Pytorch官方英文文档:https://pytorch.org/docs/stable/torch.html?
Pytorch中文文档:https://pytorch-cn.readthedocs.io/zh/latest/
1. 模型的保存与加载
我们的建立的模型训练好了是需要保存的,以备我们后面的使用,所以究竟如何保存模型和加载模型呢? 我们下面重点来看看, 主要分为三块: 首先介绍一下序列化和反序列化,然后介绍模型保存和加载的两种方式,最后是断点的续训练技术。
1.1 序列化与反序列化
序列化就是说内存中的某一个对象保存到硬盘当中,以二进制序列的形式存储下来,这就是一个序列化的过程。 而反序列化,就是将硬盘中存储的二进制的数,反序列化到内存当中,得到一个相应的对象,这样就可以再次使用这个模型了。

序列化和反序列化的目的就是将我们的模型长久的保存。
Pytorch中序列化和反序列化的方法:
torch.save(obj, f):
obj表示对象, 也就是我们保存的数据,可以是模型,张量, dict等等,f表示输出的路径torch.load(f, map_location):
f表示文件的路径,map_location指定存放位置, CPU或者GPU, 这个参数挺重要,在使用GPU训练的时候再具体说。
1.2 模型保存与加载的两种方式
Pytorch的模型保存有两种方法, 一种是保存整个Module, 另外一种是保存模型的参数。
保存和加载整个Module: torch.save(net, path), torch.load(fpath)
保存模型参数: torch.save(net.state_dict(), path), net.load_state_dict(torch.load(path))
第一种方法比较懒,保存整个的模型架构, 比较费时占内存, 第二种方法是只保留模型上的可学习参数, 等建立一个新的网络结构,然后放上这些参数即可,所以推荐使用第二种。 下面通过代码看看具体怎么使用:
这里先建立一个网络模型:
1 | class LeNet2(nn.Module): |
下面就是保存整个模型和保存模型参数的方法:
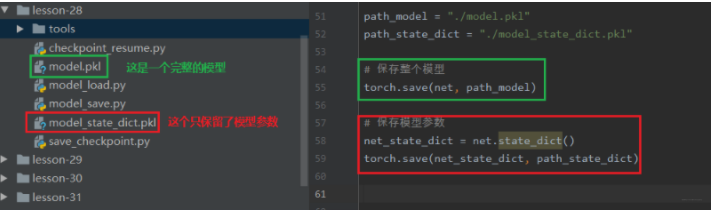
通过上面,我们已经把模型保存到硬盘里面了,那么如果要用的时候,应该怎么导入呢? 如果我们保存的是整个模型的话, 那么导入的时候就非常简单, 只需要:
1 | path_model = "./model.pkl" |
并且我们可以直接打印出整个模型的结构:
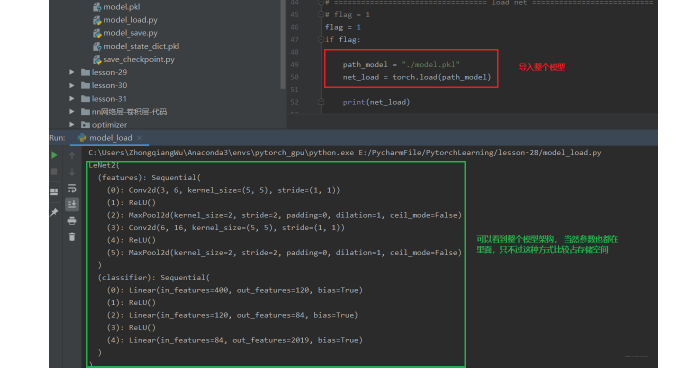
下面看看只保留模型参数的话应该怎么再次使用:
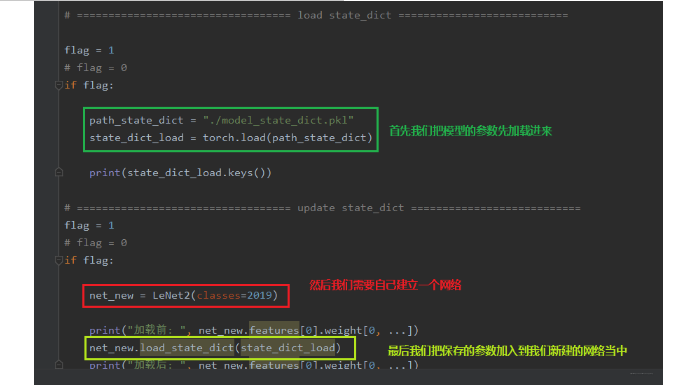
上面就是两种模型加载与保存的方式了,使用起来也是非常简单的,推荐使用第二种。
1.3 模型断点续训练
断点续训练技术就是当我们的模型训练的时间非常长,而训练到了中途出现了一些意外情况,比如断电了,当再次来电的时候,我们肯定是希望模型在中途的那个地方继续往下训练,这就需要我们在模型的训练过程中保存一些断点,这样发生意外之后,我们的模型可以从断点处继续训练而不是从头开始。 所以模型训练过程中设置checkpoint也是非常重要的。
那么就有一个问题了, 这个checkpoint里面需要保留哪些参数呢? 我们可以再次回忆模型训练的五个步骤: 数据 -> 模型 -> 损失函数 -> 优化器 -> 迭代训练。 在这五个步骤中,我们知道数据,损失函数这些是没法变得, 而在迭代训练过程中,我们模型里面的可学习参数, 优化器里的一些缓存是会变的, 所以我们需要保留这些东西。所以我们的checkpoint里面需要保存模型的数据,优化器的数据,还有迭代到了第几次。

下面通过人民币二分类的实验,模拟一个训练过程中的意外中断和恢复,看看怎么使用这个断点续训练:
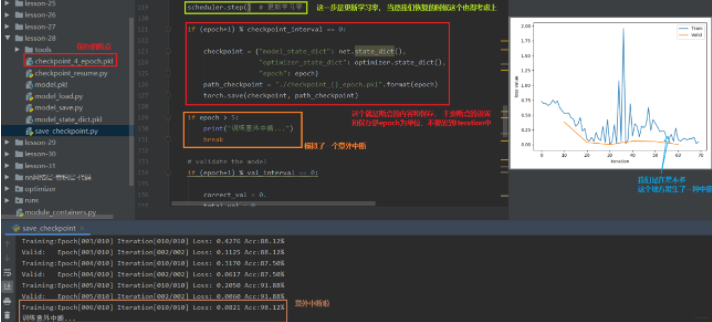
我们上面发生了一个意外中断,但是我们设置了断点并且进行保存,那么我们下面就进行恢复, 从断点处进行训练,也就是上面的第6个epoch开始,我们看看怎么恢复断点训练:
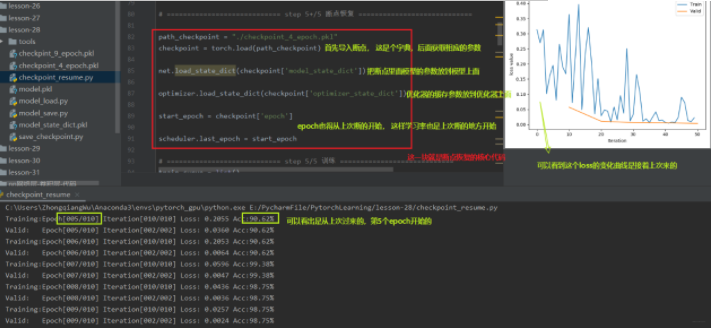
所以在模型的训练过程当中, 以一定的间隔去保存我们的模型,保存断点,在断点里面不仅要保存模型的参数,还要保存优化器的参数。这样才可以在意外中断之后恢复训练。
2. 模型的finetune
在说模型的finetune之前,得先知道一个概念,就是迁移学习。
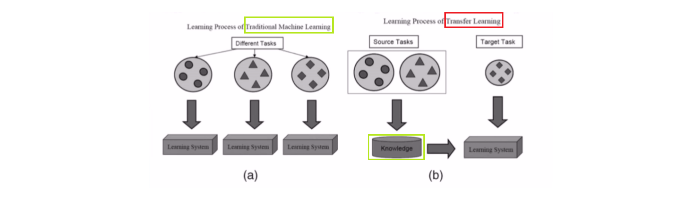
迁移学习: 机器学习分支, 研究源域的知识如何应用到目标域,将源任务中学习到的知识运用到目标任务当中,用来提升目标任务里模型的性能。
所以,当我们某个任务的数据比较少的时候,没法训练一个好的模型时, 就可以采用迁移学习的思路,把类似任务训练好的模型给迁移过来,由于这种模型已经在原来的任务上训练的差不多了,迁移到新任务上之后,只需要微调一些参数,往往就能比较好的应用于新的任务, 当然我们需要在原来模型的基础上修改输出部分,毕竟任务不同,输出可能不同。 这个技术非常实用。 但是一定要注意,类似任务上模型迁移(不要试图将一个NLP的模型迁移到CV里面去)
模型微调的步骤:
- 获取预训练模型参数(源任务当中学习到的知识)
- 加载模型(load_state_dict)将学习到的知识放到新的模型
- 修改输出层, 以适应新的任务
模型微调的训练方法:
- 固定预训练的参数(requires_grad=False; lr=0)
- Features Extractor较小学习率(params_group)
好了,下面就通过一个例子,看看如何使用模型的finetune:
下面使用训练好的ResNet-18进行二分类: 让模型分出蚂蚁和蜜蜂:

训练集120张, 验证集70张,所以我们可以看到这里的数据太少了,如果我们新建立模型进行训练预测,估计没法训练。所以看看迁移技术, 我们用训练好的ResNet-18来完成这个任务。
首先我们看看ResNet-18的结构,看看我们需要在哪里进行改动:
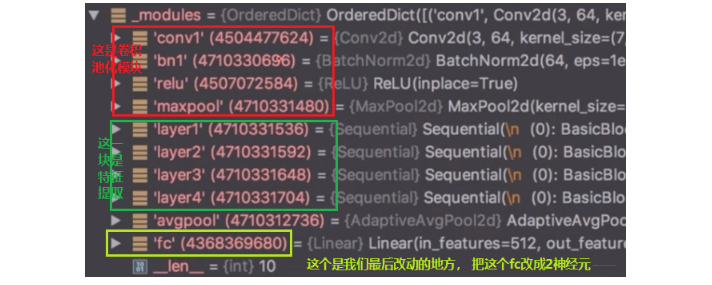
下面看看具体应该怎么使用:
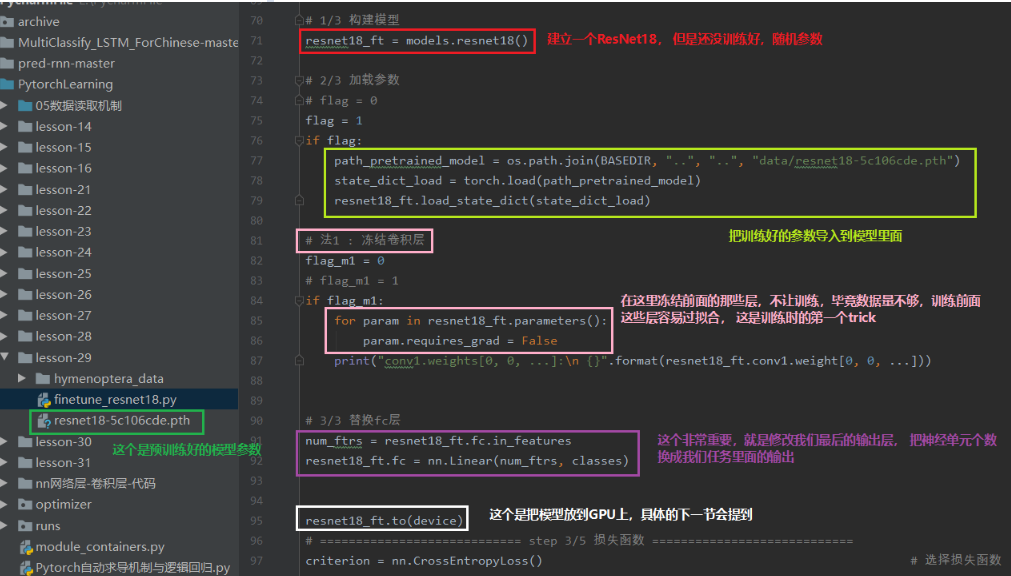
当然,训练时的trick还有第二个,就是不冻结前面的层,而是修改前面的参数学习率,因为我们的优化器里面有参数组的概念,我们可以把网络的前面和后面分成不同的参数组,使用不同的学习率进行训练,当前面的学习率为0的时候,就是和冻结前面的层一样的效果了,但是这种写法比较灵活
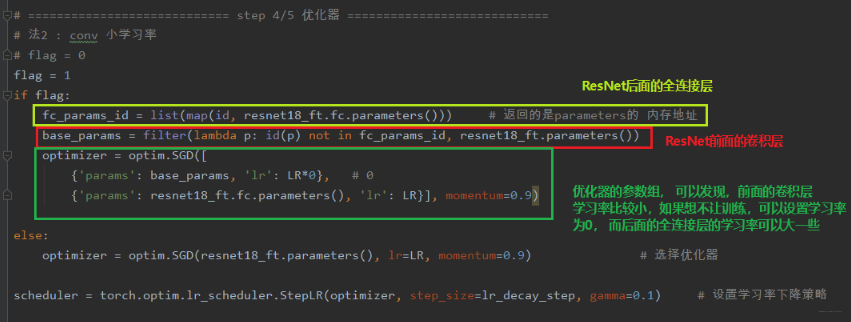
通过模型的迁移,可以发现这个任务就会完成的比较好。
3. GPU的使用
3.1 CPU VS GPU
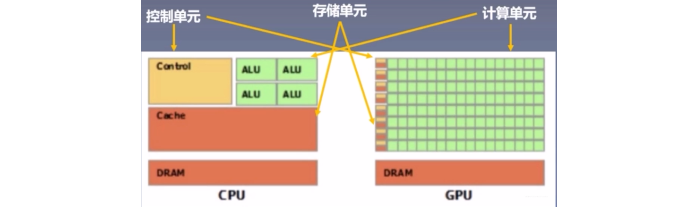
CPU(Central Processing Unit, 中央处理器): 主要包括控制器和运算器
GPU(Graphics Processing Unit, 图形处理器): 处理统一的, 无依赖的大规模数据运算
3.2 数据迁移至GPU
首先, 这个数据主要有两种: Tensor和Module
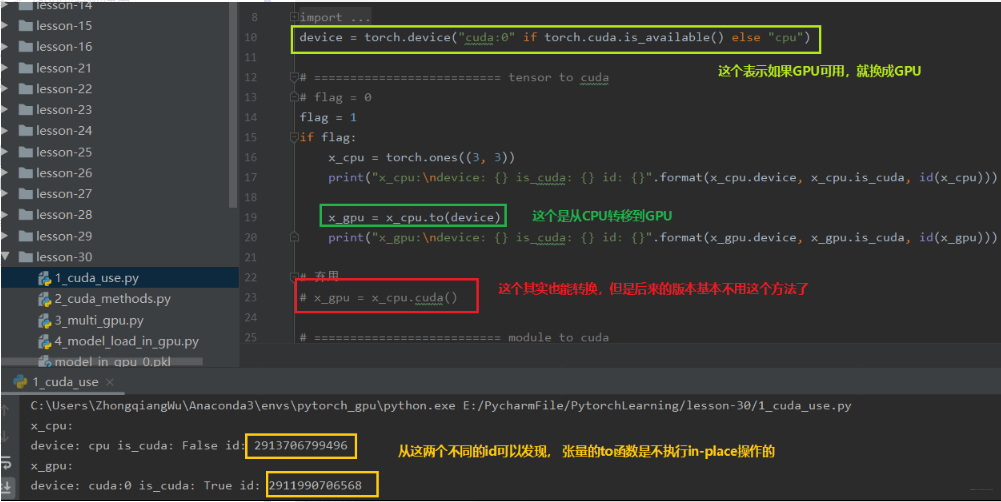
CPU -> GPU: data.to(“cpu”)
GPU -> CPU: data.to(“cuda”)
to函数: 转换数据类型/设备
1.tensor.to(args, *kwargs)
1 | x = torch.ones((3,3)) |
2.module.to(args, **kwargs)
1 | linear = nn.Linear(2,2) |
上面两个方法的区别: 张量不执行inplace, 所以上面看到需要等号重新赋值,而模型执行inplace, 所以不用等号重新赋值。下面从代码中学习上面的两个方法:
下面看一下Module的to函数:
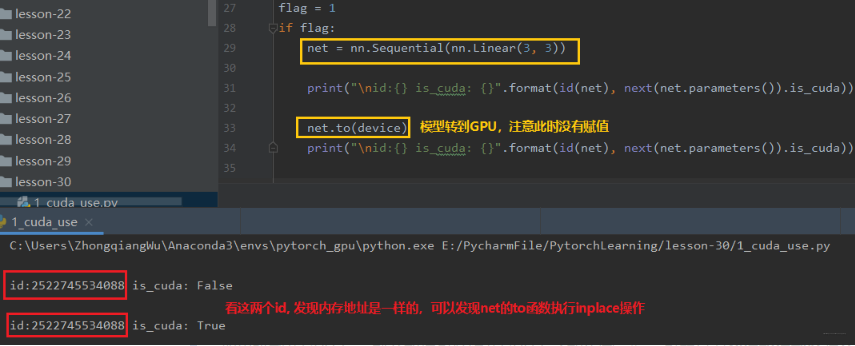
如果模型在GPU上, 那么数据也必须在GPU上才能正常运行。也就是说数据和模型必须在相同的设备上。
torch.cuda常用的方法:
torch.cuda.device_count(): 计算当前可见可用的GPU数
torch.cuda.get_device_name(): 获取GPU名称
torch.cuda.manual_seed(): 为当前GPU设置随机种子
torch.cuda.manual_seed_all(): 为所有可见可用GPU设置随机种子
torch.cuda.set_device(): 设置主GPU(默认GPU)为哪一个物理GPU(不推荐)
推荐的方式是设置系统的环境变量:os.environ.setdefault("CUDA_VISIBLE_DEVICES", "2,3") 通过这个方法合理的分配GPU,使得多个人使用的时候不冲突。 但是这里要注意一下, 这里的2,3指的是物理GPU的2,3。但是在逻辑GPU上, 这里表示的0,1。 这里看一个对应关系吧:
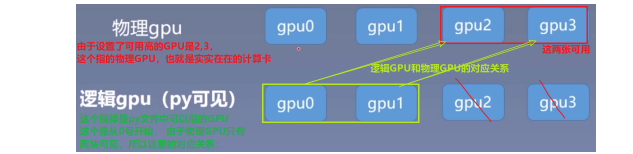
那么假设我这个地方设置的物理GPU的可见顺序是0,3,2呢? 物理GPU与逻辑GPU如何对应?
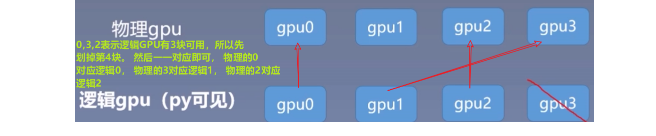
这个到底干啥用呢? 在逻辑GPU中,我们有个主GPU的概念,通常指的是GPU0。 而这个主GPU的概念,在多GPU并行运算中就有用了。
3.3 多GPU并行运算
多GPU并且运算, 简单的说就是我又很多块GPU,比如4块, 而这里面有个主GPU, 当拿到样本数据之后,比如主GPU拿到了16个样本, 那么它会经过16/4=4的运算,把数据分成4份, 自己留一份,然后把那3份分发到另外3块GPU上进行运算, 等其他的GPU运算完了之后, 主GPU再把结果收回来负责整合。 这时候看到主GPU的作用了吧。多GPU并行运算可以大大节省时间。所以, 多GPU并行运算的三步:分发 -> 并行计算 -> 收回结果整合。
Pytorch中的多GPU并行运算机制如何实现呢?
torch.nn.DataParallel: 包装模型,实现分发并行机制。

主要参数:
- module: 需要包装分发的模型
- device_ids: 可分发的gpu, 默认分发到所有的可见可用GPU, 通常这个参数不管它,而是在环境变量中管这个。
- output_device: 结果输出设备, 通常是输出到主GPU
下面从代码中看看多GPU并行怎么使用:
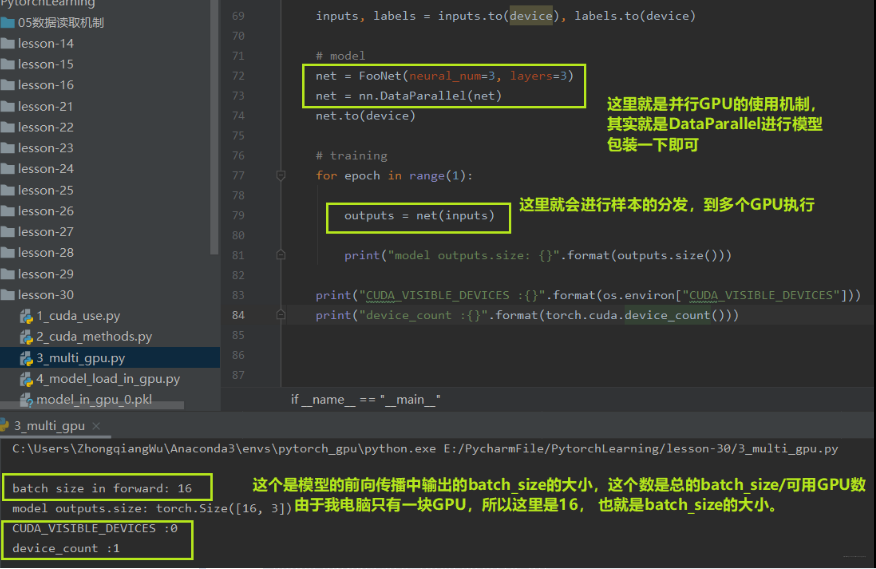
由于这里没有多GPU,所以可以看看在多GPU服务器上的一个运行结果:

下面这个代码是多GPU的时候,查看每一块GPU的缓存,并且排序作为逻辑GPU使用, 排在最前面的一般设置为我们的主GPU:
1 | def get_gpu_memory(): |
在GPU模型加载当中常见的两个问题:

这个报错是我们的模型是以cuda的形式进行保存的,也就是在GPU上训练完保存的,保存完了之后我们想在一个没有GPU的机器上使用这个模型,就会报上面的错误。 所以解决办法就是:torch.load(path_state_dict, map_location="cpu"), 这样既可以在CPU设备上加载GPU上保存的模型了。

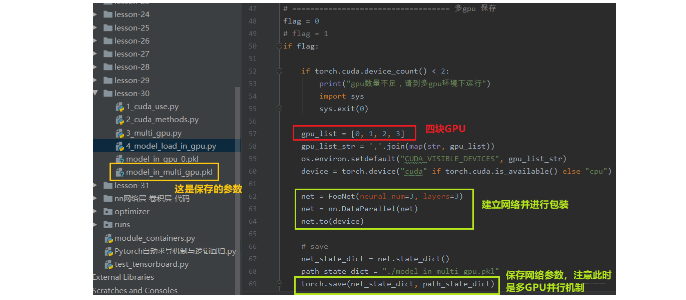
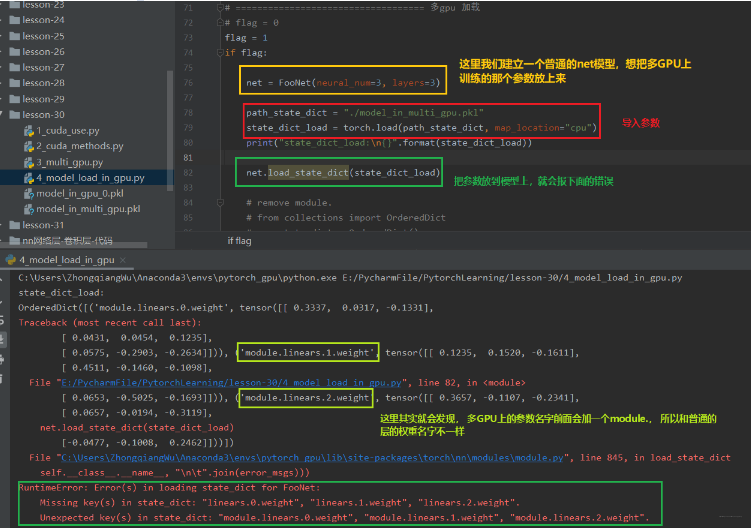
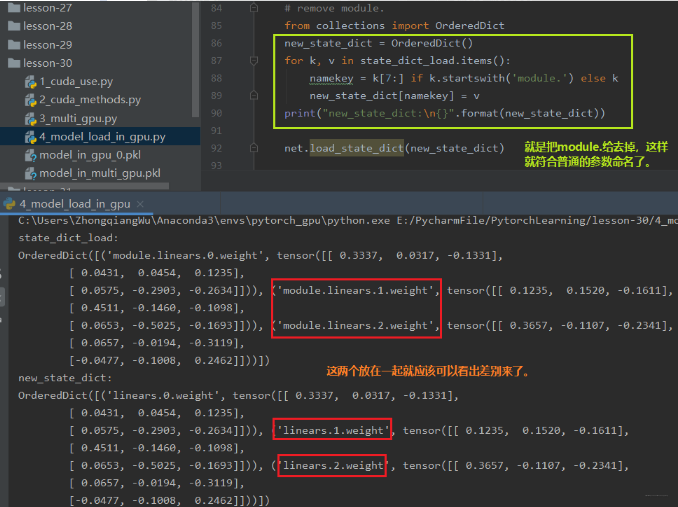
这个报错信息是出现在我们用多GPU并行运算的机制训练好了某个模型并保存,然后想再建立一个普通的模型使用保存好的这些参数,就会报这个错误。 这是因为我们在多GPU并行运算的时候,我们的模型net先进行一个并行的一个包装,这个包装使得每一层的参数名称前面会加了一个module。 这时候,如果我们想把这些参数移到我们普通的net里面去,发现找不到这种module.开头的这些参数,即匹配不上,因为我们普通的net里面的参数是没有前面的module的。这时候我们就需要重新创建一个字典,把名字改了之后再导入。
我们首先先在多GPU的环境下,建立一个网络,并且进行包装,放到多GPU环境上训练保存:
下面主要是看看加载的时候是怎么报错的:
那么怎么解决这种情况呢? 下面这几行代码就可以搞定了:
1 | from collections import OrderedDict |
下面看看效果:
4. Pytorch的常见报错
这里先给出一份Pytorch常见错误与坑的一份文档:https://shimo.im/docs/PvgHytYygPVGJ8Hv,这里面目前有一些常见的报错信息,可以查看, 也欢迎大家贡献报错信息。





5. 总结
这篇文章到这里也就结束了,也就意味着Pytorch的基础知识,基本概念也都整理完毕,首先先快速回顾一下这次学习的知识,这次学习的比较杂了,把一些零零散散的知识放到这一篇文章里面。 首先学习了模型的保存与加载问题,介绍了两种模型保存与加载的方法, 然后学习了模型的微调技术,这个在迁移学习中用处非常大,还介绍了迁移学习中常用的两个trick。 然后学习了如何使用GPU加速训练和GPU并行训练方式, 最后整理了Pytorch中常见的几种报错信息。
到这里为止,关于Pytorch的基本知识结束, 下面也对这十篇文章进行一个梳理和总结,这十篇文章的逻辑其实也非常简单,就是围绕着机器学习模型训练的五大步骤进行展开的:首先是先学习了一下Pytorch的基本知识,知道了什么是张量, 然后学习了自动求导系统,计算图机制,对Pytorch有了一个基本的了解之后,我们就开始学习Pytorch的数据读取机制,在里面知道了DataLoader和Dataset,还学习了图像预处理的模块transform。接着学习模型模块,知道了如何去搭建一个模型,一个模型是怎么去进行初始化的,还学习了容器,常用网络层的使用。再往后就是网络层的权重初始化方法和8种损失函数, 有了损失函数之后,接着就开始学习各种优化器帮助我们更新参数,还有学习率调整的各种策略。 有了数据,模型,损失,优化器,就可以迭代训练模型了, 所以在迭代训练过程中学习了Tensorboard这个非常强大的可视化工具,可以帮助我们更好的监控模型训练的效果, 这里面还顺带介绍了点高级技术hook机制。 然后学习了正则化和标准化技术,正则化可以帮助缓解模型的过拟合,这里面学习了L1,L2和Dropout的原理和使用,而标准化可以更好的解决数据尺度不平衡的问题, 这里面有BN, LN, IN, GN四种标准化方法,并对比了它们的不同及应用场景。 最后我们以一篇杂记作为收尾,杂记里面学习了模型的保存加载,模型微调,如何使用GPU以及常用的报错。 这就是这十篇文章的一个逻辑了。
下面放一张神图, 看到这个眼了吗? 这个代表着监视模型训练的整个过程:

希望这些知识能帮助你真正的入门Pytorch,在脑海中建立一个Pytorch学习框架,掌握Pytorch的内部运行机制, 学习知识,知其然,更要知其所以然,这样在以后用起来的时候才能体会更加深刻。这十篇文章用了大约半个月的时间整理总结, 学习完之后,收获很多,当然这种收获不是立马就能用Pytorch训练一个神经网络出来,立即用Pytorch搞定一个项目,而是Pytorch在我脑海中不是那么的陌生了,慢慢的变得熟悉起来, 从DataLoader和Dataset的运行机制,差不多对Pytorch的数据读取有了一个了解,从各种模型搭建的过程,权重初始化,损失函数有哪些怎么用,优化器的运行原理渐渐的熟悉了一个模型应该怎么去训练。这样过来一遍之后,真的能深入了解每一个细节,也知道了模型训练中出现的一些问题,比如权重初始化不适当就容易出现梯度消失和爆炸,在代码中的结果就是容易nan。再比如损失不下降反而上升, 这有可能是学习率过大导致的, 还有各种技术及原理,真的是收获颇多,也希望你也有所收获吧。
这十篇文章虽然里面图片很多,还有各种调试, 整体看起来还是挺乱的, 相信大家看起来也心烦意乱,能坚持看完的并不会太多,但依然希望能有所帮助,即使没法看完一遍,等遇到问题了,当做查阅的手册也可以,反正我是这样的,这十篇文章写得过程中没有注意各种排版啥的,依然是以详细为主,所以为了说明原理,我用了各种调试,各种图片,这样回来看的时候就能很容易记起来,毕竟只看一遍肯定是记不住的,我后期依然会回来查阅观看。
踏踏实实的搞定这十篇文章,相信对Pytorch真正入门了,那么接下来就可以去用Pytorch做一些项目了,想象一下,当你无障碍读懂大佬的Pytorch代码,当你无障碍用Pytorch复现论文,无障碍用Pytorch实现项目, 理直气壮对面试官说熟悉Pytorch,那是多么的爽, 哈哈, 爽一下即可, 先别睡,Pytorch的路依然是任重而道远,因为这些都得去练,如果想无障碍手写神经网络, 就得照着代码反复练,反复看,重点是练习手写神经网络的感觉,然后多做项目,多写代码,依然是那句话无它,唯手熟尔 😉