王喆《深度学习推荐系统》
1. 写在前面
今天开始, 开始尝试进行机器学习算法的一些查缺补漏知识的整理, 主要还是之前没有注意的一些点吧, 之前的一篇补充了线性回归与梯度下降算法的一些细节, 这篇文章主要是对逻辑回归算法模型的细节梳理,以及常用的两种优化算法, 包括梯度下降和拟牛顿法, 最后就是L1和L2正则。
这次梳理以重点知识为主, 白话为辅了哈哈 , 因为这些细节部分都是面试中容易出现的一些身影, 所以先初步整理一下, 到时候再简单复习回顾, 这次得严肃一点 😉
大纲如下:
- 逻辑回归算法(要点, 来历)
- 常用的优化算法(梯度下降算法和拟牛顿法)
- 正则(L1和L2正则的区别再次梳理)
Ok, let’s go!
2. 逻辑回归算法
2.1 要点说明
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
模型: 线性模型加入sigmoid函数就是逻辑回归模型, 所以理解起来就是这样:
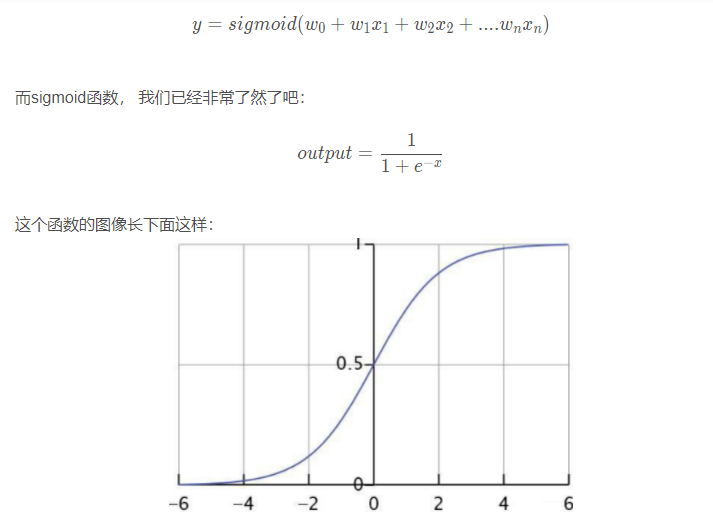

基于这几点性质, 才使得逻辑回归适合二分类问题, 上面这些是基本常识了。当然sigmoid也是有来历的, 不是凭空出来的, 后面的广义线性模型里面会提到这点。
损失函数以及由来: 关于逻辑回归的损失函数, 这里先上结论
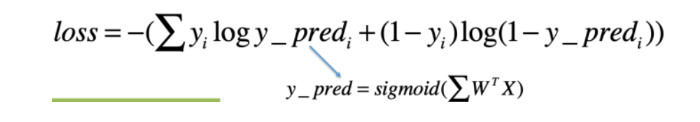
这就是大名鼎鼎的交叉熵损失, 那么这个东西是怎么来的呢? 这个才是重点了, 哈哈。
逻辑回归模型是这样的, 它假设样本服从的是伯努利分布, 伯努利分布就是概率论里面学的多次抛硬币试验的那个, 每次试验两个结果, 每次试验互不干扰, 那么假设y_pred表示y=1的概率, 则给定X, Y的概率结果就是0和1, 如果y=1是y_pred, 那么y=0就是1-y_pred, 即下面的这个式子:

也就是说, 给定我一个样本, 我预测它属于某一类的概率就是上面这个式子, 注意, 这个式子里面对于某一个样本只会有一个概率, 因为y要么等于1, 要么等于0。 如果是等于1, 那么我们的预测概率是y_pred, 我们希望这个越大越好,因为他越大, 就越接近1, 而如果等于0, 我们预测概率是1-y_pred, 我们依然希望这个越大越好, 也就是说对于一个样本, 上面的这个式子越大, 我们预测的分类就会越准确。
那么多个样本呢? 就是它了:
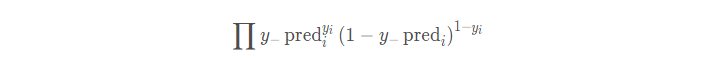
我们依然是希望这个概率最大, 这就是极大似然的思想。 概率最大, 才说明我们的模型预测的更加准确。但是这个函数呢, 有连乘, 不太好优化, 所以取对数, 然后取负号, 就变成了loss的形式了:

这就是逻辑函数的损失函数的推导过程, 主要有两个要点:
- 假设样本服从的分布: 伯努利
- 损失函数的由来: 伯努利分布的极大似然估计
那么应该怎么求解参数w呢?
这时候就用到了梯度下降算法。关于梯度下降算法的细节补充, 可以参考前面梳理的这个梯度下降算法的细节补充, 要明确下面几个概念:
- 梯度下降算法属于优化算法, 另外一个常见的优化算法是牛顿法
- 梯度下降法要优化的参数是w, 也就是自变量
- 梯度下降法中的“梯度”针对的是损失函数loss
下面看一下逻辑回归模型中梯度的推导过程:
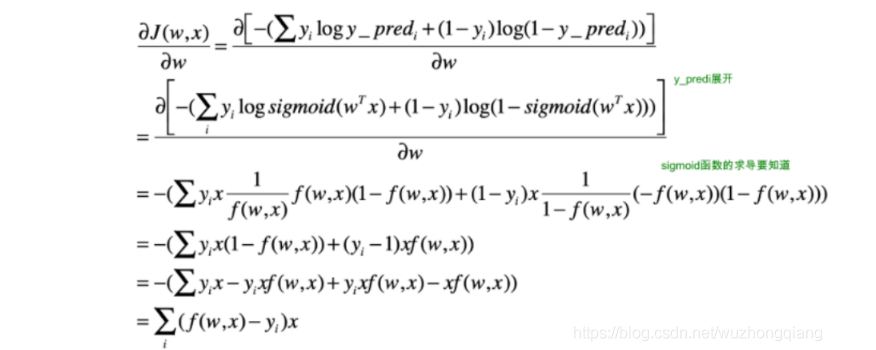
可以发现一个很有意思的事情, 竟然这个梯度等于了每一个样本的预测误差乘以样本的特征值本身。
有了参数, 就可以进行更新:
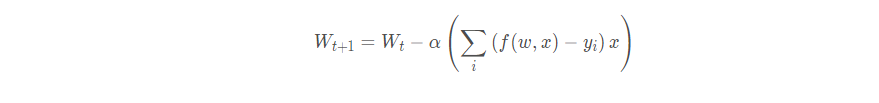
关于逻辑回归, 还需要知道:
- 逻辑回归对于高维稀疏类别的特征有比较好的拟合效果
- 由于特征的稀疏性, 还间接的起到了特征选择的作用, 因为某些特征非常稀疏, 会有很多的0, 这时候, 参数的更新基本上就只更新那几个对于loss非常重要的特征, 使得w0+w1*x1…这一长串很多值都是0
- 离散化比如说对某个特征进行分桶, 这样可以增加模型的鲁棒性, 不容易被某个特征给带偏, 比较稳定, 类似于归一化
- 分桶之后, 也相当于引入了非线性
2.2 指数族分布与广义线性模型
这里算是一个拓展知识吧, 毕竟有些东西知其然, 知其所以然才有意思,我们上面埋了一个伏笔就是说sigmoid函数并不是凭空出现的, 而是有一定来历的, 那么这个东西到底是怎么来的呢?
答: sigmoid函数是由对数线性模型推过来的, 但是啥子叫对数线性模型? 在介绍这个之前, 得需要知道几率比的定义。

但是突然出现了这么一个东西, 又是非常的玄幻和疑问吧, 尤其是这个对数线性模型, 为啥要取对数? 为啥取对数之后可用线性模型来表达? 感觉是在故意凑这个玩意呢? 哈哈。 下面刨根问底一下。
2.2.1 指数族分布
这个就得先从指数族分布说起, 指数族分布(The exponential family distribution),区别于指数分布(exponential distribution)。在概率统计中,若某概率 分布满足下式,我们就称之属于指数族分布

关于指数族分布, 典型的有: 泊松, gamma分布, beta分布, 伯努利分布, 正态分布。而逻辑回归, 我们说正好假设样本服从伯努利分布, 所以对上了哈哈。
那么为啥伯努利分布是指数族分布呢? 我们可以看看它公式的化简:
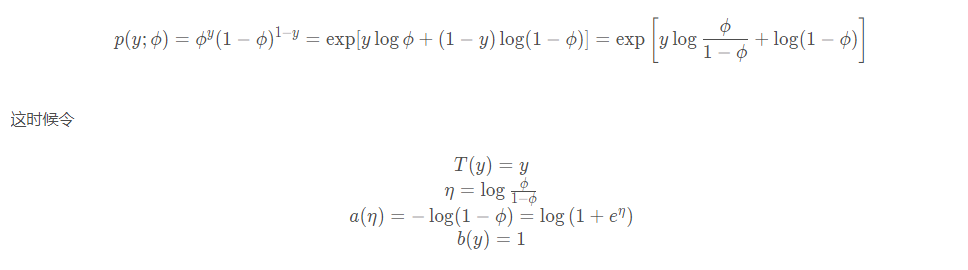
就是上面指数族分布的通式形式了。
为啥要讲这个东西呢? 首先从上面我们知道了逻辑回归模型的假设分布是一个指数型分布, 然后我们再来看看广义线性模型。
2.2.2 广义线性模型
首先, 广义线性模型的代表:
- 逻辑回归(拟合的伯努利分布)
- 线性回归(拟合的高斯分布)
这个是不是又和前面对上了, 考虑一个分类或回归问题, 我们就是想预测某个随机变量y, y是某些特征x的函数, 为了推导广义线性模型, 我们必须做出如下三个假设:

上面说的白话一下就是:
- 第一条说的就是我们要拟合的这个随机变量y的分布, 并且是一个指数族分布, 而逻辑回归拟合的伯努利分布是不是正是这个?
- 第二条说的就是怎么去拟合这个分布,也就是拟合这个分布的哪些统计量能代表这个分布。这里拟合的就是这个分布的期望
- 第三条就是线性的含义, 为啥是广义线性, 这个地方指出来了

所以最后就推出了sigmoid函数。 其实是这样出来的, 而前面讲的几率比, 对数几率回归等都是基于指数族分布, 广义线性模型的理论推导出来的。
说完了逻辑回归, 下面再来说说优化算法了。
3. 常用的优化算法
优化算法包括梯度法和牛顿法。
3.1 梯度法
梯度法比较简单, 更新公式也整理过多遍, 这里不再多解释。 这里重点依然是那个问题: 为何沿着梯度的方向下降就是最快的?
之前整理的时候, 白话太多, 导致知识点不连贯, 这里直接上重点:
当我们在某个要优化的函数, 这里设为f(x), 我们在x点处, 然后沿着方向v进行移动, 到达f(x+v), 看下面图:

3.2 牛顿法

关于牛顿法, 计算太慢了, 所以目前用的比较少, 因为这些x可不是1个数, 这些都是向量, 并且二阶导这里是一个海塞矩阵, 而分母上的话就涉及到了矩阵求逆的问题了。 所以计算量太大了,并且也不一定逆矩阵存在。 所以更多的时候用的拟牛顿法。
最后, 再来看看正则。
4. 正则化
正则化的目的: 减小模型参数大小或者参数的数量, 缓解过拟合。 正则化其实就是在原来的目标函数的基础上又加了一项非负项, 并且这个非负项是w的函数。 这样的话target不变的基础上得让这个loss变得小一点, 相当于对其产生了一种约束。 比如之前的时候, 我要拟合100, 我有10个w, 假设特征是1, 那么这时候, 我每个w要是10, 而如果后面加了个非负, 相当于我10个w拟合的值不足100了, 那么要么去w, 要么w都变得小一点。 这正好对应了L1和L2的方式。
正则化的通用形式:
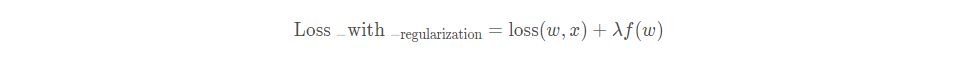
此处的λ为正则化系数。关于正则化:
- 正则化恒为非负
- 正则化项又称为惩罚项, 惩罚的是模型的参数
- 正则化系数调节惩罚的力度, 越大则惩罚力度越大。
正则化的方法: L1正则和L2正则

4.1 角度一: 解空间形状
第一个角度,就是图像的角度
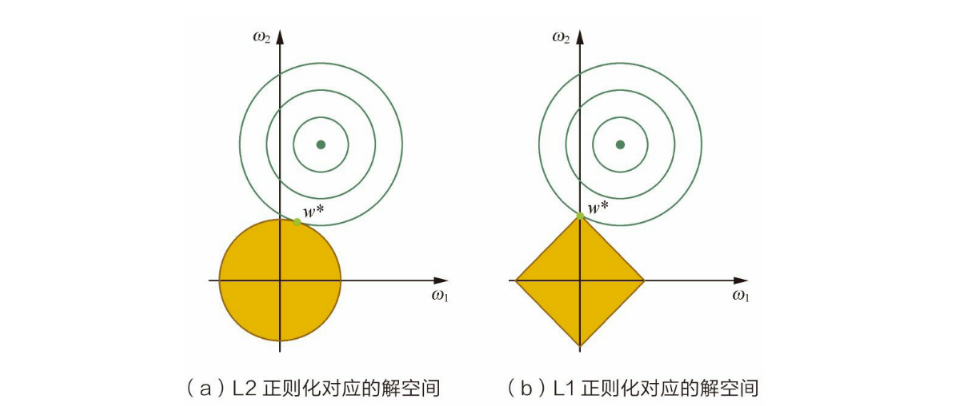
直观感受: 黄色区域表示正则项限制, 绿色色区域表示优化项的等高线, 要满足在两者交点上的点才符合最优解w\∗ , 故: 但w ww的等高线逐步向正则限制条件区域扩散的时候, 前者交点大多在非坐标轴上, 后者在坐标轴上。这是因为L1正则化约束后的解空间是菱角形, L2正则化约束的解空间是圆形, 显然, 菱角形的解空间更容易在尖角处于等高线碰撞出稀疏解。但是这样回答,还是有些笼统的,为啥加入正则项就是定义了一个解空间约束? 为啥L1和L2的解空间不同? 这个就需要从KKT条件看下了:

所以,L2正则化相当于为参数定义了一个圆形的解空间(因为必须保证L2范数不能大于m mm), 而L1正则化相当于为参数定义了一个菱形的解空间,如果原问题目标函数的最优解不是恰好落在解空间内,那么约束条件下的最优解一定是解空间的边界上,而L1“菱角分明”的解空间更容易与目标函数在等高线交点碰撞,从而产生稀疏解。
4.2 角度二: 求导
第二个角度, 求导。
从表达式上来看, L2和L1分别如上图表示, 我们想要求最小值, 很直观的一个方法就是求导, 那么不妨看看L1和L2正则化下的目标函数的导数。
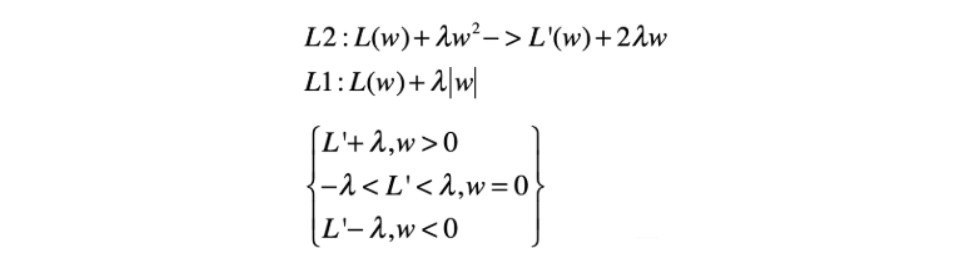
下面解释一下为啥稀疏和不稀疏:

