1. 简书
2018-09-28 RCNN,FAST-RCNN,FASTER - RCNN家族发展史演进
首先,object detection,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。所以,object detection要解决的问题就是物体在哪里以及是什么的整个流程问题。
目前学术和工业界出现的目标检测算法分成3类:
传统的目标检测算法:Cascade + HOG/DPM/SIFT + Haar/SVM以及上述方法的诸多改进、优化;
候选窗+深度学习分类:通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如:
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
R-FCN
等系列方法;
- 基于深度学习的回归方法:YOLO/SSD/DenseBox 等方法;以及最近出现的结合RNN算法的RRC detection;结合DPM的Deformable CNN等
今天我们了解一下第二类的发展历程
object detection技术的演进:
RCNN->SppNET->Fast-RCNN->Faster-RCNN
我们不妨从从图像识别的任务说起:
这里有一个图像任务:
既要把图中的物体识别出来,又要用方框框出它的位置。那么任务用专业的说法就是:图像识别+定位
图像识别我们用cnn去做一分类问题,无论用softmax,还是Logistic,都可以解决问题,但定位如何做呢?
思路1:回归的方法做
看做回归问题,我们需要预测出(x,y,w,h)四个参数的值,从而得出方框的位置。
所以对于一个cnn我们可以保持前面不变,对cnn结尾处做出改进,做成classification + regression模式,
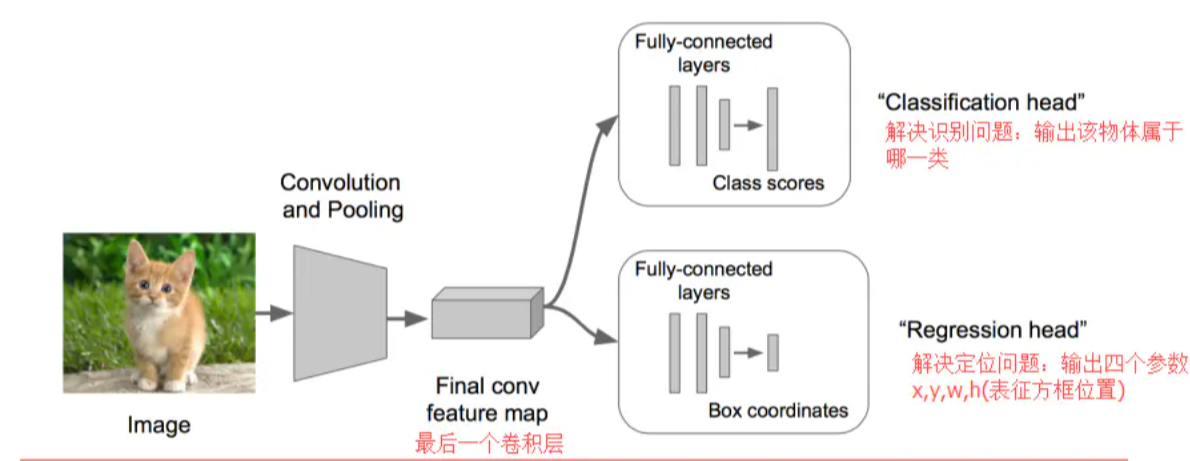
Regression那个部分用欧氏距离损失,并用使用SGD训练,并在预测阶段把2个头部拼上从而完成不同的功能。
Regression那个部分用欧氏距离损失,并用使用SGD训练,并在预测阶段把2个头部拼上从而完成不同的功能。
而Regression的部分加在哪?两个处理方法:
• 加在最后一个卷积层后面(如VGG)
• 加在最后一个全连接层后面(如R-CNN)
但regression太难做了,regression的训练参数收敛的时间要长得多,应想方设法转换为classification问题。
所以上面的只是引子,取窗口图像的方法才是正题
还是刚才的classification + regression思路
• 咱们取不同的大小的“框”
• 让框出现在不同的位置,得出这个框的判定得分
• 取得分最高的那个框
但问题又来了,框有位置,大小之分,我们怎么叫计算机找到合适的呢?比如:
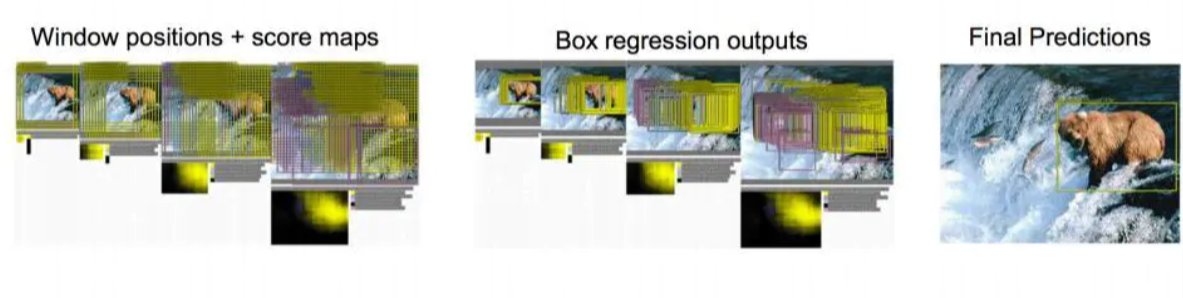
这就是学过的取不同的框,依次从左上角扫到右下角。非常粗暴的方法,就是对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出每个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)
这个方法明显人工智障,所以我们做了优化:
这个方法明显人工智障,所以我们做了优化:
1.把FC层改为conv层,提提速
但问题又来了,当图像有很多物体怎么办?
