Pytorch官方文档:https://pytorch.org/docs/stable/torch.html
1. 关于词向量的基础知识
这一块不会讲的很深, 但是应该够理解这节课的知识了,如果想更加深入的学习,可以搜一些相关的资料进行研究。 毕竟这个系列的课都是实战,理论不会涉及太多,我这里把我了解的这块描述一下,尽量通俗易懂。
首先,我们先来聊一聊在计算机中是如何表示一个词的。 比如下面一句话
““John likes to watch movies. Mary likes too.””
这句话如果想让计算机看明白,我们应该怎么表示呢? 首先,我们会有一个词典,这个词典,就类似下面这样子:
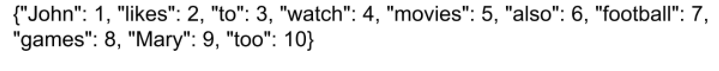
词典包含10个单词,每个单词有唯一的索引。 开始的时候,我们使用one-hot的方式表示每个词的,就是建立一个和词典一样大的向量,然后词典位置用1,然后其他位置用0. 比如单词John,因为在词典中的位置是1, 所以表示成[1, 0, 0, …0], 其他的词也一样。其他的词类似表示出来。

这么这句话就是这些向量放在一块了。 这就是一开始我们表示每一个词的方式,这是一种离散表示,这样计算机至少能读懂了。
但是这样的方式有没有问题呢?有的, 比如我下面这些词, Man, Woman, King, Queen, Apple,Orange。 如果用上面的方式表示每个向量只有一个1, 其余位置是0. 并且互相的内积都是0。 这样在计算机看来,这些词之间没有关联互相独立。 但实际情况肯定不是这样子的,我们知道苹果和橘子比国王和橘子的关系近的多。所以这种表示方法的一大缺点就是它把每个词孤立起来了,这样使得算法对相关词的泛化能力不强。
比如计算机学到一个语言模型:
I want a glass of orange________.计算机读了之后,会填上一个juice,因为计算机学到了orange juice的关系。 但是如果我把orange换成apple, 计算机就不知道怎么填了,因为它不知道orangeh和apple的关系。
所以这种表示词的方式不好,那我们能不能换一种方式呢?
如果我不是用每个词在词典中的位置,而是找一些特征去描述某个词会不会更好一些呢? 比如还是上面的Man, Woman, King, Queen, Apple, Orange这几个单词,我们找一些特征,比如是不是和性别有关,是不是和高贵有关,是不是和年龄有关,是不是和食物有关…。这样,最后每个词就可能得到一种下面的表示方式(拿吴恩达老师的图看一下)

如果用这种方法,来表示苹果和橘子的时候,苹果和橘子很定会非常相似,至少大部分特征是一样的,这样对于已经知道橙子果汁的算法,很大几率上会明白苹果果汁是什么东西。这样对于不同的单词,算法会泛化的更好。 并且,我们找的特征的个数一般会比词典小的多,比如找300个特征,那么描述每个词的话向量是300维,也比之前的one-hot的方式维度小的多。
所以这种方法就可以捕捉到单词之间的关联了,这就是词嵌入的一种表示方法,word-embedding。
那么我们是如何得到的这种表示呢? 其实是先有一个嵌入矩阵Embedding Matrix的。 就是一开始,我们是用one-hot,也就是字典的位置表示每个词,然后通过嵌入矩阵,就得到了每个词的词嵌入向量。 还是看图说话:
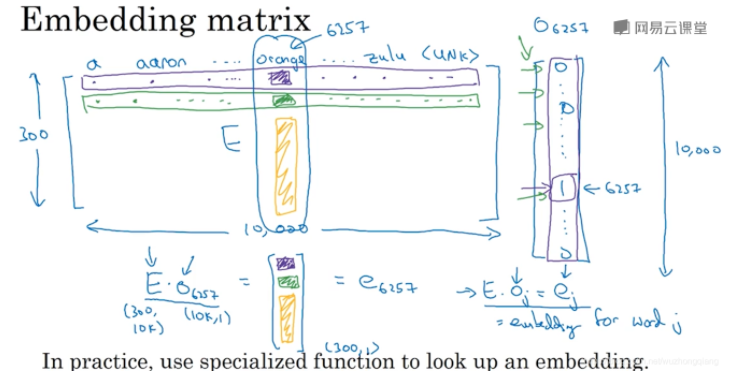

那么重点来了,这个词嵌入矩阵是怎么学习到的呢? 因为我们其实有了词嵌入矩阵之后,单词的表示就一目了然了。早起的时候,使用的自然语言模型计算嵌入矩阵的, 举个例子:
““I want a glass of orange __””
我们想让计算机填juice,嵌入矩阵未知,我们可以构建下面的神经网络去训练:
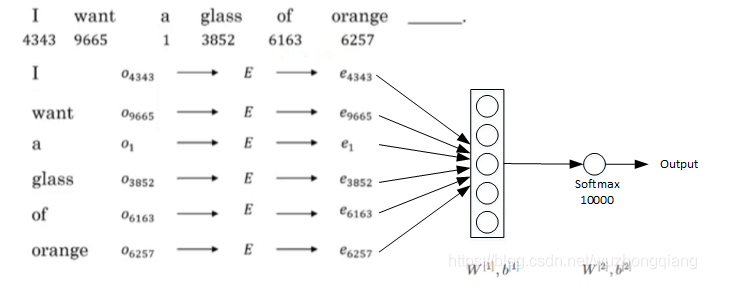
把嵌入矩阵也当做一层参数W, 通过梯度下降的方式得到。 实际上,这种算法能够很好的学习词嵌入。
因为我们在训练网络的时候, 不仅有orange juice, 还会有apple juice。 在这个算法的激励下,苹果和橘子会学到很相似的嵌入。 这样做能够让算法更好的符合训练集。 因为它有时
看到orange juice,有时看到apple juice, 如果只有一个300维的特征向量来表示这些词,算法会发现,要想更好的拟合训练集,就要使苹果、橘子、梨、葡萄等这些水果都拥有相似的
特征向量,这就是早期最成功的的学习矩阵E的算法之一。
但是如果只是为了得到嵌入矩阵E而去训练一个语言模型的话是不是大材小用了一些呢? 毕竟语言模型训练起来可是挺复杂的。
人们就想出了一种简单的方式学习词嵌入,选上下文的方式,比如我如果单纯只是为了得到嵌入矩阵,我根本没必要用一句话进行训练,我用几个单词对或者短语就可以,比如我要预测juice, 就可以把这个当做target, 然后只考虑它周围的词就可以了,orange, a glass of orange这种。
我们一般通过某个单词周围的一些词就基本上可以知道这个词是什么意思了, 比如单词bank, 一般它周围的词都是什么money, 政府啊,金融啊这样的一些词,通过这些,就基本上可以推测bank和什么有关系了。所以这种上下文的方式也能很好的学习单词之间的关联,并且比起建立一个语言模型来说,要容易的多。
那么我们对于一个句子,如何选择上下文和目标词呢? 铺垫了这么多,终于讲到重点了,Skip-gram模型就是一个流行的方式。 拿一句话:
“I want a glass of orange juice to go along with my cereal.”
Skip-Gram模型的做法是:抽取上下文和目标词配对,来构造一个监督学习问题。这里的上下文不一定总是目标单词之前离得最近的4个单词或最近的n个单词。我们要做的是:
首先随机选择一个单词作为context,例如“orange”;然后我们要做的,随机在一定距离内选另外一个词作为target(使用一个宽度为5或10(自定义)的滑动窗,在context附近选择一个单词作为target),可以是“juice”、“glass”、“my”等等。最终得到了多个context—target对作为监督式学习样本。
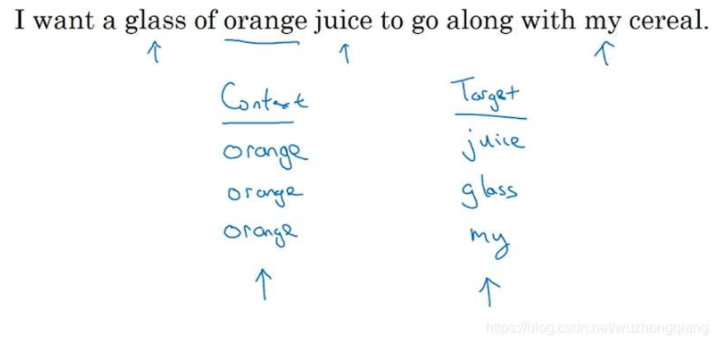
那么skip-gram模型究竟是怎么训练的呢?
假设单词数还是10000, 我们随机选择上下文context c(“orange”) ,然后再根据滑动距离随机选择一个target t(“juice”)。 我们让神经网络学习这个映射关系。
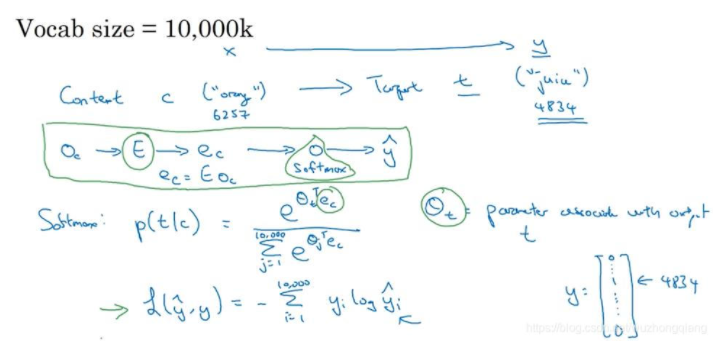
训练的过程是构建自然语言模型(如上图框的那个),经过softmax单元的输出为:
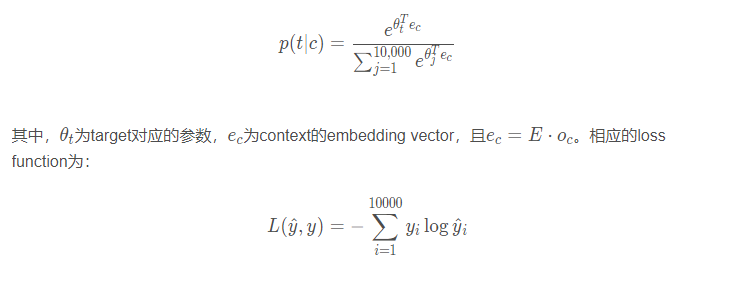
然后,运用梯度下降算法,迭代优化,最终得到embedding matrix EE。这个就叫做skip-gram模型,它把一个像orange这样的词作为输入,并预测这个输入词从左数或者从右数的
某个词,预测上下文词前面或后面的一些是什么词。
上面这个简单的理解起来,我有一些正确的单词对,我想让模型做这样的一个训练,就是我把上下文输入进去,你给我预测出最后的目标出来,比如我有orange-juice, orange-glass, orange-my, 我输入orange,你分别给我输出后面的三个单词来。 这样训练好的时候,我就可以通过中心词去预测周围的单词了。
那么这种方式有什么缺点呢? 可以看到softmax这个公式,分目是有个求和的,也就是如果有10000个单词的时候,模型最后输出的时候都得考虑进来,10000个单词究竟哪个单词概率最大。如果1000000个单词的话,模型得1000000次加和,这样的计算量太大了,能不能改进这个模型呢? 论文里面提到了两种,一个是Hierarchical softmax classifier, 另一个是负采样的方式。 我们重点看看第二种。
这里多说一句:Skip-Gram模型是Word2Vec的一种,Word2Vec的另外一种模型CBOW(Continuous Bag of Words), 它获得中间词两边的上下文,去预测中间的词。
负采样的方式就是我们最终要训练skipgram模型得到词嵌入矩阵的方式,所以我们重点看看这个是怎么改进的:
Negative sampling是另外一种有效的求解embedding matrix EE的方法。它的做法是判断选取的context word和target word是否构成一组正确的context-target对,一般包含一个正样本和k个负样本。例如,“orange”为context word,“juice”为target word,很明显“orange juice”是一组context-target对,为正样本,相应的target label为1。若“orange”为context word不变,target word随机选择“king”、“book”、“the”或者“of”等。这些都不是正确的context-target对,为负样本,相应的target label为0。这就是如何生成训练集的方法。选一个正样本和K个负样本(样本是成对出现的)
一般地,固定某个context word对应的负样本个数k一般遵循:
- 若训练样本较小,k一般选择5~20;
- 若训练样本较大,k一般选择2~5即可。
下面我们学习,从x映射到y的监督学习模型:
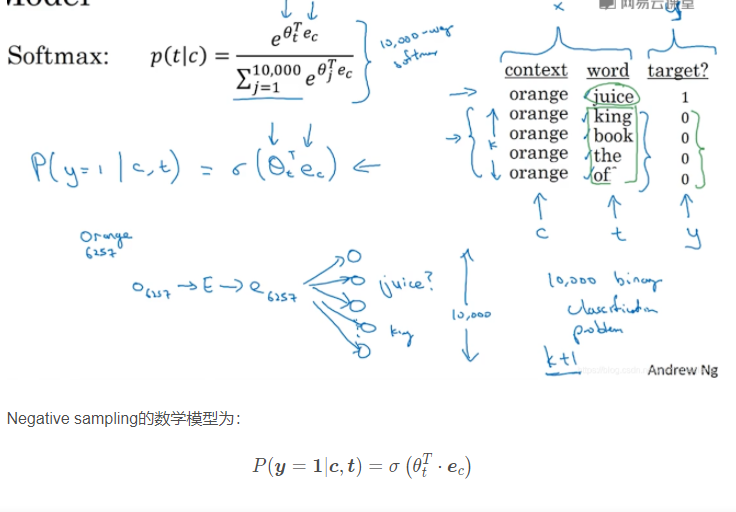
其中,σ表示sigmoid激活函数。很明显,negative sampling某个固定的正样本对应k个负样本,即模型总共包含了k+1个binary classification。对比之前介绍的10000个输出单元的softmax分类,negative sampling转化为k+1个二分类问题,计算量要小很多,大大提高了模型运算速度。
(就是每一次训练,都是K+1个二分类问题, 就看target的那几个是不是我们想要的0或者1,然后用这几个去计算损失更新参数即可).
最后提一点,关于如何选择负样本对应的target单词,可以使用随机选择的方法。但论文中提出一个更实用、效果更好的方法,就是根据该词出现的频率进行选择,相应的概率公式为:

说到这里,基本上把这节课涉及到的基础知识说完,不知道我说清楚了没有,水平有限,所以如果没大明白的建议先去看看吴恩达的深度学习课程,然后结合着上面我说的再理解理解。然后再进行下面的代码实战部分,否则可能会懵逼。当然,也可以先试试,或许代码会给你一些灵感帮助理解呢?
好了,下面就是代码实战: 我们就是通过负采样的方式建立一个模型,并通过训练得到词嵌入矩阵。
2. 实现skip-gram模型,得到词嵌入矩阵
我们在实战之前,先根据上面的基础知识理理思路:
- 首先,我们得有一个词汇表,也就是字典(这个根据训练集进行构建)
- 其次,有了这个表之后,我们就可以建立模型训练
- 训练过程中我们要保存模型的参数,测试的时候导入就可以直接进行预测
好了,现在开始。 先导入包:
1 | import torch |
2.1 构建一张词汇表
从文本文件中读取所有的文字,通过这些文字创建一个vocabulary
1 | with open("./dataset/text8/text8.train.txt", 'r') as fin: |
由于单词数量可能太大,我们只选取最常见的30000个单词
1 | """选择常用的30000个单词, 后面所有不常用的词统一用unk表示""" |
我们添加一个UNK单词表示所有不常见的单词
1 | vocab["<unk>"] = len(text) - np.sum(list(vocab.values())) |
我们需要记录单词到index的mapping,以及index到单词的mapping,单词的count,单词(normalized)frequency, 以及单词总数
1 | # 建立映射 |
2.2 实现DataLoader
DataLoader,它是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py中,只要是用PyTorch来训练模型基本都会用到该接口(除非用户重写…),该接口的目的:将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练。有了dataloader之后,我们可以轻松随机打乱整个数据集,拿到一个batch的数据等等。, 后面训练的时候你会看到DataLoader的强大。
- dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
- 使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
- 也可以使用
for inputs, labels in dataloaders进行可迭代对象的访问; - 一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据;
这里有一个好的tutorial介绍如何使用PyTorch dataloader.
torch.utils.data.Dataset是表示数据集的抽象类。您的自定义数据集应继承Dataset并覆盖以下方法:
__len__function需要返回整个数据集中有多少个item,这样就len(dataset)返回数据集的大小。__getitem__根据给定的index返回一个item,dataset[i]可以用来获取i样本
下面,我们看看在这个任务中如何实现一个DataLoader:
在这个任务中,dataloader需要以下内容:
- 把所有text编码成数字,然后用subsampling预处理这些文字。
- 保存vocabulary,单词count,normalized word frequency
- 每个iteration sample一个中心词
- 根据当前的中心词返回context单词
- 根据中心词sample一些negative单词
- 返回单词的counts
1 | # 首先,DataLoader得继承torch.utils.data.Dataset |
看看上面的这个DataSet是怎么定义的, 首先是继承了dataset这个抽象类,然后,初始化里面得定义自己的成员,然后得实现抽象类的两个成员函数,__len__和 __getitem__, 重点是后面这个,你需要什么样的数据,就要返回什么样的数据, 下面创建一个dataset和DataLoader,看看是什么样子的:
1 | dataset = WordEmbeddingDataset(text, word_to_idx, idx_to_word, word_freqs, word_counts) |
这样,取batch的时候就非常简单了。
1 | # for i, (center_work, pos_words, neg_words) in enumerate(dataloader): |
2.3 定义Pytorch模型
我们使用灵活的方式去定义模型, 继承nn.Module类。这里面,需要我们自己写前向传播
1 | class EmbeddingModel(nn.Module): |
关于Embedding详细看官方文档:https://pytorch.org/docs/stable/nn.html#embedding
下面定义Pytorch模型,并且移动到GPU
1 | model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE) |
2.4 训练模型
Pytorch只要定义好了模型之后,训练起来就比较简单了,还是下面这几步, 前向传播,计算损失,梯度清零,反向传播,参数更新。
- 模型一般需要训练若干个epoch
- 每个epoch我们都把所有的数据分成若干个batch
- 把每个batch的输入和输出都包装成cuda tensor
- forward pass,通过输入的句子预测每个单词的下一个单词
- 用模型的预测和正确的下一个单词计算cross entropy loss
- 清空模型当前gradient
- backward pass
- 更新模型参数
- 隔一定的iteration输出模型在当前iteration的loss,并且保存参数
1 | # 下面是训练部分 |
这里要整理一个知识点: Pytorch的模型保存与加载
Pytorch官方的加载和保存模型的方式有两种:
1.保存和加载整个模型。这种方式再重新加载的时候不需要自定义网络结构,保存时已经把网络结构保存了下来,比较死板不能调整网络结构。
1 | torch.save(model, 'model.pkl') |
2.仅保存和加载模型参数(推荐使用)。这种方式再重新加载的时候需要自己定义网络,并且其中的参数名称与结构要与保存的模型中的一致(可以是部分网络,比如只使用VGG的前几层),相对灵活,便于对网络进行修改。
1 | torch.save(model_object.state_dict(), 'params.th') |
这里就是用了第二种保存模型的方式,毕竟训练模型的目的是为了得到嵌入矩阵,模型本身不是重点。下次使用嵌入矩阵的时候,可以:
1 | model.load_state_dict(torch.load("embedding-{}.th".format(EMBEDDING_SIZE))) |
2.5 模型的测试
这里,就不用MEN和SImplex-999了,这个是衡量的余弦相似性具体的可以看我下面给出的链接。 这里只看看训练的这个词向量矩阵的效果。
2.5.1 寻找nearest neighbors
1 | def find_nearest(word): |
结果如下:

可以发现,与good类似的有bad, perfect, 与green有关的有blue,yellow,white, orange这些颜色的,与America有关的都是些国家的一些词。 效果还是不错的。
2.5.2 单词之间关系的类比推理
这个就是吴恩达老师讲的那个词嵌入有个很好的特性,就是它能帮助实现类比推理。
假设我提出 一个问题,男人对应女人,那么King对应什么?能否有一种算法能够自动推导出这种关系。
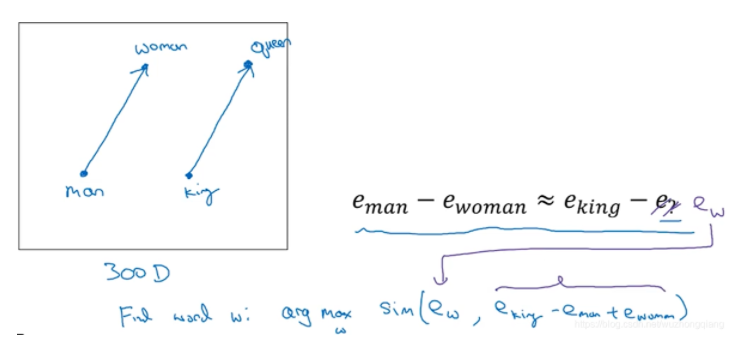
看看代码的实现:
1 | man_idx = word_to_idx["man"] |
结果如下:

可以看到, 国王对应上面的这些,里面还是有queen的, 伊丽莎白等吧, 哈哈,还是挺有意思的,可以自己试试。