Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N
韩松教授:CS231N-2017年客座教授讲座。本科清华,博士斯坦福,现在MIT。他的研究领域就是边缘计算加速,模型压缩,在讲座中讲了很多自己独到的贡献和见解。个人主页:https://songhan.mit.edu/
油管搜索:efficient methods and hardware for deep learning
视频地址:
- https://www.youtube.com/watch?v=eZdOkDtYMoo
- https://www.bilibili.com/video/BV1K7411W7So?p=14&spm_id_from=pageDriver
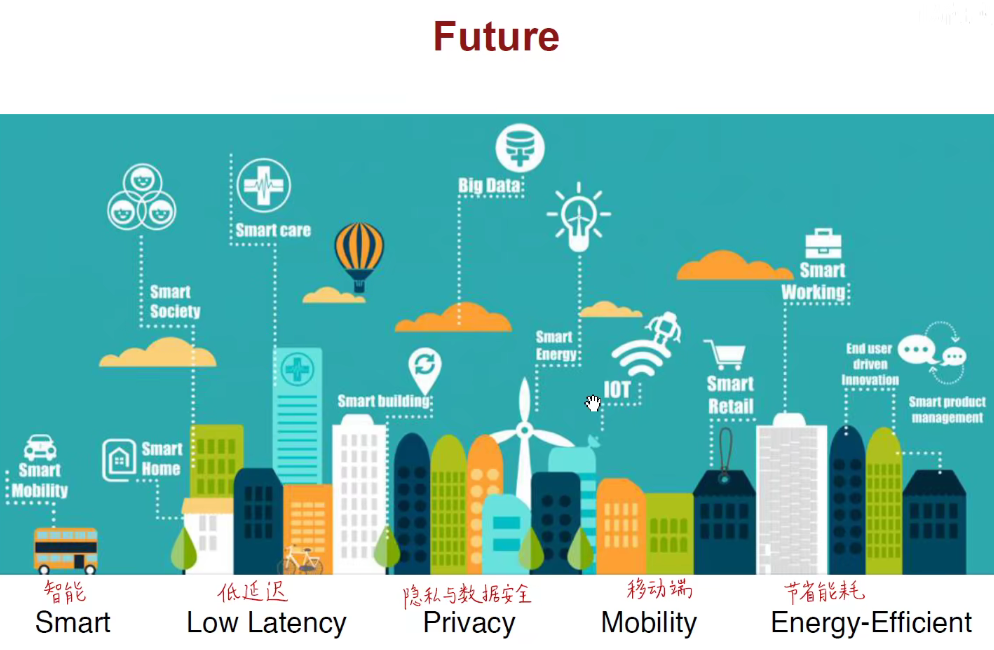
大型深度学习模型对能耗、低延迟、快速训练、芯片的需求。
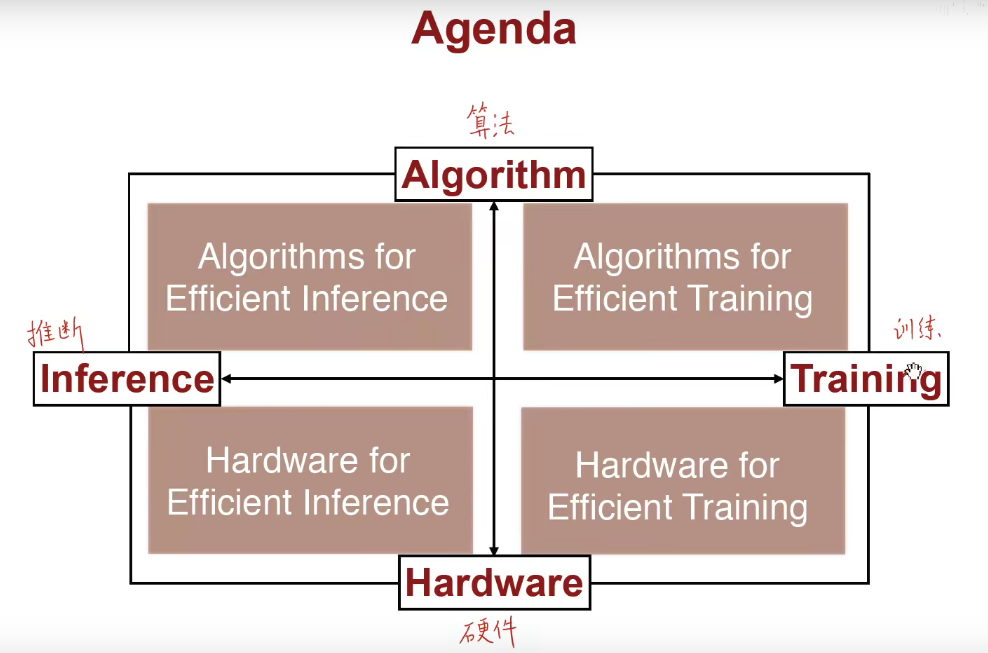
加快推断的算法:模型裁剪、权重合并、权重量化、低秩近似、二值/三值量化、Winograd加速卷积。
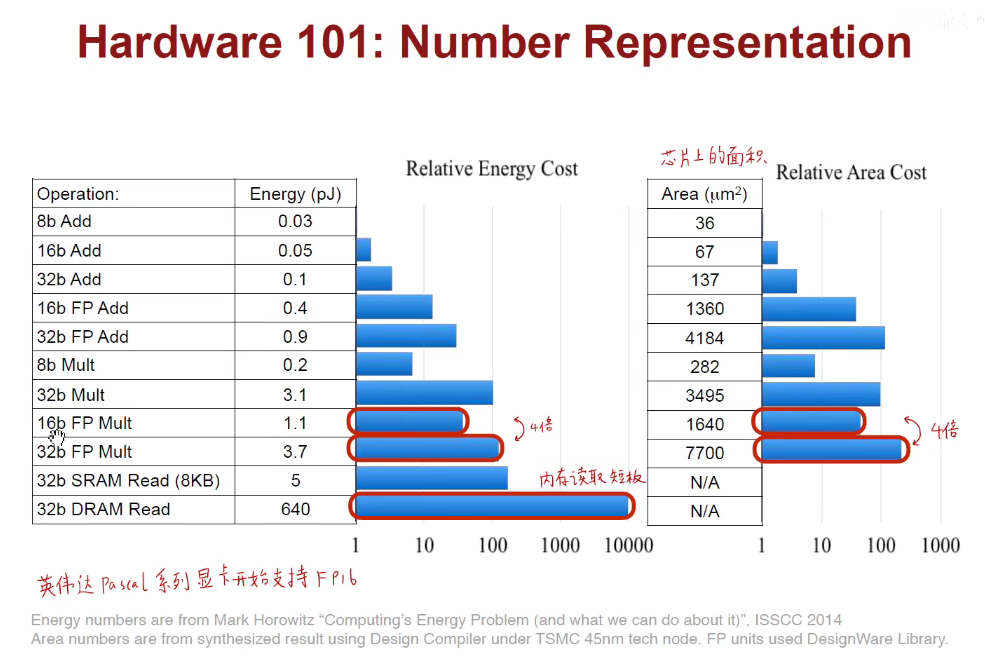
加快推断的硬件:Roofline Model计算瓶颈理论,EIE芯片架构
加快训练的算法:数据并行、模型并行、混合浮点数精度、知识蒸馏、DSD密集-稀疏-密集训练。
加快训练的硬件:CPU、GPU、TPU、FPGA。
拓展链接
模型压缩总览:https://www.jianshu.com/p/e73851f32c9f
霍夫曼编码的理解:https://blog.csdn.net/xgf415/article/details/52628073
winograd加速卷积:https://www.cnblogs.com/shine-lee/p/10906535.html
卷积神经网络中的Winograd快速卷积算法:https://zhuanlan.zhihu.com/p/74567600
高效卷积实现算法和应用综述(上):https://www.cxyzjd.com/article/qq_32998593/86177151
陈云霁与DADIANNAO:https://www.bilibili.com/video/av24683679
知乎、Roofline Model与深度学习模型的性能分析:https://zhuanlan.zhihu.com/p/34204282
知识蒸馏原始论文:https://arxiv.org/abs/1503.02531
Intro




如上图:无人驾驶车辆,需要在当下就决定是否要超车、拐弯、避开行人,如果存在一个很高的延迟,车可能会翻沟里。同样,高能耗也是不可被接受的,智能手机的充电量是比较有限的,特别是苹果手机,充电都是一个老大难的问题。模型过大无法通过无线传输的方式将其部署在终端上。无人车有时必须开到他这个基站,连上他这个Hub,才能进行传输。所以要对模型压缩。




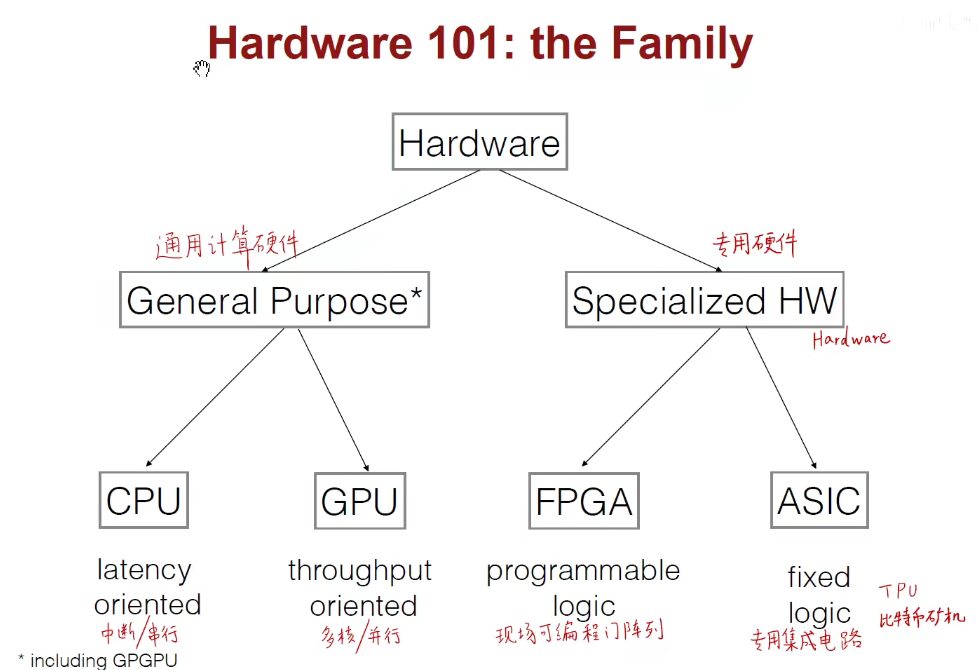
像前几年的TPU比特别币挖矿机,使用ASIC架构专用挖矿,干不了其他事情,因此泡沫破碎后,只能卖废铁。

1. 加速推断的算法

1.1 Pruning Neural Networks
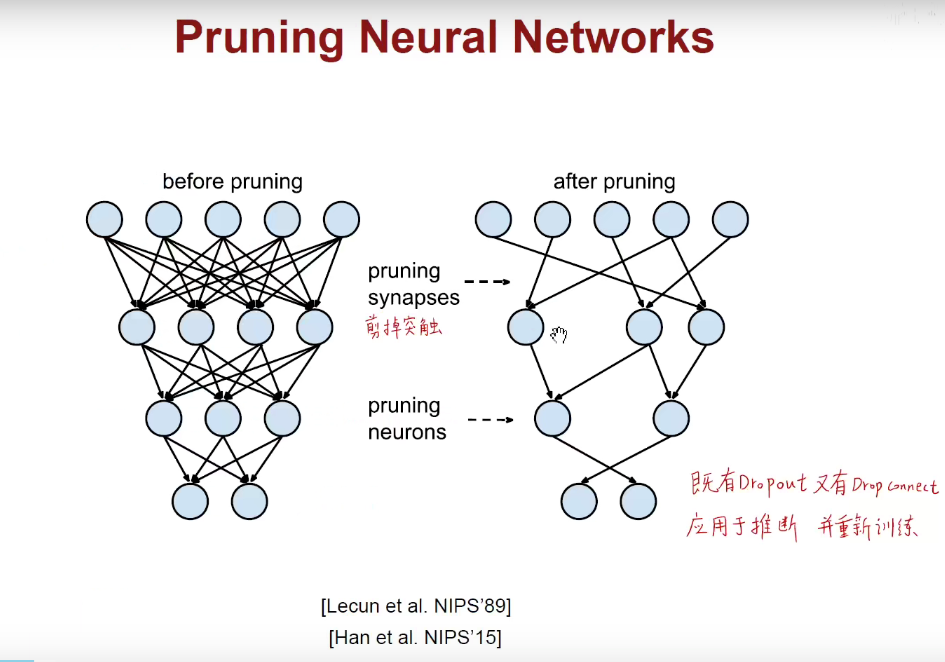
Dropout:随机掐死神经元,DropConnect:随机掐死其中的一些链接,相当于是减掉树突。
Dropout是用于训练的,但我们现在要讲的是用于加速推断的算法,意思就是我已经训练好了一个完整的模型,我能否把其中的一些枝丫减掉,在这个残留的模型上继续训练,同时保证它的精度相比于原模型不会显著的下降。
Model-Pruning
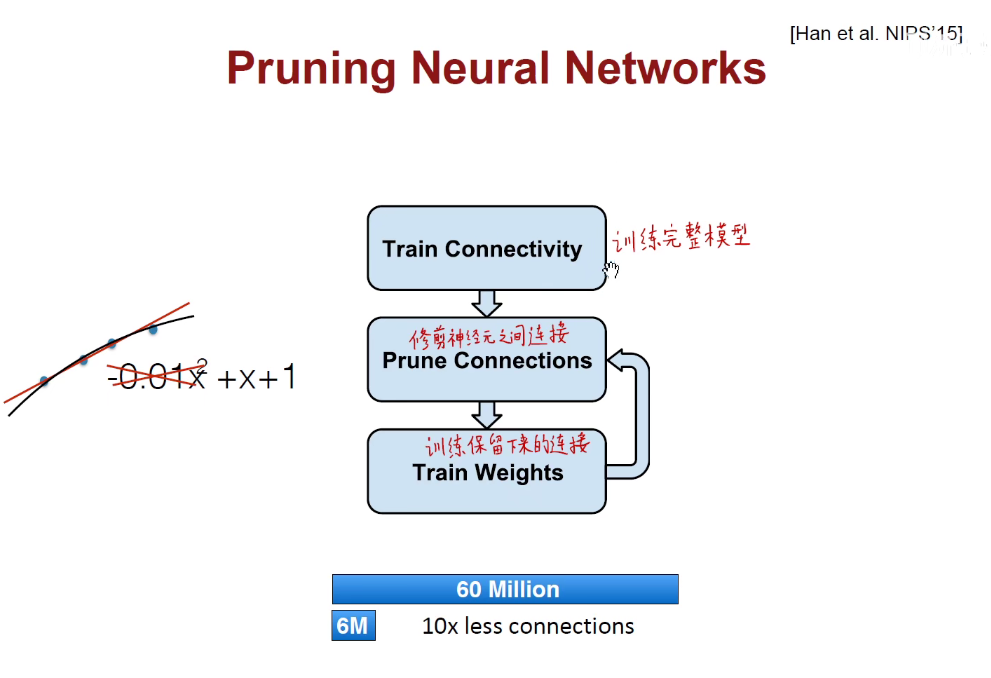
如上图:我们先训练一个完整的模型,修剪他们中间的一些连接,既可以把神经元的激活减掉,也可以把神经元面向输入的连接减掉,之后在这个残留的模型上训练保留下来的连接。这其实起到了一个正则化的效果。类比上述左图:拟合的时候将高阶的权重去掉,符合奥卡姆剃刀原理:如无必要,勿增实体。
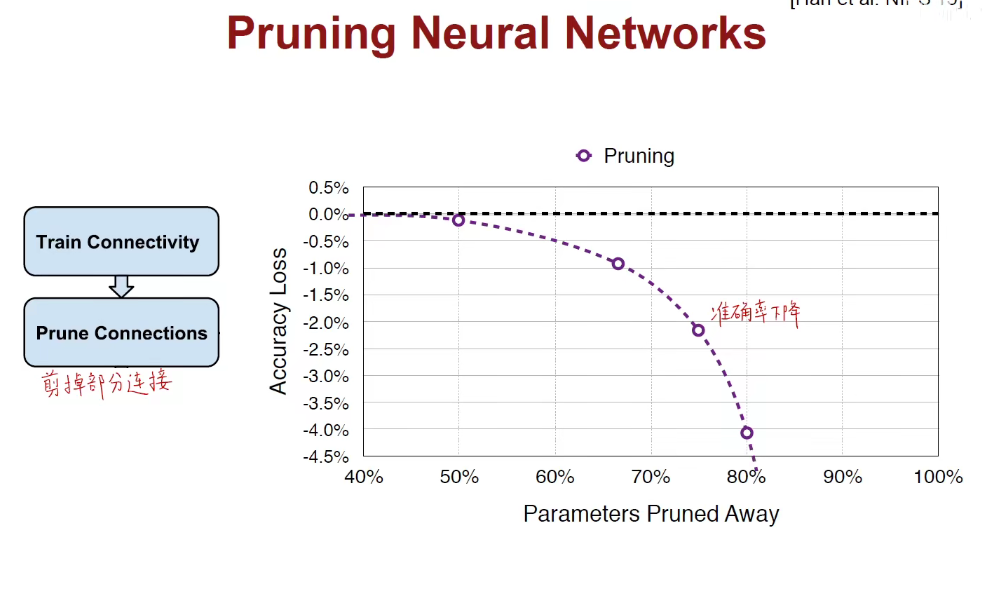
如上图:直线是完整模型,减掉越多的连接,准确率下降越快。这是符合我们的认知的。
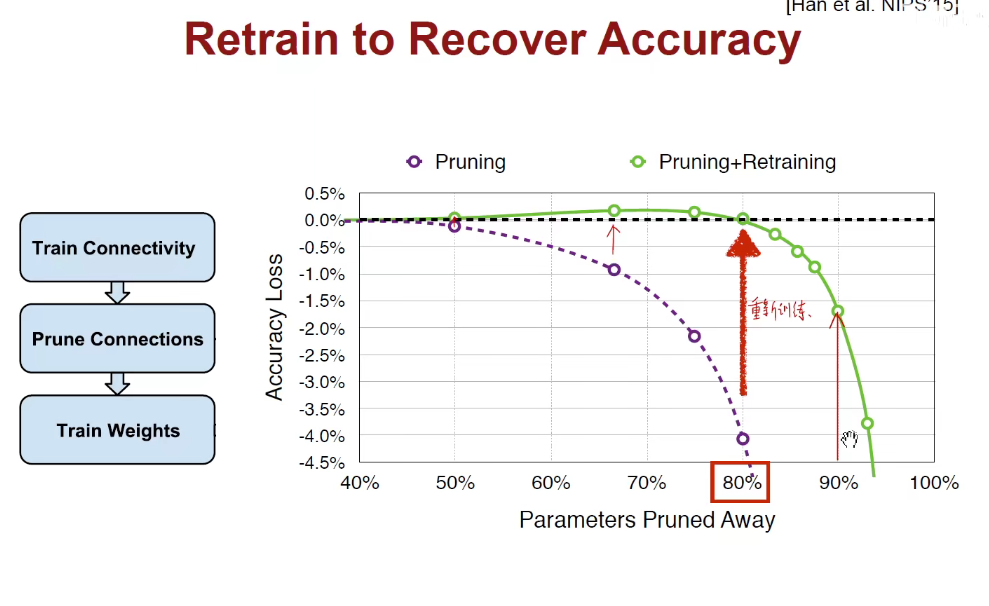
如上图,我们可以在不同比例减掉枝丫后,重新训练模型,绿色的点表明准确率有所提高。
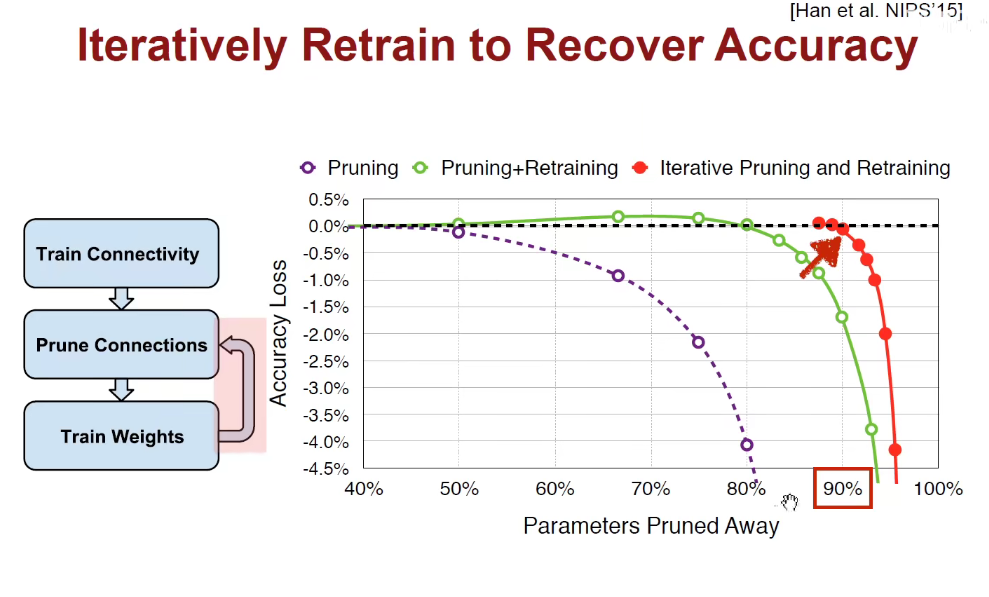
我们可以迭代的进行剪枝和训练,剪了训练,再剪再训练。。。最后如上图,把90%的枝丫都去掉,而且模型精确度还没有丢失太多。但不能剪的太厉害,否在就会欠拟合,精确率下降。
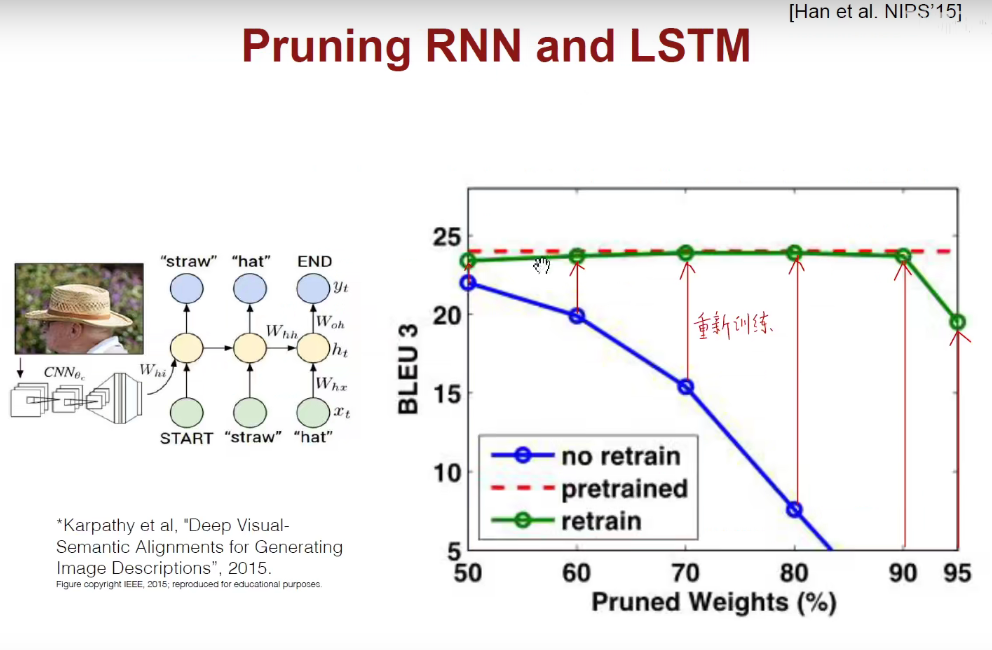

如上图,剪枝需要有限度,剪的太多模型就开始胡说八道了。。。。
类别人脑,所以又仿生学的影子在其中的。
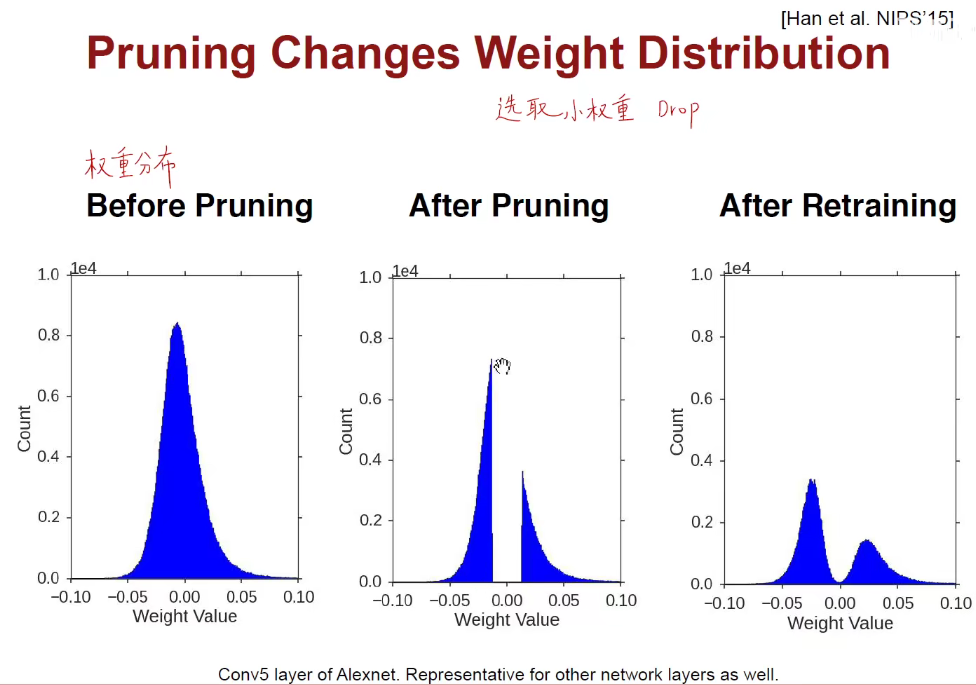
为什么要剪掉中间的区域呢?因为中间区域是权重为0附近的区域,如无必要,勿增实体,如果权重很小,我们就认为他没有必要,把0附近的权重全部剪掉,再把绝对值比较大的权重重新训练,凸显主要矛盾,引入稀疏性,让那些平时什么都不干得少爷就歇着(把他们淘汰掉),只留下那些真正发挥作用的,真正有话语权,真正有主要矛盾的权重。
1.2 Weight-Sharing
权重合并:我们可以把2附近的权重全都用2表示。这样就不需要更多的位数去存储每一个更高精度的权重,

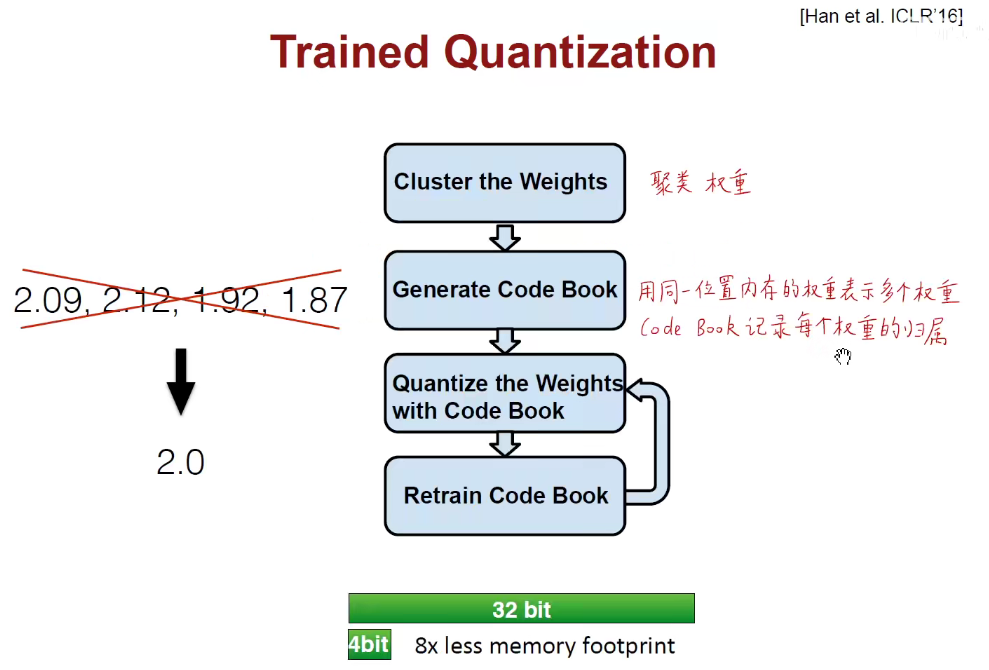
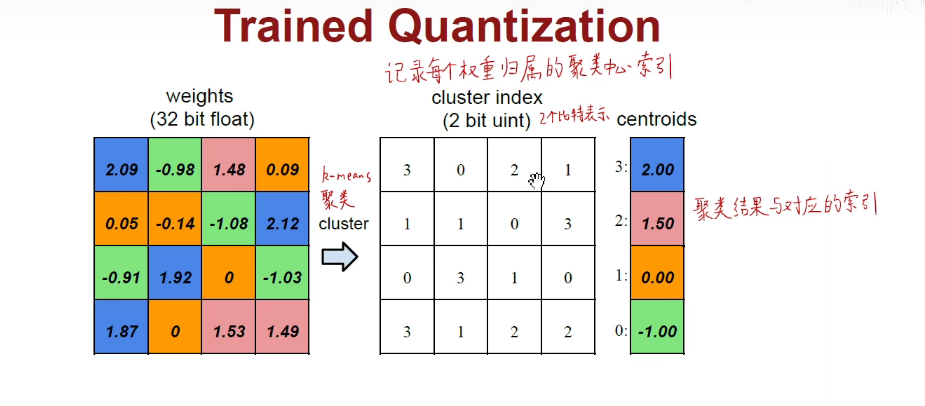
如上述左图是权重矩阵,每一个数字用32bit的浮点数来表示,所有的蓝色都是2附近的,所有的绿色都是-1附近的,所有的粉色都是1.5附近的,所有的橙色都是0附近的。我们就可以使用K-Means方法对它进行聚类。总而言之,就是把这里面的四簇挑出来,每一簇用索引0-1-2-3表示,画出对应的索引矩阵,即2.09用3表示。
上述方法相当于对权重进行了合并,且用2bit就可以,不像之前的需要32bit。
对于梯度而言是一样的,所有蓝色归结到一类,以此类推。。
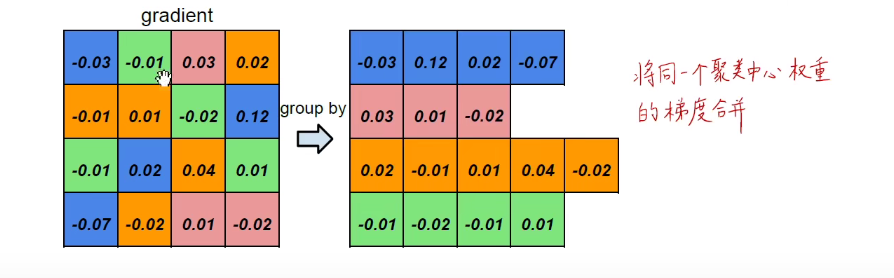
累加,求出各个颜色的梯度之和。如下图:
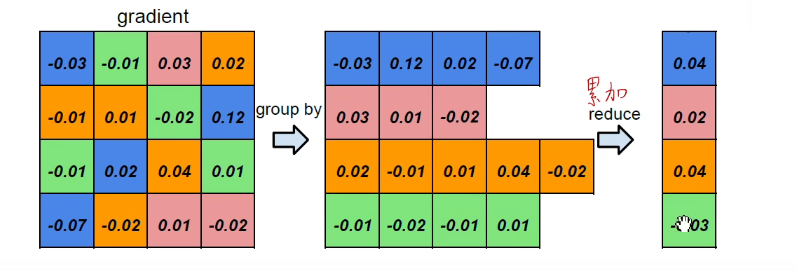
再把得到的梯度加到权重上,此处是反方向,所以是减。得到的值相当于对聚类中心进行了微调。
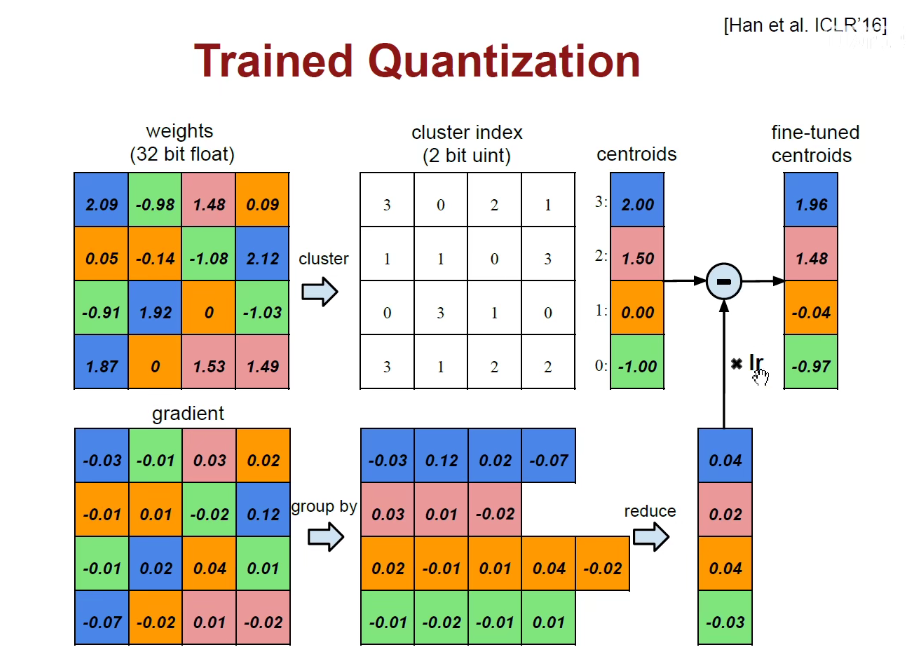
用权重的合并可以大大减少表示数字的位数。
之前提到过权重是一个连续的分布:
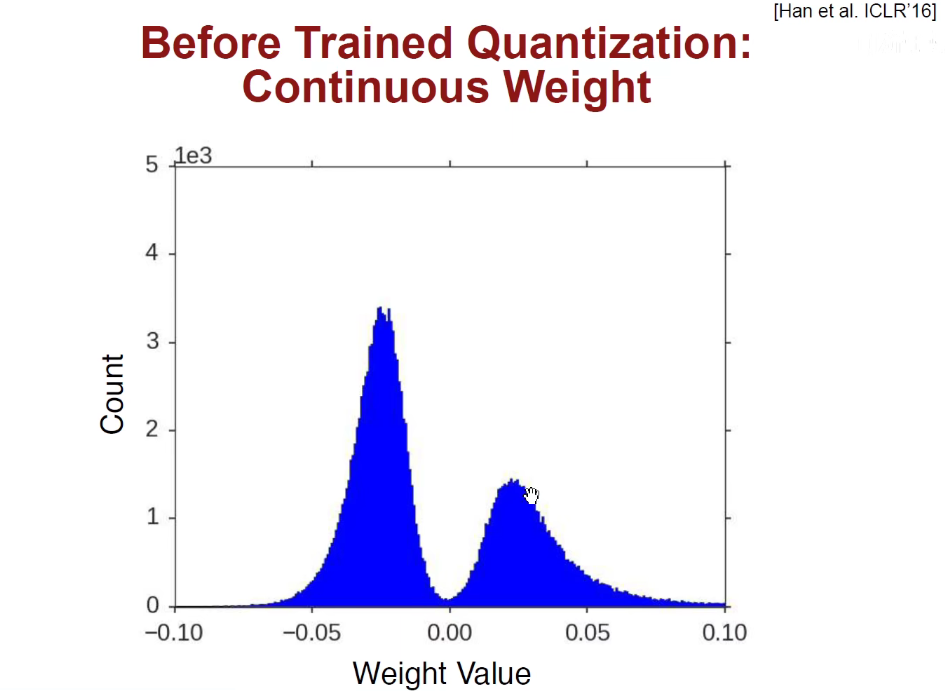
现在合并之后分布变成离散的
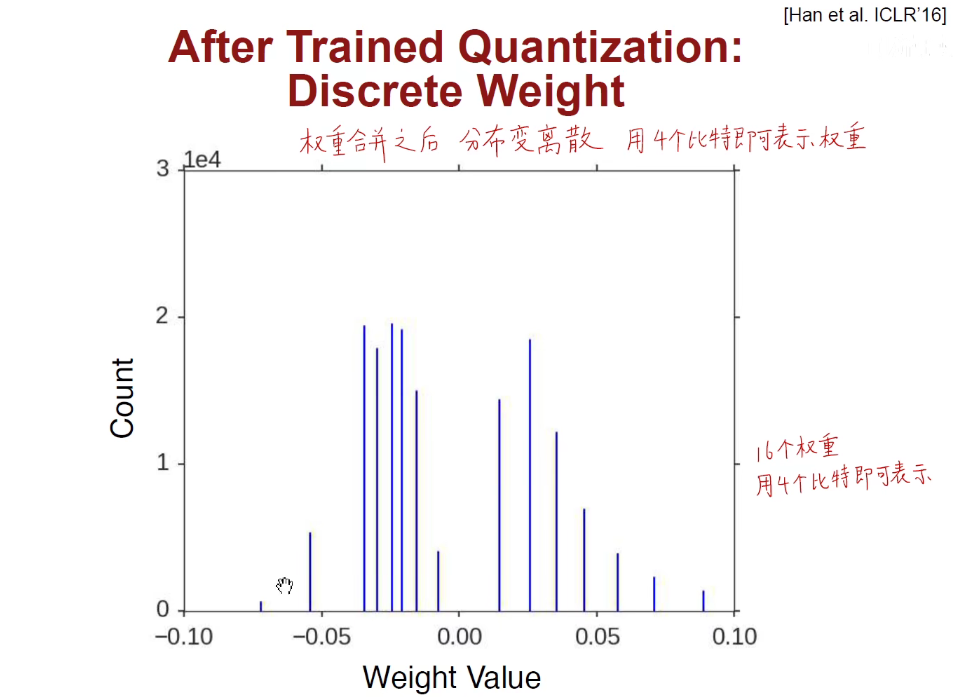
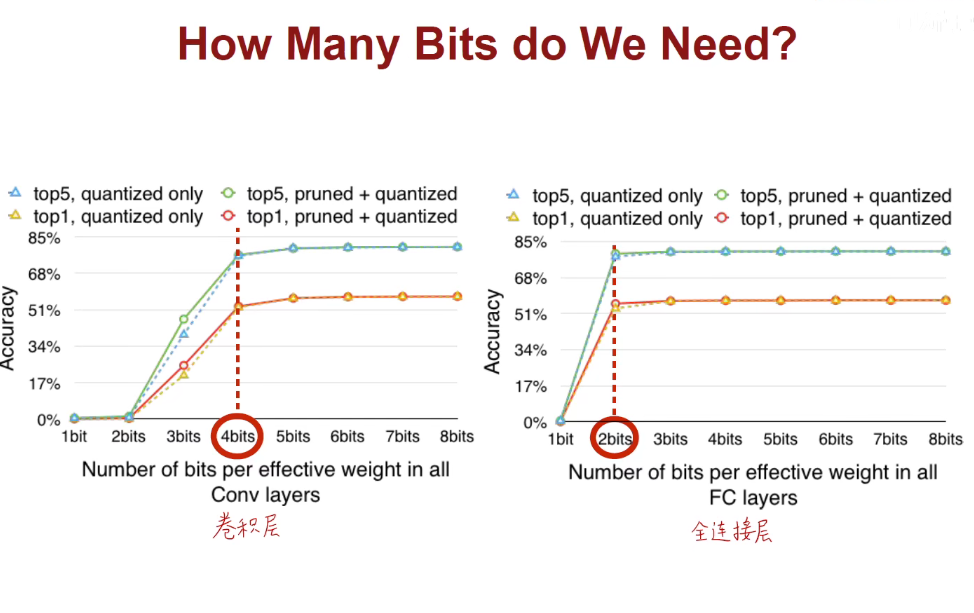
卷积层用4bit表示,FC层用2bit表示,兼顾准确率和内存。
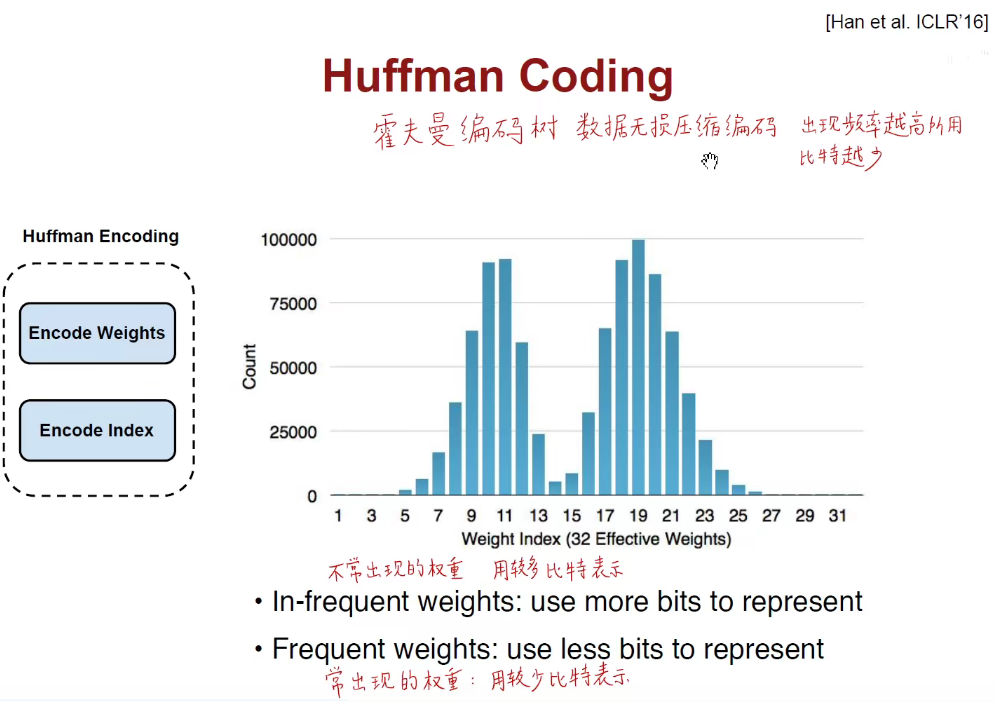
1.3 Huffman Coding
出现频率高的用短比特数表示,出现频率低的用长比特数表示。
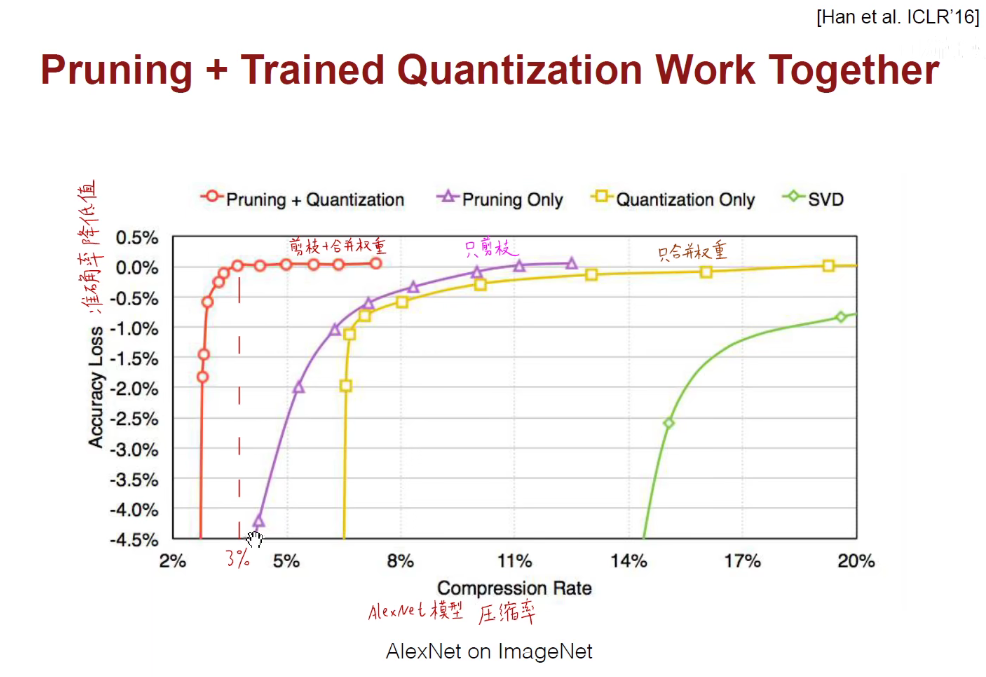
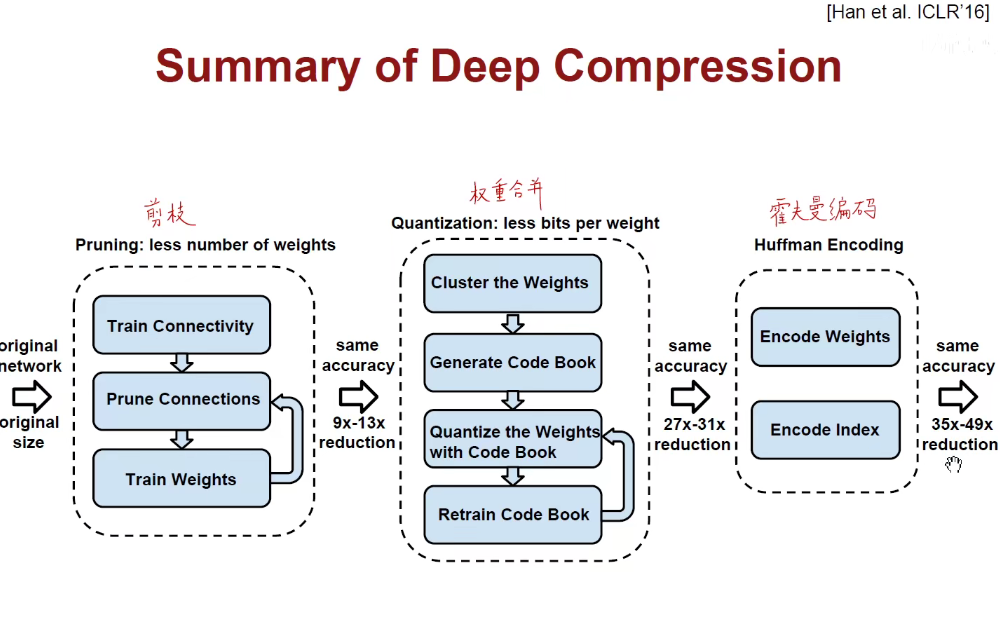
将剪枝-权重合并-霍夫曼编码合并堆叠,压缩模型。
韩松老师团队还提出了SqueezeNet,轻量化网络模型中一个典型的架构。
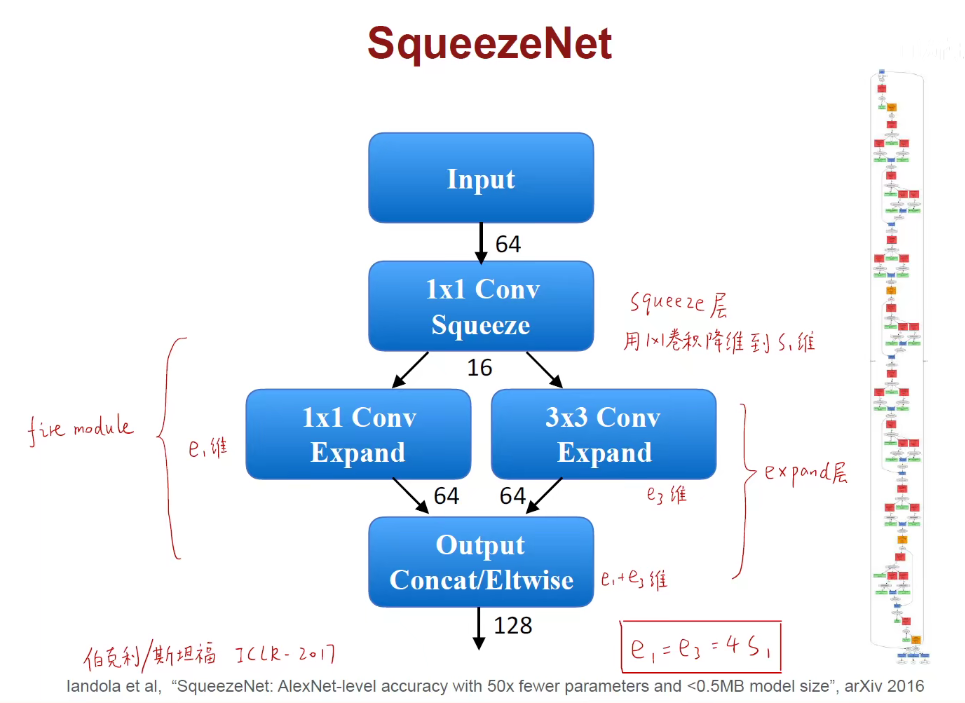
SqueezeNet核心就是fire-module,fire模块包含一个squeeze层和一个expand层,首先用1x1的卷积对它进行降维到S1维,此处的S1就是16,之后像Inception一样扩展两条路,一条路升级到e1维,另外一条路是3x3的卷积升维到e3维。此处是分别升到64维。
相当于是之前的1x1卷积得到16个feature-map,1x1卷积对上述的16个通道进行卷积得到64张纸,3x3卷积对上述的16个通道进行卷积得到64张纸。将这两个64张纸摞在一起,变成128张纸。
e1+e3相当于进行了因此Concat。
e1=e3=4S1
关键就是先用1x1卷积降维,再用不同的卷积核对它进行升维,有效的减少参数量,减少运算量。
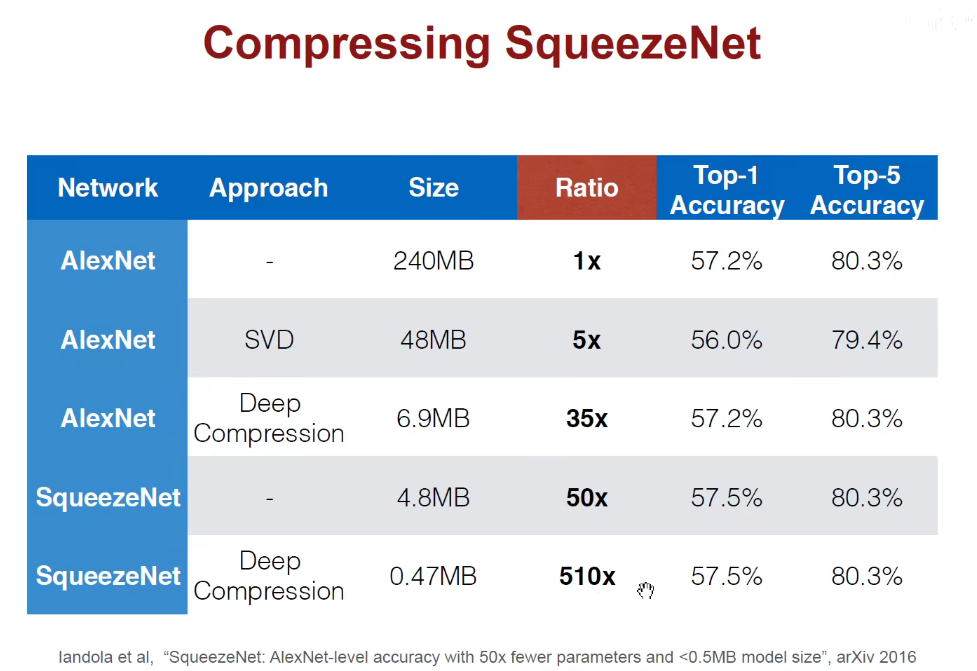
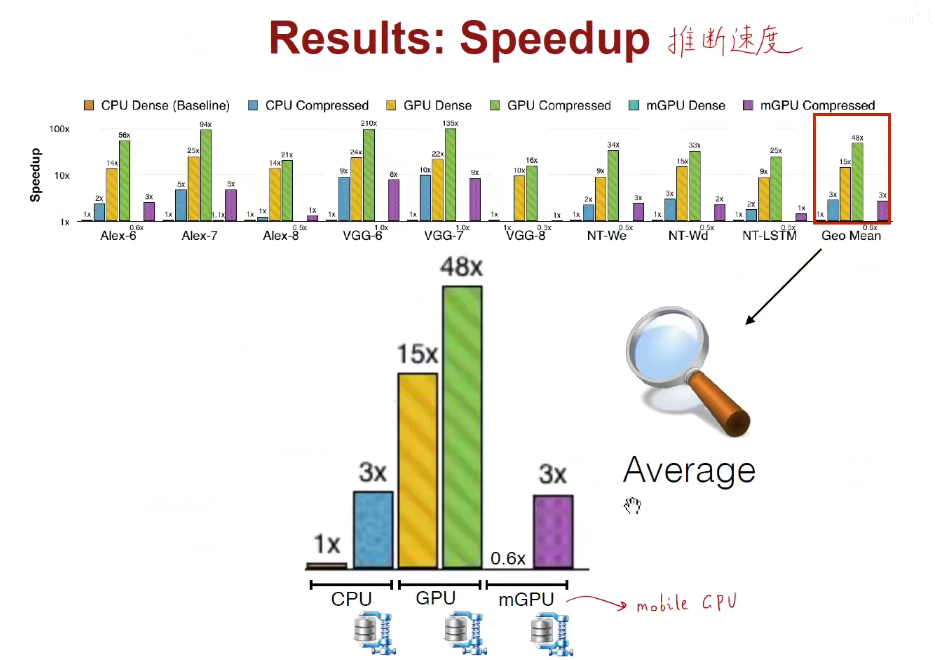
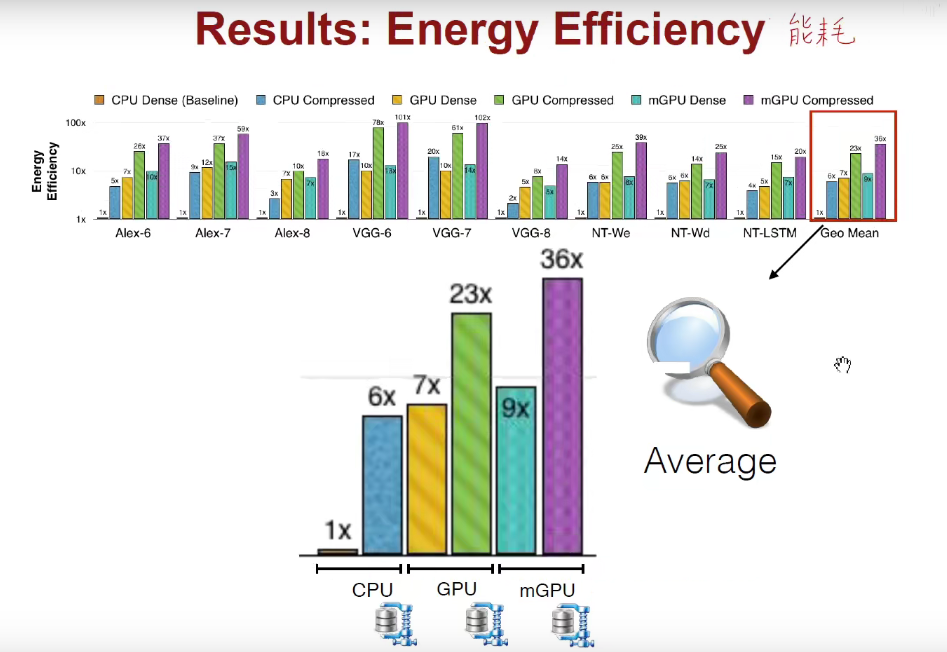
如下图:在推断速度、能耗上都是领先的。
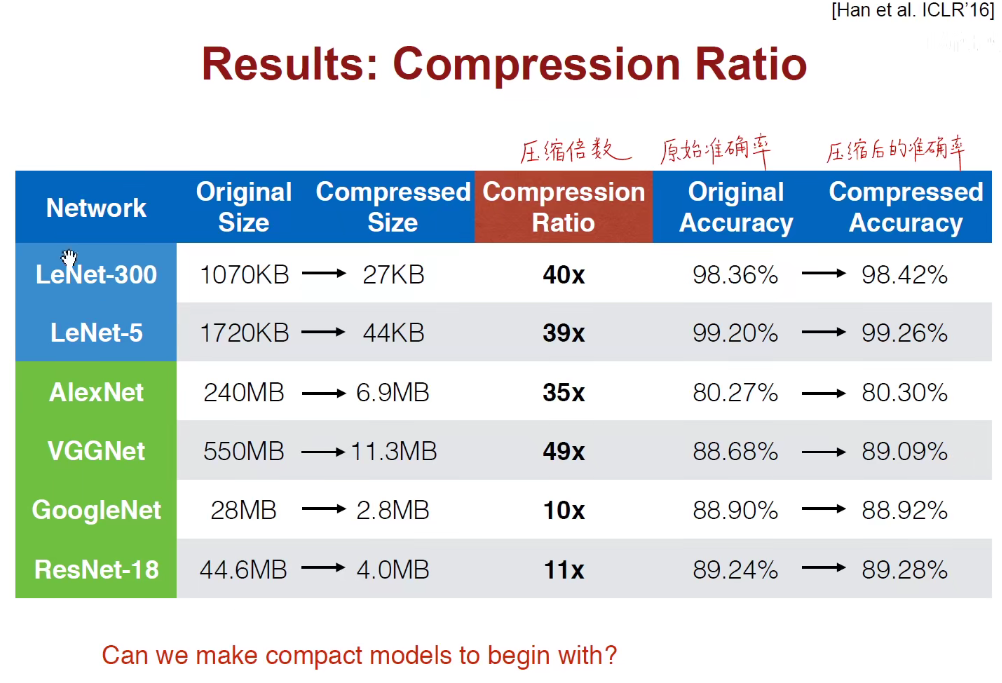
在很多人工智能公司,都采用了Deep Compression。
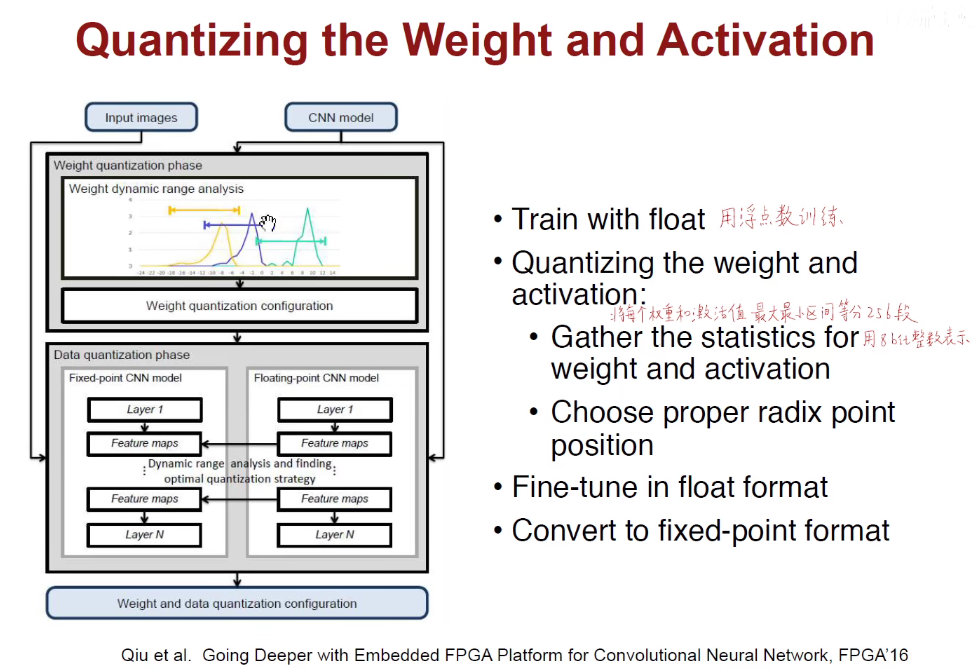
1.4 Quantization-量化
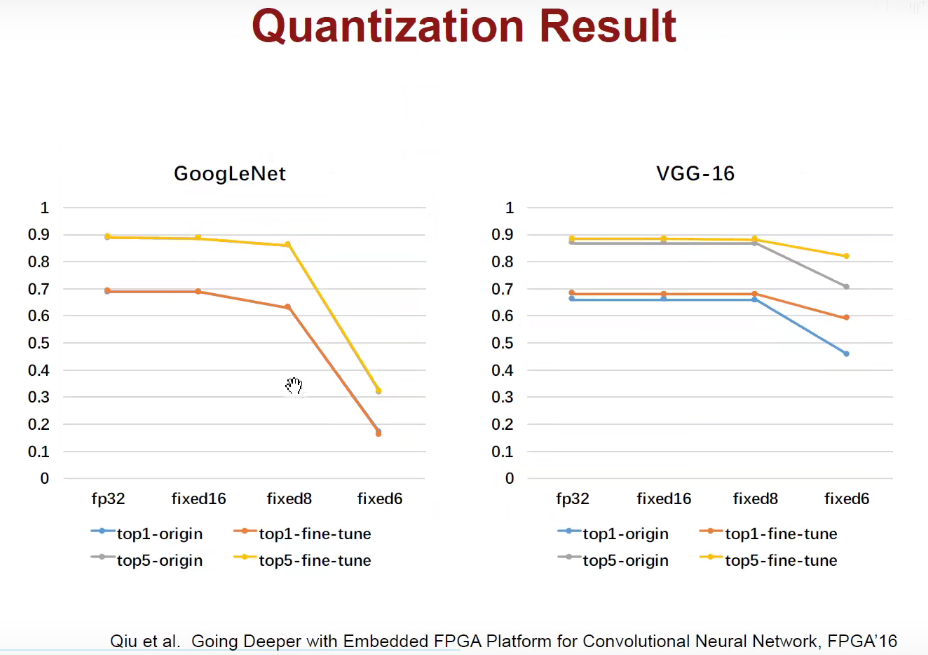
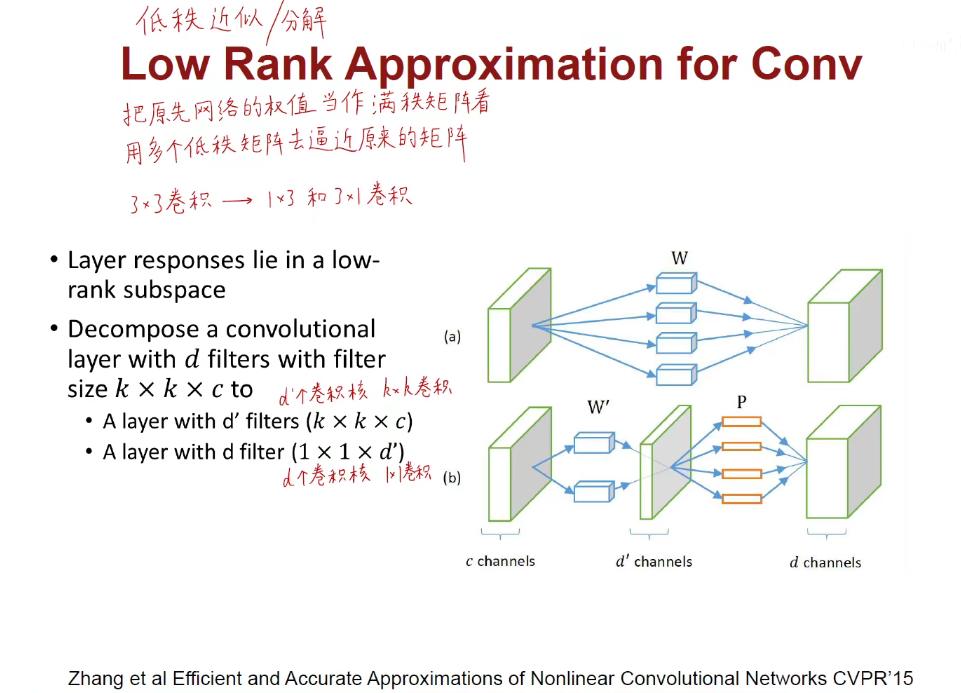
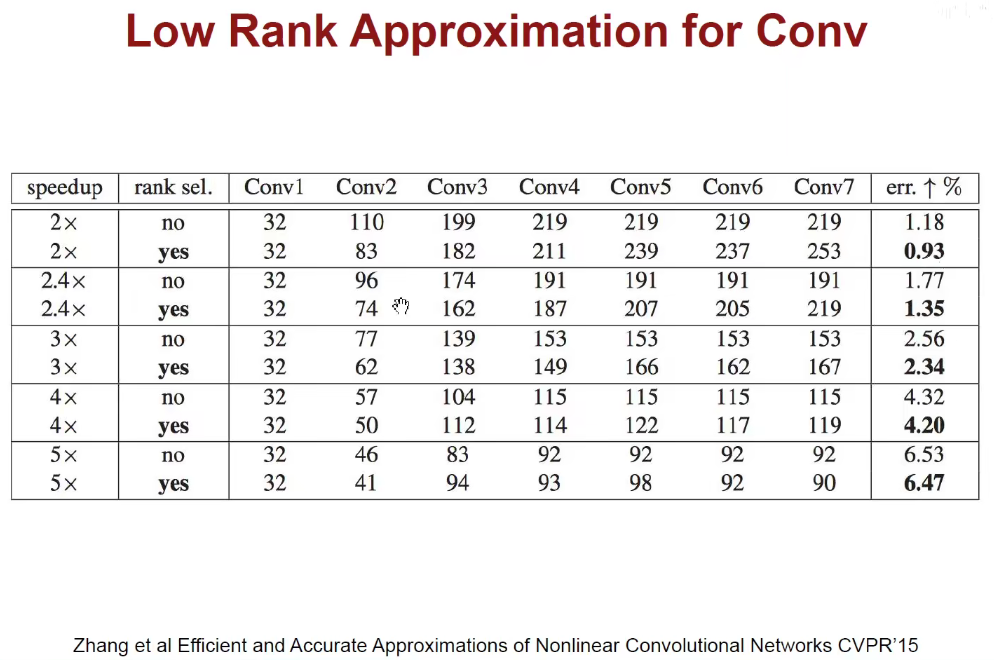
1.5 Low Rank Approximation

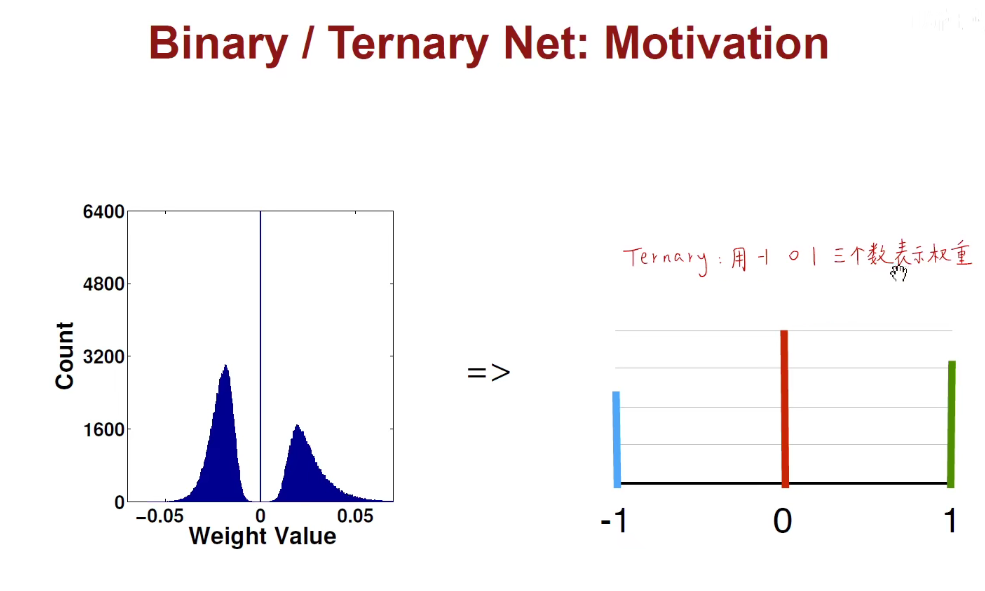
1.6 Binary/Ternary Net(二值/三值量化)
我们想用更少的位数来表示权重和激活值,那最少能用多少位呢?
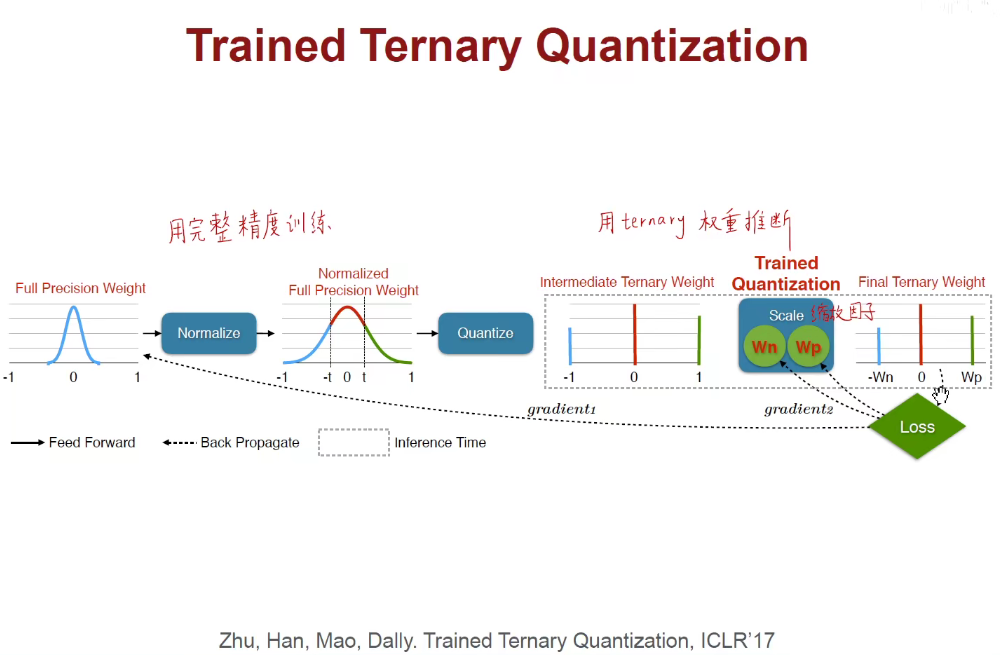
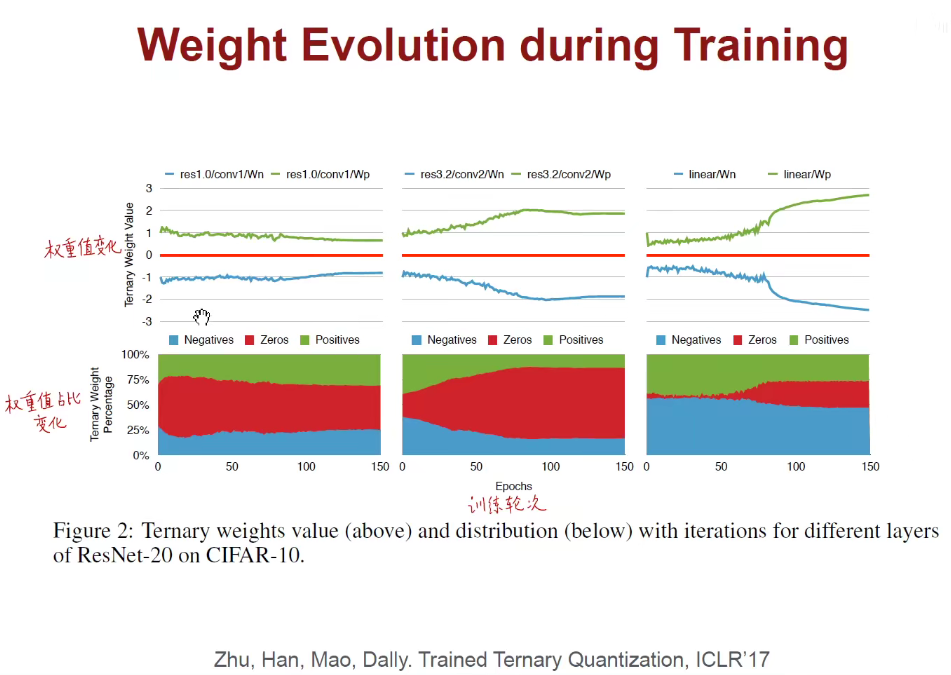
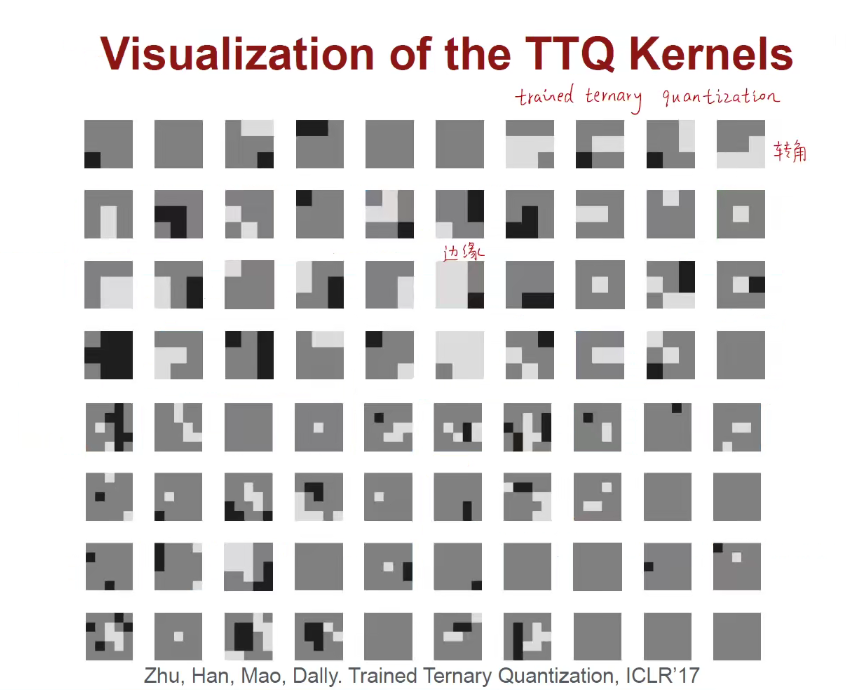
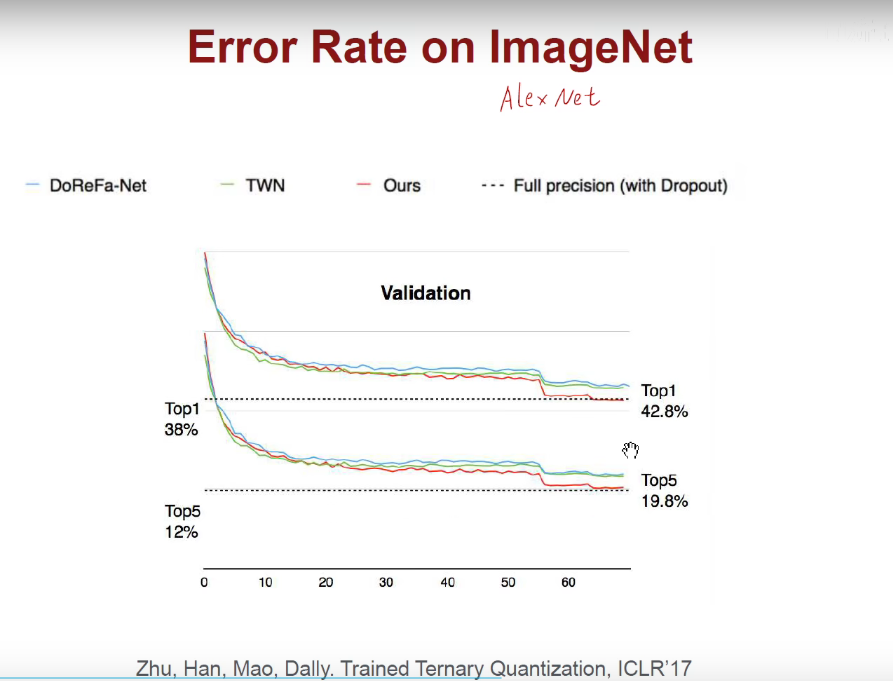
1.7 Winograd Transformation

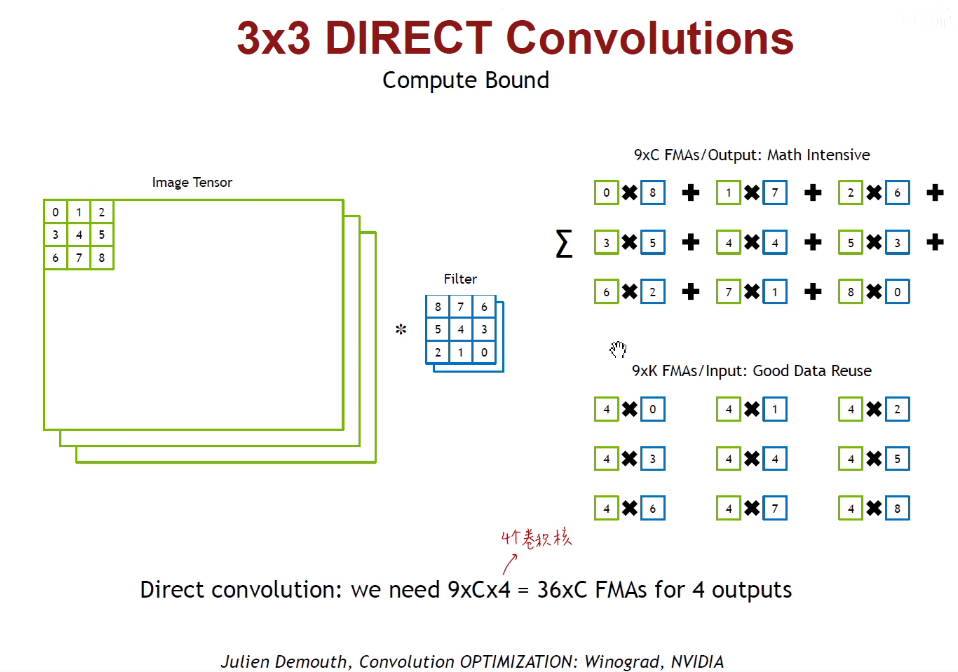
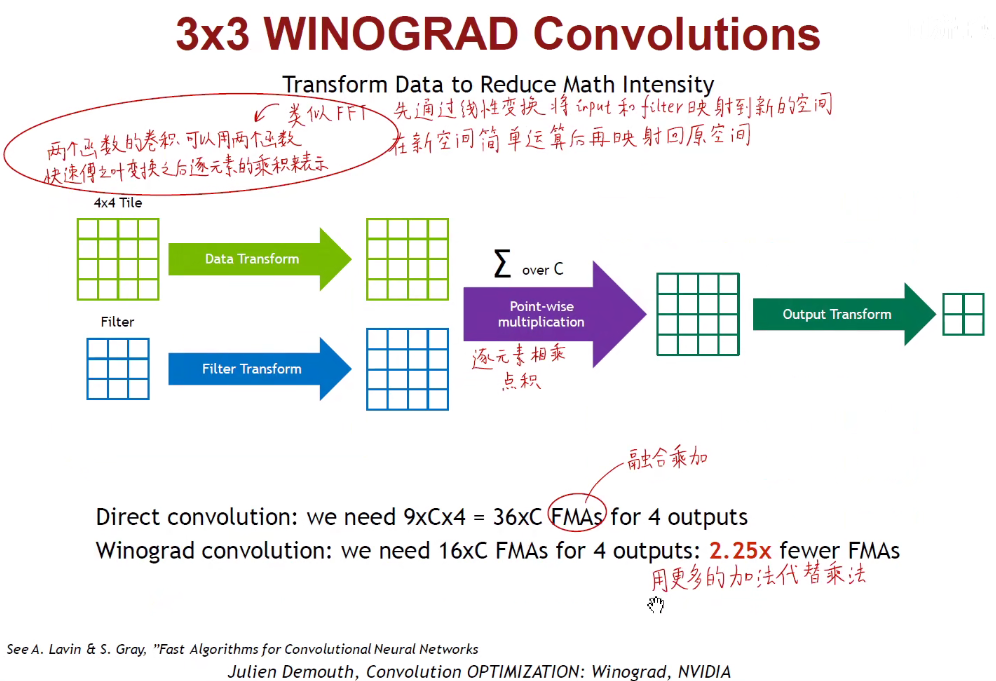
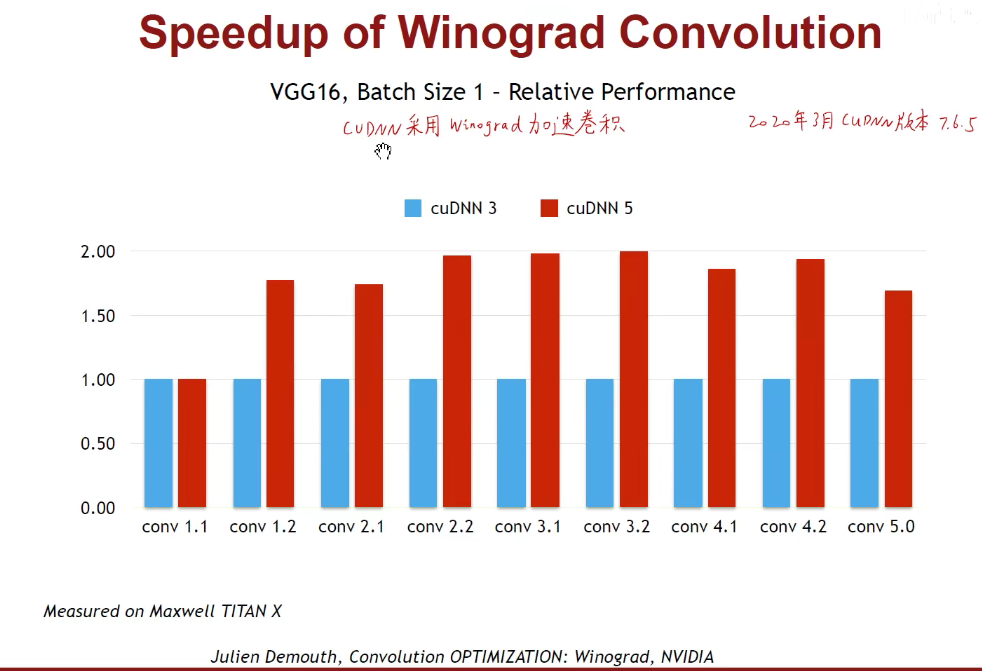
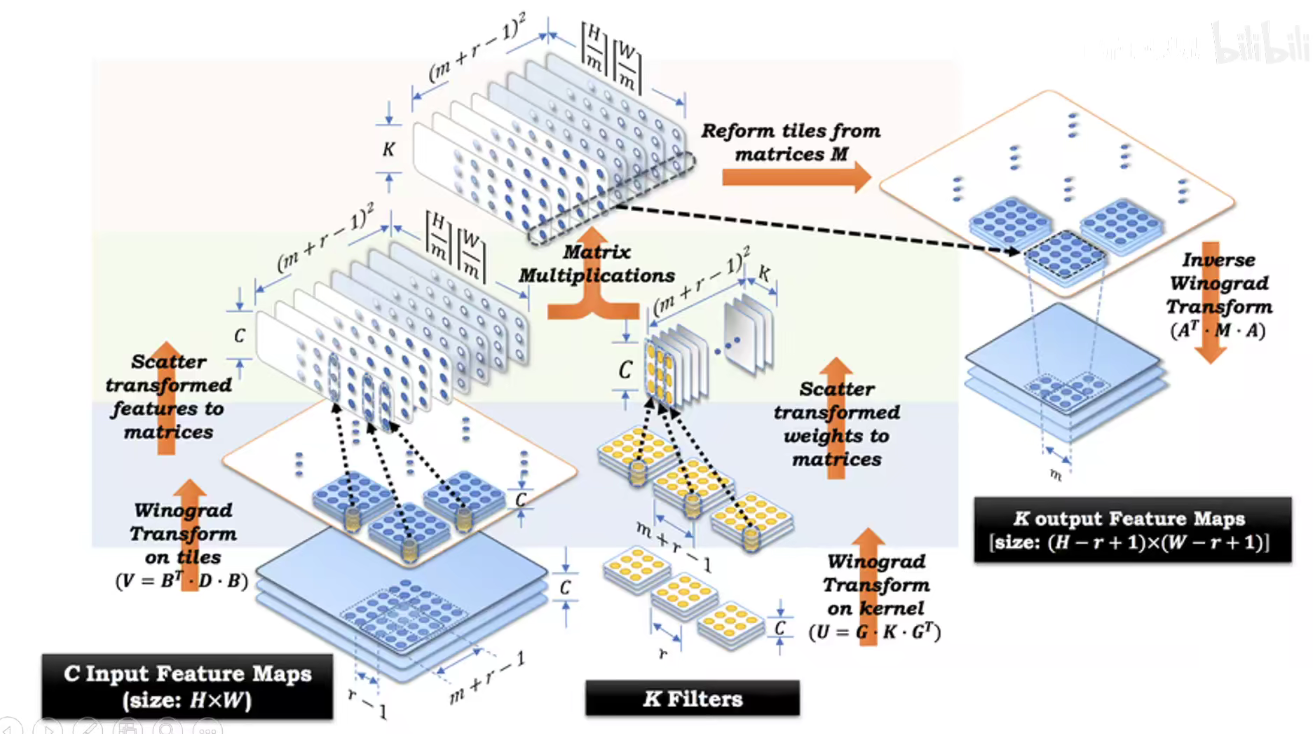
2. 加速推断的硬件(AI芯片)

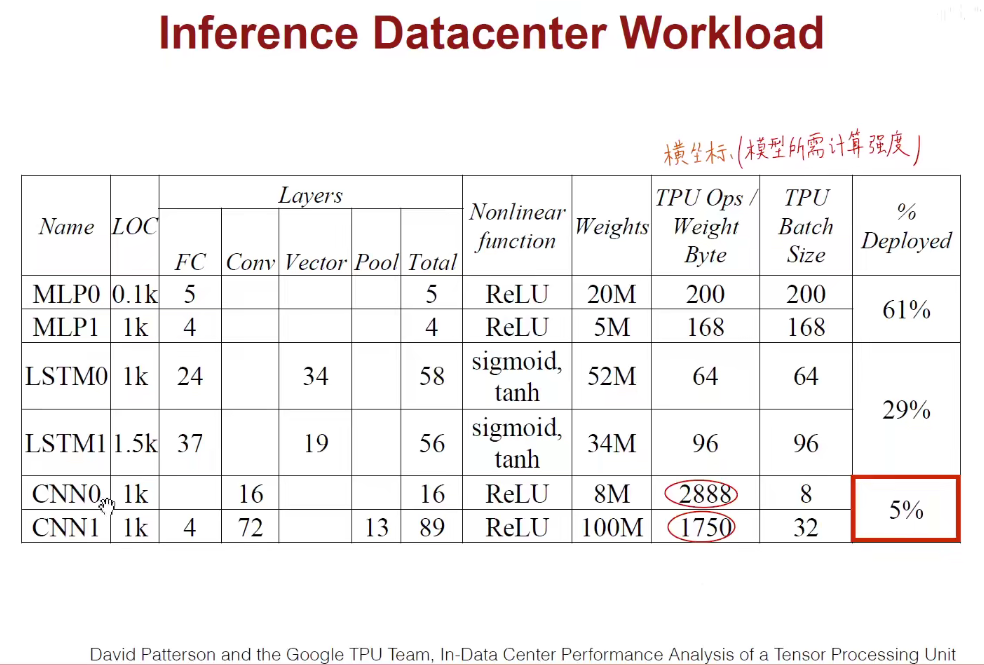
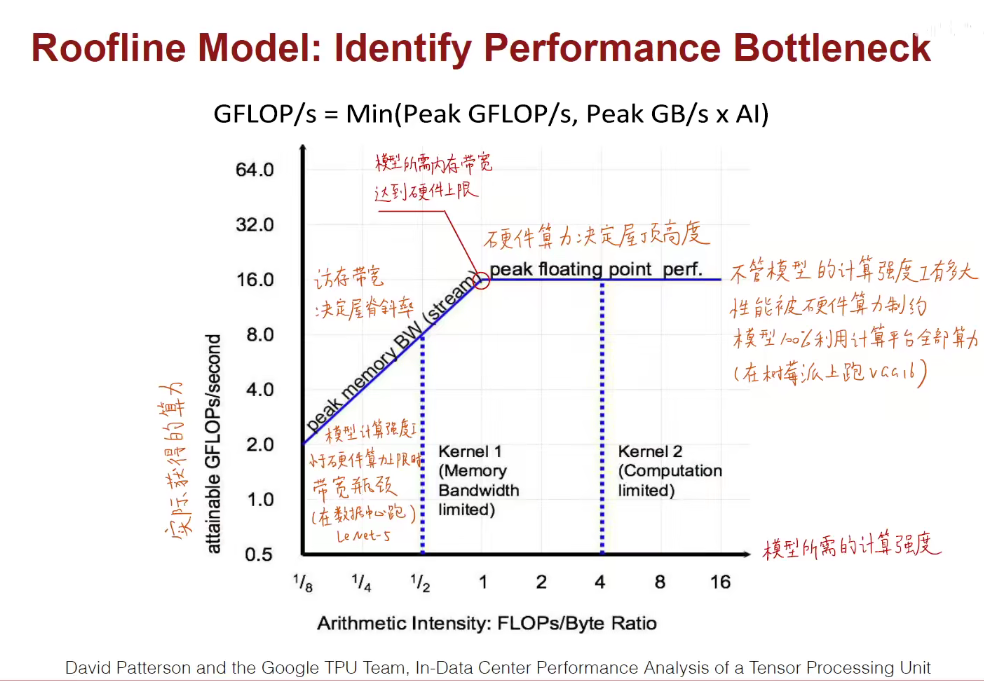
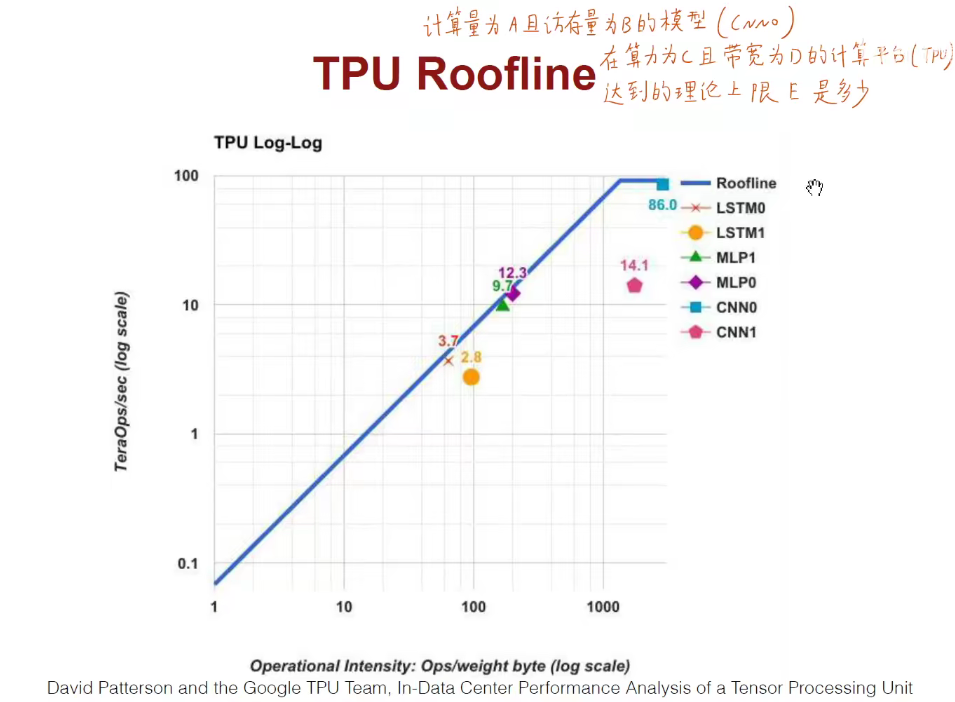
模型太牛逼,硬件很垃圾 or 硬件很牛逼,模型很垃圾。
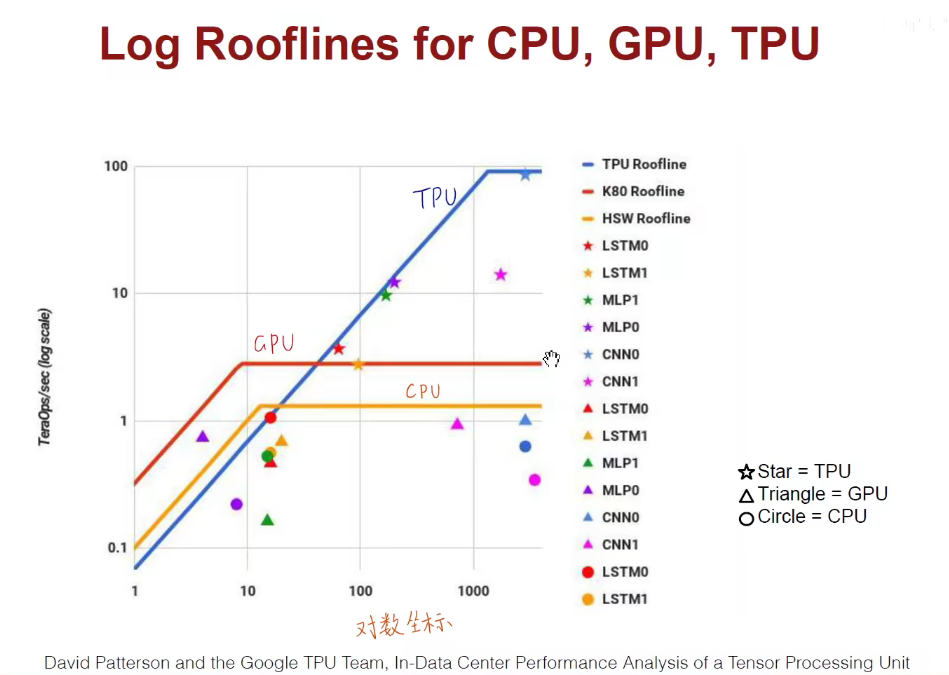
上述是在对数坐标中,更详细。
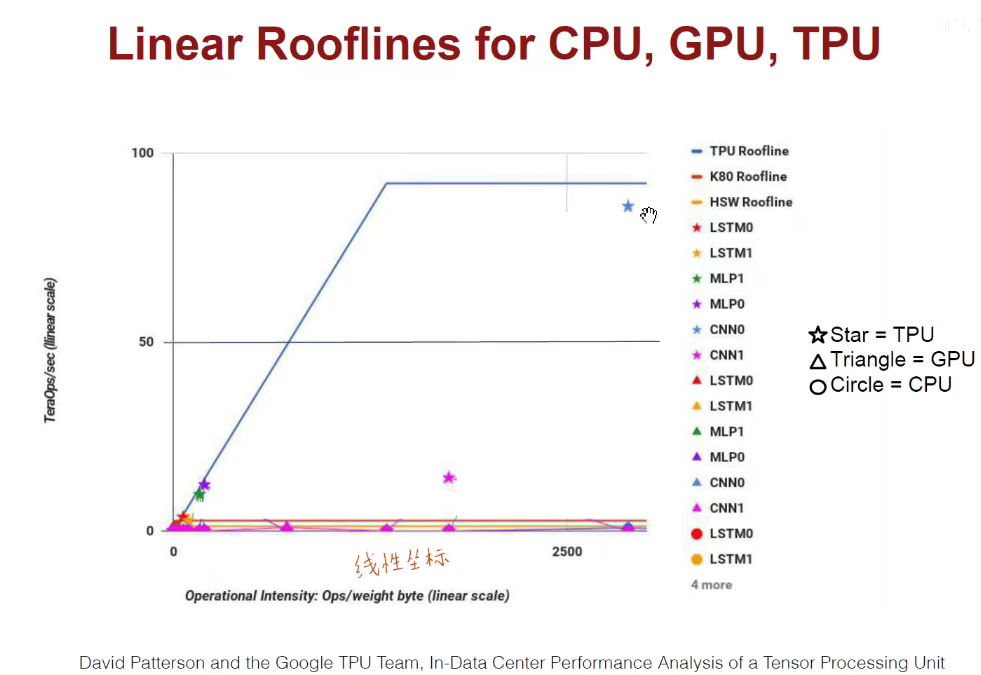
上述是在线性坐标中,更直观。


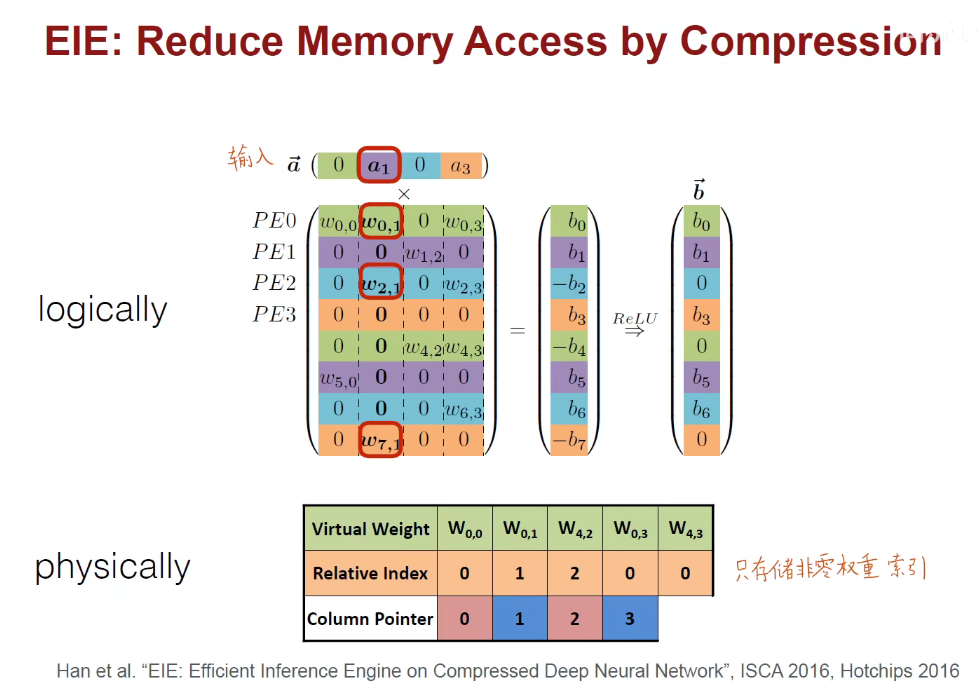
3 加速推断的算法
3.1 并行

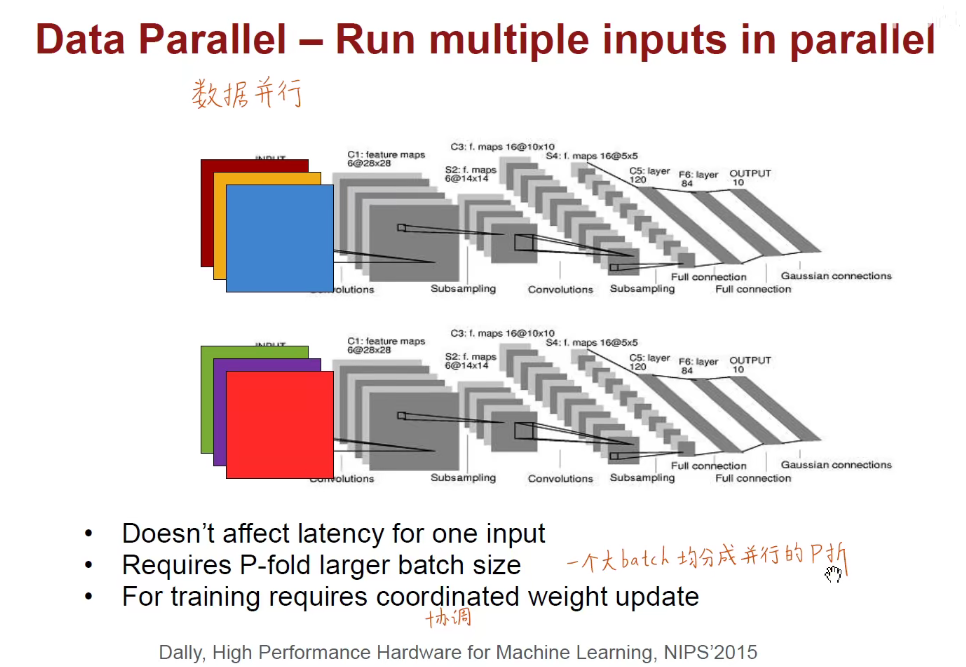
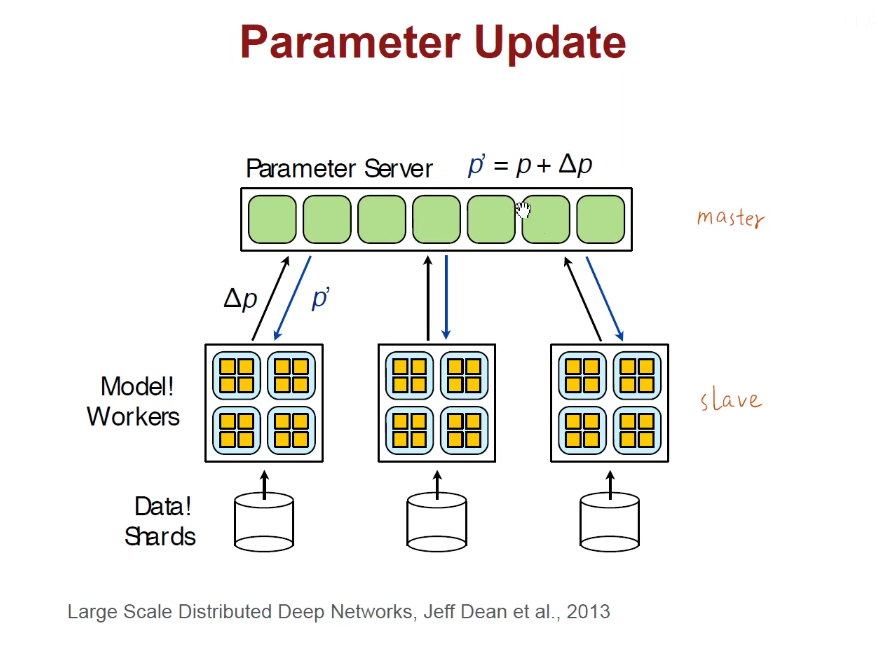
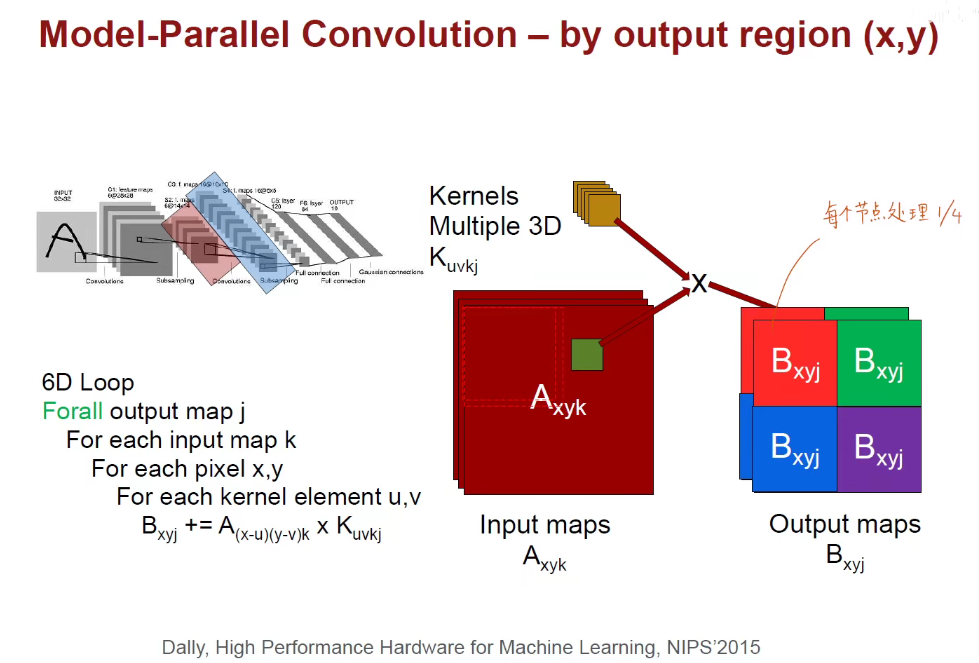
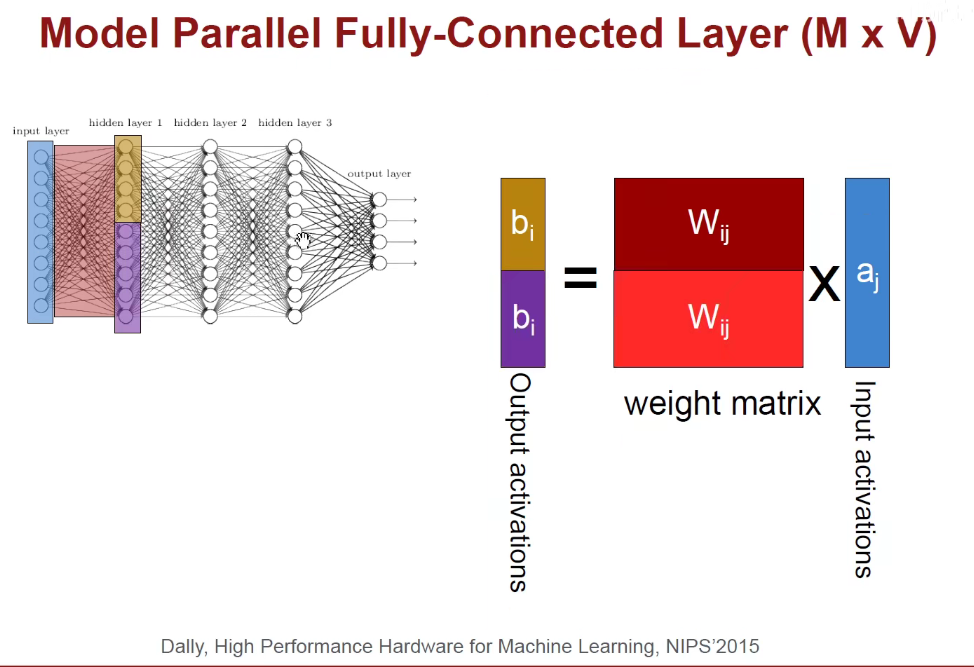
将模型进行均分,每一个节点算一半的模型。


3.2 Mixed Precision with FP16 and FP32

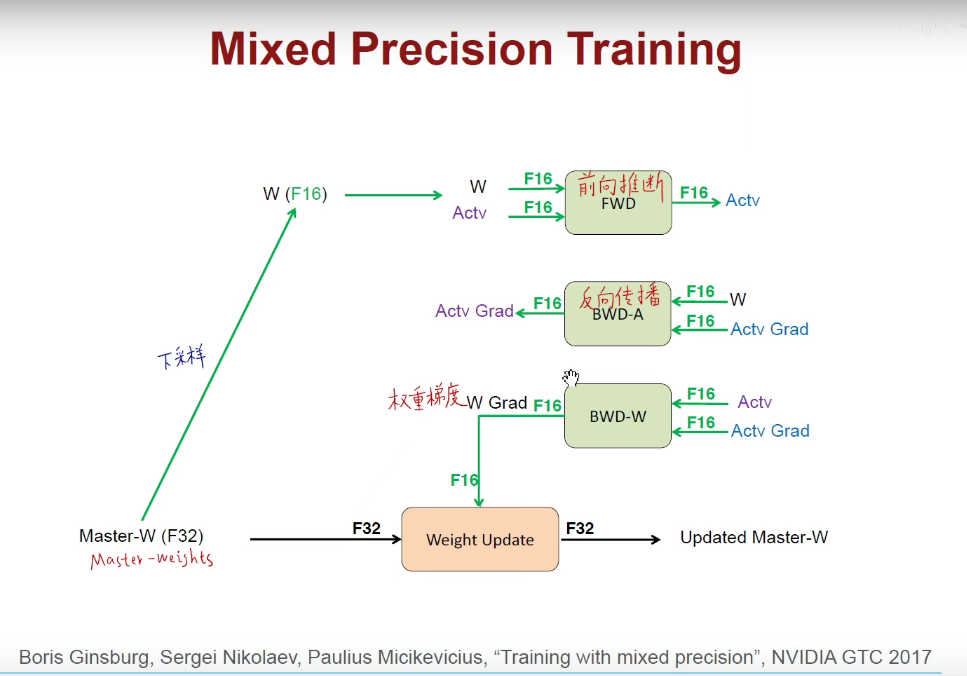
16位参与前向和反向运算,把16位结果加到32位上,进行权重的更新。
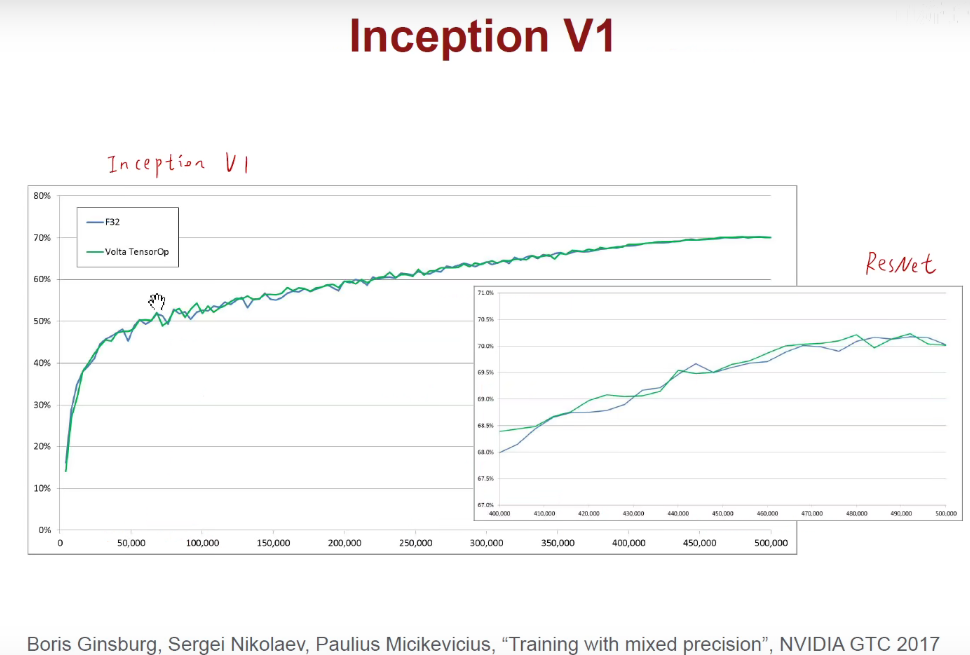
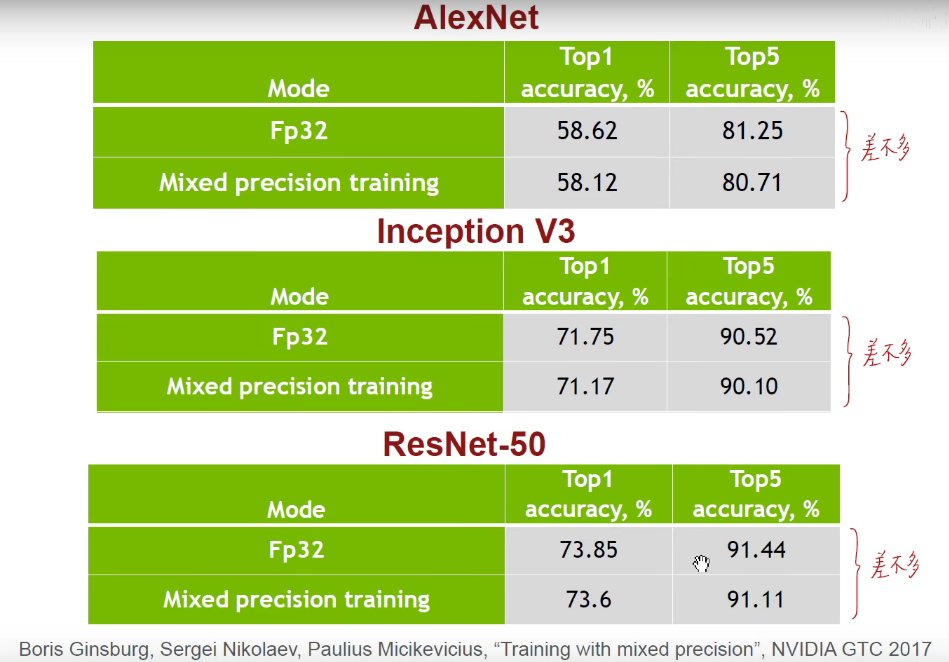
可以看到,效果差不多,但是占的比特位少了。
3.3 Model Distillation(模型蒸馏)-Hinton提出

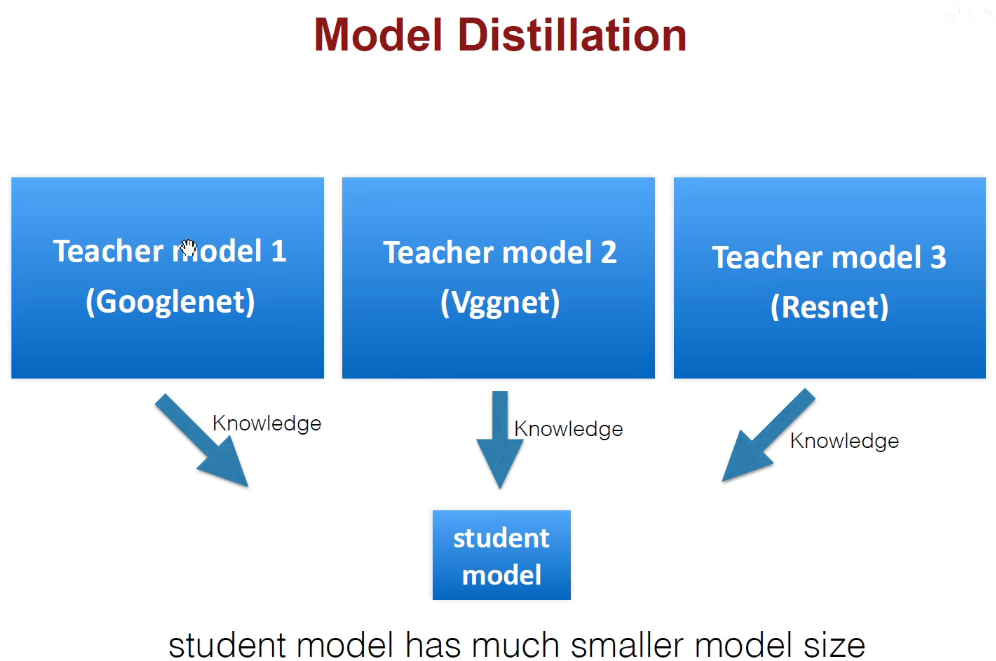
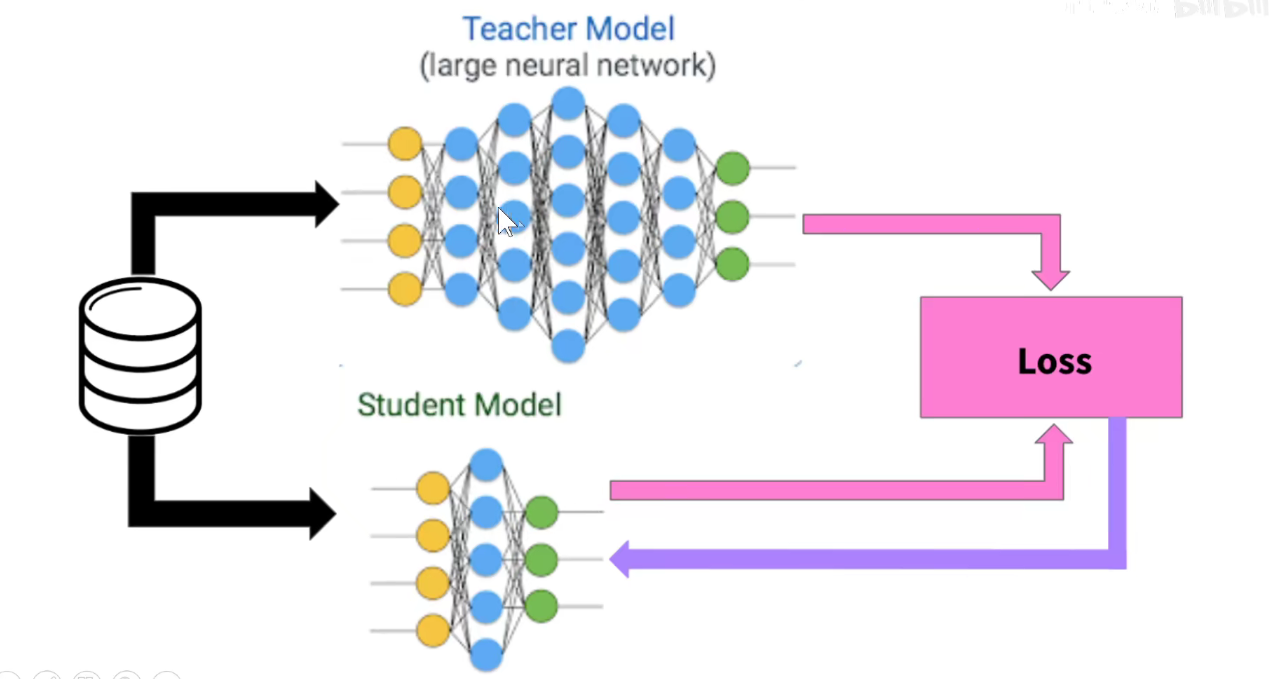
我们有很多预训练的模型,可以用预训练的模型当老师,他们都是久经沙场、德高望重的老师,但也非常臃肿,现在想得到一个轻量化的学生模型,学生模型的尺寸要远远小于老师模型,怎么做呢?

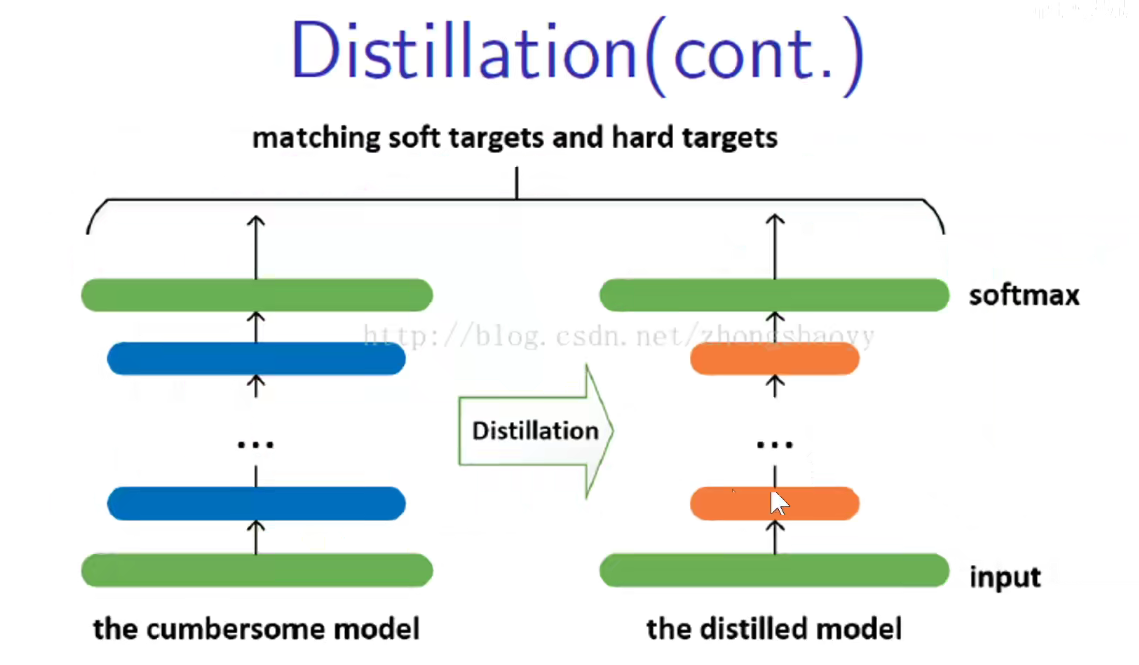
如上图:(第一行)原来的标签是一个one-hot编码,只有真正的标签是1,其他都是0,丢失了其他类别之间的关系。用老师的角度来看,猫和豹子、老虎等都是有关系的,但是独热编码确实冷冰冰的过滤掉他们之间的相关关系。
(第二行):用teacher模型去预测的效果。我们不想把概率小的标签全部设为0,想保留一些他们之间的相关关系。
(第三行):做变换。
具体做法如下:使用蒸馏的方法。
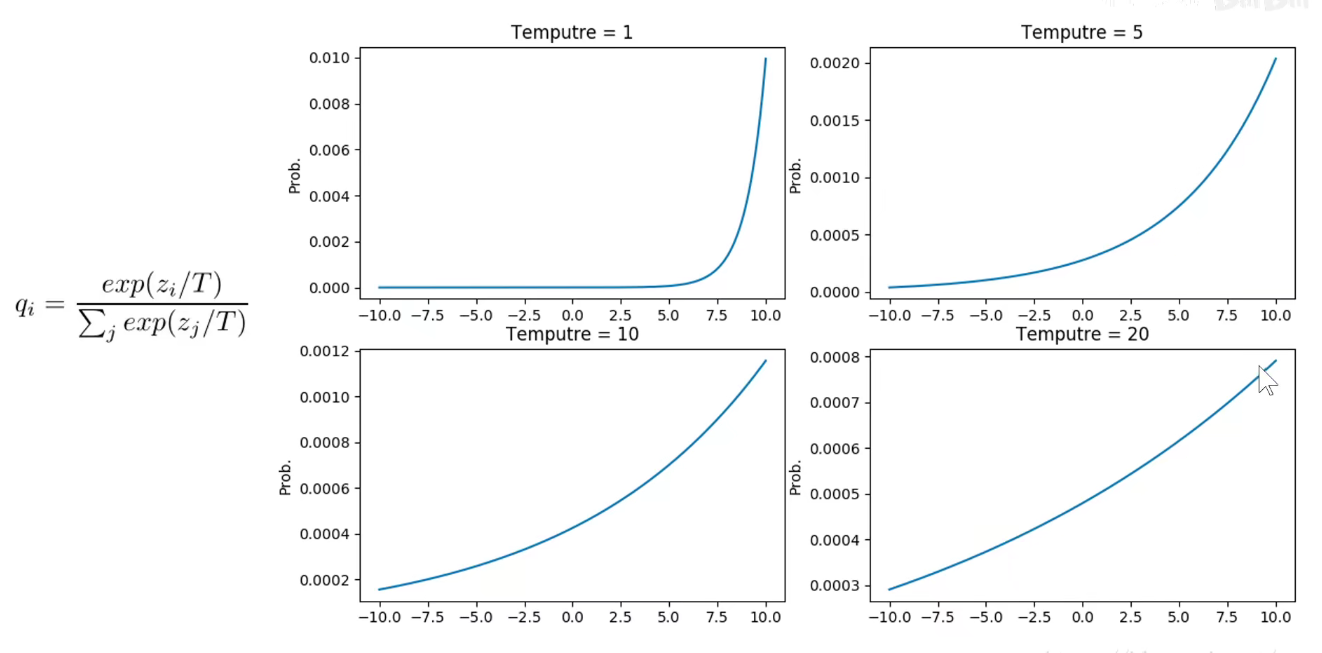
T接近于0,类似于第一行的独热编码。 T接近于1,类似于第二行的普通softmax,T接近于正无穷,类似于第三行,均匀分布,越能体现相似类别之间的关系。

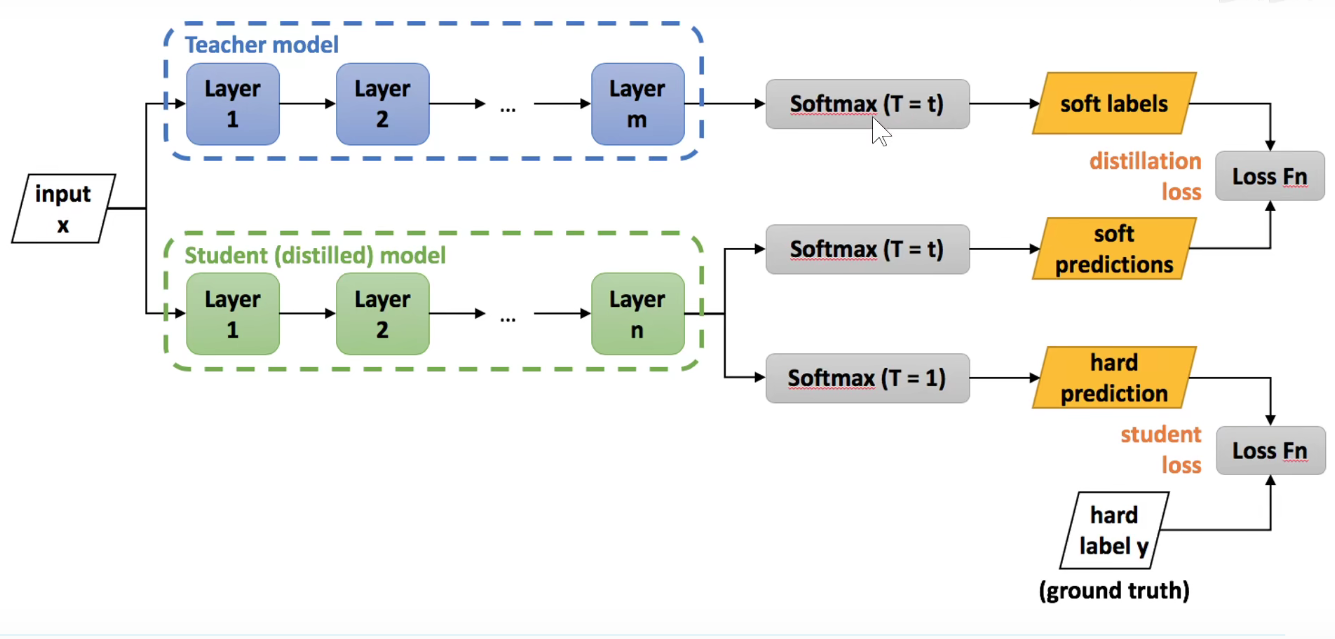
把上述两个损失函数按比例加起来,就是最终的损失函数。
T越大,平滑效果越好。分类结果越接近于均匀分布。类似于“绑着沙袋练轻功,训练时绑着沙袋T=t,把真正标签的概率压低了,将其他标签的概率相对提高了”。

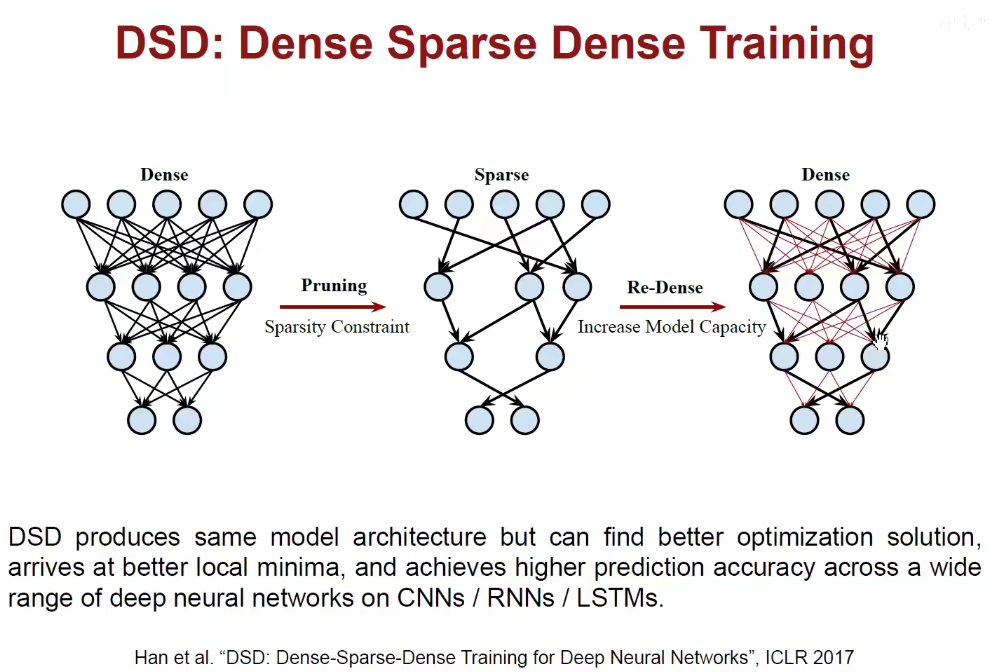
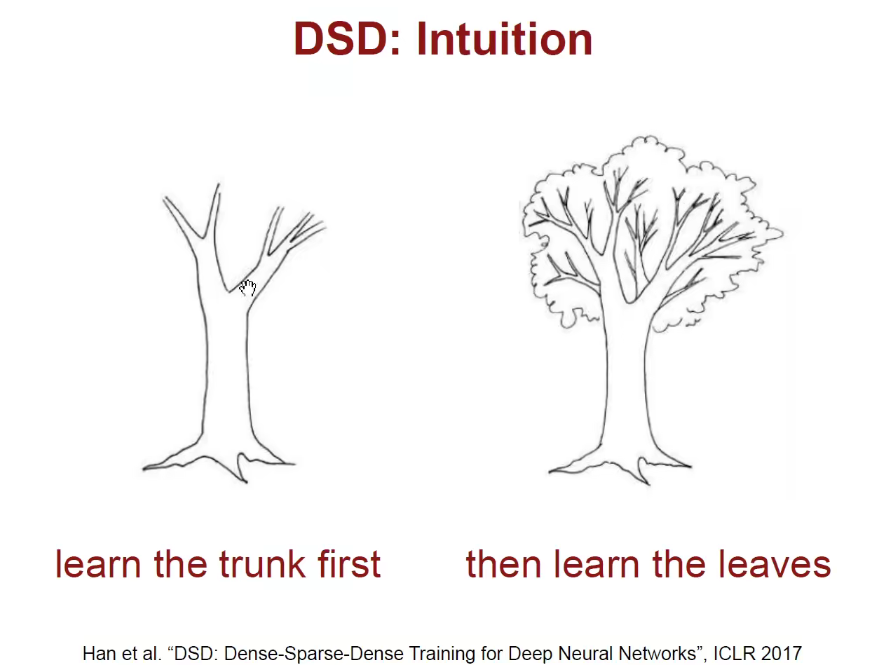
3.4 DSD
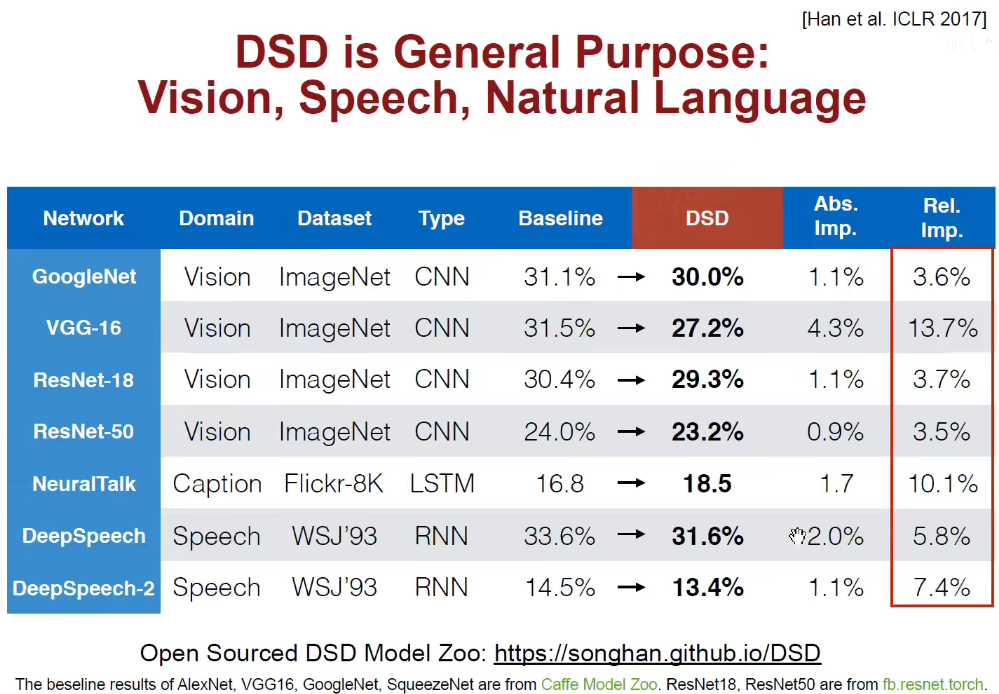
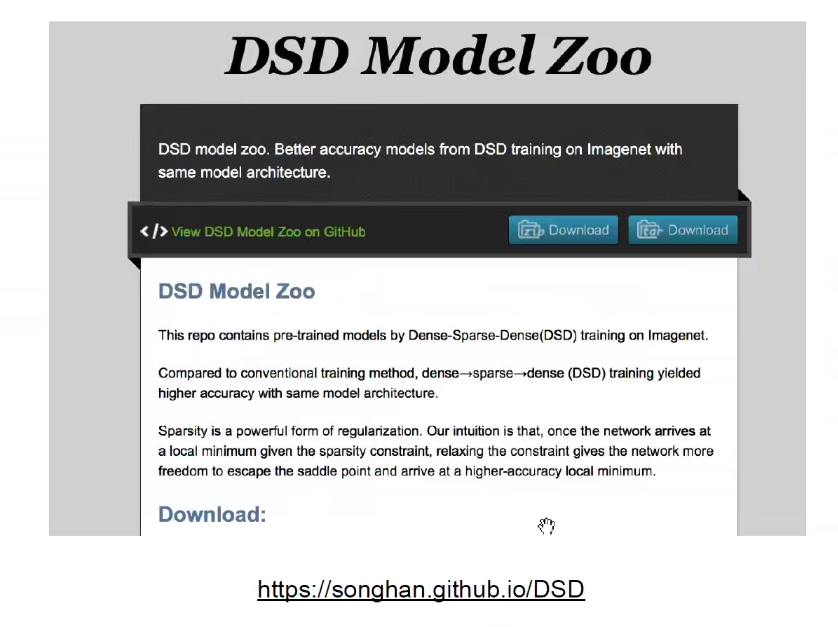
韩松老师开源部分预训练模型:

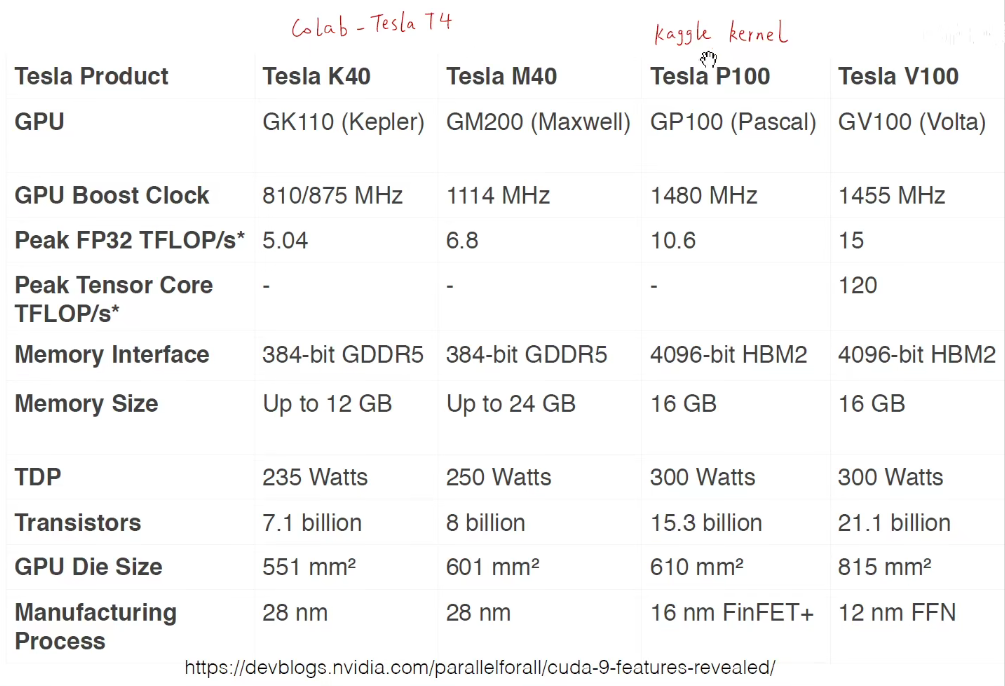
4 加速推断的硬件(已过时,硬件总是在发展)
还是稍微看一下吧。。。

5 Feature