Author: haoransun
WeChat: SHR—97
图片&知识点来源:CS231N
之前已经学过了多层感知器-MLP-全连接神经网络和CNN-卷积神经网络。
MLP:每一层都与上一层神经元的输出密集相连,所以也称为全连接神经网络-FC。
CNN:专门用来处理CV,处理图像数据的神经网络。之前讲过CNN具有局部连接、权值共享、下采样等特点,回顾了2012-2018经典CNN架构。1998-LeNet、2012-AlexNet、2013-ZFNet、2014-VGGNet/GoogLeNet-Inception-V1/2/3/、2015-ResNet、SeNet、MobileNet、NASNet等等,它们大都是用来解决计算机视觉问题的。层数越来越深,精度度越来越高,同时人们在想各种各样的方法在网络加深的同时来进行模型的优化,如增加残差模块。我们希望找到参数量少-计算量少-精确度高的模型。
今天学习Recurrent-Neural-Networks:循环神经网络:专门用来处理序列数据,在自然语言处理-NLP、视频分类、语音识别、文本情感分析那些涉及序列数据问题的处理上很不错,它可以保留先后发生的记忆,
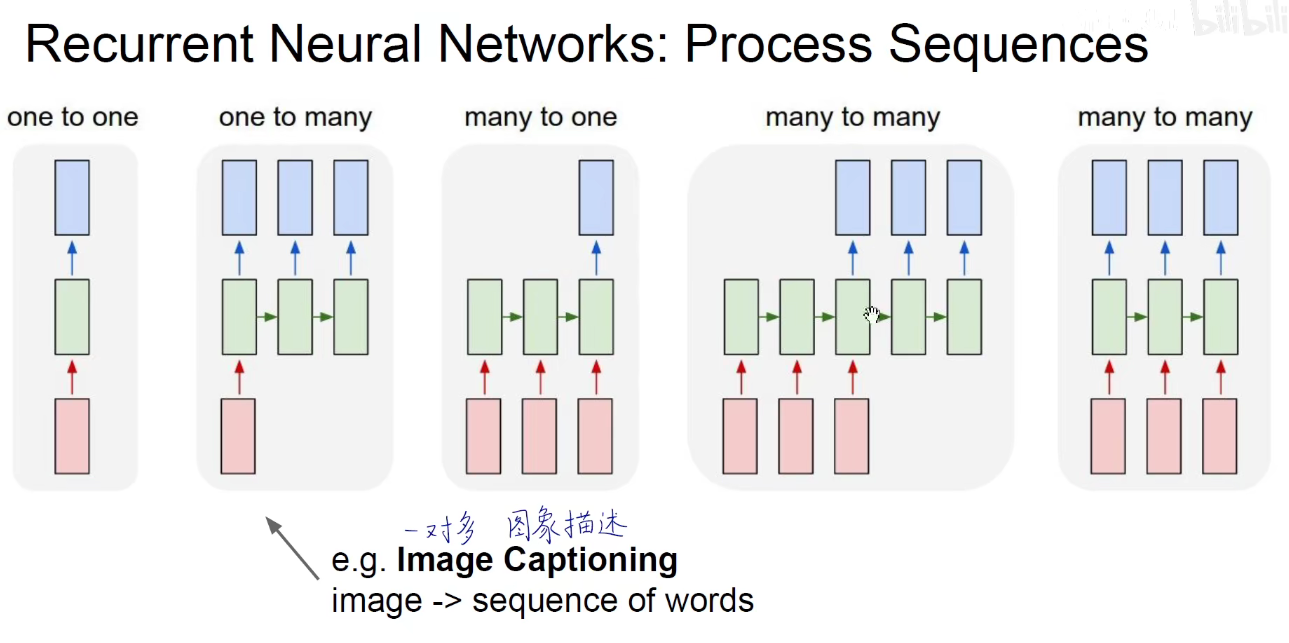
如上图:存在一对多/多对一/多对多对齐/多对多不对齐4种情况。最开始的one to one 是多层感知器(没有序列这个维度)。
one to many:如我输入一张图像,输出描述这张图片的文字,文字是自然语言,就称为序列。一对一。image to sequence of words,图像描述。Image Captioning
many to one:如我输入一个序列,输出一个向量/标量。比如进行文本情感分析,输入豆瓣影评、淘宝评价、景区评价等,我能够判断这个评论是积极的还是消极的,这是二分类问题,同时我们也可以提取成多分类问题,如新闻文本,判断它属于政治新闻、军事新闻、旅游新闻等等。多对一。文本情感分析,文本分类。sequence of words to sentiment.Sentiment Classification
many to many:多对多不对齐,即我先输入一个序列,他处理之后给我返回一个新的序列,如机器翻译场景下,中英文在Google翻译下进行转换。seq of words to seq of words。机器翻译
many to many:多对多对齐,以帧为粒度的视频分类。Video Classification on frame level。如把视频的每一帧沿着时间展开就是一个序列数据,如果对视频的每个帧都进行处理,都输出一个分类值,就是以帧为粒度的视频分类。这个是在循环神经网络场景下的,每一个输出都是与之前所有的帧都想光,过去的帧会对未来的帧产生影响。而不是把每一帧单独的拿出来处理。
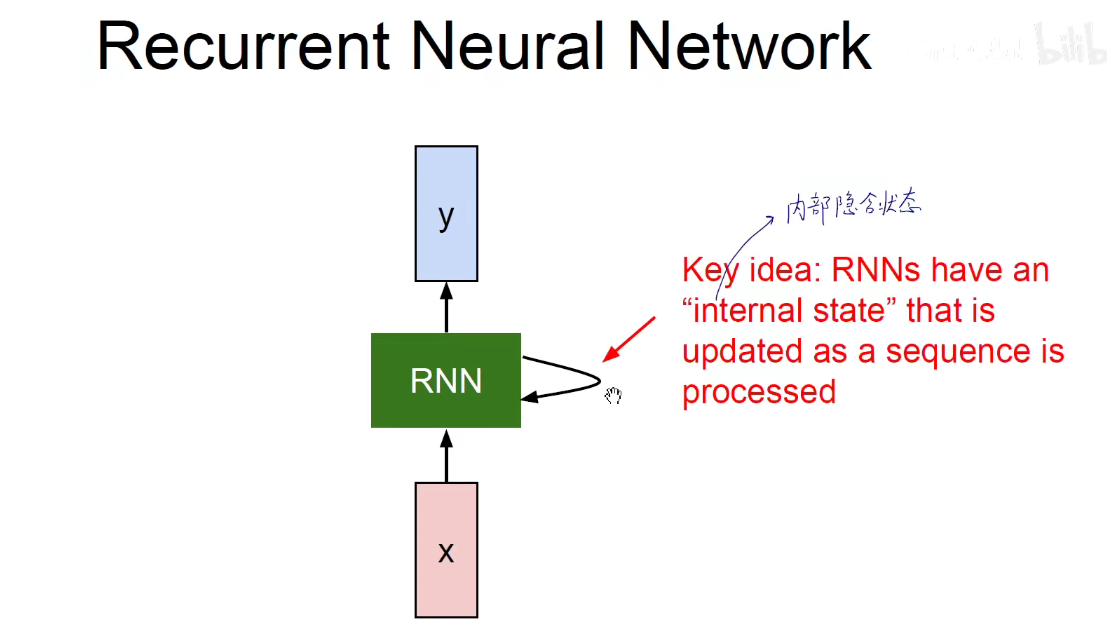
所以RNN不仅取决于当前的输入,还取决于过去的输入和输出。正式因为循环神经网络可以保持记忆,让过去发生的事情可以对当下产生影响,因此它可以处理序列数据。
同样可以将RNN用于处理非序列数据。

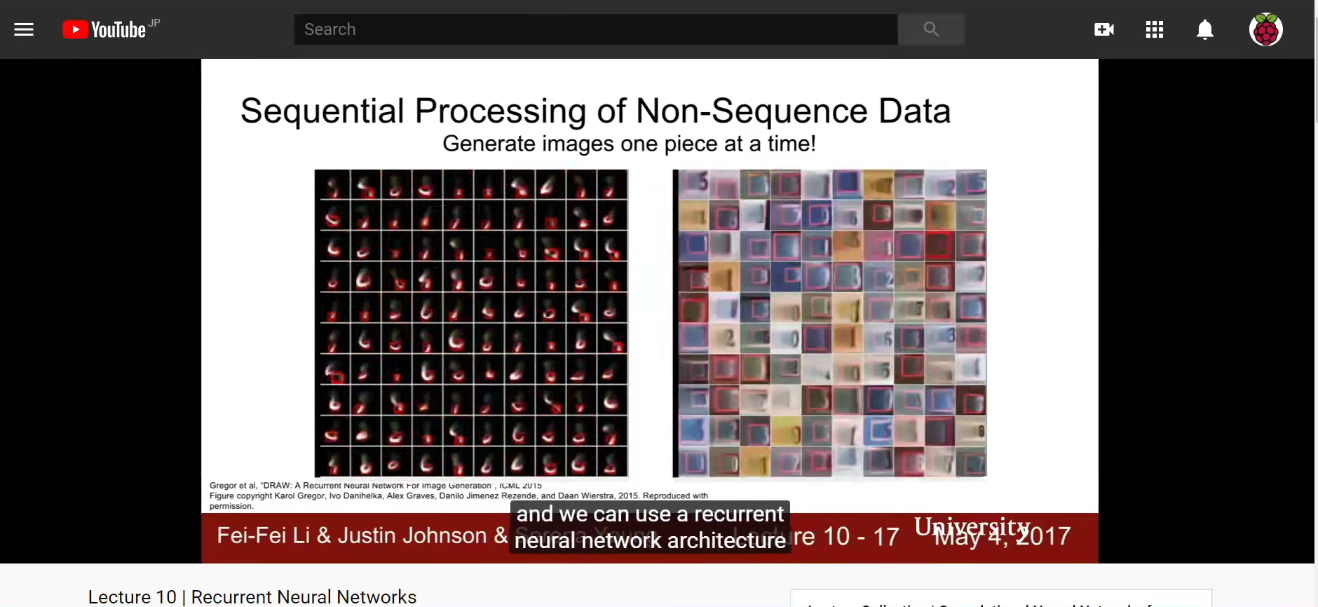
可以按照某个顺序去读取数字,也可以按照某个序列去生成数字。把不是序列的数据按照序列的方法区处理。
图像生成有很多种,如生成对抗网络、变分自动编码器等等,此处采用了序列方法来处理。
记忆更新方式: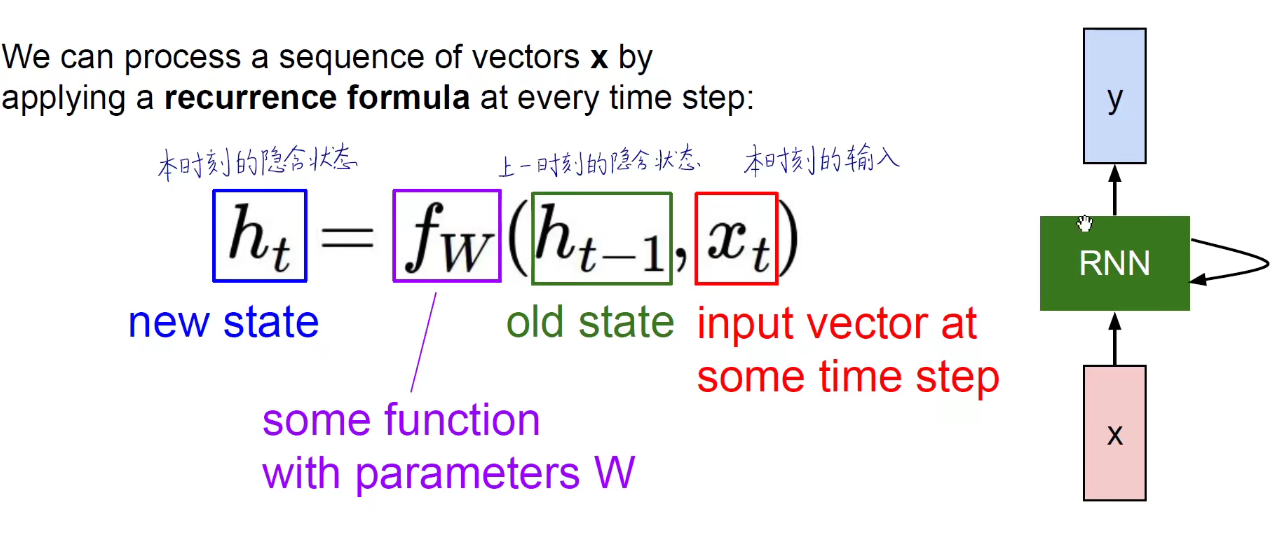
RNN: 沿着时间维度权值共享,CNN:沿着空间维度权值共享。
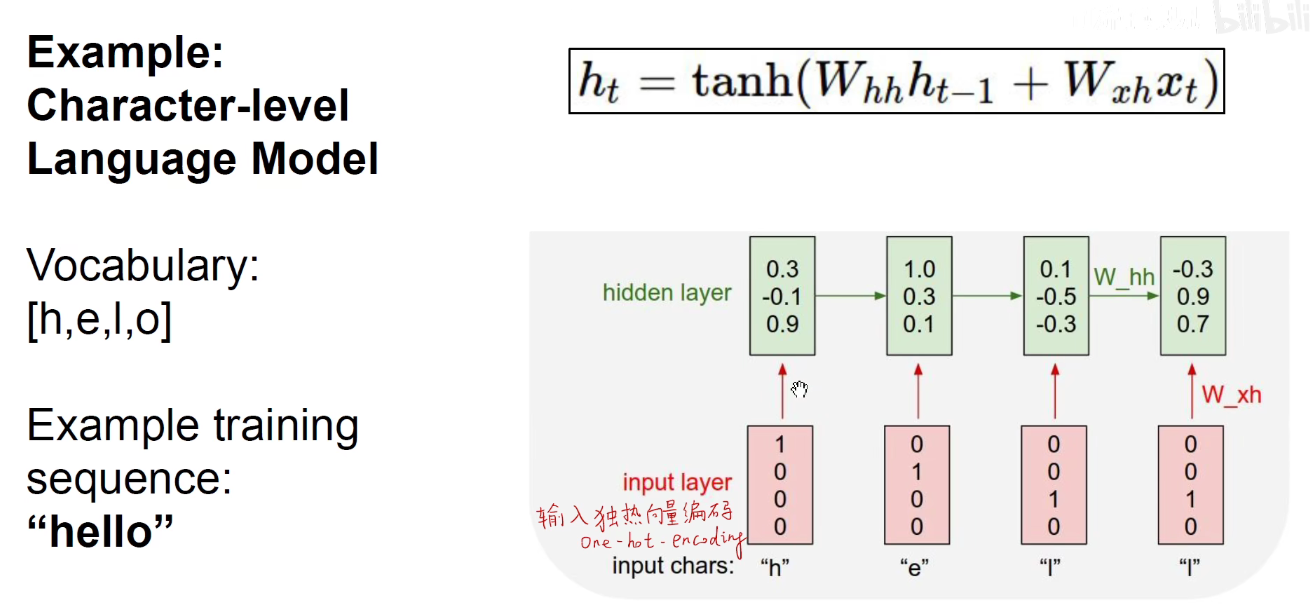
三套矩阵:沿着时间维度权值共享。Whh对上一个隐含状态处理的矩阵,Wxh对当前输入处理的矩阵,就得到了当前时刻的隐含状态ht,由当前时刻的隐含状态ht乘以一个矩阵,得到当前时刻的输出。所有时刻的Whh都是同样的矩阵,Wxh是同样的矩阵,Why是同样的矩阵。
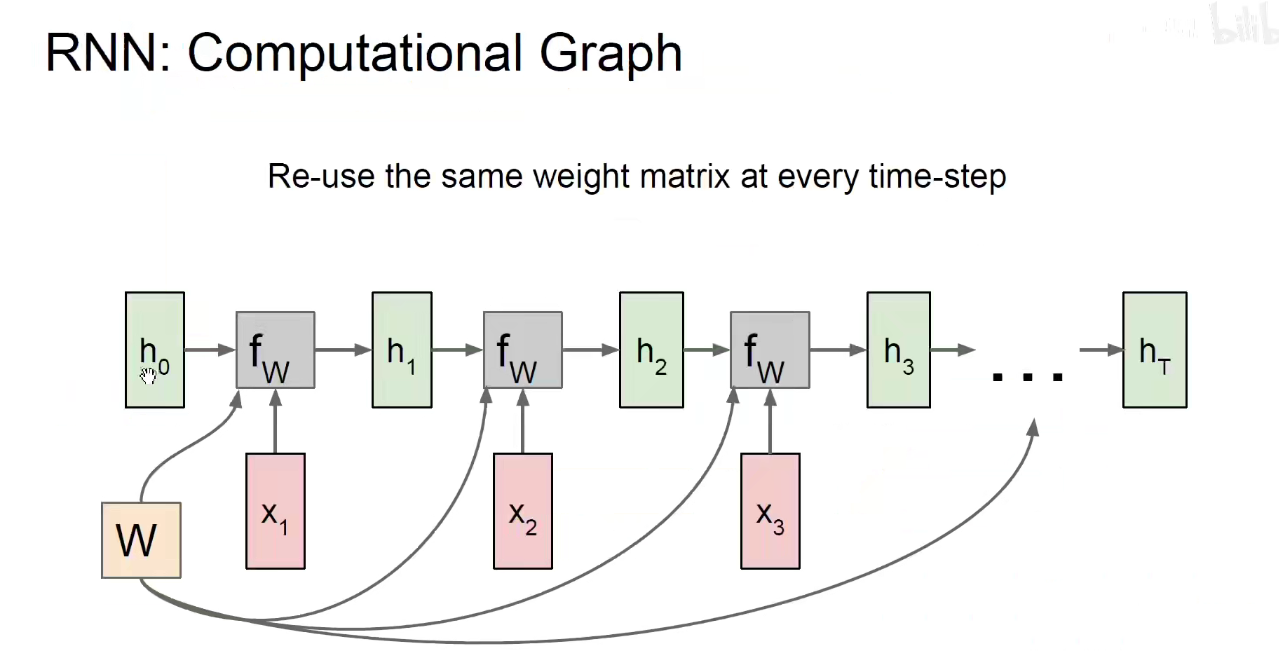
比如:在第开始时刻我们随机初始化一个隐含状态h0,他和Whh相乘,再加上(第一时刻的输入x1与当前输入的Wxh矩阵相称),得到了h1,这是第一个时刻的隐含状态h1,再由第一个时刻的Why乘以隐含状态h1就得到了输出。
之后都是同样的,使用Whh矩阵处理上一个时刻的隐含状态,使用Wxh处理每一个时刻的输入,使用Why矩阵将当前的隐含状态变为输出。所有的横向箭头都是同样的Whh矩阵,所有的W都是同样的Wxh矩阵,所有指向y的都是同样的Why矩阵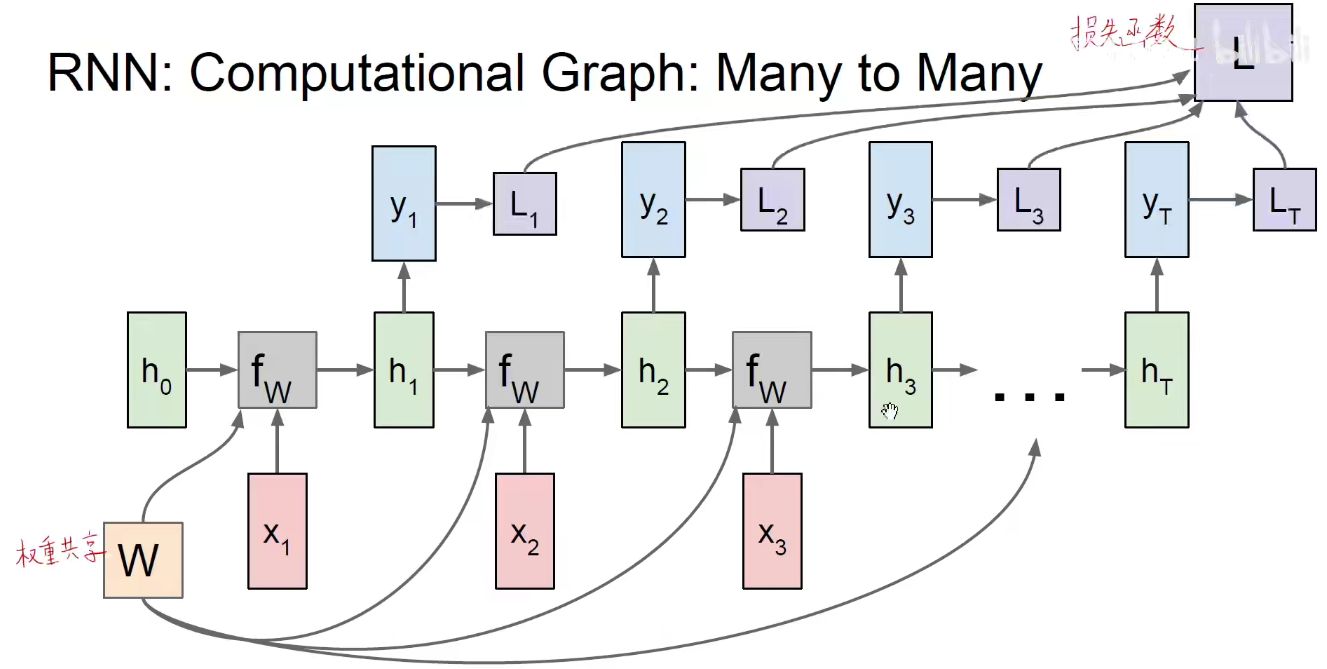
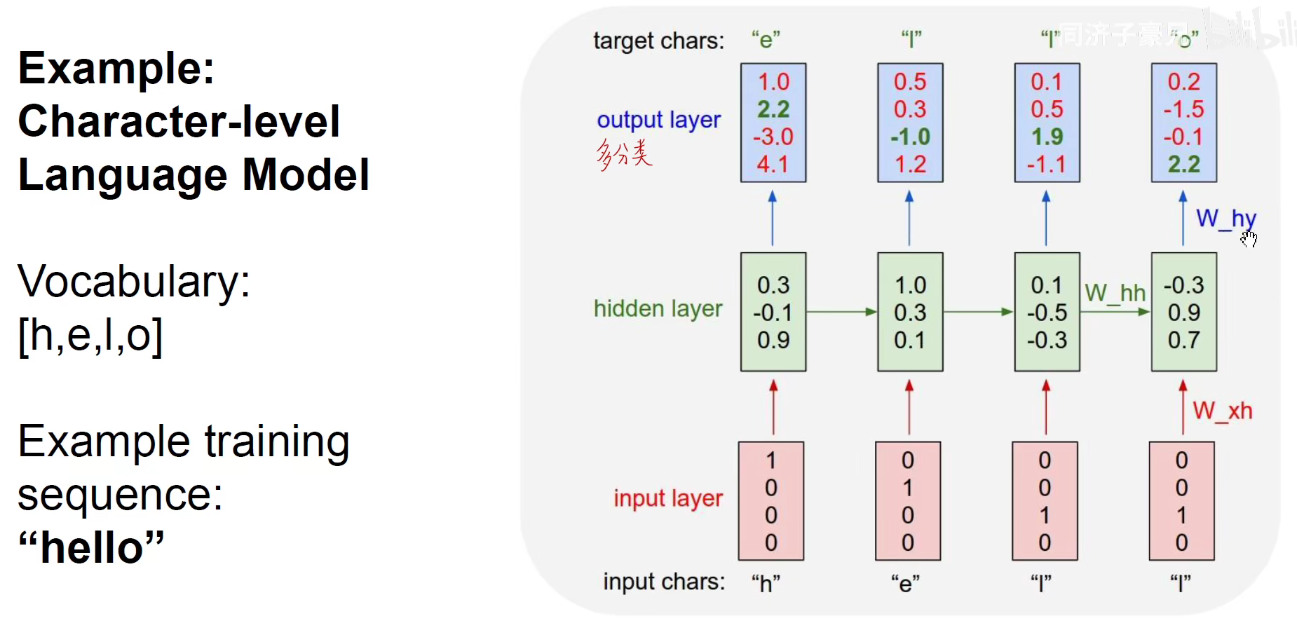
如上图:由输出的y(比如是一个多分类问题)就可以构建一个交叉熵损失函数,完成了一个监督学习的问题,目标就是调整三套权重的值,使损失函数最小化,可以使用梯度下降和反向传播的方法进行求解。反向传播具体的方式:是因为它是沿着时间维度传上去的,所以需要沿着时间维度传回去。
BPTT算法:BackPropagation Through Time。
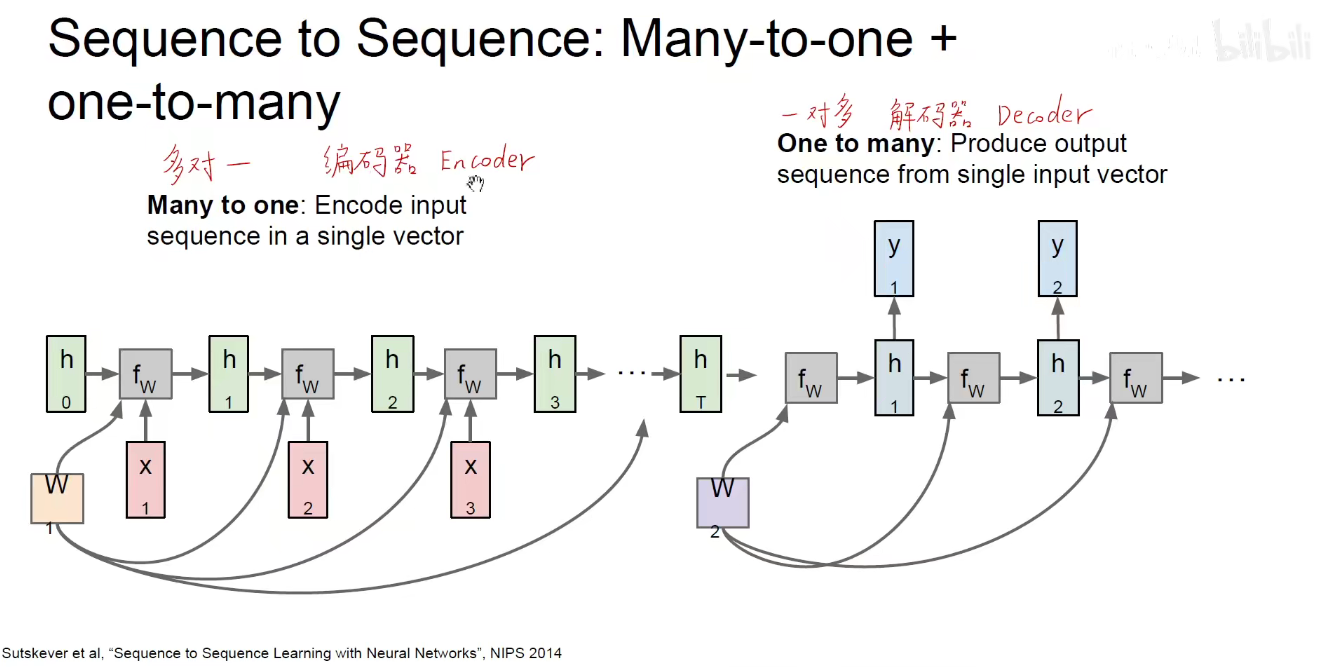
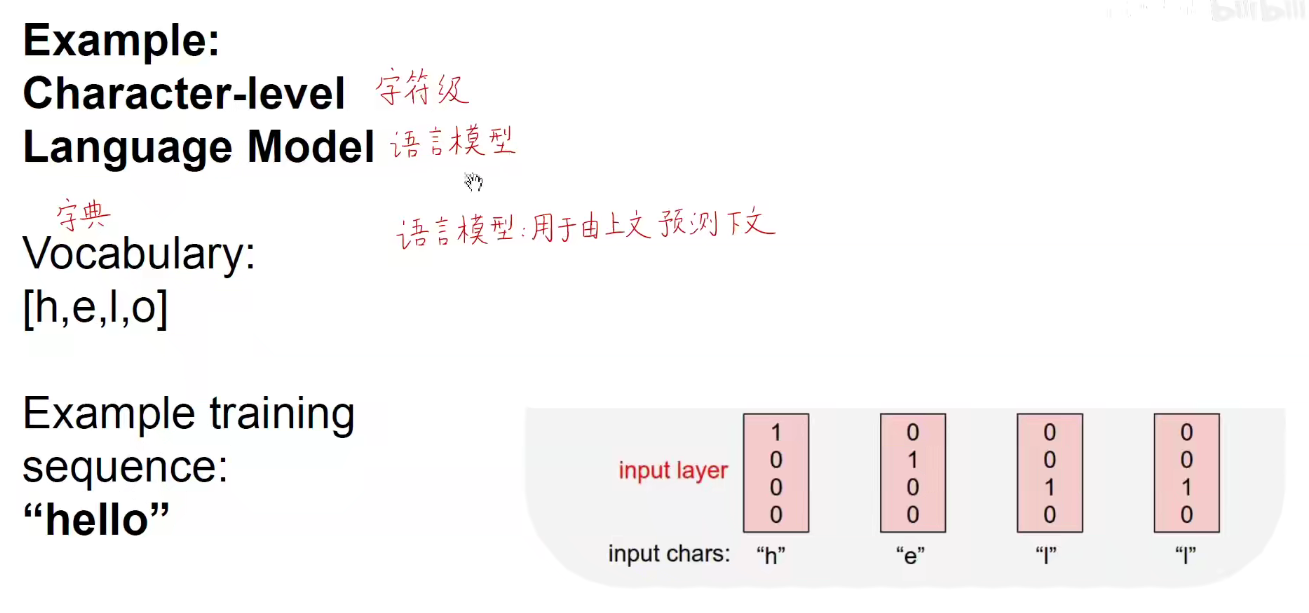
将当前时刻的输出作为下一个时刻的输入,希望无穷无尽的来生成后面的内容。此处同样都是输入“L”,第一次输入L,输出L,第二次输入L,输出O,就算是某两个时刻的输入是相同的,但RNN有记忆功能,过去的时间对它现在产生了影响,他能够通过隐含状态记住这是第一次输入L,那是第二次输入L,就会给出不同的输出结果。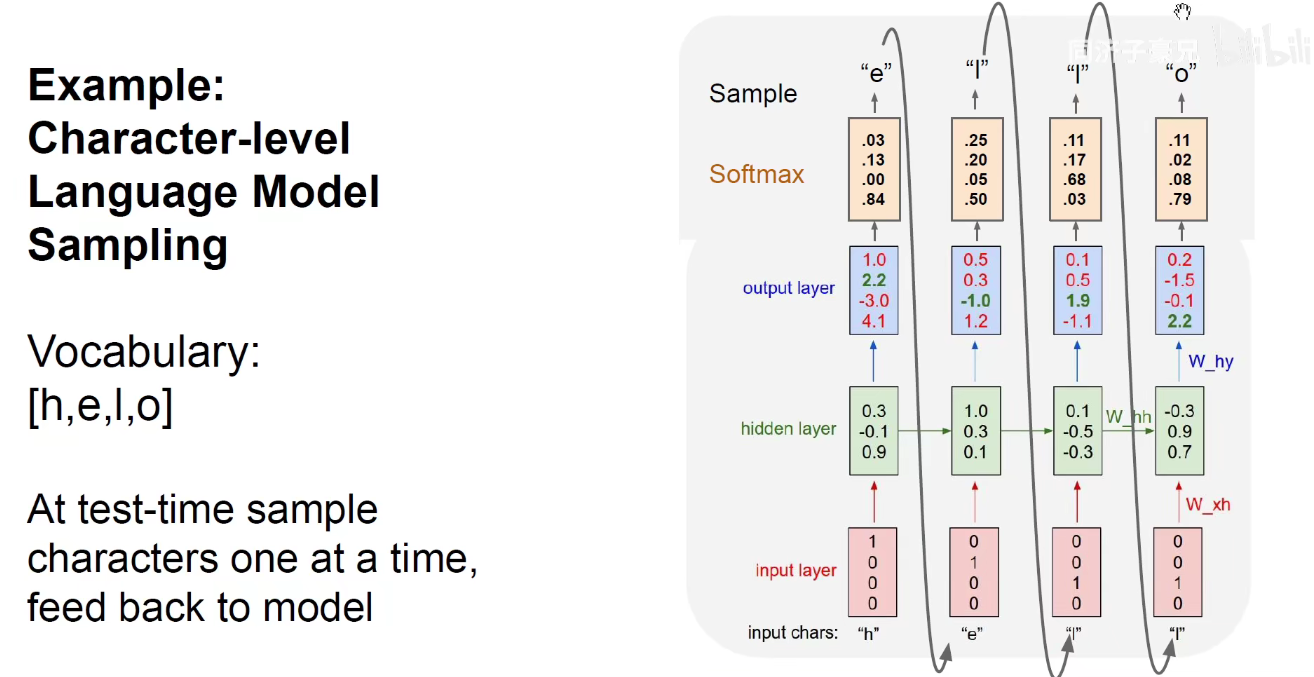
如果这个时间序列很长很长的话,每一个序列都能够得到一个损失函数,所有时刻的损失函数加起来,作为总的损失函数,将总的损失函数对权重中的每一个值求偏导,和过去的BP不同,过去求偏导是只有一个方向,每一个权重只参与了一次运算,现在是每一个时间维度都有同一套权重参加运算,因此需要对每一个时间,每一个时刻的步长求导,再把所有时间维度的导数加起来,作为它真实的导数。。。
好比一个权重在计算图中在A分支计算得到了A值,在B分支上计算得到了B值,最后的损失函数是这两个数的加和,即损失函数的来源有多个,反向传播时要分别对不同来源的梯度进行链式法则的求导,再将不同来源的梯度加起来。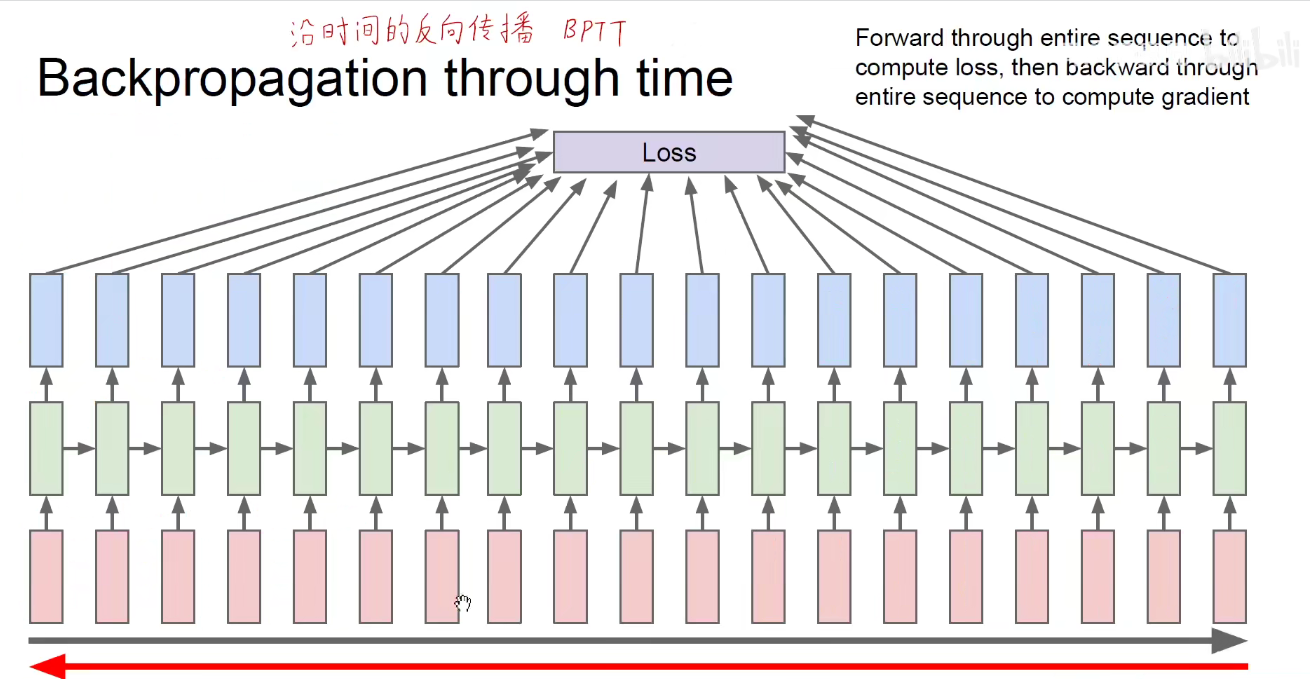
如果一下子将那么多的时间序列喂给模型,运算量极其庞大,通常将输入截断为小片段,再送入RNN。如每次都填入100个词,长的就砍到100词,短的就补到100词。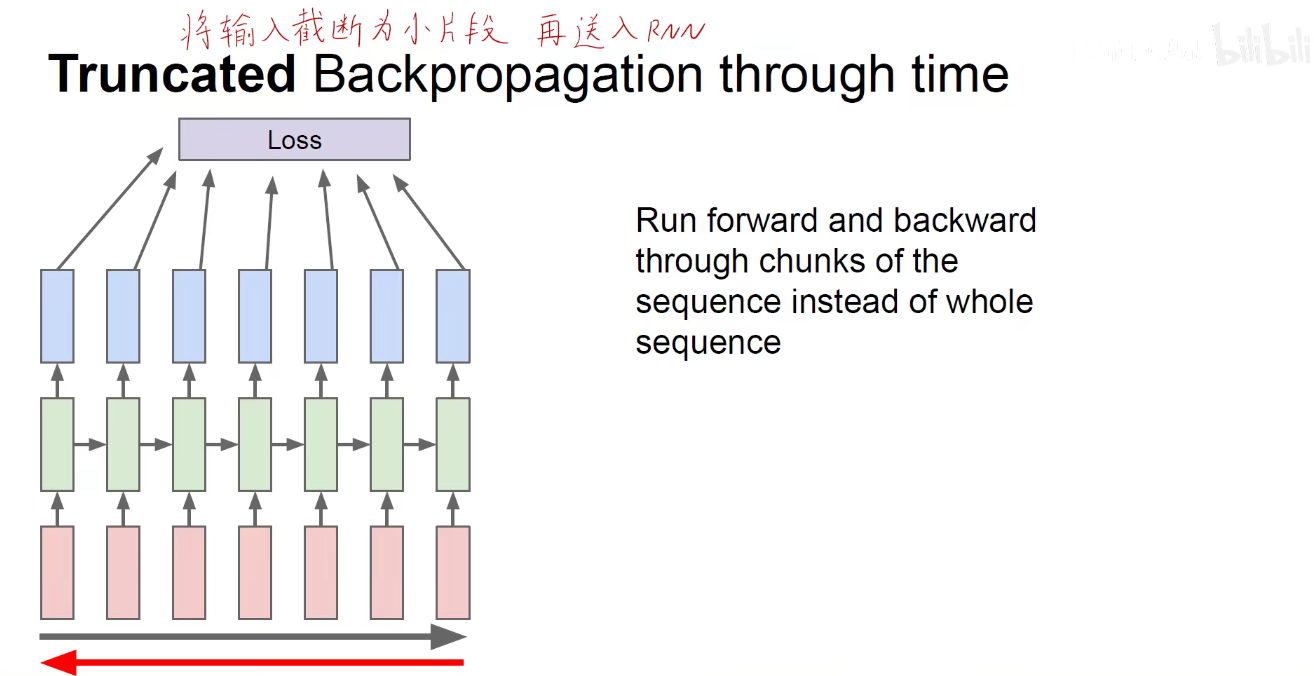
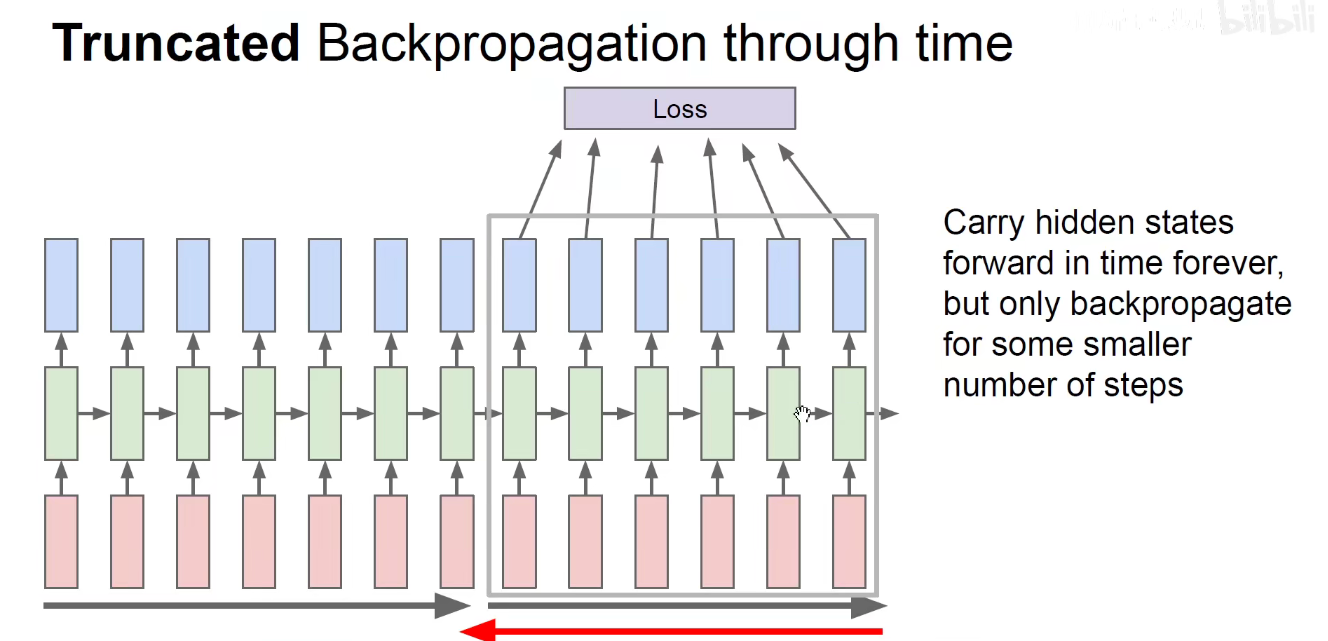
RNN简朴代码:有兴趣可以下载运行
用莎士比亚的剧本作为语料库训练模型,他就能生成莎士比亚风格的短文。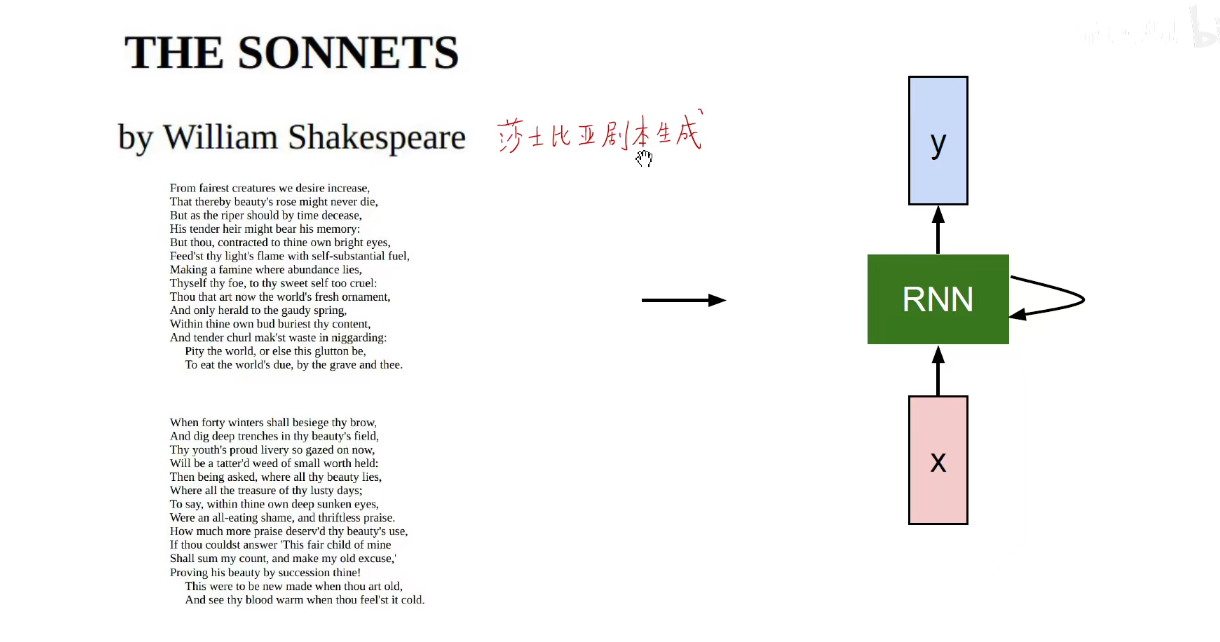


如果使用Latex作为语料库来训练,他就能生成下图这样的论文文档。

装模作样的写一些公式、图像、证明-略等。。。
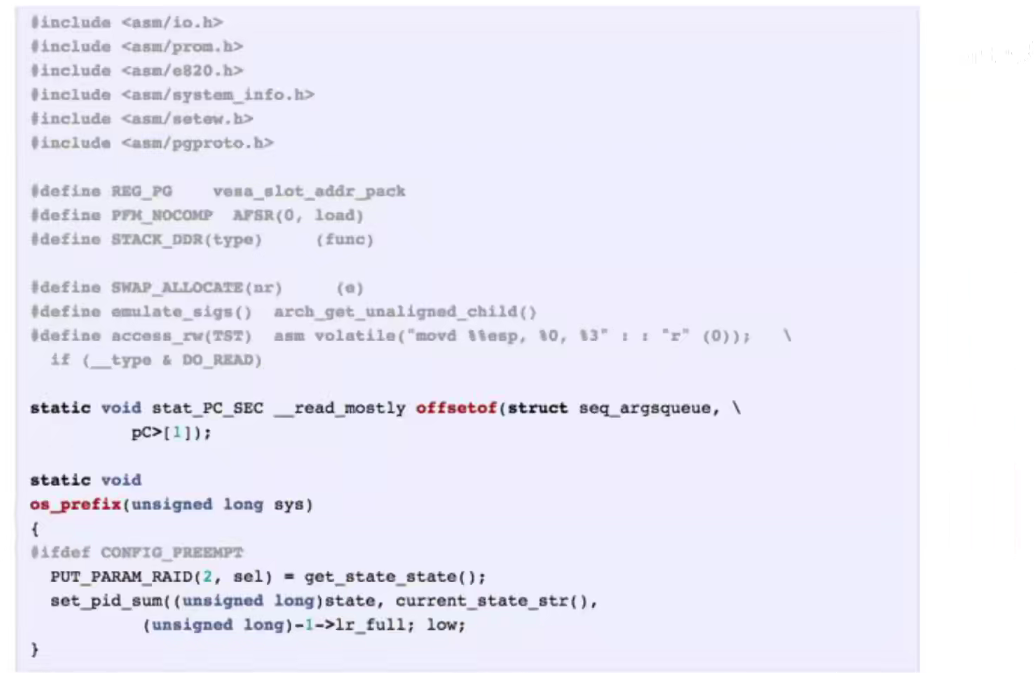
如果我们使用Linux的源代码作为语料库进行训练呢?
