Pytorch官方英文文档:https://pytorch.org/docs/stable/torch.html?
Pytorch中文文档:https://pytorch-cn.readthedocs.io/zh/latest/
1. Tensorboard的简介与安装
首先,什么是Tensorboard, 这是TensorFlow中强大的可视化工具,支持标量,图像,文本,音频,视频和Embedding等多种数据可视化。下面是它的一个界面:
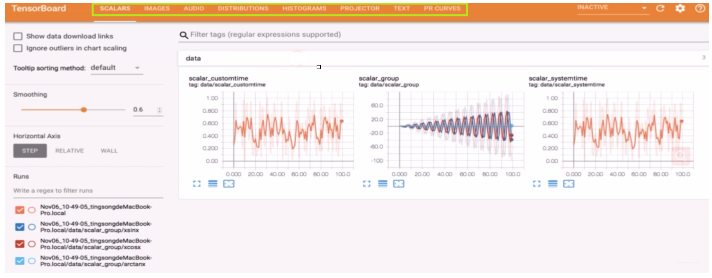
我们先看一下它的一个运行机制:
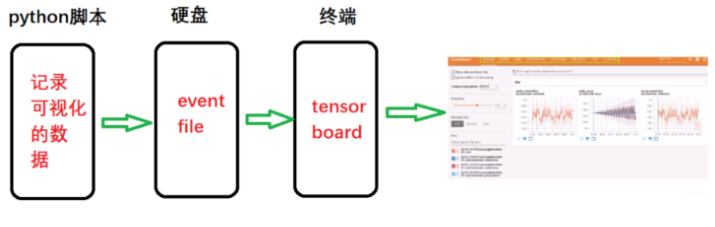
上面就是Tensorboard的一个运行机制,先从python脚本中记录可视化的数据然后生成eventfile文件存储到硬盘, 然后从终端运行Tensorboard,打开web页面, 然后读取存储的eventfile在web页面上进行数据的可视化。
下面我们通过代码来看看这个流程:
1.我们得编写python脚本文件记录数据可视化数据
1 | import numpy as np |
上面要从torch.utils.tensorboard里面导入SummaryWriter这个类,这个类是我们最根本的类,用来创建一个writer,这个writer可以记录我们想要可视化的那些数据,这里做的演示很简单,就是可视化几个函数图像。
我们运行代码,会发现报错,提示ModuleNotFoundError: No module named 'tensorboard', 所以我们得先安装Tensorboard, 这个pip install tensorboard进行安装即可,一定要安装到你运行的环境里面。然后运行,依然会报错,提示ModuleNotFoundError: No module named 'past', 这个注意, 我们得pip intall future, 这里千万不要用past。 这时候我们会发现当前文件夹下有个runs:
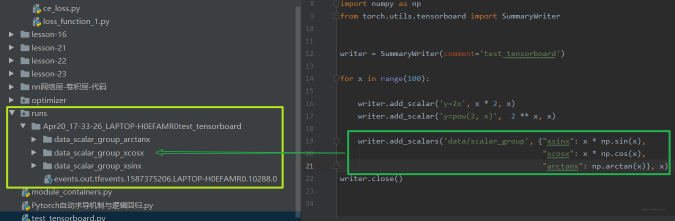
下面我们回到终端当中, 然后输入tensorboard读取这个event files
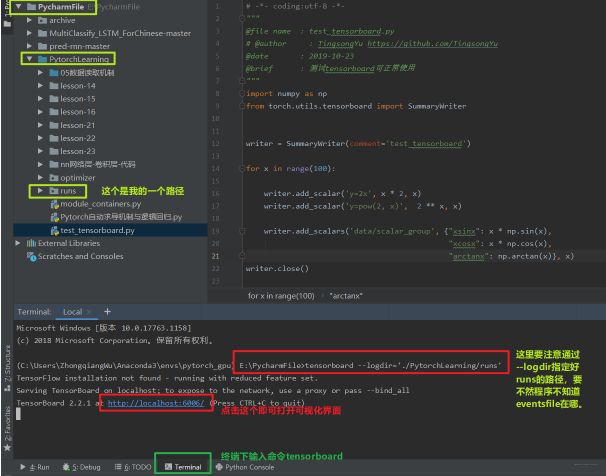
注意, 那个--logdir=后面不能加引号,上面的会提示找不到eventsfile, 所以应该tensorboard --logdir=./PytorchLearning/runs, 这样我们点击下面的那个链接就可以看到我们创建的可视化事件了。 下面一个图介绍Tensorboard界面:
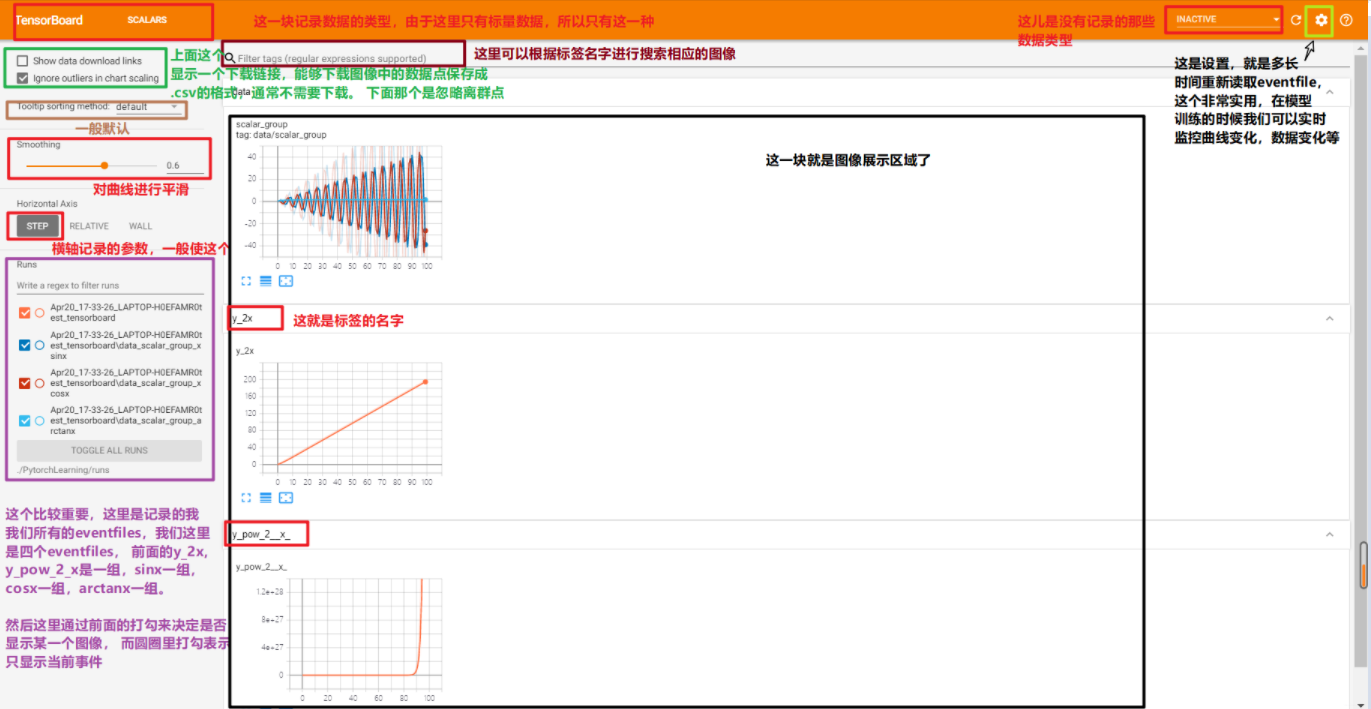
这就是Tensorboard的安装和简介的东西了。 下面我们看看这个东西到底应该如何使用了。
2. Tensorboard的基本使用
Tensorbord的基本使用包括准确率和损失的可视化, 参数数据的分布及参数梯度的可视化等。 下面我们一一来学习。但是在正式学习之前,我们得先了解一些基础知识:
2.1 SummaryWriter
这个类的功能是提供创建event file的高级接口。

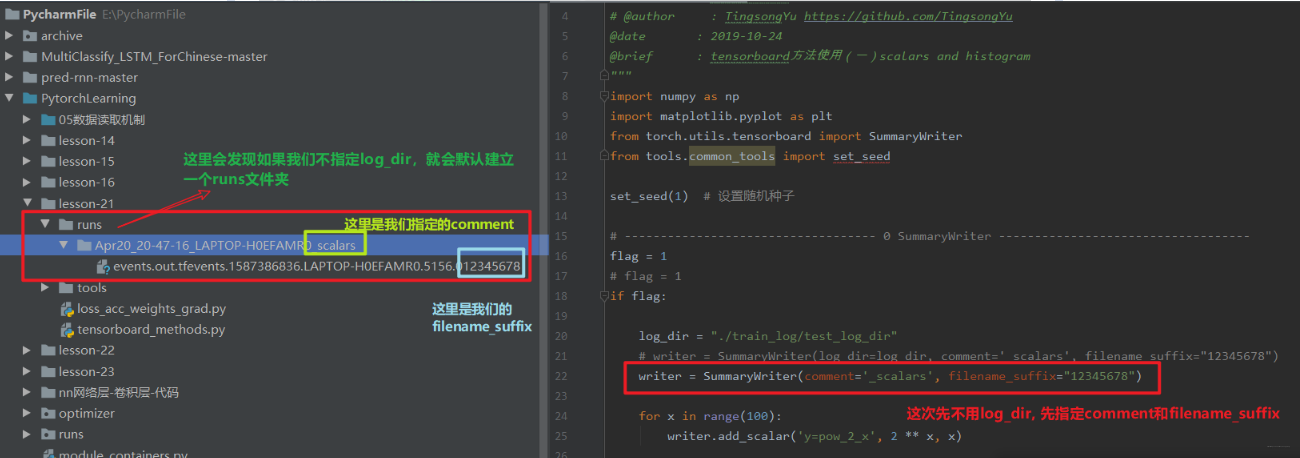
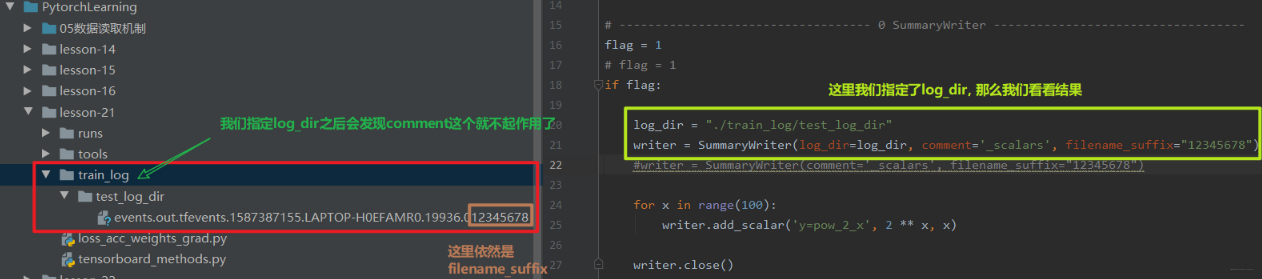
- log_dir: event file输出文件夹, 如果不设置的话,就会创建一个runs, 通常自己设置
- comment:不指定log_dir时, 文件夹后缀
- filename_suffix: event file文件名后缀
我们可以从代码里面看一下, 先看一下不用log_dir的效果:
下面我们指定load_dir,就会发现此时comment就不起作用了:
上面就是如何创建一个event file, 那么我们再看看一些方法:
1.add_scaler()/add_scalers()
功能: 记录标量

tag表示图像的标签名, 图的唯一标识,就是图的标题 scaler_value表示要记录的标量,可以理解为y轴, global_step表示x轴。 注意这个用起来的一个局限性就是它只能画一条线,但是往往模型训练的时候想监控训练集和验证集的曲线的对比情况,那时候这个不能使了。可以用add_scalers(),这里面两个参数:
- main_tag: 该图的标签
- tag_scaler_dict: key是变量的tag(类似于每条曲线的标签), value是变量的值(等用于上面的scaler_value, 只不过是可以多个线)
这两个的使用我们前面的那个例子:
1 | writer.add_scalar('y=2x', x * 2, x) |
我们可以看一下这个的结果:
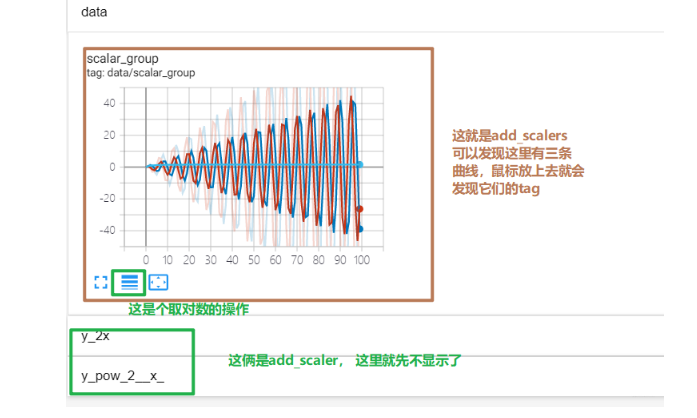
2.add_histogram()
功能: 统计直方图与多分位数直线图, 这对参数的分布以及梯度的分布非常有用

tag表示图像的标签名,图的唯一标识; values表示要统计的参数, global_step表示y轴, bins表示取直方图的bins。 下面从代码中看看:
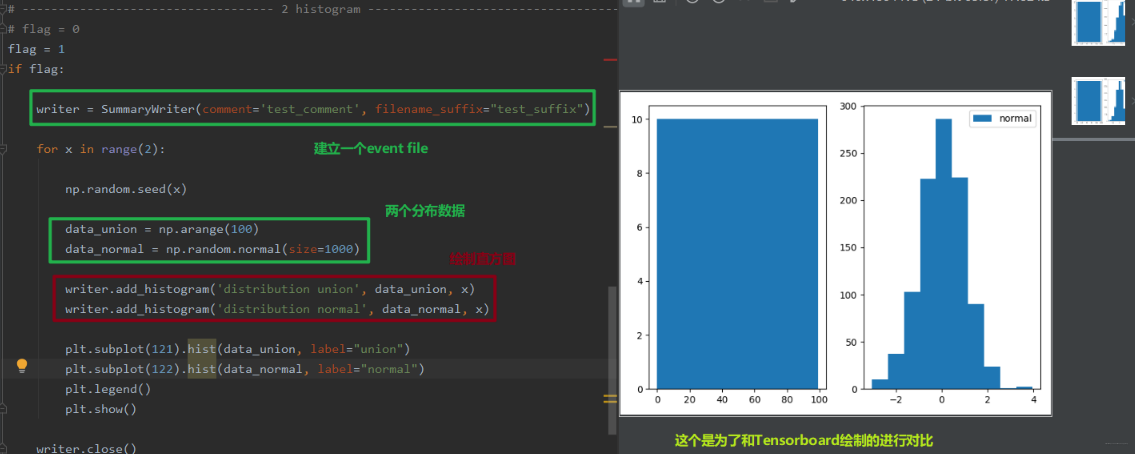
下面看看Tensorboard中的结果:
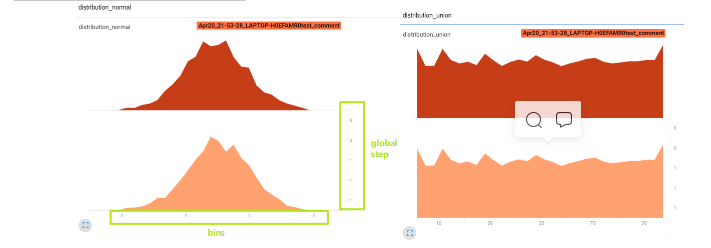
并且Tensorboard还能查看多分位折线图:
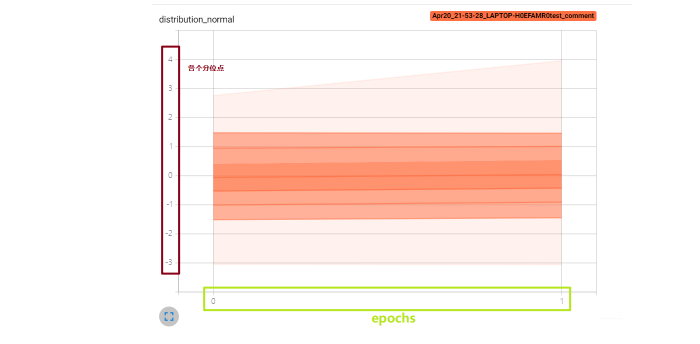
这个图的作用是观察每个数据方差的一个变化情况。这就是add_histogram的一个使用情况了
下面我们就拿人民币二分类的例子,采用上面的两个方法进行模型训练过程中loss, acc的一个监控和参数的分布以及参数对应的梯度的一个分布, 就是看看在具体的模型训练中应该怎么用?我们当前学的这个模块是模型训练中的第5个模块,所以直接从这里构建我们的event file就可以了。
我们首先在第五模块构建一个SummaryWriter
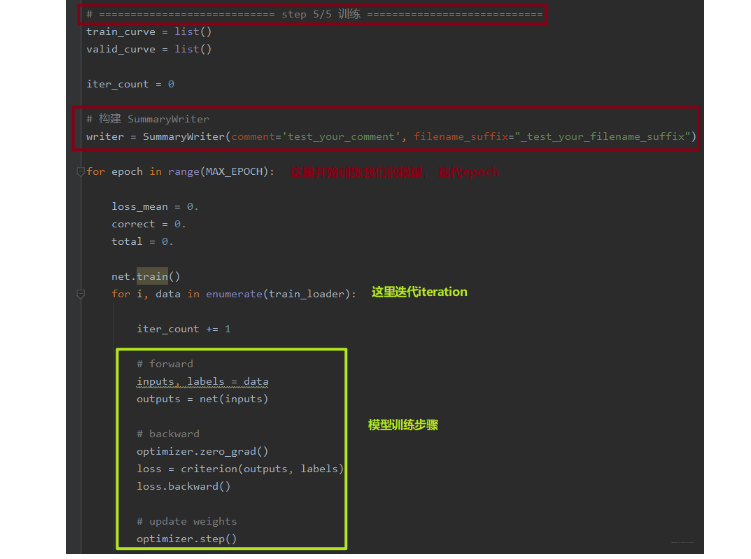
下面我们看看如何绘制训练过程中的损失,正确率变化曲线以及参数的分布及它们权重的一个分布:
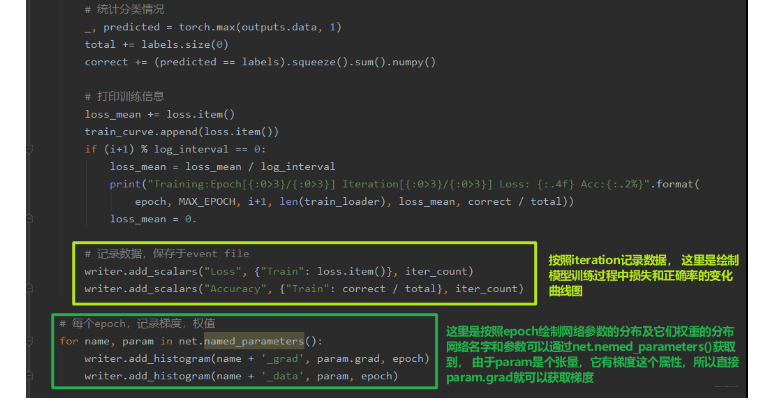
下面还可以绘制验证集上的损失和正确率的曲线变化图像:
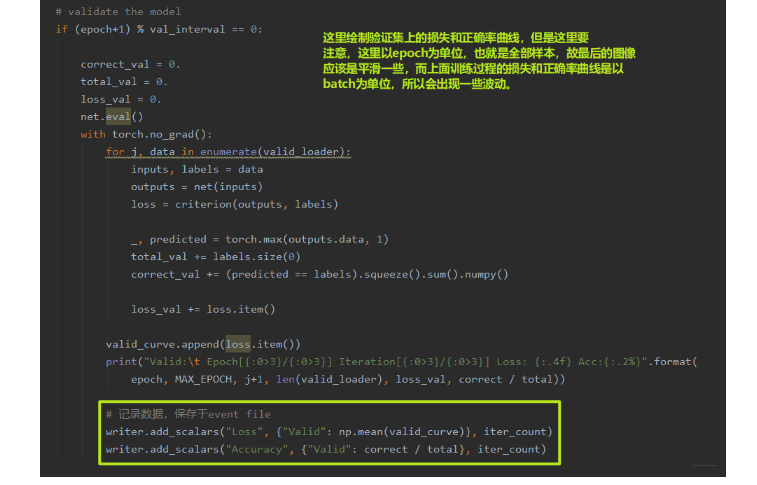
我们看看最后的结果:
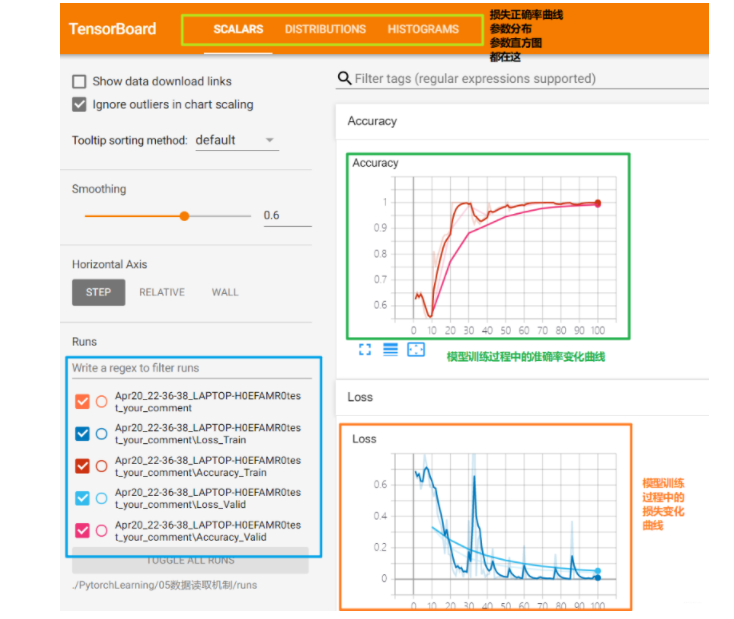
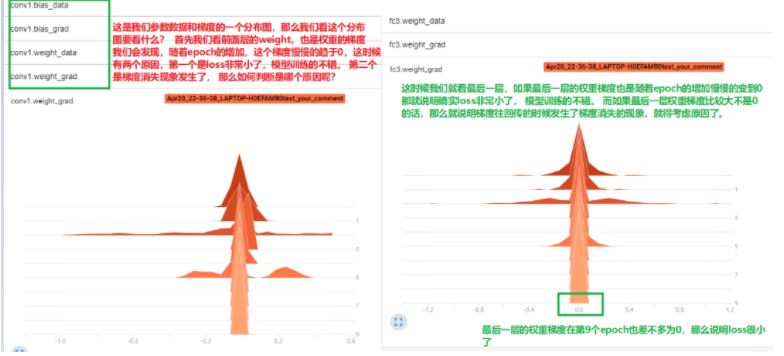
上面这是模型训练验证过程中学习曲线的可视化。下面我们看看参数的分布直方图,然后说个现象:
好了, 这就是SummaryWriter怎么去构建event file的一个路径,设置路径,然后就是add_scaler和add_histogram方法,采用这两个方法就可以监控我们模型训练过程中训练集和验证集loss曲线及准确率曲线对比,还有模型参数的数据分布以及每个epoch梯度更新的一个分布。 下面我们再学习Tensorboard的图像可视化方法。
2.2 Tensorboard图像可视化方法
我们下面学习Tensorboard中图像可视化相关的两个方法:
1.add_image()
功能: 记录图像

参数说明:
tag表示图像的标签名, 图的唯一标识。
img_tensor这个要注意, 表示的我们图像数据,但是要注意尺度, 如果我们的图片像素值都是0-1, 那么会默认在这个基础上*255来可视化,毕竟我们的图片都是0-255, 如果像素值有大于1的,那么机器就以为是0-255的范围了,不做任何改动。
global_step: x轴
dataformats: 数据形式, 有CHW, HWC, HW(灰度图)
下面用一组代码来演示一下这个add_image()方法的使用:
1 | writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix") |
下面看一下效果:
上面的图片中我们就可视化了5张图片, 但是发现显示的时候,还得拖动去一次次的显示每一张图片,这样就没法同时对比, 如果我们想从一个界面里面同时显示5张图片怎么办? 那就需要下面的方法:
2.torchvision.utils.make_grid
功能: 制作网格图像
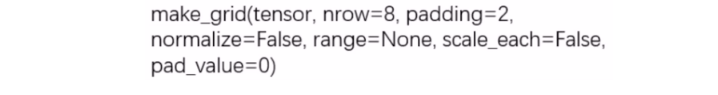
参数说明:

下面演示一下这个函数的使用,我们用的是人民币二分类实验中的图片进行可视化,代码如下:
1 | writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix") |
我们可以看看效果:
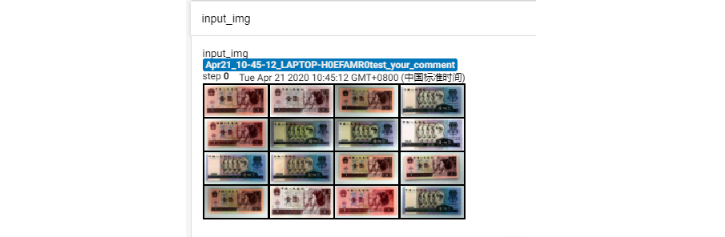
add_image结合make_grid的使用方法还是比较实用的,我们可以对我们的数据进行一个基本的审查,快速的检查训练数据样本之间是否有交叉,这些样本的标签是否是正确的。这样审查数据集就比较快了。
3.add_graph()
功能: 可视化模型计算图

参数说明:
- model: 模型,必须时nn.Module
- input_to_model: 输出给模型的数据
- verbose: 是否打印计算图结构信息
这个就先不进行演示了, 因为这个Pytorch1.2运行的时候存在bug,显示不出计算图来。 版本不支持了,所以得装一个Pytorch1.3版本,这个最好是新构建虚拟环境,然后下载Pytorch和torchvision安装包进行安装即可。我们这里只看一下计算图的显示效果:
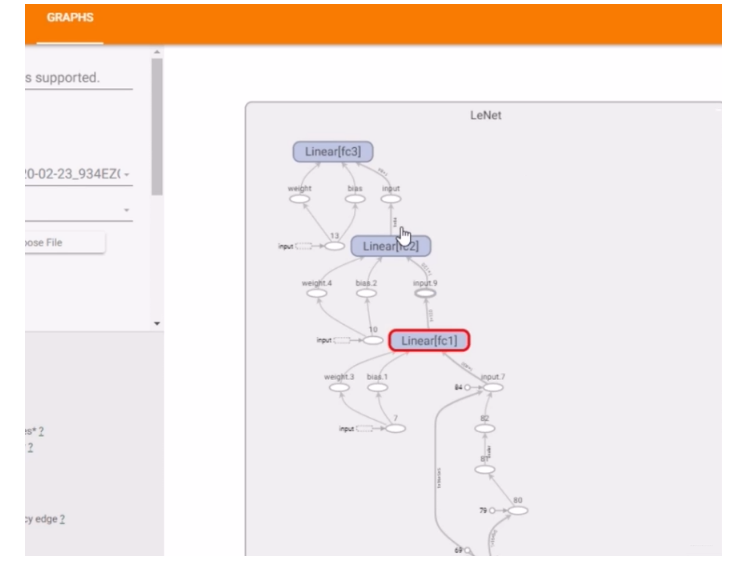
所以Tensorboard的可视化功能还是很强大的,竟然计算图也能可视化。用的时候这么用这个方法:
1 | writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix") |
当然,计算图一般用不到,我们平时更加关心的反而是数据经过各个模块之后的shape变化,所以下面介绍一个使用的工具:
4.torchsummary
功能: 查看模型信息,便于调试, 打印模型输入输出的shape以及参数总量

参数说明:
- model: pytorch模型
- input_size: 模型输入size
- batch_size: batch size
- device: “cuda” or “cpu”, 通常选CPU
这个torchsummary需要自己安装 pip install 这个东西。安装完了之后我们导入,然后直接打印即可:
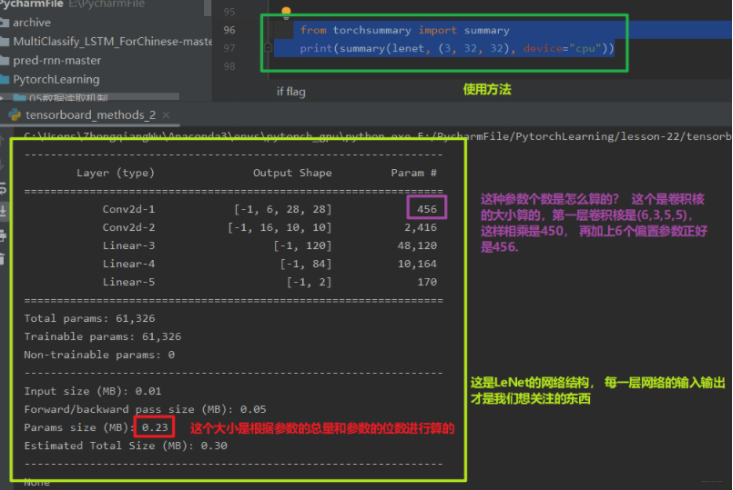
这个工具还是非常实用的。
好了,上面就是图像的可视化的一些方法了。感觉常用的是最后这个网络的结构summary。 下面再介绍一些高级的一些东西了。
3. hook函数与CAM可视化
这些属于一些挺高级的一些知识了,作为知识框架内容,这里简单的进行整理, 这一块会分为三块,首先介绍一下什么是hook函数,然后hook函数怎么使用,最后介绍一个比较强大的可视化方法叫做CAM。
3.1 hook函数介绍
Hook函数机制: 不改变模型的主体,实现额外功能,像一个挂件和挂钩。
为什么需要个这样的东西呢? 这个和Pytorch动态计算图的机制有关,我们知道在动态图的运算过程中,运算结束之后,一些中间变量就会被释放掉,比如特征图,非叶子节点的梯度。 但是往往我们想提取这些中间变量,这时候我们就可以用hook函数在前向传播,反向传播的时候,挂上一个额外的函数,通过这个额外的函数去获取这些可能被释放掉而我们后面又想用的这些中间变量, 甚至可以通过hook函数去改变中间变量的梯度。
Pytorch提供了四种hook函数
- torch.Tensor.register_hook(hook): 针对tensor
- torch.nn.Module.register_forward_hook: 后面这三个针对Module
- torch.nn.Module.register_forward_pre_hook
- torch.nn.Module.register_backward_hook
3.2 hook函数与特征图提取
下面我们一一来看一下:
1.torch.Tensor.register_hook
这是一个张量的hook函数,作用就是注册一个反向传播的hook函数,为什么这里强调反向传播呢? 因为我们只有在反向传播的时候某些中间叶子节点的梯度才会被释放掉,才需要我们使用hook函数去保留一些中间变量的信息。 这个东西其实就可以理解成一个钩子就可以,我们用这个钩子挂一些函数到计算图上,然后去帮助我们完成一些额外的功能。既然是一个钩子,那么我们看看它上面允许挂什么样的函数:

可以发现这里允许挂的函数只有一个输入参数, 不返回或者返回张量。
这里的重点是看看应该怎么使用这个东西,这里的注册是个什么意思? 看到下面你会发现,与其说是注册,不如通俗点说叫“挂上”, 下面详细说一说这个钩子到底怎么用: 我们从需求开始,还记得第二篇里面的那个计算图吗?
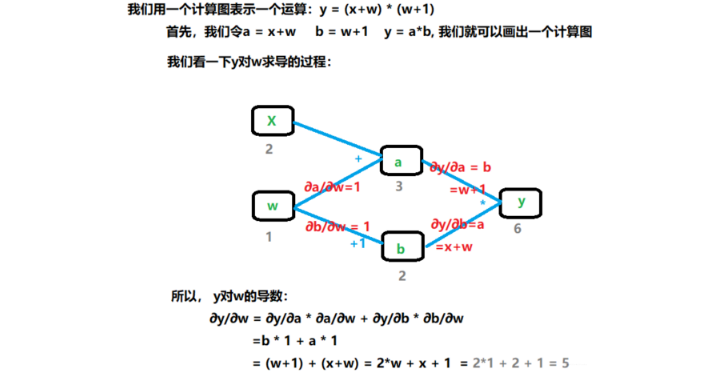
这个图我们当时说在反向传播结束之后,非叶子节点的梯度是会被释放掉的,也就是这里的a, b的梯度,那么我们如果想保留住呢? 在第二篇的时候我们讲了一个方法,叫做retain_grad(), 这个可以保留住中间节点的梯度,其实这里的hook也可以保留住梯度,我们下面可以看看:
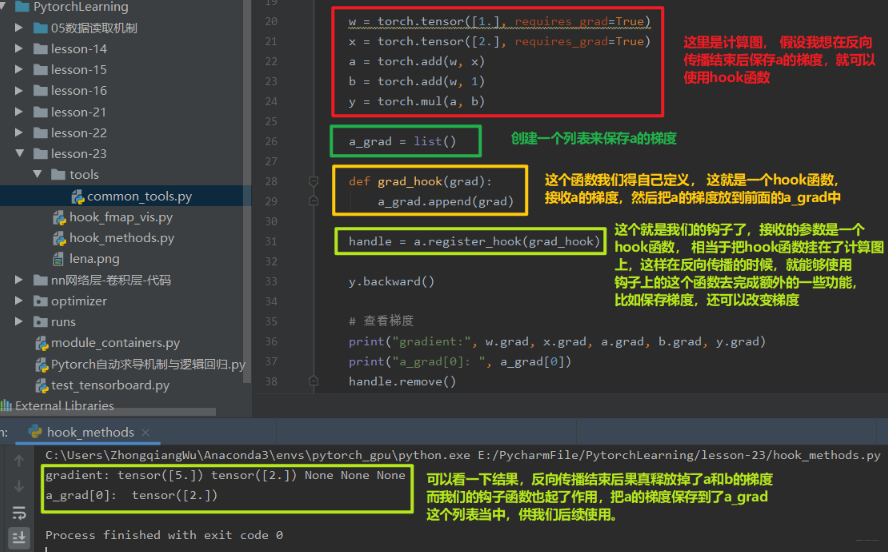
那你可能就要说了, 我既然有个retain_grad()方法了,我何必再多次一举弄个hook函数呢? 这个使用起来还那么麻烦, 当然如果只想保留梯度的话,hook函数的作用可能不那么明显,但是hook函数可不只是能保留梯度那么简单,这个函数的功能就很大了,具体做什么可以自己去写的, 比如我想在反向传播的时候改变叶子节点w的梯度, 这个要怎么弄? 依然可以使用hook函数,参数都一样,只不过改改具体实现方法即可:
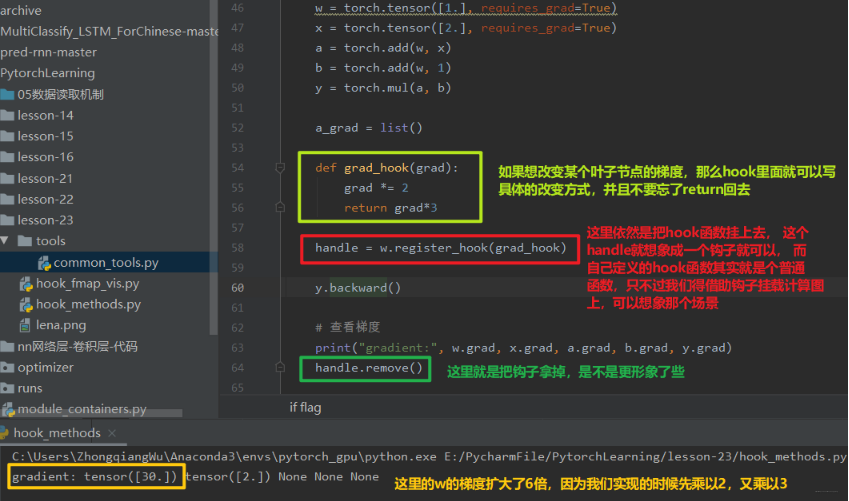
可以看到,通过钩子的方式在计算图上挂函数然后去完成一些功能还是很方便的。 这是针对张量的钩子,那么我们看看针对Module的钩子。
2.Module.register_forward_hook
功能: 注册module的前向传播hook函数, 下面是它的hook函数的定义方法,也就是我们钩子上要挂的函数是什么样的,毕竟不同的钩子应该挂不同的hook函数。

这个钩子允许挂的函数有3个输入,module表示当前网络层, input表示当前网络层的输入数据, output表示当前网络层的输出数据。通常使用这个函数在前向传播过程中获取卷积输出的一个特征图。
3.Module.register_forward_pre_hook
功能: 注册module前向传播前的hook函数, 允许挂的函数结构:

因为它是挂在前向传播前的函数,所以这里的接收参数就没有output了。 这个功能可以查看我们网络之前的数据。
4.Module.register_backward_hook
功能: 注册module反向传播的hook函数

由于是挂在了反向传播后,所以当前的输入有三个参数,并且后两个是grad_input和grad_out, 当前网络层输入梯度数据和输出梯度数据。
好了,四个hook函数已经介绍完毕, 第一个是针对tensor的,而后面三个是针对Module的, 但是又根据钩子摆放的位置不同分成了前向传播之前,前向传播,反向传播后三个。下面我们先通过代码看看后面三个到底应该怎么用, 这里会通过调试的方式看看钩子函数调用的内容机制,然后再梳理一遍这几个函数的逻辑。
我们还是从需求出发:
假设我们有一张图片,首先会通过两个卷积核提取一些特征,然后这些特征再通过池化得到最后的值,我们知道如果是单纯的前向传播,那么传完了之后我们通过卷积之后的特征图就会被释放掉,那么我们如何进行保留这些特征图并且后期可以用Tensorboard进行可视化呢?
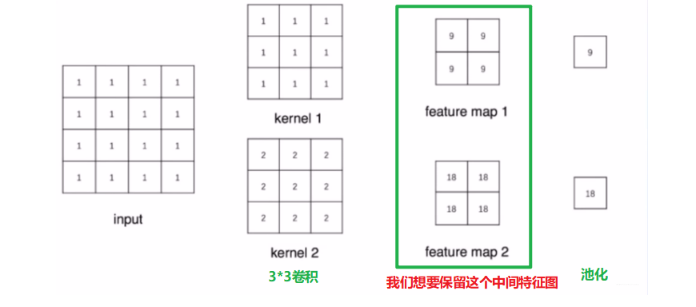
这时候我们就可以采用前向传播hook函数来获取中间的这个特征图, 看看如何操作:
1 | ## 定义我们的网络, 这里只有卷积核池化两个操作 |
我们看一下结果:
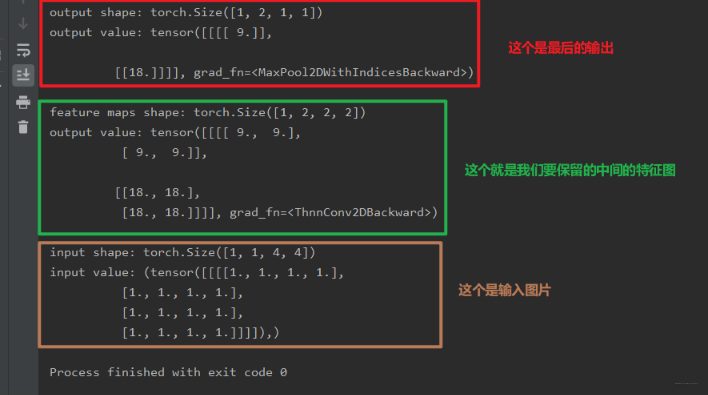
我们发现,通过这种方式就可以进行中间特征图的保存与可视化。但是这个机制是怎么运作的呢? 是什么时候调用的我们的钩子函数呢? 下面通过调试的方式看看背后的工作原理。
我们在output = net(fake_img)前面打上断点,然后debug,步入。我们会进入Module的__call__函数, 在这里面会调用前向传播函数:
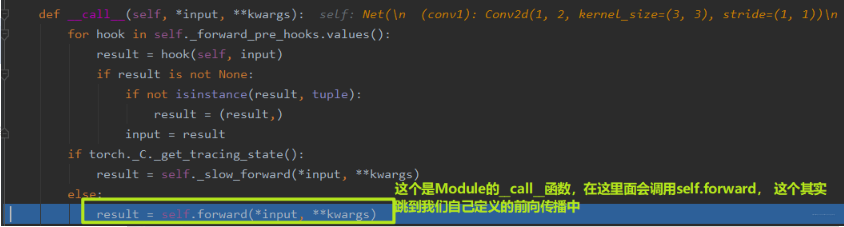
我们在前向传播这一行再次步入,就跳到了我们自己写的前向传播函数里面:
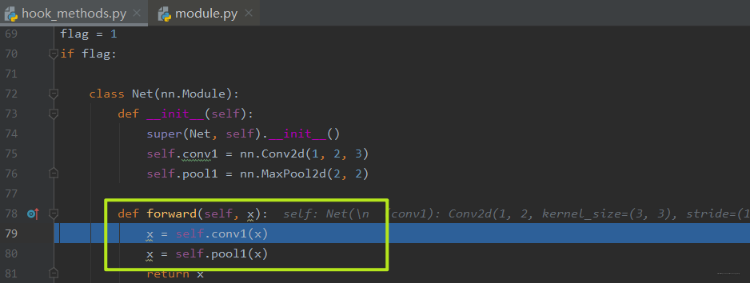
这里面第一个子模块就是卷积模块,也就是我们想放钩子的地方,我们再次步入, 这一次依然到了Module的call函数,因为子模块也是继承的Module了,那么这里就趁机说一说这个call了,因为这里不仅是只完成前向传播了,而且别忘了,我们在第一个子模块是放了一个钩子的, 所以得说一说这个call函数实际上不止完成forward, 看下图:
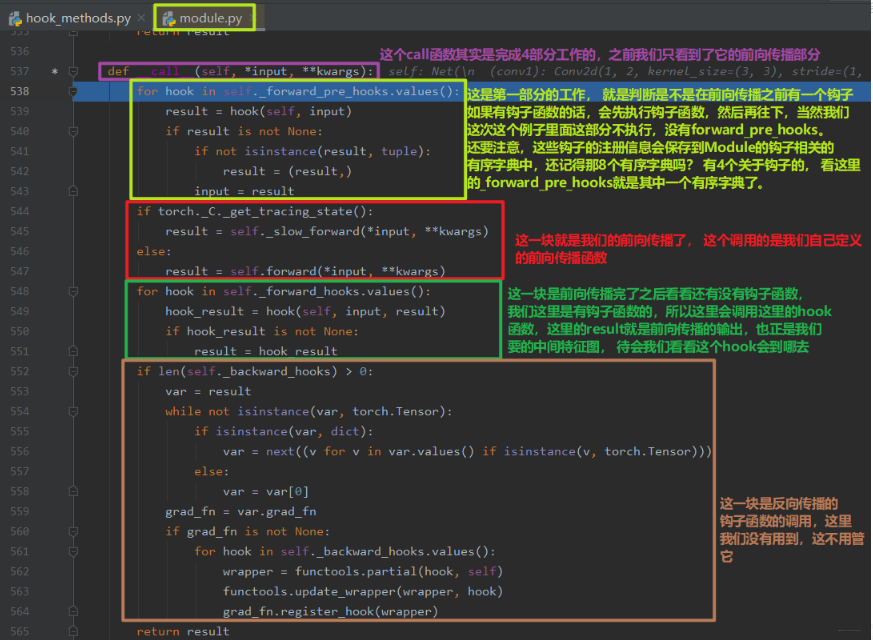
所以在这里,前向传播之后,我们就获得了中间特征图,但是这一次我们是有一个钩子放这里的,那么获取了中间特征图之后,不会返回,而是去执行我们的钩子函数:
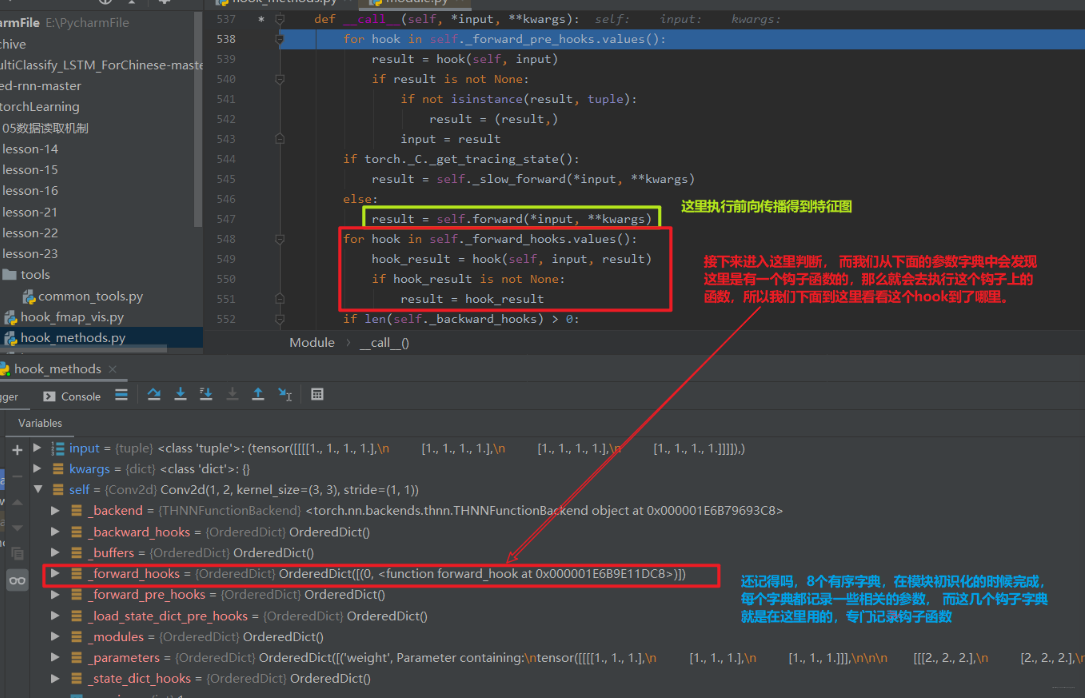
我们在hook_result = hook(self, input, result)这一行再次步入,就会发现跳到了我们自己定义的hook函数中来:
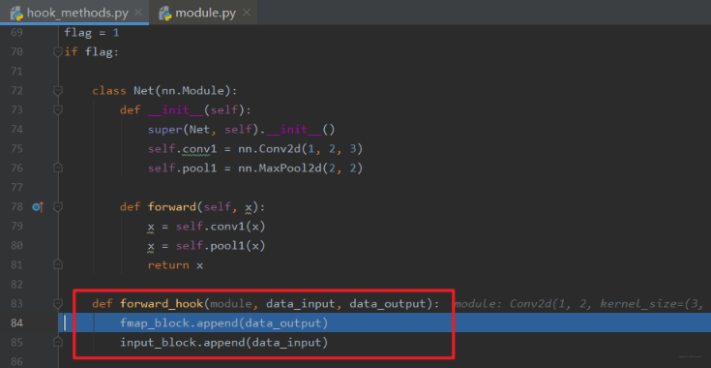
这样就完成了中间图的存储。
好了,上面的hook函数的运行机制差不多清楚了吧,其实都是在__call__函数中完成的,这也是Pytorch代码高级的一个地方了,它实现了一些hook机制,提供了一些额外的实现别的功能的一些接口。稍微梳理一下这个逻辑吧, 首先我们在定义网络的时候,这里会调用父类Module的init函数对模块进行初始化,当然这里的模块不仅指的最后的大网络,每个小的子模块也是如此,这个初始化的过程中是完成了8个参数字典的初始化。在模型调用的时候,其实是在执行Module的__call__函数,这个函数其实是完成4部分的工作,首先是前向传播之前的hook函数,然后才是前向传播的函数, 之后是forward_hooks函数, 最后是反向传播的hooks函数。这个就是Pytorch中hook函数的一个运行机制了。
下面我们看看再加上另外两个hook函数看看到底是不是这样的一个运行顺序:
1 | class Net(nn.Module): |
这里加了另外两个hook函数, 然后把最后的输出注释掉,我们看看这三个hook函数的运行顺序:
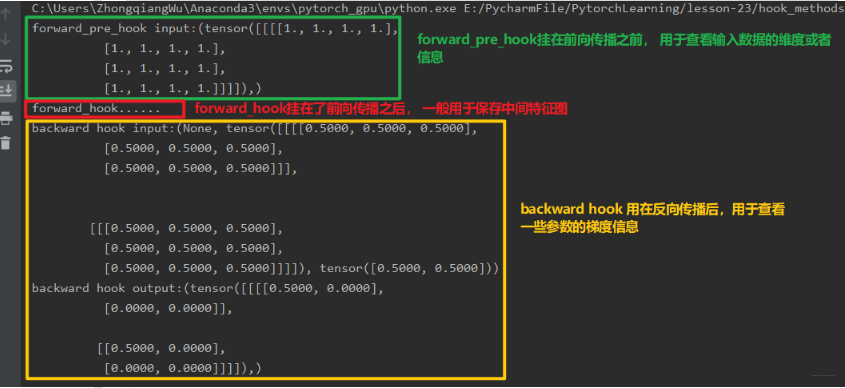
好了,上面就基本上把hook函数给通了一遍,现在再来回想hook函数的作用: 不改变模型主体而可以增加额外的功能,应该知道是什么意思了吧,玄机都在这个__call__函数中。 下面梳理一下子这几个hook函数的关系吧:
hook机制,是在计算图上挂一些钩子,然后钩子上挂一些函数,在不改变模型或者计算图的主体下,实现了一些额外的功能,比如保存一些中间变量等。
主要有四个hook函数,其中一个是针对Tensor的,这个挂在了反向传播之后,常用来保留中间节点的梯度或者改变一些梯度等。另外三个是针对Module的, 根据挂的位置不同分为三个, 有挂在前向传播前的,这个接收的参数没有输出,一般用来查看输入数据的信息,有挂在前向传播之后的,这个接收的参数就是输入和输出, 一般用来存储中间特征图的信息。 还有一个是挂在反向传播后面, 常用来查看梯度信息。
hook机制的运行原理主要是在Module的
__call__函数中, 这里面完成四块功能, 先看看有没有前向传播前的钩子,然后前向传播,然后前向传播后的钩子,然后反向传播钩子。
3.3 CAM可视化
CAM: 类激活图, class activation map。这个东西的功能就是分析卷积神经网络,当卷积神经网络得到了输出之后,可以分析我们的网络是关注图像的哪些部分而得到的这个结果。通过这个东西就可以分析出我们的网络是否学习到了图片中物体本身的特征信息, 可以看看下面的这个过程图:
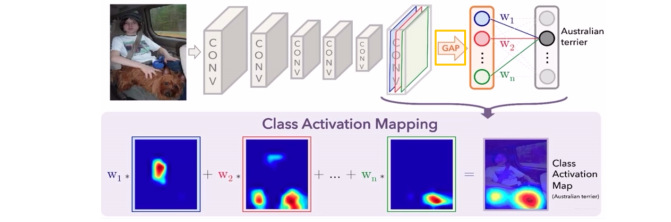
网络最后的输出是澳大利亚犬种。 那么我们的网络从图像中看到了什么东西才确定是这一个类呢? 这里就可以通过CAM算法进行一个可视化,结果就是下面的图像。 红色的就是网络重点关注的, 在这个结果中看以发现,这个网络重点关注了狗的头部,最后判定是一个这样的犬种。
CAM的基本思想: 它会对网络的最后一个特征图进行加权求和,就可以得到一个注意力机制,就是卷积神经网络更关注于什么地方。 这里有个比较有趣的小实验:

我们可以发现这个实验中的网络在预测是飞机的时候,其实关注的并不是飞机本身,而是飞机周围的天空, 发现一片蓝色,所以网络就预测是飞机。 预测汽车的时候,如果把汽车进行缩小, 周围出现了大片蓝色,就发现网络把车也预测成了飞机。 而最后一张图片,竟然还预测出了一个船。 这个可能是因为底部的左边是蓝色,右边不是蓝色,所以网络认为这个是个船。 这说明这个网络根本就没有在学习物体本身,而是光关注物体周围的环境了。
通过Grad-CAM可视化我们可以分析卷积神经网络学习到的特征是否真的是好的,是否真的在学习物体本身,是否真的在学习飞机本身,而不是因为看到了蓝天才判断是飞机。
关于详细的CAM的知识,这里不说了,可以参考CAM分析与代码实现
4. 总结
这次的整理就到这里了,内容依然是挺多的,但是这次的这些内容好像在实战中并不是太常用,所以也类似于一个知识扩充吧, 简单的梳理一下:
首先我们学习了Tensorboard的安装与使用方法, 见识了Tensorboard的强大可视化功能,学习了对于标量的可视化,尤其是绘制模型的学习曲线,这个还是非常重要的,因为学习曲线这个东西可以看出模型究竟是过拟合还是欠拟合的问题。 当然参数的分布和梯度可视化也是挺重要的, 当发现参数的梯度非常小的时候,有时候也不能盲目的去判断是梯度消失,或许是因为loss本身就不大。 然后学习了图像的可视化方式,add_graph, add_image,还有make_grid等 函数。add_image结合make_grid的使用方法还是比较实用的,可以帮助我们更好的去审查输入数据。
第二块介绍了hook机制,这个是Pytorch中留给我们扩展功能的一些接口,在不改变网络的主体下额外增加功能。 主要有四种hook函数, 并且学习了内部的运行机制。 最后了解了一下CAM可视化的东西,可以帮助我们更好的理解网络的输出究竟是学习到了什么而让它做出的这个判断。
下面依然是一张导图把知识拎起来:

好了,下面就进行迭代训练过程中另一部分,这一部分是非常重要的,也是非常实用的东西,尤其是模型发生过拟合的时候,那就是正则化,下一次会整理各种正则化及其原理部分, 我们继续走着 😃