那任务就变成了:多物体识别+定位多个物体
看成分类问题是完全可以的,但如果还用人工智障的方法,估计运算就没尽头了。。。。
所以有人就提出一个好方法:候选框思路
找出可能含有物体的框(也就是候选框,比如选1000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举的所有框了。

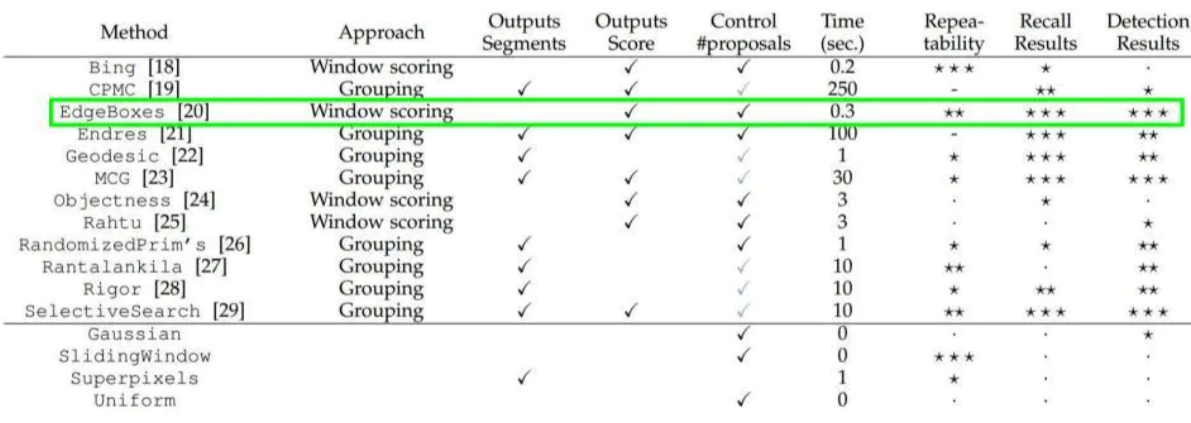
大牛们发明好多选定候选框的方法,比如EdgeBoxes和Selective Search。以下是各种选定候选框的方法的性能对比。
到了这一步,RCNN就横空出世了
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
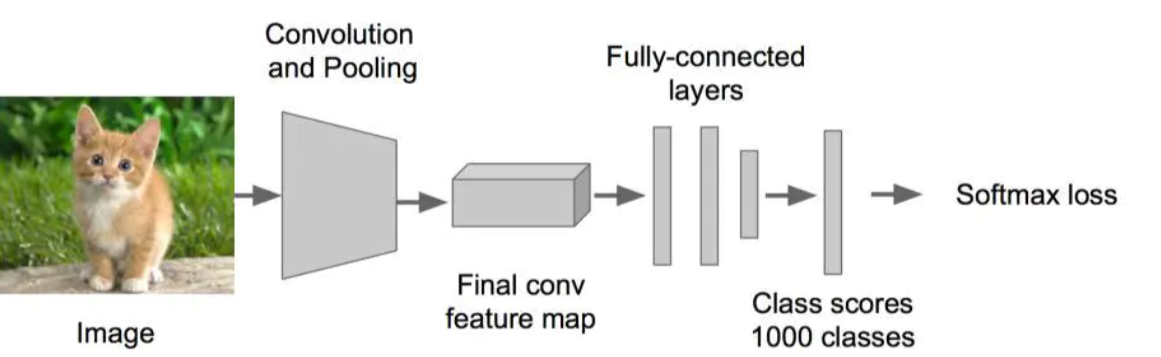
步骤二:对该模型做fine-tuning,将分类数从1000改为20,去掉最后一个全连接层
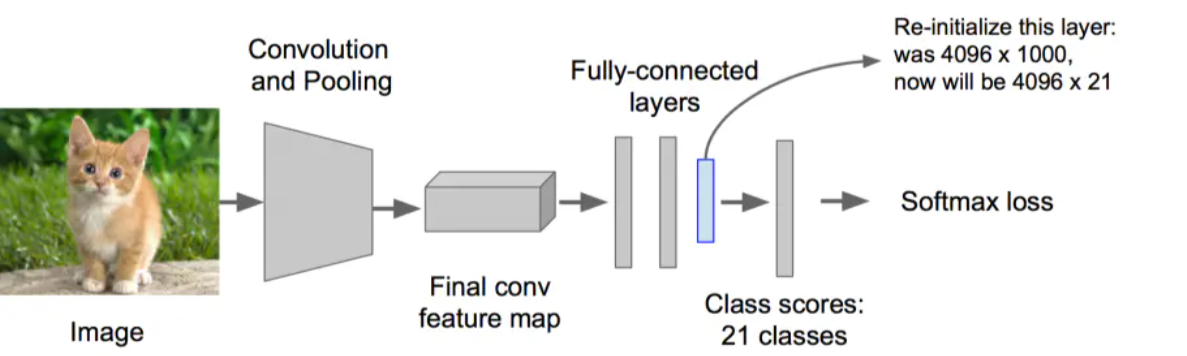
步骤三:特征提取
• 提取图像的所有候选框(选择性搜索)
• 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
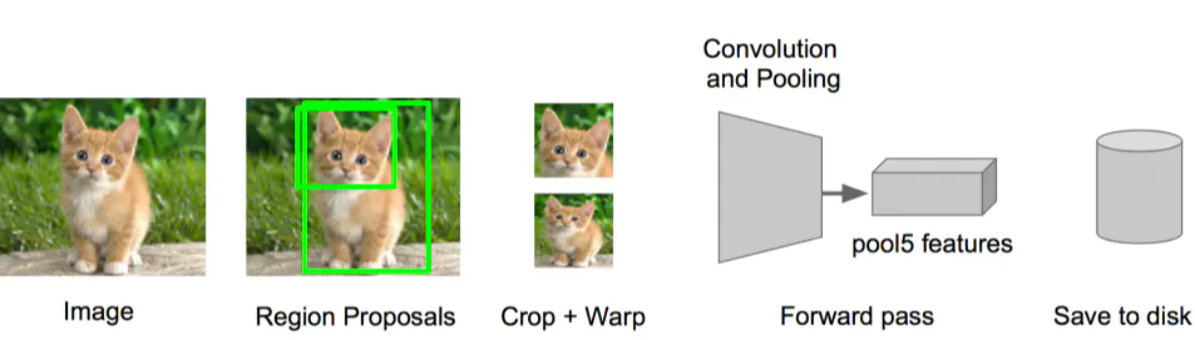
步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative
比如下图,就是狗分类的SVM你输入几张图片后svm分类的反应:
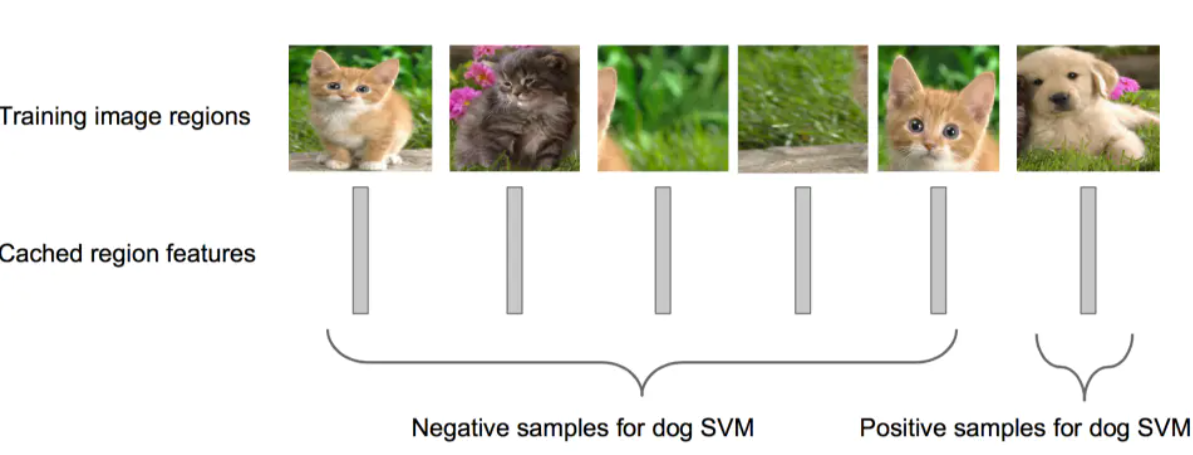
步骤五:使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。如此循环往复,直到框的位置达到理想的范围

