Pytorch官方文档:https://pytorch.org/docs/stable/torch.html?
1. Pytorch的基础知识
1.1 什么是Pytorch?
PyTorch是一个基于Python的科学计算库,它有以下特点:
Tensor类似与NumPy的ndarray,唯一的区别是Tensor可以在GPU上加速运算。
下面实际演练一下Tensor的一些构造方式:
1 | # 导入Pytorch |
1.3 演示一些简单运算
1 | # 加法运算 |
各种类似NumPy的indexing都可以在PyTorch tensor上面使用。
1 | # 切片 |
更多阅读
各种Tensor operations, 包括transposing, indexing, slicing,mathematical operations, linear algebra, random numbers在
https://pytorch.org/docs/torch.
1.4 Numpy和Tensor之间的转化
- 在Torch Tensor和Numpy array之间的转化非常容易
- Torch Tensor和Numpy array会共享内存,所以改变其中一项也会改变另一项
- 把Torch Tensor转变成Numpy array 函数 张量.numpy()
- Numpy array 转变成Torch Tensor 用 torch.from_numpy(array)
1 | """Torch Tensor 转变成Numpy array""" |
所有的CPU上的Tensor都支持转成numpy或者从numpy转成Tensor
1.5 CUDA Tensors
如果有GPU的话,我们可以使用.to方法,Tensor被移动到别的device上去
1 | if torch.cuda.is_available(): |
一个Tensor在GPU上,是无法直接转成numpy的, 需要先转到CPU上
1 | # y.data.numpy() 这个会报错 |
把模型搬到GPU上 (如果想用GPU,需要把东西搬到GPU上去)
1 | model = model.cuda() |
2. 热身: 用numpy实现两层神经网络

numpy ndarray是一个普通的n维array。它不知道任何关于深度学习或者梯度(gradient)的知识,也不知道计算图(computation graph),只是一种用来计算数学运算的数据结构。
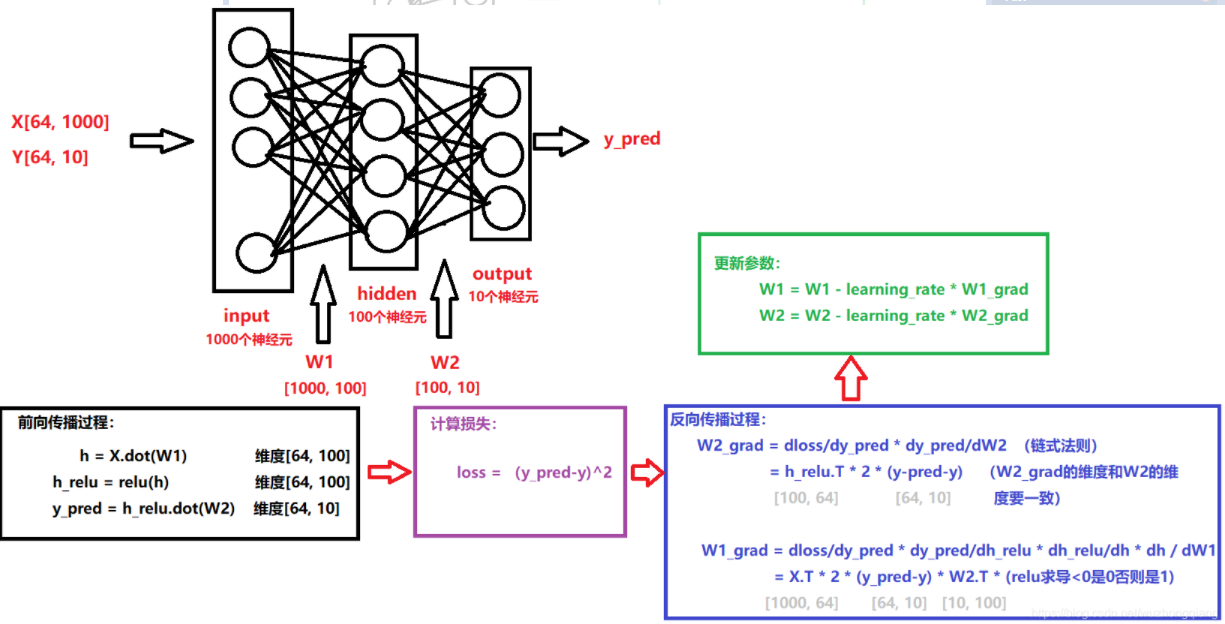
我们实现的神经网络长下面这个样子,我已经标注好了参数的维度,并且也把计算过程写了一下:
下面我们根据上面的计算过程,用numpy一步步的实现这个网络:
1 | # 定义样本数,输入层,隐藏层,输出层的参数 |
这样就完成了numpy手写两层神经网络的过程。可以运行一下,会发现loss值随着迭代次数的增加,会减小。
但是你会发现,上面这个过程很复杂的,尤其是反向传播那块,得需要自己小心翼翼的求导数。
所以,我们下面看看Pytorch版本是如何一步一步的取代numpy版本的代码的。(你会享受下面的过程 😉)
3. Pytorch一步一步的替代上面的网络
3.1 Pytorch: Tensors
这次我们使用PyTorch tensors来创建前向神经网络,计算损失,以及反向传播。(也就是先把numpy的写法,换成tensor的写法)
一个PyTorch Tensor很像一个numpy的ndarray。但是它和numpy ndarray最大的区别是,PyTorch Tensor可以在CPU或者GPU上运算。如果想要在GPU上运算,就需要把Tensor换成cuda类型。
1 | # 定义输入,中间,输出层的个数和上面一样 |
这一块,没有太大的改变,只不过是把numpy的数组操作,换成了相应的张量运算,下面我们看看Pytorch一个强大的地方:自动求导,这时候你会发现代码简洁了很多。
3.2 Pytorch: Tensor 和 autograd
PyTorch的一个重要功能就是autograd,也就是说只要定义了forward pass(前向神经网络),计算了loss之后,PyTorch可以自动求导计算模型所有参数的梯度。
一个PyTorch的Tensor表示计算图中的一个节点。如果x是一个Tensor并且x.requires_grad=True那么x.grad是另一个储存着x当前梯度(相对于一个scalar,常常是loss)的向量。
我们再改动上面代码之前,先看一个简单的自动求导的例子:
1 | x = torch.tensor(1., requires_grad=True) |
好了,我们尝试引进Pytorch的自动求导机制
1 | # 这里依然不变 |
好了,这个版本的两层神经网络计算,就简单一些了,反向传播过程只需要一句话就搞定了。
但是那两个小问题要注意:
- 更新参数的时候,我们如果不需要求参数的梯度,我们应该关上梯度计算,这样会节省内存空间
- Pytorch的求导机制默认是累加,我们需要每一代之后,参数的导数给它清零
好了,我们已经知道了Pytorch的自动求导机制,.backward()。 这时候,会把前面声明时需要求导的参数的导数保存在相应的.grad变量中,我们可以直接使用。 下面我们看还能不能精简,哈哈,能的,前向传播也可以通过模型的方式。
3.3 Pytorch: nn
这次我们使用PyTorch中nn这个库来构建网络。 用PyTorch autograd来构建计算图和计算gradients, 然后PyTorch会帮我们自动计算gradient。
1 | # 这次先导入nn的库 |
这一个版本中,我们使用了Pytorch里面的nn模型,替换了numpy手写的前向传播部分,然后用换了一下损失函数计算方式,然后借助Pytorch的自动求导机制完成了反向传播部分。我们还有差一个地方,就成了全自动模式,那就是更新参数了。下一步我们把这个也换掉。
3.4 Pytorch:optim
这一次我们不再手动更新模型的weights,而是使用optim这个包来帮助我们更新参数。 optim这个package提供了各种不同的模型优化方法,包括SGD+momentum, RMSProp, Adam等等。
1 | # 定义输入输出层的个数 和上面一样 |
好了,我们基本上大功告成,已经把numpy的两层神经网络的计算换成了Pytorch版本了,换完之后,我们会发现,原来我们需要的复杂运算,在Pytorch里面只需要几句话就搞定了。
简单总结一下上面的替换过程:
- 首先,我们把把numpy的计算形式换成了tensor的计算形式,形成第一个版本
- 然后,我们使用Pytorch的自动求导机制loss.backward()替换了反向传播过程,形成了第二个版本
- 然后,我们使用Pytorch的nn模型,建立model,替换了前向传播,并且调用了Pytorch写好的损失函数替换了计算损失的过程
- 最后,我们使用optim库里面的优化函数,替换了更新参数的过程
这样,Pytorch的两层神经网络完毕。
但是,仍然有一个问题,就是nn.Sequential就类似于Keras的Sequential,只能类似堆积木般的一层一层往上堆,线性模块。不太擅长搭建复杂的模型,所以Keras那边有一个model系列。 而对应Pytorch里面,我们也有对应的解决办法,那就是自定义nn.Modules模型。 我们接着往下看。
3.5 Pytorch: 自定义nn Modules
我们可以定义一个模型,这个模型继承自nn.Module类。如果需要定义一个比Sequential模型更加复杂的模型,就需要定义nn.Module模型。
1 | # 我们定义一个两层的神经网络类,这个继承与nn.Module模块 |
看完这个,你会发现,这啥? 这不基本上啥也没改吗? 无非就是把model的定义写成了一个类的形式, 看起来还不如nn.Sequential搭建起来简单,但是,我们发现了吗? 这个写法更加灵活了,我们可以在类里面的forward函数中,自定义任何复杂结构的神经网络。 而前面的Sequential,灵活性不够,这个就类似于Keras的Sequential和Model这两种方式的定义神经网络的方法。 Pytorch这里也是给出了两种,一般简单的网络,Sequential就可以搞定,但是复杂的,我们还得用下面这个写法,所以习惯了就好。 如果对于Keras好奇,我也正在写关于Keras的一个系列,那个读完之后会有一种修仙的快感 😉
好了, 我们已经会用Pytorch搭建神经网络了,下面亲手搭一个神经网络,教你的神经网络玩个游戏吧,看看表现咋样?
4. 教你的网络玩FizzBuzz小游戏
FizzBuzz是一个简单的小游戏。游戏规则如下:从1开始往上数数,当遇到3的倍数的时候,说fizz,当遇到5的倍数,说buzz,当遇到15的倍数,就说fizzbuzz,其他情况下则正常数数。
这个就类似于我们酒席上玩的那个数数游戏,只不过是个简化版,你看到规则之后,转念一想,这还不简单,分分钟写个程序,按照这个规则从1-1000遍历,遇到3的倍数,输出fizz,遇到5的倍数,输出buzz, 遇到15的倍数,输出fizzbuzz。其他情况正常输出。 哈哈哈,你真这么写,我也无语,但那不是你机器玩的,那是你玩的, 我们的目的是搭建一个网络,让网络玩这个游戏。 看看网络怎么玩?
分下面几个步骤:
1.我们先写一个编码函数,就是传进一个数,如果是3的倍数,返回1, 是5的倍数,返回2, 是15的倍数,返回3,其他情况返回0,这个好写吧:
1 | def fizz_buzz_endode(i): |
2.我们写一个解码函数,就是根据上面的返回数,我们得到fuzz,buzz还是别的
1 | def fizz_buzz_decode(i, prediction): |
3.我们定义模型的输入,由于我们是数数,但是训练模型的时候,我们得把数转换成特征的方式网络才能懂,所以这里采用二进制的编码形式
1 | import numpy as np |
4.然后用Pytorch定义模型,这实际上是一个4分类的问题,就是输入数字,看看模型输出的是哪一个类别。
1 | NUM_HIDDEN = 100 |
5.模型的训练
- 为了让我们的模型学会FizzBuzz这个游戏,我们需要定义一个损失函数,和一个优化算法。
- 这个优化算法会不断优化(降低)损失函数,使得模型的在该任务上取得尽可能低的损失值。
- 损失值低往往表示我们的模型表现好,损失值高表示我们的模型表现差。
- 由于FizzBuzz游戏本质上是一个分类问题,我们选用Cross Entropyy Loss函数。
- 优化函数我们选用Stochastic Gradient Descent。
1 | loss_fn = torch.nn.CrossEntropyLoss() |
6.最后用我们训练好的模型尝试在1-100上玩FIZZBUZZ游戏
1 | testX = torch.Tensor([binary_encode(i, NUM_DIGITS) for i in range(1, 101)]) |
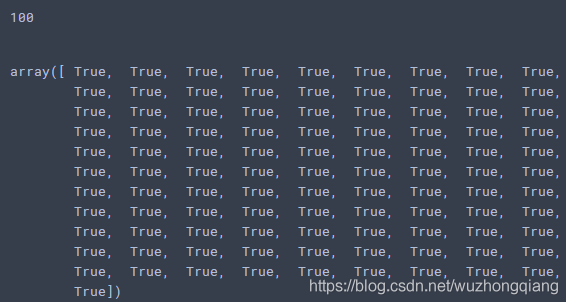
我们可以看一下网络玩的结果:

我们对比一下真实情况,看看网络错了多少:
1 | print(np.sum(testY.max(1)[1].numpy() == np.array([fizz_buzz_encode(i) for i in range(1,101)]))) |
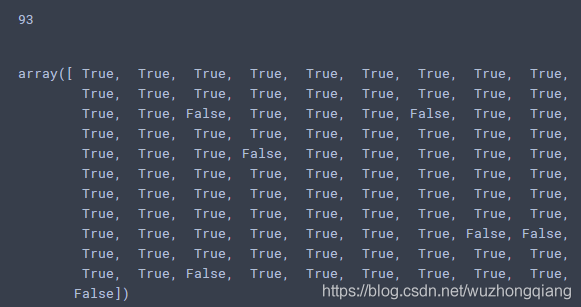
我们可以发现,100个数,模型错了7个, 对了93个数,还算可以吧,毕竟只是单层的网络,你可以换成多层或者调调参数试试会不会好一些。(我加了一层60个单元的隐藏,然后特征长度改成了15,这样稍微简单一改,模型就到了100%的效果,并且只需要1000次迭代),你也可以试试其他的,既然有这么好的机会,好好利用,改改参数学习率啥的,换换优化方法啥的都可以