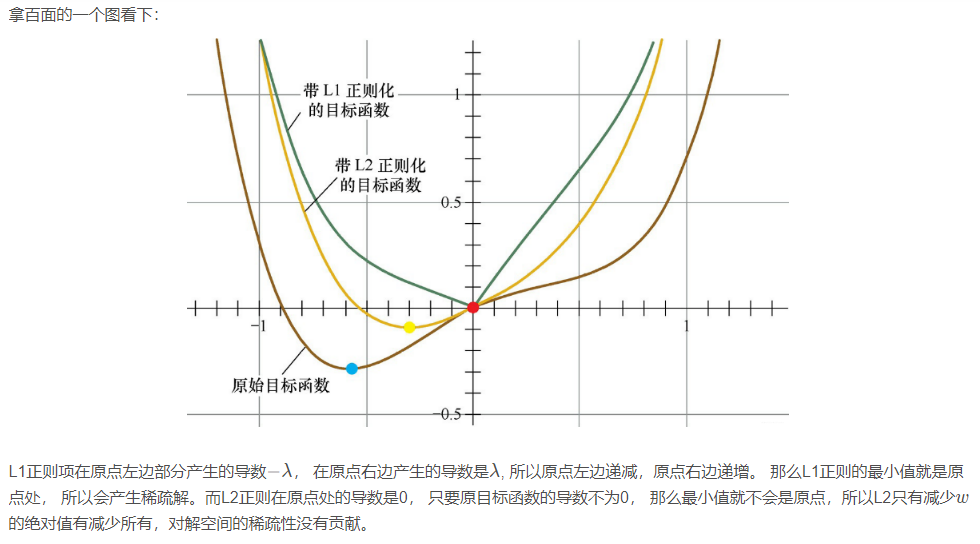
在一些在线梯度下降算法中,往往会采用截断梯度法来产生稀疏性, 这和L1正则产生稀疏的原理类似。
4.3 角度3: 贝叶斯先验
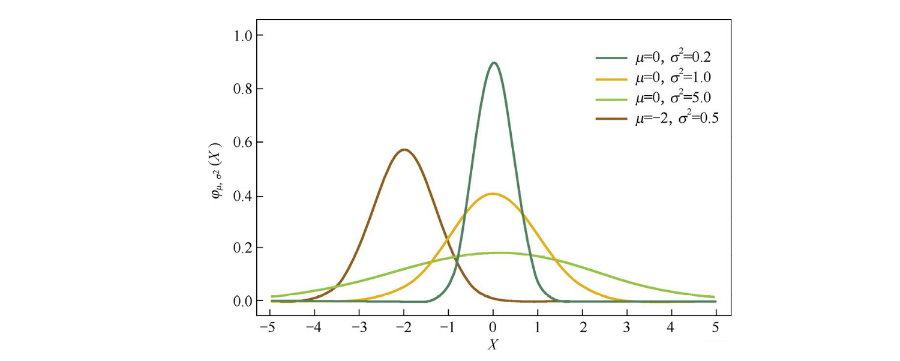
从贝叶斯的角度理解正则, 简单解释: L1正则化相当于对模型参数w ww引入了拉普拉斯先验的假设, 而L2正则相当于对参数引入了高斯先验的假设, 而拉普拉斯先验使得参数为0的可能性更大。
下面是高斯分布曲线图:
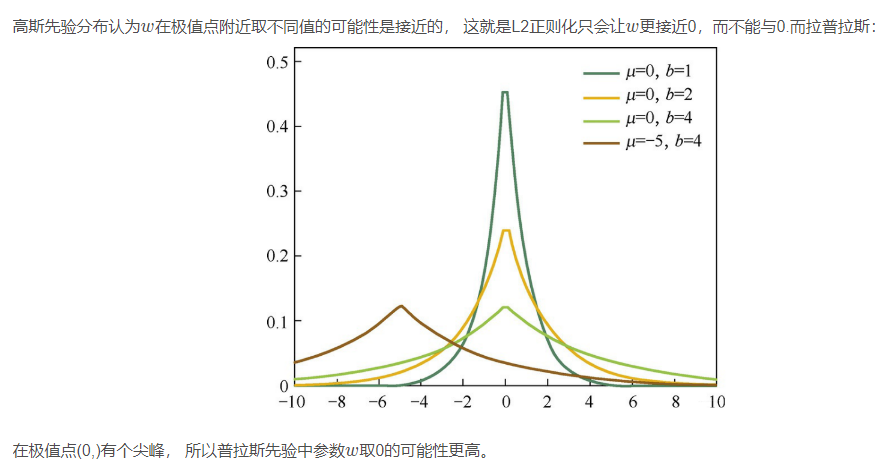
关于逻辑回归, 优化算法和正则化就先补充这么多,后面如果发现还有重要的, 会再进行补充。 上面这些点, 可以一些面试中常考的点。 关于更多逻辑回归的东西, 可以参考下面这篇文章。
【机器学习】逻辑回归(非常详细)- 阿泽哥这篇文章梳理的透透的了
逻辑回归是面试非常喜欢问的一个模型, 关于面试的重点, 可以参考下面这篇文章: