Pytorch官方英文文档:https://pytorch.org/docs/stable/torch.html?
Pytorch中文文档:https://pytorch-cn.readthedocs.io/zh/latest/
1. 张量的简介与创建
这部分内容介绍pytorch中的数据结构——Tensor,Tensor是PyTorch中最基础的概念,其参与了整个运算过程,主要介绍张量的概念和属性,如data, device, dtype等,并介绍tensor的基本创建方法,如直接创建、依数值创建和依概率分布创建等。
1.1 张量的简介
1.张量的基本概念
张量其实是一个多维数组,它是标量、向量、矩阵的高维拓展
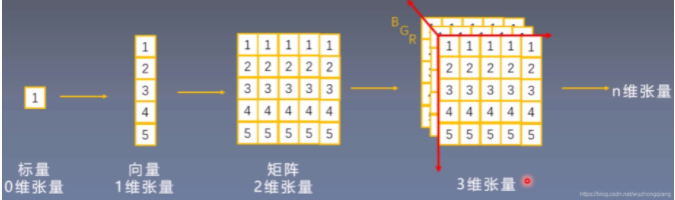
2.Tensor与Variable
在Pytorch0.4.0版本之后其实Variable已经并入Tensor, 但是Variable这个数据类型的了解,对于理解张量来说很有帮助, 这到底是个什么呢?
Variable是torch.autograd中的数据类型。
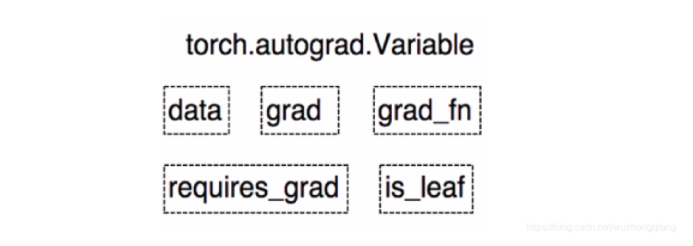
Variable有下面的5个属性:
- data: 被包装的Tensor
- grad: data的梯度
- grad_fn: fn表示function的意思,记录创建张量时用到的方法,比如说加法,乘法,这个操作在求导过程需要用到,Tensor的Function, 是自动求导的关键
- requires_grad: 指示是否需要梯度, 有的不需要梯度
- is_leaf: 指示是否是叶子节点(张量)
这些属性都是为了张量的自动求导而设置的, 从Pytorch0.4.0版开始,Variable并入了Tensor, 看看张量里面的属性:
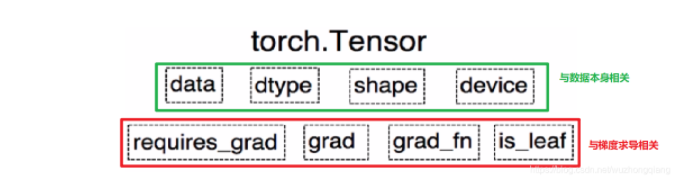
可以发现,如今版本里面的Tensor共有8个属性,上面四个与数据本身相关,下面四个与梯度求导相关。 其中有五个是Variable并入过来的, 这些含义就不解释了, 而还有三个属性没有说:
- dtype: 张量的数据类型, 如torch.FloatTensor, torch.cuda.FloatTensor, 用的最多的一般是float32和int64(torch.long)
- shape: 张量的形状, 如(64, 3, 224, 224)
- device: 张量所在的设备, GPU/CPU, 张量放在GPU上才能使用加速。
知道了什么是张量,那么如何创建张量呢?
1.2 张量的创建
1.2.1 直接创建张量
torch.Tensor(): 功能: 从data创建Tensor

这里的data,就是我们的数据,可以是list,也可以是numpy。 dtype这个是指明数据类型, 默认与data的一致。 device是指明所在的设备, requires_grad是是否需要梯度, 在搭建神经网络的时候需要求导的那些参数这里要设置为true。 pin_memory是否存于锁页内存,这个设置为False就可以。下面就具体代码演示:
1 | arr = np.ones((3, 3)) |
1.2.2 通过numpy数组来创建
torch.from_numpy(ndarry): 从numpy创建tensor
注意:这个创建的Tensor与原ndarray共享内存, 当修改其中一个数据的时候,另一个也会被改动。
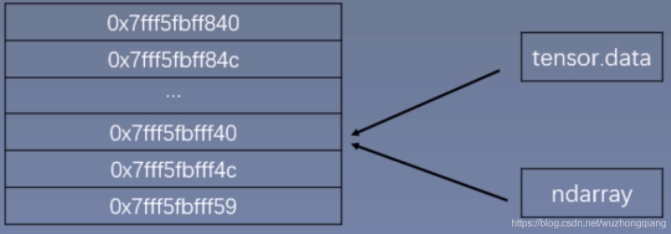
下面具体看代码演示(共享内存):
1 | arr = np.array([[1, 2, 3], [4, 5, 6]]) |
1.2.3 依据数值创建
torch.zeros(): 依size创建全0的张量
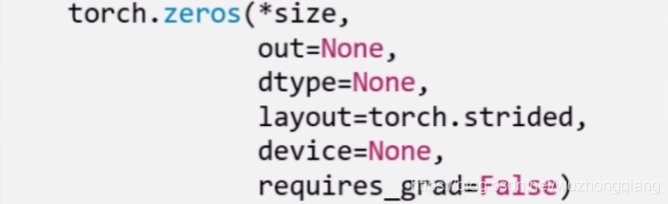
这些参数都比较好理解,layout这个是内存中的布局形式, 一般采用默认就可以。 这个out,表示输出张量,就是再把这个张量赋值给别的一个张量,但是这两个张量是一样的,指的同一个内存地址。看代码:
1 | out_t = torch.tensor([1]) |
torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False) : 这个是创建与input同形状的全0张量
1 | t = torch.zeros_like(out_t) # 这里的input要是个张量 |
除了全0张量, 还可以创建全1张量, 用法和上面一样,torch.ones(), torch.ones_like(), 还可以自定义数值张量:torch.full(), torch.full_like()

这里的fill_value就是要填充的值。
1 | t = torch.full((3,3), 10) |
torch.arange(): 创建等差的1维张量,数值区间 [start, end), 注意这是右边开,取不到最后的那个数。

这个和numpy的差不多,这里的step表示的步长。
1 | t = torch.arange(2, 10, 2) # tensor([2, 4, 6, 8]) |
torch.linspace(): 创建均分的1维张量, 数值区间[start, end] 注意这里都是闭区间,和上面的区分。

这里是右闭, 能取到最后的值,并且这里的steps是数列的长度而不是步长。
1 | t = torch.linspace(2, 10, 5) # tensor([2, 4, 6, 8, 10]) |
除了创建均分数列,还可以创建对数均分数列:
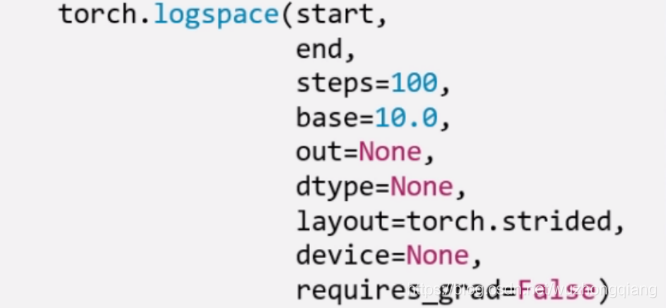
这里的base表示以什么为底。
最后一个方法就是torch.eye(): 创建单位对角矩阵, 默认是方阵

n, m分别是矩阵的行数和列数。
1.2.4 依概率分布创建张量
torch.normal():生成正态分布(高斯分布), 这个使用的比较多

mean是均值,std是标准差。 但是这个地方要注意, 根据mean和std,分别各有两种取值,所以这里会有四种模式:
- mean为标量, std为标量
- mean为标量, std为张量
- mean为张量, std为标量
- mean为张量,std为张量
这个看代码来的直接:
1 | # 第一种模式 - 均值是标量, 方差是标量 - 此时产生的是一个分布, 从这一个分部种抽样相应的个数,所以这个必须指定size,也就是抽取多少个数 |
下面一个是标准正态分布:torch.randn(), torch.randn_like()

生成均匀分布:torch.rand(), rand_like() 在[0,1)生成均匀分布
torch.randint(), torch.randint_like(): 区间[low,hight)生成整数均匀分布

下面看最后两个:
torch.randperm(n): 生成从0 - n-1的随机排列, n是张量的长度, 经常用来生成一个乱序索引。
torch.bernoulli(input): 以input为概率,生成伯努利分布(0-1分布,两点分布), input: 概率值
2. 张量的操作
这次整理张量的基本操作,比如张量的拼接,切分,索引和变换以及数学运算等,并基于所学习的知识,实现线性回归模型。
2.1 张量的基本操作
2.1.1 张量的拼接
torch.cat(tensors, dim=0, out=None): 将张量按维度dim进行拼接, tensors表示张量序列, dim要拼接的维度
torch.stack(tensors, dim=0, out=None): 在新创建的维度dim上进行拼接, tensors表示张量序列, dim要拼接的维度
这是啥意思, stack会新创建一个维度,然后完成拼接。还是看代码:
1 | # 张量的拼接 |
.cat是在原来的基础上根据行和列,进行拼接, 我发现一个问题,就是浮点数类型拼接才可以,long类型拼接会报错。 下面我们看看.stack方法:
1 | t_stack = torch.stack([t,t,t], dim=0) |
.stack是根据给定的维度新增了一个新的维度,在这个新维度上进行拼接,这个.stack与其说是从新维度上拼接,不太好理解,其实是新加了一个维度Z轴,只不过dim=0和dim=1的视角不同罢了。 dim=0的时候,是横向看,dim=1是纵向看。
所以这两个使用的时候要小心,看好了究竟是在原来的维度上拼接到一块,还是从新维度上拼接到一块。
2.1.2 张量的切分
torch.chunk(input, chunks, dim=0): 将张量按维度dim进行平均切分, 返回值是张量列表,注意,如果不能整除, 最后一份张量小于其他张量。 chunks代表要切分的维度。 下面看一下代码实现:
1 | a = torch.ones((2, 7)) # 7 |
torch.split(tensor, split_size_or_sections, dim=0): 这个也是将张量按维度dim切分,但是这个更加强大, 可以指定切分的长度, split_size_or_sections为int时表示每一份的长度, 为list时,按list元素切分
1 | # split |
所以切分,也有两个函数,.chunk和.split。
.chunk切分的规则就是提供张量,切分的维度和几份, 比如三份, 先计算每一份的大小,也就是这个维度的长度除以三,然后上取整,就开始沿着这个维度切,最后不够一份大小的,也就那样了。 所以长度为7的这个维度,3块,每块7/3上取整是3, 然后第一块3,第二块是3,第三块1。这样切
.split这个函数的功能更加强大,它可以指定每一份的长度,只要传入一个列表即可,或者也有一个整数,表示每一份的长度,这个就根据每一份的长度先切着, 看看能切几块算几块。 不过列表的那个好使,可以自己指定每一块的长度,但是注意一下,这个长度的总和必须是维度的那个总长度才用办法切。
2.1.3 张量的索引
torch.index_select(input, dim, index, out=None): 在维度dim上,按index索引数据,返回值,以index索引数据拼接的张量。
1 | t = torch.randint(0, 9, size=(3, 3)) # 从0-8随机产生数组成3*3的矩阵 |
torch.masked_select(input, mask, out=None): 按mask中的True进行索引,返回值:一维张量。 input表示要索引的张量, mask表示与input同形状的布尔类型的张量。 这种情况在选择符合某些特定条件的元素的时候非常好使, 注意这个是返回一维的张量。下面看代码:
1 | mask = t.ge(5) # le表示<=5, ge表示>=5 gt >5 lt <5 |
所以张量的索引,有两种方式:.index_select和.masked_select
- .index_select: 按照索引查找 需要先指定一个Tensor的索引量,然后指定类型是long的
- .masked_select: 就是按照值的条件进行查找,需要先指定条件作为mask
2.1.4 张量的变换
torch.reshape(input, shape): 变换张量的形状,这个很常用,input表示要变换的张量,shape表示新张量的形状。 但注意,当张量在内存中是连续时, 新张量与input共享数据内存
1 | # torch.reshape |
上面这两个是共内存的, 一个改变另一个也会改变。这个要注意一下。
torch.transpose(input, dim0, dim1): 交换张量的两个维度, 矩阵的转置常用, 在图像的预处理中常用, dim0要交换的维度, dim1表示要交换的问题
1 | # torch.transpose |
torch.t(input): 2维张量的转置, 对矩阵而言,相当于torch.transpose(inpuot, 0,1)
torch.squeeze(input, dim=None, out=None): 压缩长度为1的维度, dim若为None,移除所有长度为1的轴,若指定维度,当且仅当该轴长度为1时可以被移除
1 | # torch.squeeze |
torch.unsqueeze(input, dim, out=None): 依据dim扩展维度
2.2 张量的数学运算
2.2.1 标量运算
Pytorch中提供了丰富的数学运算,可以分为三大类: 加减乘除, 对数指数幂函数,三角函数


1 | t_0 = torch.randn((3, 3)) |
2.2.2 向量运算
向量运算符只在一个特定轴上运算,将一个向量映射到一个标量或者另外一个向量。
1 | #统计值 |
cum扫描
1 | #cum扫描 |
张量排序
1 | #torch.sort和torch.topk可以对张量排序 |
2.2.3 矩阵运算
矩阵必须是二维的。类似torch.tensor([1,2,3])这样的不是矩阵。
矩阵运算包括:矩阵乘法,矩阵转置,矩阵逆,矩阵求迹,矩阵范数,矩阵行列式,矩阵求特征值,矩阵分解等运算。
1.矩阵乘法
1 | #矩阵乘法 |
2.转置
1 | #矩阵转置 |
3.矩阵求逆
1 | #矩阵逆,必须为浮点类型 |
4.矩阵求迹
1 | #矩阵求trace |
5.求范数和行列式
1 | #矩阵求范数 |
6.特征值和特征向量
1 | #矩阵特征值和特征向量 |
7.QR分解
1 | #矩阵QR分解, 将一个方阵分解为一个正交矩阵q和上三角矩阵r |
8.SVD分解
1 | #矩阵svd分解 |
下面基于上面的这些方法玩一个线性回归模型。
3. 搭建一个线性回归模型

这就是我上面说的叫做代码逻辑的一种思路, 写代码往往习惯先有一个这样的一种思路,然后再去写代码的时候,就比较容易了。 而如果不系统的学一遍Pytorch, 一上来直接上那种复杂的CNN, LSTM这种,往往这些代码逻辑不好形成,因为好多细节我们根本就不知道。 所以这次学习先从最简单的线性回归开始,然后慢慢的到复杂的那种网络。下面我们开始写一个线性回归模型:
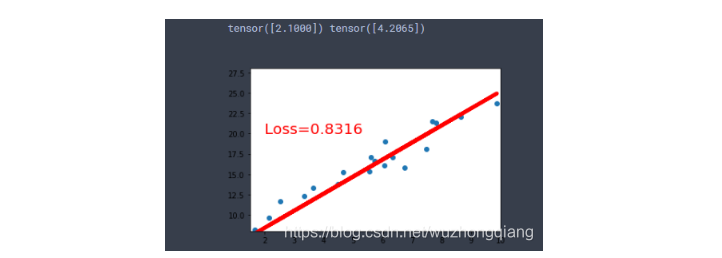
1 | # 首先我们得有训练样本X,Y, 这里我们随机生成 |
我们看一下结果:
4. 总结
今天的学习内容结束, 下面简单的梳理一遍,其实小东西还是挺多的, 首先我们从Pytorch最基本的数据结构开始,认识了张量到底是个什么东西,说白了就是个多维数组,然后张量本身有很多的属性, 有关于数据本身的data, dtype, shape, dtype, 也有关于求导的requires_grad, grad, grad_fn, is_leaf。 然后学习了张量的创建方法, 比如直接创建,从数组创建,数值创建,按照概率创建等。 这里面涉及到了很多的创建函数tensor(), from_numpy(), ones(), zeros(), eye(), full(), arange(), linspace(), normal(), randn(), rand(), randint(), randperm()等等吧。
接着就是张量的操作部分, 有基本操作和数学运算, 基本操作部分有张量的拼接两个函数(.cat, .stack), 张量的切分两个函数(.chunk, .split), 张量的转置(.reshape, .transpose, .t), 张量的索引两个函数(.index_select, .masked_select)。 数学运算部分,也是很多数学函数,有加减乘除的,指数底数幂函数的,三角函数的很多。
最后基于上面的所学完成了一个简单的线性回归。 下面以一张思维导图把这一篇文章的内容拎起来:
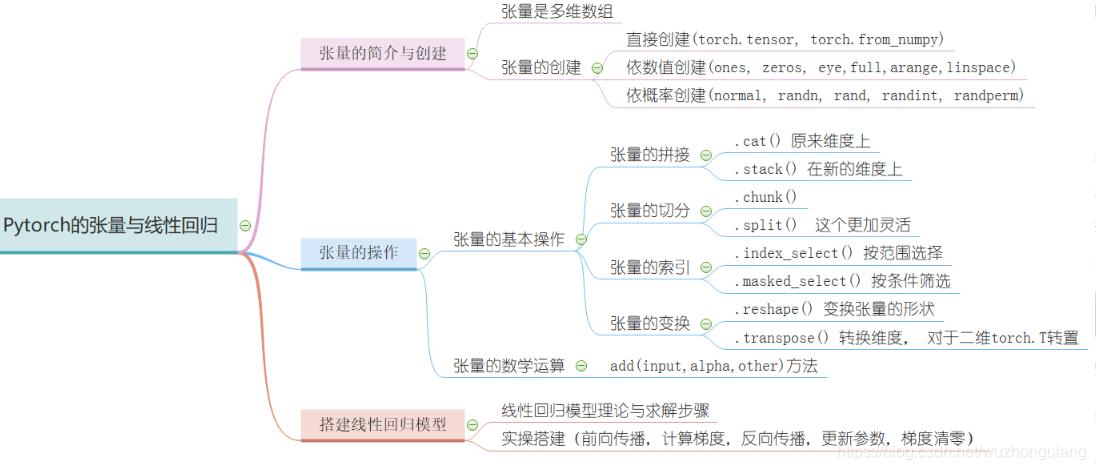
这次整理了很多的函数,每个函数的用法不同,具体用法先不用刻意记住,先知道哪些函数具体完成什么功能,到时候用的时,边查边用,慢慢的多练才能熟。
Ok, 下一次学习Pytorch的动态图机制以及自动求导机制, 然后基于前面的这两篇再玩一个逻辑回归, 我们从最简单的模型开始 😉