1. 写在前面
最近用深度学习做一些时间序列预测的实验, 用到了一些循环神经网络的知识, 而当初学这块的时候,只是停留在了表面,并没有深入的学习和研究,只知道大致的原理, 并不知道具体的细节,所以导致现在复现一些经典的神经网络会有困难, 所以这次借着这个机会又把RNN, GRU, LSTM以及Attention的一些东西复习了一遍,真的是每一遍学习都会有新的收获,之前学习过也没有整理, 所以这次也借着这个机会把这一块的基础内容进行一个整理和总结, 顺便了解一下这些结构底层的逻辑。
当然,这次的整理是查缺补漏, 类似于知识的串联, 一些很基础的内容可能不会涉及到, 这一部分由于篇幅很长,所以打算用三篇基础文章来整理, 分别是重温循环神经网络RNN, 重温LSTM和GRU和重温Seq2Seq与Attention机制。 前面两篇已经搞定, 今天是第三篇, 尝试整理Seq2Seq和Attention机制,这次依然是基于前面两篇的知识, 这里的逻辑就是Seq2Seq是一种编码器-解码器的网络结构, 而这里的编码器和解码器就可以是RNN或者是它的变体, 所以如果想弄明白Seq2Seq的工作原理, 就需要先知道RNN或者变体的工作原理。 而Attention是在Seq2Seq的基础上又做了一些改进, 依然是这个结构,只不过在计算的时候加了一些新的东西,使得神经网络在计算的时候有了注意力或者说聚焦的地方,使得网络的工作更高效。
以,这篇文章首先会从Seq2Seq这个结构出发, 说一下Seq2Seq是什么样子的, 为什么要有这个结构, 然后说一下它的计算原理, 最后分析一下单纯的Seq2Seq有什么问题,从而能够引出为什么需要加入Attention, Attention的计算过程如何运用到这个结构中去, 在最后我们可以通过代码的方式看一下如何实现一个带有Attention的Seq2Seq,这样有利于更好的理解细节。 这篇文章的内容有些多, 主要聚焦Attention,这里的Attention整理不像Attention is all you need这篇论文中的那样, 这次重在细节。
大纲如下:
- Seq2Seq初识
- Seq2Seq的工作原理和计算细节
- Seq2Seq存在的问题及Attention初识
- Attention的计算细节
- 带有Attention机制的Seq2Seq的简单代码实现
- 总结
Ok, let’s go!
2. Seq2Seq初识
我们知道, RNN是非常擅长处理序列数据的, 但是RNN能够应对的序列数据场景很有限, 你要是给个句子: The cat, which …, was tired! , 假设我们让RNN预测一句话中的某个词这种的, RNN能够轻松应对。
But, 如果是比较复杂的任务, 不是让RNN预测词语, 而是让它做机器翻译, 我输入一个句子,让它输出一个句子了, 这时候RNN就表现的不是那么出色了, 为啥呢? 因为这种情况, 我们的输入和输出都是不定长的序列,比如将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长, 输出就不确定了。 这时候单独用一个RNN网络就不是那么好了, 所以就想到了能不能用两个RNN网络把输入的处理和输出的处理分开进行呢, 就诞生了Seq2Seq模型。
Seq2Seq模型是输出的长度不确定时采用的模型, 现在应用场景也非常普遍, 在机器翻译, 人机对话等都会看到这种模型的身影。 这个模型长这个样子:
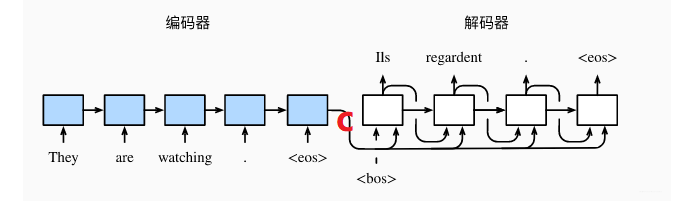
这个就是Seq2Seq的一个结构, 在这里我们会看到, 这种模型使用了两个RNN网络, 左边那个叫做编码器, 负责的是将我们的输入进行编码, 右边的叫做解码器, 负责的是基于左边的编码进行生成我们想要的结果。 这样,就能把输入和输出分开处理, 解决了输入和输出都不定长的问题。 是不是也挺简单的? 其实就是两个RNN而已, 哈哈。
当然, 外表是挺简单的, 但是却有着丰富的内涵, 所以下面就看一看具体的细节, 编码器和解码器到底在干啥。
3. Seq2Seq的工作原理及计算细节
3.1 Seq2Seq的宏观工作原理
在具体介绍编码器和解码器之前, 我们先来宏观的看一下编码器和解码器的工作过程, 这里再放一张和上面不一样的图(不一样的图可以帮助我们更好的理解原理,而不是局限于图本身),这个图出自2014年的一篇经典论文Learning Phrase Representations using RNN Encoder–Decoderfor Statistical Machine Translation
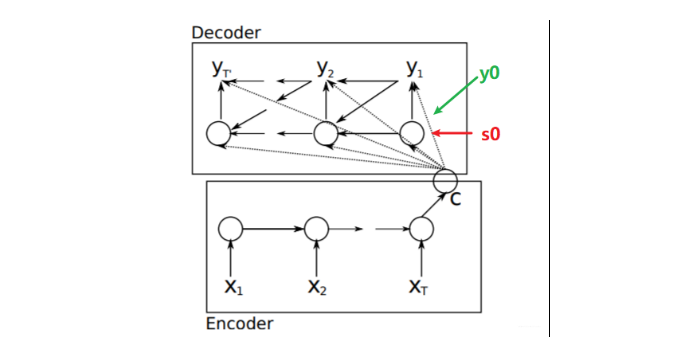

有了这个综合输入句子信息的上下文向量C, 然后把这个作为解码器的输入, 去进行句子的翻译, 当然句子翻译的时候, 可能还需要前面时间步的预测的结果, 所以解码器工作是这样: 在第一个时间步, 会接收一个初始化的y0, 这个表示句子的起始, 一般可以初始化为<bos>, 标志着我句子要开始翻译, 还会接收一个初始化的s0, 这个表示的隐藏状态(之所以用s是为了和编码器那里的隐藏状态h区分开), 然后就是这个输入C, 基于这三个就可以计算出第一个时间步隐藏状态s1和输出y1, 也就是第一个单词。 然后来到第二个时间步,接收第一个时间步的输出y1, 接收第一个时间步的隐藏状态s1和C三个计算出s2和y2, 这样依次进行下去, 直到遇到终止符(一般用<Eos>表示), 也就是说当神经网络预测的概率最大的单词是EOS的时候, 神经网络就终止输出了。
所以, 这个就是Seq2Seq的宏观工作过程, 编码器是接收一个输入, 然后输出一个综合输入信息的上下文向量。 解码器部分接收这个上下文向量和前面时间步的预测值得到后面时间步的预测值,也是我们想要的结果。
那么具体细节呢? 我们下面就分开看看吧:
3.2 Seq2Seq的计算细节
3.2.1 编码器
编码器的作用是把一个不定长的输入序列变换成一个定长的上下文变量C ,并在该背景变量中编码输入序列信息。编码器可以使用循环神经网络。
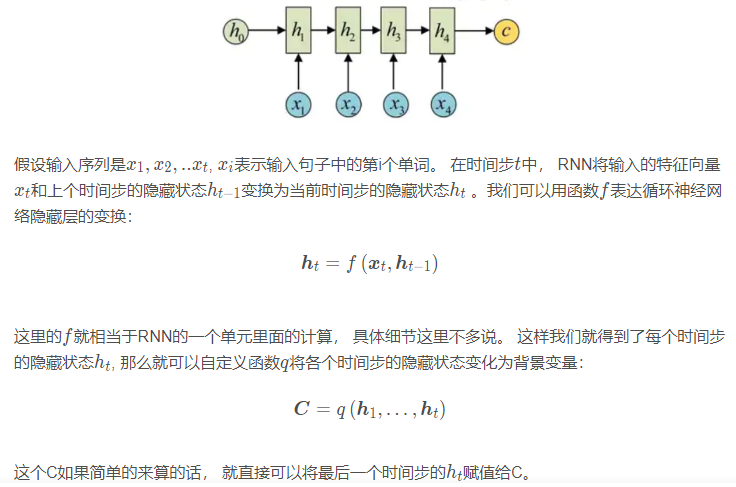
上面就是编码器的计算细节, 这里用了一个单向的RNN, 每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。 这个在下面的代码实例中会看到这种方式。
3.2.2 解码器
解码器负责根据语义向量生成指定的序列,
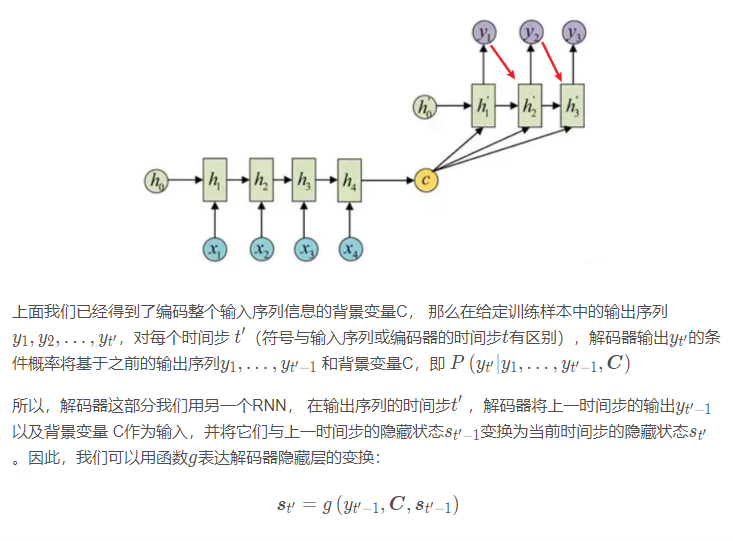

这样就相当于我们要最小化上面的这个函数。 这样就可以选择相应的损失函数(比如交叉熵)去训练模型了。
这就是Seq2Seq的计算细节了, 下面来个图再看一遍这个过程:
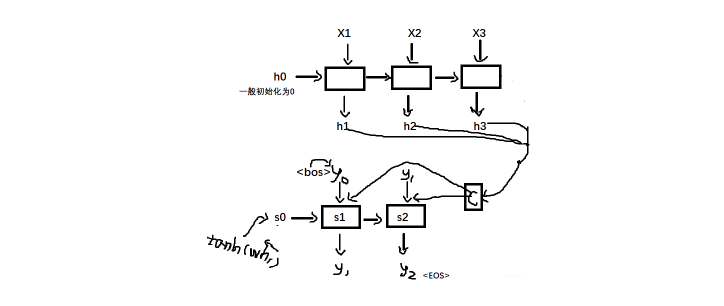
好吧, 这图有点魔性, 但是应该能说明上面的过程了, 有个细节就是上面的tanh那个地方, 论文里面的s0初识化成了这个, 原因是想翻译第一个词的时候更多的考虑一下输入的第一个词。 上面那个箭头表示是先逆向运算得到的h1。
这就是Seq2Seq了, 应该挺好理解的吧, 那么这个结构有没有问题呢?
4. Seq2Seq存在的问题及Attention初识
上面的Seq2Seq其实存在一些问题的, 其中最显眼的就是那个C, 上面的Seq2Seq是吧所有的输入信息组合到了一个C上去,然后所有的输出都是基于同样的C去做翻译。
那么我们可以试想一下, 在机器翻译的时候, 如果序列很长, 我翻译第一个单词相当于考虑了所有的输入信息, 这显然不符合我们翻译的习惯(我们人翻译一句话的时候也不是考虑所有的句子再进行翻译吧), 我们做翻译的时候,通常是先将长的句子分段, 翻译的时候, 只聚焦于对某一小段进行翻译, 这样会比较准确。 比如翻译“I love China, because it 巴拉巴拉”, 那么我翻译第一个词的时候, 是不是更关注于” love China”, 然后翻译出“我”, 而不需要关注后面那一长串, 同理翻译love的时候, 更关注I和China多一些?
这其实就是在说, 我们在做翻译的时候,解码器的每一时间步对输入序列中不同时间步的表征或编码信息分配的注意力应该是不同的。 这也是注意力机制的由来。那么如何做到这一点呢?
我们就可以在每个时间步得到不同的上下文向量C, 而这个C的由来, 是对编码器隐藏层输出的一个加权平均, 这个权重,就代表着我对于每个输入所放上去的注意力大小。 这样, 我们翻译的时候, 就可以在不同的时刻只注重某一部分的区域。
所以, 加入注意力机制的Seq2Seq模型是下面的一个感觉:
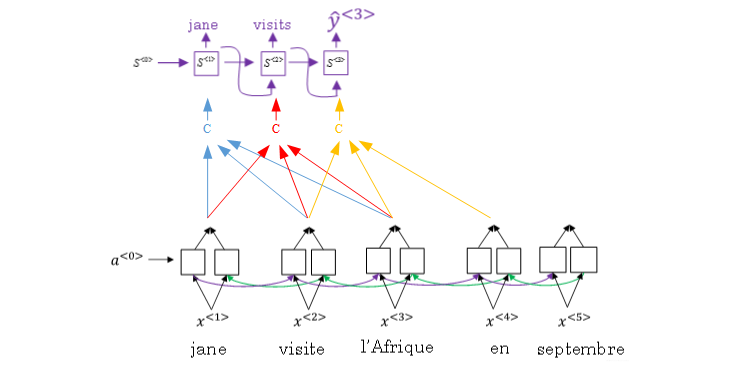
这里就会看到, 在每个时刻, 都会有一个单独的上下文向量C, 这个C只聚焦于部分输入, 且可以对关注的这部分输入加入不同的权重表示关注度(应该放多少注意力在这个输入上)
那么, 上面这个过程就是这样子的了: 我输入下面的一段话进行翻译, 当第一个时间步的时候, 我想输出jane, 也就是翻译输入的第一个单词, 这时候, 编码器部分的工作是只用到了输入的前三个单词, 进入了RNN, 然后计算出隐藏状态h, 然后会给输入的这三个h进行一个加权求和得到这一个时间步的上下文向量C, 这里的C就是只综合了”jane visite I’Afrique” 这三个单词的信息,并且会把注意力重点放在第一个单词上, 也就是jane的权重会大一些。 这样在解码的时候, 就会更容易的翻译出第一个单词jane。 解码器部分的工作细节和Seq2Seq的基本上一样。 这就是加入Attention的Seq2Seq的宏观工作过程。
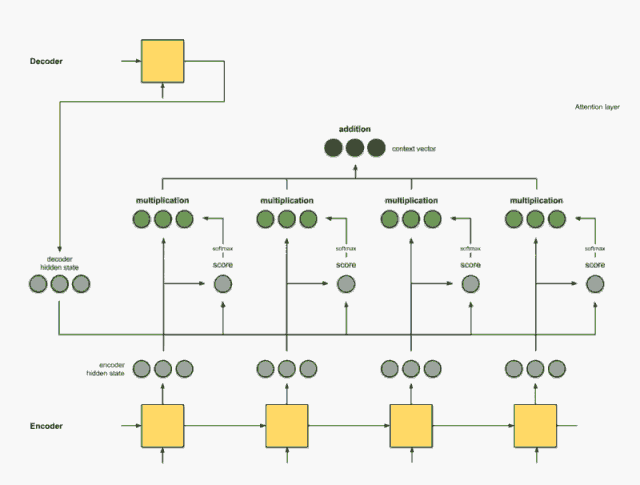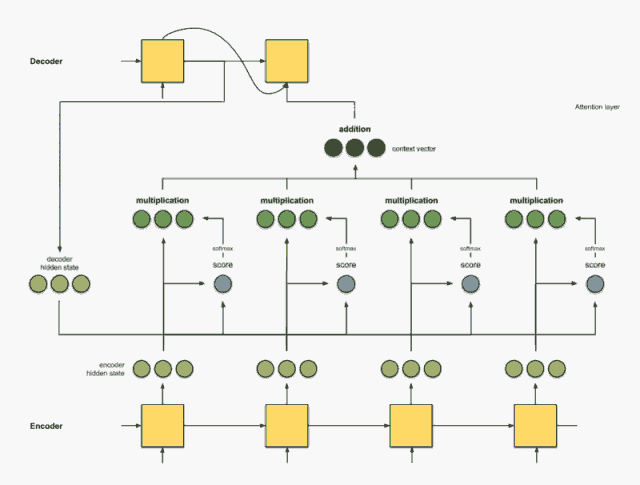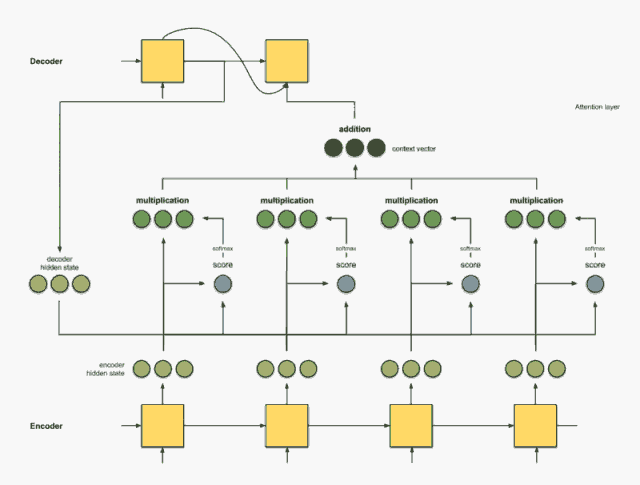
如果还没明白, 我找到了一个动画解释上面的宏观过程, 具体链接会在下面给出, 把宏观过程简单总结, 其实就是六步: 输入通过编码器的RNN得到隐藏状态信息、 给每一个隐藏状态信息打分、 把分数进行softmax获得每个隐藏状态的权重、 把权重与隐藏状态相乘、 把前面的相乘结果相加得到上下文向量C、把C放入到解码器就可以进行翻译。 下面采用动画的方式看一下这六步:
输入通过编码器的RNN得到隐藏状态信息
我们首先准备第一个解码器的隐藏状态(红色)和所有可用的编码器隐藏状态(绿色)。在下面的示例中,有4个编码器隐藏状态和当前解码器隐藏状态。
给每一个隐藏状态信息打分
这个后面在计算的细节会比较详细, 说白了,就是根据解码器前一状态的隐藏信息和当前输入隐藏状态进行一个计算得到每个输入隐藏状态的分数。 这个分数就代表着当前时刻的这些输入对于当前的翻译提供信息的多少(或者说对于当前时间步的翻译的关键程度), 最简单的打分方式就是每个输入和解码器前一隐藏状态进行内积运算获得。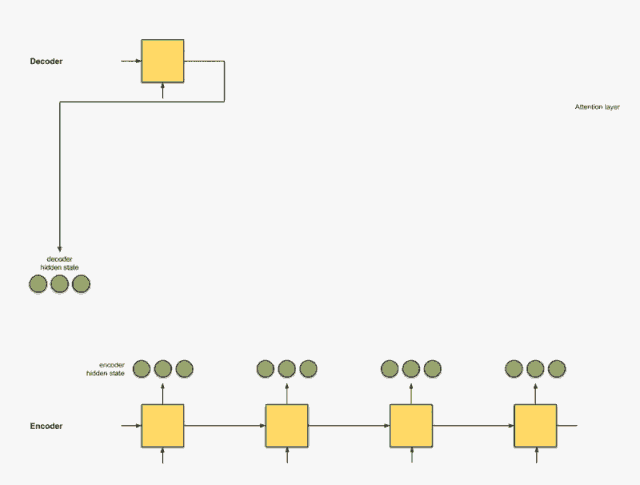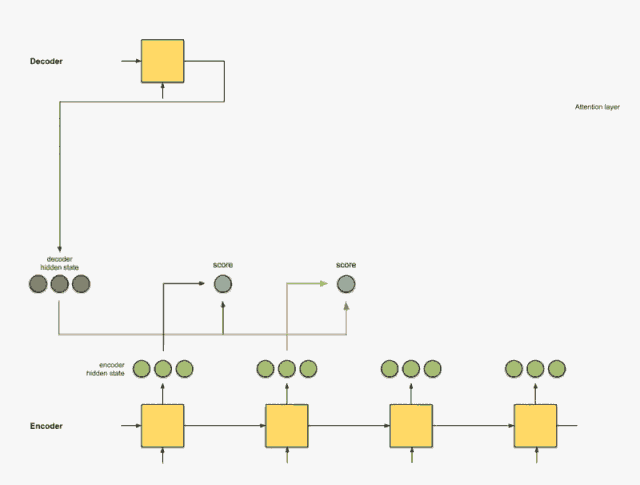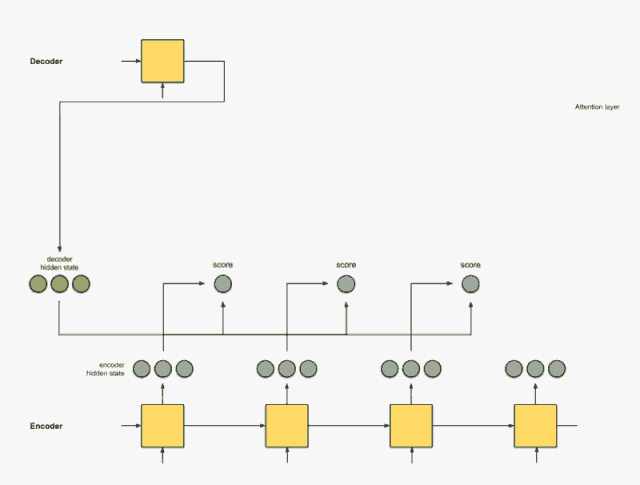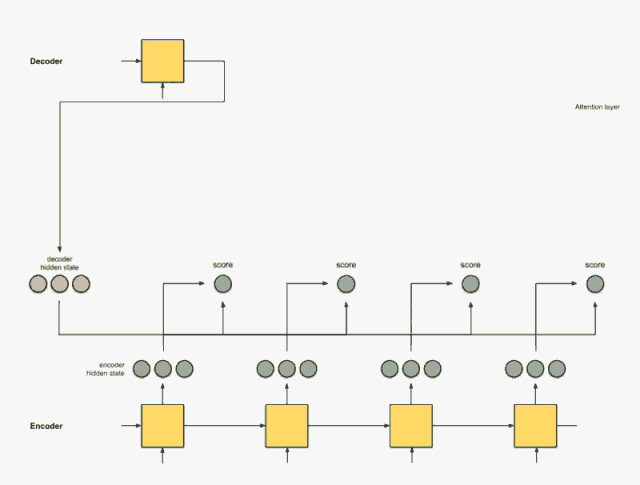

把分数进行softmax获得每个隐藏状态的权重
第三步的softmax无非就是把这些想办法让这些分数的加和为1, 这样就得出了每个隐藏状态的权重,并且权重加和为1。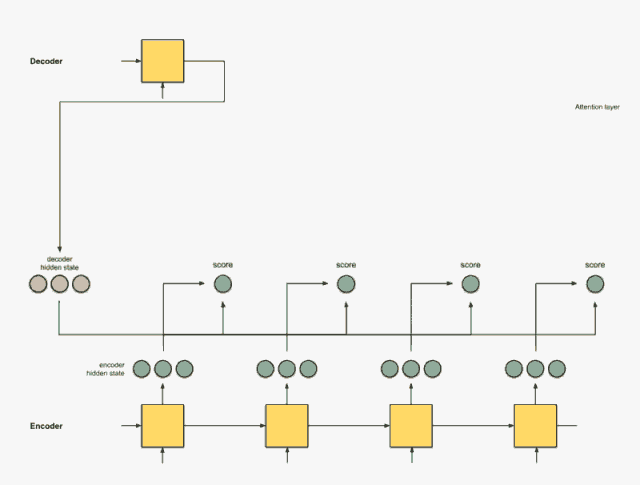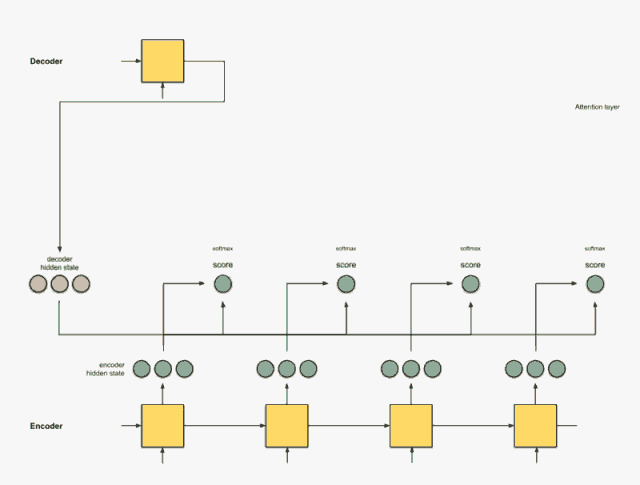
把权重与隐藏状态相乘
通过将每个编码器的隐藏状态与其softmax之后的分数(标量)相乘,我们就得到对其向量。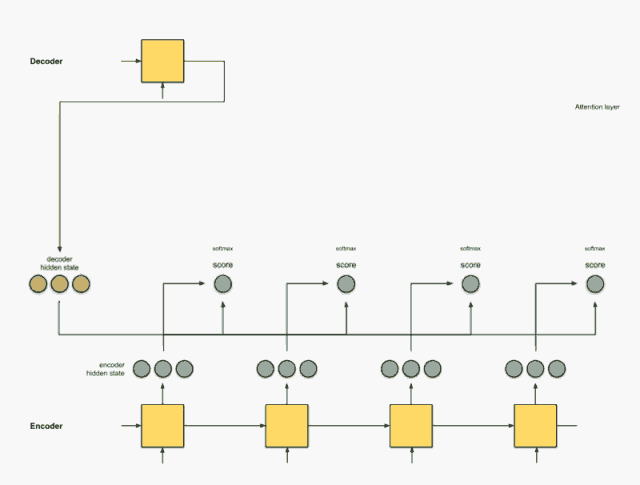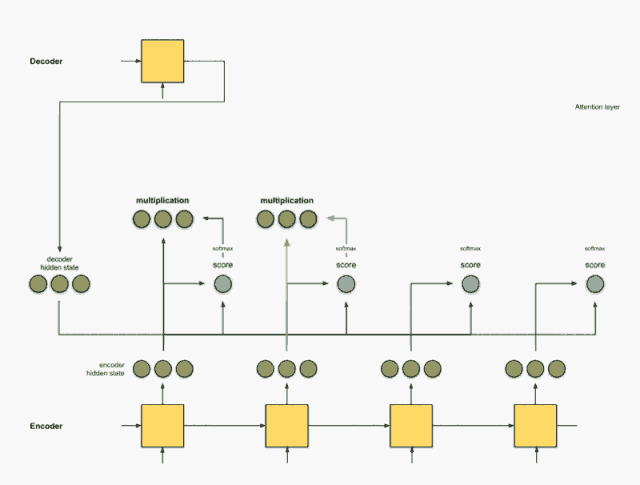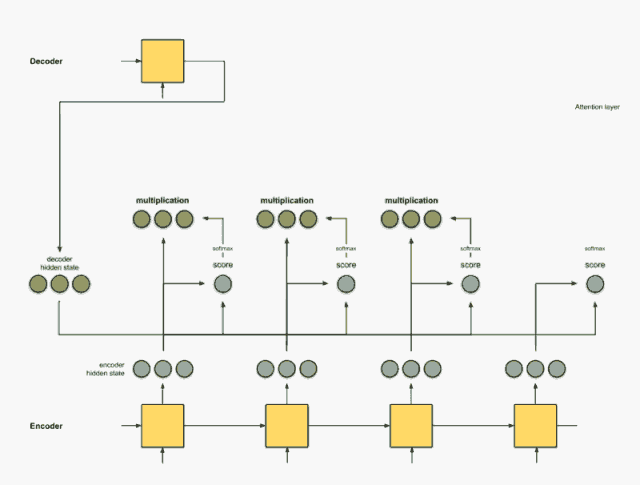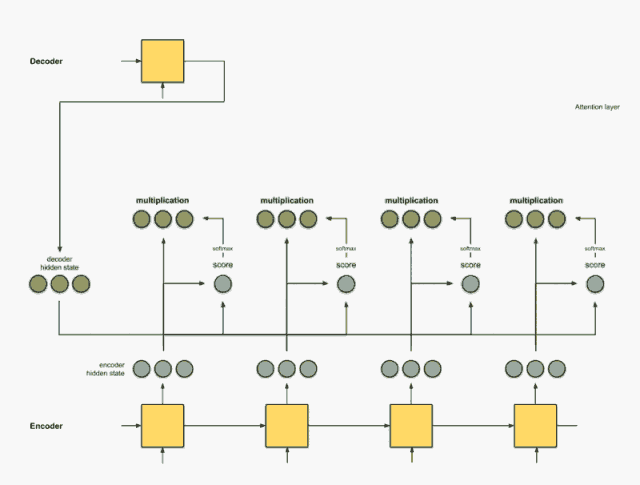
把前面的相乘结果相加得到上下文向量C
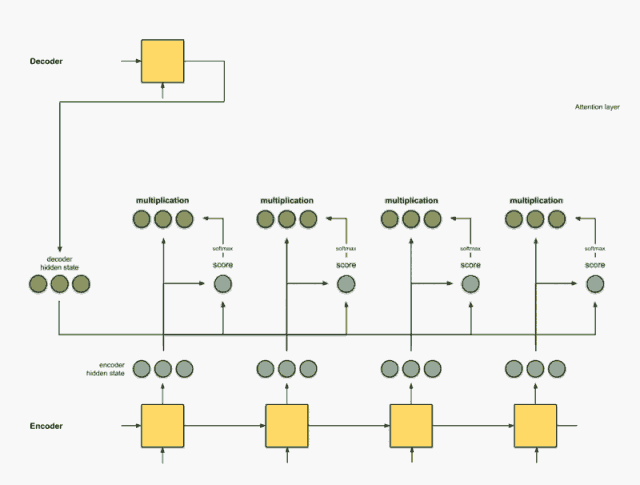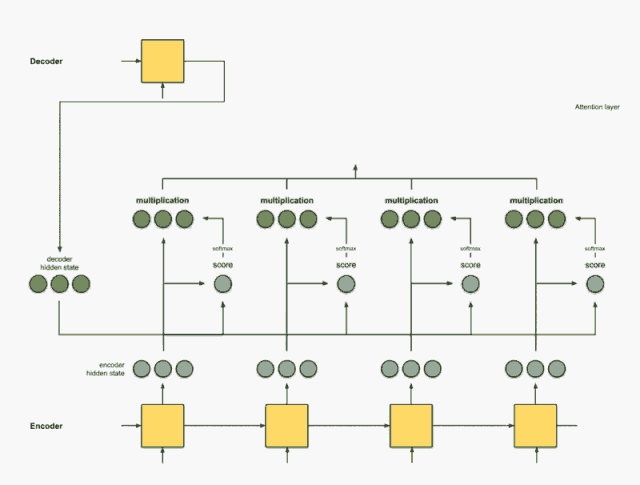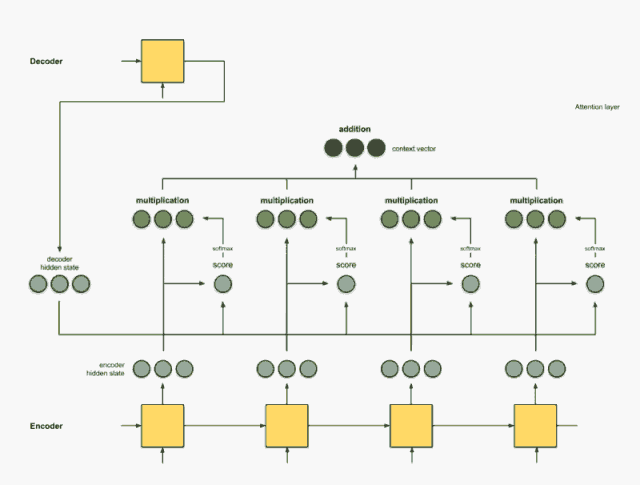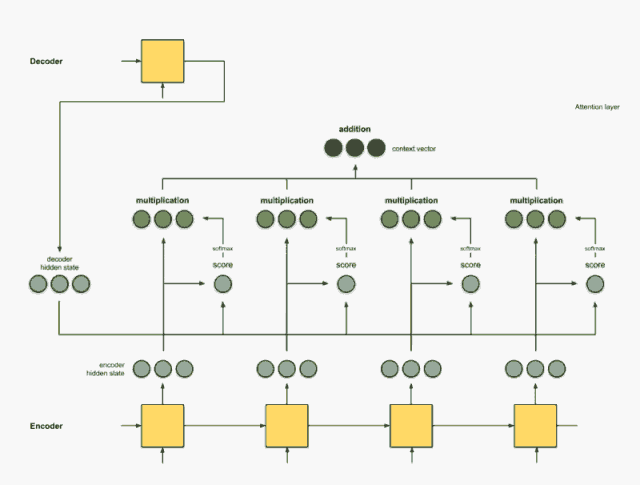
把C放入到解码器就可以进行翻译
相信这个动画,应该能把这个宏观过程解释的更加明白。 那么下面就看看具体细节, 这个权重到底是啥? 要怎么加? 最后的C应该怎么计算了?
5. Attention的计算细节
关于计算的部分, 我们先从这个上下文向量开始, 先看看这个C现在是怎么计算的, 还记得Seq2Seq的C是怎么计算的吗? 那里我们说是综合了所有的编码器的隐藏状态, 也就是这样的一个公式:


这里再拓展一下, 就是上面的这个过程还可以进行向量化计算,这样计算会高效一些, 广义上,注意力机制的输入包括查询项以及一一对应的键项和值项,其中值项是需要加权平均的一组项。在加权平均中,值项的权重来自查询项以及与该值项对应的键项的计算。这里详细的我在自然语言处理之Attention大详解(Attention is all you need)整理过了, 这里就说一下这个地方怎么向量化。

而GRU我们知道有两个门, 还有个候选隐藏状态:

所以,关于Attention的计算细节, 也就这么多了, 下面简单的实现一个带有Attention的Seq2Seq, 这个作业是来自吴恩达老师的课后作业, 这里只拿出一部分来看, 有利于理解更多的细节。
7. 带有Attention机制的Seq2Seq的简单代码实现
这个大作业里面, 编码器用的是双向的LSTM, 解码器用的是单向的LSTM, 整个带注意力机制的Seq2Seq结构如下:
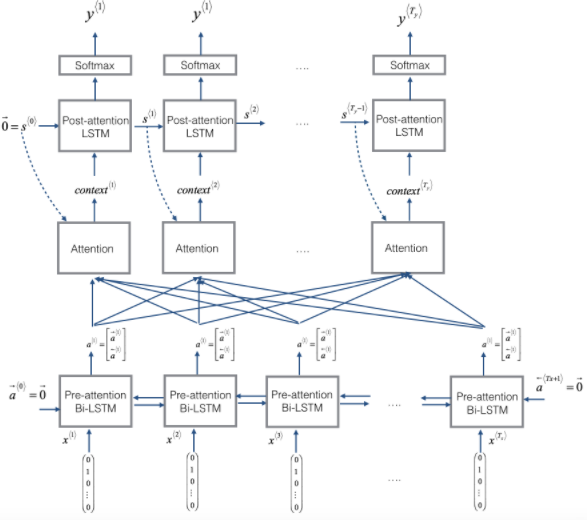
这个图其实解释的也非常的清楚, 可以当做回顾看一遍, 下面就是简单的实现这个网络, 但是实现之前, 还想先解释一下双向的LSTM究竟是怎么计算的? 编码器这里的隐藏状态输出会看到有一个正向的隐态, 有一个逆向的隐态然后两者进行了一个堆叠, 那么逆向的这个隐态究竟是怎么算的呢? 这里来个双向RNN的图:
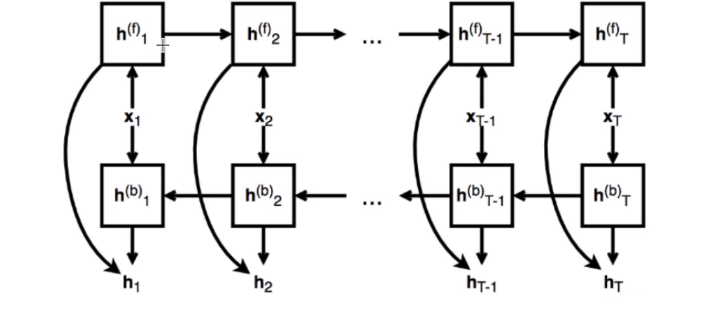
其实看这个也挺明白的, 正向隐藏状态的输出我们知道是按照时间步从第一步开始计算,然后依次往后这样计算即可, 那么反向其实是同理的, 无非就是输入的时候我们把输入进行逆序一下就可以了,就相当于先从最后一个时间步开始往前进行计算了, 这样每个时间步就会有一个正向隐藏状态,一个反向隐藏状态, 两者进行一个拼接即可。
好了, 这个问题也说明白了,当然双向RNN不用我们自己实现, 调用相应的包即可。 那么怎么实现上面的结构呢? 思路是这样, 我们下面是一个双向LSTM, 这个有包可以实现, 上面是单向LSTM, 也有包实现, 这么多时间步无非就是一个循环。 但是我们知道, 每个时间步里面都会有一个上下文向量C, 而这个注意力机制是我们要实现的关键, 只要实现了这个注意力机制, 那么这个计算过程就很容易了, 逻辑就是我先根据一个双向的LSTM, 把输入转成隐藏状态, 然后对于每一个时间步的隐态, 我得计算一个上下文向量, 然后把上下文向量作为解码器的输入去计算输出。
所以我们得自己写个函数,来获取一个时间步的上下文向量, 看下面这个图:
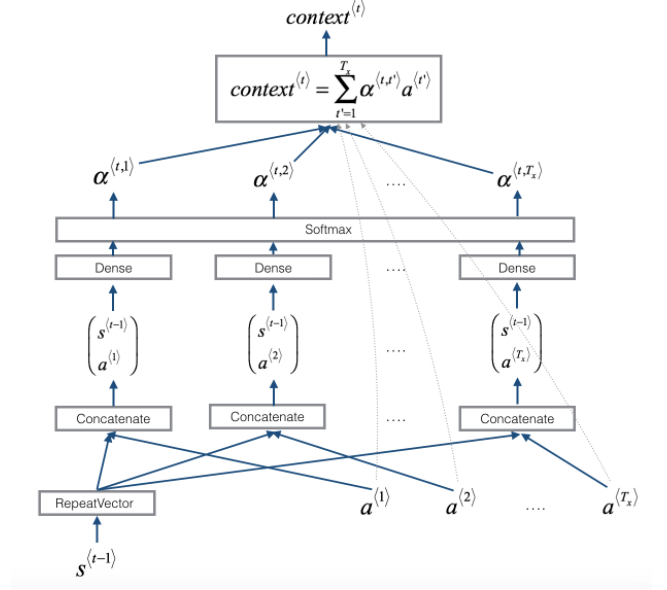
这就是一个时间步上下文向量的计算, 输入是解码器上一时刻的隐藏状态, 和编码器所有时间步的隐藏状态(这里考虑了所有时间步, 但是会根据当前位置对时间步的隐态加不同的权重), 而输出就是当前时刻的上下文向量。 过程上面其实都说的挺清楚了, 计算得分, 然后softmax, 然后加和。 当然这里也是采用了向量的方式, 开始写代码:
1 | def one_step_attention(a, s_prev): |
有了这一步的上下文向量的计算, 上面的的seq2seq就比较容易实现了, 逻辑就是先计算出编码器中的隐藏状态, 然后对于每个解码器的时间步进行遍历, 每一步都是先根据编码器的隐藏状态和上一步的s求当前步的上下文向量c, 然后基于c, 前一步的s, 前一步的y得到当前步的输出, 然后依次循环,直到结束。 代码如下:
1 | def seq2seq_att(Tx, Ty, n_a, n_s, input_dim, output_dim): |
上面就是一个简单的带有注意力机制的seq2seq的实现过程, 通过代码能更好的帮助理解一些细节,比如attention实现的时候一些向量的维度变化, 再比如LSTM单元的传递有h和c两个向量。 千万不要忘了这里的c, 并且这个c和上下文的context可不一样。
这样, 关于Attention的内容就差不多介绍到了这里。
8. 总结
这篇文章就总结到这里吧, 通过重温的这三篇文章, 又重新学习了一下RNN, LSTM, GRU和Seq2Seq, Attention, 这次学习收获很多,之前都没有学习的这么细, 通过这次机会希望能整理的详细一些, 这篇文章又是挺长的, 下面简单回顾一下。
我们先从seq2seq模型开始说起的, 这个模型是为了应对输入和输出都是不定长的那种任务 ,比如机器翻译, 人机对话等。 这种模型分为编码和解码两部分, 一般由两个RNN网络或者变体组成, 原理就是先基于编码器得到一个综合所有输入的上下文向量C, 然后进行解码,解码的时候, 将C作为解码RNN的输入, 最后得到输出结果。 这一块从宏观和计算细节两方面进行展开。
然后分析了这种结构的弊端就是当前时刻的输出要考虑所有的输入, 这个是不符习惯的,并且会发生序列信息的丢失,当输入的句子越长, 越前面词的信息丢失就越严重。在解码的时候, 当前词以及对应的源语言的上下文信息和位置信息在编解码过程中也会丢失。 当然这里的建模技巧就是将源语言句子再逆序输入,或者重复输入两遍来训练模型,可以达到一定性能的提升。但依然改进有限。
所以引入了注意力机制, 即给输入进行加权, 每个时刻都会有一个上下文向量, 当时每个时刻的上下文向量对所有的输入加了不同的注意力, 也就是当前时刻的输出要重点关注某部分的输入序列。 这个机制就保证了seq2seq模型能够进行长序列的任务。 这一块也是宏观和计算细节两方面展开。加入注意之后,在生成输出词时,会考虑每个输入词和当前输出词的对齐关系, 对齐越好的词,会有越大的权重,对当前生成词的影响也就越大。要注意这里的编码器使用了双向的RNN结构, 这样能够有效的缓解前后信息的丢失情况。
最后,还利用keras简单的实现了一个带有注意力机制的Seq2Seq模型, 了解了一些细节。 总之, Attention机制现在用的非常广泛也非常重要, 关于它的一些知识就介绍到这里。 最后再宏观上看一下带有注意力机制的Seq2Seq的工作过程:

有了这些基础的知识, 就可以进行一些实战任务, 就像第一篇里面说的后面会总结一篇用于时间序列预测非线性自回归模型的论文,这篇论文用的就是带有双阶段注意力机制的LSTM(如果掌握了上面的这些知识点, 就会发现读这篇论文无压力了, 并且很清晰的感觉)。 后面也会使用keras尝试复现并用于时间序列预测的任务,通过这样的方式,可以把这些基础知识从理论变成实践。 这叫做首尾呼应 哈哈!😉
参考: