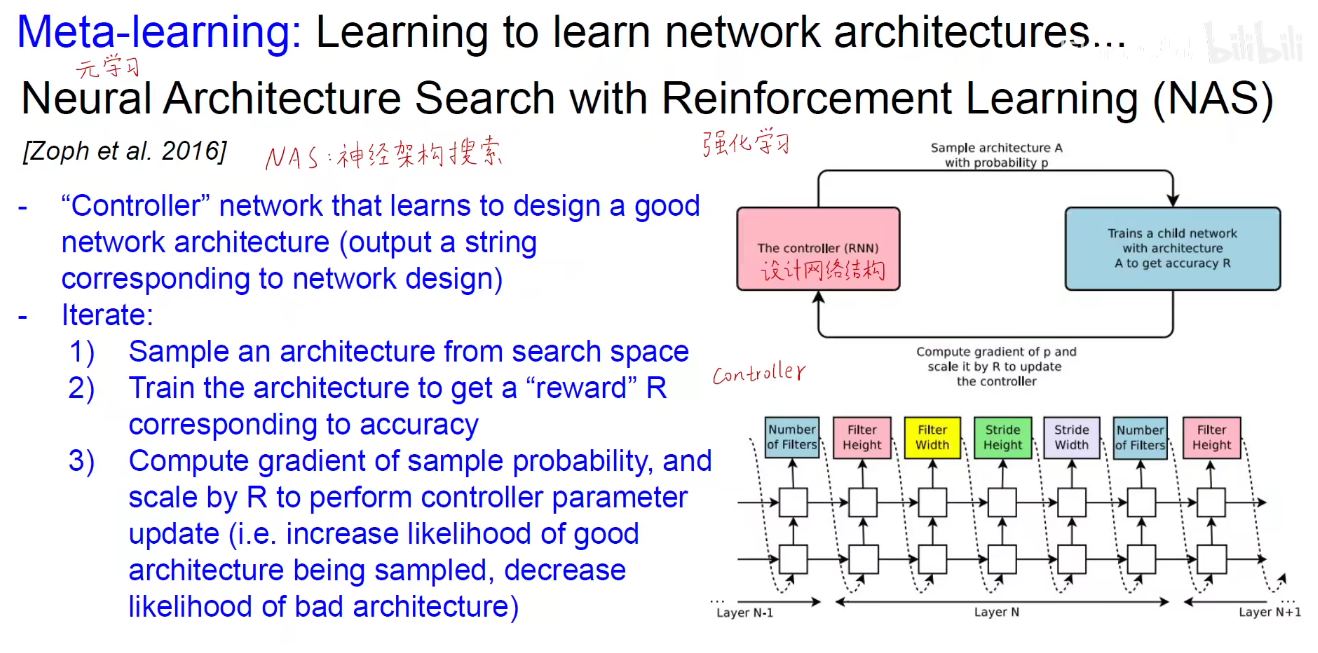
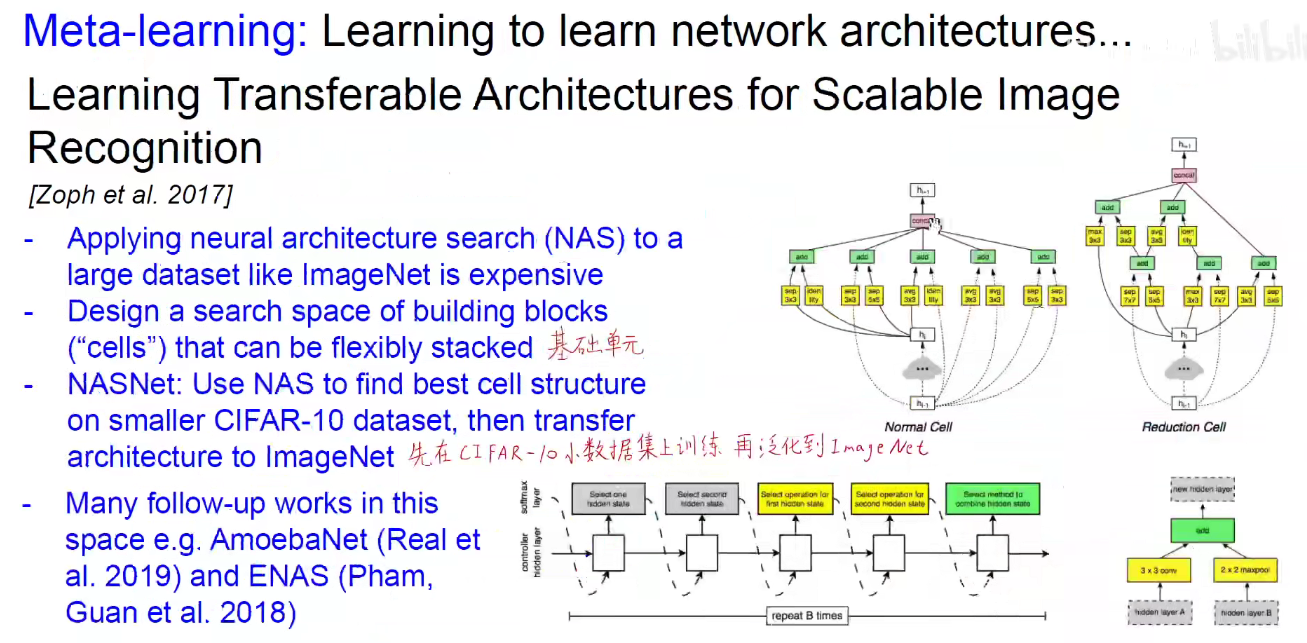
Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N & B站子豪兄
应该阅读图片中每一篇论文文献

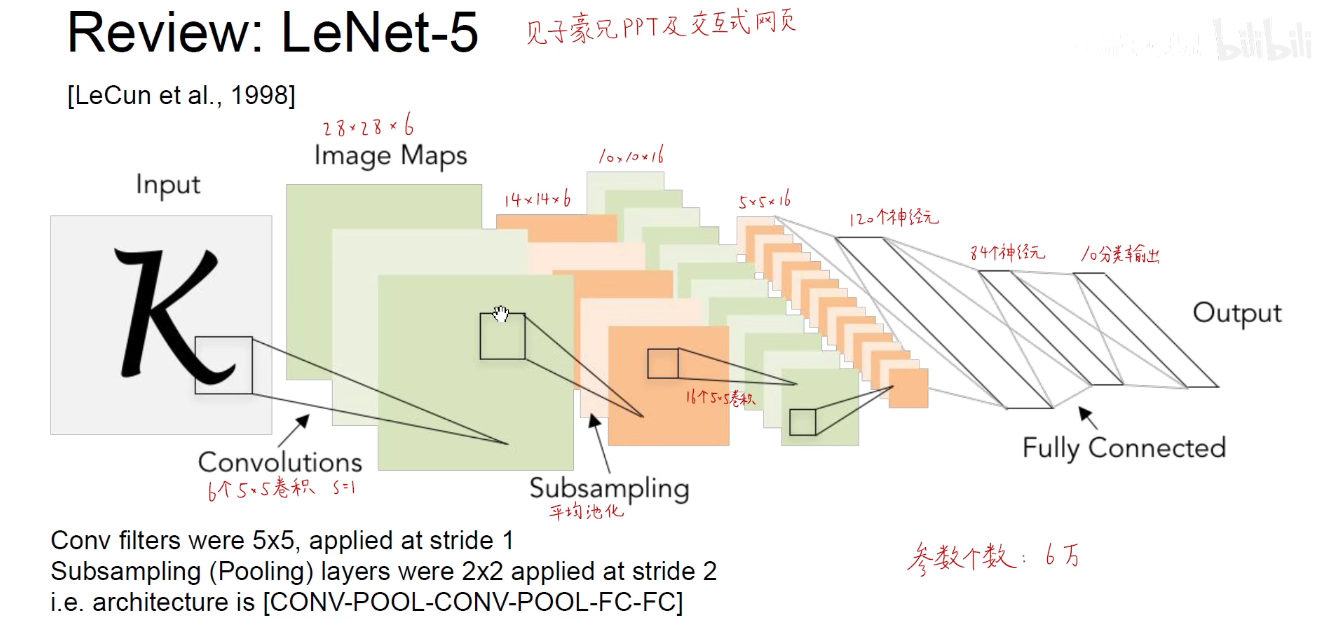
1. 1998-LeNet-5
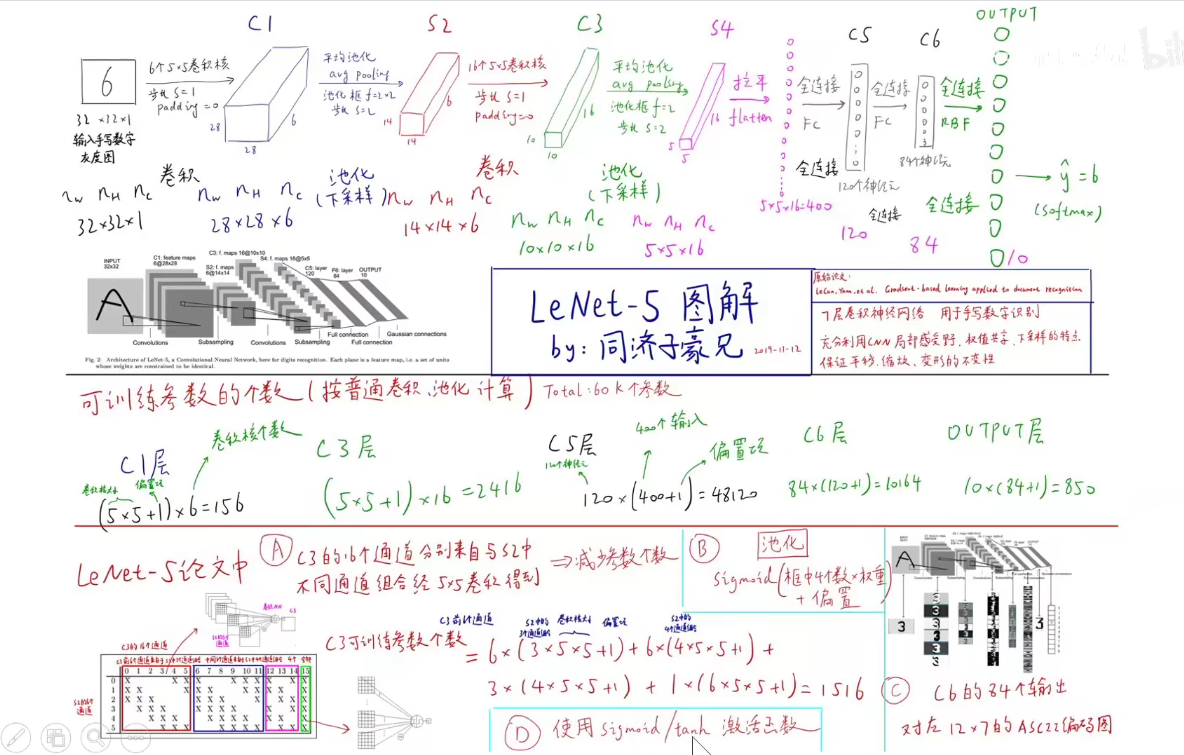
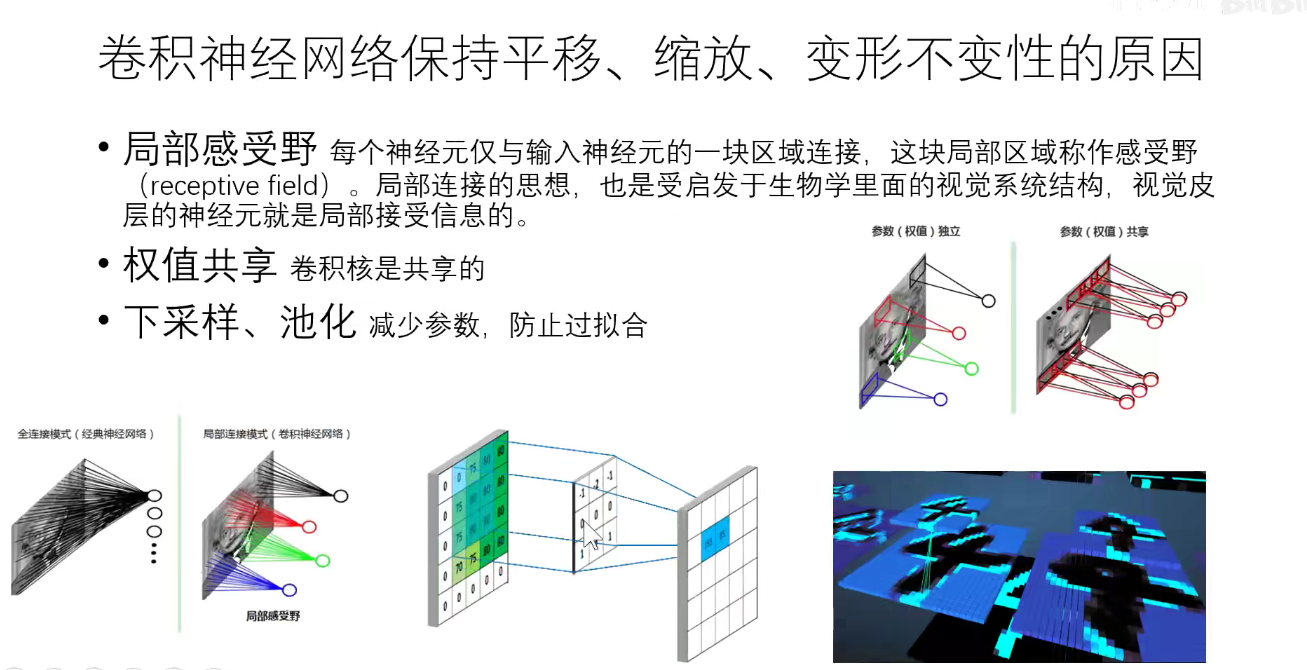

手写数字识别体验网址如下:
https://www.cs.ryerson.ca/~aharley/vis/conv/
https://www.cs.ryerson.ca/~aharley/vis/conv/flat.html

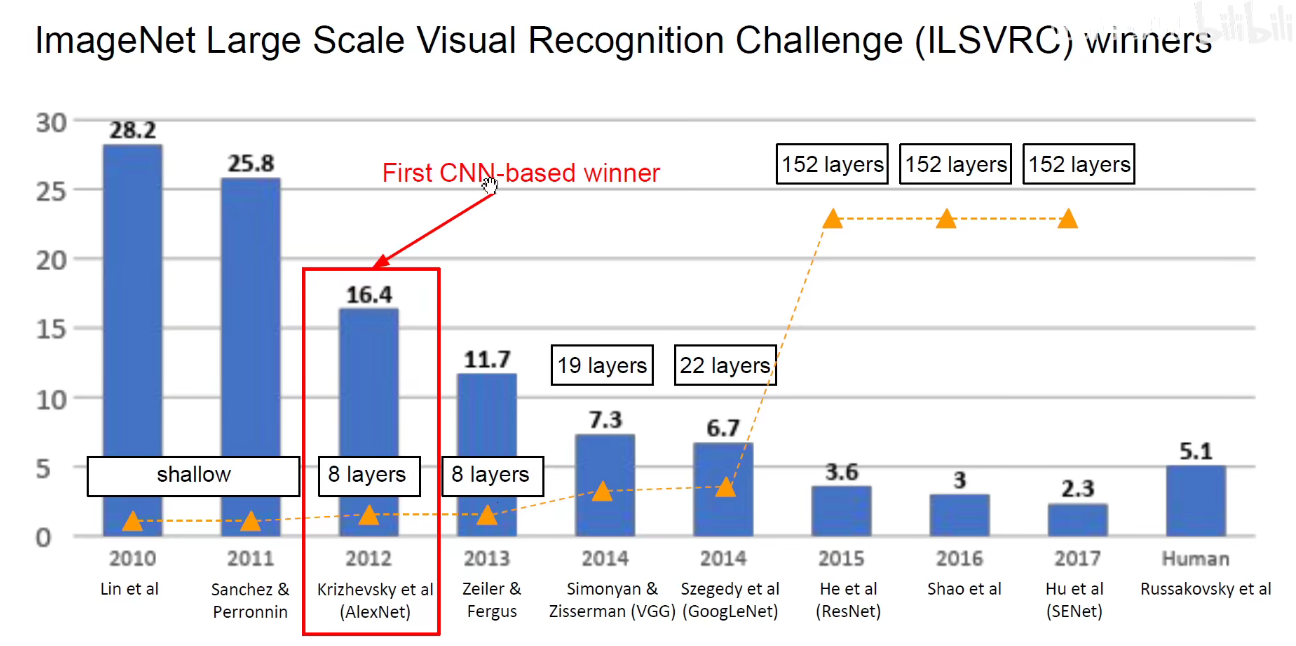
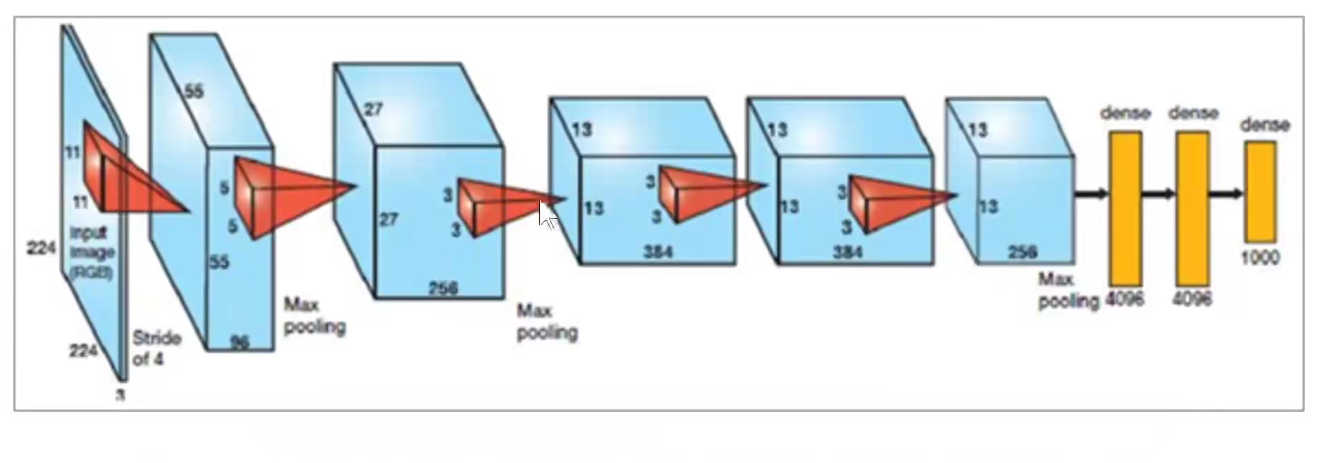
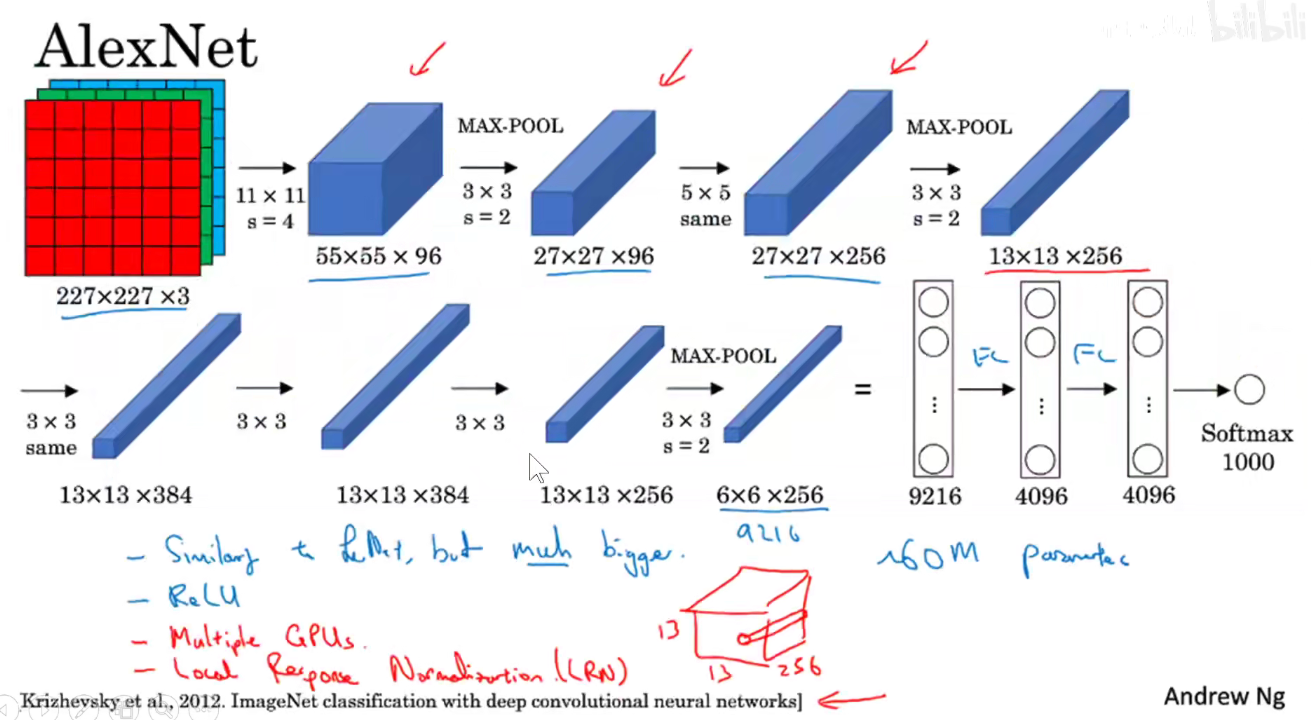
2. 2012-AlexNet
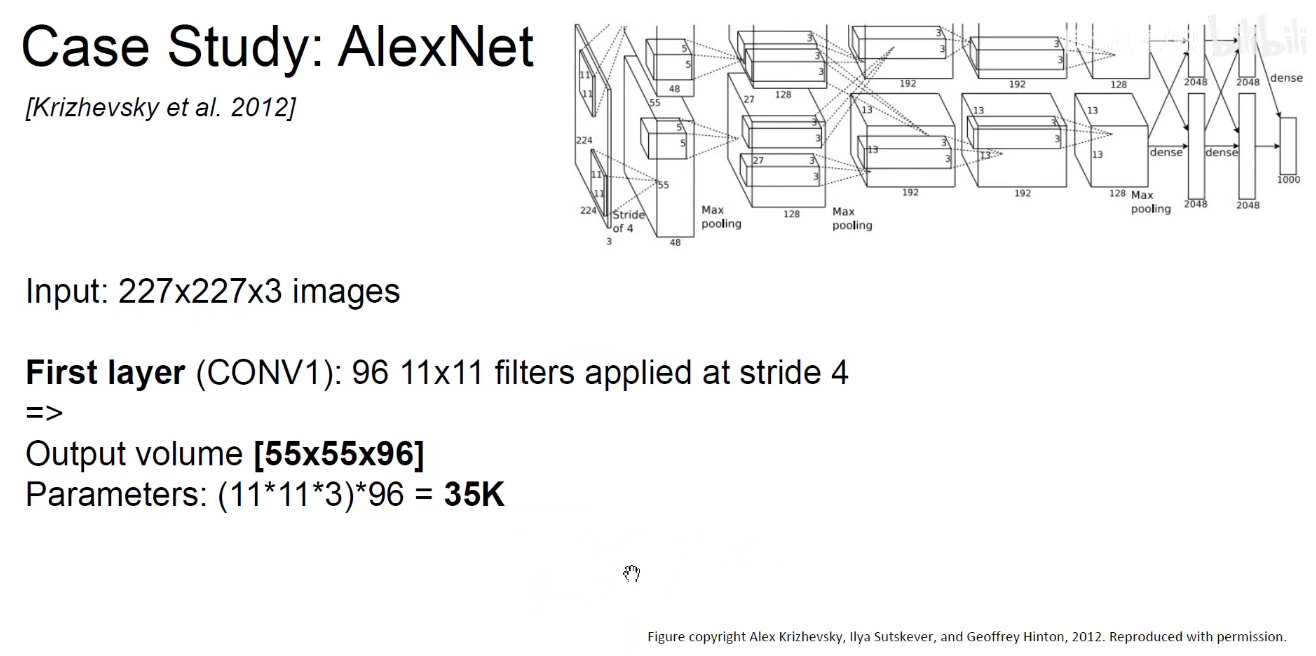
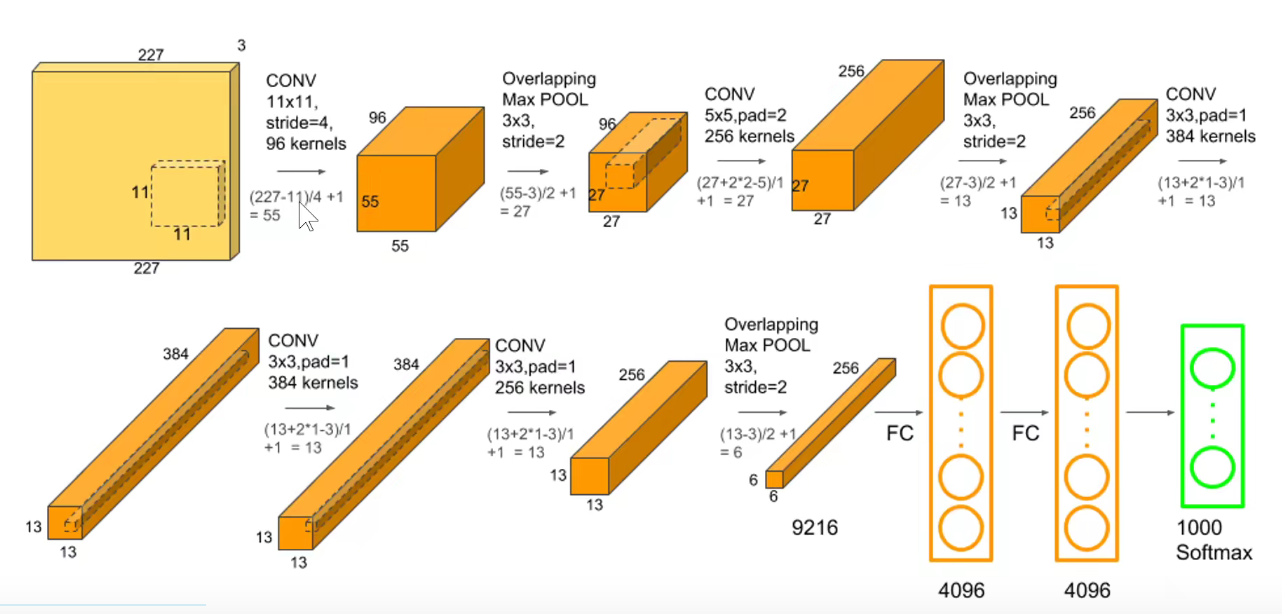
第一层卷积
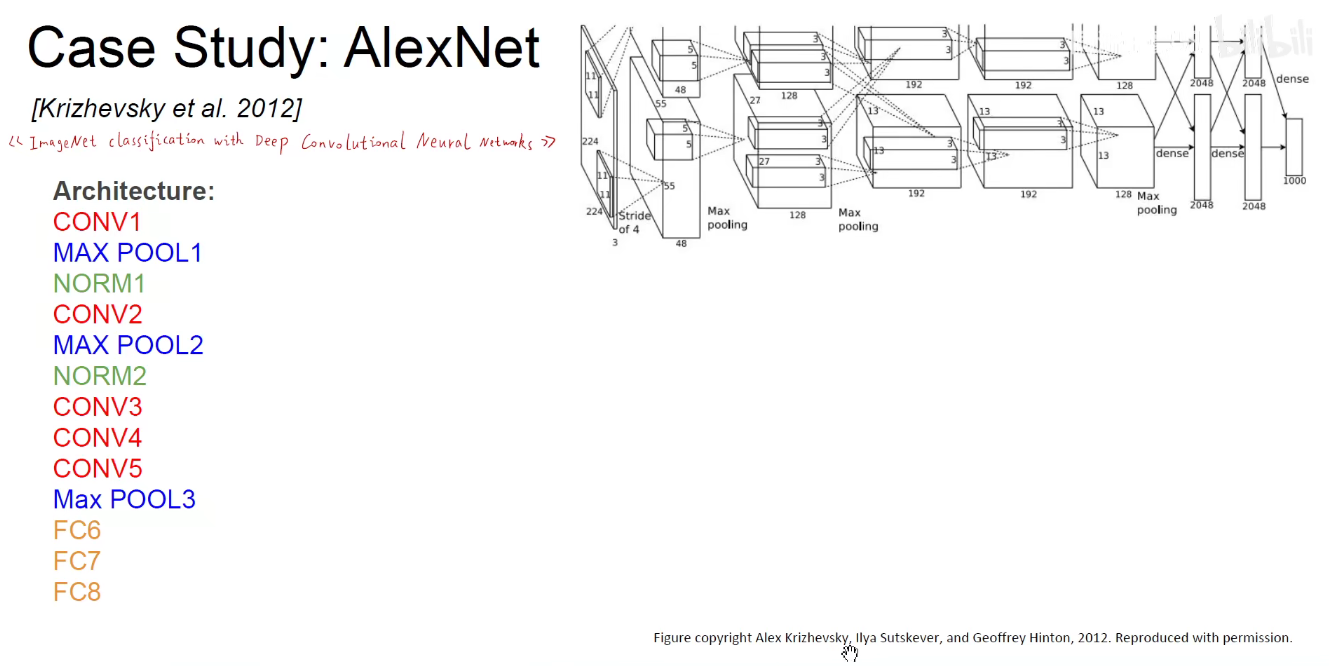

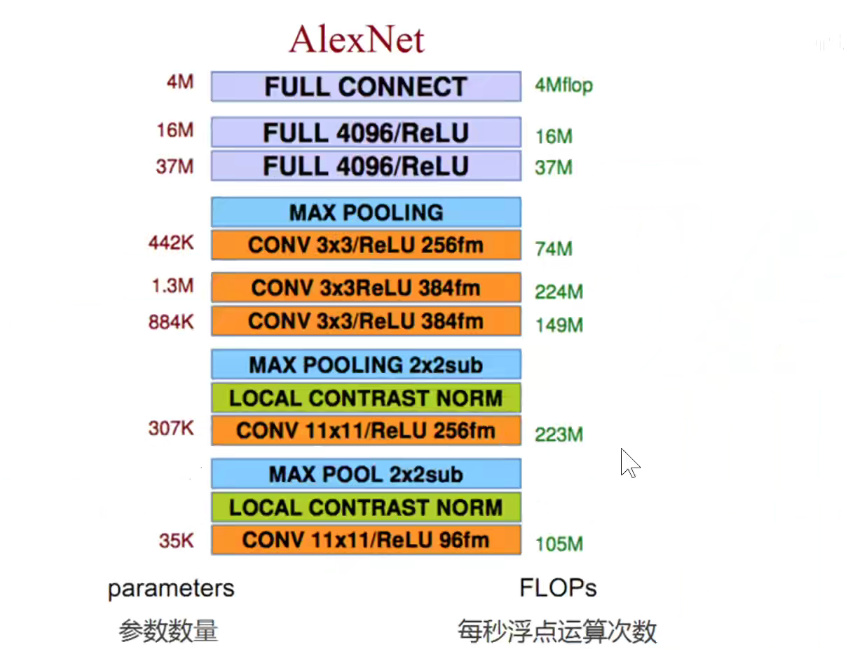
参数量如下图,此处没有考虑偏置项:
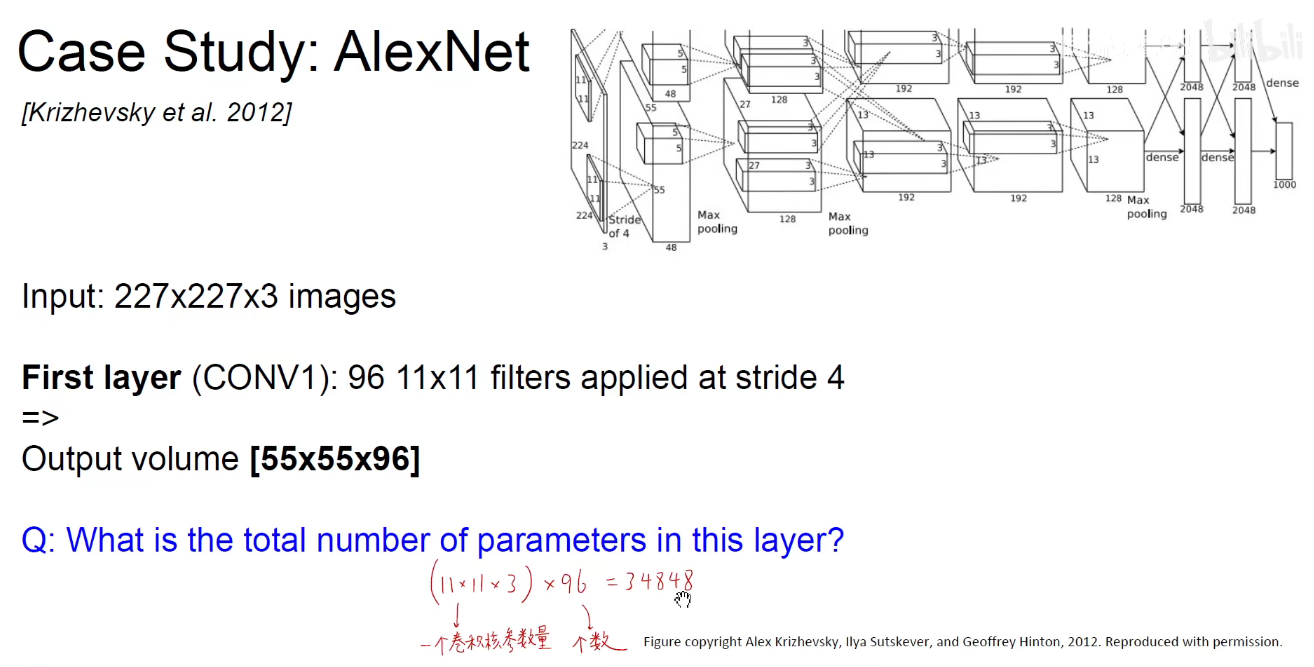
池化



可以看到: LeNet-5需要6W个参数,而AlexNet需要6千万个参数。

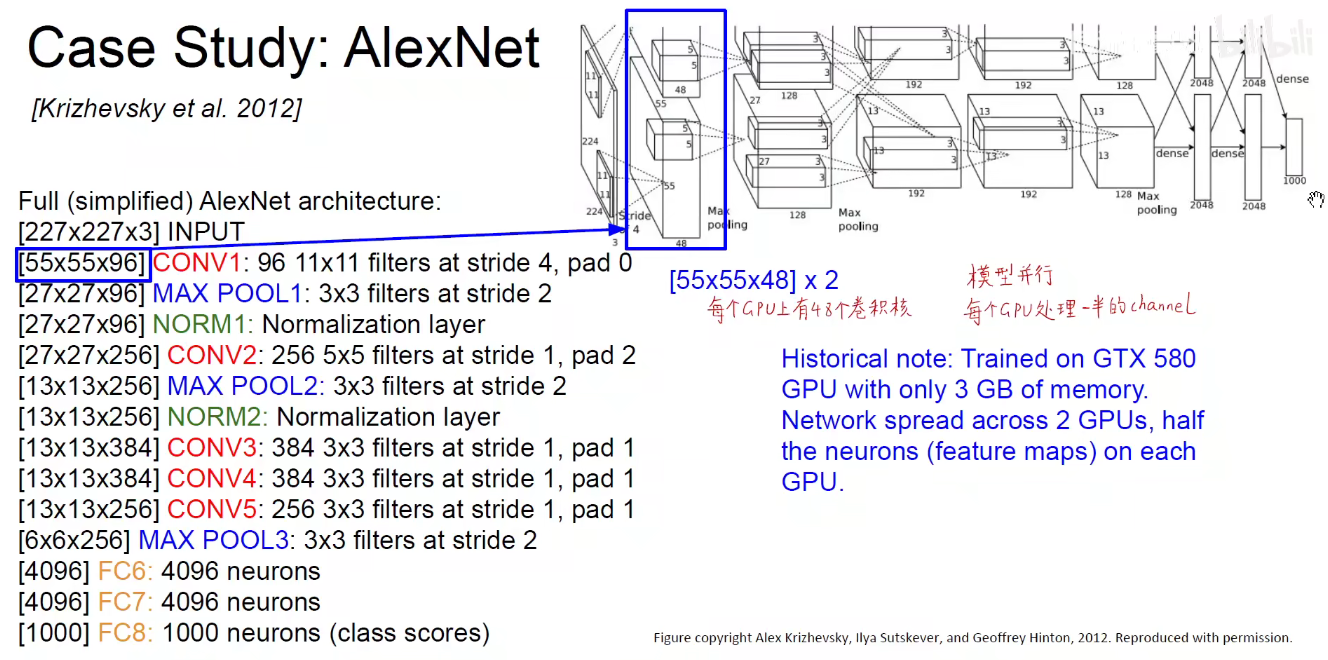
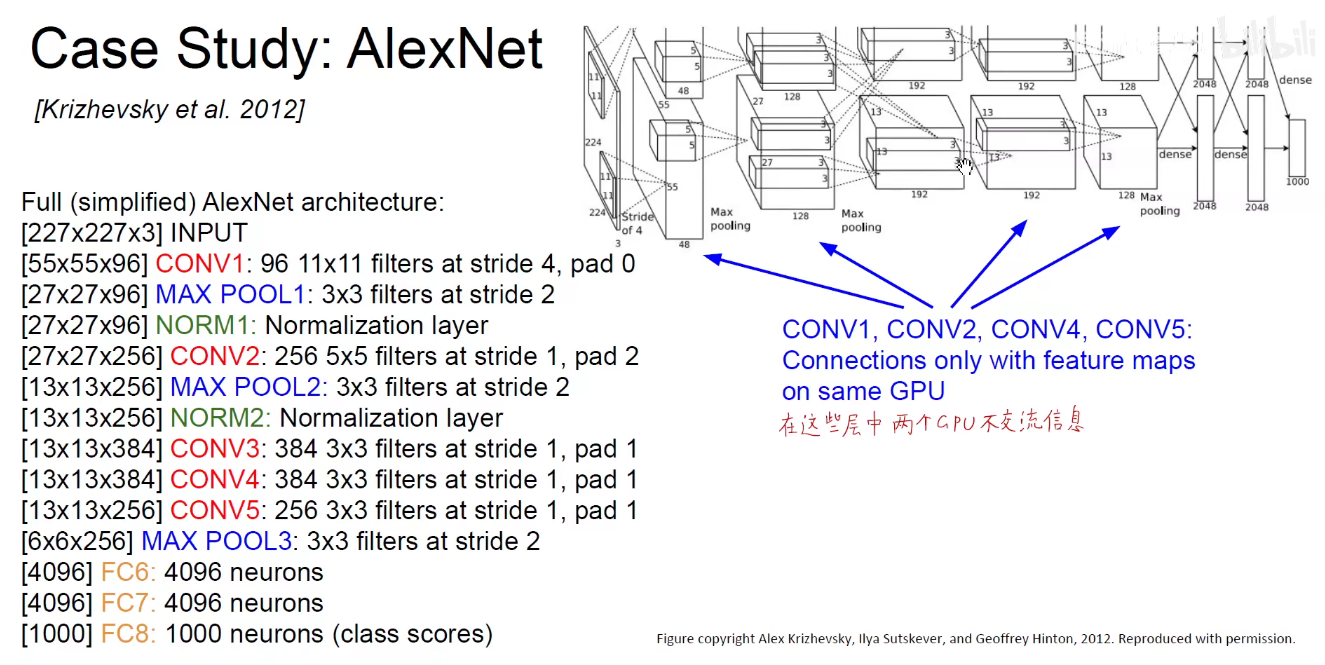
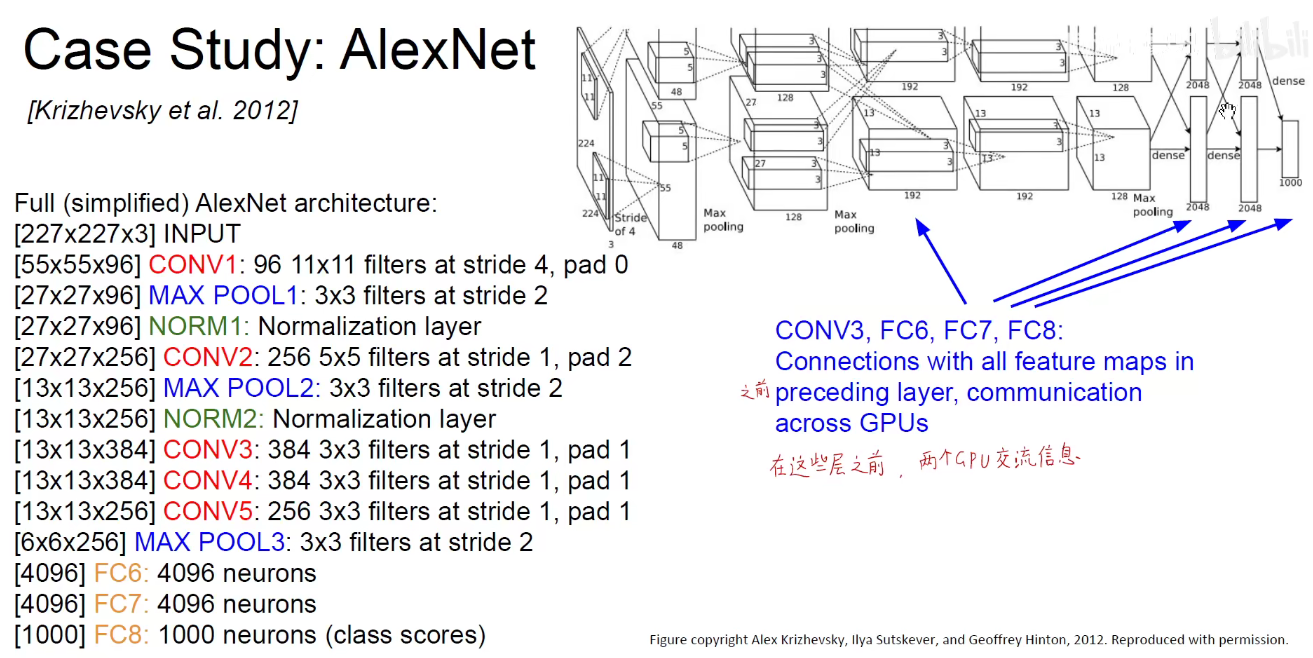
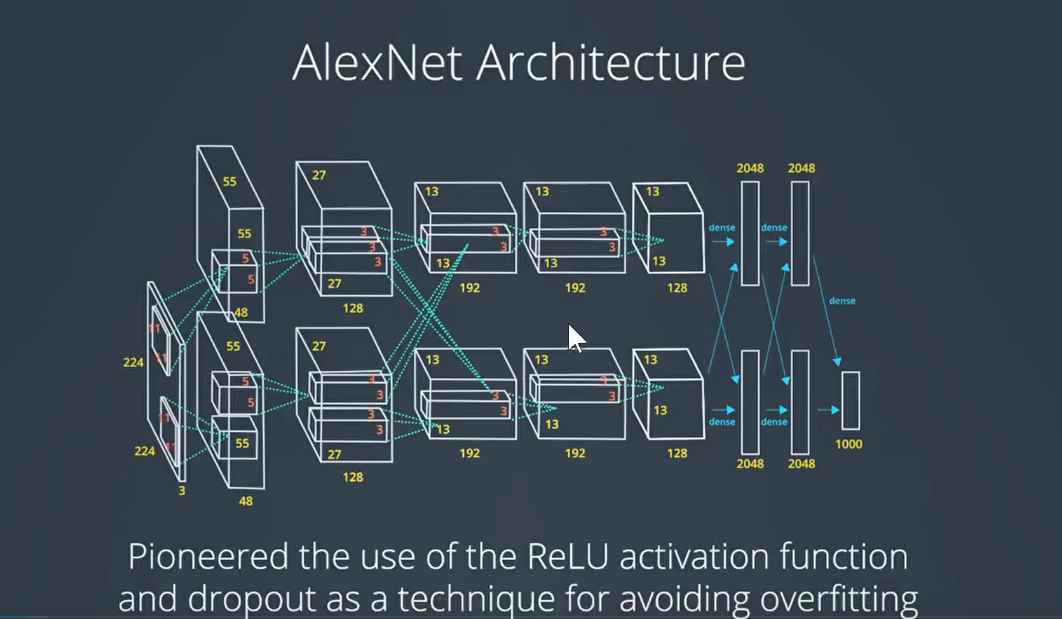
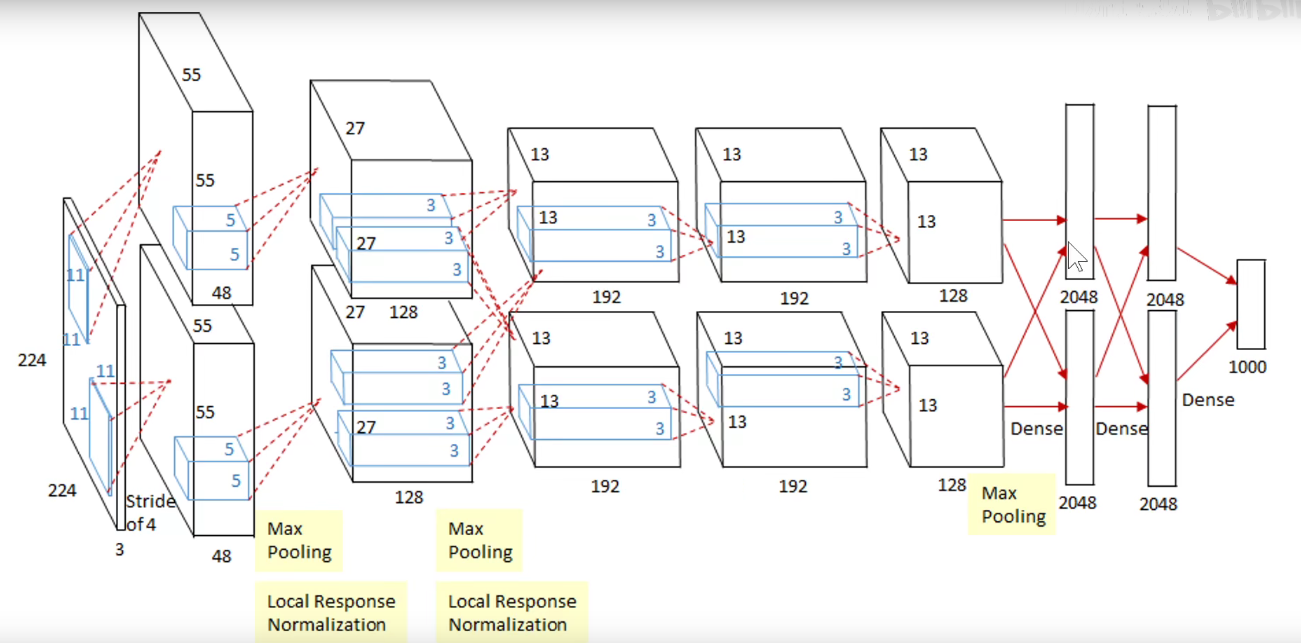
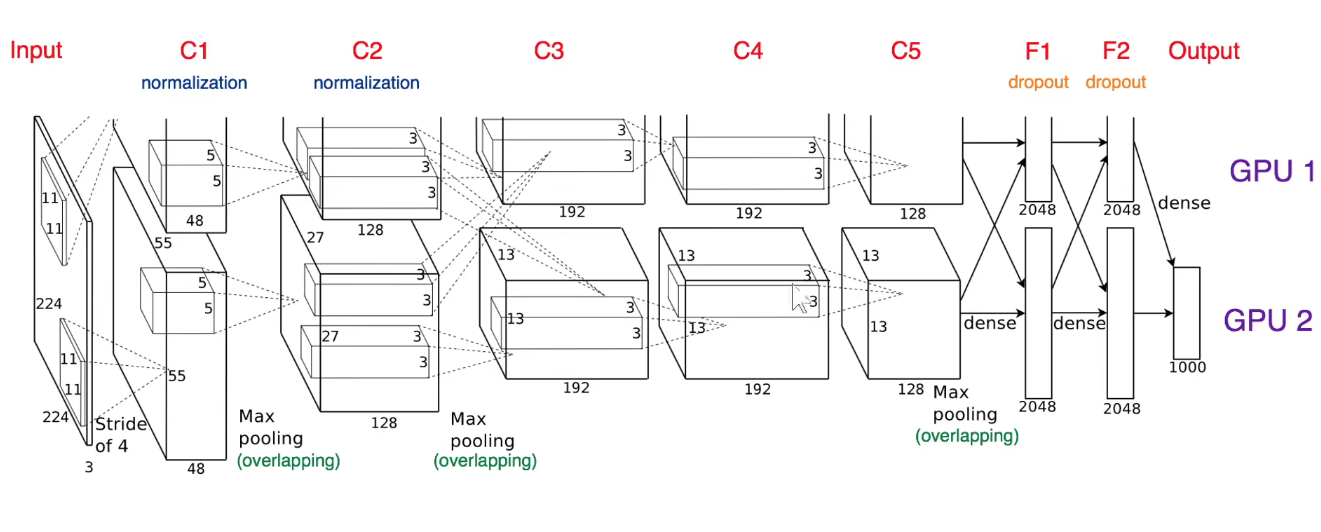
将它画到一个流中:如下图
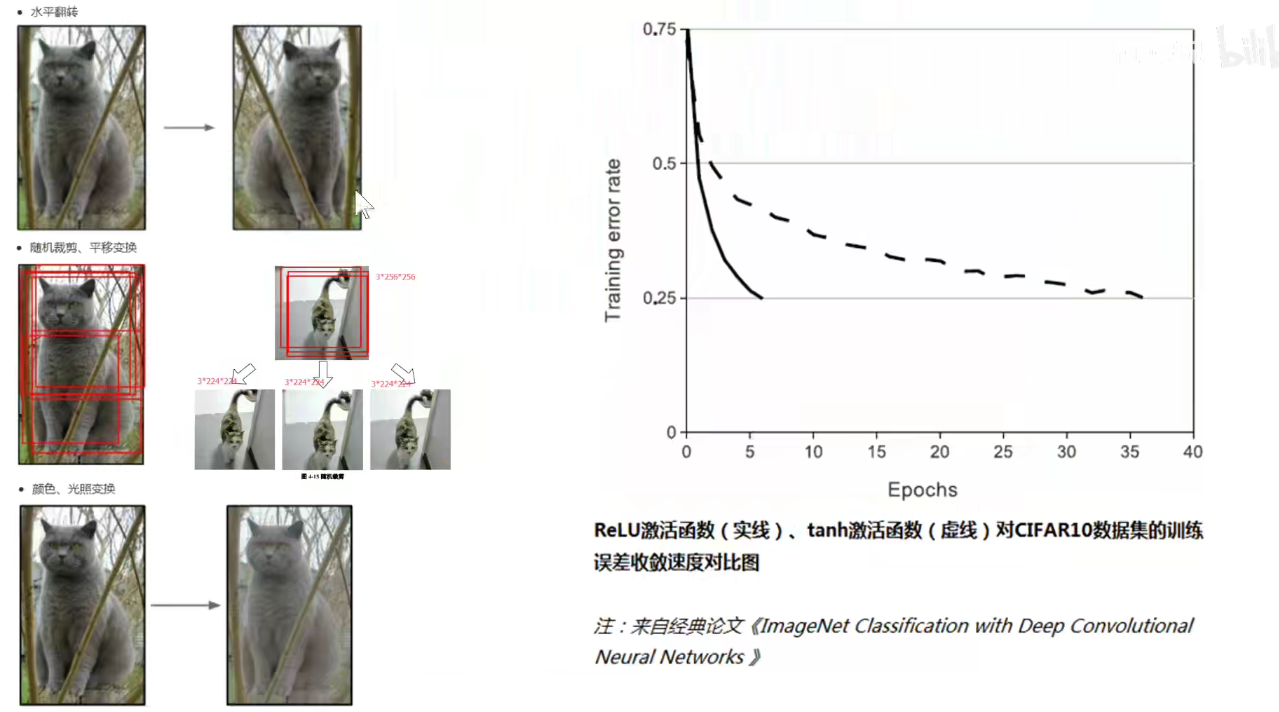
数据增强