可以生成类似于C语言风格的代码文本。。。
外行人很难看到其破绽,因为使用的字符级的语言模型,他只能捕获字符之间的关系,至于变量是什么意思,函数声明是什么意思,它是不理解的。
甚至还会记住每一二个C语言文件开头的GNU开源协议,还有C语言的头文件。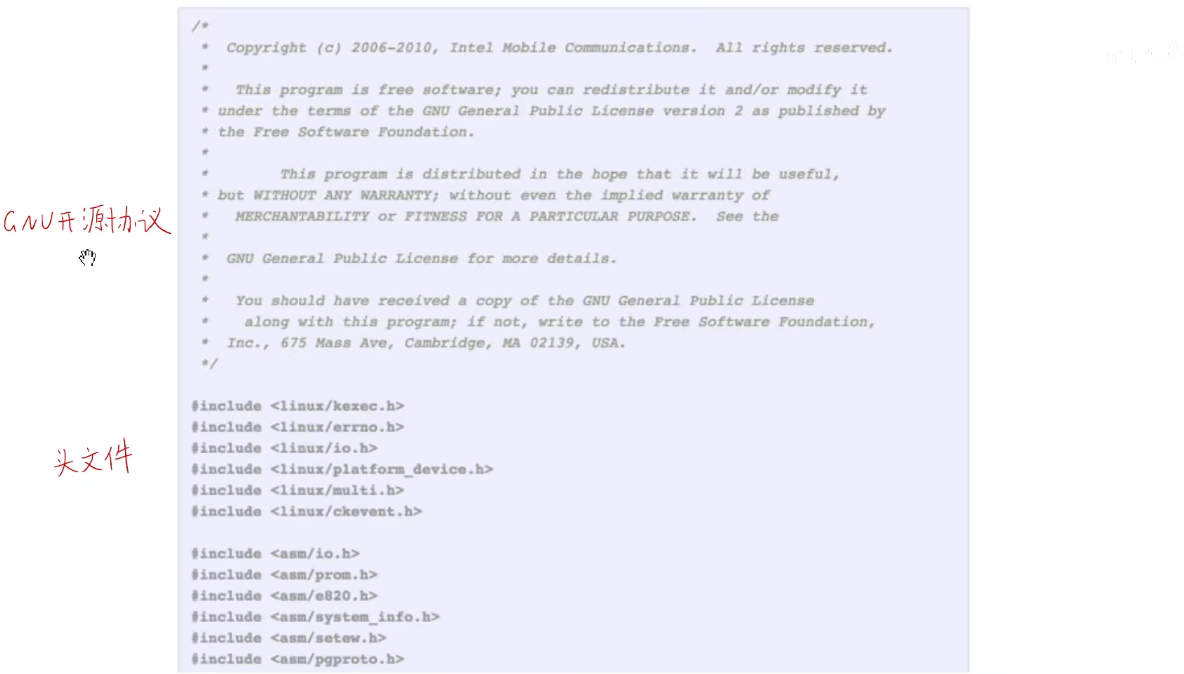
现在只是用最简单的字符集模型使用海量的语料库去训练,他能够生成跟这些语料库相类似的文本。
RNN原理:它是有一个隐含状态的,当前的输出不仅取决于当前的输入,还与上一时刻的隐含状态有关系,有三套权重,一套是竖直方向红色指向绿色的Wxh,绿色指向蓝色的Why,还有横向的绿色指向绿色的Whh,即红色是x,绿色是h,蓝色是y。他们各自在时间维度上权重是共享的,如所有红色权重一样,蓝色权重一样,绿色权重一样。
这个时候发现他之所以保留记忆,是因为有了隐含状态,其实是可以观察这么多隐含状态,分别负责什么样的功能。即把中间中的某些隐含状态在序列化中可视化出来。看他什么时候是高值,什么时候是低值。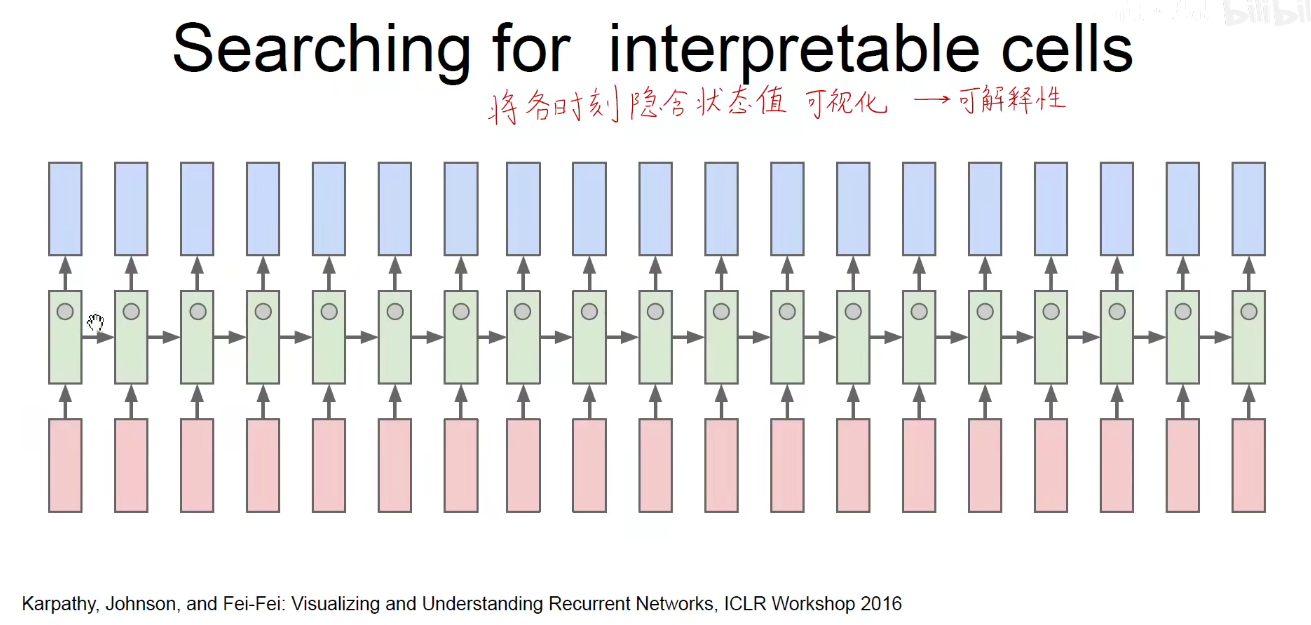
比如我们看到某些是负责引号开关的,引号一旦闭合,值就会飙高,引号一旦结束,值就会变低。
还有一些是负责换行的,一旦到了行尾值就变高。



像上图,有负责函数声明、注释、代码缩进等,不同隐含层中不同的值其实是负责不同的特征。如果隐含状态越多,越能捕获底层的一些特征。
再比如之前讲过的Image-Captioning模型:输入一张图片,先用CNN对图像进行预处理,即特征抽取,得到一个向量,将向量乘以权重作为初始的隐含状态。然后把一个START标签喂进去,他就能输出一段描述这个图像的文字。比如straw-草帽。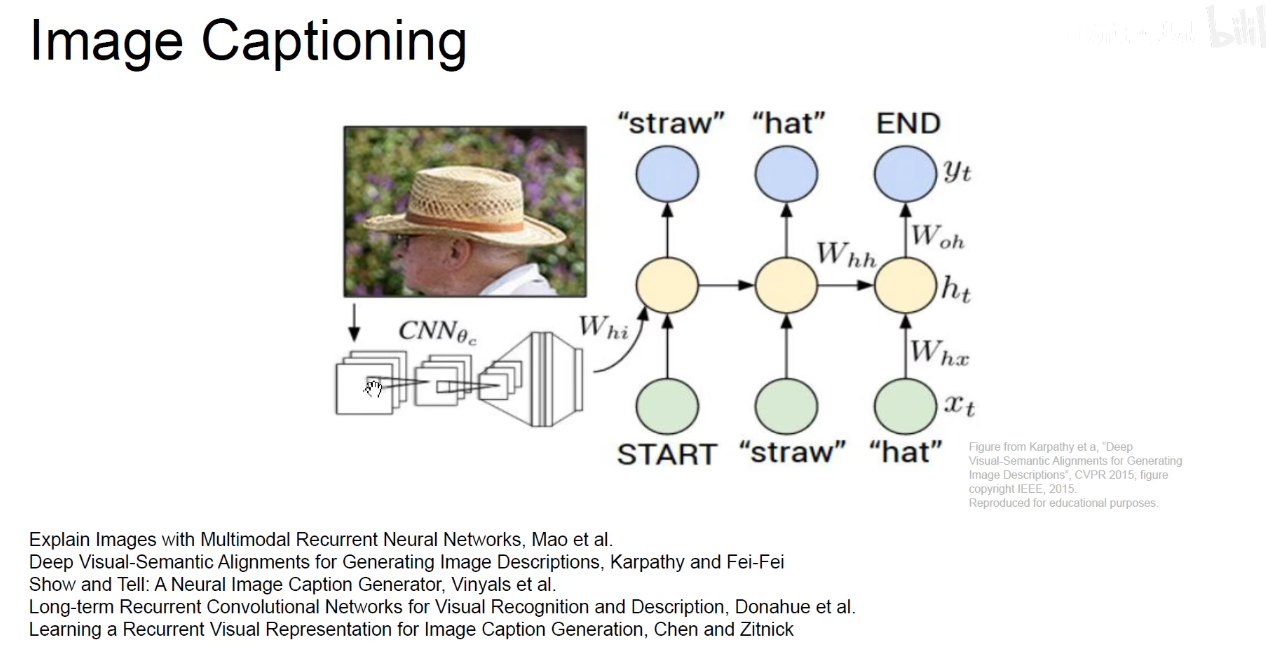
就像搭乐高积木一样,先用CNN做编码,把一个图像编码成一个向量,将向量喂到循环神经网络,称之为解码器,Decoder将该向量解码成一段文本,
Encoder-Decoder这种类型是专门负责把不同类别的数据进行装换的。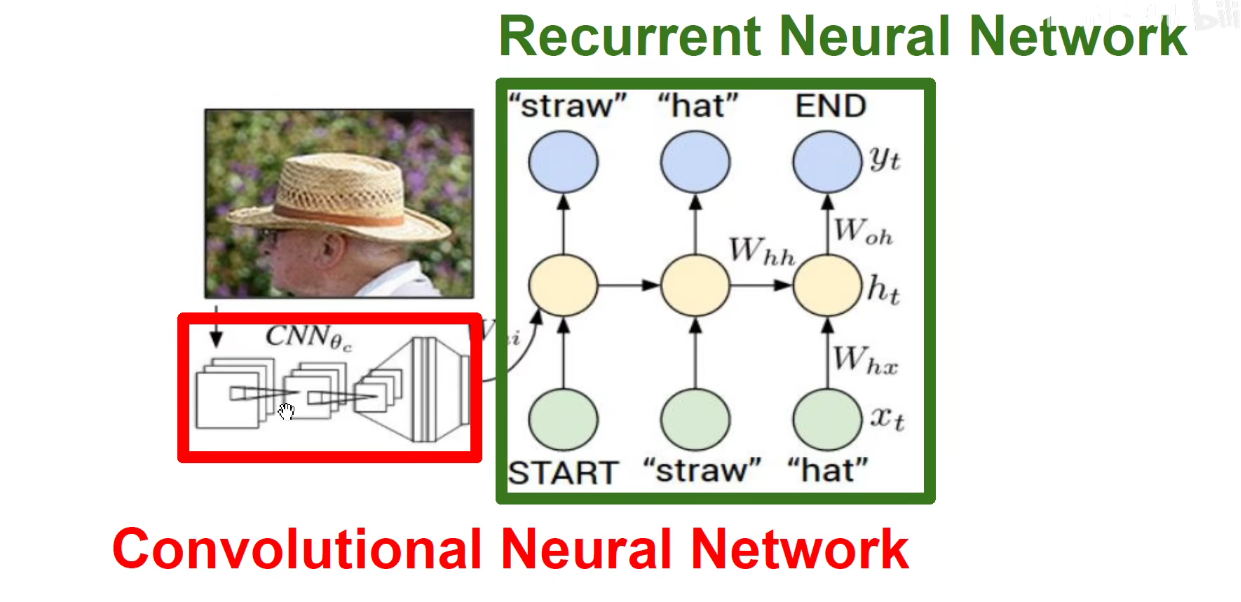
具体做法:


比如CNN我们采用VGG来做,VGG有5个Block,每一个Block都是3x3卷积,第一个是64个卷积核,第二个是128个卷积核,第三个是256个卷积核,第四个和第五个是512个卷积核。之后是两个4096神经元的全连接层,然后是1000个分类的输出层。现在可以不要1000个分类的输出层,将这个4096维的向量作为图像的编码。
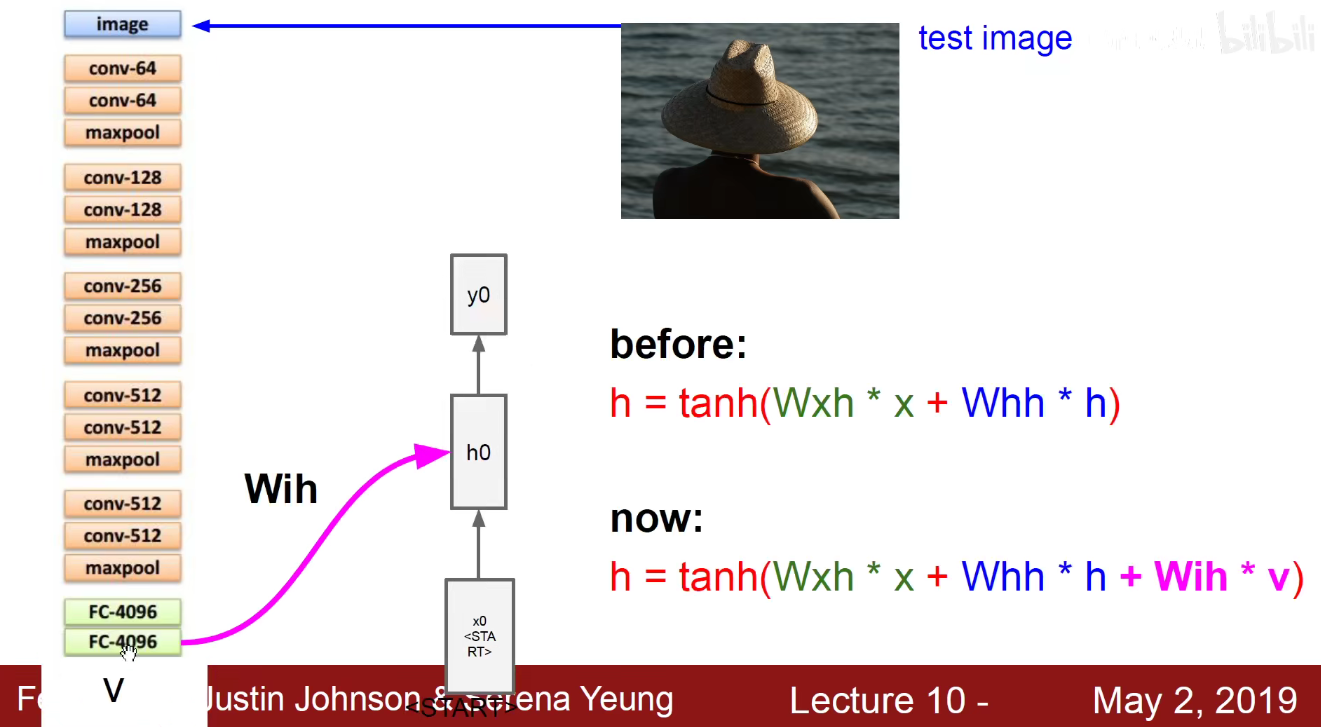
如上图,给这个4096维的向量乘以一个Wih的权重,就得到公式中紫色的值Wih x v,紫色值作为初始的隐含状态,就能够和我当前输入的START开始汇总,生成一个词,该词作为下一个时刻的输入。如下图,源源不断的生成新词,直到他输入截止符号END为止。
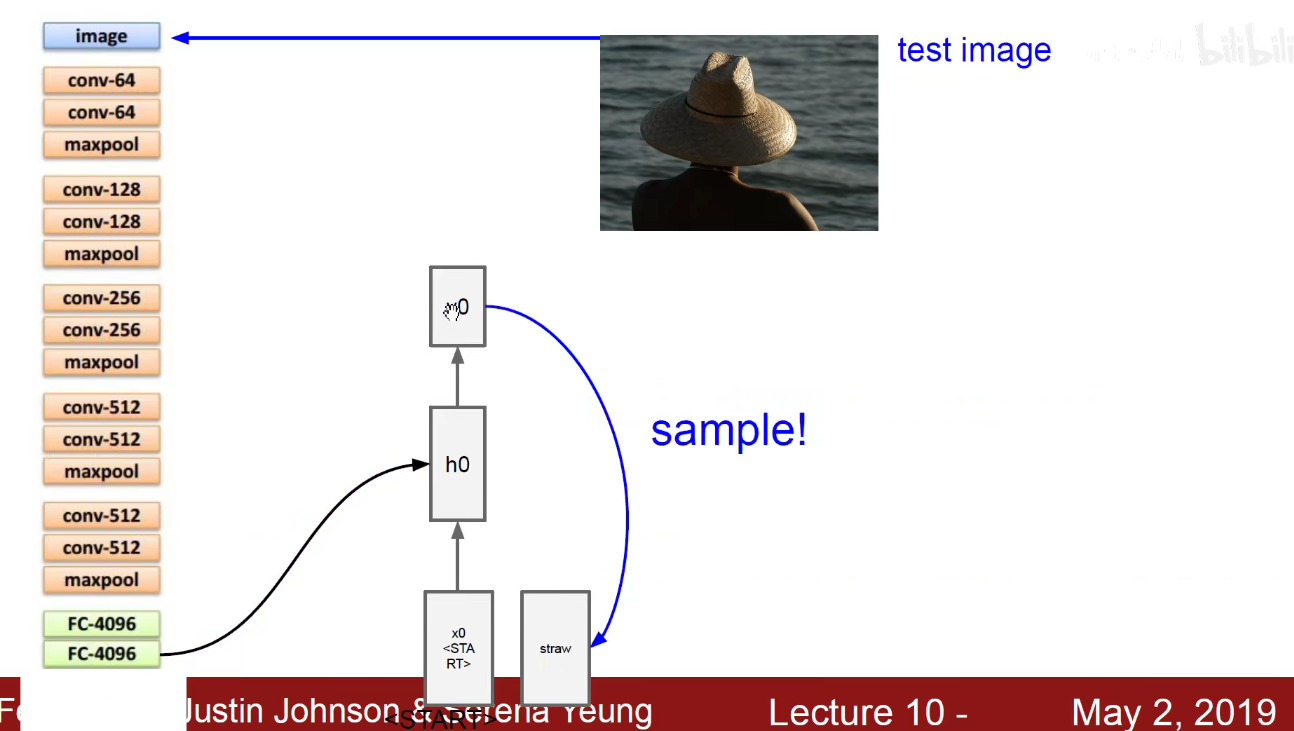
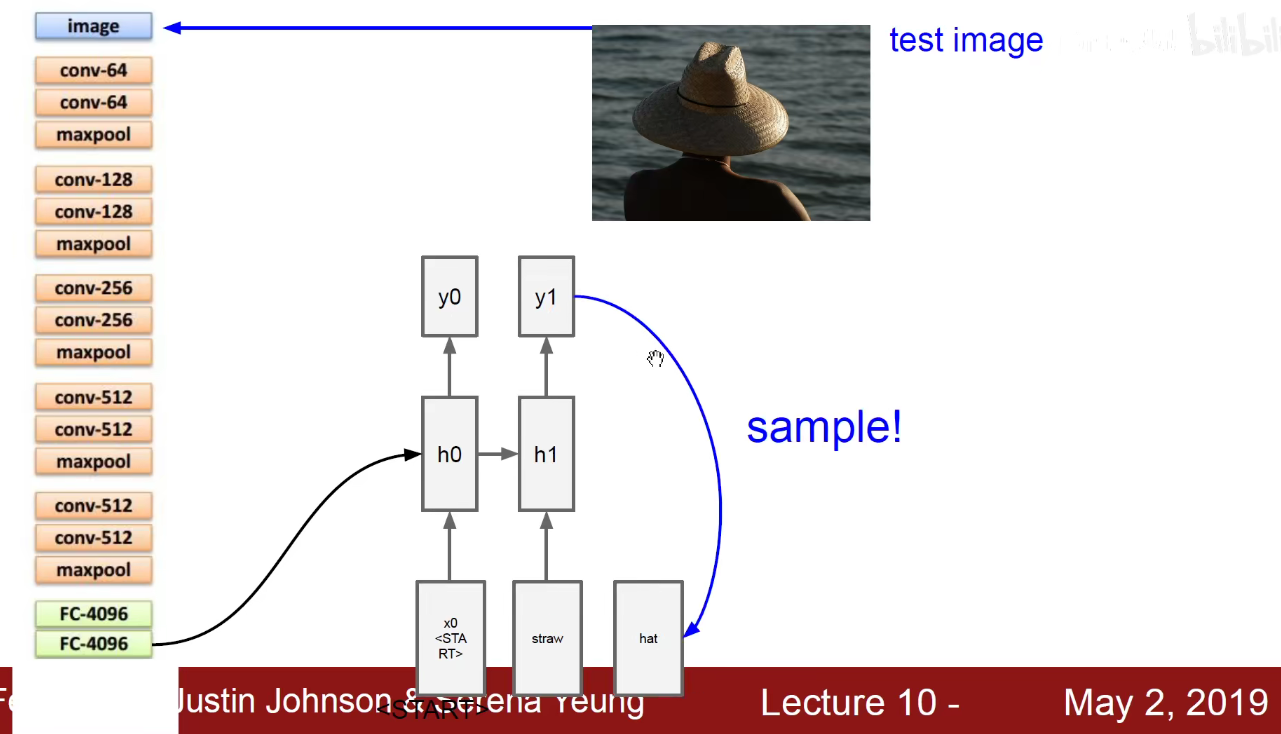
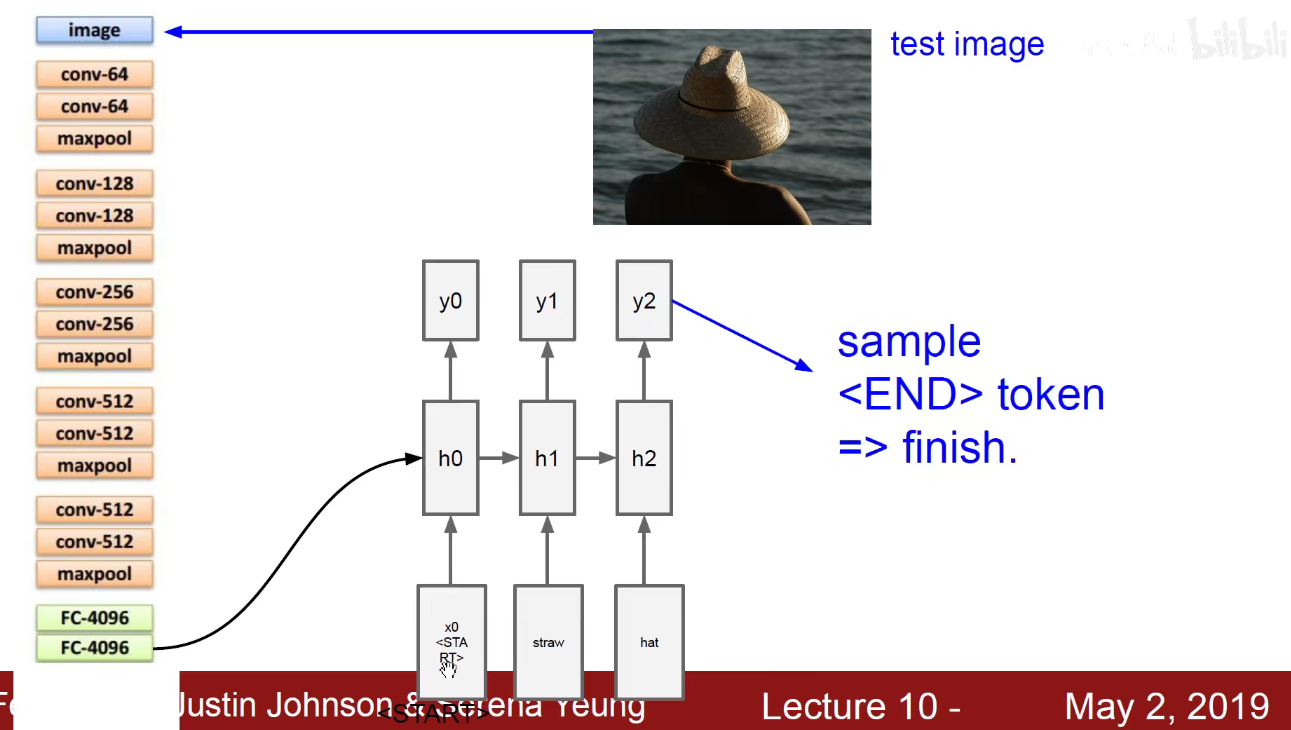
Image*Captioning:案例


同样可以引入注意力机制。大致意思就是:先输入一张图片,然后使用CNN对图片进行特征提取,生成Feature-Map,将Feature-Map送到循环神经网络中,RNN输出每个次的时候应该关注那一部分,caption生成到bird这个单词时,关注的就是鸟,生成water这个单词时,关注的就是水,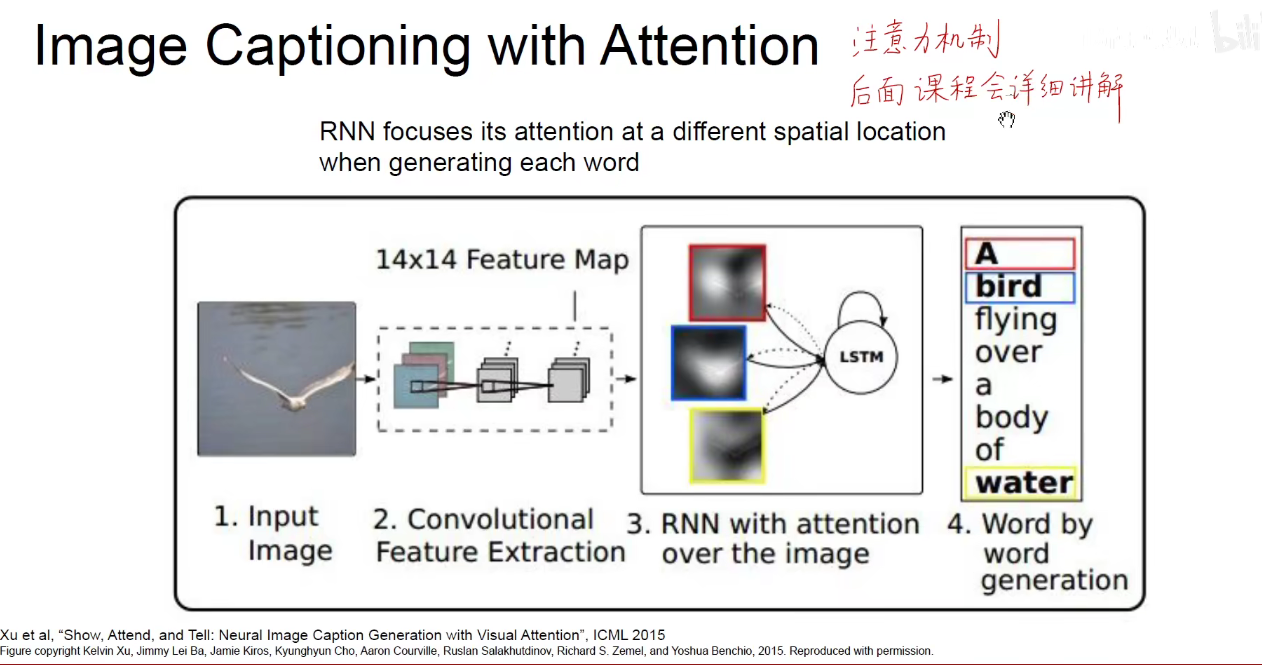
具体是先对图像进行CNN卷积,得到一个Feaure-Map,Feature-Map是一个L X D 维度的矩阵,L就是 HxW 长宽的意思。我们把编码得到的Feature-Map输入到循环神经网络中,h0之后输出的a1就是一个L维向量,L维向量其实就是一个HxW维的二维矩阵,反映了当前的神经网络应该对Feature-Map哪一个位置产生更大的影响和更多的关注。
将权重与原来的Feature-Map相乘,就得到了D维的向量(Z1前面的),D维向量表示对Feature-Map中不同通道的权重,进而Z1和feature-map中不同通道相乘,得到之后的热力图。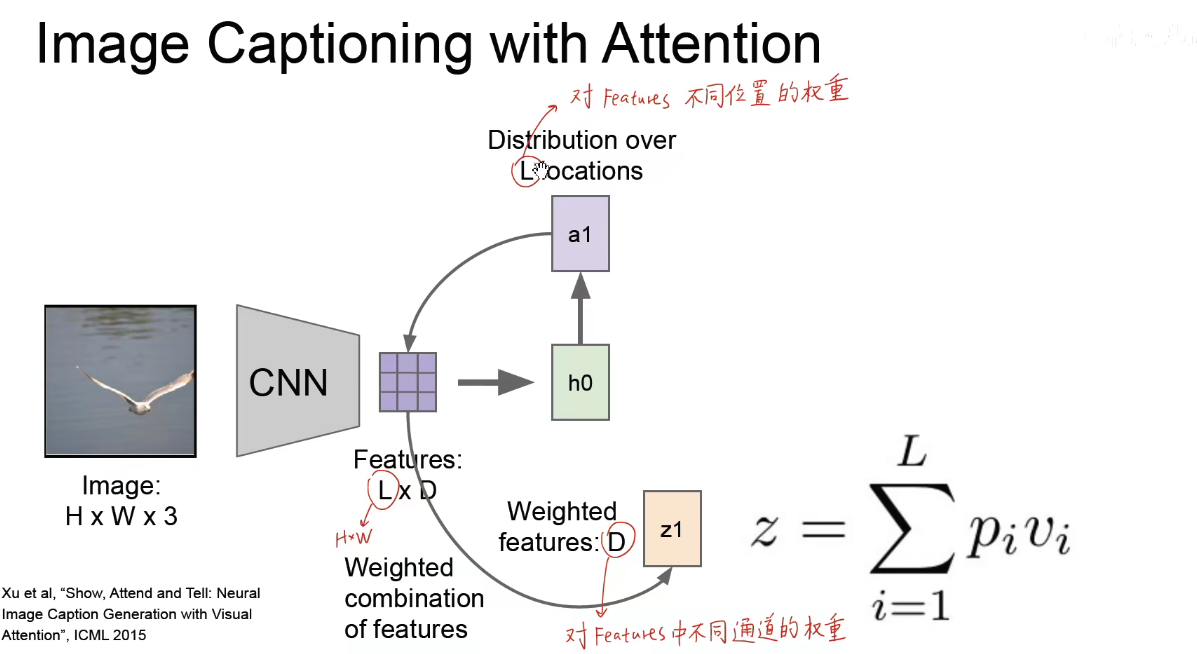
训练时,将标签中的文字y1和D维的向量Z1一起喂进去,就生成了新的词d1和第二个L维的向量a2,第二个L维的向量再和原来的feature-map相乘得到新的D维的Z2,Z2和第二个词y2输入进去得到新的维向量和新的词,循环往复。。。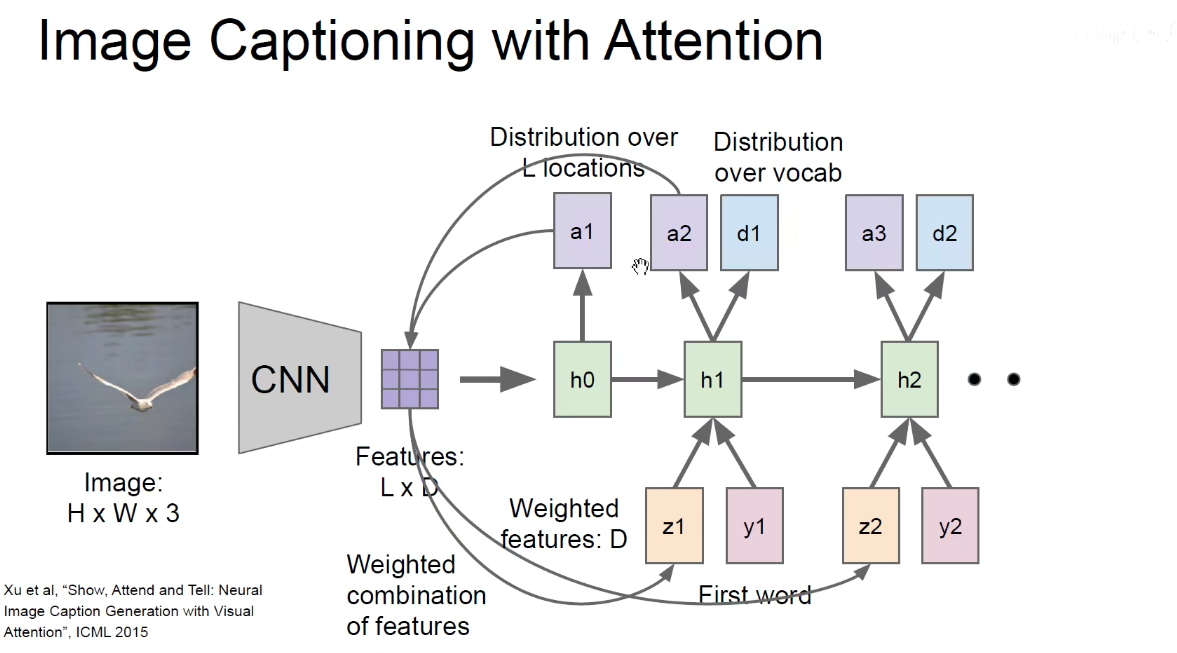
L维向量:反映了对features中不同位置的权重,生成的向量a1是一个二维矩阵,它对应了图像中不同的位置,如果包含各个位置的权重,称为soft-attention,生成对应的概率分布。如果只包含最大的权重,称为Hard-attention,如下图: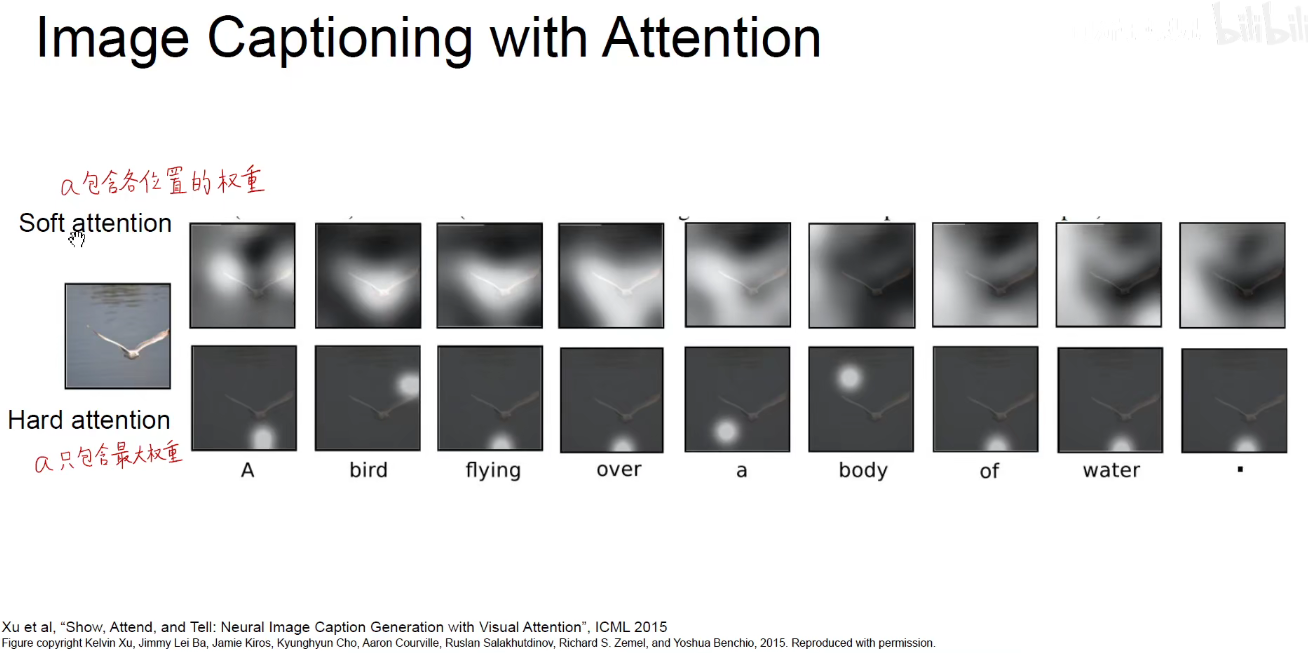
bird就会关注到鸟这个而区域,water就会关注水面这个区域。 我们并没有刻意的去训练他,而是他得到的结果中可以反应这样的注意力机制,

视觉问答:给一张图像,给一个问题,他能够回答这个问题。
这是他的一篇论文: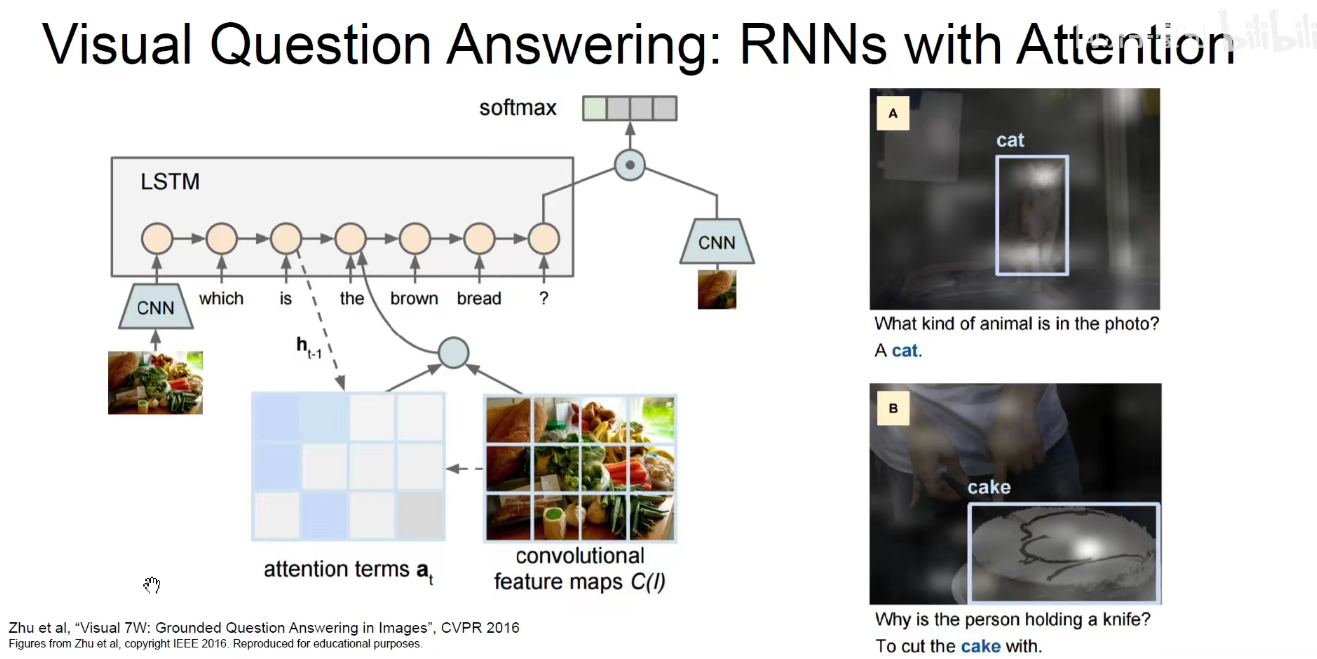
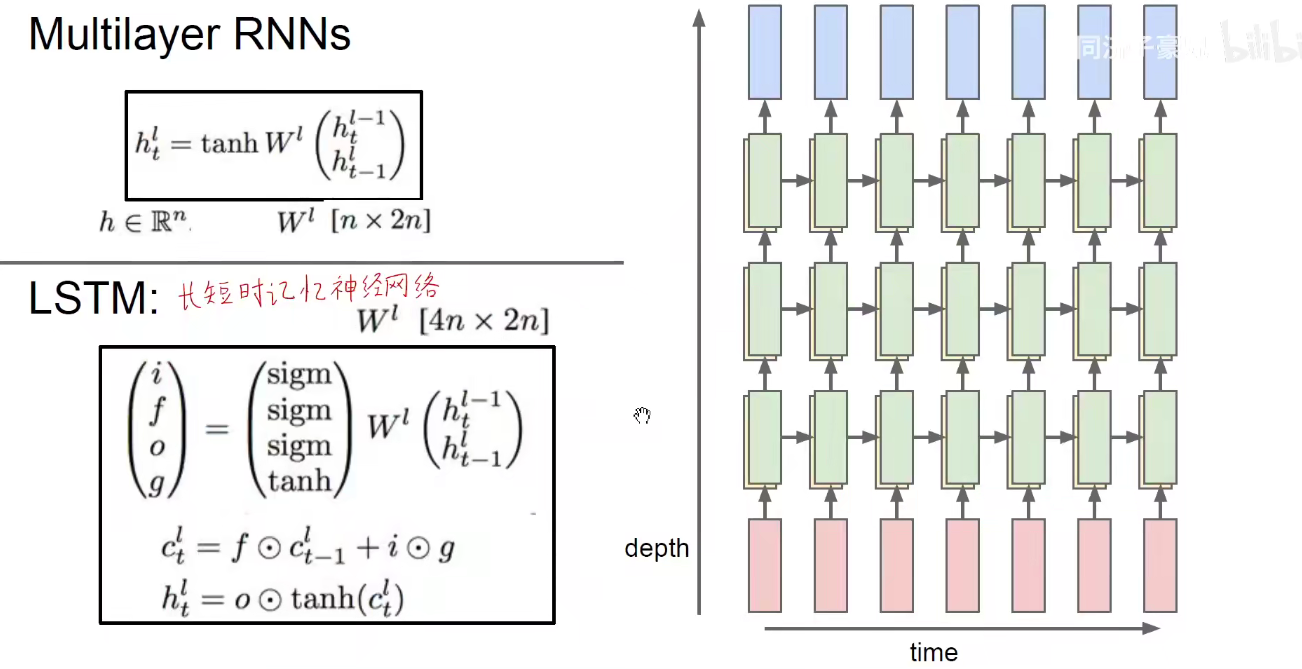
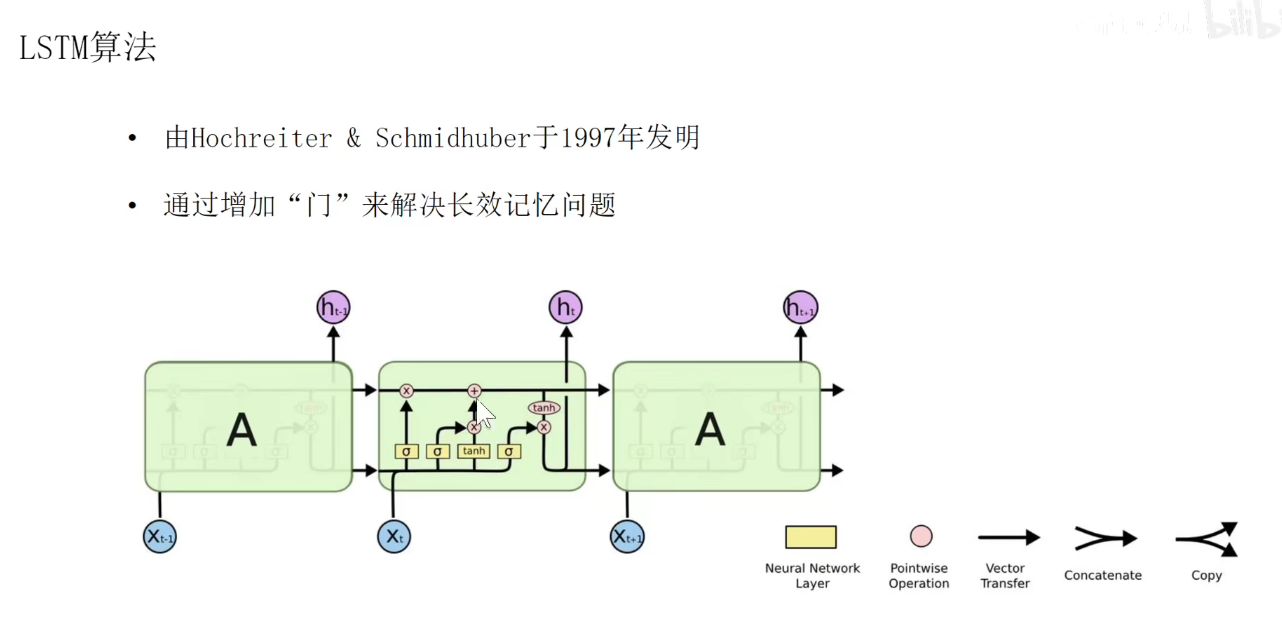
RNN变体-LSTM(长短时记忆神经网络)简述
Long short-term memeoy是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
我们提到循环神经网络非常的简单,权重共享。但是有个问题:BP时需要沿着时间回溯,明显存在严重的梯度消失现象,特别是当我们堆叠多层的隐含层(绿色所在的层)之后,BP就变得更加难办。过去的以及对未来影响就越来越小,解决这个问题就需要使用LSTM。
在讲LSTM之前,看看RNN为什么会有梯度消失的问题。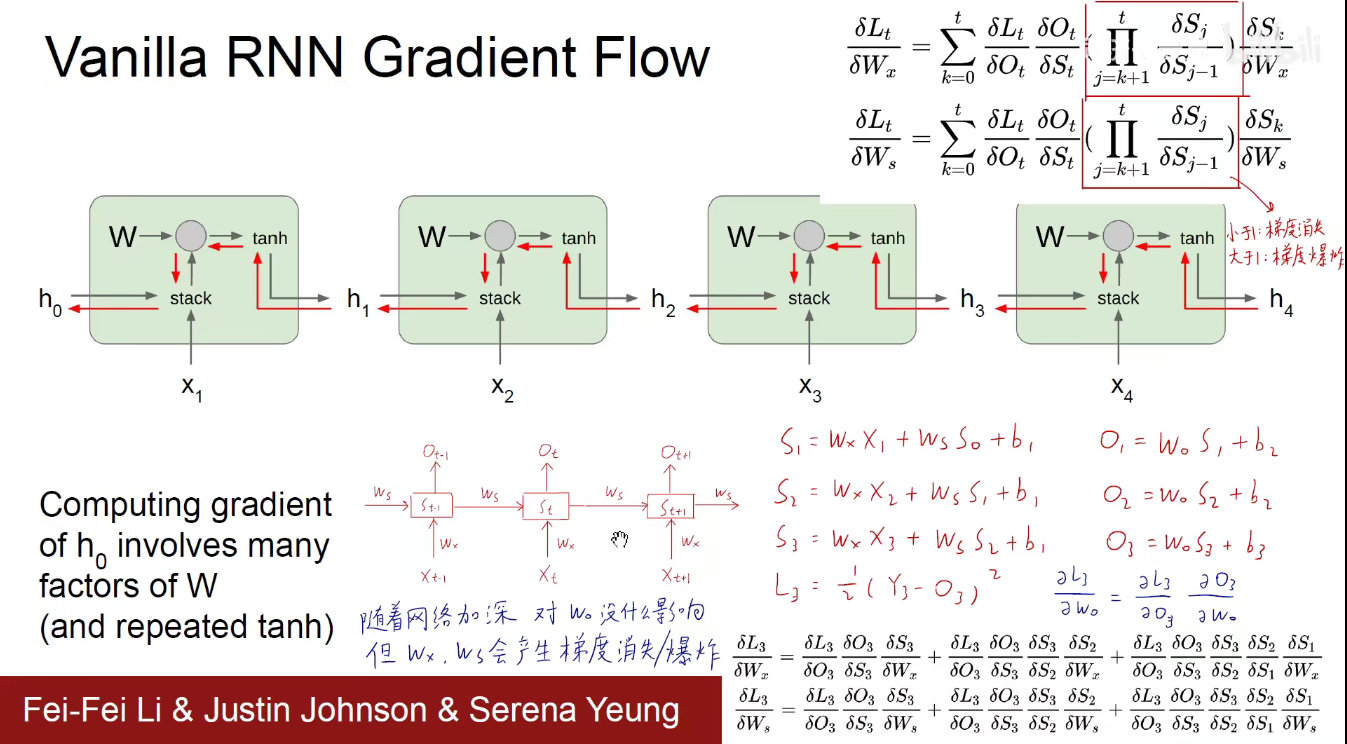

三套权重:Wx(输入值权重) Ws(隐含状态权重) Wo(输出值权重)
以上图中最简单的图为例(手绘的中间红色笔记)。输入是x,隐含状态是S,输出是O。
由手绘公式可看出每一时刻的计算结果。(举个例子:第一个时刻,是第一个时刻的输入X乘以Wx,上一个时刻的隐含状态即S0乘以Ws, 最后求和再加上偏置项,第一个时刻的输出是Wo乘以第一个时刻的隐含状态S1再加上偏置项)。
损失函数在第三个时刻,可以认为它是一个均方误差,假如我们要解决一个回归预测问题,用我们估计的值减去真实的值作差平方乘以二分之一,二分之一的目的是为了让求导的时候平方项下来正好抵消。
现在来看看第三个时刻的损失函数L3对Wo进行求导,链式求导法则,先对外层求导,再对内层求导。结果如蓝色手绘显示,可以看到是可以直接算出来一个值的。
如果我们看Wx和Ws这两个权重呢?我们要多次求导,将它的各个来路都搞清楚,把各个来路的梯度加起来,将各个时间片段的梯度相加求和,才能作为最终的L3对Wx的偏导数,L3对Ws一样。
随着网络的加深,对Wo没什么影响,但Wx和Ws加的项就越多,会产生梯度消失/爆照等问题。可以简写为右上角的连乘形式。
即在RNN中,网络越深,序列越长,它的梯度就越小或者越大,一般是越小-梯度消失。
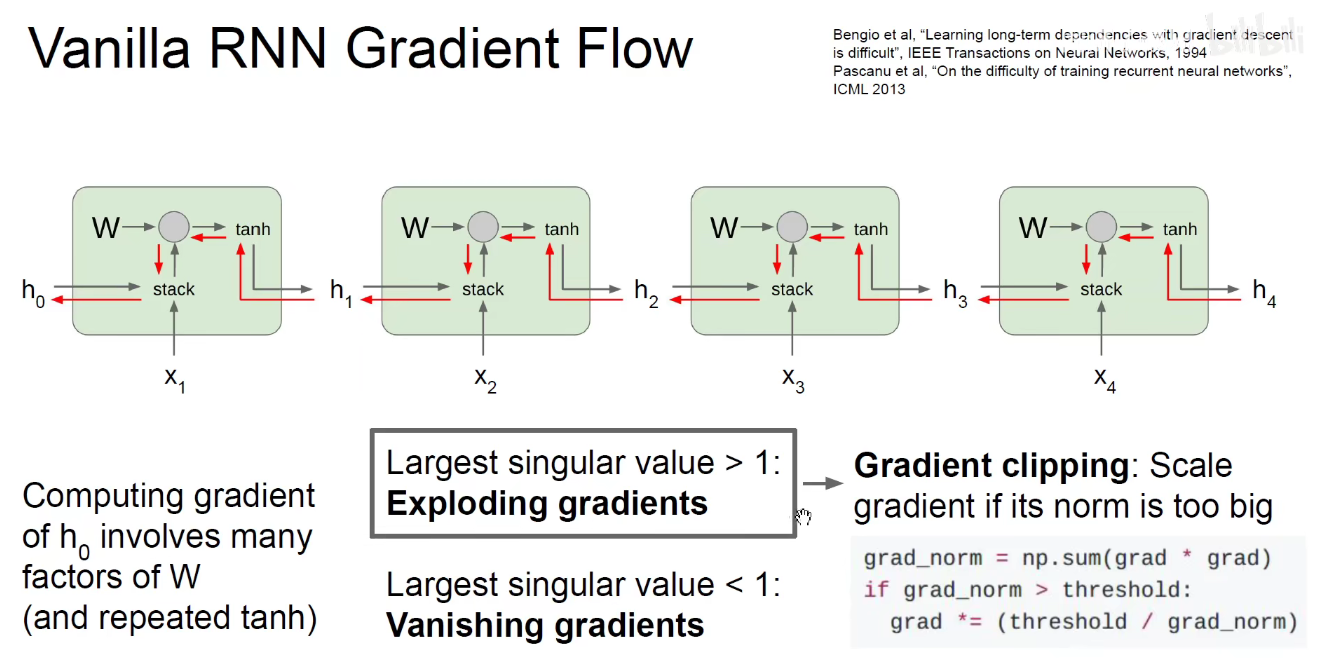