这个方法明显还是会有很大的运算量,对实时识别还是相当不利的,而后来的FAST-RCNN则是吸收了SPP Net的
空间金字塔池化(spp)的方法,做到了对这个问题的优化。(FPN是特征金子塔网络)
1.运用金子塔的思想,SPP layer的pooling中拥有自适应的filter,实现了数据的多尺度输入
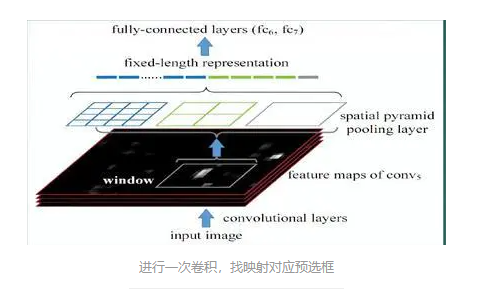
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。
如下图所示,在卷积层和全连接层之间加入了SPP layer。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
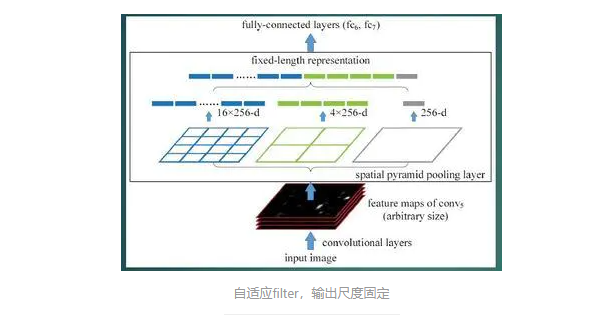
2.只对原图提取一次卷积特征,不再是挨个把候选框一个一个的输入到下一层,一个一个去卷积
在R-CNN中,每个候选框先resize到统一大小,然后分别作为下一层CNN的输入去conv,这样是很低效的。
所以SPP Net根据这个缺点做了优化:只对原图进行一次conv得到整张图的feature map,然后找到每个候选框zaifeature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。这样就节省了大量的之前一个一个conv所花费的计算时间,比R-CNN有一百倍左右的提速。
Fast R-CNN问世
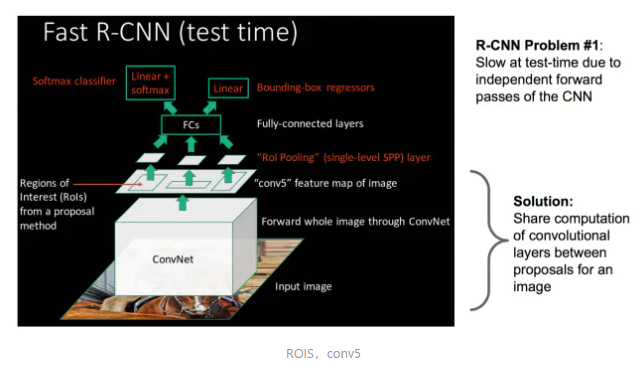
fast-rcnn不同在于:
1.它含有一个可以视为单层sppnet的网络层,叫做ROI Pooling,这个ROI Pooling做到跟sppnet一样,对每个不同的region都提取一个固定纬度的特征表示,在通过softmax进行类型识别。这是它吸取了spp net的第一个优点
2.在Fast-RCNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。(其实就是做了spp net的第二个优势处)
也就是fast-rcnn利用共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,只卷积一次,每个框找自己的对应映射,输入映射patch在第五个卷积层再得到每个候选框的特征。
原来的方法:许多候选框(比如两千个)–>CNN–>得到每个候选框的特征–>分类+回归
现在的方法:一张完整图片–>CNN–>得到每张候选框的特征–>分类+回归
所以容易看见,Fast RCNN相对于RCNN的提速原因就在于:不过不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
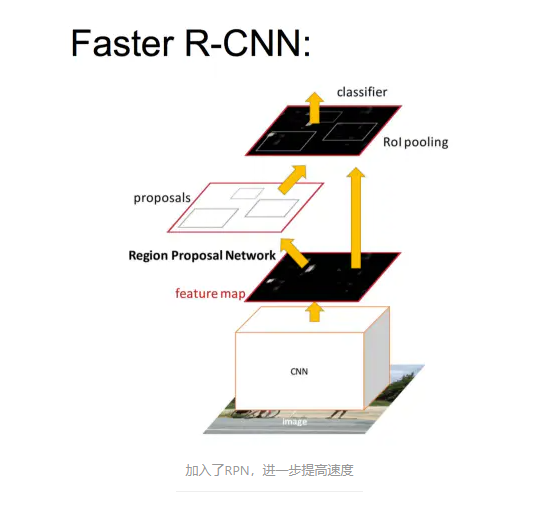
FASTER-RCNN:
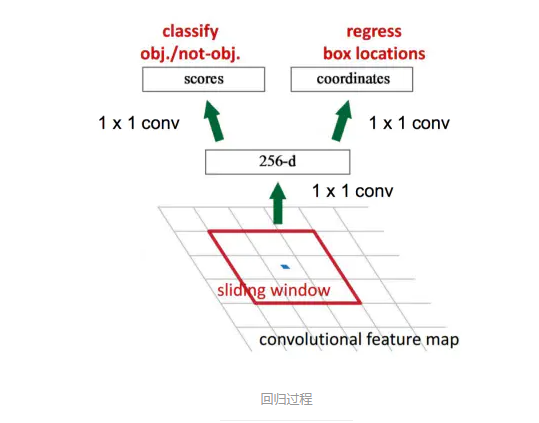
RPN简介:
• 在feature map上滑动窗口
• 建一个神经网络用于物体分类+框位置的回归
• 滑动窗口的位置提供了物体的大体位置信息
• 框的回归提供了框更精确的位置
一种网络,四个损失函数;
• RPN calssification(anchor good.bad)
• RPN regression(anchor->propoasal)
• Fast R-CNN classification(over classes)
• Fast R-CNN regression(proposal ->box)
也就是说,RPN预先已经帮它找了一遍预选框,所以它的速率得以进一步提升
速度对比:
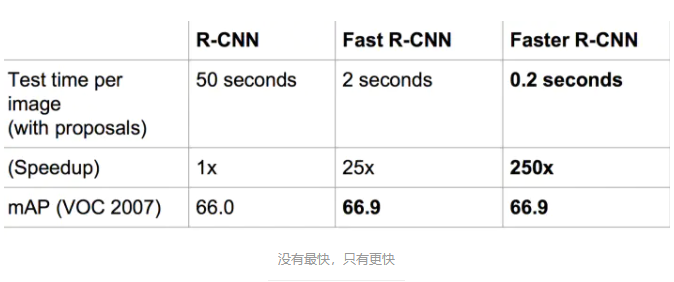
总结各个算法的步骤:
RCNN
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 每个候选框内图像块缩放至相同大小,并输入到CNN内进行conv
3. 对候选框中提取出的特征,使用svm分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
Fast RCNN
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 对整张图片输进CNN进行一次conv,得到feature map ———(_快在这一步_)
3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5. 对于属于某一特征的候选框,用回归器进一步调整其位置
Faster RCNN
1. 对整张图片输进CNN,得到feature map
2. 卷积特征输入到RPN,得到候选框的特征信息 ———(_更快在这一步_)
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
总的来说,从R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简,精度越来越高,速度也越来越快。可以说基于region proposal的R-CNN系列目标检测方法是当前目标检测技术领域最主要的一个分支。