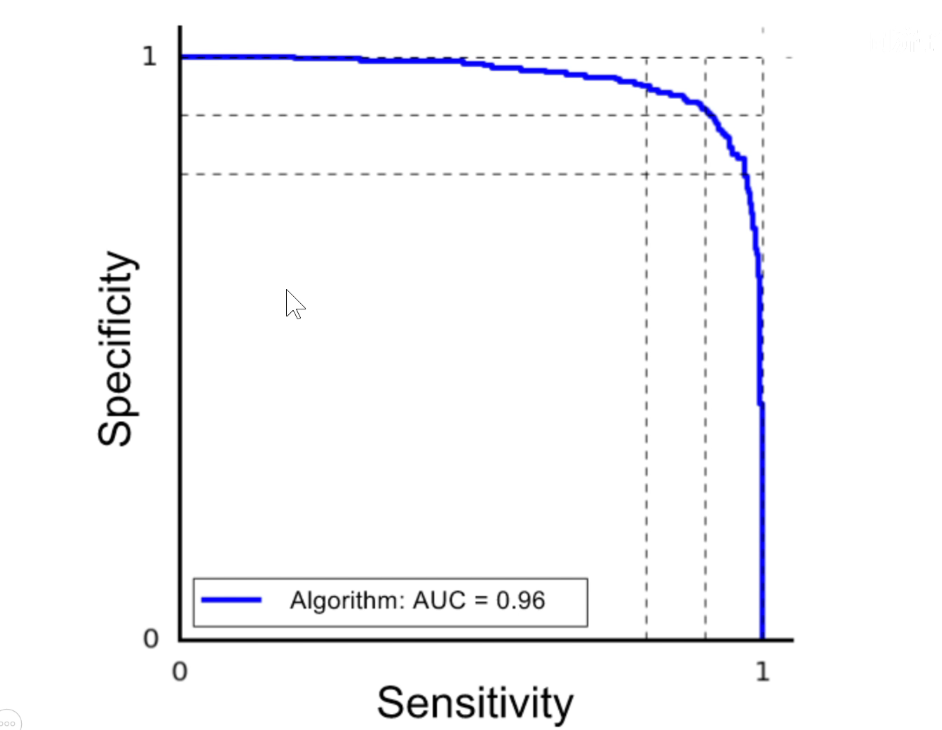
ROC曲线越靠近右上角,说明模型越好
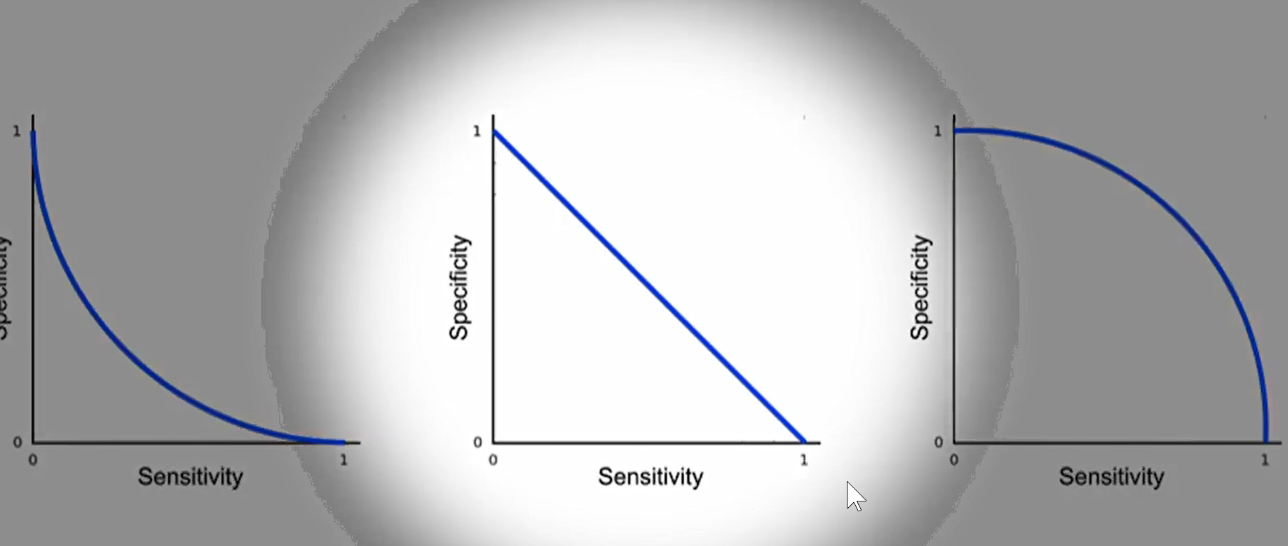
如下图:中间的模型表示随机猜,左边的模型表示还不如随机猜,右边的模型表示好于随机猜。
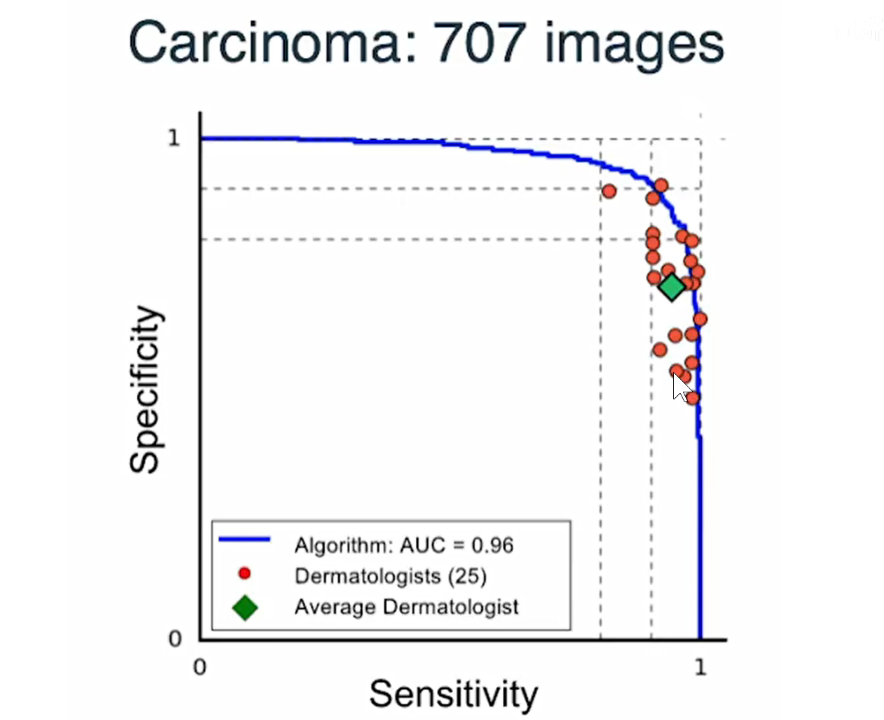
下图将25个医生的诊断和模型自身的ROC曲线划到一张图中,可以看到,医生的诊断点基本都在ROC模型内部,说明训练出的模型要比这些专家要更好。绿点表示专家的平均水平。
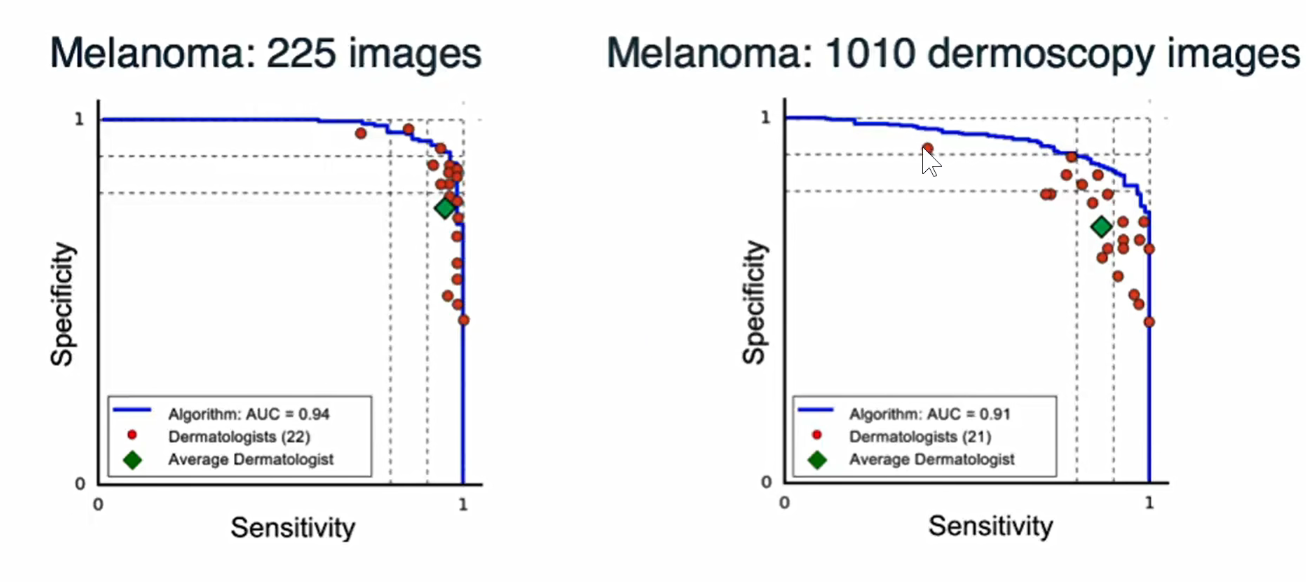
如下图,在不同的数据集上进行训练。发现CNN的模型基本上都是比专家要好的。
之前讲卷积神经网络可视化,讲到一种方法是可以把模型提取出的编码用T-SNE这种非线性降维的方法,降维到低维空间,特别是到2d和3d这种人类可以理解的空间中进行可视化,
每一个颜色表示不同的类别,每一个点表示不同的数据,
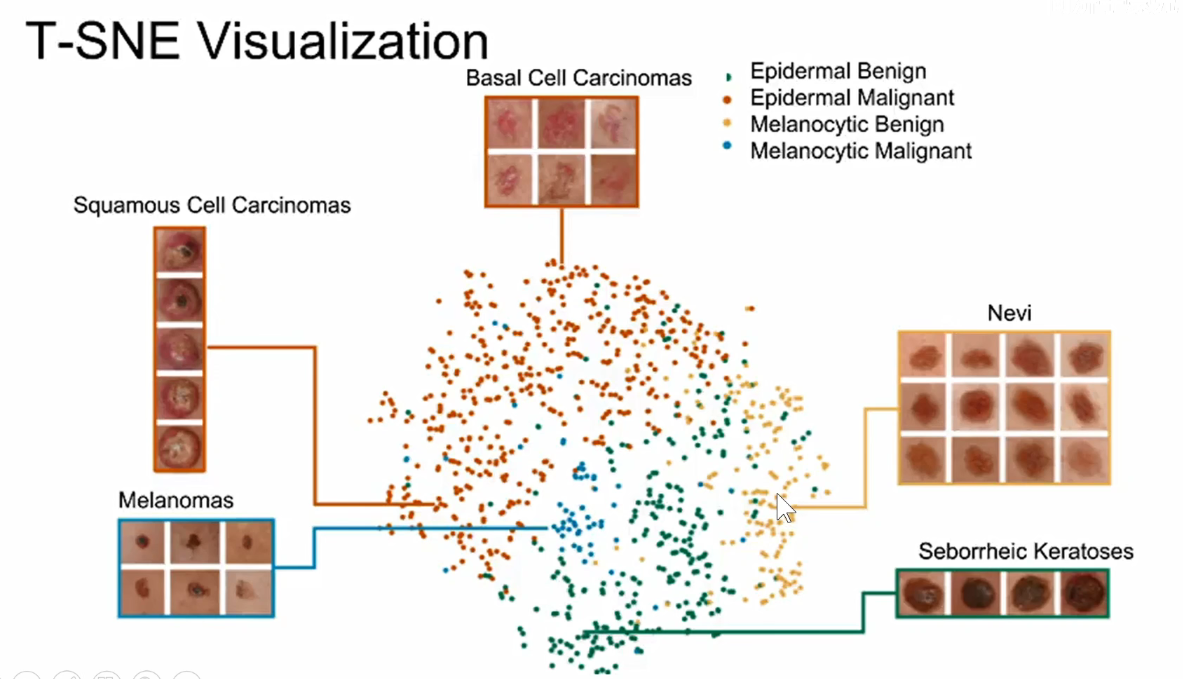
这篇文章最后发到了2017-Nature的封面上。

商业前景:部署到手机APP上,进行拍摄来判断是否会演变为皮肤癌。