如上图:我们可以使用梯度裁剪-Gradient clipping的方法进行惩罚,如果大于某个阈值,就惩罚它。如果小于1,就需要对RNN架构做出改变。
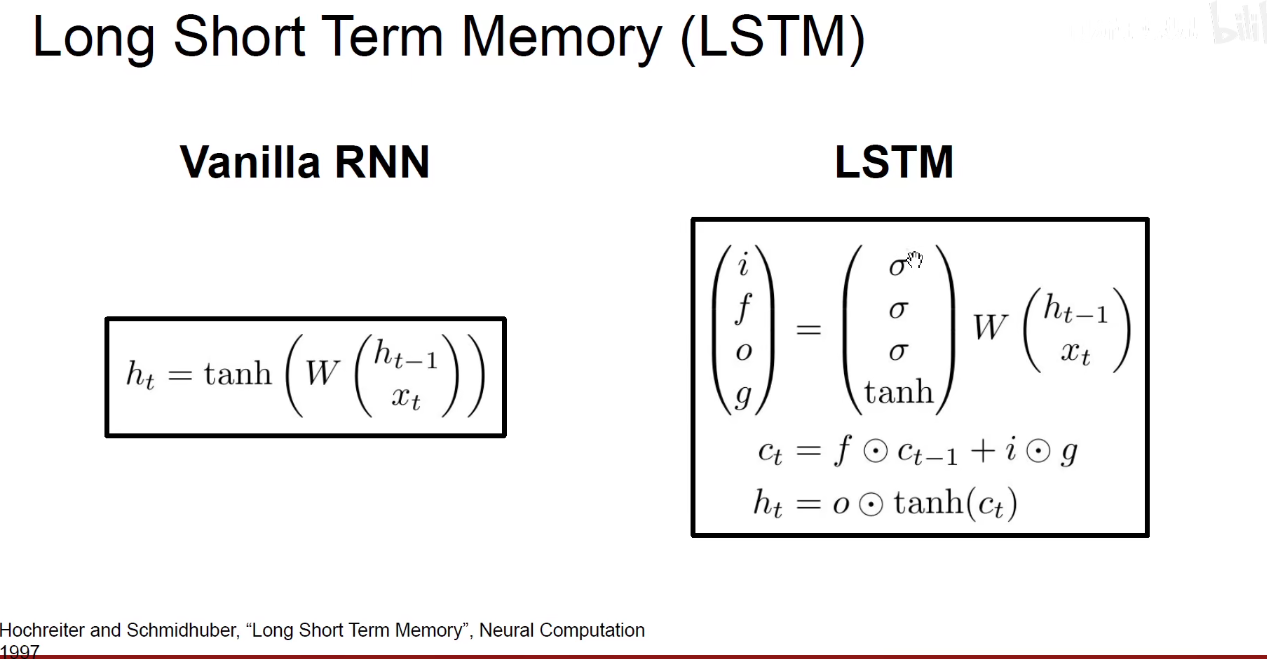
RNN变种-LSTM和GRU
LSTM:Long short-term memeoy,长短时记忆神经网络。
GRU:Gate Recurrent Unit,门控循环单元。
在LSTM中,有一个长期记忆和一个短期记忆,即隐含状态不再是一个向量,而是两个向量,上面的是长期记忆,下面的是短期记忆,他其实有4个门,遗忘门、输入门、输出门。更新门。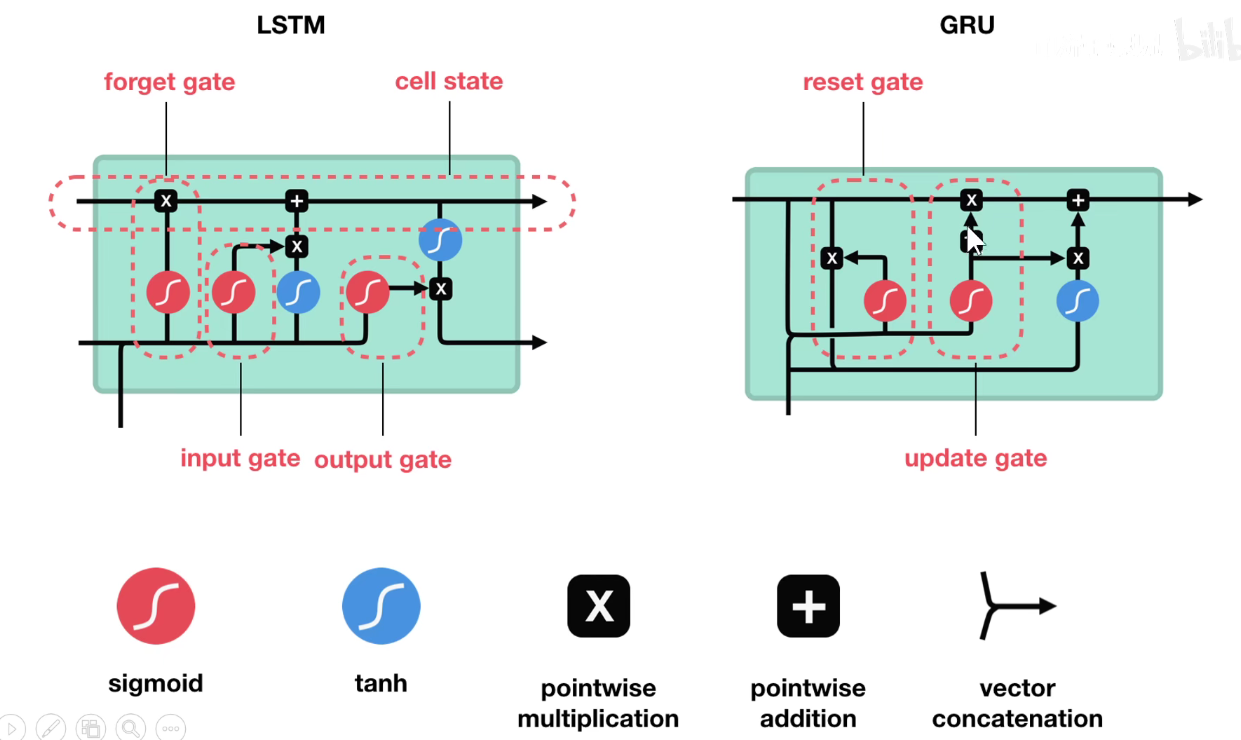
LSTM
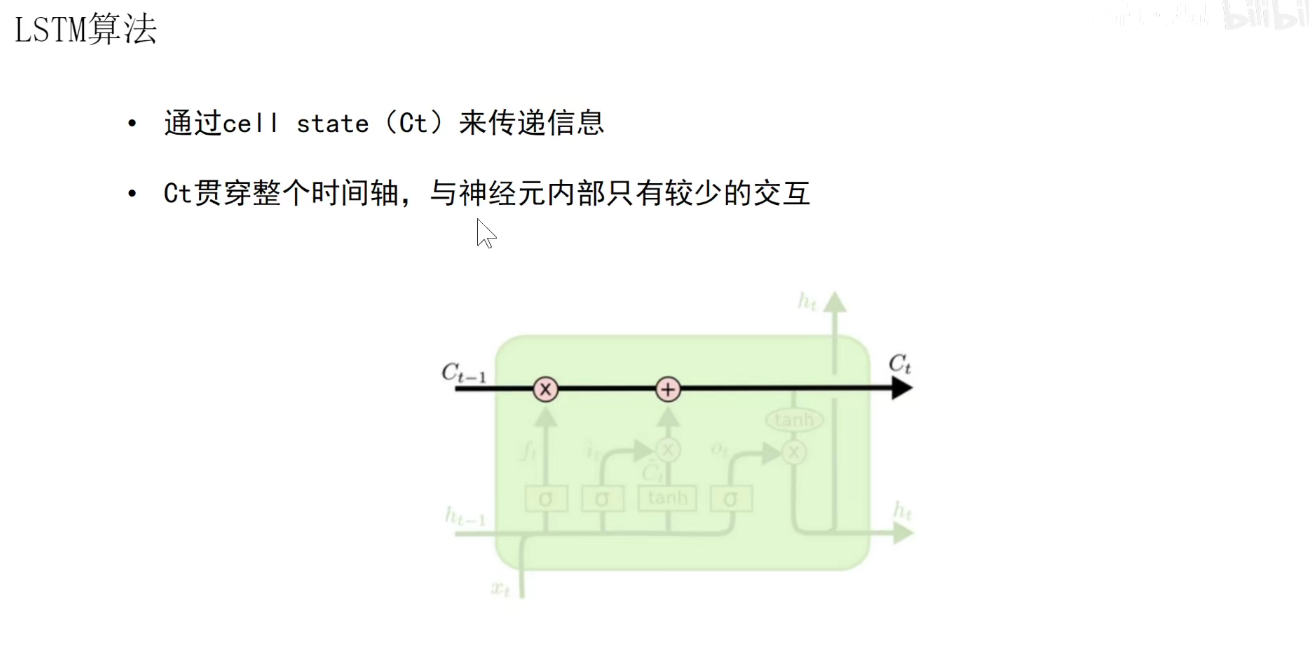
我们输入当前时刻的输入Xt,以及上一个时刻的短期记忆Ht-1,还有上一个时刻的长期记忆Ct-1,长期记忆又称为Cell State。
输出是新的短期记忆ht,新的长期记忆Ct还有当前的输出ht。当前的输出是由短期记忆产生的。
中间要经过很多的处理。如长期记忆处理流程:上一个长期记忆要乘以一个Sigmoid函数的结果(0-1),对长期记忆乘以一个0到1的数,表示要让他忘掉一些东西,值为1表示保留,值为0,表示忘掉。因此称为遗忘门。
经过遗忘门之后。需要增加一些记忆,增加的记忆由seigema和tanh等不同变体产生,加上后输出了新的长期记忆。
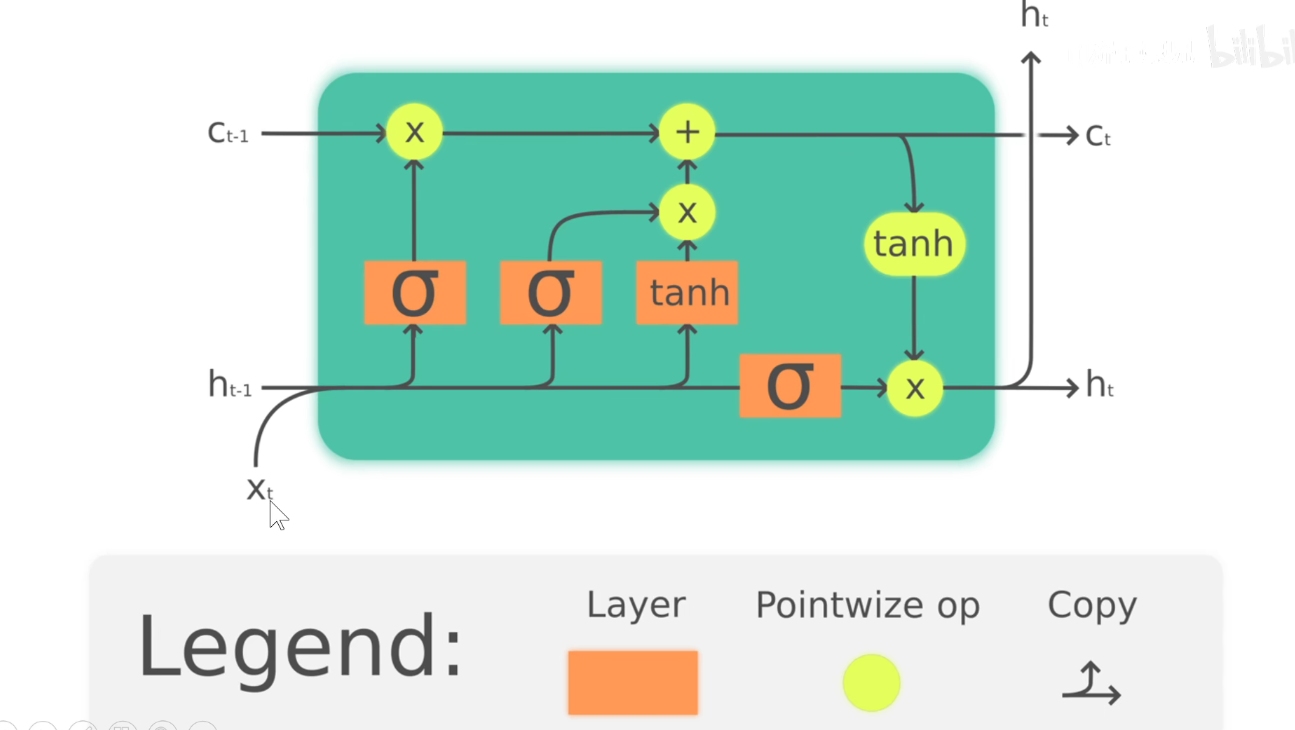
在每一个单元中,长期记忆是可以贯通的(如果他不忘记的话),所以在LSTM中,长期记忆是操作最少的,只有一个忘记操作和一个更新操作,没有其他花里胡哨的操作。
遗忘门的操作:ft就是一个0-1之间的值,表示他要忘掉多少。Wf表示一套权重。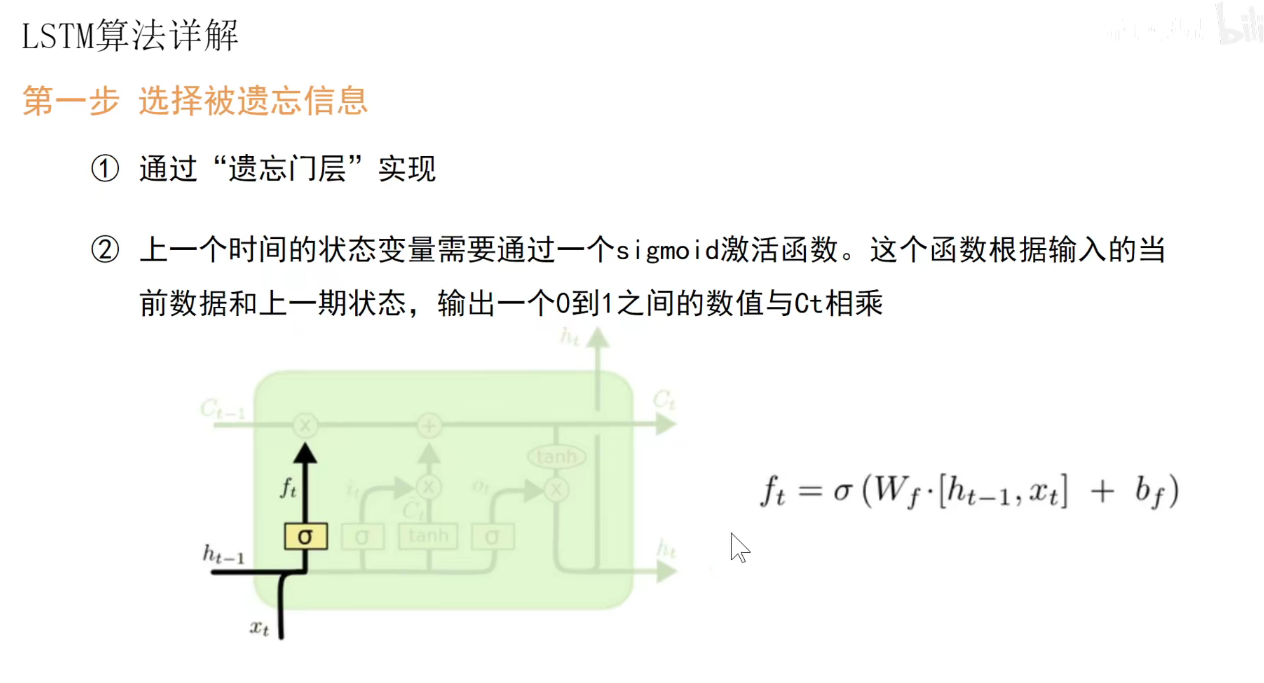
更新们的操作:用另外两套权重Wi和WC对其进行处理。分贝生成i和Ct,作为输入量。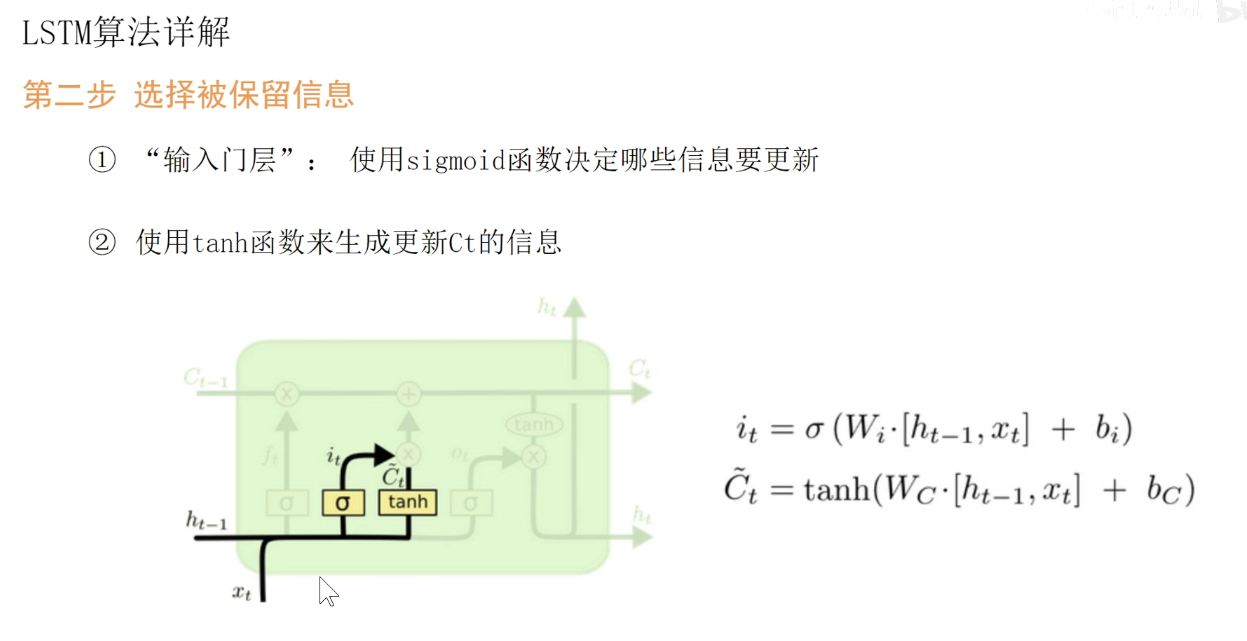
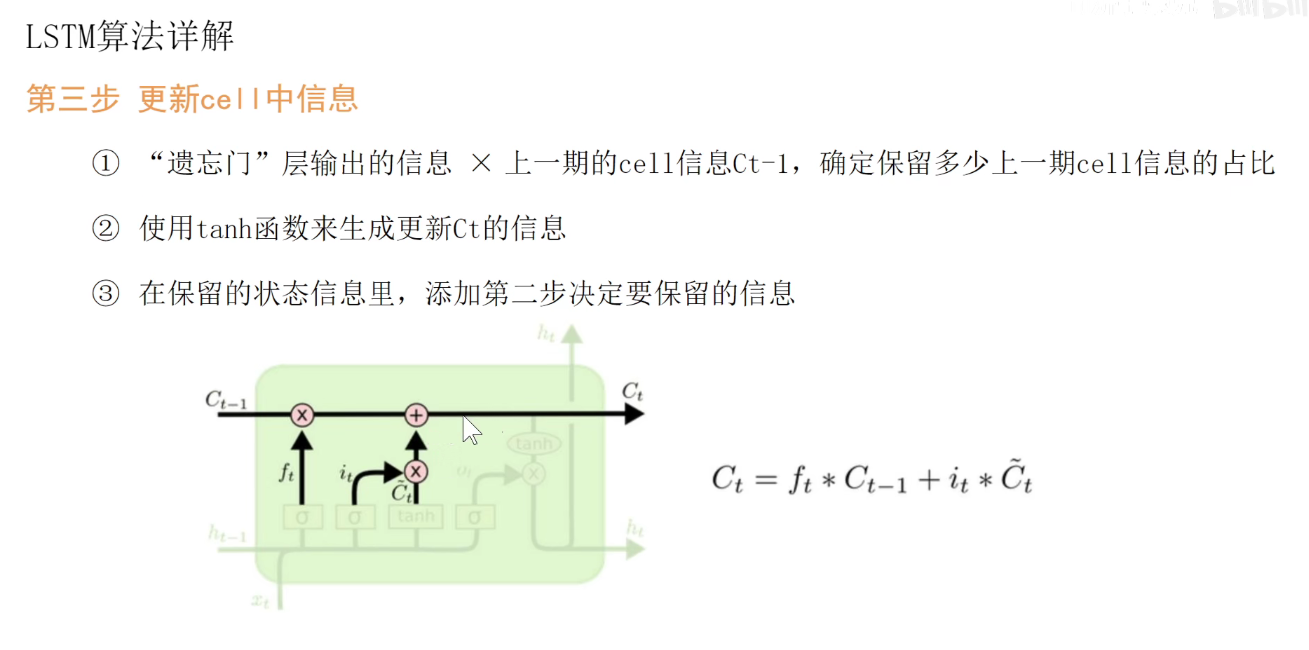
至此,新的长期记忆Ct已经完成。
下面来看看新的短期记忆是如何产生的?
用第四套权重Wo,对其进行处理,使用Sigmoid对其进行激活,得到了Ot这个值,然后用Ot乘以经过tanh处理过的新长期记忆值,就得到了短期记忆Ht,并且短期记忆Ht是作为每个单元的输出的。
在循环神经网络中,每个时刻都是要有输出的,这个输出就是短期记忆Ht,同时短期记忆Ht作为下一个时刻的输入,被作为了新的Ht-1.
中间变量就是4个值,ft ,it,Ct ,O。
现在来看看CS231N的课件
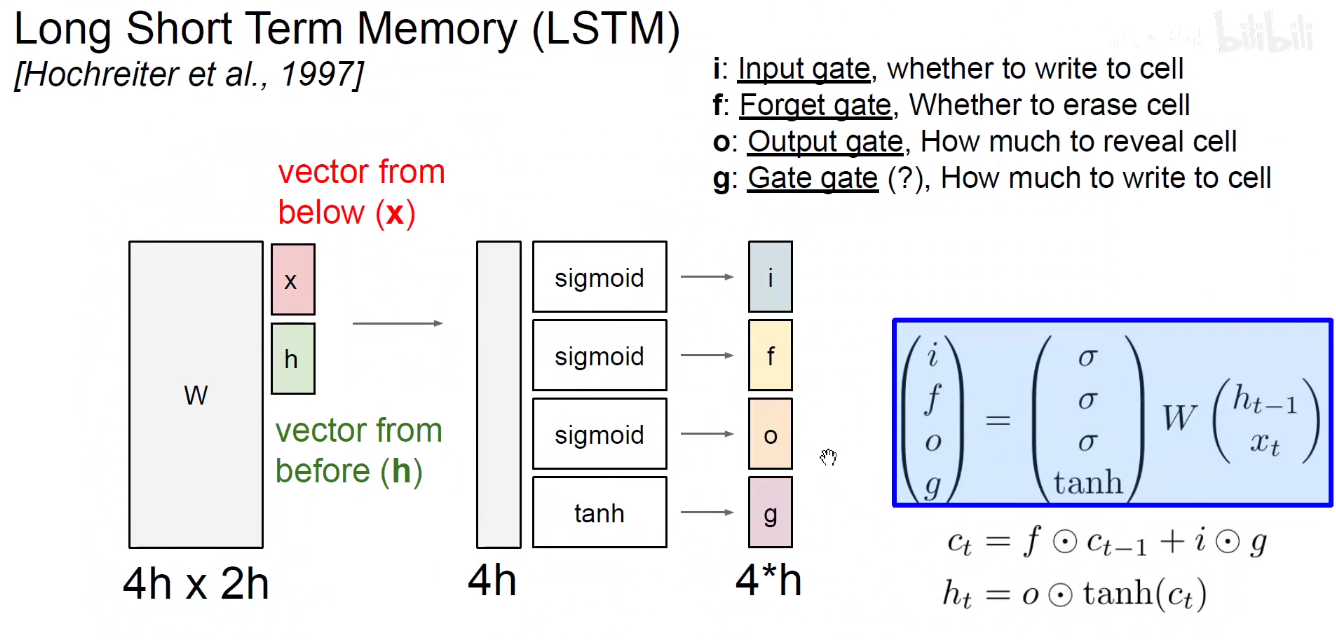
把当前的输入和上一个时刻的隐含状态Stack起来,分别用4套权重去得到这四个值。
f这个值用于点乘长期记忆,让他遗忘掉某些值。
i和g点乘再加到原来的长期记忆上输出。
长期记忆经过双曲正切变换,和O点乘得到新的短期记忆。
正是因为长期记忆是贯穿整个时间轴的,而且它是通过加法来更新,使得梯度可以顺利的传递回去。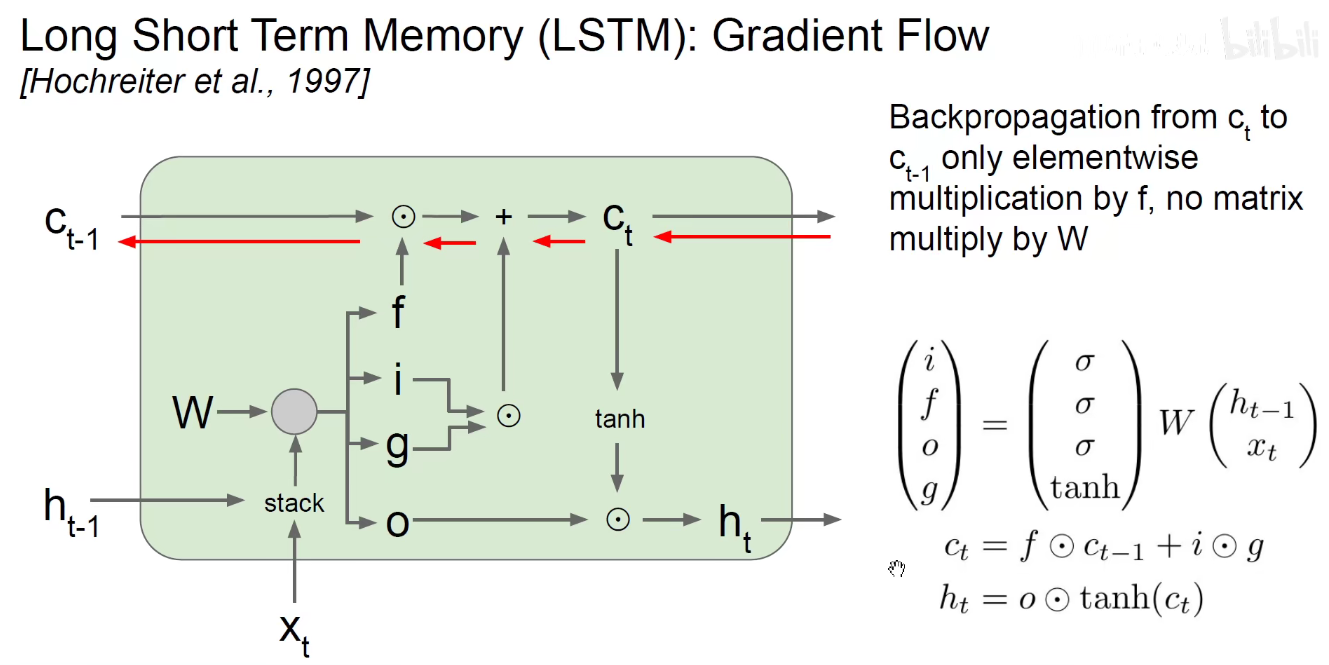
可以认为遗忘门是非开机关的门。如果门开着,相当于长期记忆畅通无阻的贯穿到最后,如果中间某个时刻门关上了,那之后的梯度与之前毫无关系,后续的长期记忆仍然按照上述流程。。
此处的图画的不是很明白,看16年的图吧。。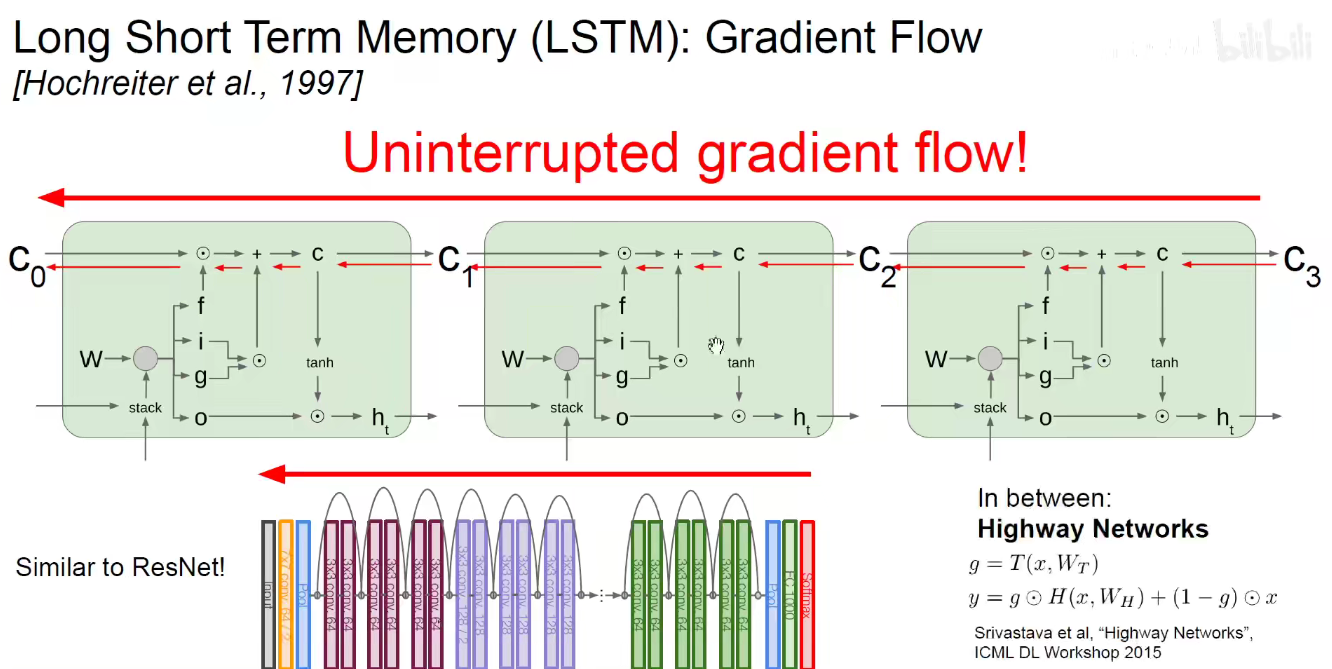
16年的图: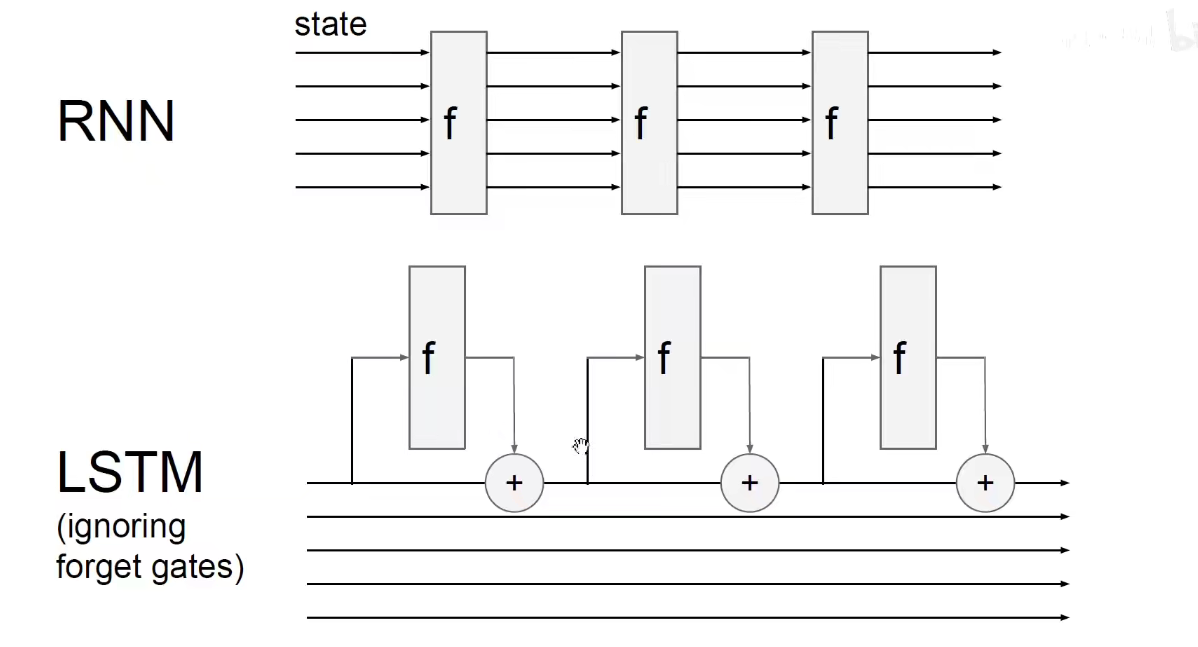
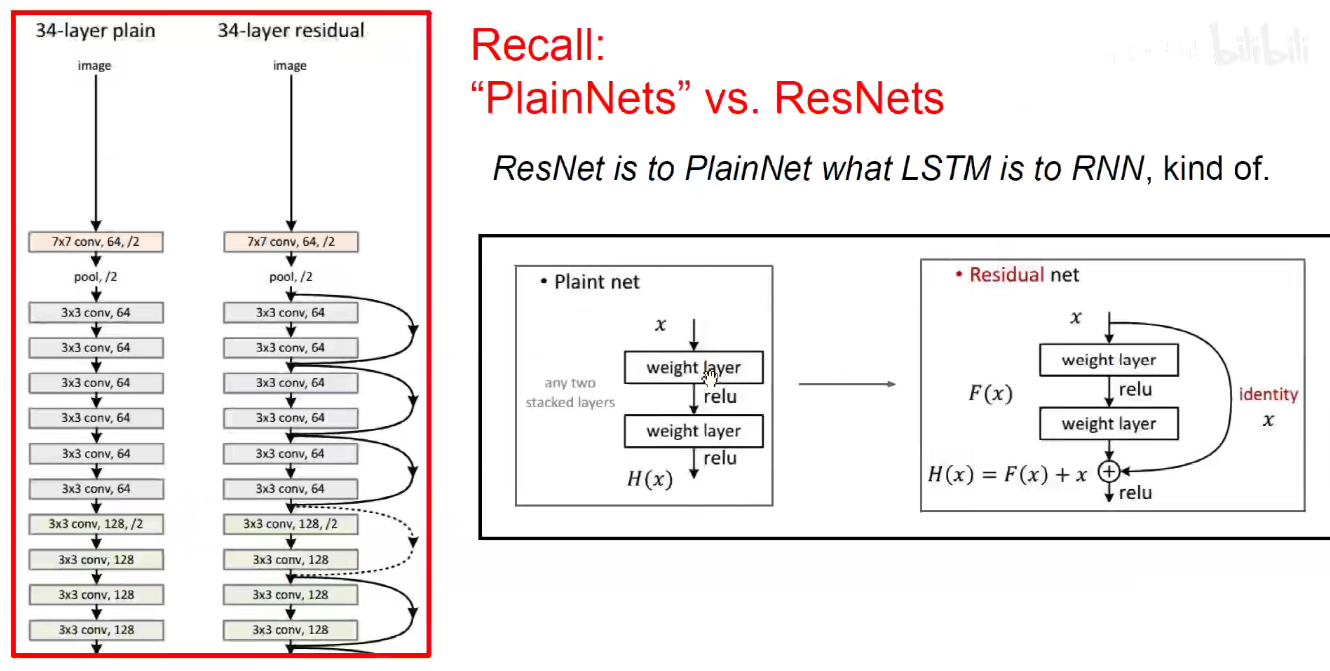
由上可知,在RNN和CNN中都用到了同样的技巧来避免梯度消失。
其他RNN的变种:
GRU:两个门,重置门和更新门。
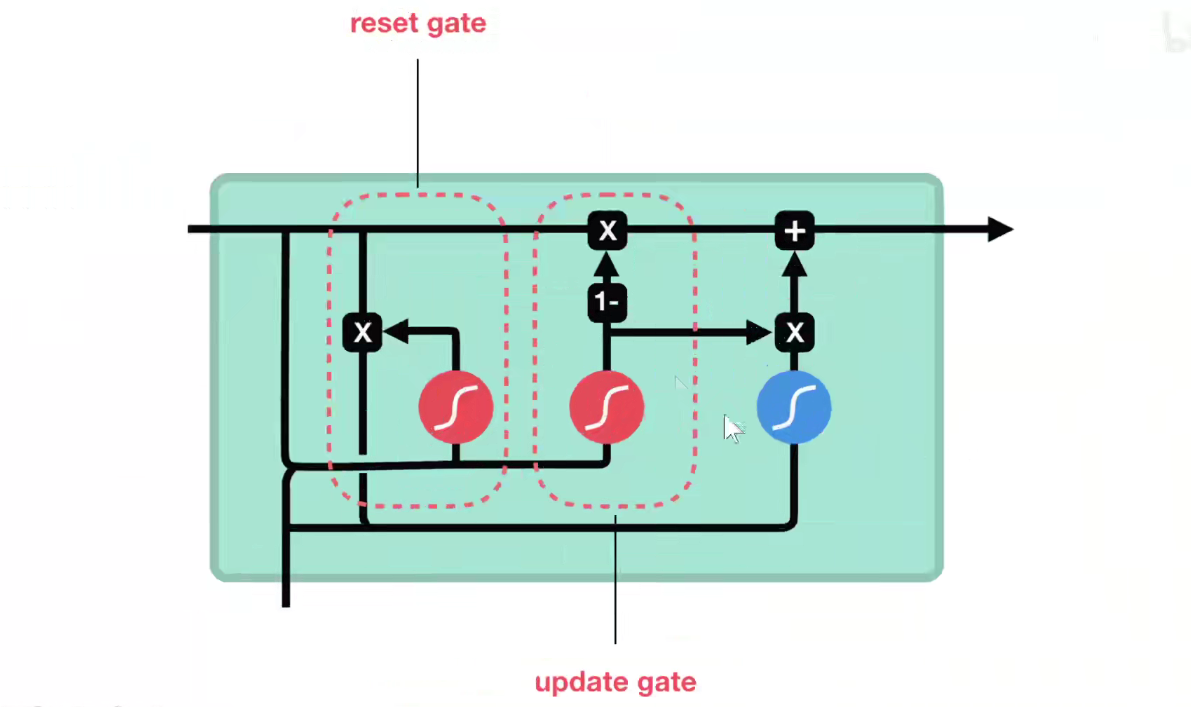
LSTM先发明,GRU后发明,真实情况下,使用LSTM更多一些。

总结