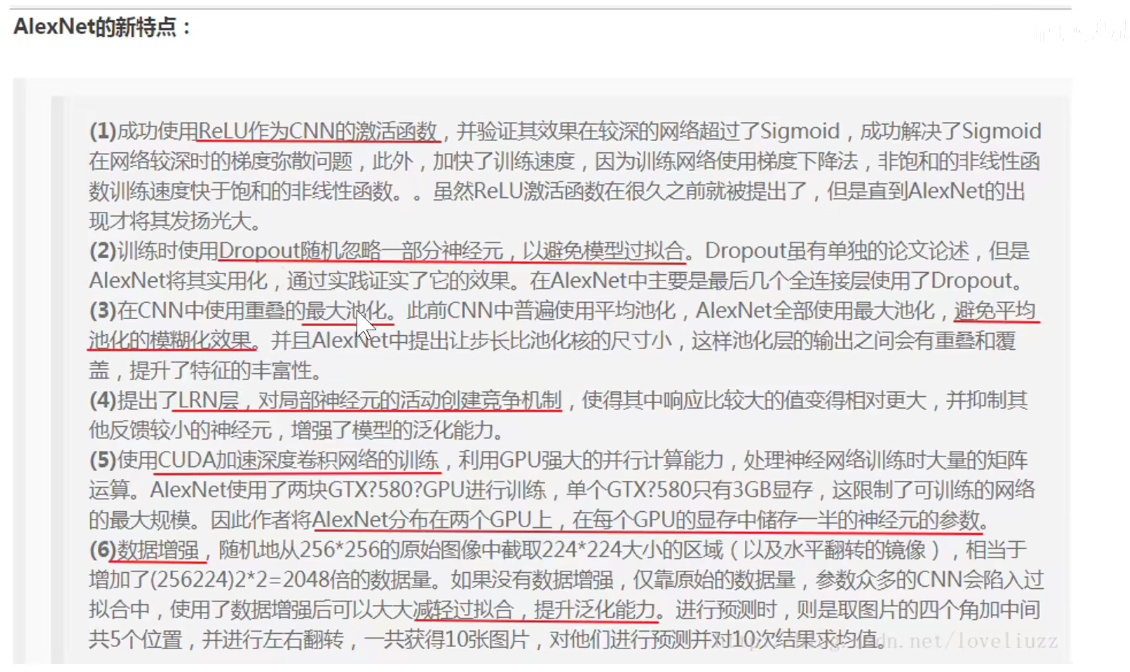
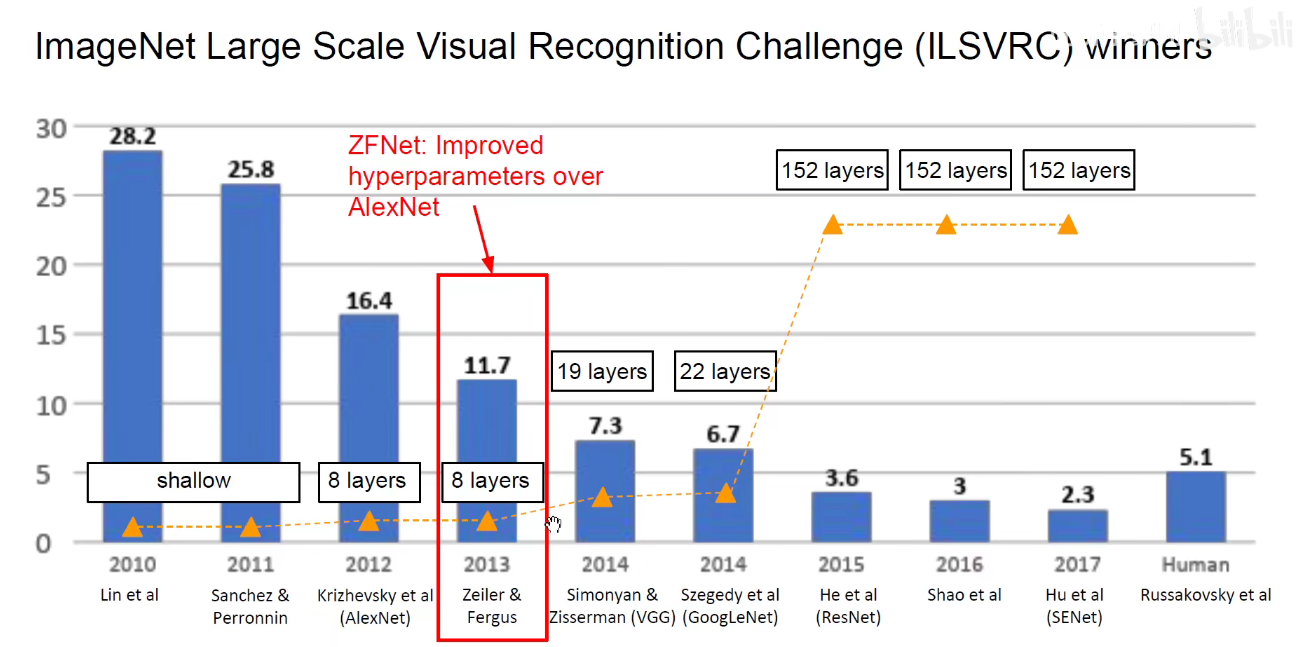
3. 2013-ZFNet
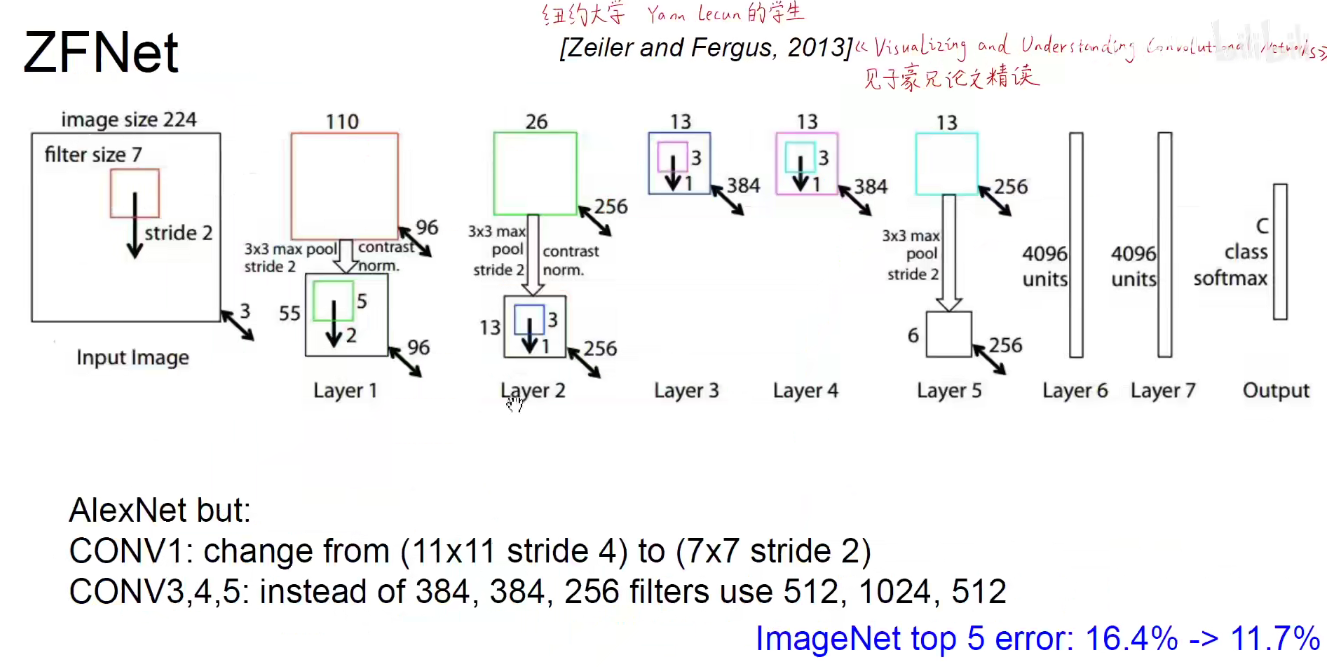
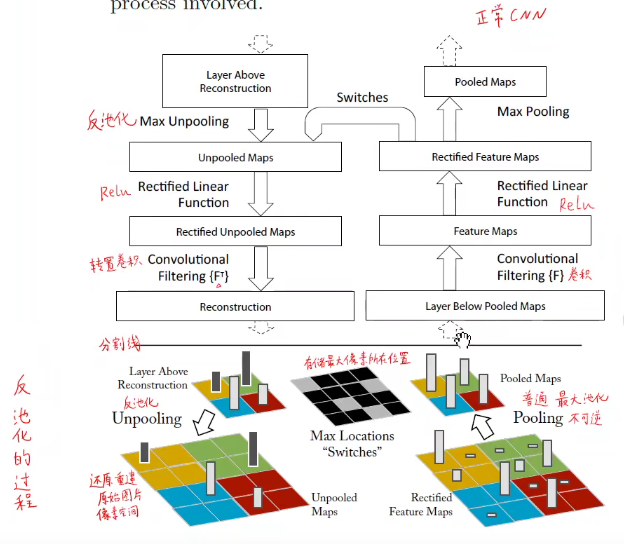
论文可参看《经典论文阅读》
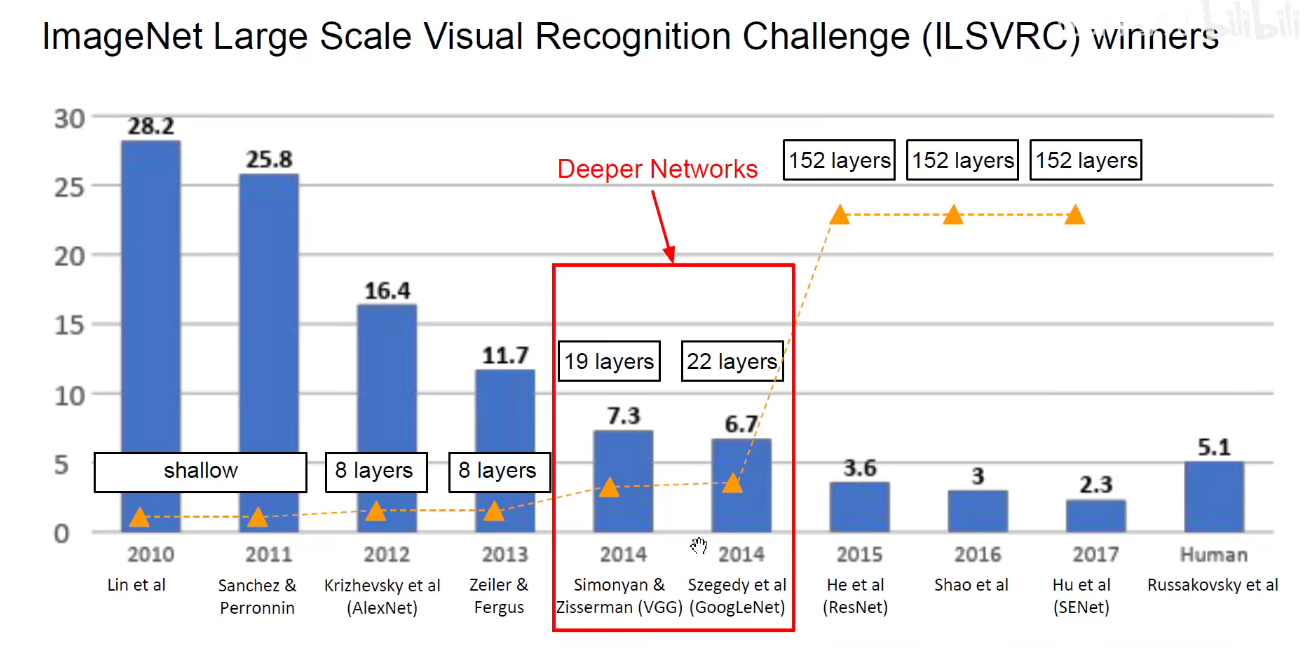
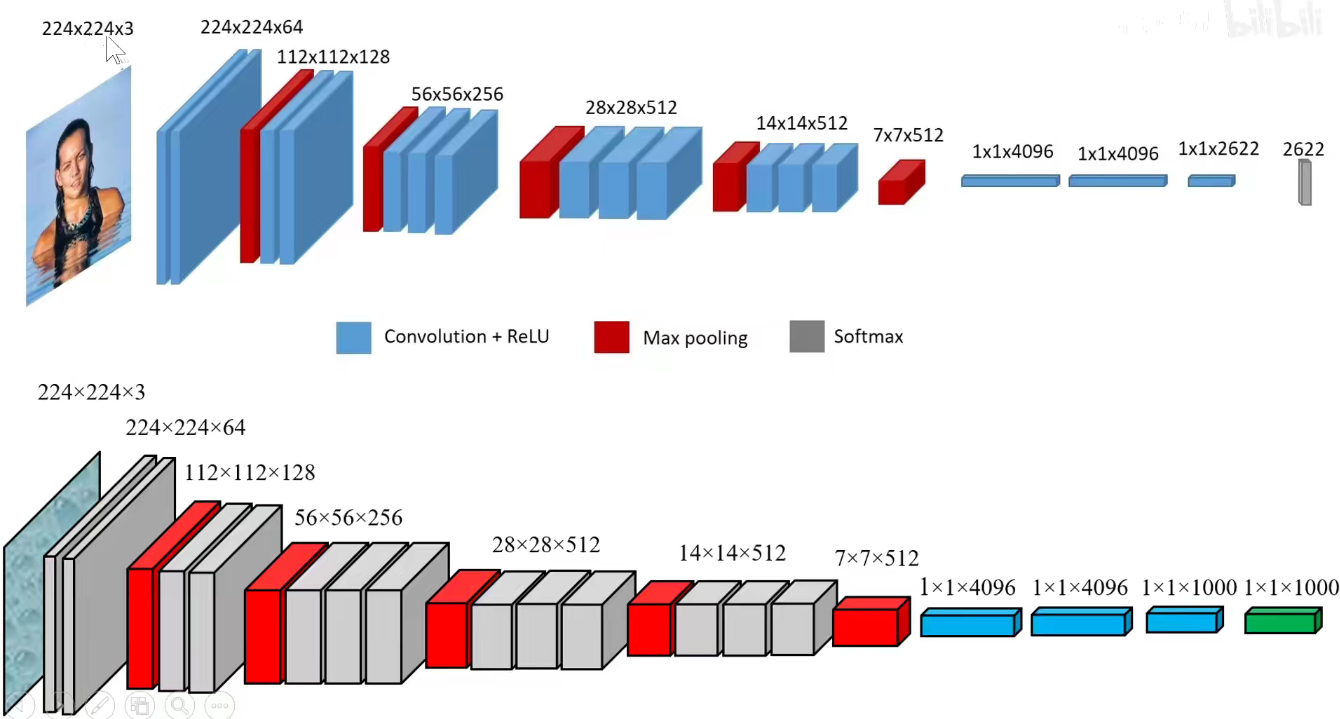
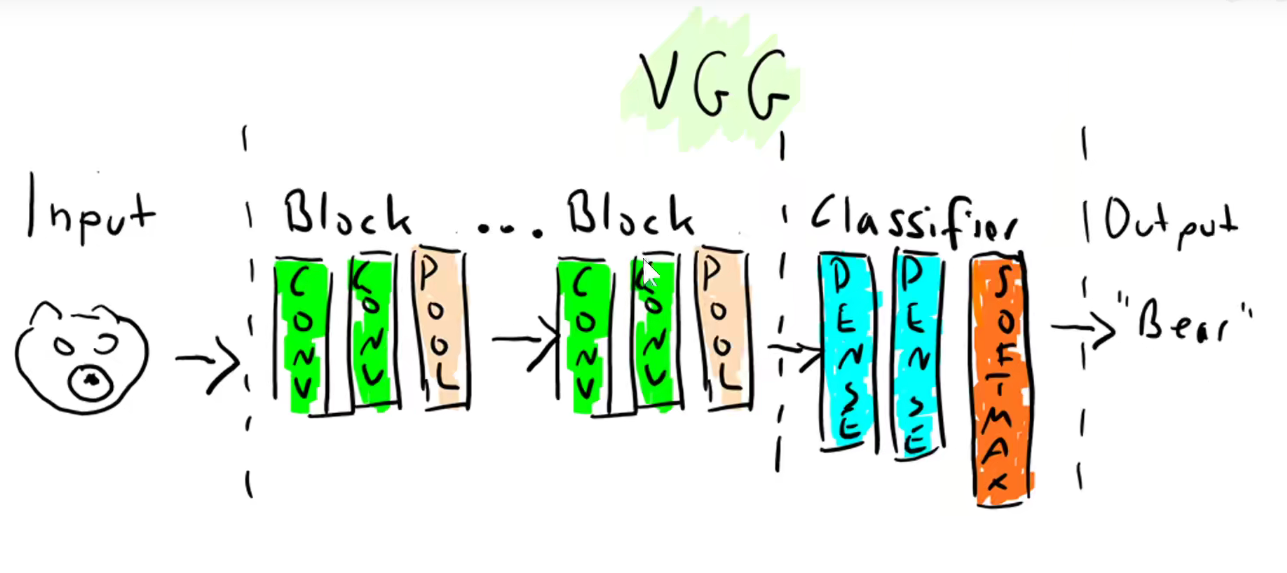
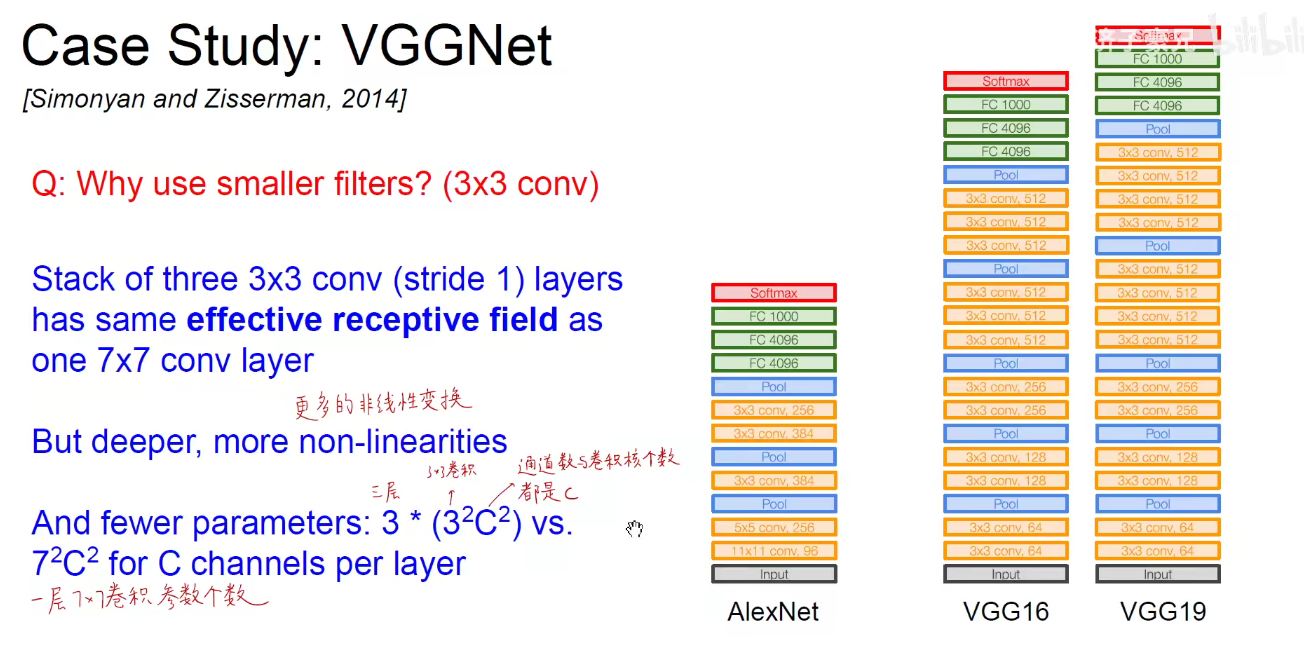
4. 2014-VGGNet
2014图像分类亚军,定位冠军。
论文名称:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
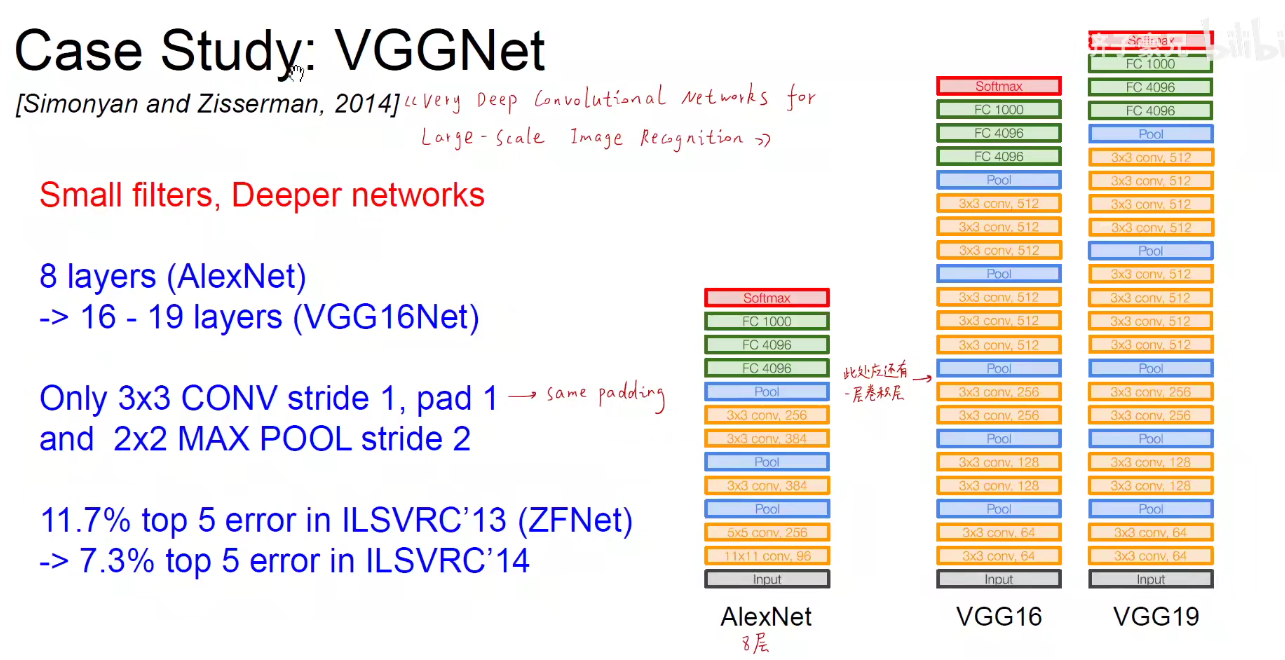

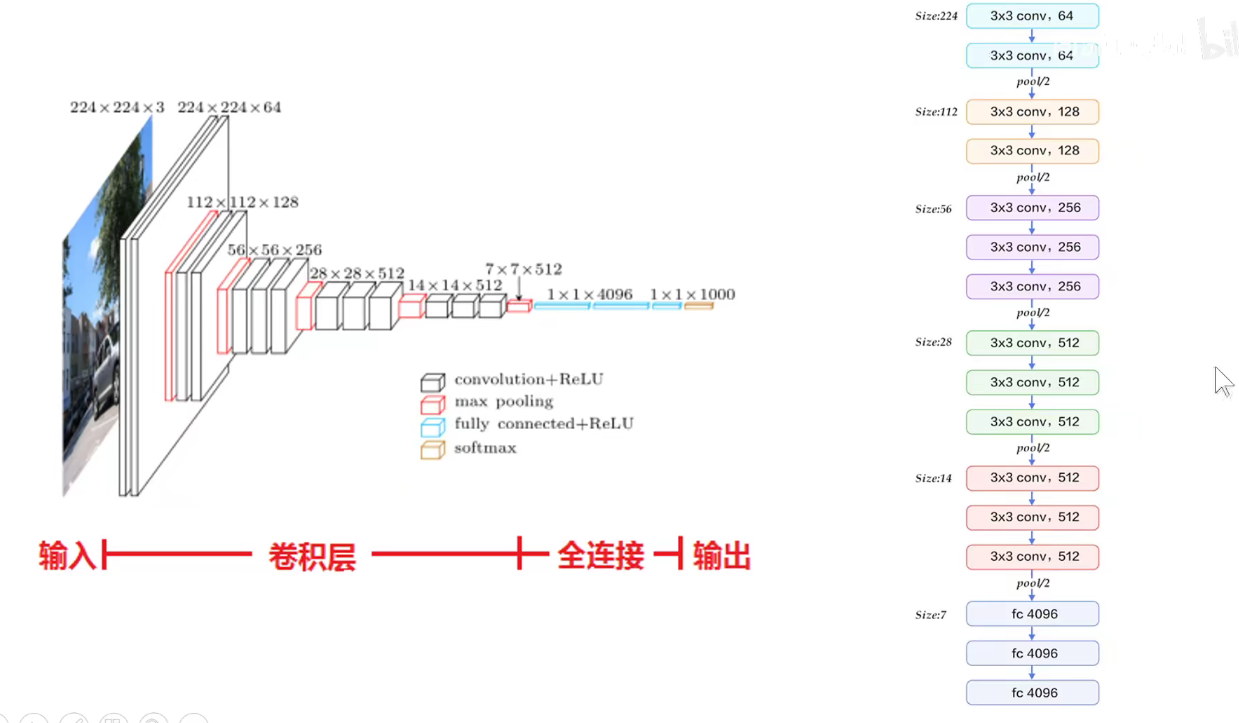
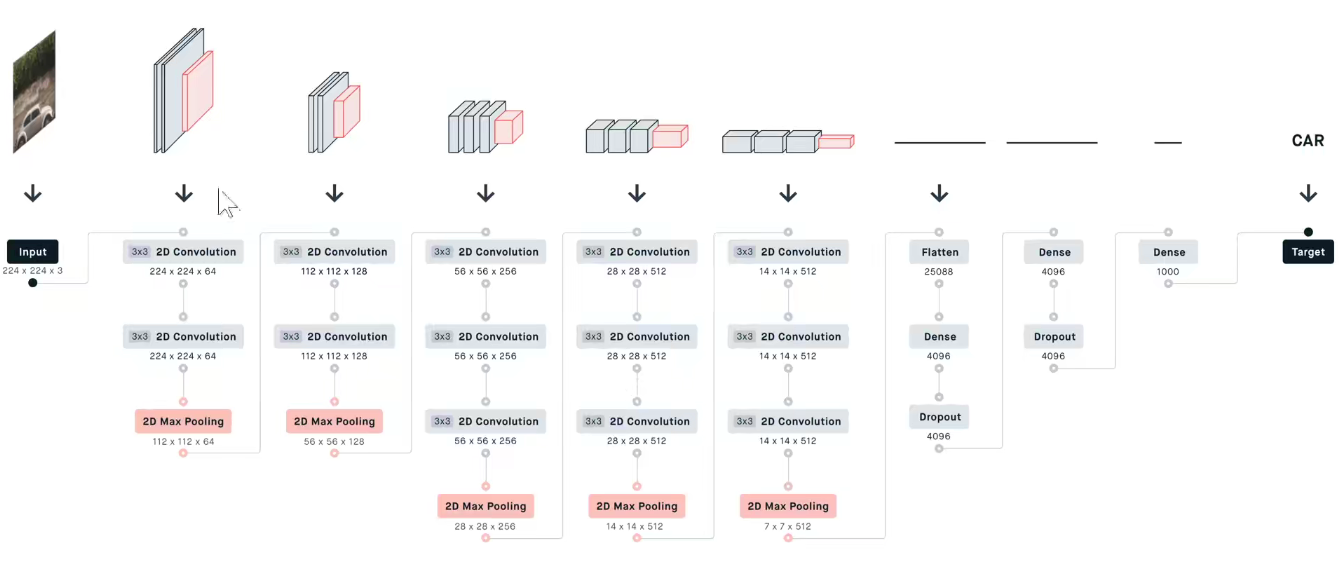
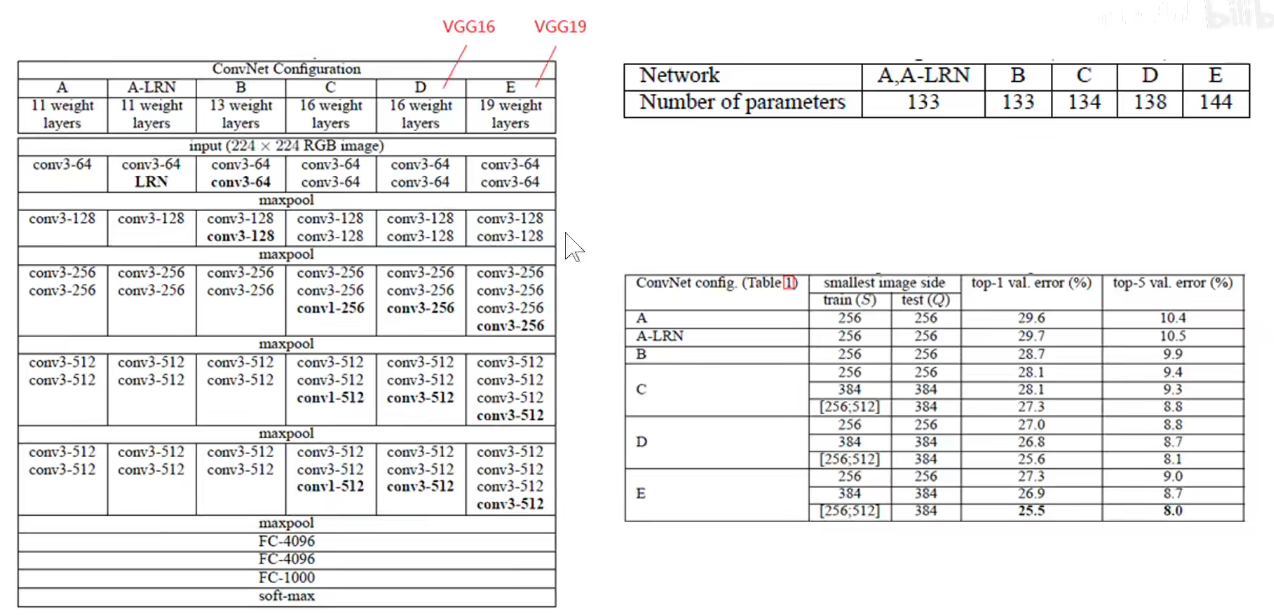
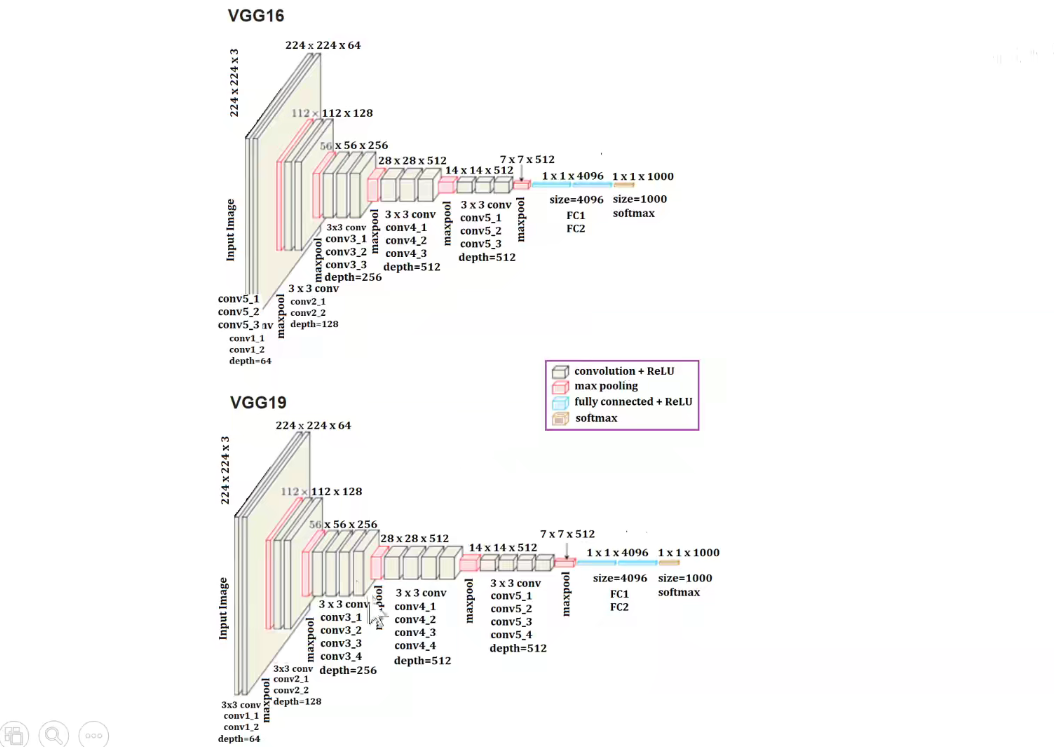
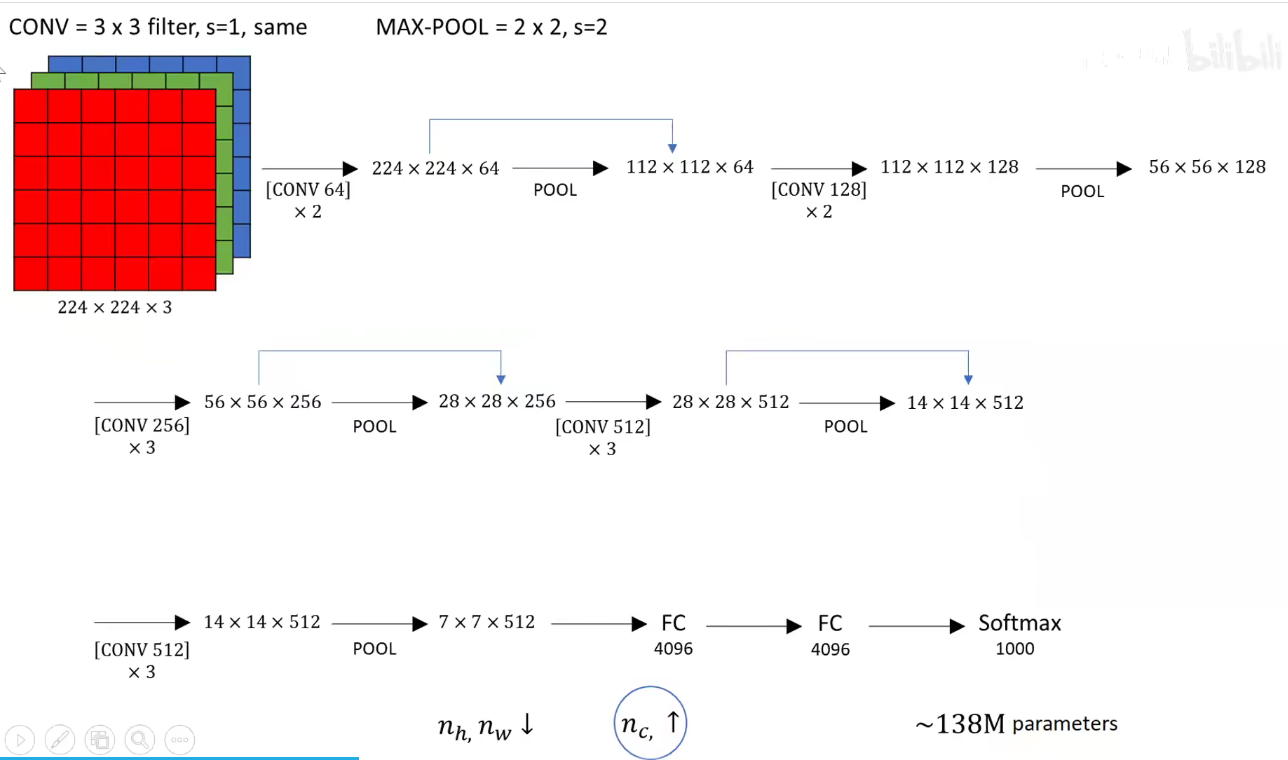
VGG16分为5个Block, 第一个和第二个Block分别有两个卷积层,后三层分别有3个卷积层。
VGG19分为5个Block,不同的是,后三层比VGG16多一层,即后三层分别有4个卷积层。



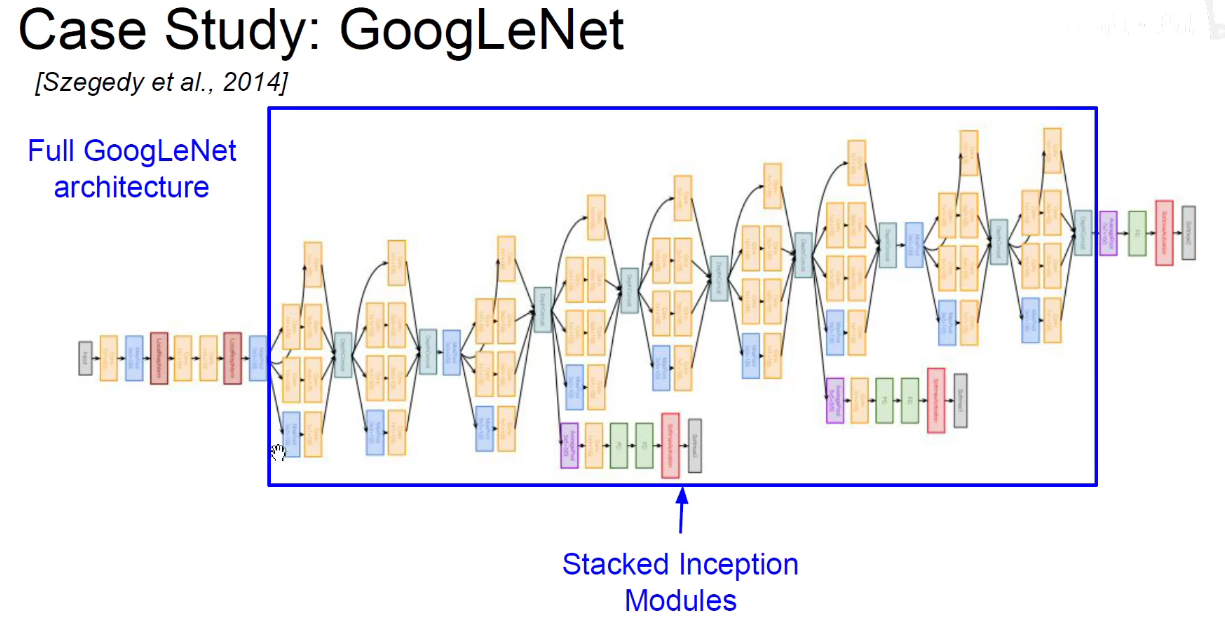
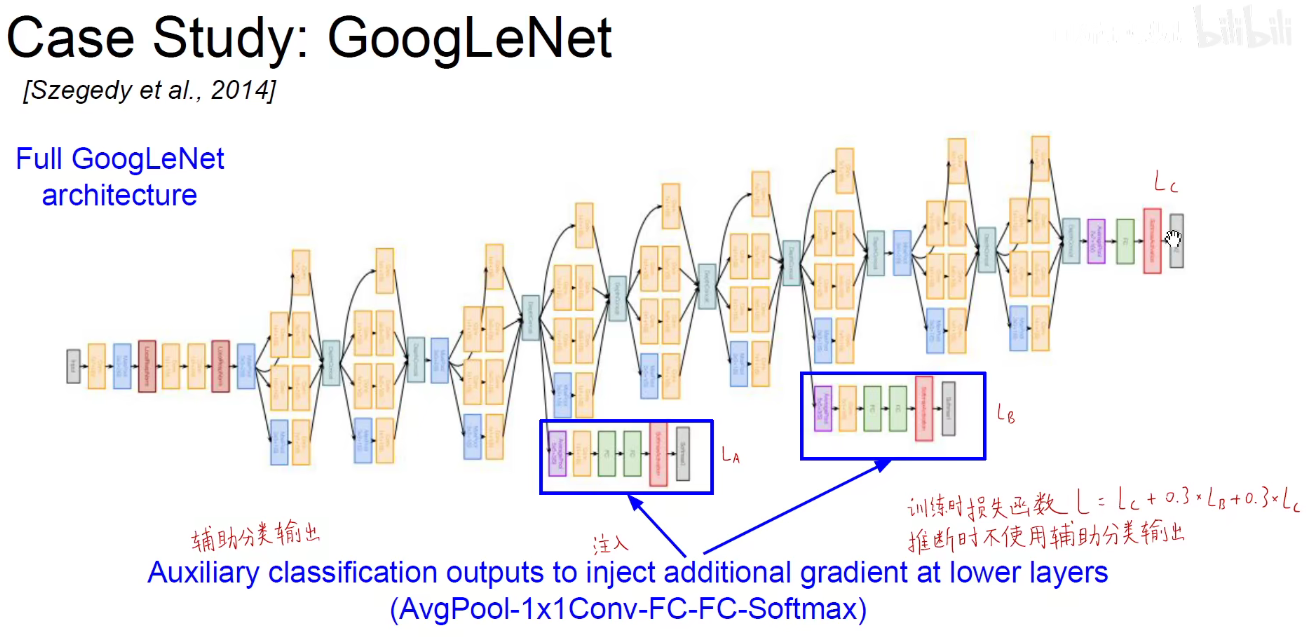
5. 2014-GoogLeNet
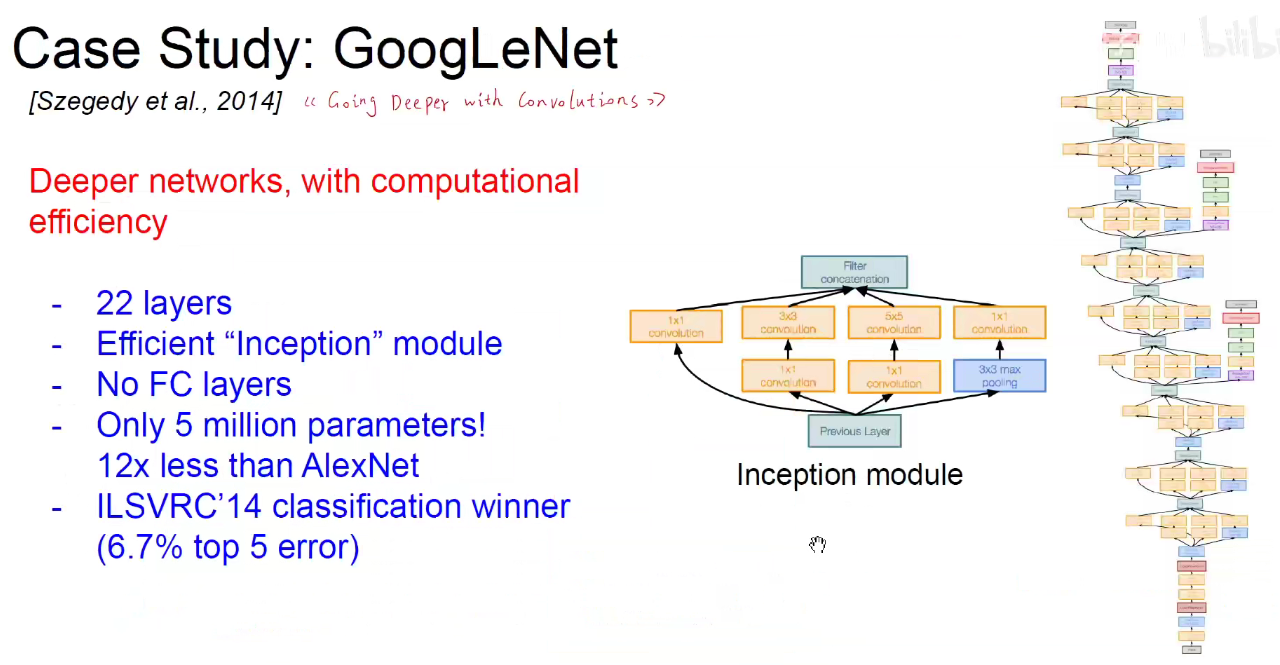
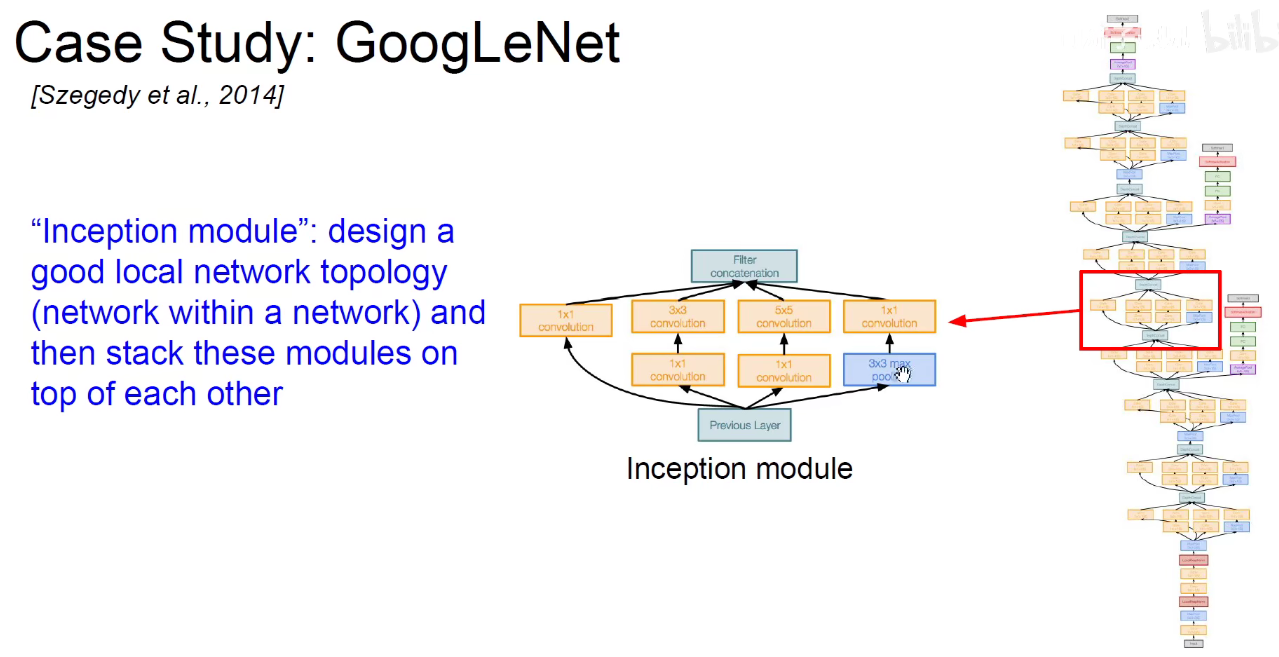
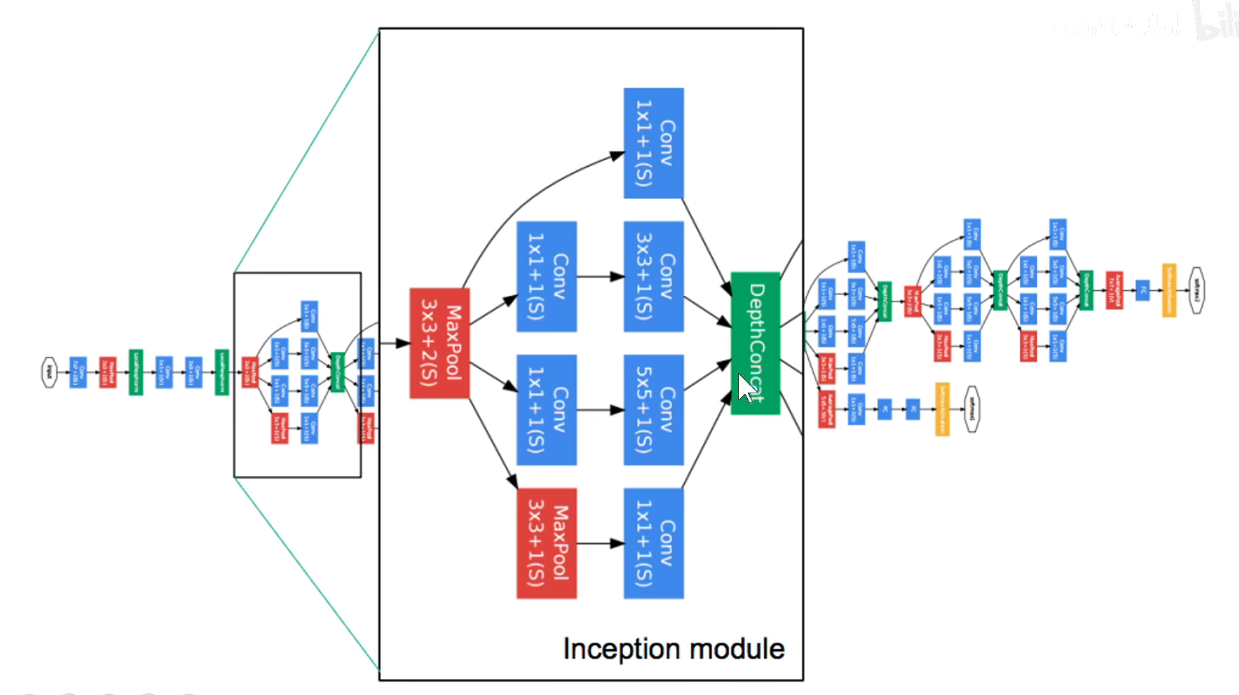
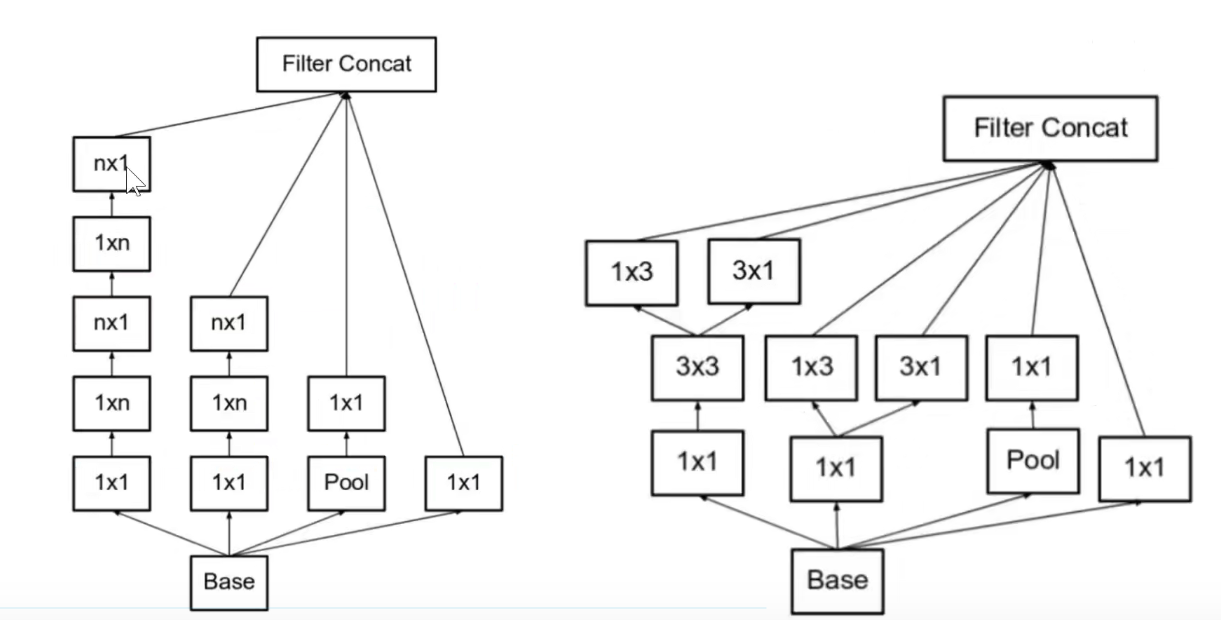
如下图:使用不同尺度的卷积核对前层进行卷积,再把卷积结果堆叠起来,传递给下一层。算无遗策,保证Same-Padding即可,可能不一样厚,但大小相同。
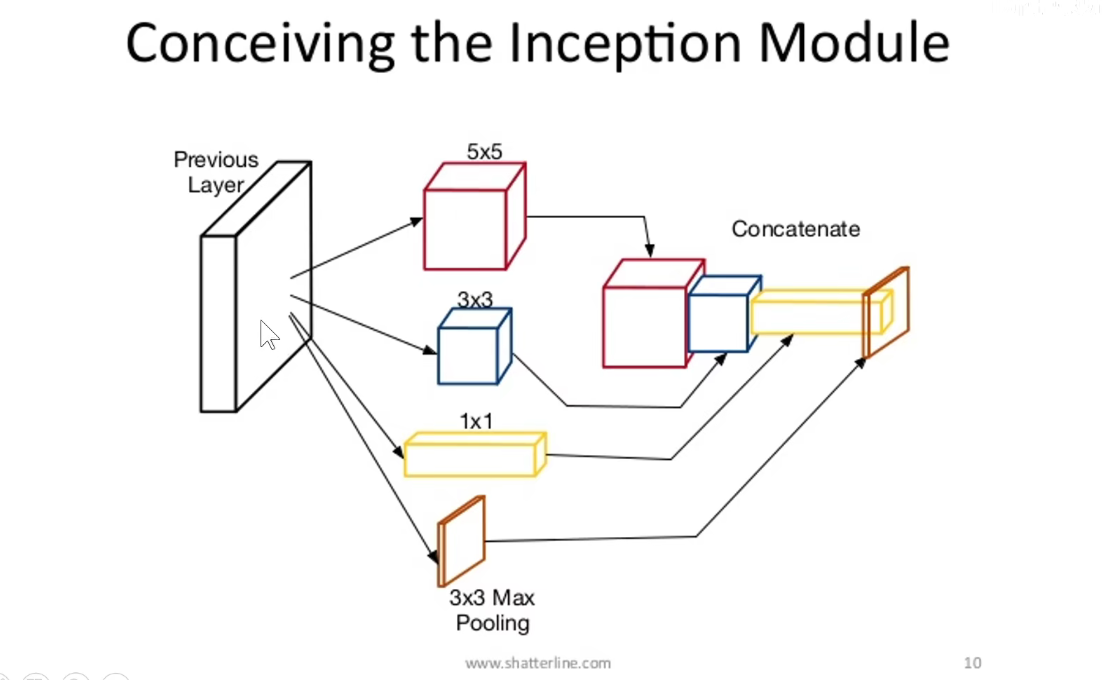
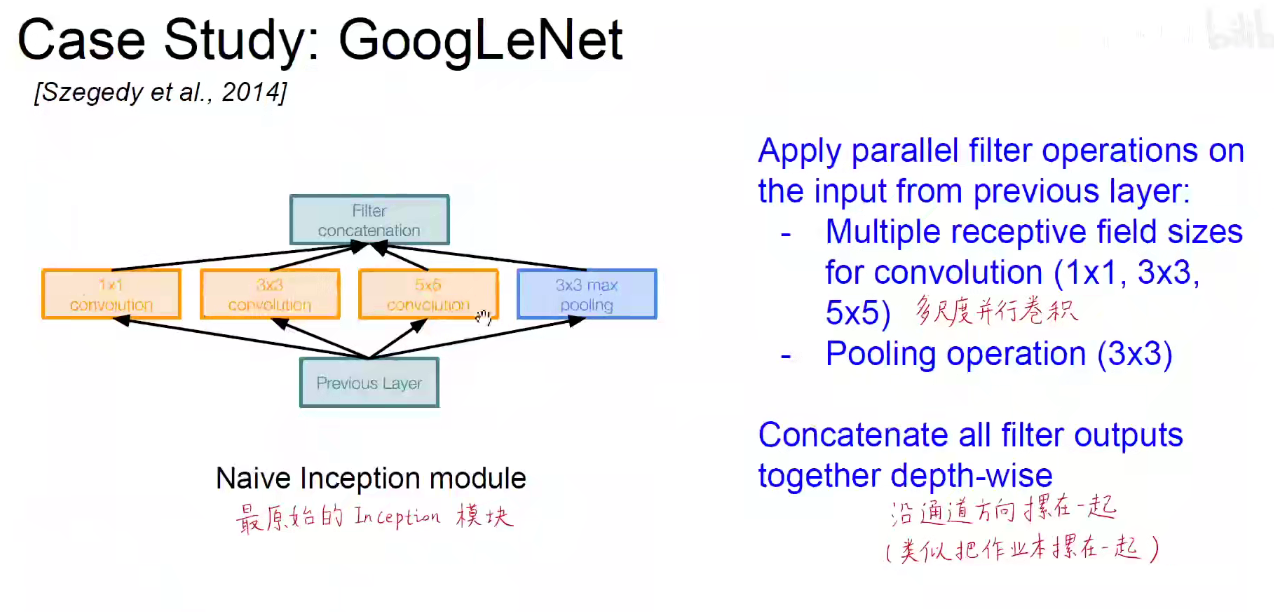
Naive问题:
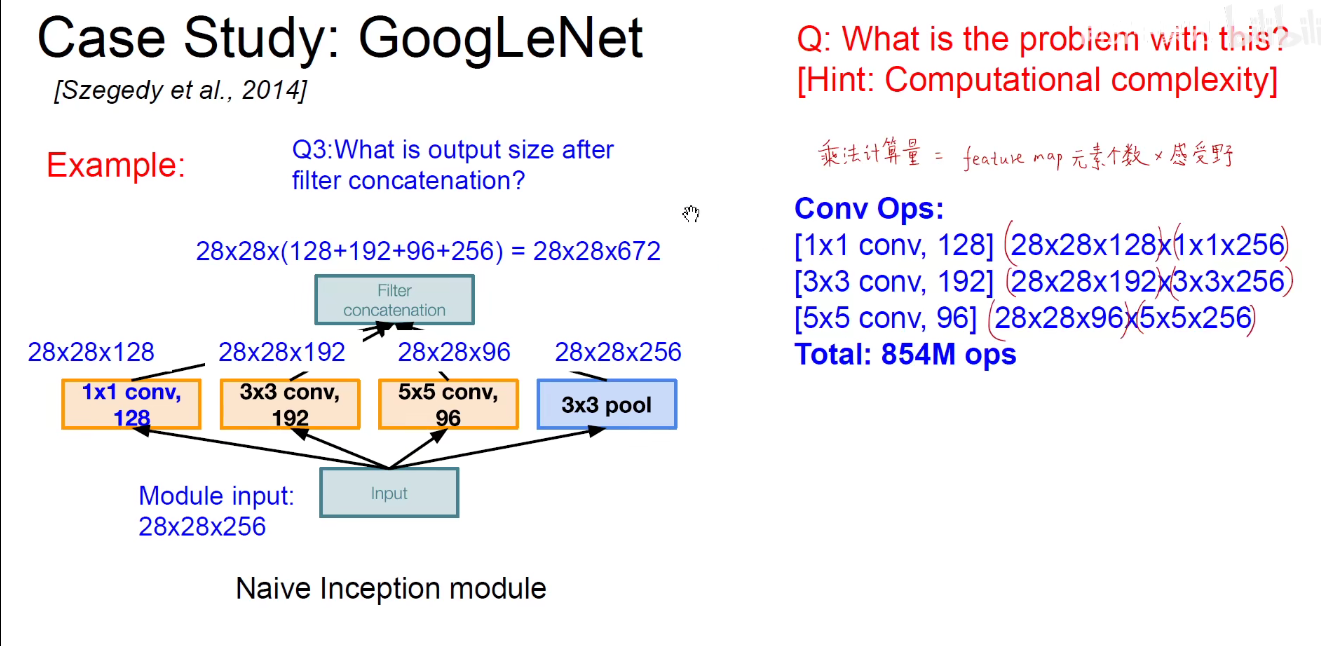
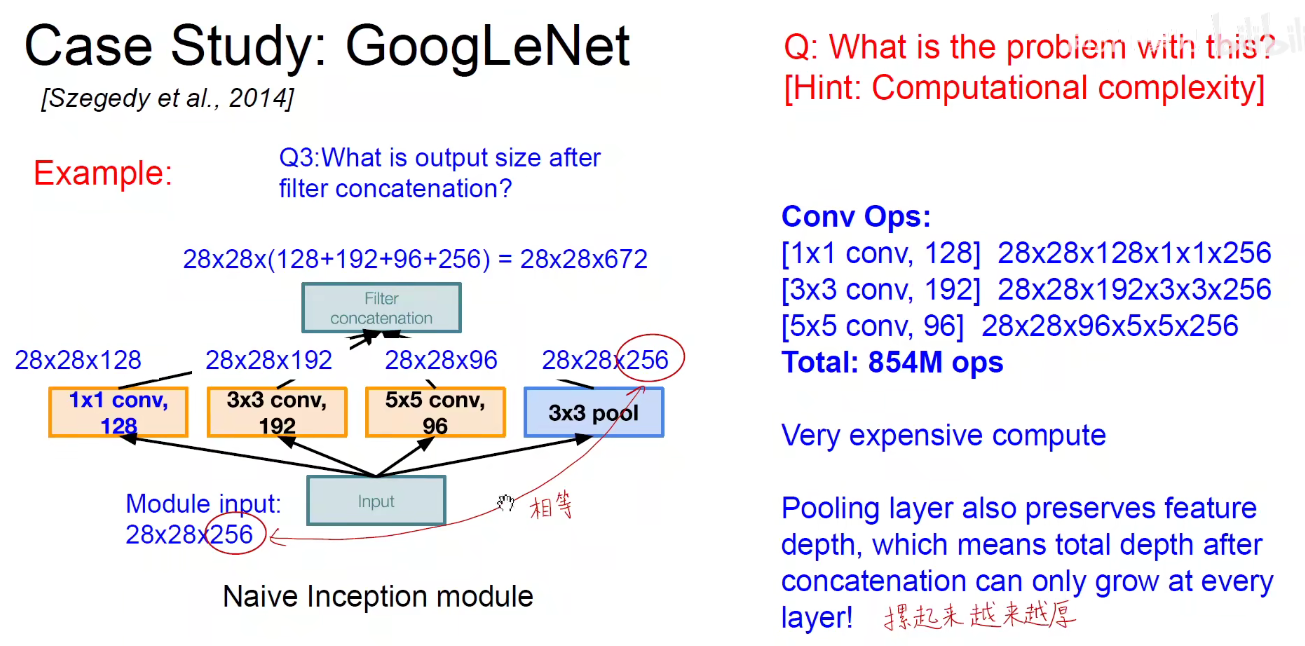
因为池化层不会改变通道数,所以摞起来后只会增加,不会减小。模型变得越来越臃肿。
为了解决上述问题,引入了1x1卷积
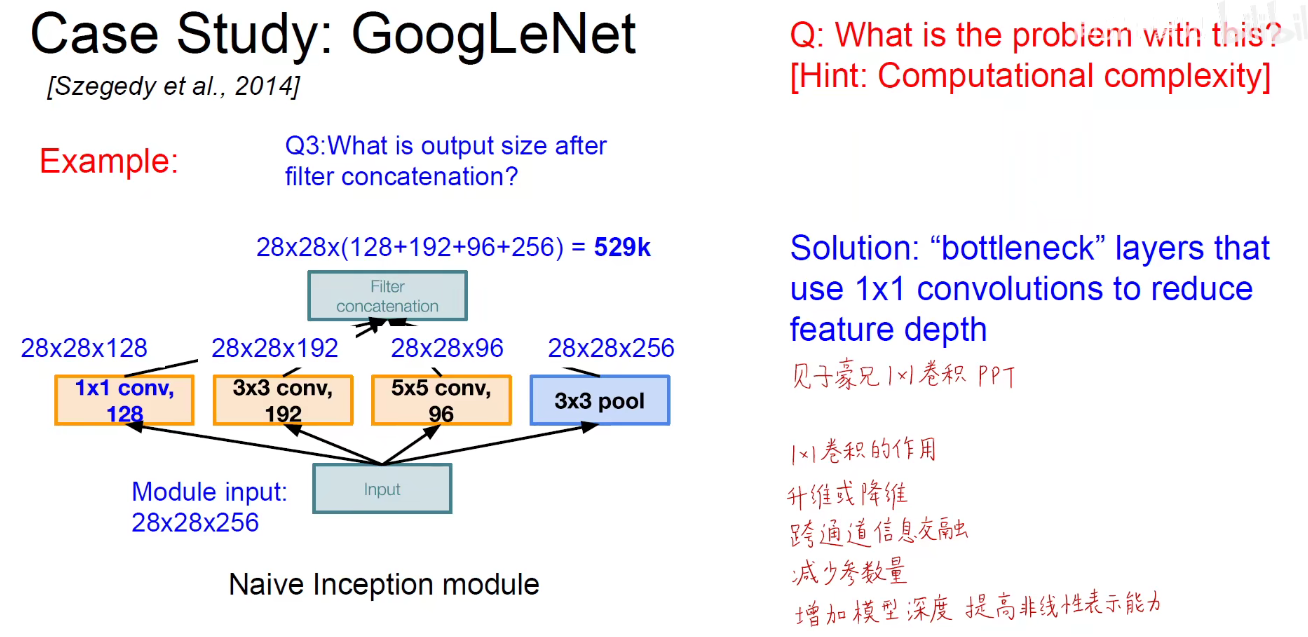
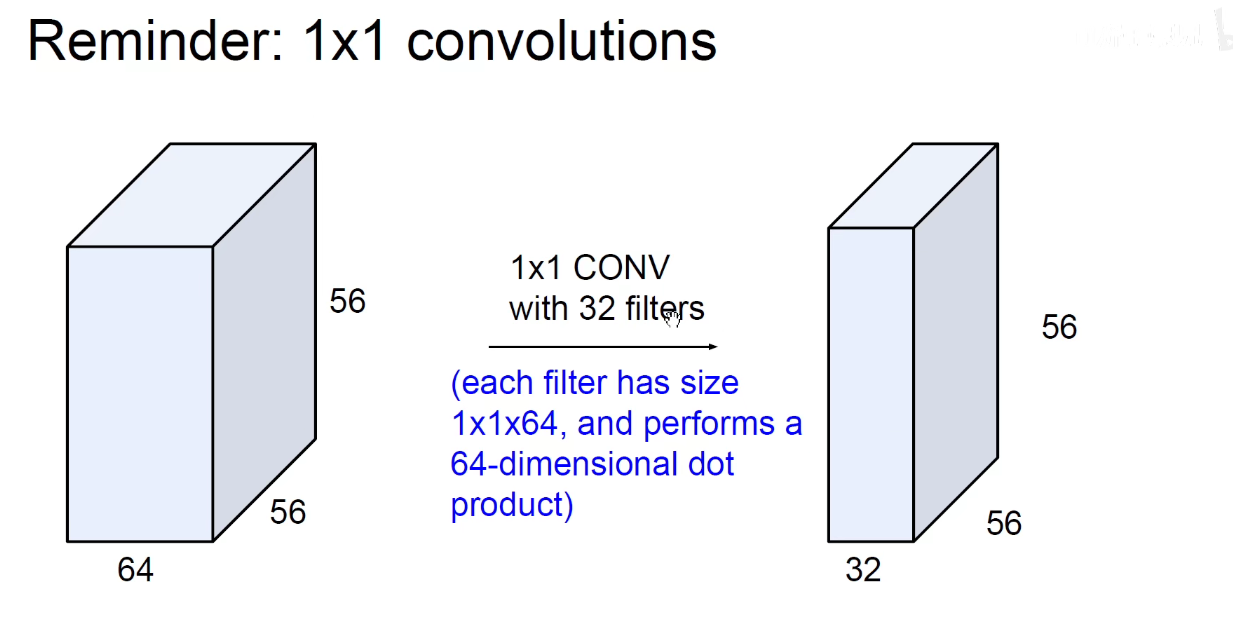
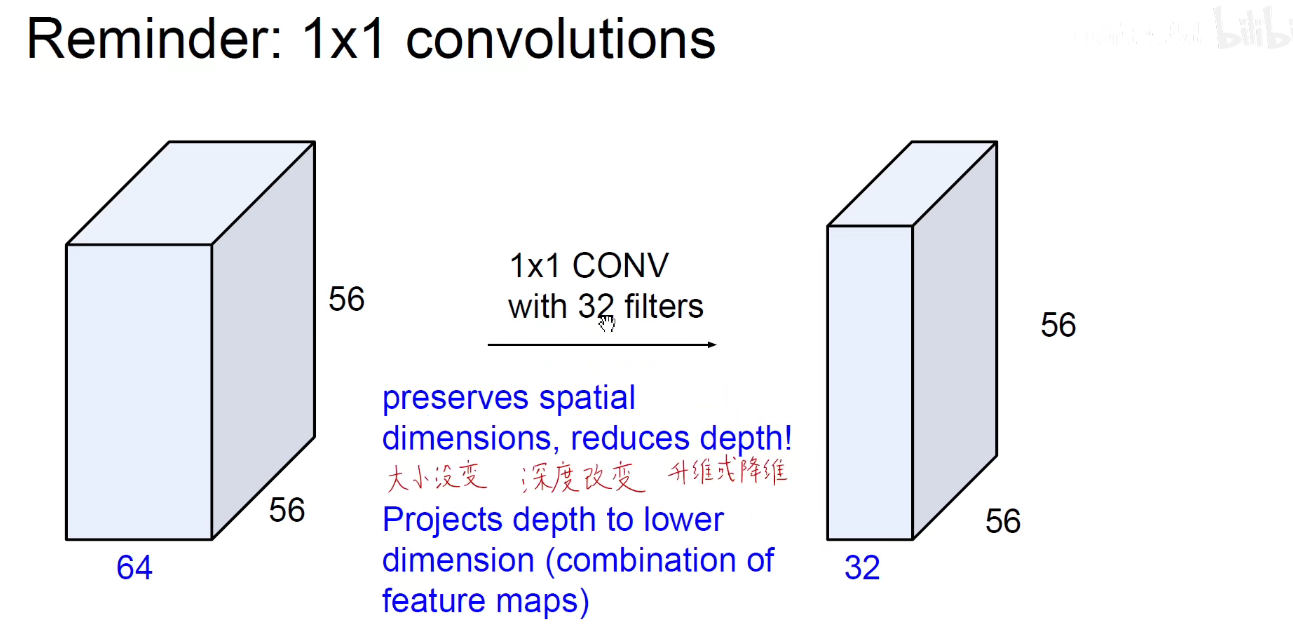
调整上述32这个数,就可以进行升维或者降维。
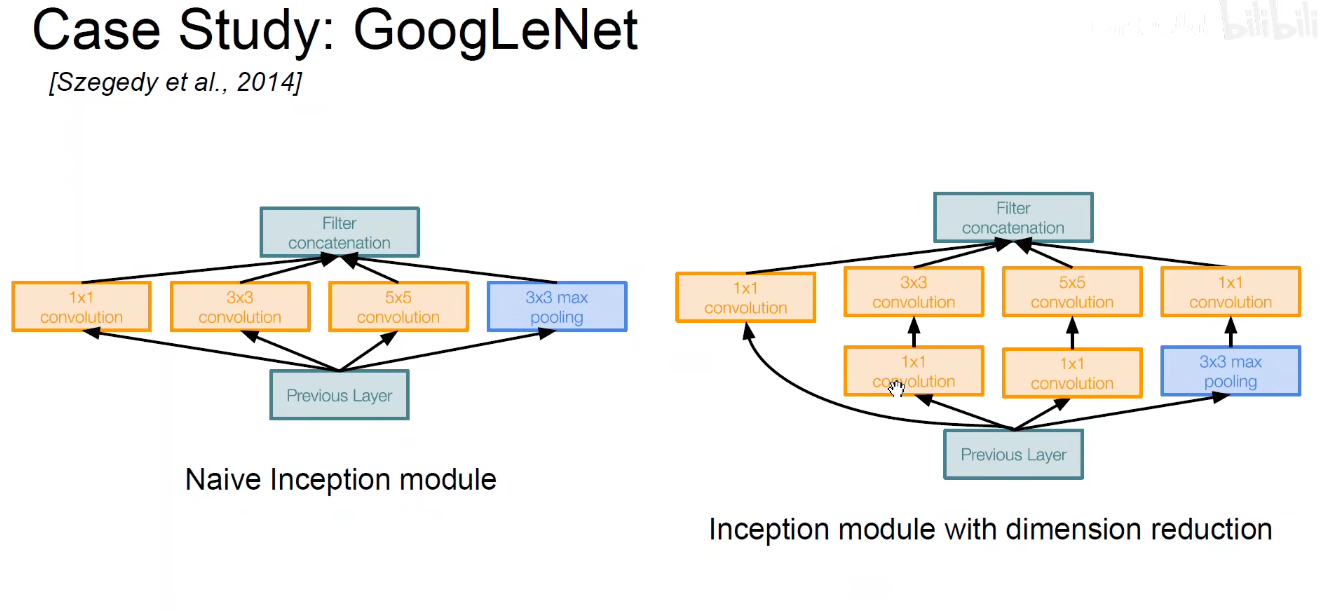
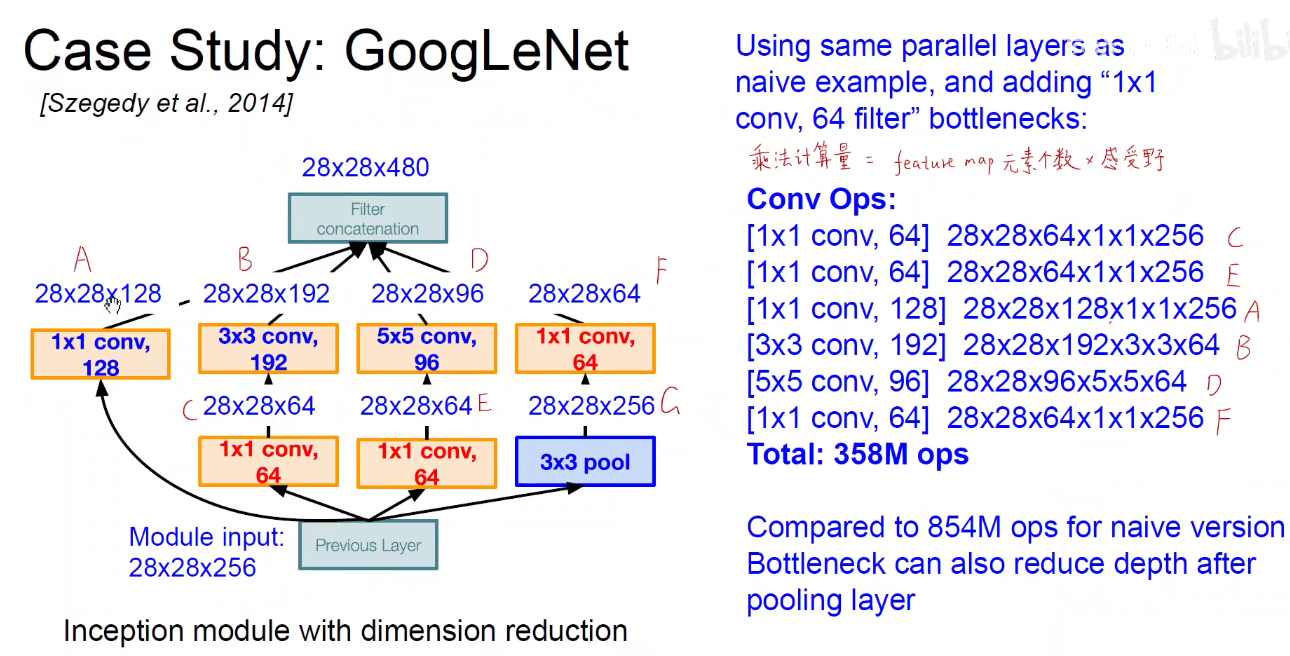
上述 C/E/F都是降维,将256降到64
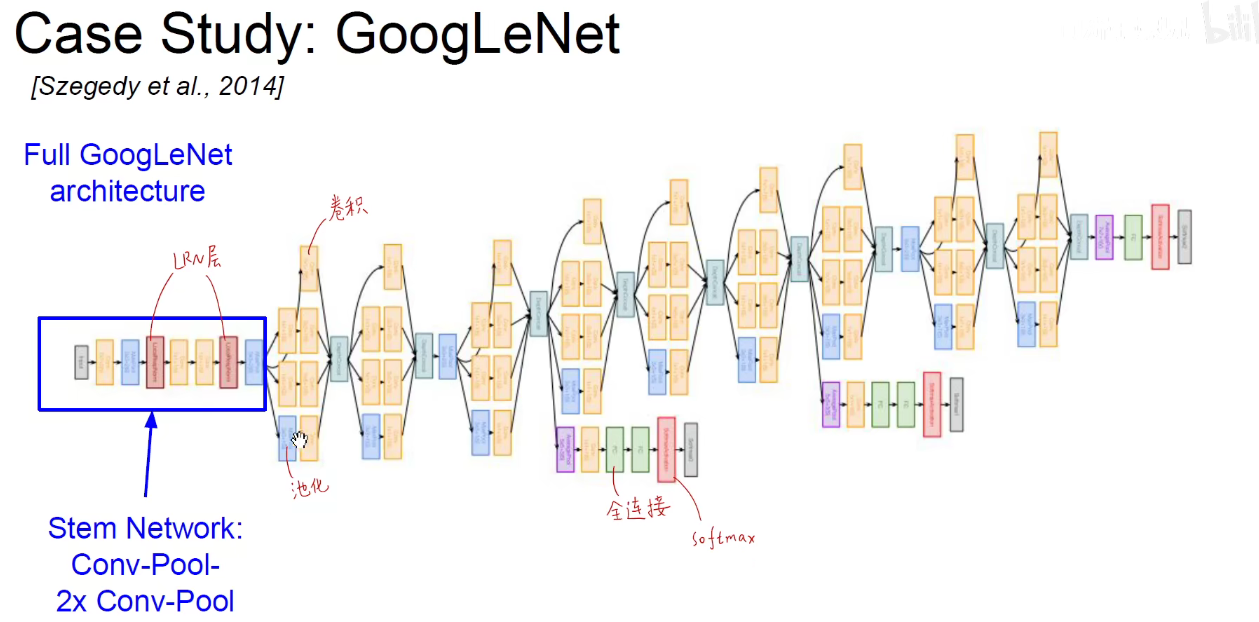
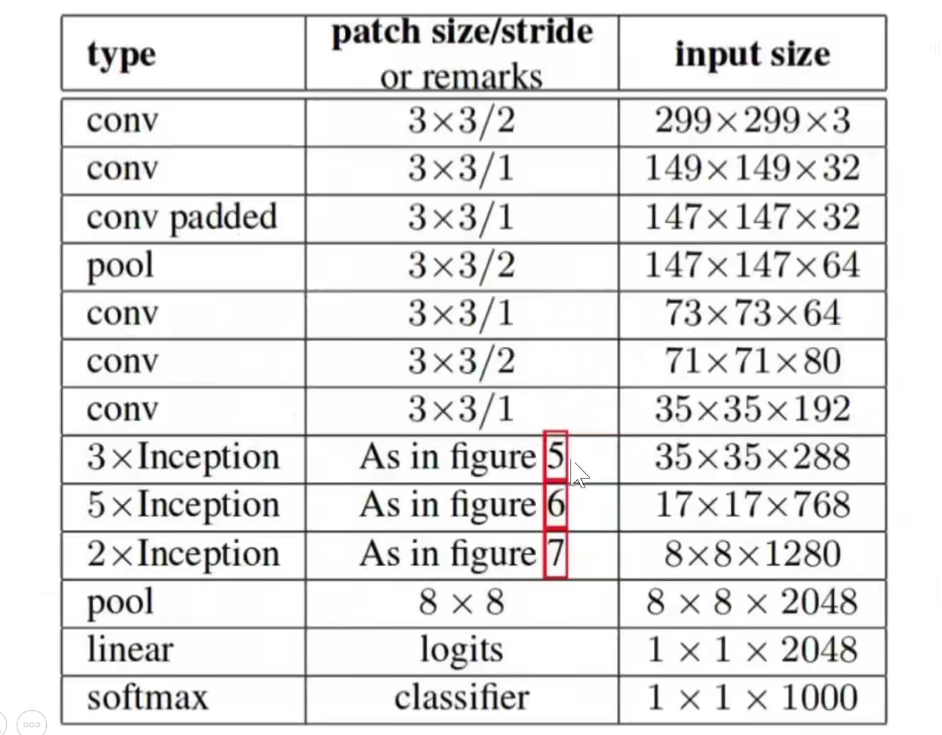
如上图,再开始阶段仍然是使用传统的CNN进行余预处理。
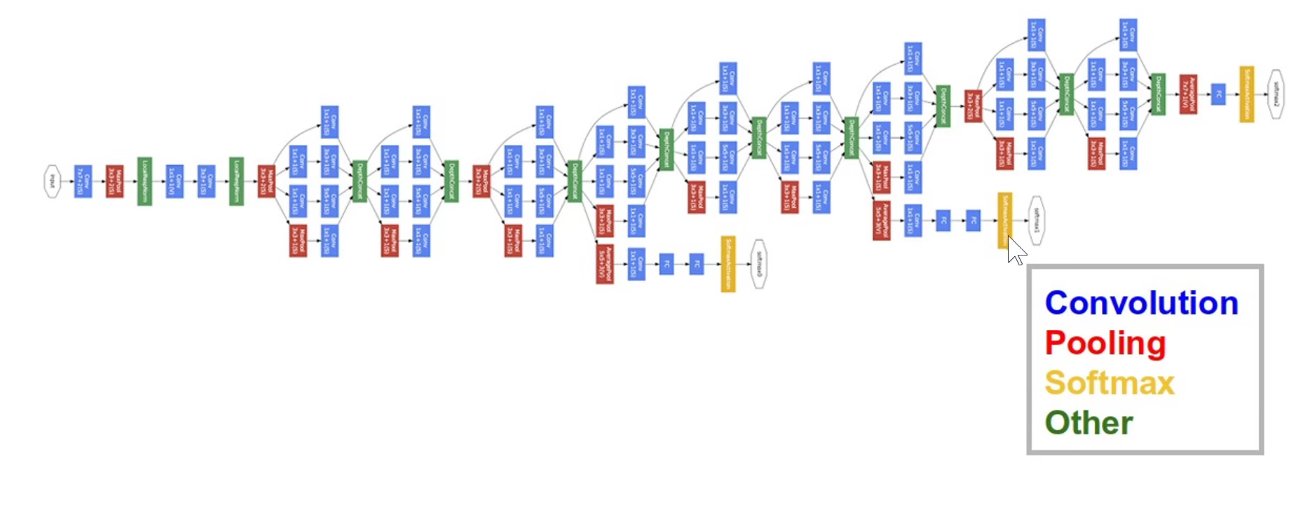
上图是模型骨干部分。
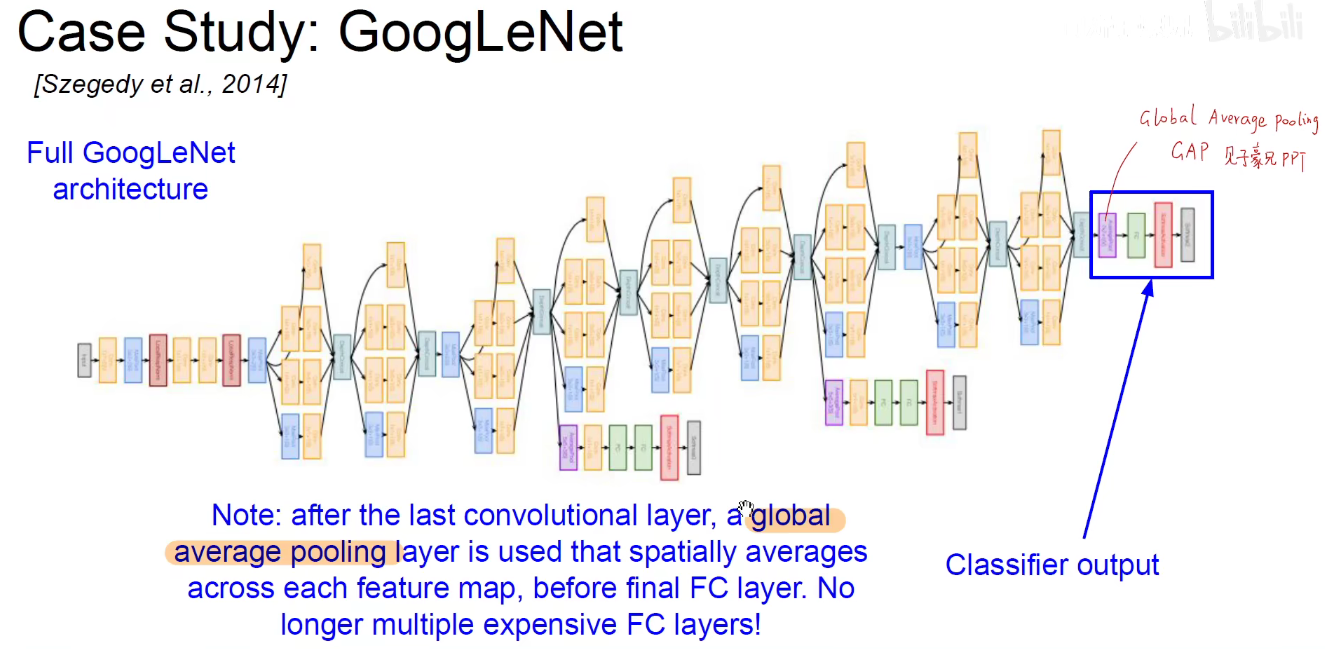
最后是一个分类的输出。
GAP:feature-map每一个通道求平均,不用把feature-map拉平成一个长向量,直接从每个通道中选一个代表出来,有效减少参数数量。
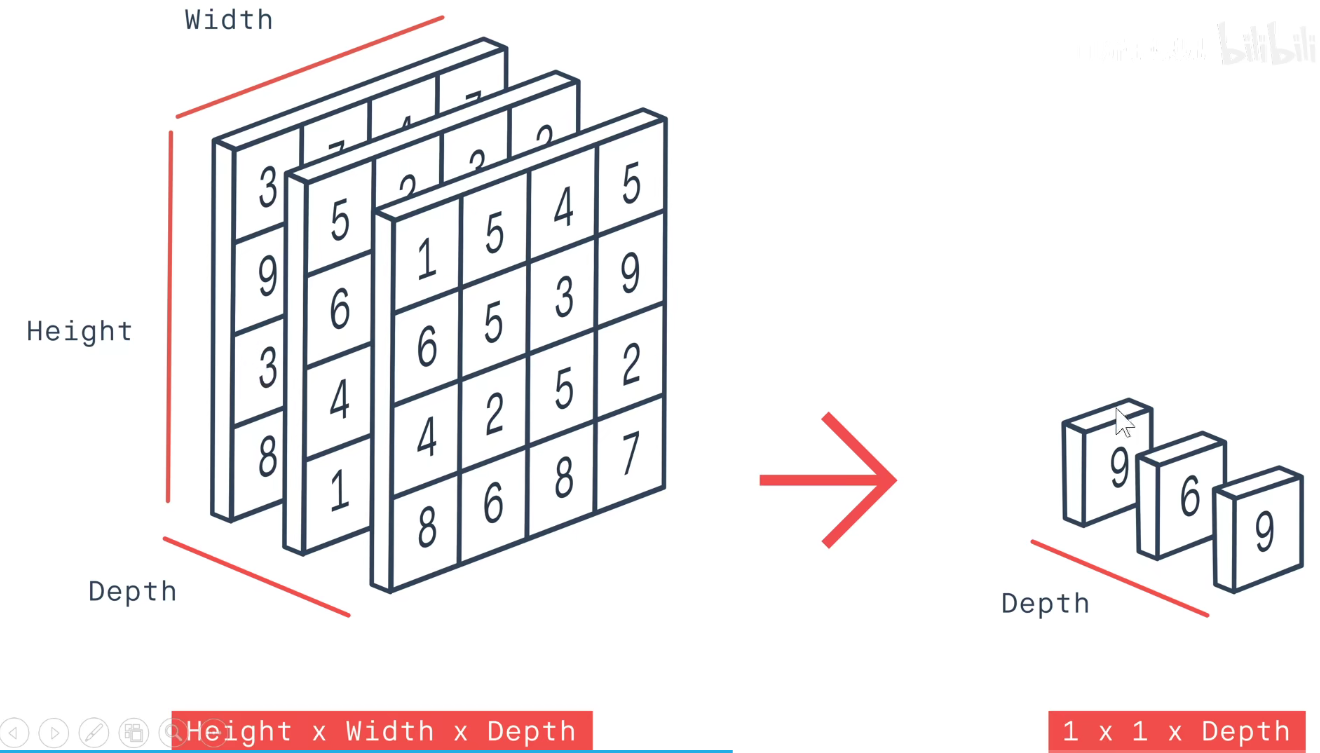
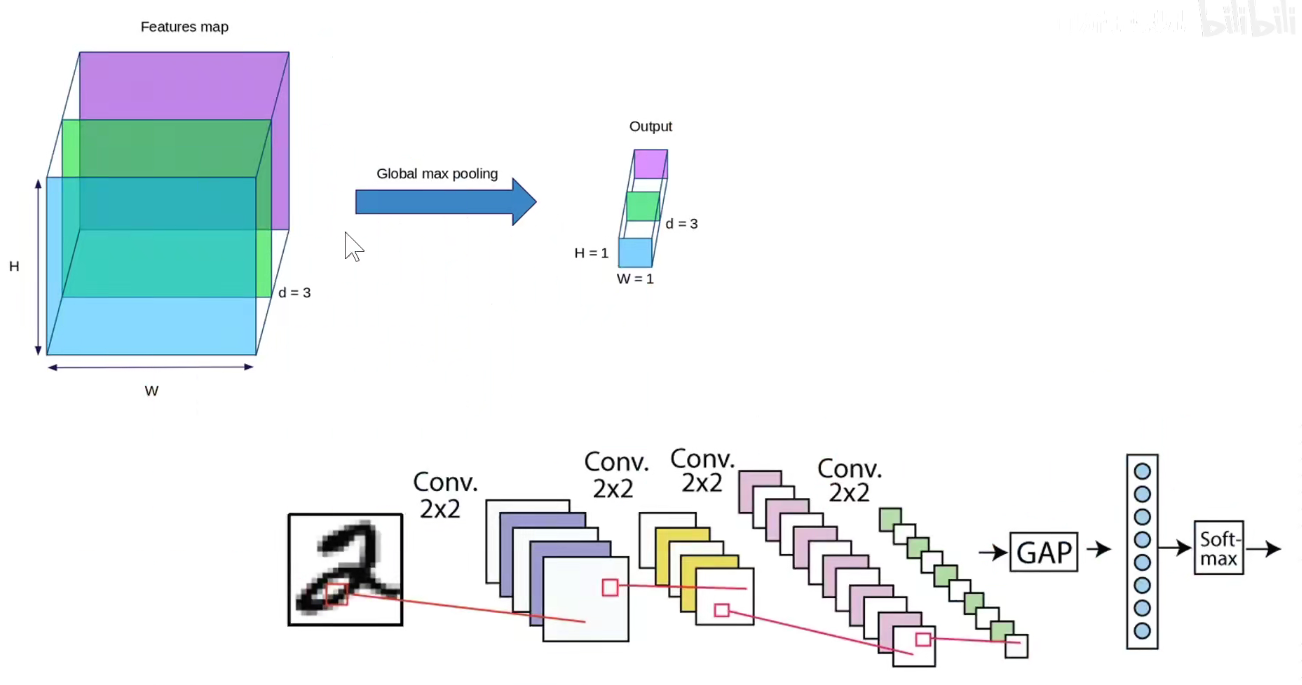
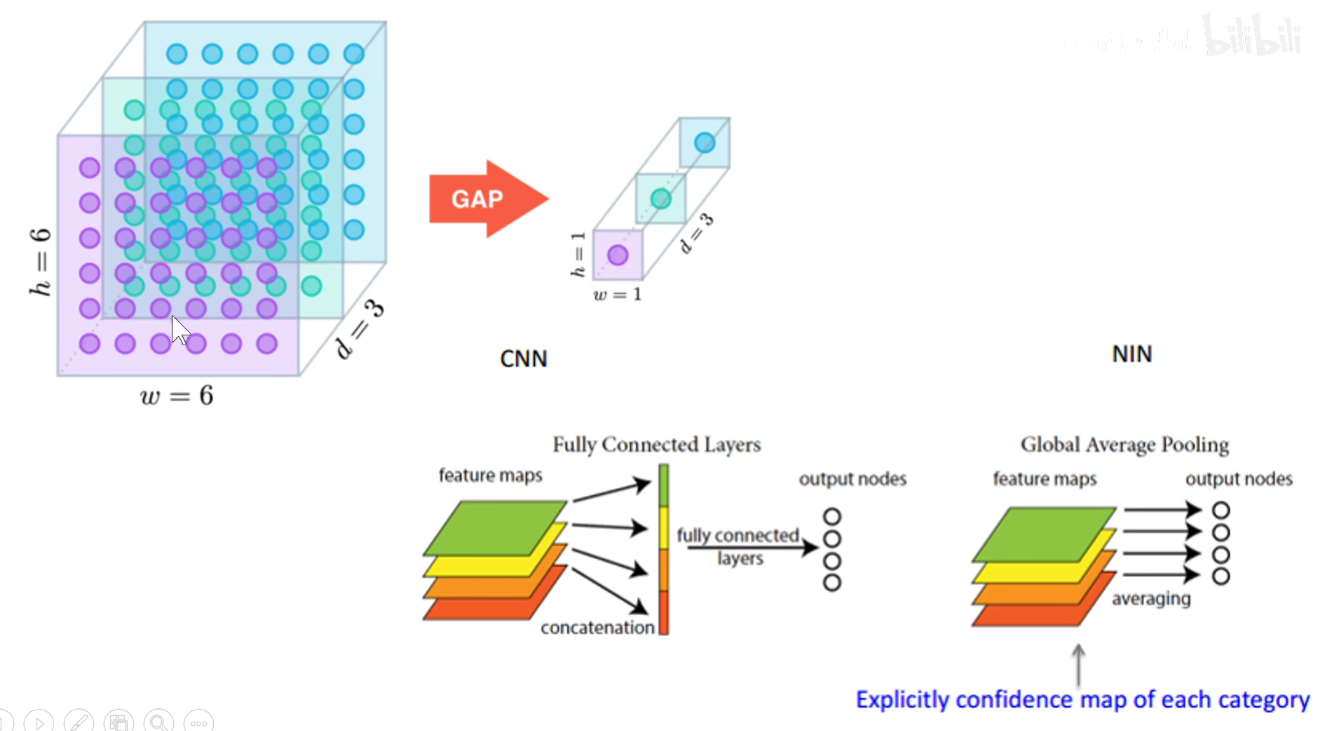
每个通道单独选一个代表出来。
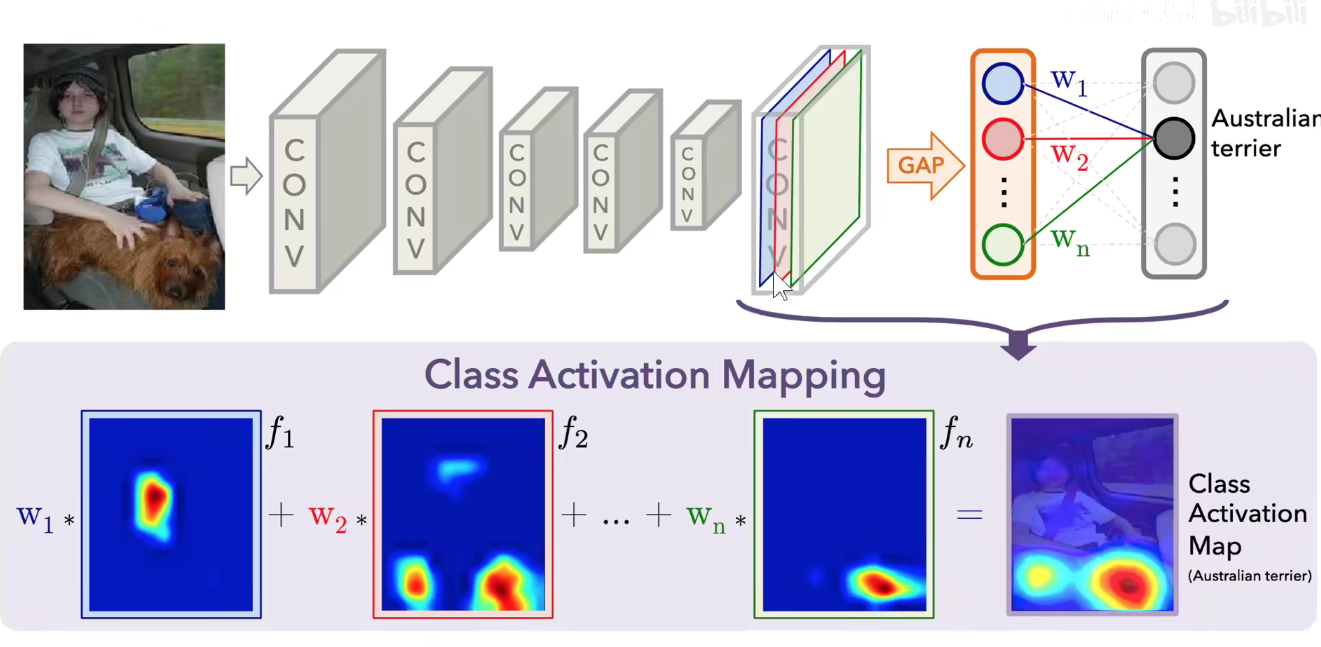
GAP作用有很多,如上图,每一个通道的代表选出来,直接加一个分类层,权重就反应了这个类别对蓝色feature-map通道的关注程度。把每一个feature-map通道值乘以他自己所在通道的关注程度可以生成这样的Class Activation Map。
可以反映神经网络关注图像中那一部分区域。如果是猫的类别,就会关注猫区域,狗的类别就会关注狗所在区域。
用图像分类的标签就可以进行物体的定位甚至是语义分割。这称为弱监督学习/半监督学习。
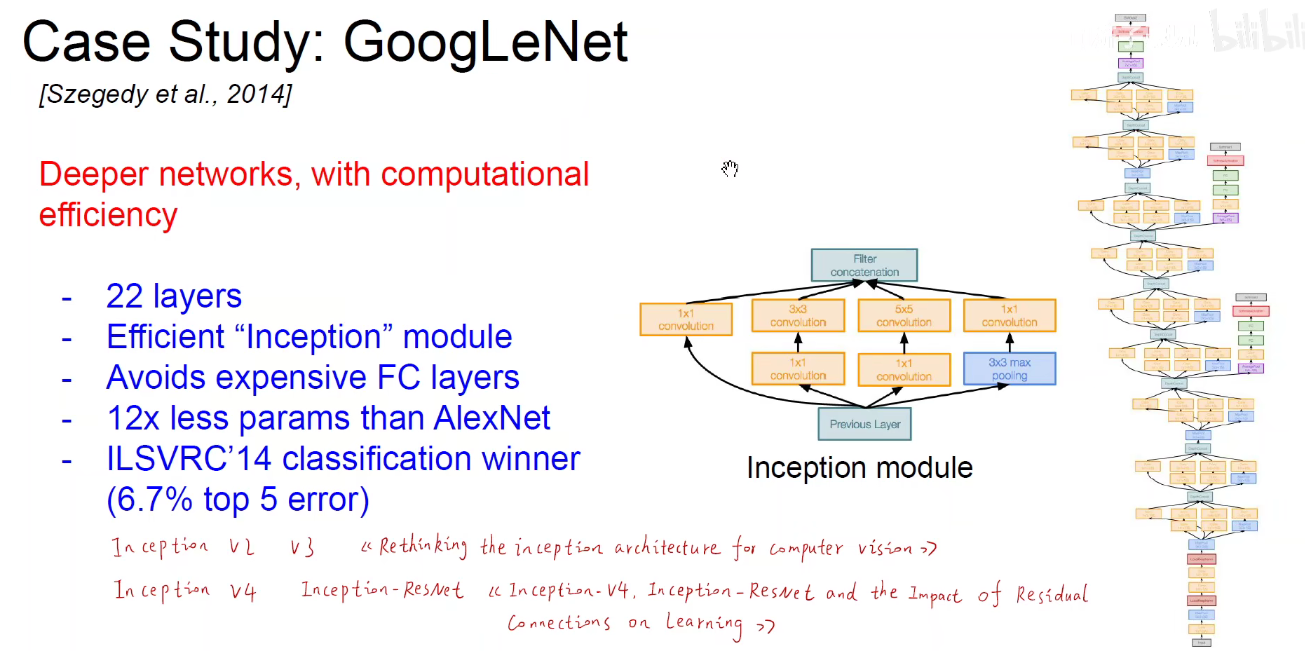
Inception-V2: 2个3x3卷积代替1个5x5卷积,3x3卷积本身也可以变成1x3和3x1的卷积,既可以沿着深度展开,也可以沿着宽度展开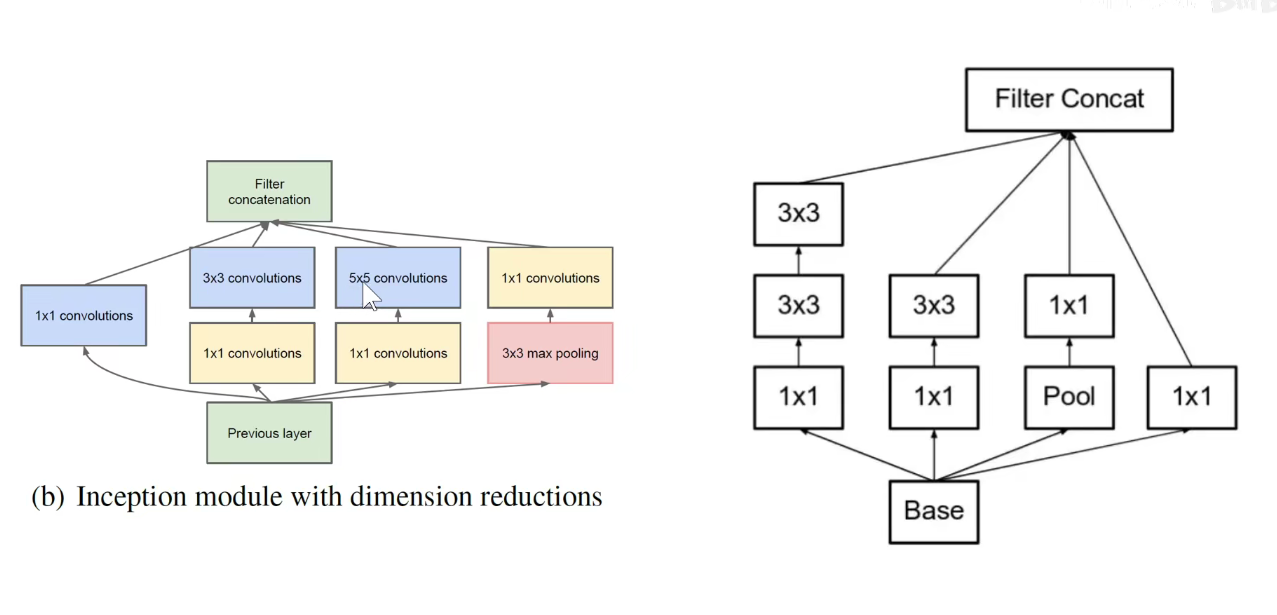
6. 2015-ResNet
神仙打架-群星闪烁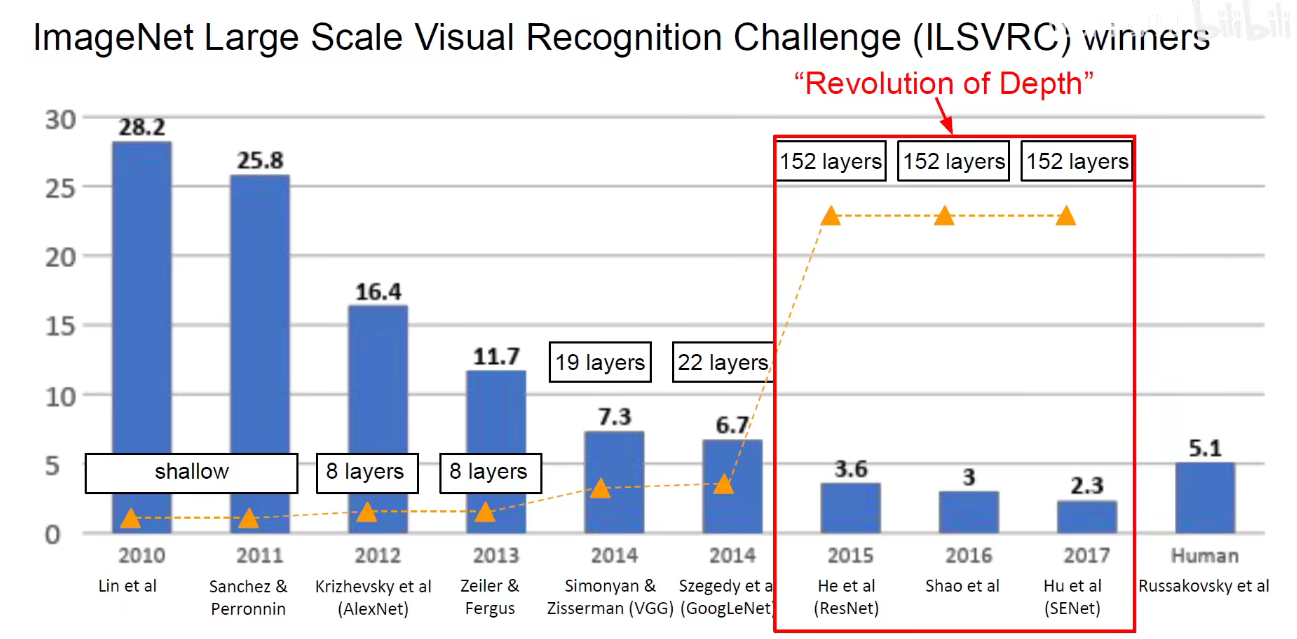
百度也参加了并取得了很不错的结果,但因为百度注册了很多账号,多次提交结果,被判违规,各种外媒跟风的带节奏,煽动,最后百度不得不道歉并退出了这一年的竞赛。
微软亚洲研究院-何凯明-ResNet(深度残差网络)
何凯明-2003年广东省理科高考状元-清华-微软亚洲研究院-FaceBook,当年提出这个模型时,是在孙剑课题组中,孙健也是一个传奇人物,旷世研究院创始人,即Face++。
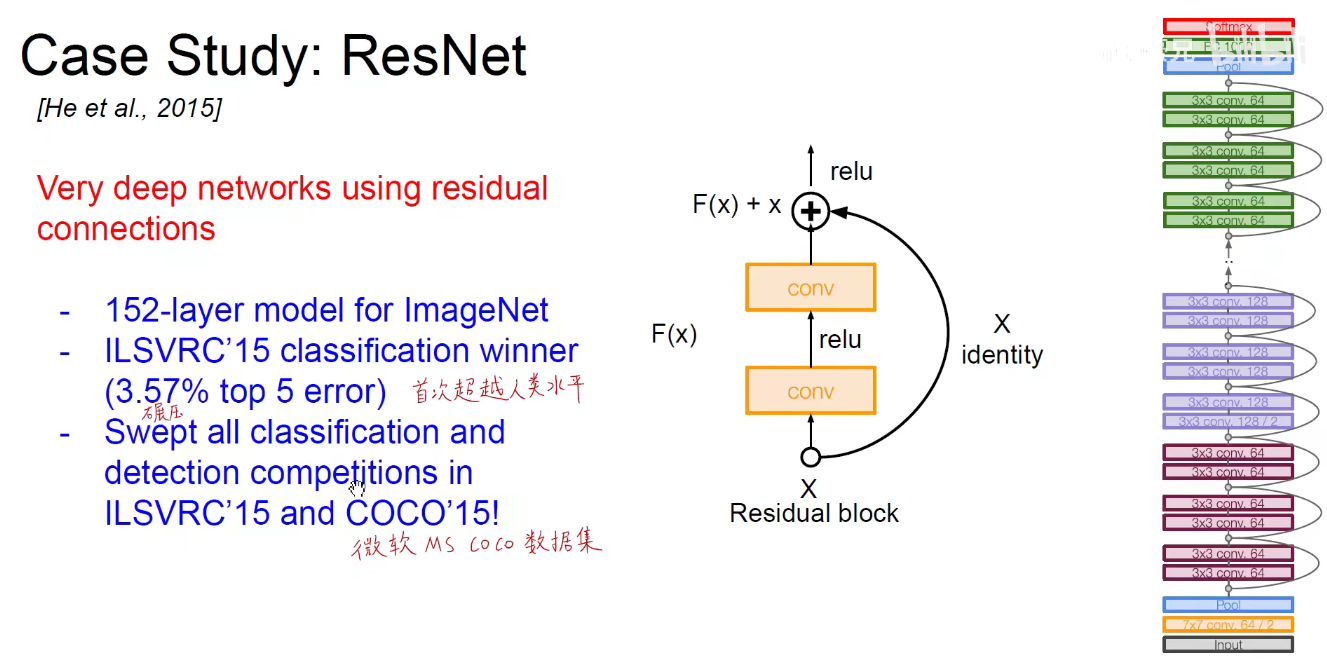
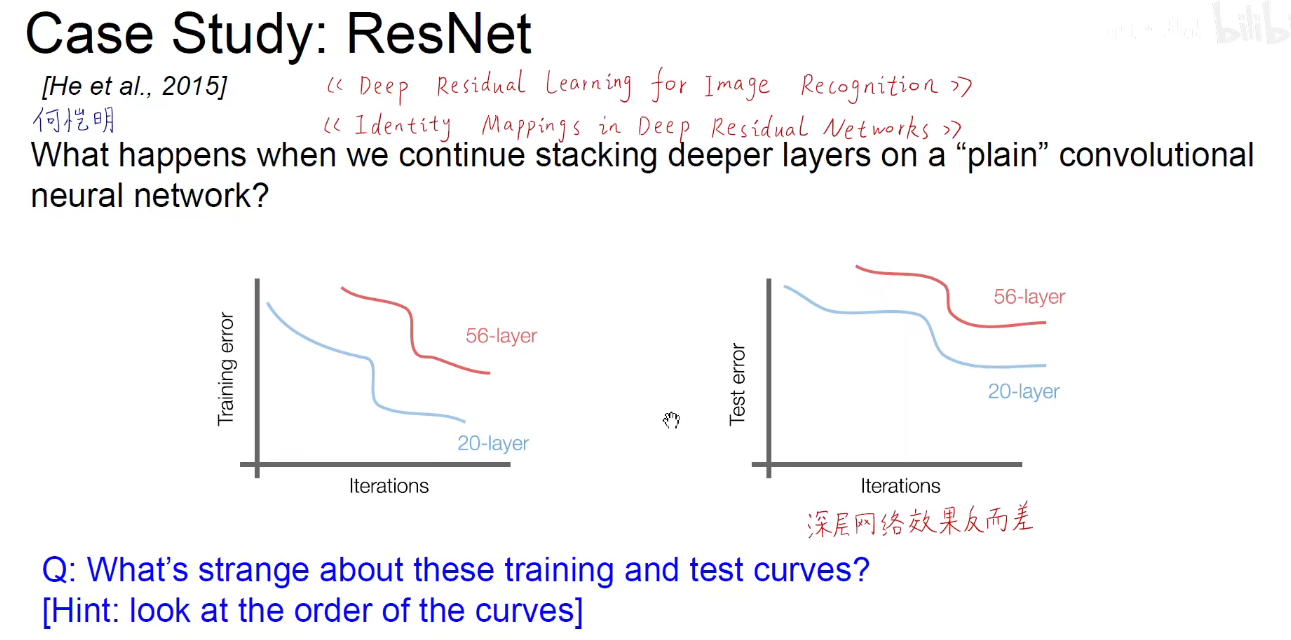
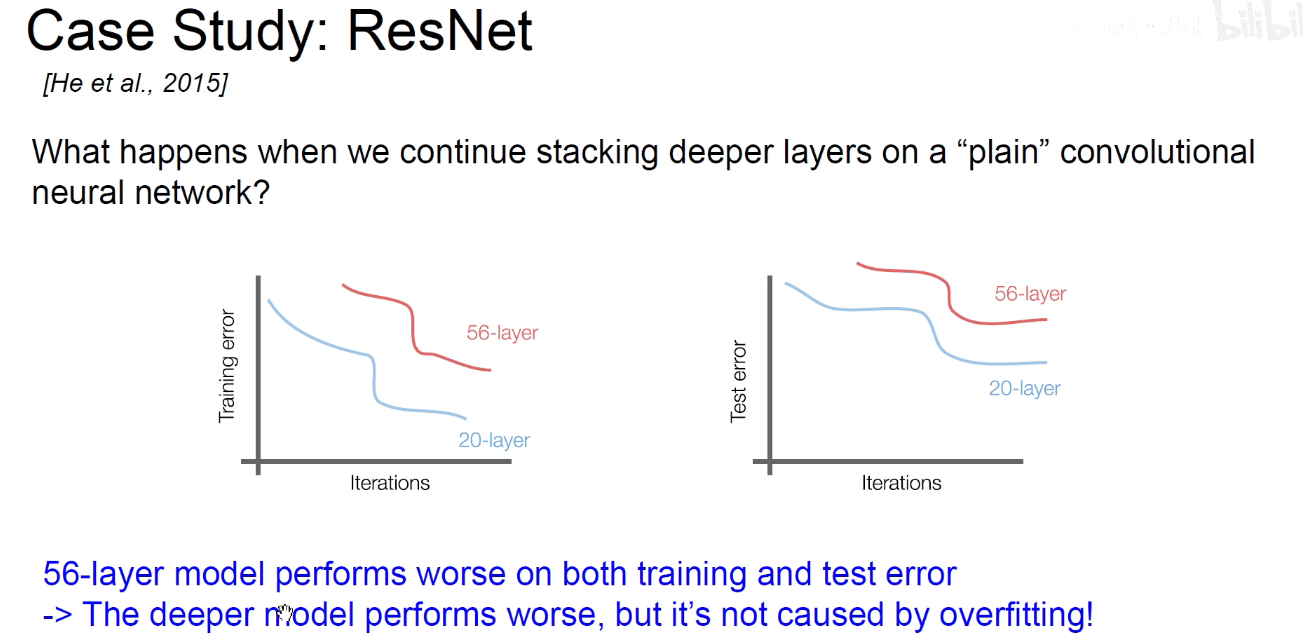
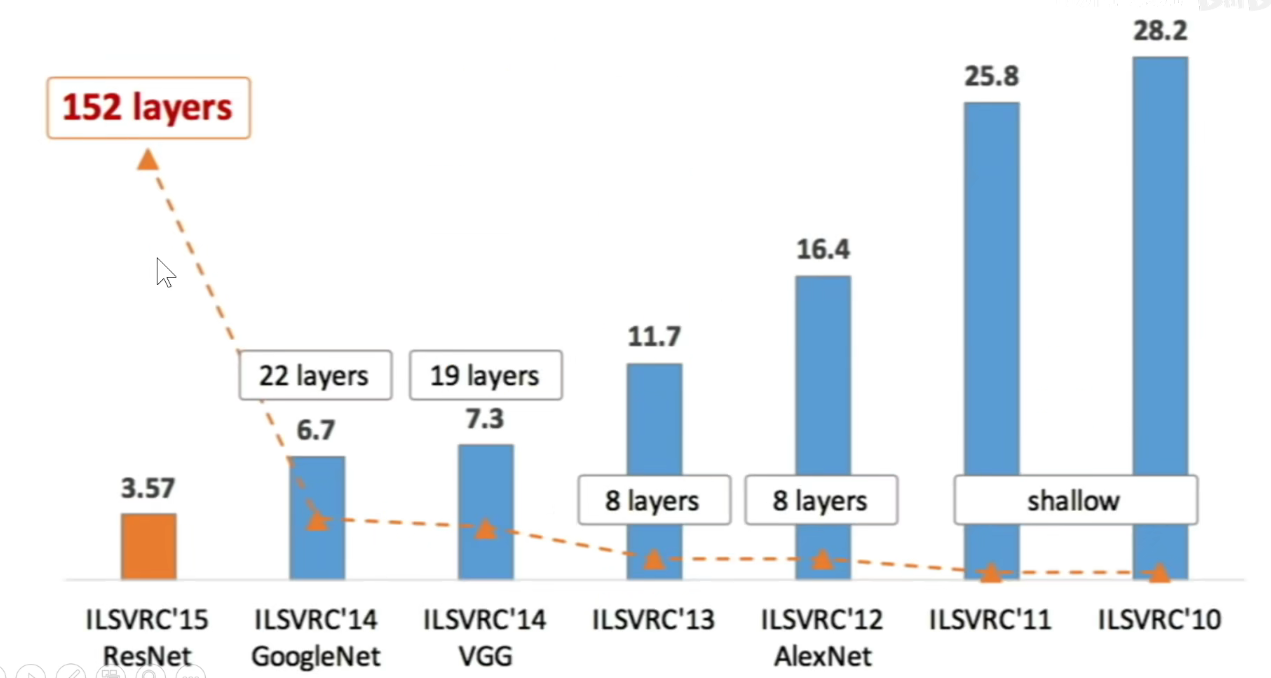
如上图:网络越深,就会引发梯度消失的现象,网络能力会退化。

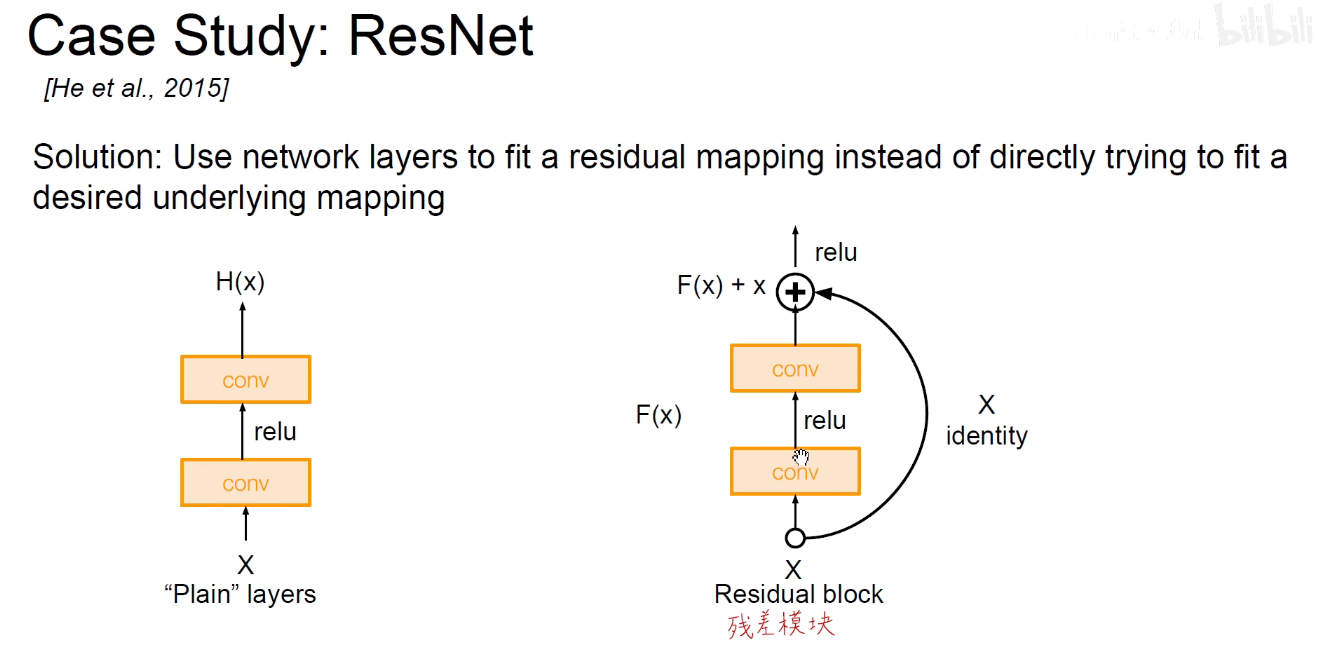
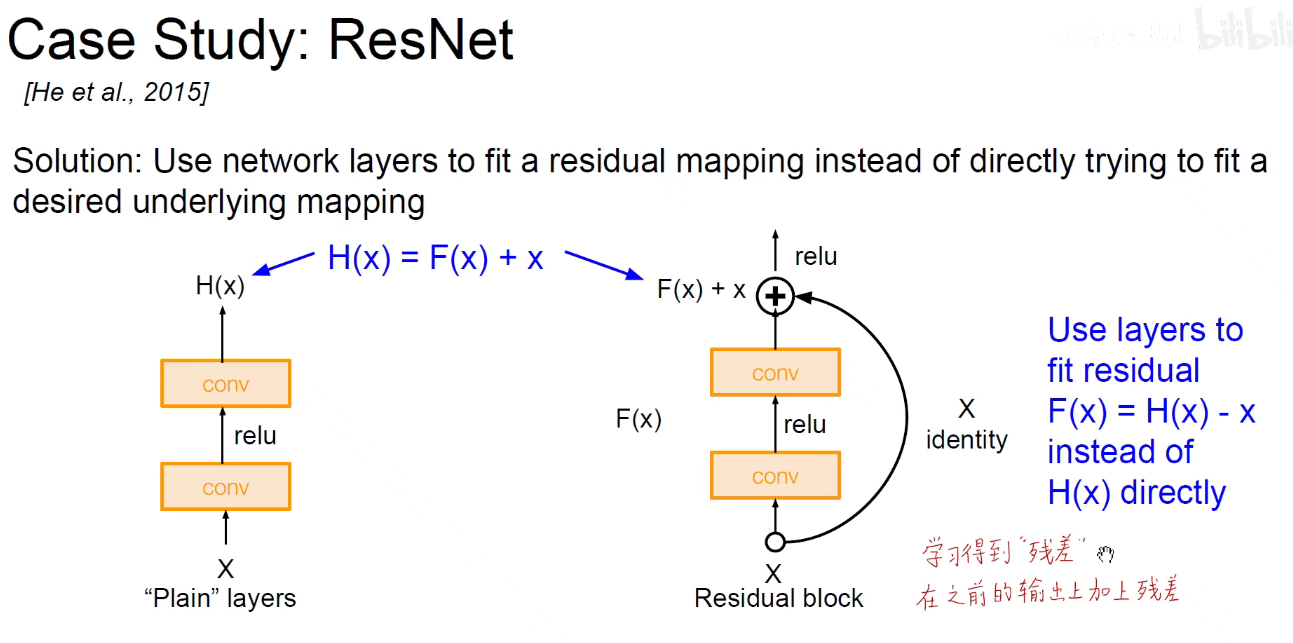
如上右图:把经过卷积处理后的结果F(x)与原始的输入(x)相加,如果什么都没有学习到,所有的权重都是0,则相当于F(x)=0,至少保证输入和最后的输出是相同的,即x=x,如果学习到了,则锦上添花,做一些微小的修改,一些微小的贡献,这个贡献就成为残差。
很深的网络,每一层都有很小的贡献,量变带来质变。
如下图:残差来源于高中学习的线性回归问题,我们要拟合一条直线,怎么衡量直线拟合的效果呢?计算真实测试集坐标上的点与我们预测它的同一个横坐标上直线上的点,竖直方向的差别。
称为残差。
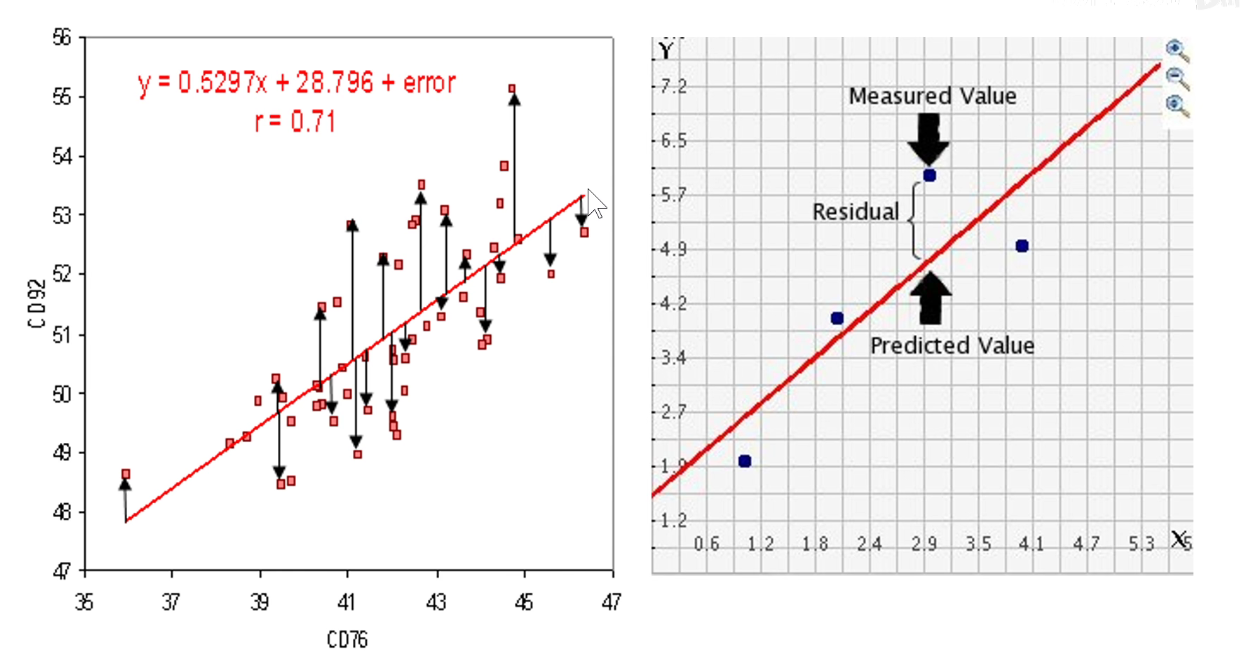
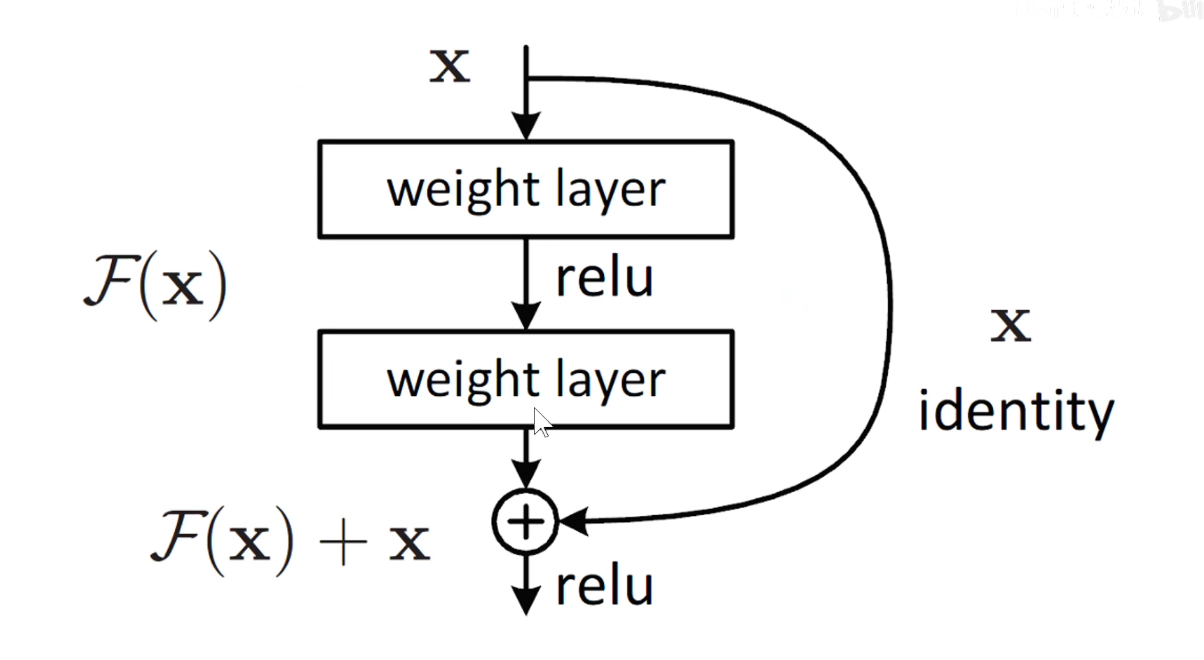
实际上相当于残差模块这一条路在学习上图中竖直方向的黑线,原来输入的x其实已经提供了一条红线,在红线的基础上对它进行微小的修改,就是f(x)。
因为使用了加法,输入可以跨层传递(Skip-Connection),跳跃连接,因此不会出现梯度消失现象。网络可以做的很深,达到152层。
要保证相加,需要保证维度是相同的。即经过卷积之后得到的形状和原始输入的形状是一样的,这样对应位置相加。
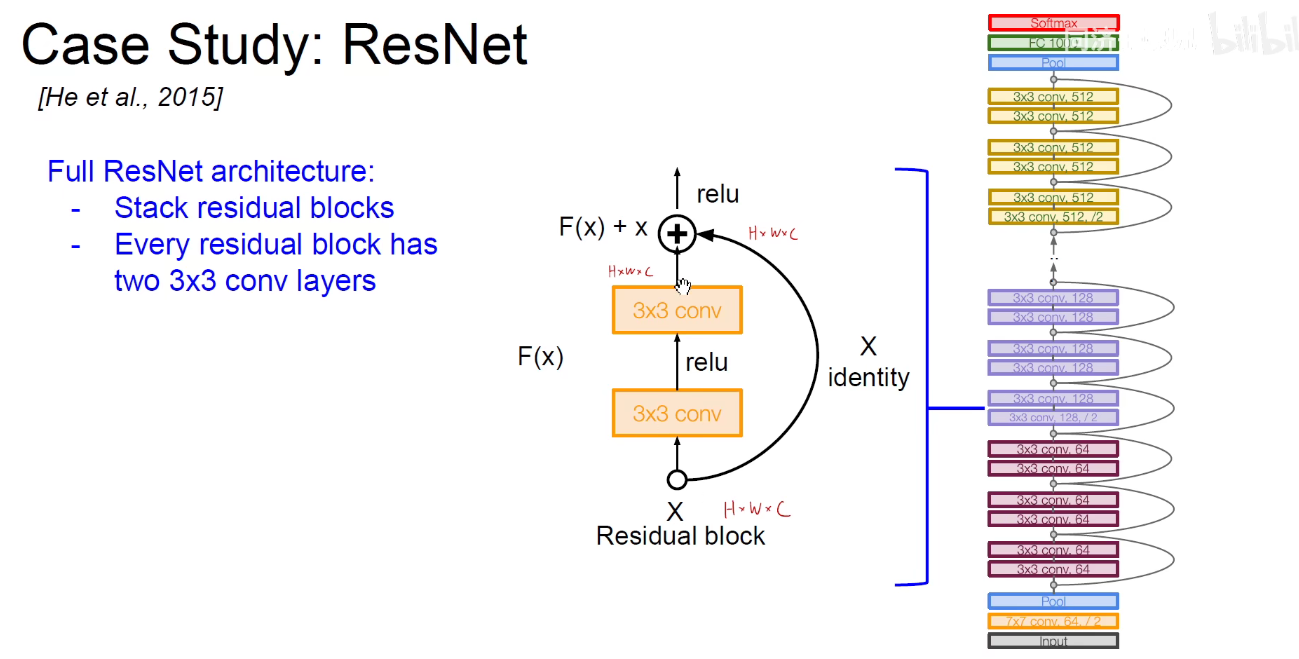
在ResNet中没有池化层,因为他是用了步长为2的卷积层替代了池化层,实现了下采样的结果。
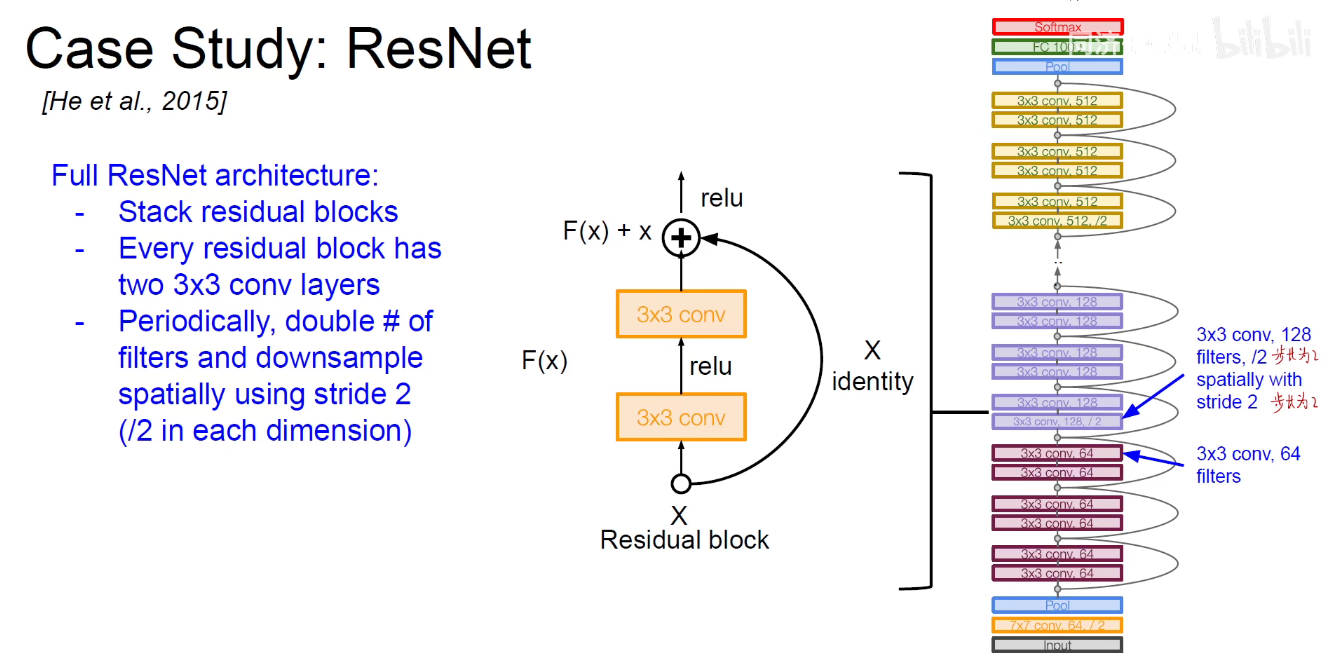
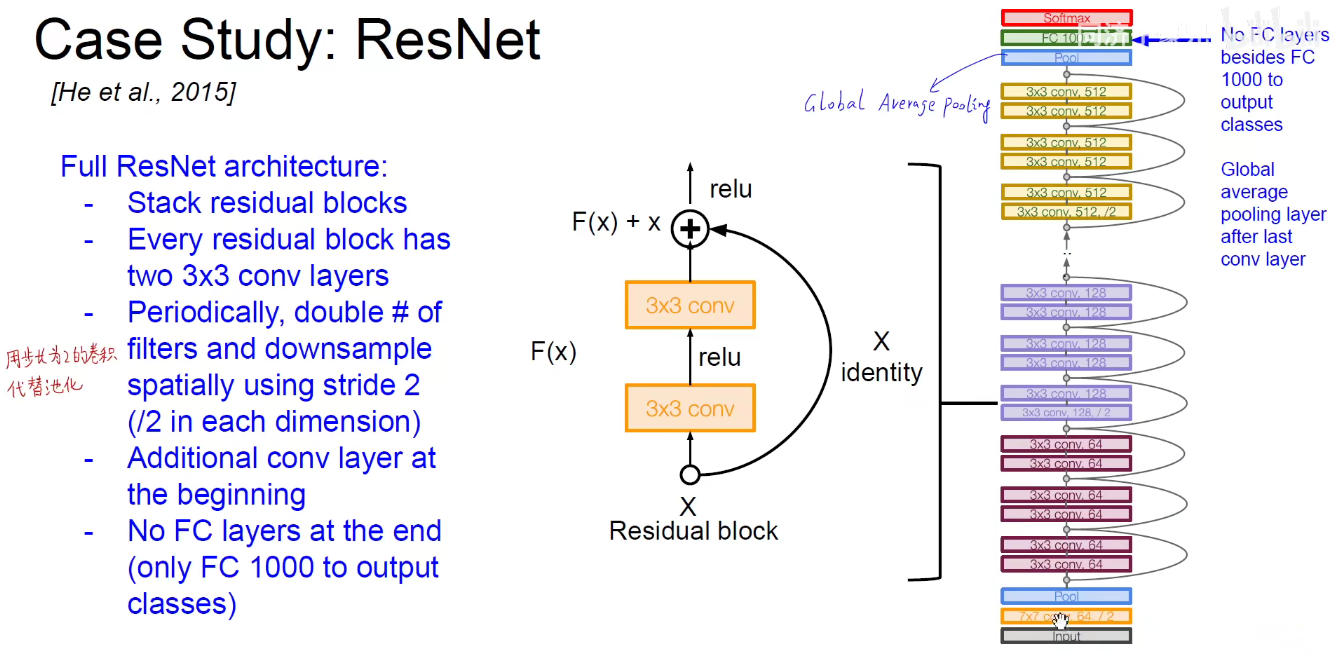
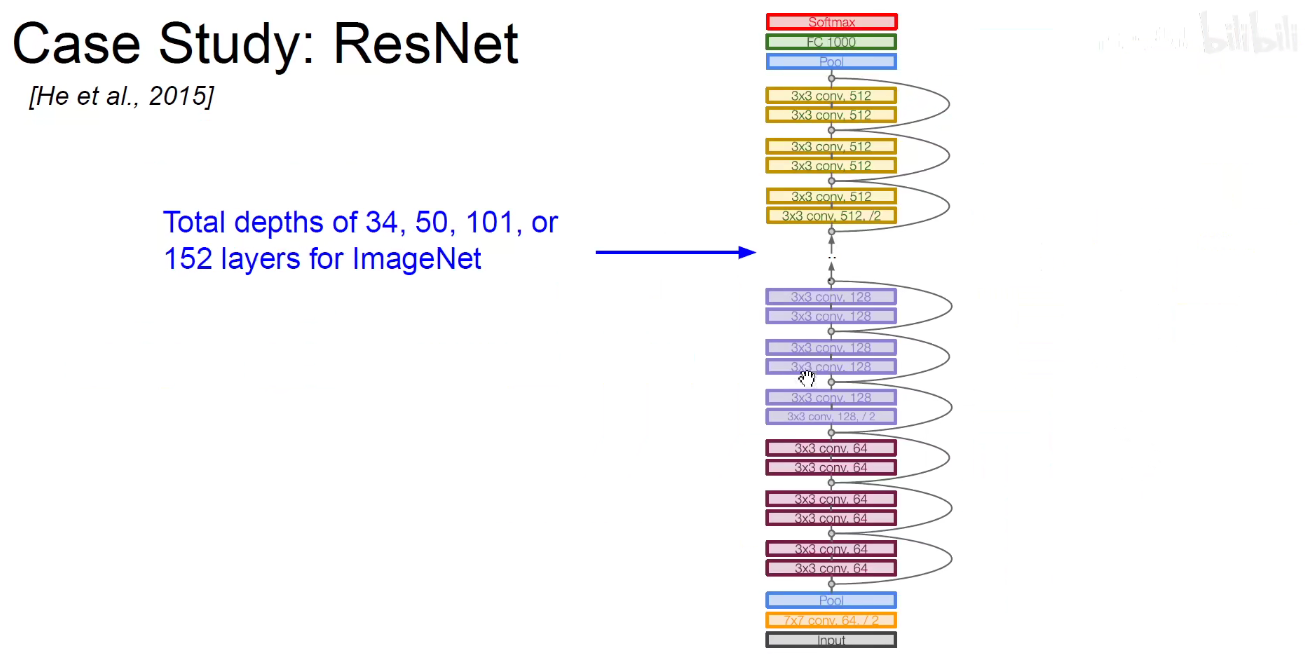
如下图:不同的模块堆叠进行堆叠,可以得到不同的版本。即ResNet-18/ResNet-34/…./ResNet-152等。
使用1x1卷积的bottleneck,对原有模型进行改进。先降维在升维。

如下图:之前讲过初始化,有Xavier和何凯明(MSRA)初始化等。
Xavier初始化要使得权重和X均值为0,并且独立同分布,并没有考虑激活函数,这样可以使得神经网络一层的输入和输出是相同的,如果用在ReLU函数中,不满足均值为0这样一个假设。
MSRA初始化:可以保证在ReLU场景下输入和输出的方差是相同而。 何凯明在ResNet中用到了它,

MSRA:微软亚洲研究院,号称是人工智能的黄埔军校。

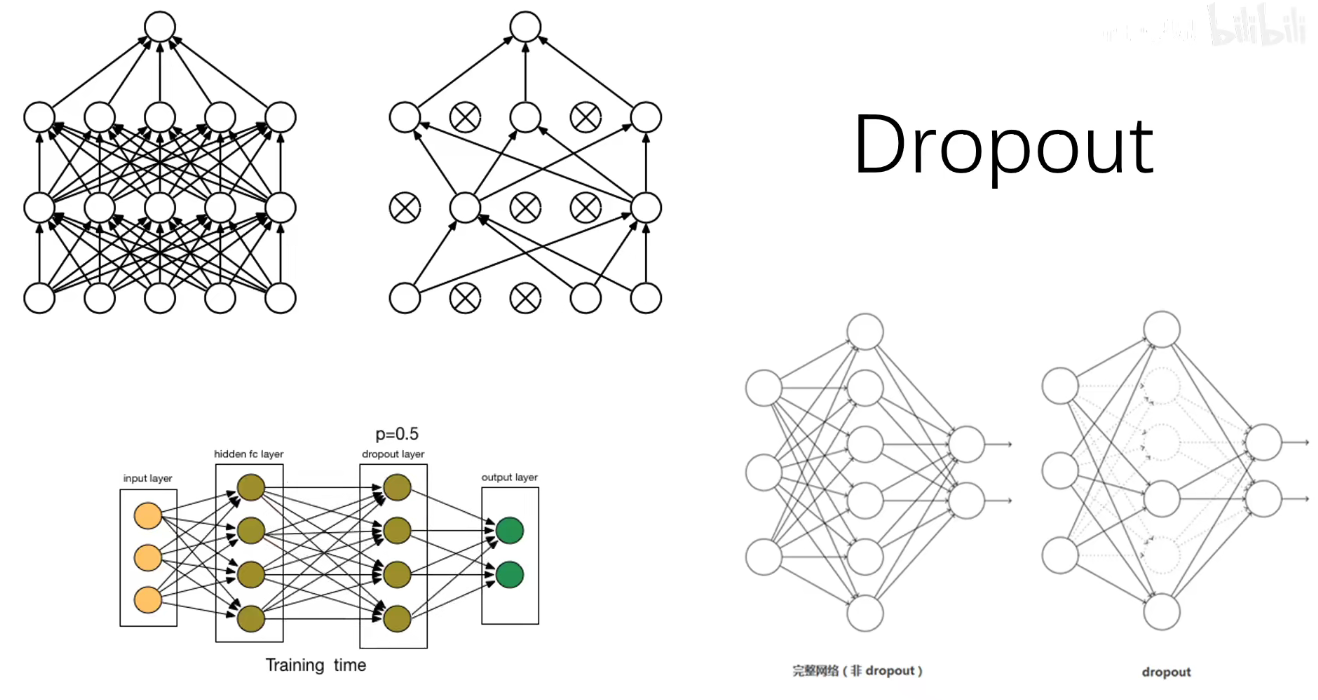
ResNet变种:Stochastic Depth:在训练时随机让一些残差块失活,这样可以让层之间的联合依赖性消失,类似于Dropout的正则化效果,让每一个层都可以独当一面,独立的去提取特征,并且可以有效的改善梯度消失现象。如果我们把这个层掐死,则表示没有这个层,它的输入和输出一样的。

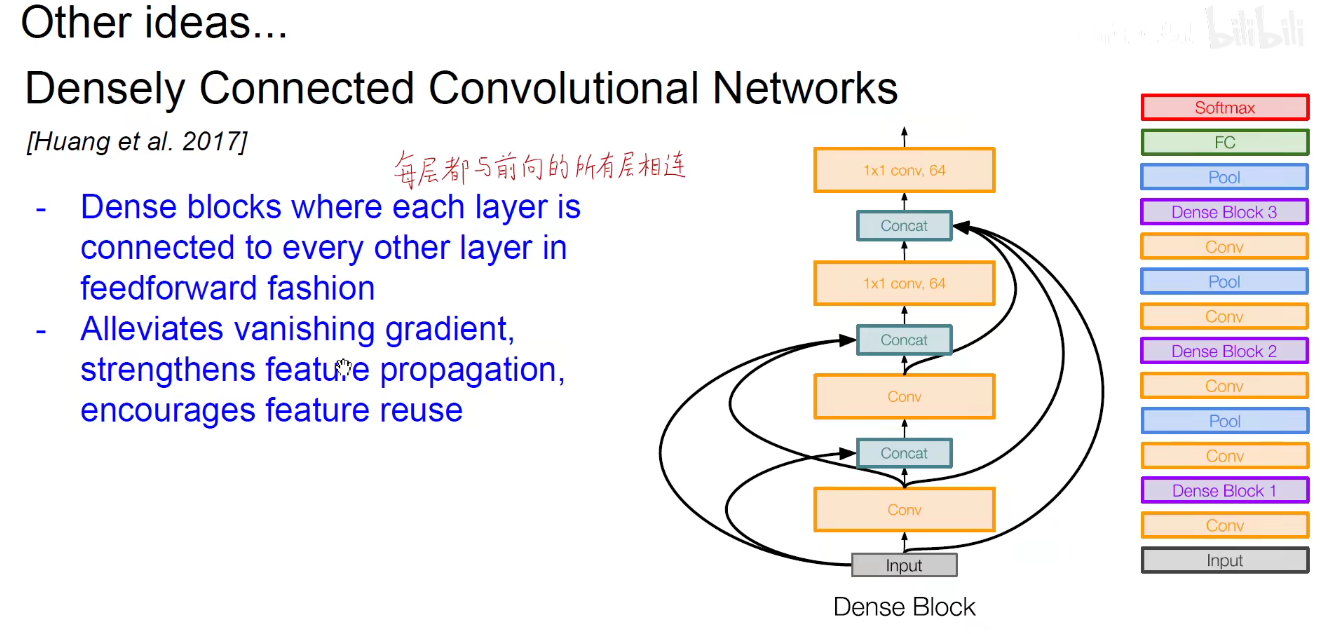
Dense-Net:表示每一层都与后面的所有层相连,后面的层都与他前面的层相连。我的附庸的附庸仍然是我的附庸。
下图就是一个Dense-Block:
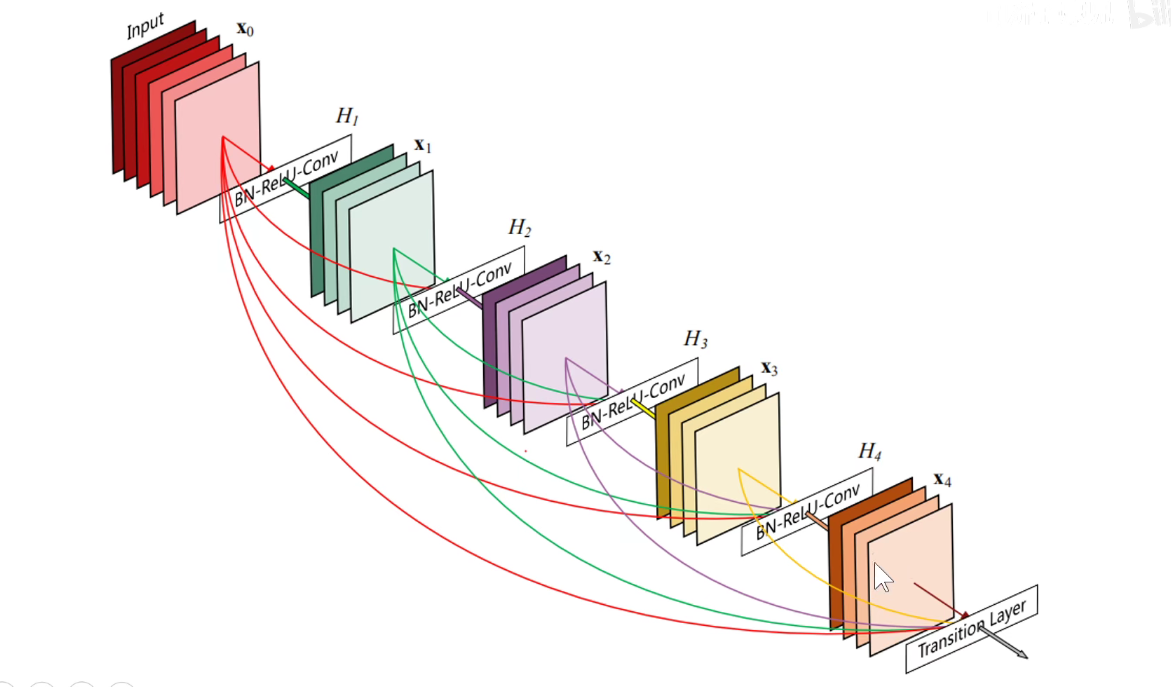
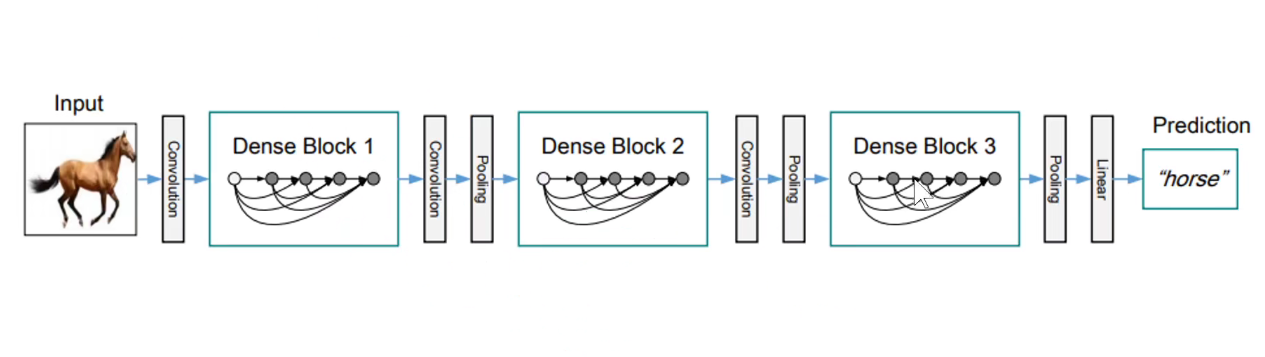
将Dense-Block模块堆叠在一些:这是2017年的论文。
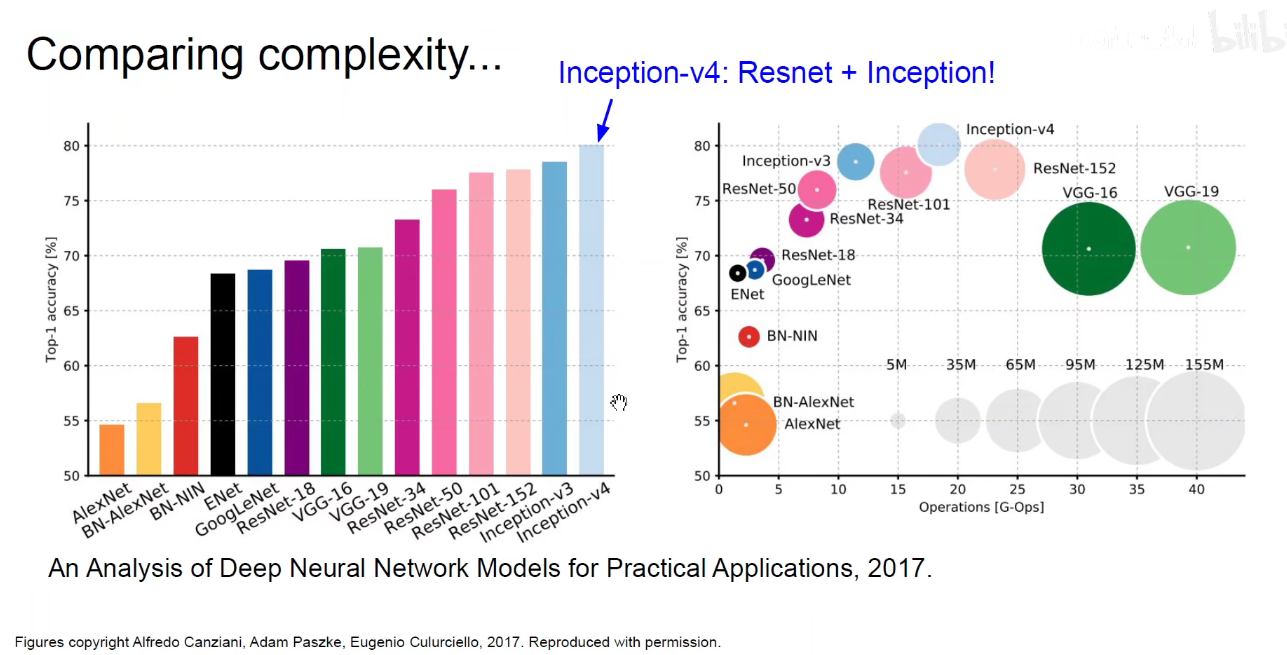
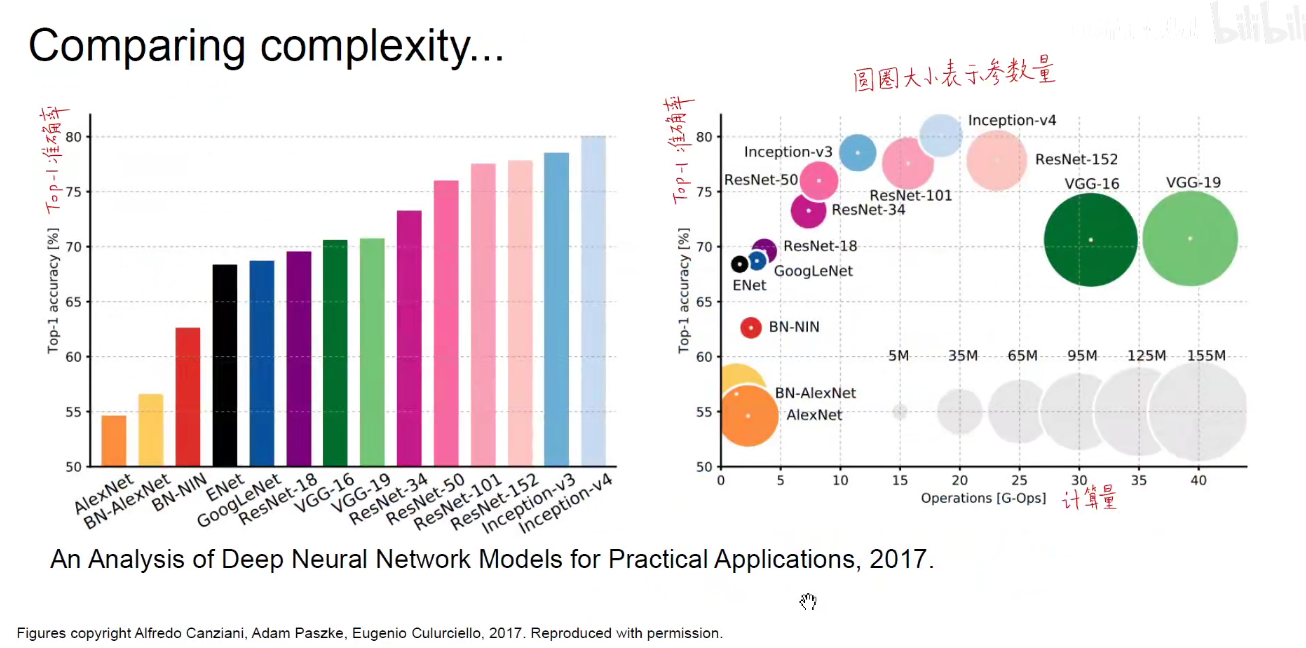
如上图:右边图示表明越靠近左上角,Top-1准确率越高,计算量越少。
Inception-V4: ResNet + Inception.
VGG:Highest Memory,most operations.
GoogLeNet: most efficient.
AlexNet: Smaller compute, still memory heavy, lower accuracy.
ResNet: Moderate efficiency depending on model, highest accuracy.
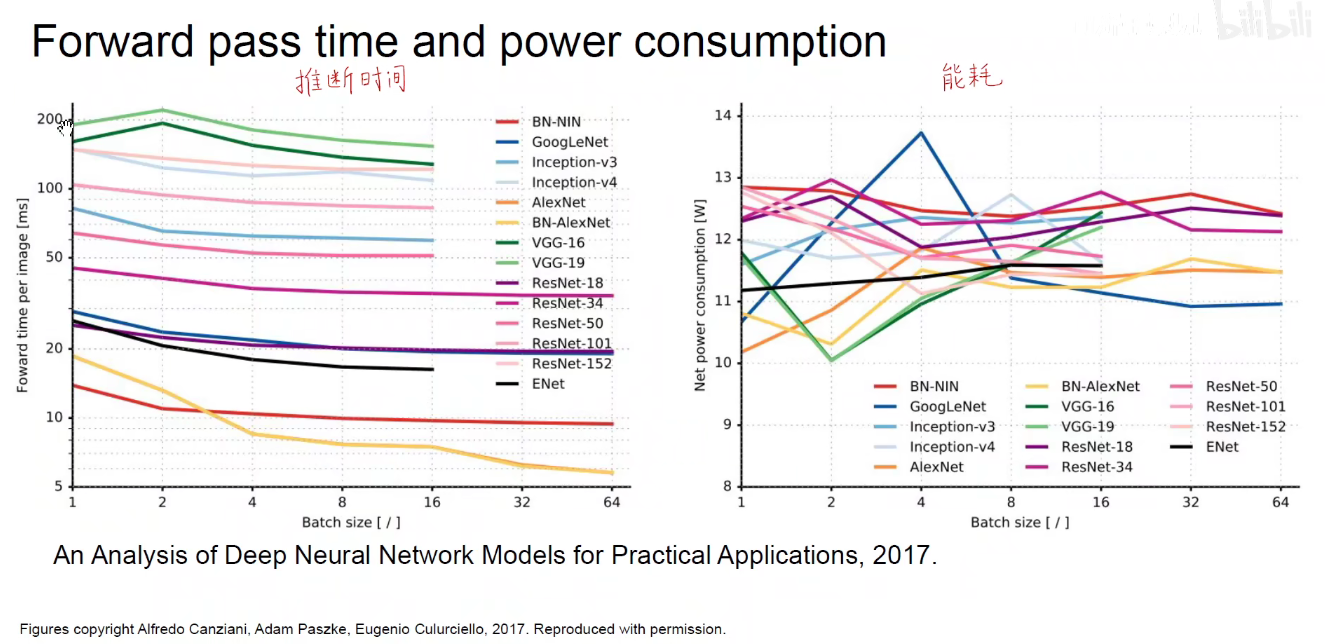
如下图:可以看到不同模型的推断时间,可以看出VGG是非常耗时的,不适用于边缘计算(无人机、无人驾驶、安防等),对延迟的要求很高,不能让人等的太久,要当下立即出结果,实时的进行反馈。
能耗:不仅仅是耗电的多少,更涉及到集成电路芯片的散热,集成电路芯片元器件的面积,寸土寸金,此处的能耗很大程度上是读写内存带来的能耗。加减乘除耗能不会太多,从内存读取一次的能耗大约是1000个加减乘除的能耗之和。
7. 2016-Network Ensembling
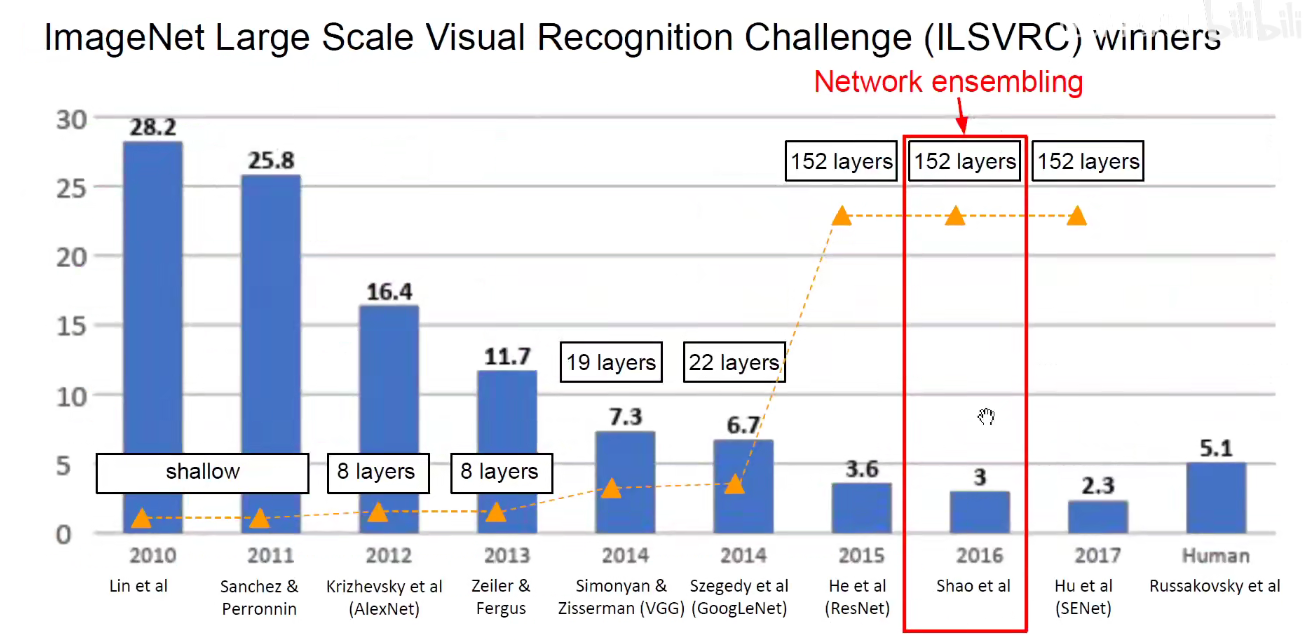
将很多模型集成在一起:下图可以看出模型集成这种方法非常强大,不用提出什么新的模型,将别人做好的拿来堆叠使用就行了。

8. 2017-Adaptive feature map reweighting(最后一届ImageNet竞赛冠军)
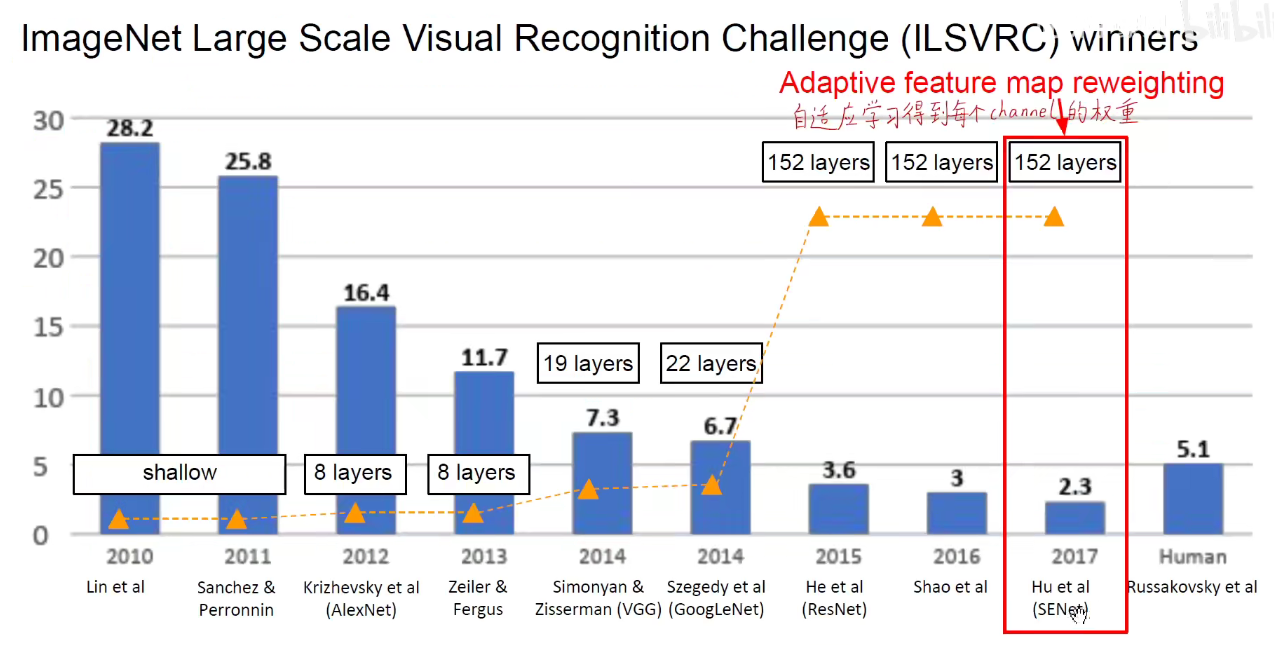
胡杰团队,ImageNet后几年基本上都是中国人上去大放异彩。
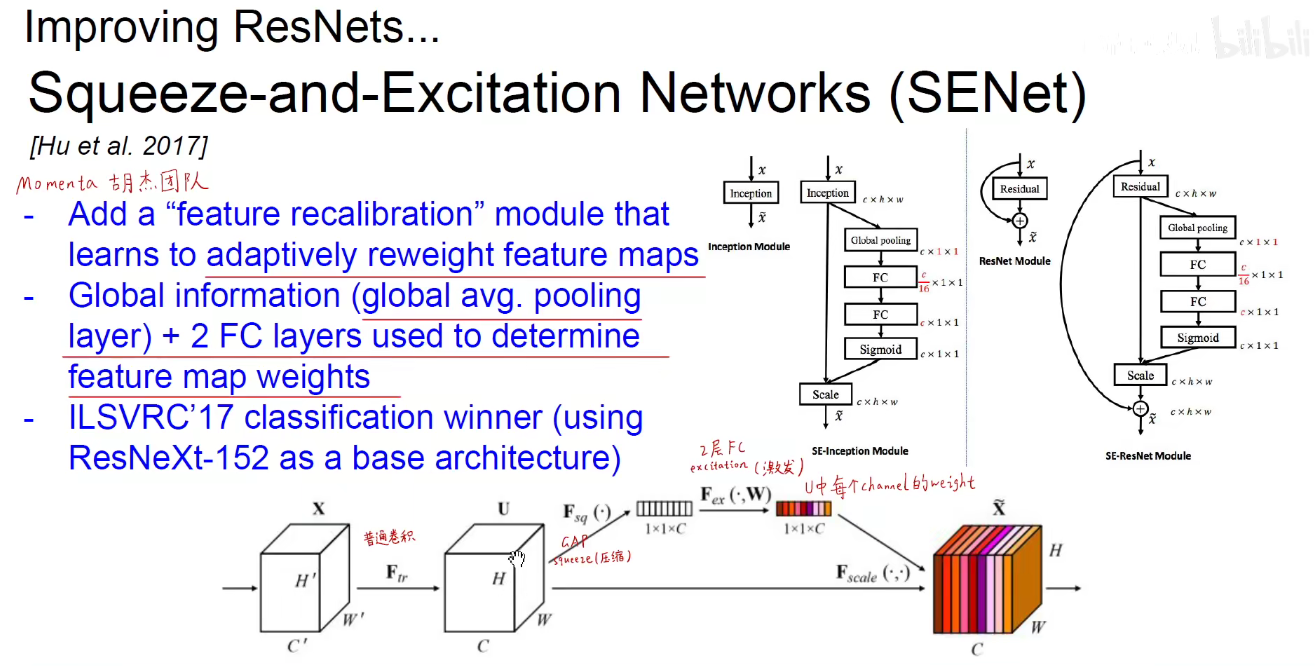
SENet可以接在任意的网络后面,如图中展示的接在Inception和ResNet后面。自适应的学习到每一个feature-map的权重。
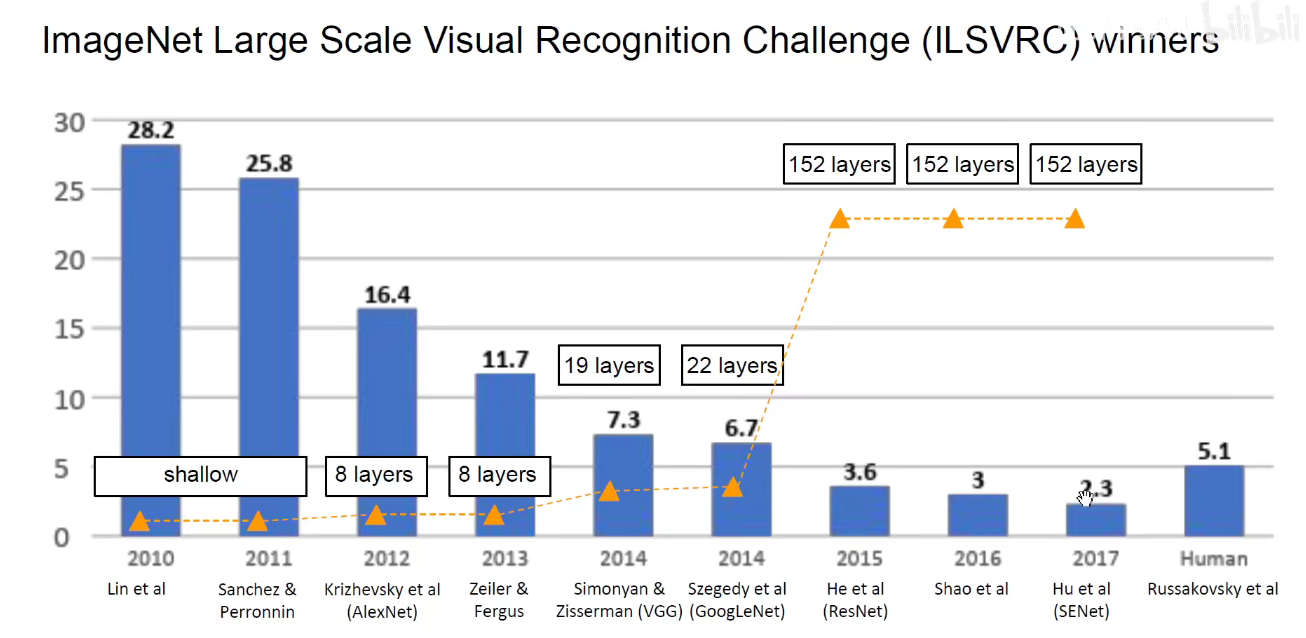
从2012-2017,短短的5年时间里,计算机视觉-图像分类领域在工程学上得到了比较靠谱的方案。
线下没有必要在举办了,竞赛迁移到Kaggle线上平台上:https://www.kaggle.com/competitions

8. 2017-SqueezeNet
韩松老师

论文写作既有致敬、彩蛋还有标题党。。。。
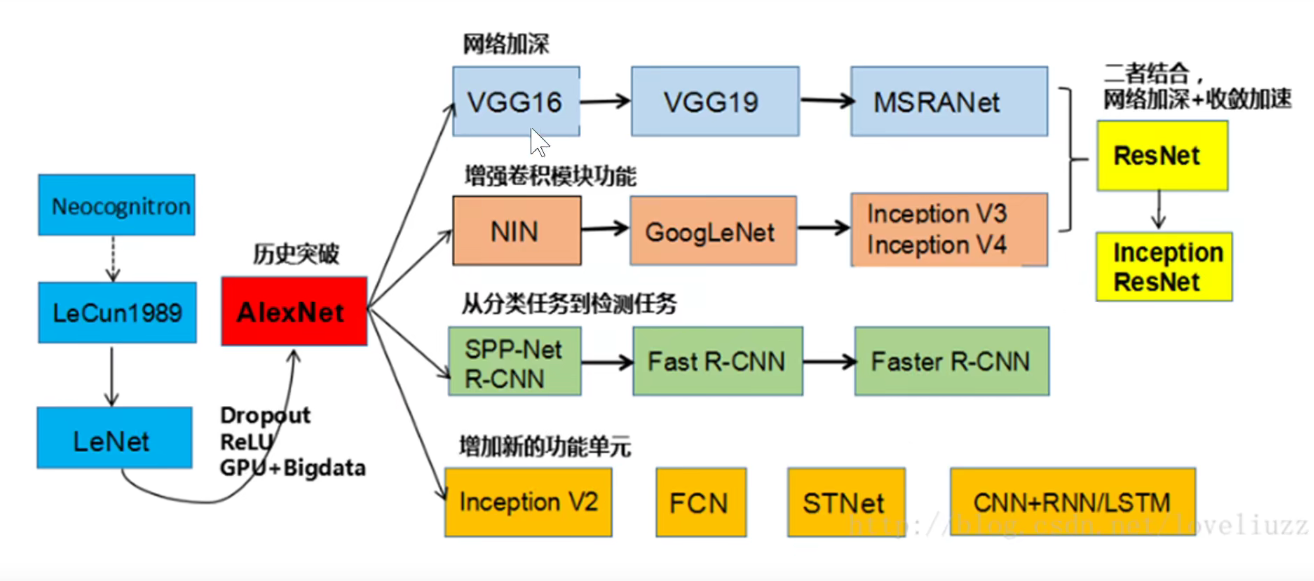
9。 回顾
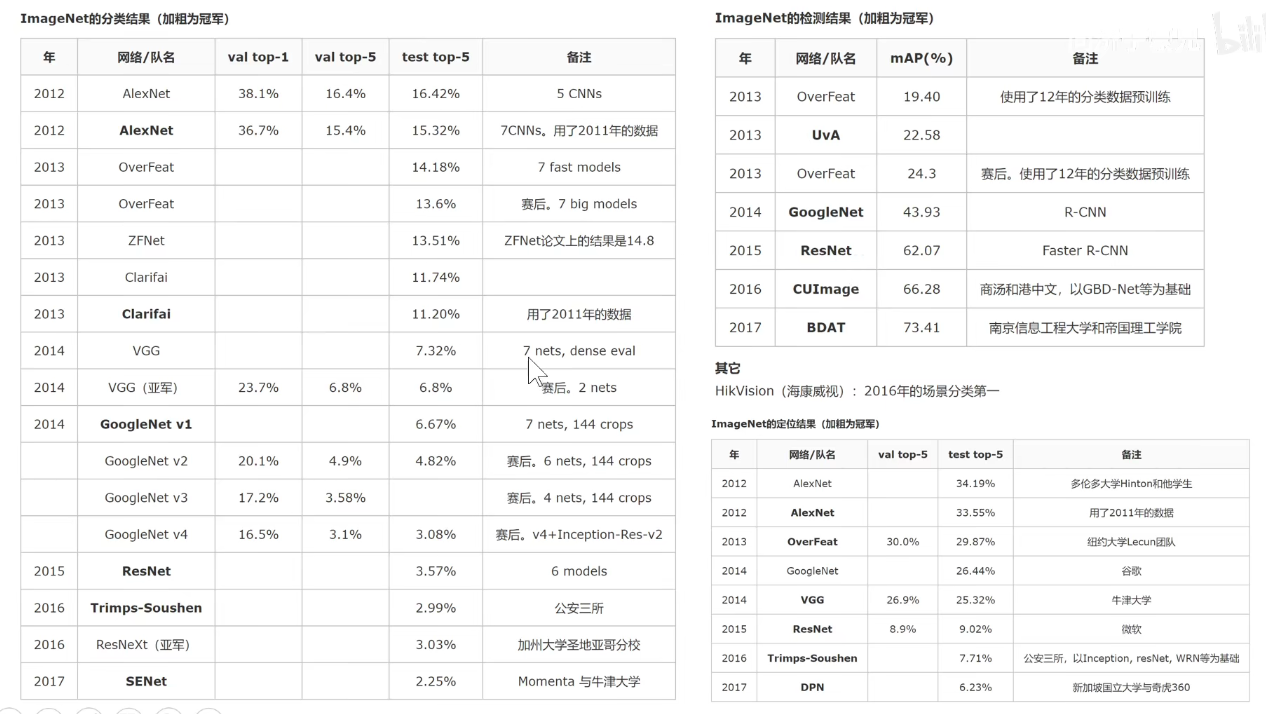
ILSVRC-XXXX竞赛
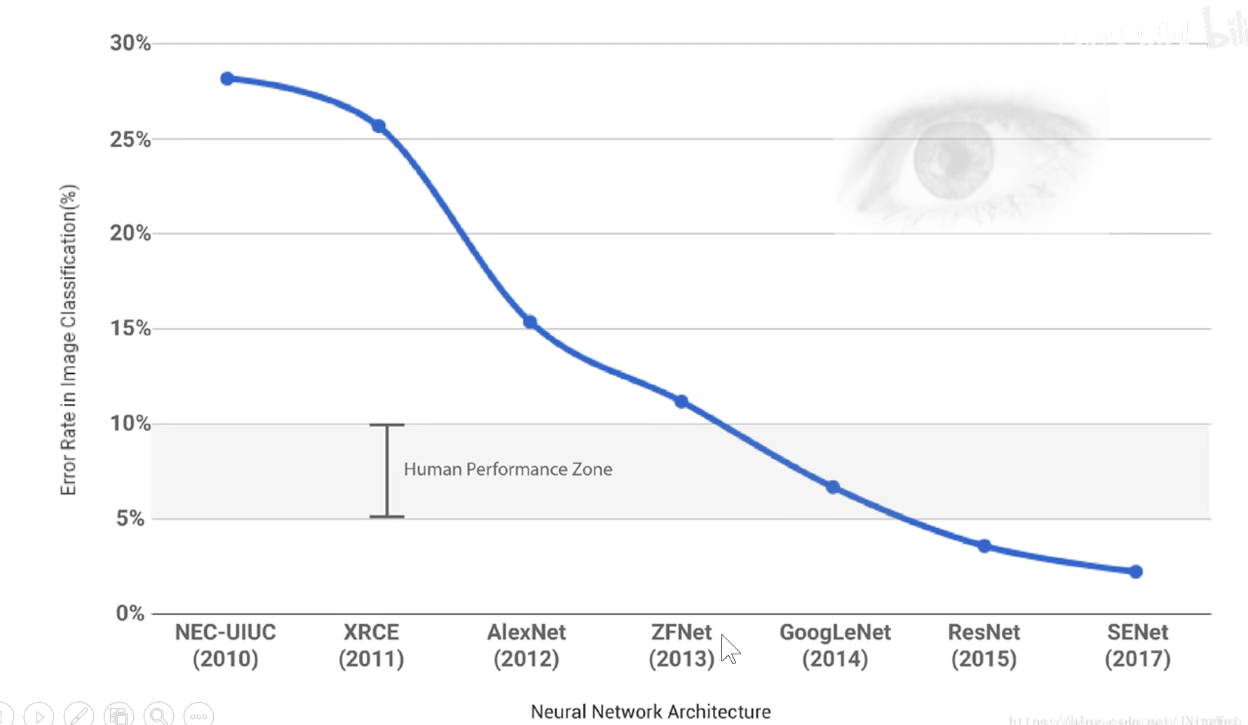
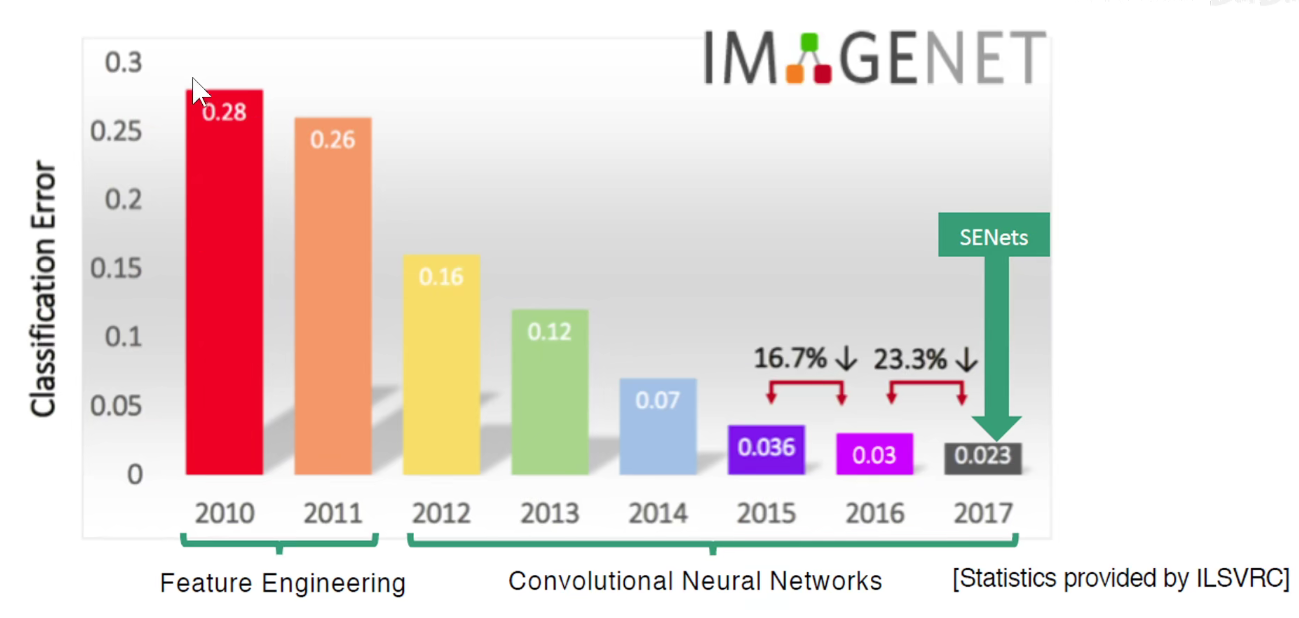
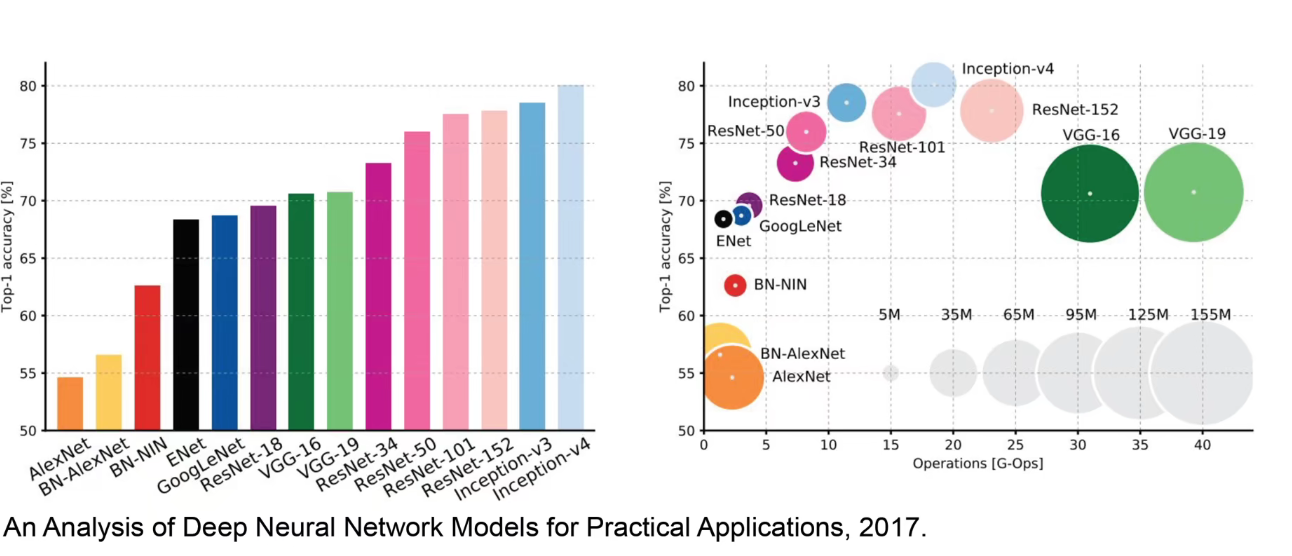
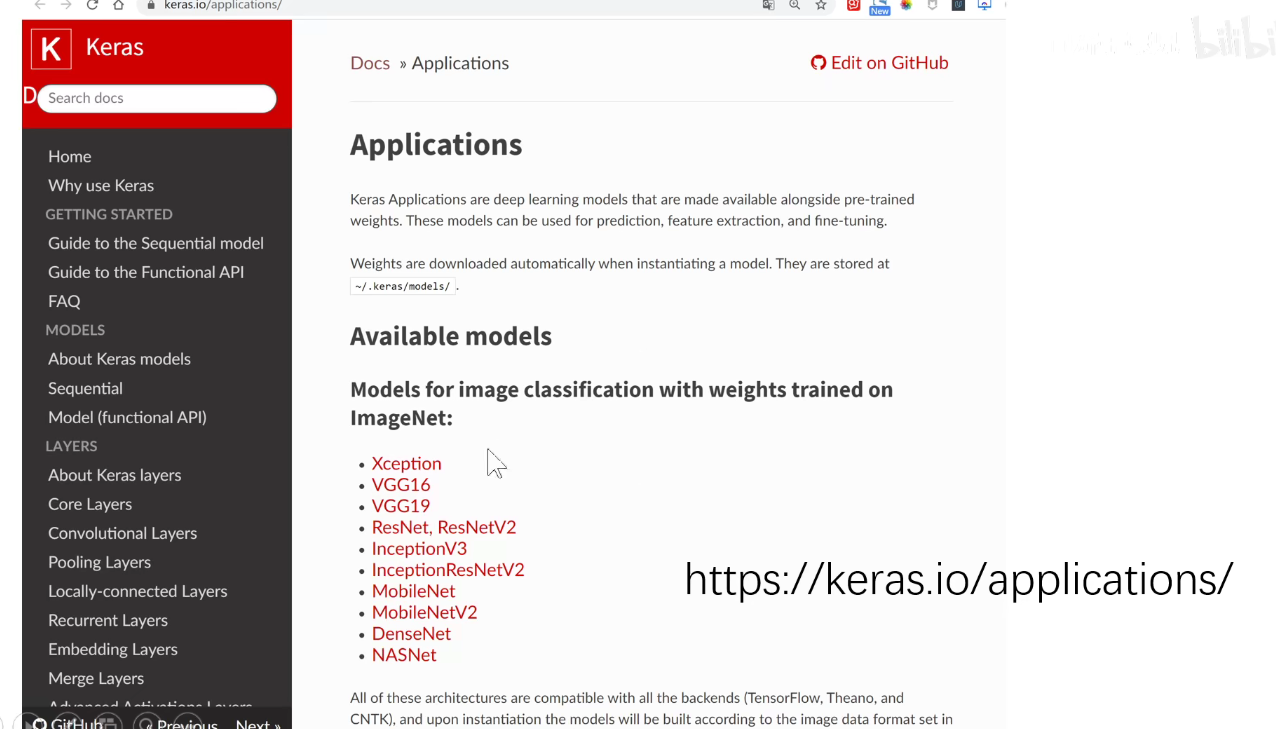
在Keras中的Applications模块中,可以调用预训练的模型。
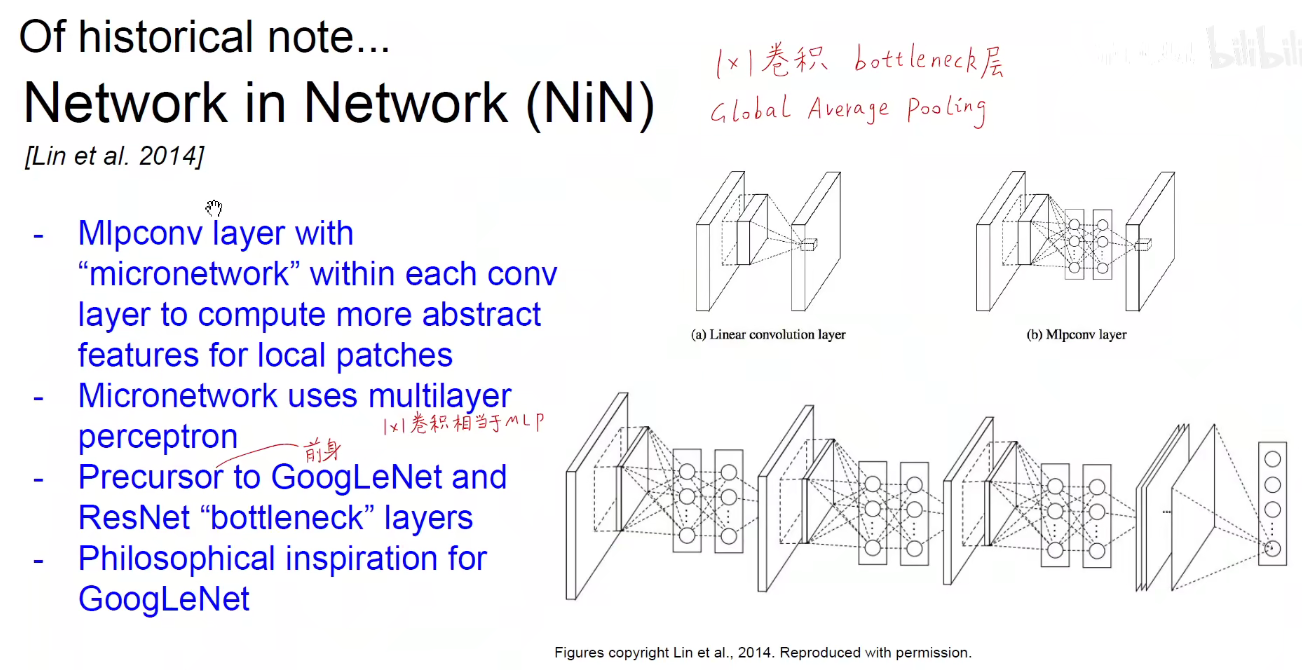
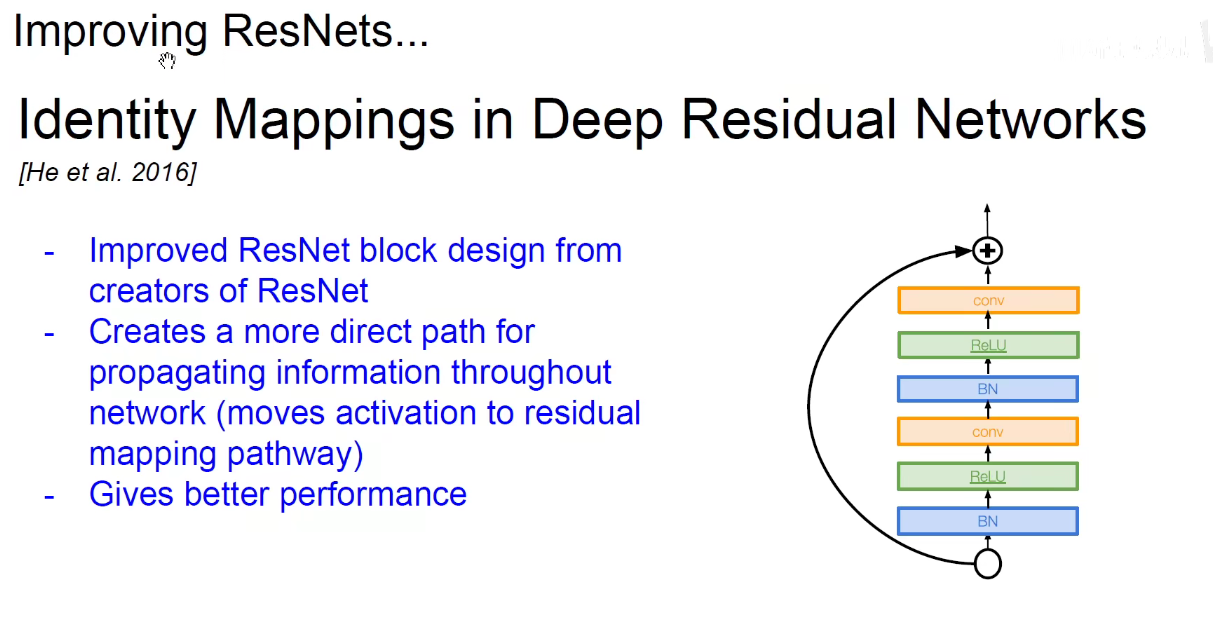
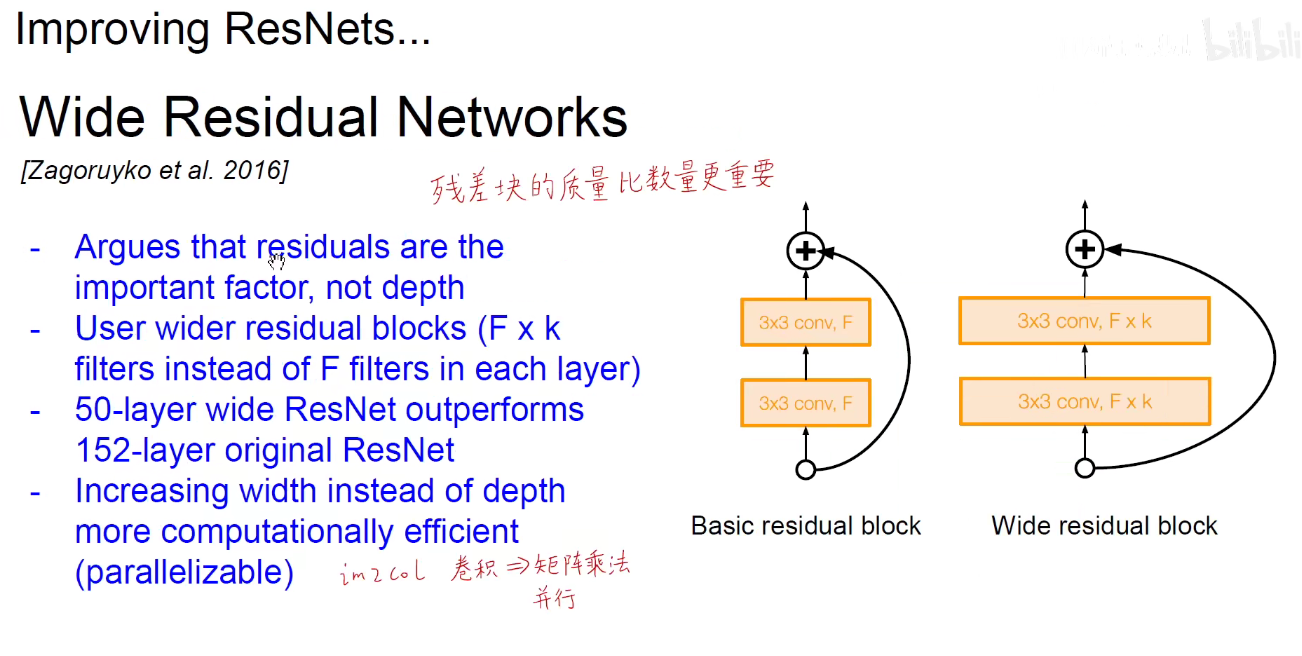
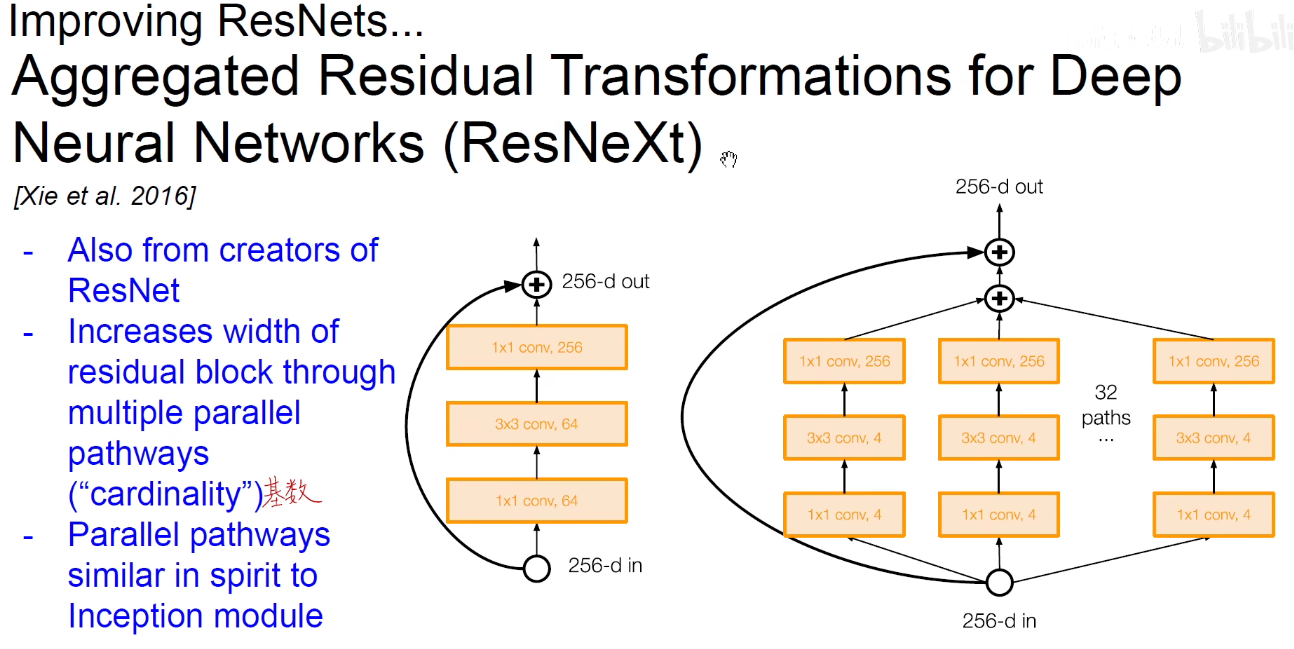
分形网络:表示物体间的自相似性。如电子绕着原子核转,地球绕着太阳转,不同尺度上都是自相似性的。
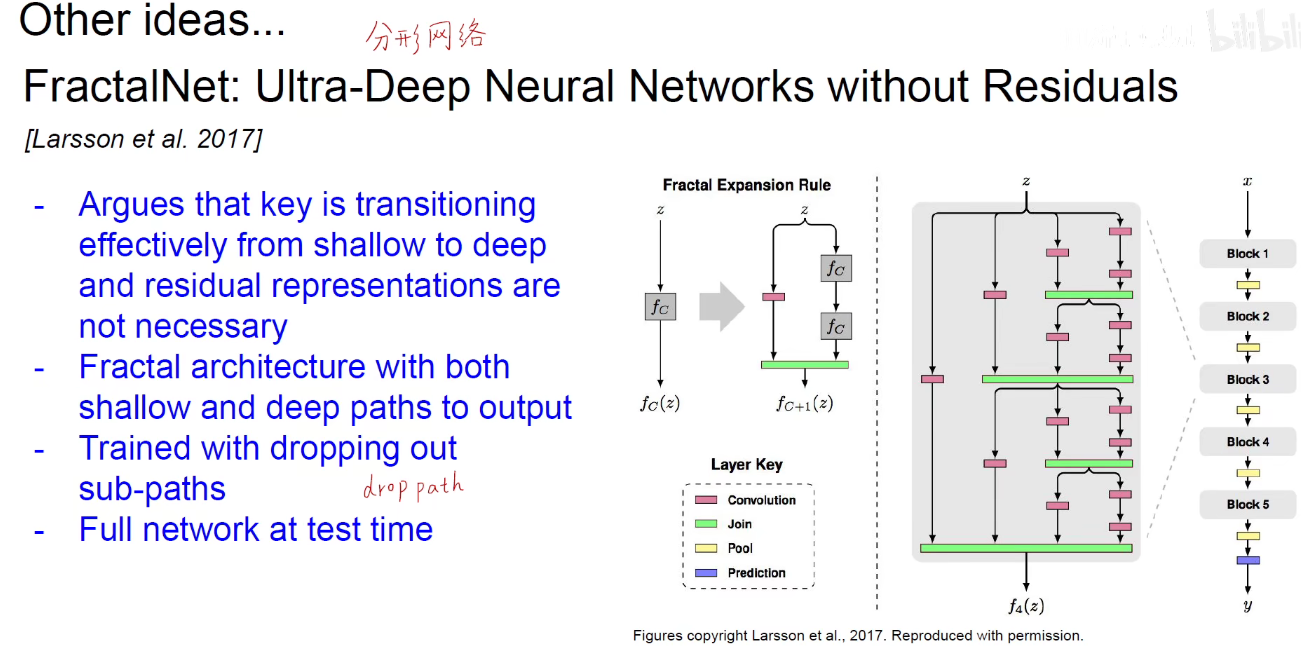
DenseNet: 我的附庸的附庸依旧是我的附庸。