https://blog.csdn.net/yyl424525/article/details/100058264
1. 为什么会出现图卷积神经网络?
普通卷积神经网络研究的对象是具备Euclidean domains的数据,Euclidean domains data数据最显著的特征是他们具有规则的空间结构,如图片是规则的正方形,语音是规则的一维序列等,这些特征都可以用一维或二维的矩阵来表示,卷积神经网络处理起来比较高效。
CNN的【平移不变性】在【非矩阵结构】数据上不适用
- 平移不变性(translation invariance):比较好理解,在用基础的分类结构比如ResNet、Inception给一只猫分类时,无论猫怎么扭曲、平移,最终识别出来的都是猫,输入怎么变形输出都不变这就是平移不变性,网络的层次越深这个特性会越明显。
- 平移可变性(translation variance):针对目标检测的,比如一只猫从图片左侧移到了右侧,检测出的猫的坐标会发生变化就称为平移可变性。当卷积网络变深后最后一层卷积输出的feature map变小,物体在输入上的小偏移,经过N多层pooling后在最后的小feature map上会感知不到,这就是为什么R-FCN原文会说网络变深平移可变性变差。
离散卷积本质就是一种加权求和。CNN中的卷积就是一种离散卷积,本质上就是利用一个共享参数的过滤器(kernel),通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取,当然加权系数就是卷积核的权重系数(W)。
那么卷积核的系数如何确定的呢?是随机化初值,然后根据误差函数通过反向传播梯度下降进行迭代优化。这是一个关键点,卷积核的参数通过优化求出才能实现特征提取的作用,GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。
生活中很多数据不具备规则的空间结构,称为Non Euclidean data,如,推荐系统、电子交易、分子结构等抽象出来的图谱。这些图谱中的每个节点连接不尽相同,有的节点有三个连接,有的节点只有一个连接,是不规则的结构。对于这些不规则的数据对象,普通卷积网络的效果不尽人意。CNN卷积操作配合pooling等在结构规则的图像等数据上效果显著,但是如果作者考虑非欧氏空间比如图(即graph,流形也是典型的非欧结构,这里作者只考虑图),就难以选取固定的卷积核来适应整个图的不规则性,如邻居节点数量的不确定和节点顺序的不确定。
例如,社交网络非常适合用图数据来表达,如社交网络中节点以及节点与节点之间的关系,用户A(有ID信息等)、用户B、帖子都是节点,用户与用户之间的关系是关注,用户与帖子之间的关系可能是发布或者转发。通过这样一个图谱,可以分析用户对什么人、什么事感兴趣,进一步实现推荐机制。
总结一下,图数据中的空间特征具有以下特点:
1) 节点特征:每个节点有自己的特征;(体现在点上)
2) 结构特征:图数据中的每个节点具有结构特征,即节点与节点存在一定的联系。(体现在边上)
总地来说,图数据既要考虑节点信息,也要考虑结构信息,图卷积神经网络就可以自动化地既学习节点特征,又能学习节点与节点之间的关联信息。
综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。
图卷积的核心思想是利用『边的信息』对『节点信息』进行『聚合』从而生成新的『节点表示』。
2. 图卷积网络的两种理解方式
GCN的本质目的就是用来提取拓扑图的空间特征。 而图卷积神经网络主要有两类,一类是基于空间域或顶点域vertex domain(spatial domain)的,另一类则是基于频域或谱域spectral domain的。通俗点解释,空域可以类比到直接在图片的像素点上进行卷积,而频域可以类比到对图片进行傅里叶变换后,再进行卷积。
所谓的两类其实就是从两个不同的角度理解,关于从空间角度的理解可以看本文的从空间角度理解GCN
2.1 vertex domain(spatial domain):顶点域(空间域)
基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有 Message Passing Neural Networks(MPNN)[1], GraphSage[2], Diffusion Convolution Neural Networks(DCNN)[3], PATCHY-SAN[4]等。
2.2 spectral domain:频域方法(谱方法)
这就是谱域图卷积网络的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的convolution,最后与深度学习结合提出了Graph Convolutional Network。
基于频域卷积的方法则从图信号处理起家,包括 Spectral CNN[5], Cheybyshev Spectral CNN(ChebNet)[6], 和 First order of ChebNet(1stChebNet)[7] 等
论文Semi-Supervised Classification with Graph Convolutional Networks就是一阶邻居的ChebNet
认真读到这里,脑海中应该会浮现出一系列问题:
Q1 什么是Spectral graph theory?
Spectral graph theory请参考维基百科的介绍,简单的概括就是借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质
Q2 GCN为什么要利用Spectral graph theory?
这是论文(Semi-Supervised Classification with Graph Convolutional Networks)中的重点和难点,要理解这个问题需要大量的数学定义及推导
过程:
(1)定义graph上的Fourier Transformation傅里叶变换(利用Spectral graph theory,借助图的拉普拉斯矩阵的特征值和特征向量研究图的性质)
(2)定义graph上的convolution卷积
下面将介绍关于频谱域的图卷积网络的推导相关的内容。
3. 什么是拉普拉斯矩阵?
拉普拉斯矩阵(Laplacian matrix) 也叫做导纳矩阵、基尔霍夫矩阵或离散拉普拉斯算子,主要应用在图论中,作为一个图的矩阵表示。对于图 G=(V,E),其Laplacian 矩阵的定义为 L=D-A,其中 L 是Laplacian 矩阵, D=diag(d)是顶点的度矩阵(对角矩阵),d=rowSum(A),对角线上元素依次为各个顶点的度, A 是图的邻接矩阵。
Graph Fourier Transformation及Graph Convolution的定义都用到图的拉普拉斯矩阵。
频域卷积的前提条件是图必须是无向图,只考虑无向图,那么L就是对称矩阵。

3.1 常用的几种拉普拉斯矩阵
普通形式的拉普拉斯矩阵
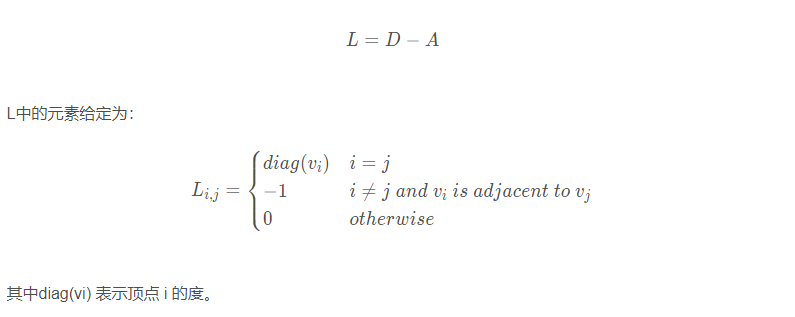
对称归一化的拉普拉斯矩阵(Symmetric normalized Laplacian)

随机游走归一化拉普拉斯矩阵(Random walk normalized Laplacian)
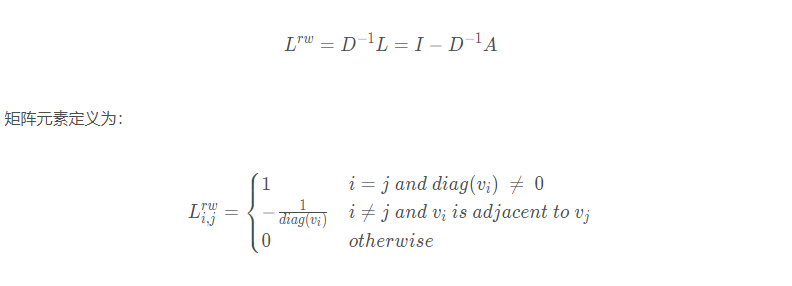
泛化的拉普拉斯 (Generalized Laplacian)
泛化的拉普拉斯(用得少)定义为:


可以看出,标准归一化的拉普拉斯矩阵还是对称的,并且符合前面的公式定义。
Graph Convolution与Diffusion相似之处,当然从Random walk normalized Laplacian就能看出了两者确有相似之处(其实两者只差一个相似矩阵的变换,可参考Diffusion-Convolutional Neural Networks)
其实维基本科对Laplacian matrix的定义上写得很清楚,国内的一些介绍中只有第一种定义。这让我在最初看文献的过程中感到一些的困惑,特意写下来,帮助大家避免再遇到类似的问题。
3.2 无向图的拉普拉斯矩阵有什么性质
(1)拉普拉斯矩阵是半正定矩阵。(最小特征值大于等于0)
(2)特征值中0出现的次数就是图连通区域的个数。
(3)最小特征值是0,因为拉普拉斯矩阵(普通形式:L = D − A )每一行的和均为0,并且最小特征值对应的特征向量是每个值全为1的向量;
(4)最小非零特征值是图的代数连通度。
拉普拉斯矩阵的半正定性证明,如下:

3.3 为什么GCN要用拉普拉斯矩阵?
- 拉普拉斯矩阵是对称矩阵,可以进行特征分解(谱分解)
- 由于卷积在傅里叶域的计算相对简单,为了在graph上做傅里叶变换,需要找到graph的连续的正交基对应于傅里叶变换的基,因此要使用拉普拉斯矩阵的特征向量。
3.4. 拉普拉斯矩阵的谱分解(特征分解)
GCN的核心基于拉普拉斯矩阵的谱分解,文献中对于这部分内容没有讲解太多,初学者可能会遇到不少误区,所以先了解一下特征分解。
特征分解(Eigendecomposition),又称谱分解(Spectral decomposition)是将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法。只有对可对角化矩阵或有n个线性无关的特征向量的矩阵才可以施以特征分解。
不是所有的矩阵都可以特征分解,其充要条件为n阶方阵存在n个线性无关的特征向量。
但是拉普拉斯矩阵是半正定矩阵(半正定矩阵本身就是对称矩阵),有如下三个性质:
- 对称矩阵一定n个线性无关的特征向量
- 半正定矩阵的特征值一定非负
- 对阵矩阵的不同特征值对应的特征向量相互正交,这些正交的特征向量构成的矩阵为正交矩阵。
由上拉普拉斯矩阵对称知一定可以谱分解,且分解后有特殊的形式。
对于拉普拉斯矩阵其谱分解为:

注意,特征分解最右边的是特征矩阵的逆,只是拉普拉斯矩阵是对称矩阵才可以写成特征矩阵的转置。
3.5 拉普拉斯算子

拉普拉斯算子(Laplacian operator) 的物理意义是空间二阶导,准确定义是:标量梯度场中的散度,一般可用于描述物理量的流入流出。比如说在二维空间中的温度传播规律,一般可以用拉普拉斯算子来描述。
拉普拉斯矩阵也叫做离散的拉普拉斯算子。
4. 如何通俗易懂地理解卷积?
4.1 连续形式的一维卷积
在泛函分析中,卷积是通过两个函数f(x)和g(x)生成第三个函数的一种算子,它代表的意义是:两个函数中的一个(取g(x),可以任意取)函数,把g(x)经过翻转平移,然后与f(x)的相乘,得到的一个新的函数,对这个函数积分,也就是对这个新的函数求它所围成的曲边梯形的面积。
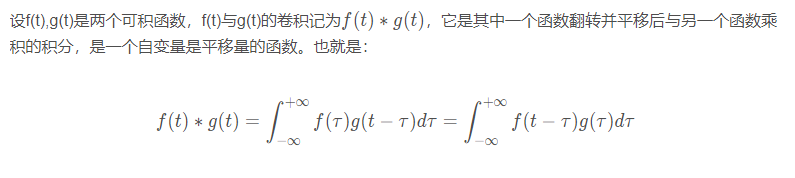
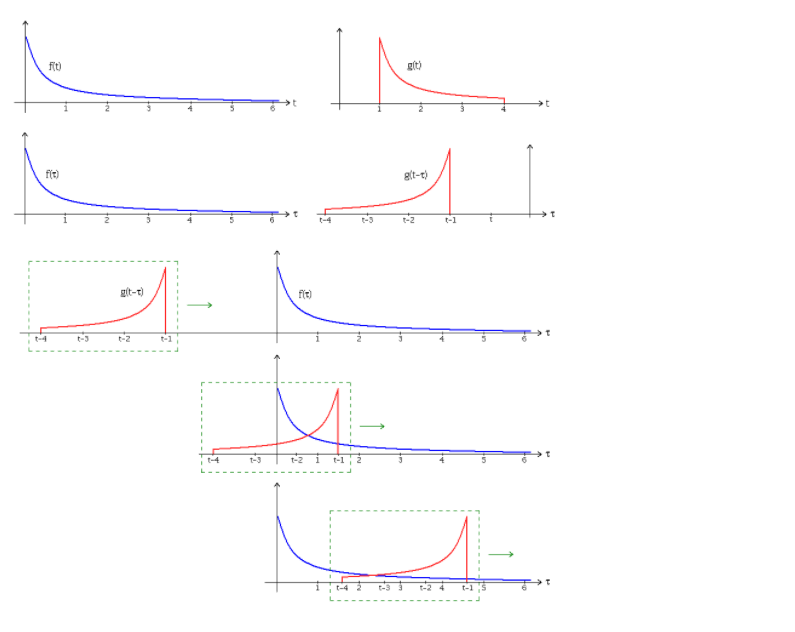
4.2 离散形式的一维卷积
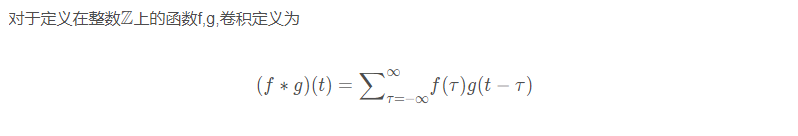
4.3 实例:掷骰子问题
光看数学定义可能会觉得非常抽象,下面举一个掷骰子的问题,该实例参考了知乎问题”如何通俗易懂地解释卷积”的回答。
想象现在有两个骰子,两个骰子分别是f跟g,f(1)表示骰子f向上一面为数字1的概率。同时抛掷这两个骰子1次,它们正面朝上数字和为4的概率是多少呢?相信读者很快就能想出它包含了三种情况,分别是:
- f向上为1,g向上为3;
- f向上为2,g向上为2;
- f向上为3,g向上为1;

这么一看,是不是就对卷积的名字理解更深刻了呢? 所谓卷积,其实就是把一个函数卷(翻)过来,然后与另一个函数求内积。
对应到不同方面,卷积可以有不同的解释:g 既可以看作我们在深度学习里常说的核(Kernel),也可以对应到信号处理中的滤波器(Filter)。而 f 可以是我们所说的机器学习中的特征(Feature),也可以是信号处理中的信号(Signal)。f和g的卷积 (f∗g)就可以看作是对f的加权求和。下面两个动图就分别对应信号处理与深度学习中卷积操作的过程。
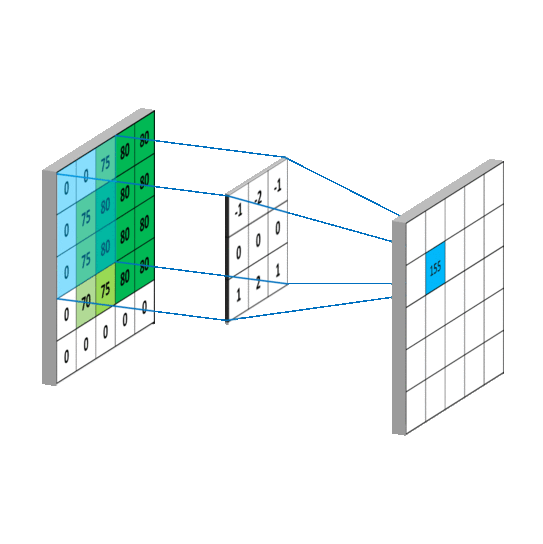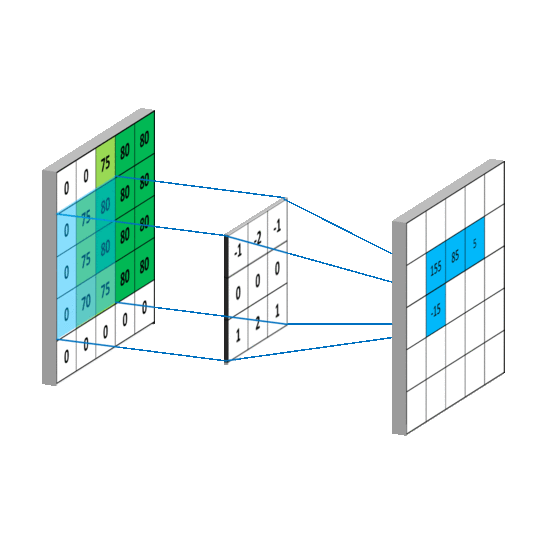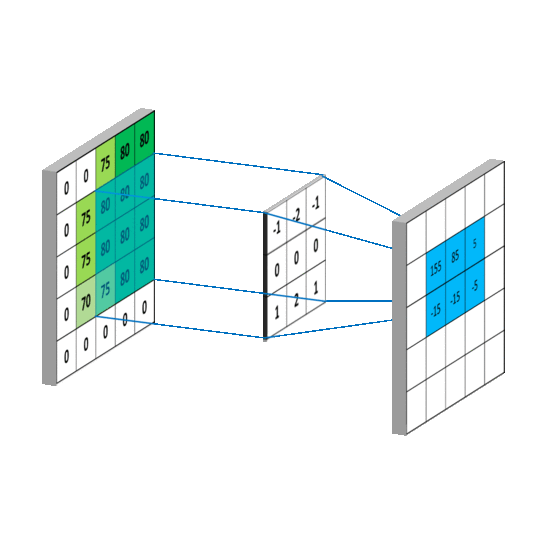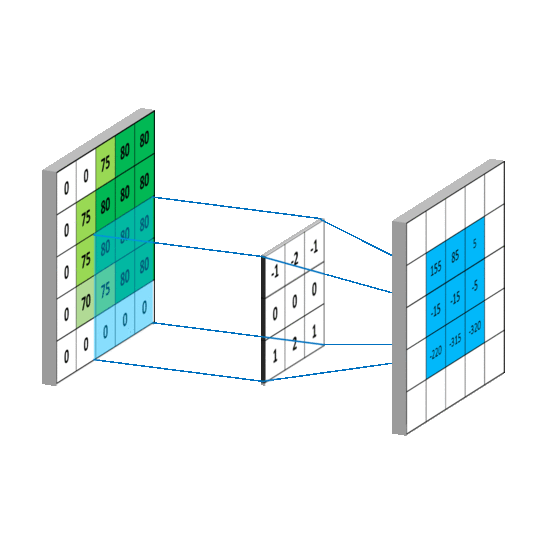

5. 傅里叶变换
5.1 连续形式的傅立叶变换
关于傅立叶变换相关的详细而有趣的内容,可以看这几篇文章:
- 如何直观地理解傅立叶变换?
- 如何理解傅立叶级数公式? (强烈推荐看一看)
- 从傅立叶级数到傅立叶变换 (强烈推荐看一看)
- 如何理解拉普拉斯变换?
下面是一个大致流程:
任意函数可以分解为奇偶函数之和:

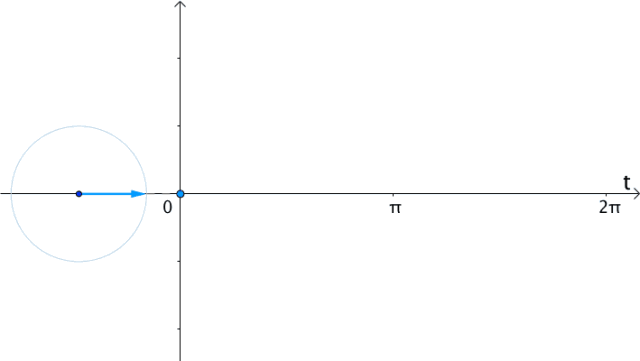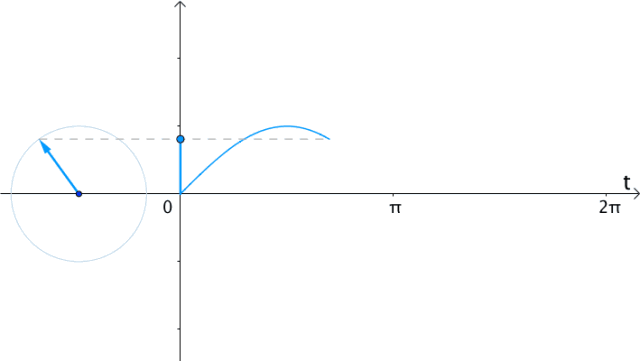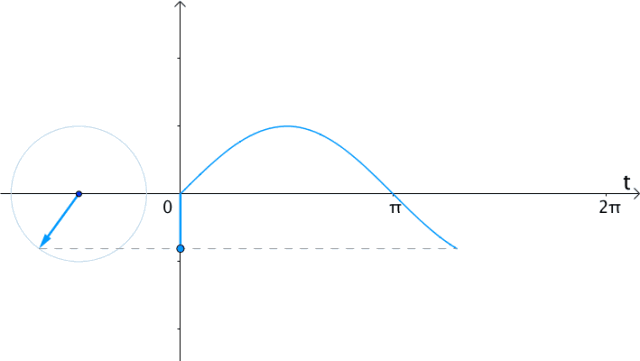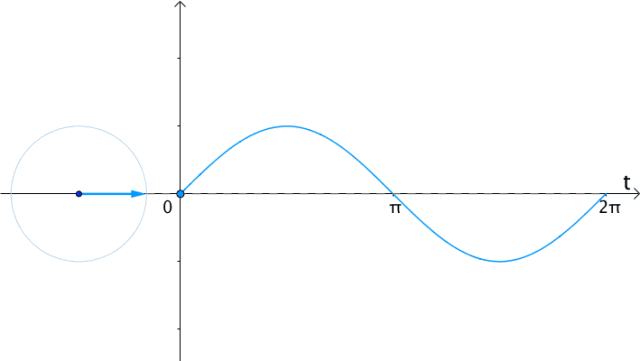
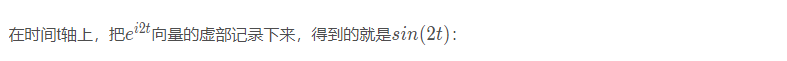
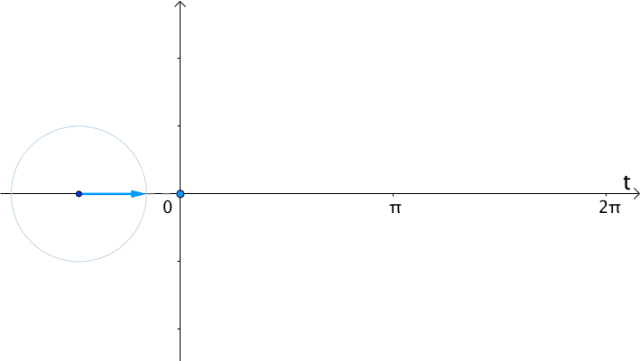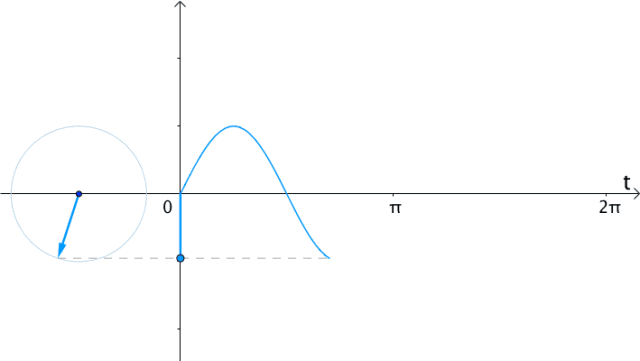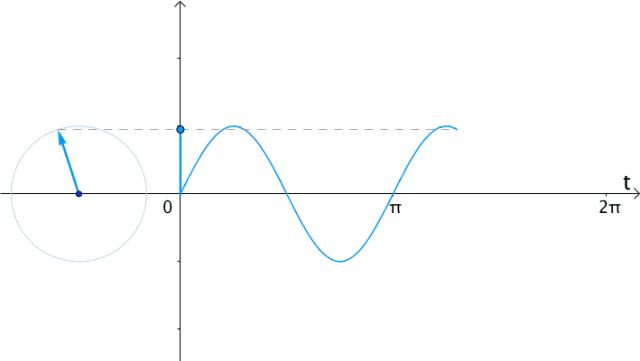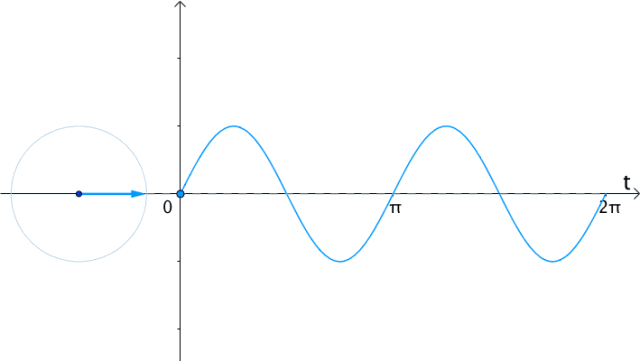

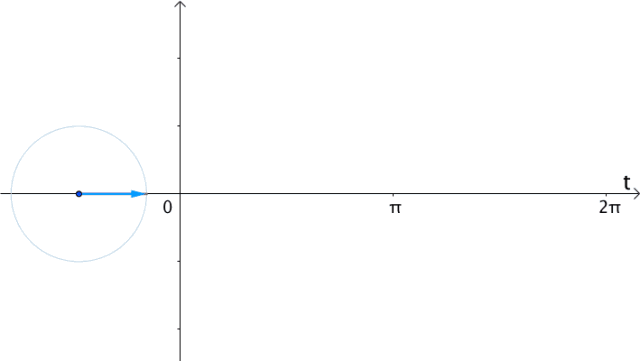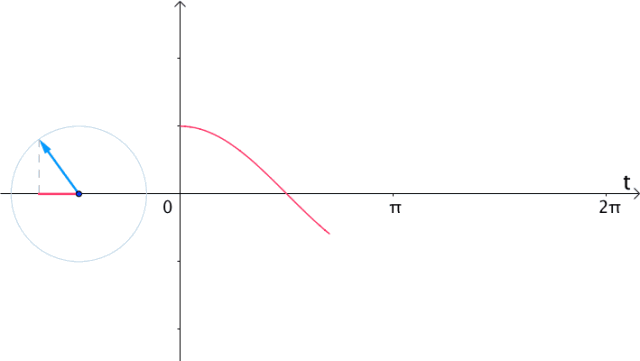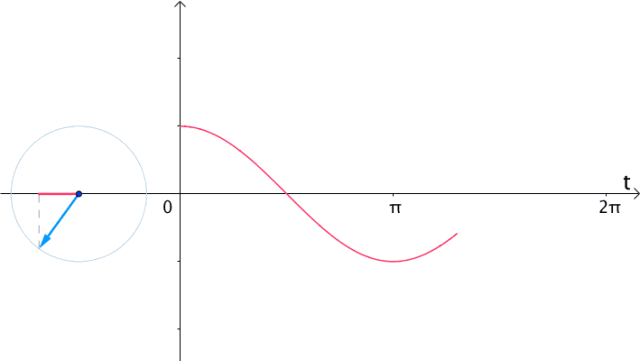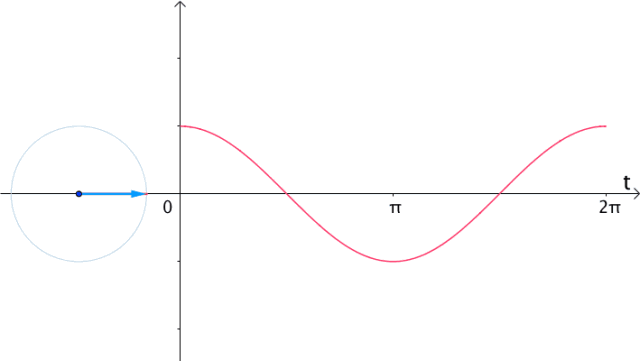
更一般的,具有两种看待sin,cos的角度:
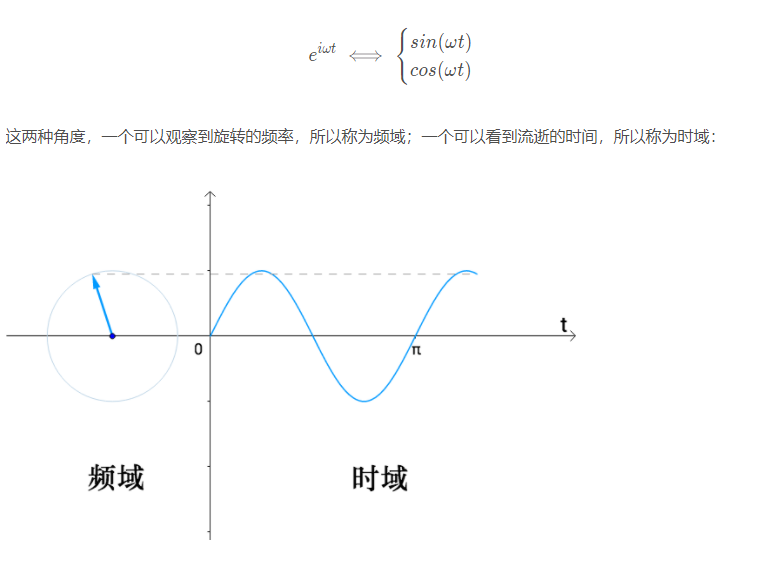


5.2 频域(frequency domain)和时域(time domain)的理解
时域:真实量到的信号的时间轴,代表真实世界。
频域:为了做信号分析用的一种数学手段。
要理解时域和频域只需要看下面两张动图就可以了:
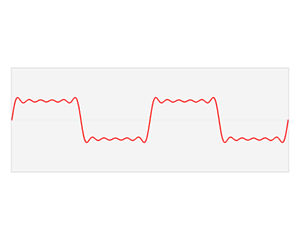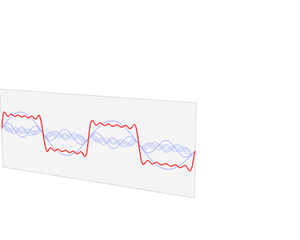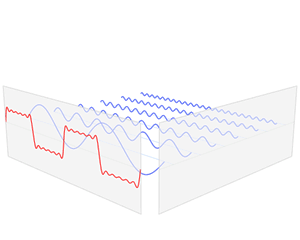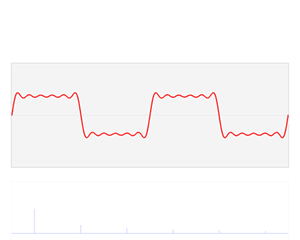
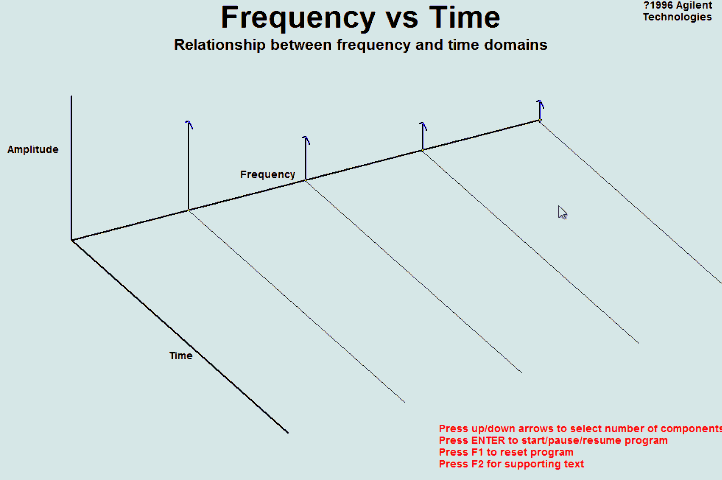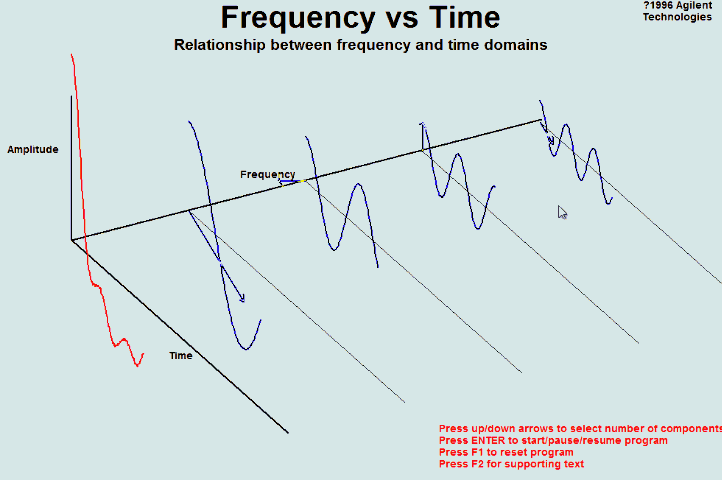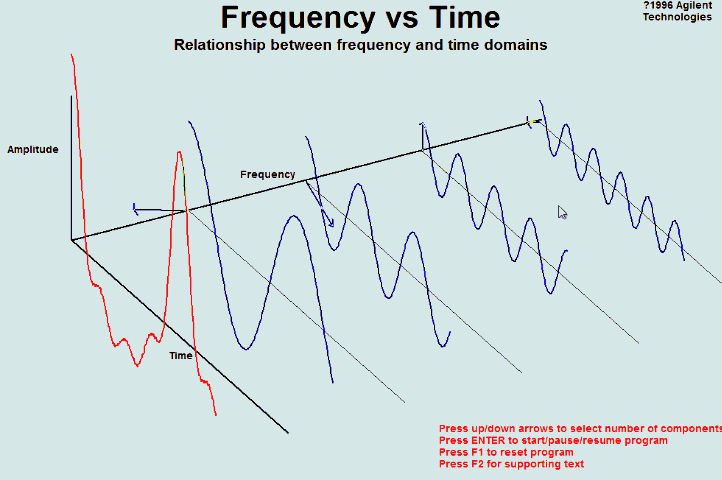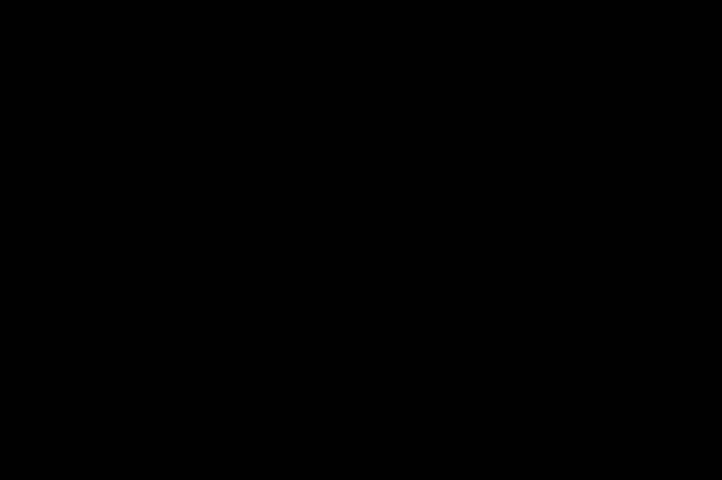
上图来自于维基百科,图中红色部分就是原函数f(x)在时域里面的曲线图,此函数经过傅里叶变换后可以分解成很多如右图中的曲线。在左图中的的蓝色线就是对应的频域中的频谱图。
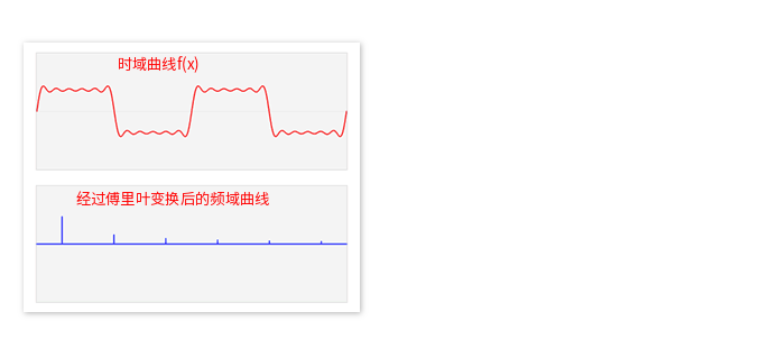
频谱图里的竖线分别代表了不同频率的正弦波函数,也就是之前的基,而高度则代表在这个频率上的振幅,也就是这个基上的坐标分量。
很多在时域看似不可能做到的数学操作,在频域相反很容易。这就是需要傅里叶变换的地方。尤其是从某条曲线中去除一些特定的频率成分,这在工程上称为滤波,是信号处理最重要的概念之一,只有在频域才能轻松的做到。
看一个傅里叶变换去噪的例子:
在傅里叶变换前,图像上有一些规律的条纹,直接在原图上去掉条纹有点困难,但我们可以将图片通过傅里叶变换变到频谱图中,频谱图中那些规律的点就是原图中的背景条纹。
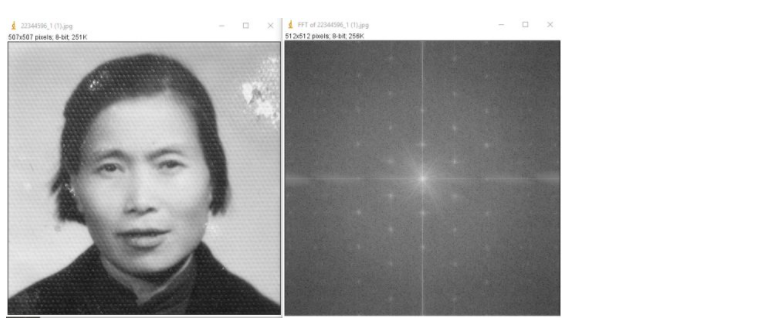
只要在频谱图中擦除这些点,就可以将背景条纹去掉,得到下图右侧的结果。
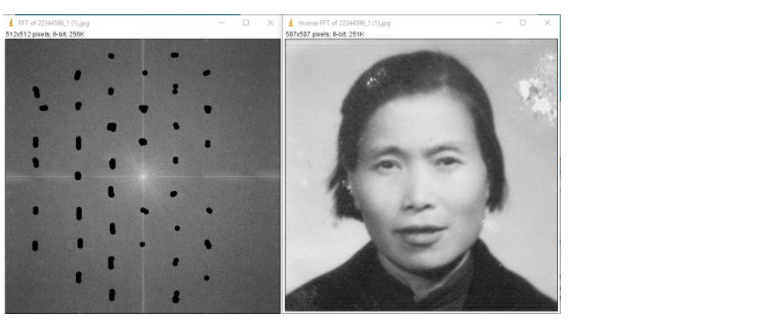
5.3 周期性离散傅里叶变换(Discrete Fourier Transform, DFT)

6. Graph上的傅里叶变换及卷积

6.1 图上的傅里叶变换

6.2 图的傅立叶变换——图的傅立叶变换的矩阵形式
利用矩阵乘法将Graph上的傅里叶变换推广到矩阵形式:
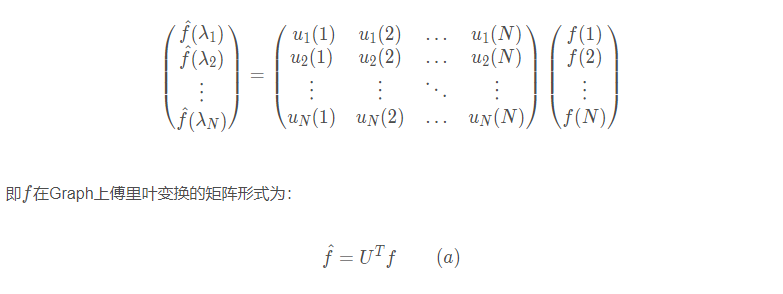
6.3 图的傅立叶逆变换——图的傅立叶逆变换的矩阵形式

6.4 图上的傅里叶变换推广到图卷积
在上面的基础上,利用卷积定理类比来将卷积运算,推广到Graph上。
卷积定理:函数卷积的傅里叶变换是函数傅立叶变换的乘积,即对于函数f与g两者的卷积是其函数傅立叶变换乘积的逆变换(中间的桥梁就是傅立叶变换与反傅立叶变换,证明见:https://zhuanlan.zhihu.com/p/54505069):


7. 为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?特征值表示频率?
在Chebyshev论文(M. Defferrard, X. Bresson, and P. Vandergheynst, “Convolutional neural networks on graphs with fast localized spectral filtering,”in Advances in Neural Information Processing Systems, 2016)中就有说明,图上进行傅里叶变换时,拉普拉斯矩阵是对称矩阵,所有有n个线性无关的特征向量,因此可以构成傅里叶变换的一组基,而其对应的特征值就是傅里叶变换的频率。
7.1 为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?
傅里叶变换一个本质理解就是:把任意一个函数表示成了若干个正交函数(由sin,cos 构成)的线性组合。

7.2 怎么理解拉普拉斯矩阵的特征值表示频率?
在graph空间上无法可视化展示“频率”这个概念,那么从特征方程上来抽象理解。

其实图像压缩就是这个原理,把像素矩阵特征分解后,把小的特征值(低频部分)全部变成0,PCA降维也是同样的,把协方差矩阵特征分解后,按从大到小取出前K个特征值对应的特征向量作为新的“坐标轴”。
Graph Convolution的理论告一段落了,下面开始Graph Convolution Network
8. 深度学习中GCN的演变
Deep learning 中的Graph Convolution直接看上去会和第6节推导出的图卷积公式有很大的不同,但是万变不离其宗,都是根据下式来推导的:

8.1 Spectral CNN

第一代的参数方法存在着一些弊端,主要在于:

8.2 Chebyshev谱CNN(ChebNet)
Chebyshev谱CNN源于论文(M. Defferrard, X. Bresson, and P. Vandergheynst, “Convolutional neural networks on graphs with fast localized spectral filtering,”in Advances in Neural Information Processing Systems, 2016)。Defferrard等人提出ChebNet,定义特征向量对角矩阵的切比雪夫多项式为滤波器,也就是


其中

公式4到公式5的补充证明如下:


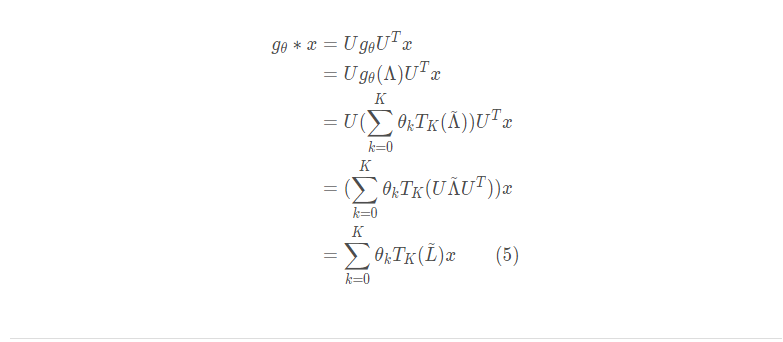
8.3 CayleyNet
CayleyNet进一步应用了参数有理复合函数的Cayley多项式来捕获窄的频带。CayleyNet的谱图卷积定义为

8.4 一阶ChebNet(1stChebNet)-GCN
一阶ChebNet源于论文(T. N. Kipf and M.Welling, “Semi-supervised classification with graph convolutional networks,” in Proceedings of the International Conference on Learning Representations, 2017)。这篇论文基于前面的工作,正式成为GCN的开山之作,后面很多变种都是基于这篇文章的。
该篇论文贡献有两点:
作者对于直接操作于图结构数据的网络模型根据频谱图卷积(Hammond等人于2011年提出的Wavelets on graphs via spectral graph theory)使用一阶近似简化计算的方法,提出了一种简单有效的层式传播方法。
作者验证了图结构神经网络模型可用于快速可扩展式的处理图数据中节点半监督分类问题,作者通过在一些公有数据集上验证了自己的方法的效率和准确率能够媲美现有的顶级半监督方法。
下面介绍ChebNet的一阶近似方法:

再加上一个激活函数,最后就可以得到了论文中的快速卷积公式:

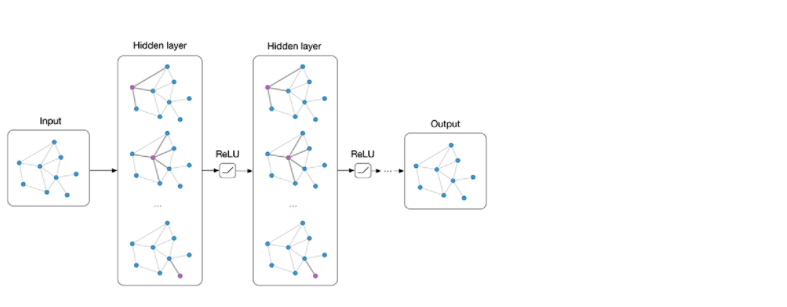
在看了上面的公式以及论文中的训练方法之后,并没有觉得GCN有多么特别,无非就是一个设计巧妙的公式,也许不用这么复杂的公式,多加一点训练数据或者把模型做深,也可能达到媲美的效果呢。
最后论文的附录里提到“even an untrained GCN model with random weights can serve as a powerful feature extractor for nodes in a graph”,可见即使不训练,完全使用随机初始化的参数W,GCN提取出来的特征就已经十分优秀了!这跟CNN不训练是完全不一样的,CNN不训练是根本得不到什么有效特征的。
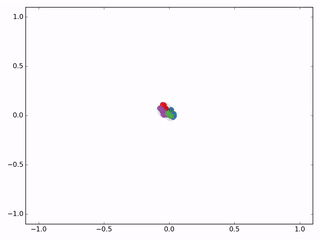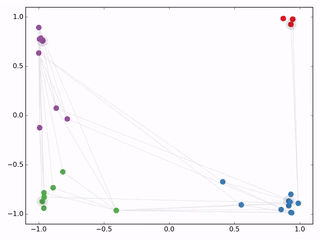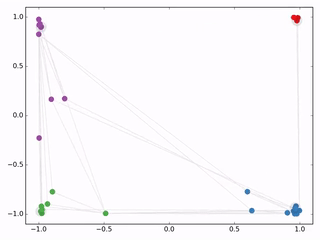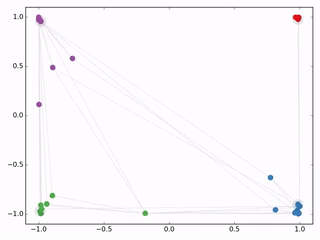
然后作者做了一个实验,使用一个俱乐部会员的关系网络,使用随机初始化的GCN进行特征提取,得到各个node的embedding,然后可视化:
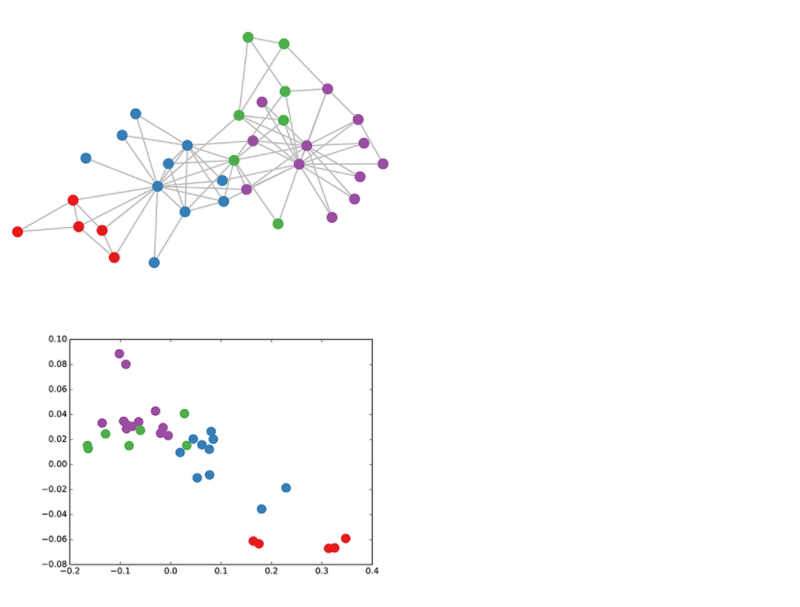
可以发现,在原数据中同类别的node,经过GCN的提取出的embedding,已经在空间上自动聚类了。
而这种聚类结果,可以和DeepWalk、node2vec这种经过复杂训练得到的node embedding的效果媲美了。
作者接着给每一类的node,提供仅仅一个标注样本,然后去训练,得到的可视化效果如下:
关于1stChebNet CGN的更多细节,可以参考博客:
Semi-Supervised Classification with Graph Convolutional Networks用图卷积进行半监督分类
GCN的优点
1)、权值共享,参数共享,从AXW可以看出每一个节点的参数矩阵都是W,权值共享;
2)、具有局部性Local Connectivity,也就是局部连接的,因为每次聚合的只是一阶邻居;
上述两个特征也是CNN中进行参数减少的核心思想
3)、感受野正比于卷积层层数,第一层的节点只包含与直接相邻节点有关的信息,第二层以后,每个节点还包含相邻节点的相邻节点的信息,这样的话,参与运算的信息就会变多。层数越多,感受野越大,参与运算的信息量越充分。也就是说随着卷积层的增加,从远处邻居的信息也会逐渐聚集过来。
4)、复杂度大大降低,不用再计算拉普拉斯矩阵,特征分解
GCN的不足
1)、扩展性差:由于训练时需要需要知道关于训练节点、测试节点在内的所有节点的邻接矩阵A AA,因此是transductive的,不能处理大图,然而工程实践中几乎面临的都是大图问题,因此在扩展性问题上局限很大,为了解决transductive的的问题,GraphSAGE:Inductive Representation Learning on Large Graphs 被提出;
2)、局限于浅层:GCN论文中表明,目前GCN只局限于浅层,实验中使用2层GCN效果最好,为了加深,需要使用残差连接等trick,但是即使使用了这些trick,也只能勉强保存性能不下降,并没有提高,Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning一文也针对When GCNs Fail ?这个问题进行了分析。虽然有一篇论文:DeepGCNs-Can GCNs Go as Deep as CNNs?就是解决GCN局限于浅层的这个问题的,但个人觉得并没有解决实质性的问题,这方面还有值得研究的空间。
3)、不能处理有图:理由很简单,推导过程中用到拉普拉斯矩阵的特征分解需要满足拉普拉斯矩阵是对称矩阵的条件;
9. GCN的一些改进
9.1 邻接矩阵的探索
Adaptive Graph Convolution Network (AGCN)

Dual Graph Convolutional Network(DGCN)

9.2 空间域的GCNs(ConvGNNs)
Neural Network for Graphs (NN4G)
NN4G是第一个提出的基于空间的ConvGNNs。NN4G通过直接累加节点的邻域信息来实现图的卷积。它还应用剩余连接和跳跃连接来记忆每一层的信息。因此,NN4G的下一层节点状态为
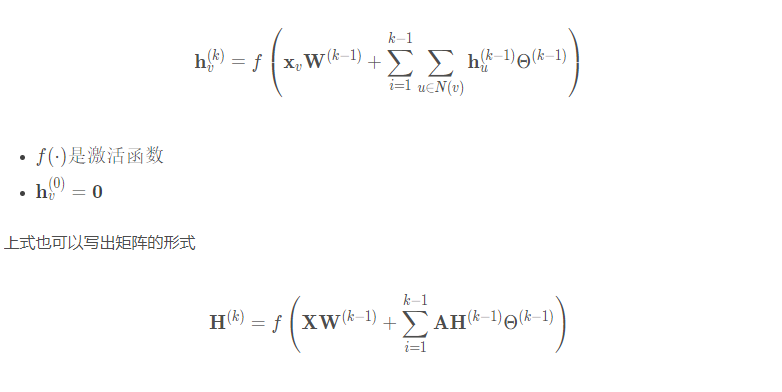
可以看出,形式和GCN类似。主要区别在于NN4G使用了非标准化邻接矩阵,这可能会导致数值不稳定问题。
Contextual Graph Markov Model (CGMM)
CGMM提出了一种基于NN4G的概率模型。在保持空间局部性的同时,CGMM还具有概率可解释性。
Diffusion Convolutional Neural Network (DCNN)扩散卷积神经网络
DCNN将图卷积看作一个扩散过程。它假设信息以一定的转移概率从一个节点转移到相邻的一个节点,使信息分布在几轮后达到均衡。DCNN将扩散图卷积定义为

利用转移概率矩阵的幂意味着,遥远的邻居对中心节点提供的信息非常少。
PGC-DGCNN

Partition Graph Convolution (PGC)

Message Passing Neural Networks (MPNN) 信息传递神经网络
信息传递神经网络(MPNNs)(Neural message passing for quantum chemistry,ICML 2017)概述了基于空间的卷积神经网络的一般框架。它把图卷积看作一个信息传递过程,信息可以沿着边直接从一个节点传递到另一个节点。MPNN运行K-step消息传递迭代,让信息进一步传播。定义消息传递函数(即空间图卷积)为

Graph Isomorphism Network (GIN) 图同构网络

GraphSage
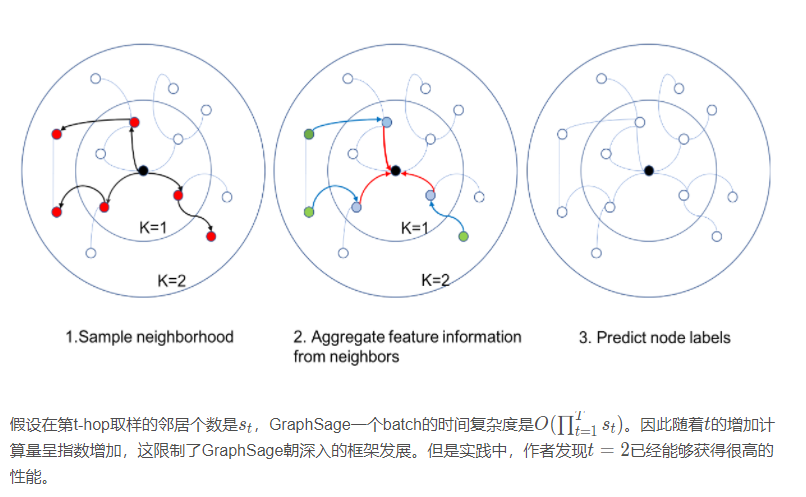
由于一个节点的邻居数量可能从1个到1000个甚至更多,因此获取一个节点邻居的完整大小是低效的。GraphSage(Inductive representation learning on large graphs,NIPS 2017)引入聚合函数的概念定义图形卷积。聚合函数本质上是聚合节点的邻域信息,需要满足对节点顺序的排列保持不变,例如均值函数,求和函数,最大值函数都对节点的顺序没有要求。图的卷积运算定义为:

GraphSage没有更新所有节点上的状态,而是提出了一种batch训练算法,提高了大型图的可扩展性。GraphSage的学习过程分为三个步骤。首先,对一个节点的K-跳邻居节点取样,然后,通过聚合其邻居节的信息表示中心节点的最终状态,最后,利用中心节点的最终状态做预测和误差反向传播。如图所示k-hop,从中心节点跳几步到达的顶点。
Graph Attention Network (GAT)图注意力网络
图注意网络(GAT)(ICLR 2017,Graph attention networks)假设相邻节点对中心节点的贡献既不像GraphSage一样相同,也不像GCN那样预先确定(这种差异如图4所示)。GAT在聚合节点的邻居信息的时候使用注意力机制确定每个邻居节点对中心节点的重要性,也就是权重。定义图卷积操作如下:

softmax函数确保节点v的所有邻居的注意权值之和为1。GAT进一步使用multi-head注意力方式,并使用||concat方式对不同注意力节点进行整合,提高了模型的表达能力。这表明在节点分类任务上比GraphSage有了显著的改进。
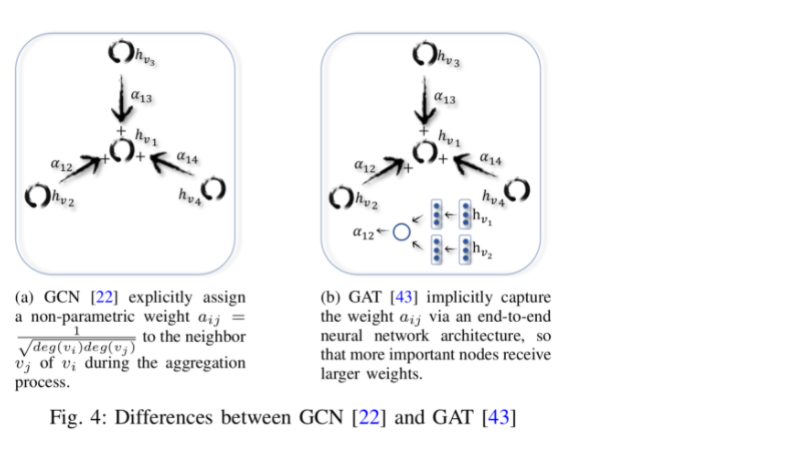
图4展示了GCN和GAN在聚合邻居节点信息时候的不同。

Gated Attention Network (GAAN)-门控注意力网络
GAAN(Gaan:Gated attention networks for learning on large and spatiotemporal graphs,2018)也利用multi-head注意力的方式更新节点的隐层状态。与GAT为各种注意力设置相同的权重进行整合的方式不同,GAAN引入self-attention机制对每一个head,也就是每一种注意力,计算不同的权重,规则如下:

GeniePath除了在空间上应用了图注意力之外,还提出了一种类似于LSTM的门控机制来控制跨图卷积层的信息流。还有其他一些有趣的图注意模型(Graph classification using structural attention,KDD 18)、(Watch your step: Learning node embeddings via graph attention,NeurIPS,2018)。但是,它们不属于ConvGNN框架。
Mixture Model Network (MoNet)
混合模型网络MoNet(Geometric deep learning on graphs and manifolds using mixture model cnns ,CVPR 2017)采用了一种不同的方法来为一个节点的邻居分配不同的权值。它引入节点伪坐标来确定一个节点与其邻居之间的相对位置。一旦知道了两个节点之间的相对位置,权重函数就会将相对位置映射到这两个节点之间的相对权重。通过这种方式,可以在不同的位置共享图数据过滤器的参数。在MoNet框架下,现有的几种流形处理方法,如Geodesic CNN (GCNN)、Anisotropic CNN (各向异性CNN,ACNN)、Spline CNN,以及针对图的处理方法GCN、DCNN等,都可以通过构造非参数权函数将其推广为MoNet的特殊实例。此外,MoNet还提出了一个具有可学习参数的高斯核函数来自适应地学习权值函数。
PATCHY-SAN
另一种不同的工作方式是根据特定的标准对节点的邻居进行排序,并将每个排序与一个可学习的权重关联起来,从而实现跨不同位置的权重共享。PATCHY-SAN(Learning convolutional neural networks for graphs,ICML 2016)根据每个节点的图标签对邻居排序,并选择最上面的q个邻居。图标记实质上是节点得分,可以通过节点度、中心度、Weisfeiler-Lehman颜色等得到。由于每个节点现在有固定数量的有序邻居,因此可以将图形结构的数据转换为网格结构的数据。PATCHY-SAN应用了一个标准的一维卷积滤波器来聚合邻域特征信息,其中该滤波器的权值的顺序对应于一个节点的邻居的顺序。PATCHY-SAN的排序准则只考虑图的结构,这就需要大量的计算来处理数据。GCNs中利用标准CNN能过保持平移不变性,仅依赖于排序函数。因此,节点选择和排序的标准至关重要。PATCHY-SAN中,排序是基于图标记的,但是图标记值考虑了图结构,忽略了节点的特征信息。
Large-scale Graph Convolution Networks (LGCN)
LGCN(Large-scale learnable graph convolutional networks,SIGKDD 2018)提出了一种基于节点特征信息对节点的邻居进行排序的方法。对于每个节点,LGCN集成其邻居节点的特征矩阵,并沿着特征矩阵的每一列进行排序,排序后的特征矩阵的前k行作为目标节点的输入网格数据。最后LGCN对合成输入进行1D-CNN得到目标节点的隐含输入。PATCHY-SAN中得到图标记需要复杂的预处理,但是LGCN不需要,所以更高效。LGCN提出一个子图训练策略以适应于大规模图场景,做法是将采样的小图作为mini-batch。
GraphSAGE
通常GCN这样的训练函数需要将整个图数据和所有节点中间状态保存到内存中。特别是当一个图包含数百万个节点时,针对ConvGNNs的full-batch训练算法受到内存溢出问题的严重影响。为了节省内存,GraphSage提出了一种batch训练算法。它将节点看作一棵树的根节点,然后通过递归地进行K步邻域扩展,扩展时保持采样大小固定不变。对于每一棵采样树,GraphSage通过从下到上的层次聚集隐含节点表示来计算根节点的隐含表示。
FastGCN
FastGCN(fast learning with graph convolutional networks via importance sampling,ICLR 2018)对每个图卷积层采样固定数量的节点,而不是像GraphSage那样对每个节点采样固定数量的邻居。它将图卷积理解为节点embedding函数在概率测度下的积分变换。采用蒙特卡罗近似和方差减少技术来简化训练过程。由于FastGCN对每个层独立地采样节点,层之间的连接可能是稀疏的。
AS-GCN
AS-GCN(Adaptive Sampling Towards Fast Graph Representation Learning,NeurIPS 2018)提出了一种自适应分层采样方法,其中下层的节点根据上层节点为条件进行采样。与FastGCN相比,该方法以采用更复杂的采样方案为代价,获得了更高的精度。
StoGCN(或VR-GCN)
StoGCN(Stochastic training of graph convolutional networks with variance reduction,VR-GCN,ICML 2018)的随机训练使用历史节点表示作为控制变量,将图卷积的感知域大小降低到任意小的范围。即使每个节点有两个邻居,StoGCN的性能也不相上下。但是,StoGCN仍然必须保存所有节点中间状态,这对于大型图数据来说是消耗内存的。
注:VR-GCN是ClusterGCN中的叫法。
Cluster-GCN
Cluster-GCN使用图聚类算法对一个子图进行采样,并对采样的子图中的节点执行图卷积。由于邻域搜索也被限制在采样的子图中,所以Cluster-GCN能够同时处理更大的图和使用更深层次的体系结构,用更少的时间和更少的内存。值得注意的是,Cluster-GCN为现有的ConvGNN训练算法提供了时间复杂度和内存复杂度的直接比较。
复杂度对比


- n 是所有节点的数量
- m 是所有边的数量
- K 是网络层数
- s 是batch size
- r 是每一个节点采样的邻居的数量
- 为简单起见,节点隐含特征的维数保持不变,用d表示
10. GCN的一些应用
11. GCN代码分析和数据集Cora、Pubmed、Citeseer格式
见另下一篇:GCN使用的数据集Cora、Citeseer、Pubmed、Tox21格式
代码分析见另一篇:图卷积网络GCN代码分析(Tensorflow版)
12. 从空间角度理解GCN
前面介绍了GCN谱方法的推导以及背后的思路等,这是一种比较严谨和理论的方法。但是,其实可以发现,在傅立叶域上定义出来的GCN操作,其实也可以在空间域上进行理解,其就是所谓的消息传递机制,或者说每次从邻居中聚集信息然后对中心节点进行更新。
如下图所示,红色节点S1的邻居正是蓝色节点B1,B2,B3,这些邻居节点根据一定的规则将信息,也就是特征,汇总到红色节点上。
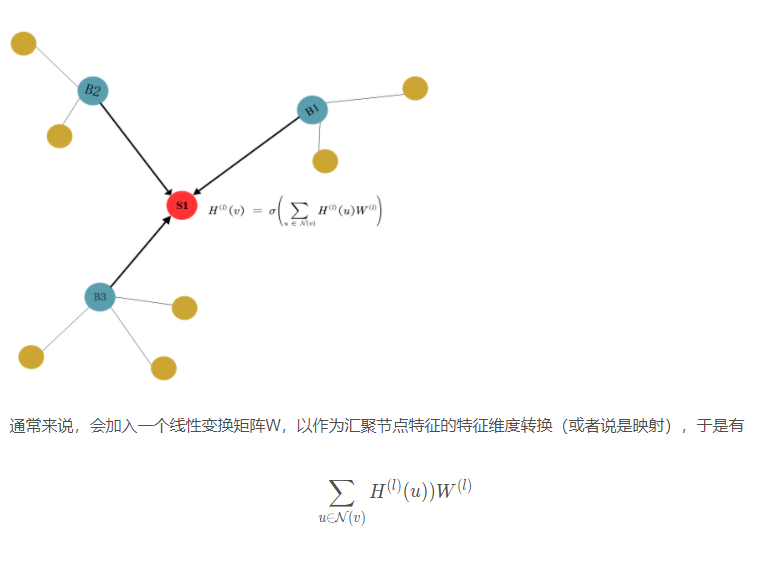
加入激活函数后有:

为了标准化(或归一化)邻接矩阵A使得每行之和为1,可以令:
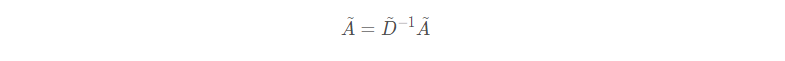
这样就行归一化以后,对邻居的聚合就不是求和了而是求平均值。
还是考虑此图

则归一化以后为

上式对邻接矩阵进行了标准化,这个标准化称之为random walk normalization。然而,在实际中,动态特性更为重要,因此经常使用的是renormalization(GCN论文中的叫法):

这就是在GCN谱方法推导中中提到的拉普拉斯矩阵要这样标准化的原因了。
经过邻接矩阵添加自环(renormalization)之后,可以得到
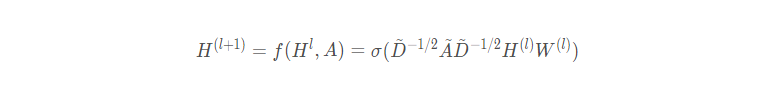
这就是GCN用谱方法推导出来的公式,这样就可以从空间结构的角度理解一阶ChebNet(GCN)了。
13. GCN处理不同类型的图
关于带权图问题
GCN论文里的针对的是无权的无向图,并且采用的是平均聚合的方法,邻居之间没有权重。但是,现实生活中更多的是带权图。比如,我们都认识马化腾,但是张志东与马化腾的亲密度要比我们和马化腾的亲密度高得多。因此,可以预测张志东的工资比我们更接近马化腾。
不过GCN还是可以直接处理带权图,原来的邻居矩阵取值只能是0和1,现在可以取更多的权值。
关于有向图问题
前面的都是针对于无向图的问题,所有拉普拉斯矩阵是对称矩阵,但是在有向图中,就不能定义拉普拉斯矩阵了。目前的两种解决思路:
(a)要想保持理论上的完美,就需要重新定义图的邻接关系,保持对称性
比如这篇文章MotifNet: a motif-based Graph Convolutional Network for directed graphs
提出利用Graph Motifs定义图的邻接矩阵。
(b)个人认为基于空间域的GCNs都可以处理有向图,比如GraphSAGE、GAT等,聚合邻居信息时根据有向边判断是否是邻居即可
节点没有特征的图
对于很多网络,可能没有节点的特征,这个时候也是可以使用GCN的,如论文中作者对那个俱乐部网络,采用的方法就是用单位矩阵 I替换特征矩阵X,有的地方也用节点度作为节点特征。
14. 问题讨论
下面将总结一些常见的问题和回答,欢迎大佬们一起讨论
Q1:GCN中邻接矩阵为什么要归一化?
看前面的例子

Q2:GCN中邻接矩阵为什么要renormalization?
还是看前面的例子

Q3:GCN中参数矩阵W的维度如何确定?怎么理解GCN是transductive的?

Q4:为什么GCN里使用NELL数据集相比于其他三个的分类准确率这么低?
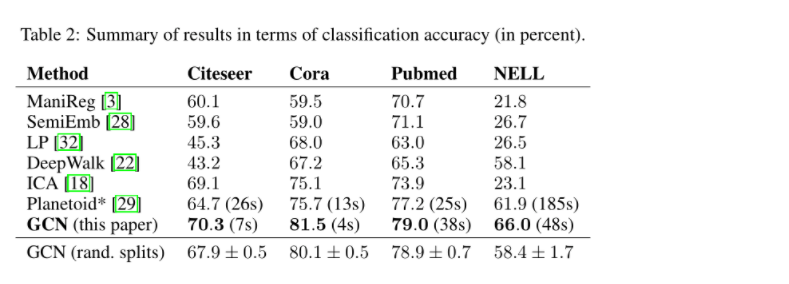
Q5:目前GCN的分类准确率仅为80%左右,如何提高GCN在Citeseer、Cora、Pubmed、Nell上的分类准确率?
Q6:增加GCN层数,为何准确率还降低了?
在“A Comprehensive Survey on Graph Neural Networks”和“Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning”中的解释是over smoothing,也就是层数多了,反而使远处的节点和近处的节点相似而更难以区分,当层数到达一定时,整个网络呈一个稳定的不动点,达到平衡。
参考
感谢以下大佬的总结,一些重要的参考如下:
知乎superbrother给出了非常详细的说明, 写得很好, 手动点赞:如何理解 Graph Convolutional Network(GCN)?
从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二)
图卷积神经网络入门基础
图卷积网络知识汇总
GNN 教程:漫谈谱图理论和GCN的起源
部分论文:
[1]. Neural Message Passing for Quantum Chemistry
[2]. Inductive Representation Learning on Large Graphs
[3]. Diffusion-Convolutional Neural Networks
[4]. Learning Convolutional Neural Networks for Graphs
[5]. Spectral Networks and Locally Connected Networks on Graphs
[6]. Convolutional neural networks on graphs with fast localized spectral filtering
[7]. Semi-Supervised Classification with Graph Convolutional Networks
[8]. A Comprehensive Survey on Graph Neural Network