1. 写在前面
今天完成了生成对抗网络GAN的学习,从基本原理到数学公式,从对GAN的一知半解到了解了全貌,感觉还是收获颇多,所以趁着学习的GAN在脑海中逗留的一刻,赶紧进行总结和整理。 这样能使学习到的知识逗留的更长久一些吧。
对世界理解的最高境界就是能创造世界,作为生成模型的两座大山之一,生成式对抗网络(Generative Adversial Networks)自从问世以来就颇受瞩目。相对于变分自编码器,生成式对抗网络也可以学习图像的潜在空间表征,它可以生成与真实图像再统计上几乎无法区分的合成图像,并且现在应用之处很多,图像生成,视频预测,图片超精度转换,图图变换等都会发现GAN的身影。所以了解GAN的工作原理是非常有必要的,而今天,就一点点的剖析一下这个伟大地思想 — 生成对抗
今天的这篇文章,我想从白话和数学推导两方面进行GAN工作原理的描述,因为GAN毕竟作为生成模型的大山,肯定少不了数学公式的陪伴,但是如果单纯的讲数学公式,那么这篇文章就变得没意思了,所以数学公式固然重要,因为是理论的核心,但数学公式之前,白话一下背后的思想也挺重要的,因为这样,后面的数学公式理解才会理所当然。
所以这篇文章的逻辑是先从一个警察与系小偷的故事出发,亲身感受一下我们身边的GAN,然后回到深度学习的宏观层面,大体描述一下GAN是如何运作的,最后理解GAN的内部工作原理和数学公式。 这篇文章花了些时间整理,所以挺长的,如果能坚持读下来,我相信在学习GAN的路上,肯定能给予一些加速度,加油!
分享大纲:
- GAN? 我们还是从警察小偷的故事讲起吧
- GAN工作原理的宏观层面
- GAN工作原理的数学层面
- 关于GAN的一些小细节
OK, let’s go!
2. GAN? 我们还是从警察小偷的故事讲起吧
谈起生成对抗或者GAN,你可能头一次听说,但是你知道吗? GAN的学习场景其实就在我们身边,如果不信的话,我先讲个故事(哈哈,听故事了):
说某个城市啊,治安很混乱,所以很快,这个城市里就出现了无数的小偷,在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。 但这样下去,这个城市就人心惶惶,人民没法安居乐业了。 这哪能行? 所以上面派来了高官开始整治治安,开展了一场打击犯罪的运动。
警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了,但是在这个过程中,还有一批比较强的小偷成了漏网之鱼,警察目前的这个水平已经抓不到这些人了,所以警察们开始训练自己的破案技术,去抓住那些越来越狡猾的小偷, 由于这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯。
而这时候,小偷的日子就不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。为了避免被捕,小偷们努力表现得不那么「可疑」,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。
随着警察和小偷之间的这种「交流」与「切磋」,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了「火眼金睛」,一旦发现可疑人员,就能马上发现并及时控制——最终,我们同时得到了最强的小偷和最强的警察。
这就是警察和小偷的故事,故事讲完了,你能有点感悟吗? 警察和小偷彼此互相对抗,然后各自学习成长,大家的水平都越来越高。
其实这个就类似于GAN的学习过程,只不过警察和小偷换成了判别器和生成器而已,所以这个过程有点感觉了吧,是不是在我们身边也会发现GAN的身影? 那么我们就具体来看看GAN吧。
3. GAN工作原理的宏观层面
GAN 的核心思想就在于两个部分:一个伪造者网络(小偷)和一个鉴定网络(警察)。二者互相对抗,共同演进,在此过程大家的水平都越来越高,伪造者网络生成的图像就足以达到以假乱真的水平(小偷伪装的和普通人很像了)。基于这个思想,我们来看一下 GAN 的原理与细节(还是先说理论,看不懂不要紧,后面会有一个例子做辅助,两者结合,肯定就懂GAN工作过程了。)
GAN 的基本原理就在于两个网络:G(Generator)和D(Discriminator),分别是生成器和判别器。
生成器网络以一个随机向量作为输入,并将其解码生成为一张图像,而判别器一张真实或者合成的图像作为输入,并预测该图像是来自于真实数据还是合成的图像。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。在理想状态下,博弈的结果就是G可以生成足以以假乱真的图片G(z),而此时的 D 难以判定生成的图像到底是真是假,最后得到D(G(z)) = 0.5的结果。这块的理解跟博弈论中零和博弈非常类似,可以说 GAN 借鉴了博弈论中相关的思想和方法。
好吧,大理论总是少不了一些抽象,理解起来也不简单,那么我直接举个例子吧,来看看GAN到底在干啥吧:
假设我想让机器生成1000张手写数字的图片(注意这里不是识别手写数字是几,而是生成手写数字的图片),并且尽可能的和原来的手写数字图片一样,这时候,我们应该怎么去训练机器呢?
准备工作
首先, 我们要准备1000张真实的手写数字图片,也就是从手写数字数据集中选出1000张来。然后,我要搭建一个生成器(就理解成一个神经网络就可以),这个生成器的任务就是我输入一个向量,你输出给我一张图片即可。 再搭建一个判别器(也是一个神经网络),这个判别器的任务就是我给你一张我生成器的图片和一张真实的图片,你给我做一个二分类问题就可以了。
然后我们开始训练两个网络(这是重点,看看究竟怎么训练让它们变强的)
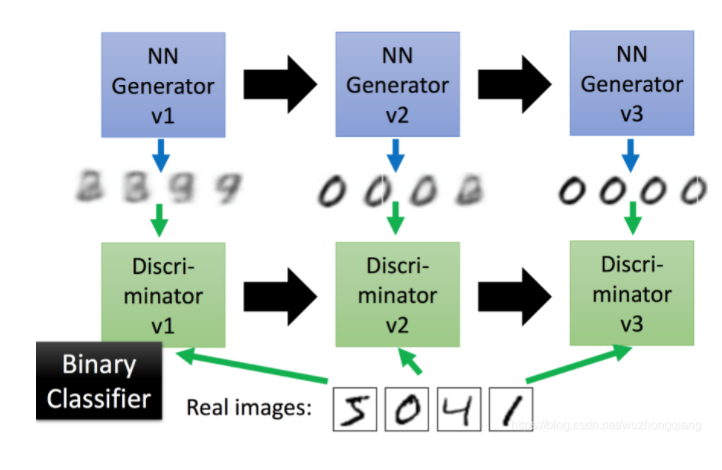
首先,我先让生成器V1随机生成1000张图片(不管图片内容,随机生成即可)并给这些图片打上0标签,然后我把1000张真实的图片打上1标签和上面1000张混合组成一个训练集,去训练我的判别器V1,由于这两种图片相差很大,判别器V1很快就能够看出来哪些是真正的手写数字图片,哪些生成器V1伪造的假图片。
然后,我们得训练生成器V1,让它提高一下伪造图片的技能(这样一下子就露馅了可不好),怎么做呢? 这时候我们冻结住判别器V1的参数不让他训练,只训练生成器V1的参数(先理解成生成器和判别器是可以搭建到一块的),训练的方式就是不断的调整生成器V1的参数,让判别器V1生成1(目前不是手写数字识别生成的是0),这样训练完了之后,就说明生成器V1生成的图片判别器V1已经判别成真实的手写数字图片了,这样生成器V1的伪造水平提高,我们赋予它一个新的名字生成器V2
接下来,我们得提高判别器V1的判别水平了,因为它已经无法判别出生成器V2生成的图片和真实的图片的区别。这时候,我们冻结住生成器V2的参数不进行训练,只训练判别器V1的参数,方式就是生成器V2生成的图片为0, 真实图片为1,混合作为训练集让判别器V1做二分类的问题进行参数调整,这样,当准确率很高的时候,判别器V1的判别能力提高了,能够区分出生成器V2生成的图片和真实图片了。 我们把这个判别器赋予新的名字:判别器V2。
这样我们就完成了一轮生成器和判别器的训练,两者都升级到了V2水平,接下来和上面的思想一样,冻结判别器V2的参数,以判别器V2输出1为目标去调生成器V2的参数,直到这个目标达成,就说明生成器V2的伪造水平进一步提高,判别器V2不行了,接下来,让生成器V3生成图片标0,真实图片标1再次训练判别器V2,这样就完成了两者的又一轮升级。
重复上面的步骤,直到生成器能够达到以假乱真的地步。
这样我们的目标就达成了,当缺少手写数字训练样本的时候,就可以利用这里锻炼的生成器进行图片生成供我们使用。当然换成别的图片一个道理。
通过这个例子,然后再看理论部分是不是清晰了一些了呢? 并且这个例子中,也基本上说明了GAN训练的过程,所以GAN的工作原理也不是那么复杂吧,当然这个生成手写数字的项目我后面会用Keras完成,放到我的Keras的感知境里面去,有兴趣的也可以到时候去看,哈哈,好像说偏了哈,现在还有一个问题,就是为什么GAN可以这样工作? 这些当然是有数学作为支撑的,包括损失函数应该怎么去定义等,所以下面我们就来从内部的数学公式上去理解GAN的工作原理了,不是有句话吗?学习知识,知其然也要知其所以然,当然前方高能,会有一大波数学公式的袭击,准备好!
4. GAN工作原理的数学层面
我们从上面已经大致上知道了GAN网络的训练过程,那么下面我们从数学的角度而这个伟大的想法找一个理论的支撑,看看为什么可以这样解决问题?
这是一个很久远的故事,我们得从极大似然开始,来看看什么是极大似然:

解释一下,这个L最大,也就是我们模型产生的这样的数据的概率分布最大,由于这组数据是从真实图片中得到的,所以模型产生的数据概率分布最大就意味着我们的模型能够产生和真实图片差不多的图片了, 你从真实世界给我一些样本,我们模型以最大概率的方式去近似得到这些样本的原始分布,这就是极大似然干的事情。我们需要找到一组合适的参数,去保证这个最大的可能性发生。

好了,我们把上面的极大似然的最后一步拿下来,并进行化简,就会得到下面的那部分:

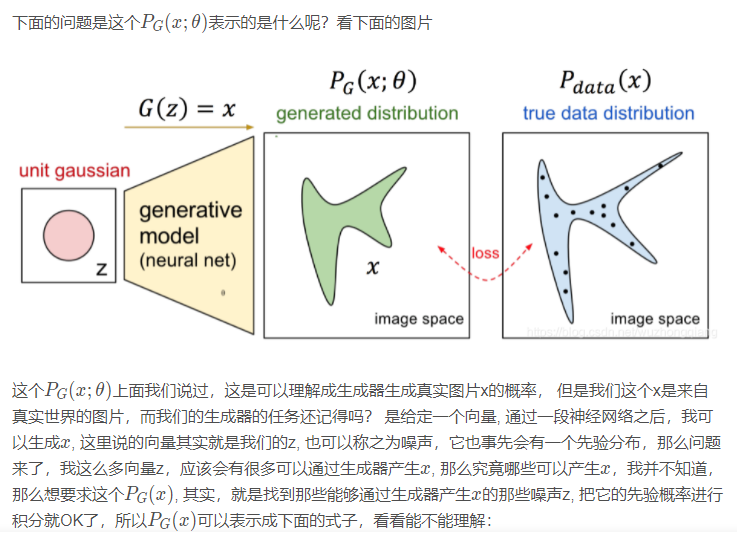

但这是理论上能够写的一个公式,真实情况我们是求不出来的。因为真实世界的向量z很难穷尽,我们怎么知道哪些z可以通过生成器生成x? 并且引入了神经网络之后,我们更不知道哪些具体的z会通过神经网络取到x了,所以这个概率直接求是求不出来的。
So, 那怎么办? 无解了吗? 哈哈,上面做了那么多铺垫,终于进入了我们的正题, 我们看看GAN是如何解决这个问题的:
我们都知道,GAN里面有Generator G和Discriminator D

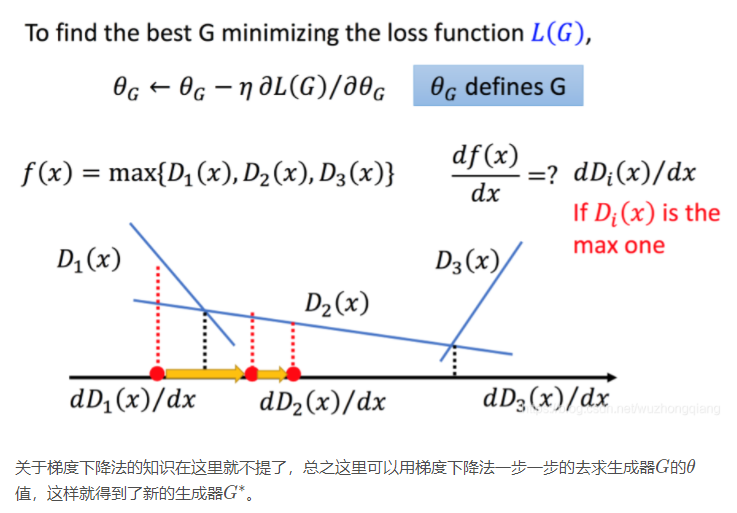
这个地方就有点难理解了,先从这个公式的宏观角度尝试理解一下:






其实这个地方我觉得应该是约等于,因为忽略掉了两个概率之后乘以前面的常数,但不管怎么说,前面那部分是常数。

这样,一步更新完成,后面就重复这个操作就行啦。最后,我们看看梳理一下最终的过程:

到这里,我们基本上就把GAN的数学部分给搞定了,不知道你懂了没? 如果没懂得话也没有关系, 但是你得明白,GAN的这个过程是有上面这个背后的理论在支撑的,嘿嘿,就是那句话伟大的思想后面都是赤果果的数学了
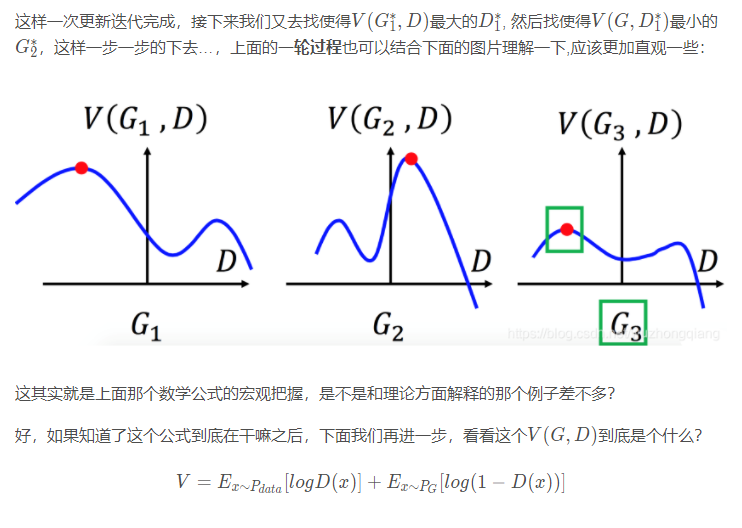
下面再看一个神奇的地方,也算是细节吧, 但是看这个地方之前,我们先把V(G,D)的公式拿过来:



哈哈,有时候数学就是这么的神奇? 现在也知道为啥让GAN的判别器在做二分类问题了吧。
好了,GAN的数学部分,到这就结束了。如果你看到这,应该会对GAN的细节部分理解的更加清晰了吧, 下面就轻松了,简单说一点GAN的小细节
5. GAN的一点小细节
这篇文章,主要是上面的GAN的白话理论和数学公式推导,下面这部分可以做一个拓展或者简单了解,不是在这篇文章的重点,所以我直接放图。
5.1 实际训练方面
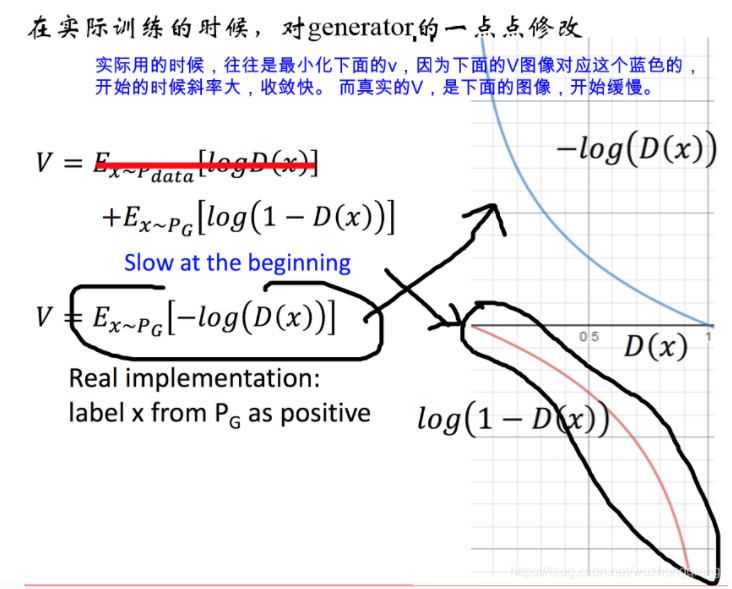
5.2 对GAN的评估方面
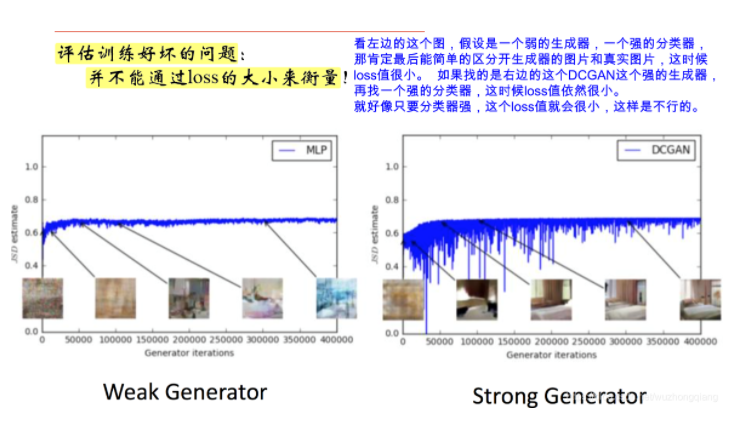
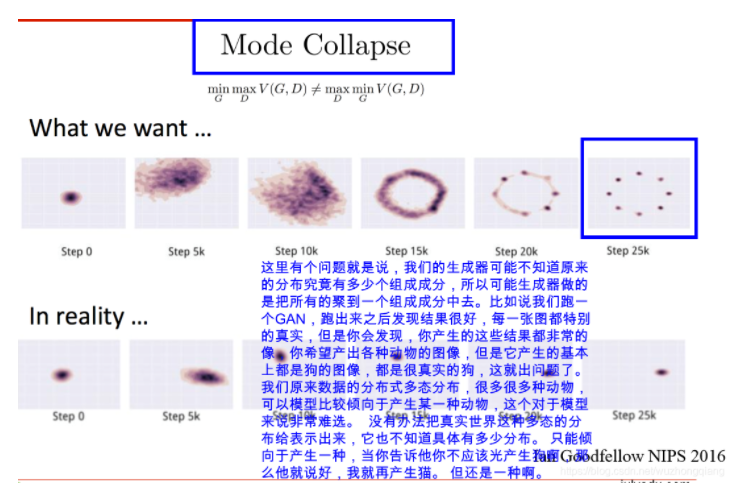
5.3 GAN存在的问题介绍
这个也是Ian Goodfellow的论文Generative Adversarial Networks中提到的,如果真实图片服从一个多态分布的话,生成器不知道,可能只会生成其中的某一类图片,即使很逼真。
下面在看优化上的一些问题:
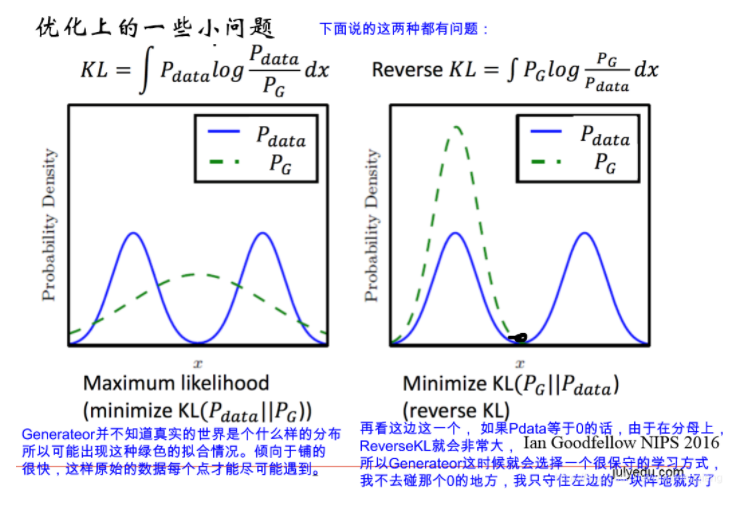
所以,针对GAN的不稳定性,后面提出了各种各样的GAN

6. 总结
终于到了结尾了,这就是我目前了解的GAN的工作原理了,简单再梳理一下这篇文章的内容,首先,讲了一个警察和小偷的故事,先感受一下GAN离我们并不是很遥远, 然后,介绍了GAN的宏观层面的工作过程, 举了一个生成手写数字的例子来进行了描述(后面也会用Keras搭建DCGAN来玩这个小项目 😉), 然后我们进入了GAN的数学公式层面,从数学的角度又解释了GAN的工作原理,最后,简单的说了几个GAN的细节问题及改进网络。
好了,GAN的理论部分就整理到这里吧,后面有Keras感知境的用Keras搭建DCGAN来生成手写数字图片或者是其他图片的小项目,从实战中,带你用Keras搭建一个生成器和判别器都是深度卷积的神经网络, 从代码的角度可能会对GAN有新的认识,哈哈,先搞懂GAN的原理吧。
参考: