1. 写在前面
今天是本系列的第二篇数据的EDA探索分析,这一块主要是对数据进行一个探索,帮助我们了解和熟悉数据,只有真正的了解数据,我们才能更好的进行后面的特征工程等处理,所以这一步也是非常重要的,所以这次会整理各种数据探索性分析的技巧,依然是围绕着上面的比赛进行展开论述,为了增加趣味性,我把数据探索这一块分成了五个维度,依然是采用将夜里面昊天世界的修炼等级境界来命名,分为数据初识,数据感知,数据不惑,数据洞玄和数据知命。因为学习的本身也是一场修行,相信通过这篇文章,能够修习到不错的数据探索技巧。
大纲如下:
- 数据初识(初识境对数据做初步探索,查看形状,字段类型,相关统计量等)
- 数据感知(感知境在初识的基础上进一步挖掘信息,主要包括数据的缺失情况和异常情况)
- 数据不惑(不惑境是前两个基础上进一步挖掘,包括查看预测值的分布和字段的类型判断)
- 数据洞玄(洞玄境对数值特征和类别特征分开挖掘,包括类别偏斜,类别分布可视化,数值相关等各种可视化技巧)
- 数据知命(知名境介绍pandas_profiling数据探索性分析的神器,通过这个神器可以对对上面的知识进行整合)
- 对知识和技巧进行总结
Ok, let’s go!
再此之前,我们先导入一些包和数据集:
1 | # 基础工具包即可 |
2. 数据初识
数据初识部分就是数据的初步探索, 这一块主要是对导入的数据有一个大致的了解,做到初识数据,包括数据简识(head,tail),行列信息(shape),数据的统计特征(describe),数据的信息(info)等。
1 | # 查看数据的形状 注意数据的行和列, 必须对数据非常了解 |
这个,我们要看一下结果:
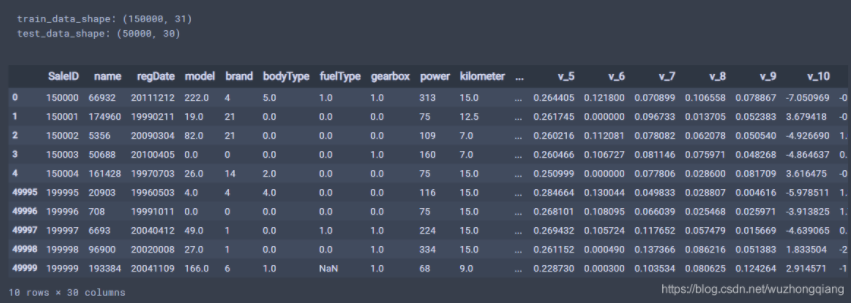
从形状可以看出训练集共150000个样本, 30列特征,一列价格,测试集50000个样本,30列特征
trick1: 要养成看数据集的head()以及shape的习惯,这会让你每一步更放心,不会导致接下里的连串的错误, 如果对自己的 pandas等操作不放心,建议执行一步看一下,这样会有效的方便你进行理解函数并进行操作
PS: 数据的维度很重要, 太多的行会导致花费大量时间来训练算法得到模型, 太少的数据会导致对算法训练不充分,得不到合适的模型 如果数据有太多的特征,会引起某些算法性能低下的问题。所以一定要先熟悉于心。
1 | # 数据信息查看 .info()可以看到每列的type,以及NAN缺失信息 |
这一个看一下结果:
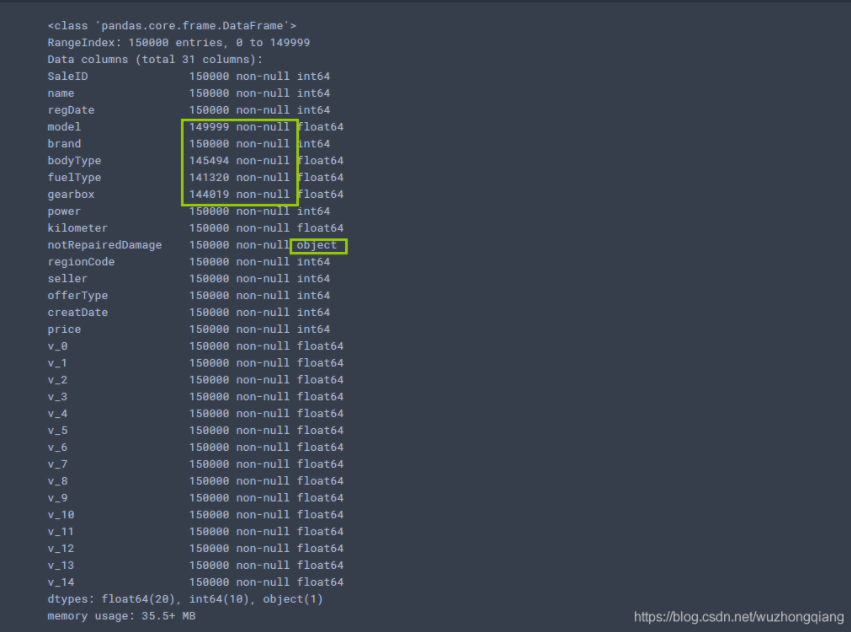
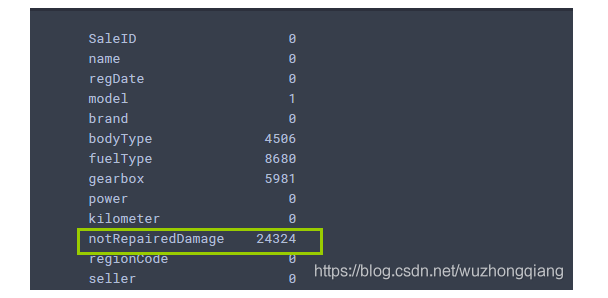
通过info就可以发现几点信息: 首先就是字段的类型, 有一个object,后面就需要单独处理。 其次就是有一些字段有空值,清洗的时候就要处理缺失。
通过info来了解数据每列的type,有助于了解是否存在除了nan以外的特殊符号异常
1 | # 通过.columns查看列名 |
describe中有每列(数值列)的统计量,个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、以 及最大值 看这个信息主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断,比如有的时候会发现 999 9999 -1 等值这些其实都是nan的另外一种表达方式,有的时候需要注意下。
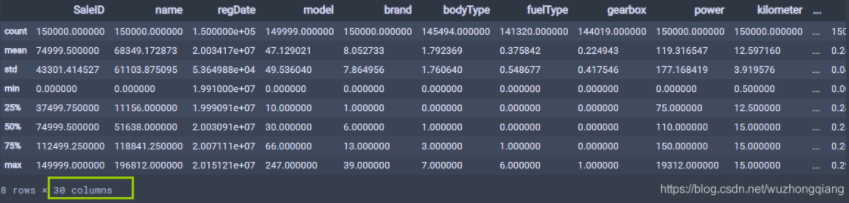
会发现,统计特征这个会有30列,我们上面输出形状的时候明明train_data有31列啊? 注意,这里面是不包括那个object类型的那个字段的统计的,毕竟不是数值类型的, 没法找中位数,均值啥的, 当然那一个可以用describe单独看看,你就会发现数值型和object用describe的区别。
1 | train_data['notRepairedDamage'].describe() |
好了,从初识境中,我们已经看到了数据的维度,了解了数据的字段类型和统计特征,算是一个初步相识吧,下面我们就进入感知。
3. 数据感知
数据感知在数据初识的基础上,进一步挖掘信息, 主要包括数据的缺失和异常等信息
1 | # 查看每列的存在nan的情况 |
看一下结果:
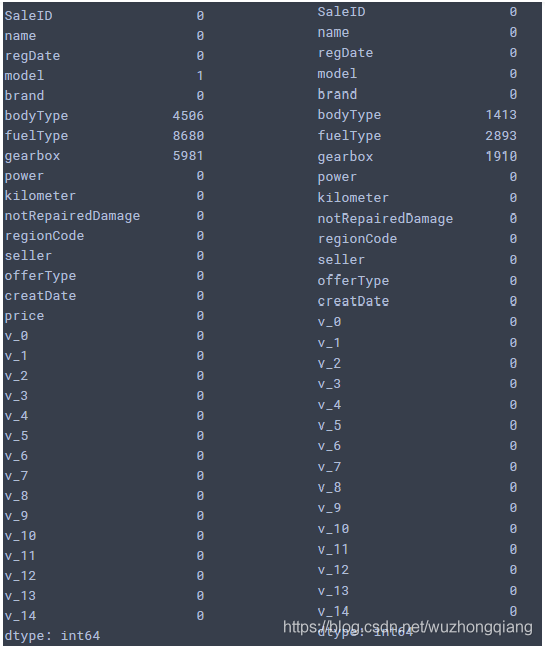
可以发现, bodytype, fueltype和gearbox有缺失值, 还可以对nan进行可视化,变得更加明显
1 | missing = train_data.isnull().sum() |
结果如下:
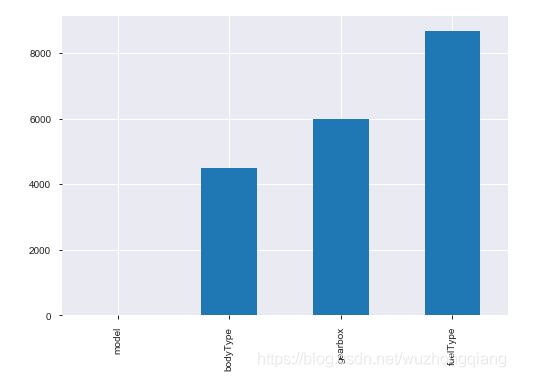
Trick2: 通过以上两句可以很直观的了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于 nan存在的个数是 否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的过多、可以考虑删掉。
下面是可视化缺省值, 用到msno这个包
1 | # 可视化看下缺省值 |
看一下结果:
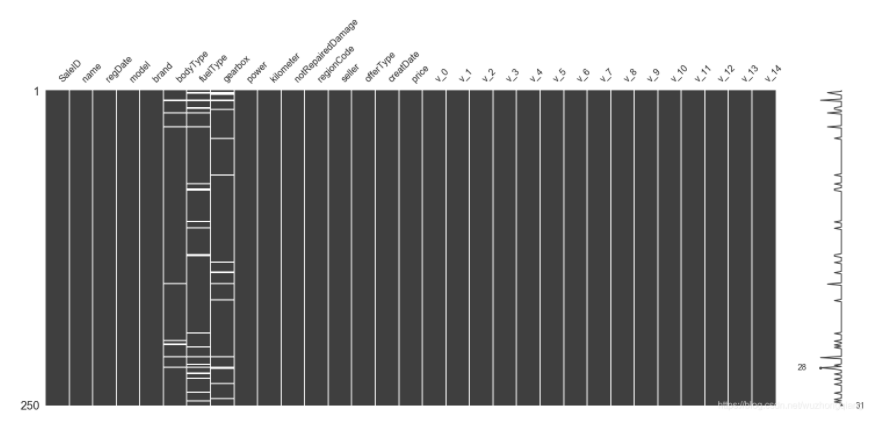
测试集的缺省和训练集的差不多情况, 可视化有三列有缺省,fuelType缺省得最多, 参考缺失值可视化处理–missingno
1 | """异常值检测""" |
上面初识数据的时候,我们使用data.info()看到了各个字段的类型,发现当时有一个object字段,这种记得要单独拿出来看一下取值,因为可能存在数值脏乱的情况,应该始终对数据保持一种怀疑的态度去审视,不是不相信数据本身,而是可能人为标注的时候或许出现错误等。数据的检查与修正还是挺重要的,这里面也提供了一点方式检查数据数据竞赛修炼笔记之工业化工生产预测, 在这里就不详细说方法了,因为对于这个比赛来说,这个问题不是那么严重。
trick3:对数据持着怀疑的角度审视,尤其是object字段。
1 | # 看看object这个字段的取值情况 |
会发现这里面竟然还有个’-’, 注意,如果单看它比赛给的字段的描述,只知道0代表有未修复的损害,1代表没有,如果我们不持着怀疑的角度,就很难发现这里竟然有个‘-’, 这个也代表着缺失,因为很多模型对nan有直接的处理, 这里我们可以先不做处理,先替换为nan, 所以字符串类型的要小心 缺失的,格式不规范的情况大有存在, 格式不规范的情况可以看我上面给出的化工生产预测的链接,从那里面才会真正体会到怀疑数据的重要性。
1 | train_data['notRepairedDamage'].replace('-', np.nan, inplace=True) |
结果如下:
这一个字段的缺失是最多的了。 对测试集也是同样的处理方式哈。
3. 数据不惑
通过初识和感知,我们不仅认识了数据,还发现了一些异常和缺失,下面我们进入不惑,不惑部分我们会进一步挖掘数据,主要包括查看预测值的分布和把字段分成数值型和类别型,后面要分开查看和处理。
3.1 了解预测值的分布
1 | """查看预测值的频数""" |
这个看下结果:
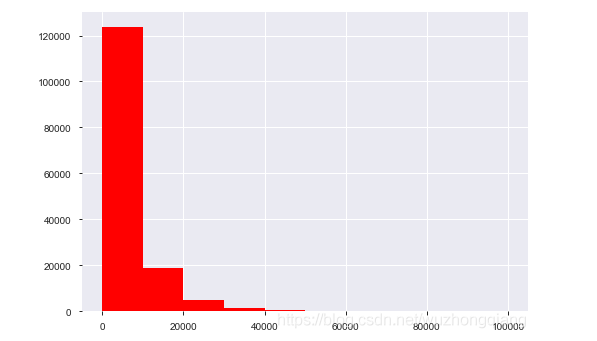
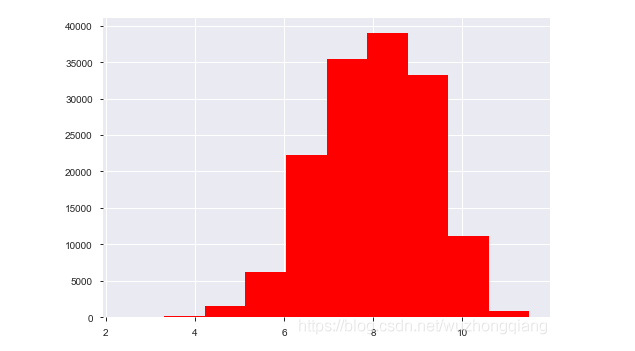
查看频数, 大于20000得值极少,其实这里也可以把这些当作特殊得值(异常值)直接用填充或者删掉,再往下进行, 不过直接删掉有点风险,毕竟这是个回归问题,我在跑baseline的时候试过,效果不太好。
1 | """总体分布概况(无界约翰逊分布等)""" |
结果如下:
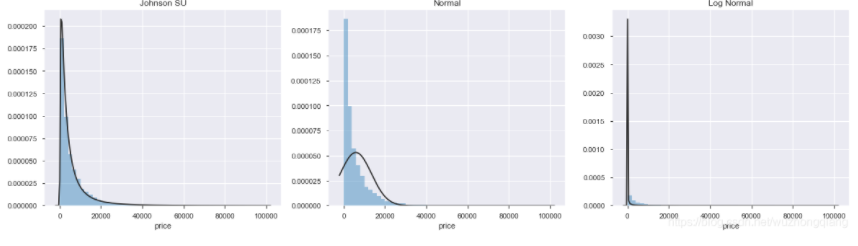
可以发现, 价格不服从正态,所以进行回归之前,它必须进行转换。 虽然对数变换做的很好,但最佳拟合是无界约翰逊分布。
1 | # log变换 z之后的分布较均匀, 可以进行log变换进行预测, 这也是预测问题常用的trick |
结果如下:
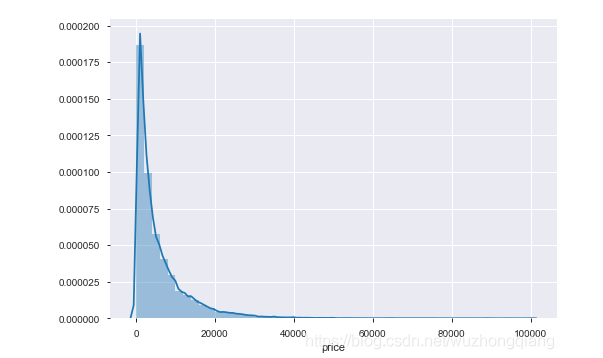
Trick4:对预测标签做log转换,使其更加服从于正态
1 | """查看偏度和峰度""" |
结果如下:
1 | # train_data.skew(), train_data.kurt() |
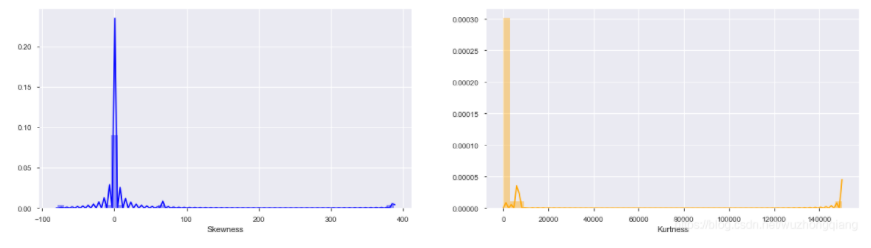
峰度Kurt代表数据分布顶的尖锐程度。偏度skew简单来说就是数据的不对称程度,skew、kurt说明参考https://www.cnblogs.com/wyy1480/p/10474046.html
3.2 把字段分成类别字段和数字字段分别处理
在赛题理解中,初步观察数据字段含义的时候,我们就发现这些字段中有数值字段和类别字段,我们应该分开处理。
1 | """先分离出label值""" |
这里要强调的就是字段类别的分类,我们有时候需要自己去设定,这就通过观测每一个字段的含义,和具体数据的字段类型信息去均衡了。 这里之所以不用注释掉的那种方式,是因为这里的类别字段都类似于LabelEncoder的处理了,虽然是0,1这种类别,但都已经成了数值型,所以我们需要自己设定把它们分出来。
4. 数据洞玄
不惑境我们已经分析了预测值的分布,从分布中我们可以看到,如果把预测值对数转换一下效果可能会更好一些, 然后我们又把特征字段分成了数值型和非数值型, 下面我们进入洞玄, 主要对数值特征和类别特征进一步分析挖掘信息,包括类别偏斜,类别分布可视化,数值相关及可视化等。 这一块我们要对类别型特征和数值型特征分开来探索,毕竟两者的处理方式上有很大的区别的。
4.1 类别特征的探索
类别特征我们主要是看一下类别的取值和分布, 会有箱型图,小提琴图,柱形图等各种可视化技巧。
1 | """类别偏斜处理""" |
这个要在显示结果中重点看一下类别特征有没有数量严重偏斜的情况(由于太多,不在这里显示),这样的情况一般对预测没有什么帮助, 比如上面的seller, offerType字段,我们可以查看一下数量
1 | train_data['seller'].value_counts() |
下面我们看一下类别的unique分布
1 | """类别的unique分布""" |
下面我们就来学习类别特征的各种可视化技巧
1 | """类别特征箱型图可视化""" |
结果如下:
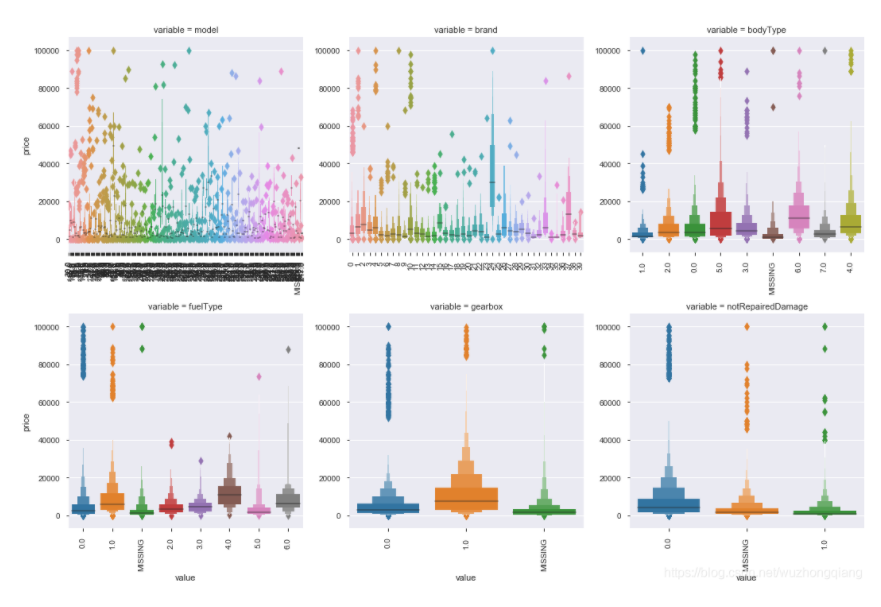
1 | """类别特征的小提琴图可视化, 小提琴图类似箱型图,比后者高级点,图好看些""" |
看一下柱形的结果(小提琴的不在这里展示):
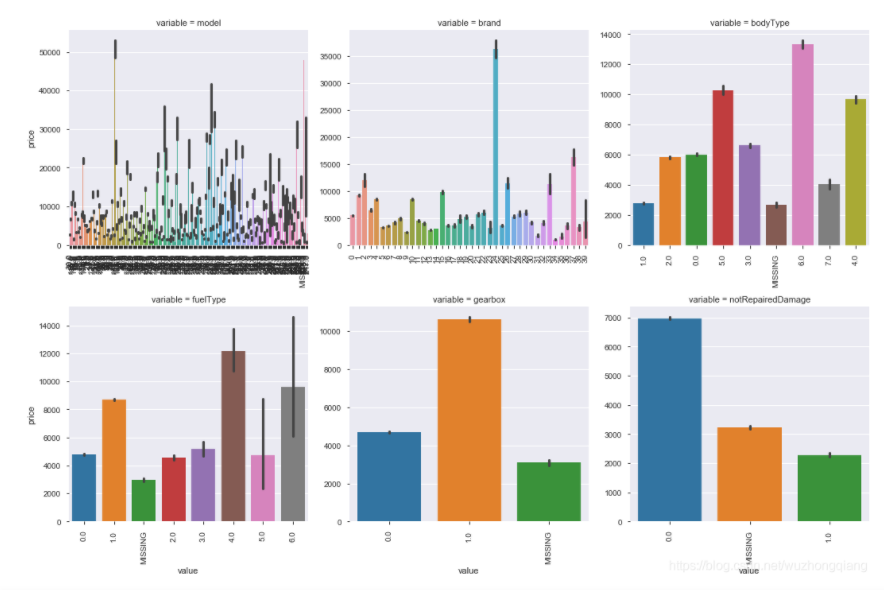
1 | """类别特征的每个类别频数可视化(count_plot)""" |
这个图还是挺好用的,可以可视化每一个类别特征的取值分布和数量,便于筛选异常
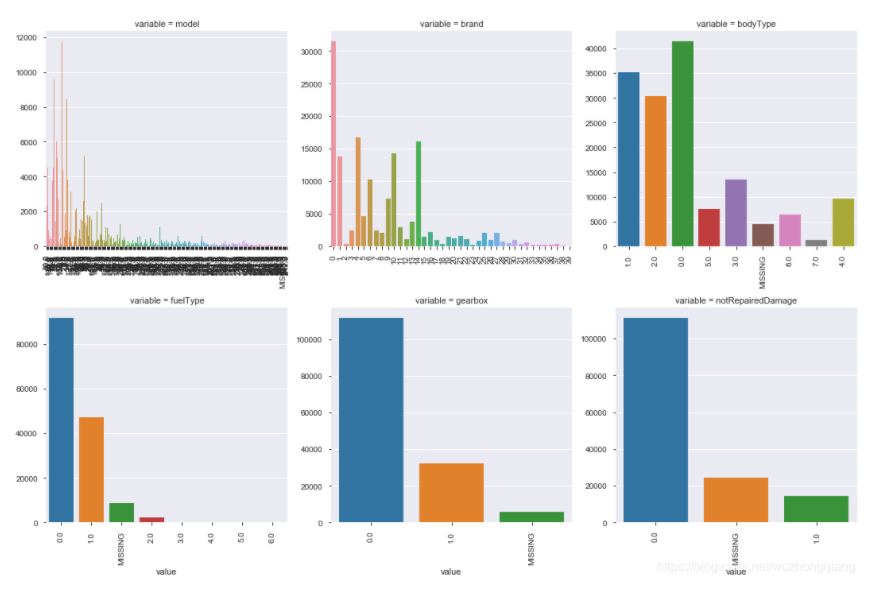
里面用到了一个melt函数,这是个转换函数,参考这篇博客:Pandas_规整数据_转换数据_melt()
4.2 数值特征的探索
数值特征的探索我们要分析相关性等,也会学习各种相关性可视化的技巧。
1 | numeric_train_data = train_data[numeric_features] |
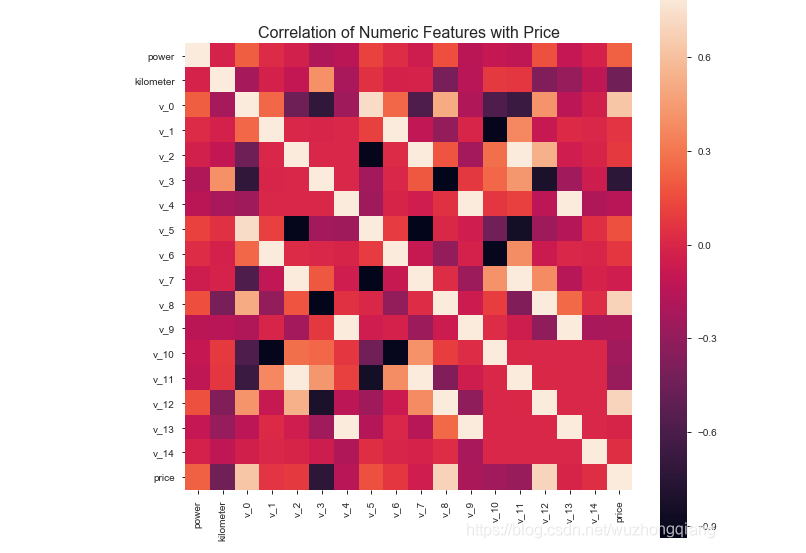
.corr()可以看到每个特征与price的相关性,我们并且排了个序。下面进行相关性可视化, 热力图比较合适(后面我会给出一个链接,是关于都可以画哪些图,分别是什么情况下使用什么图等,这样看到数据应该考虑什么图一目了然)
1 | # 可视化 |
这个看下结果:
1 | # 删除price |
数值特征的分布可视化,从这里可以看到数值特征的分布情况。可以看出匿名特征相对分布均匀
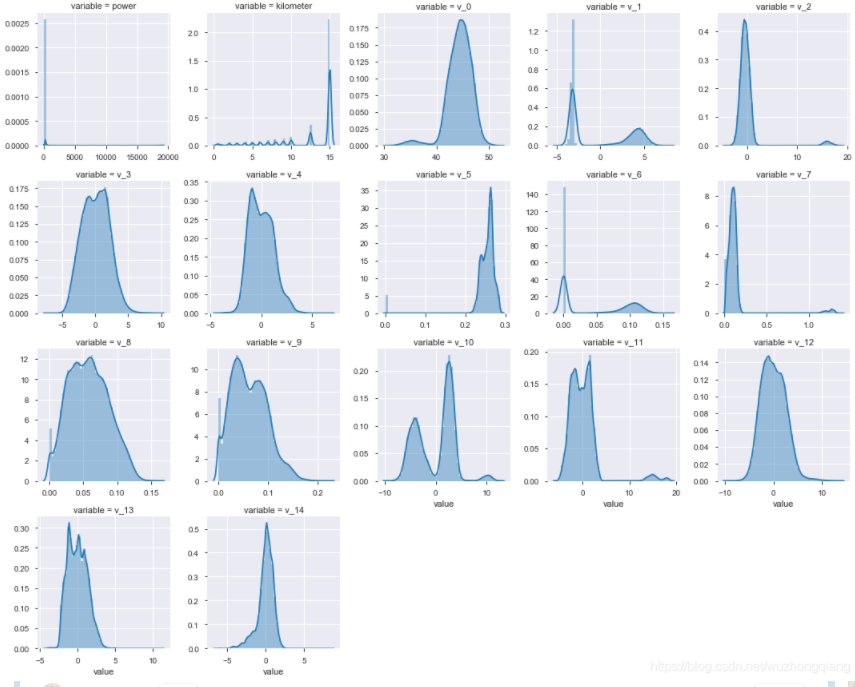
1 | """数字特征相互之间的关系可视化""" |
看下结果:

这里面会看到有些特征之间是相关的, 比如v_1和v_6
1 | """多变量之间的关系可视化""" |
看下结果:
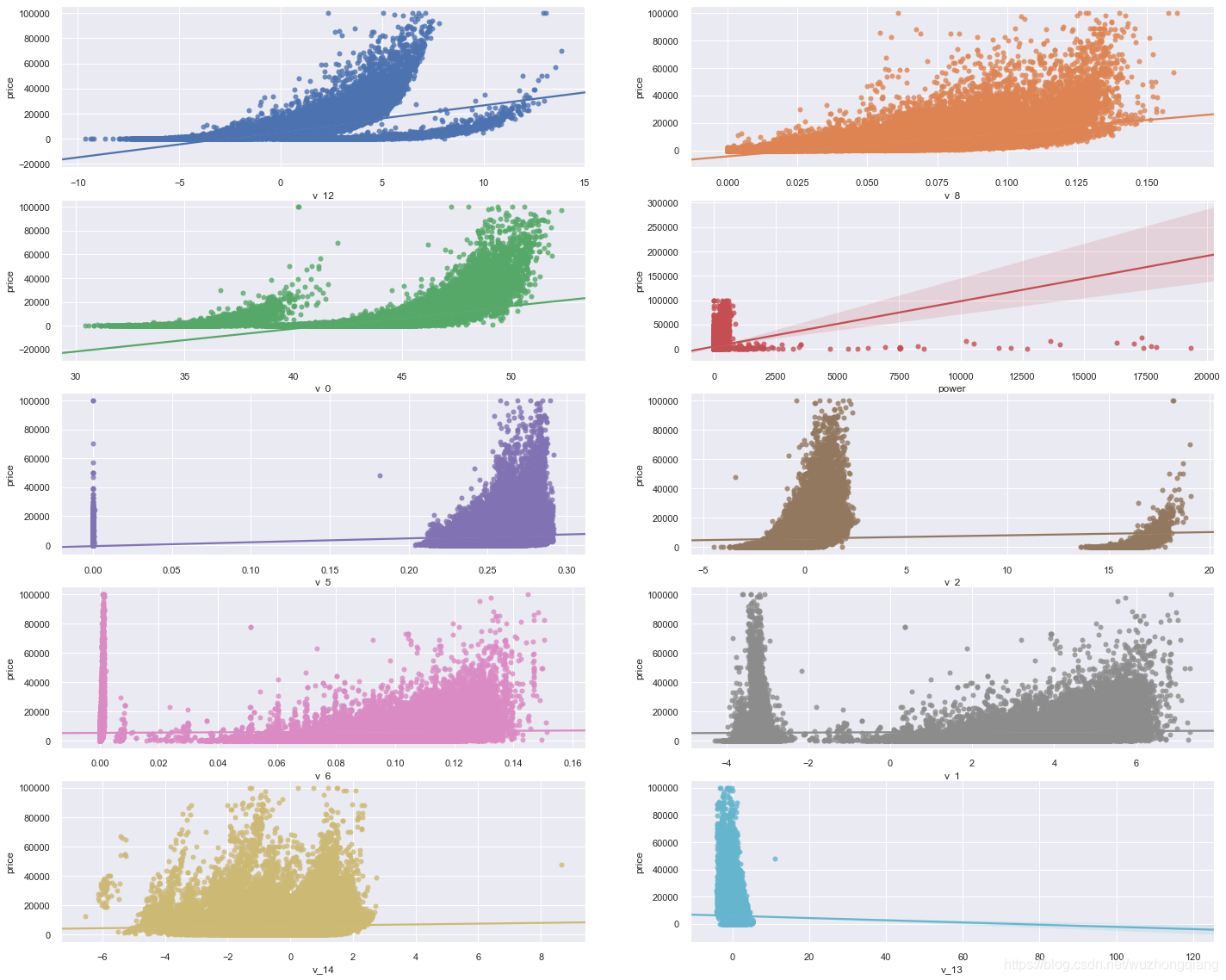
关于可视化的更多学习,可以参考:https://www.jianshu.com/p/6e18d21a4cad
5. 数据知命
这里会综合上面的这些过程,用pandas_profiling这个包使用函数ProfileReport生成一份数据探索性报告, 在这里面会看到:
总体的数据信息(首先是数据集信息:变量数(列)、观察数(行)、数据缺失率、内存;数据类型的分布情况),
警告信息
- 要点:类型,唯一值,缺失值
- 分位数统计量,如最小值,Q1,中位数,Q3,最大值,范围,四分位数范围
- 描述性统计数据,如均值,模式,标准差,总和,中位数绝对偏差,变异系数,峰度,偏度
单变量描述(对每一个变量进行描述)
相关性分析(皮尔逊系数和斯皮尔曼系数)
采样查看等
1 | # 两行简单的代码即可搞定上面的这些信息 |
这个结果没法全放在这里,简单的看下轮廓:
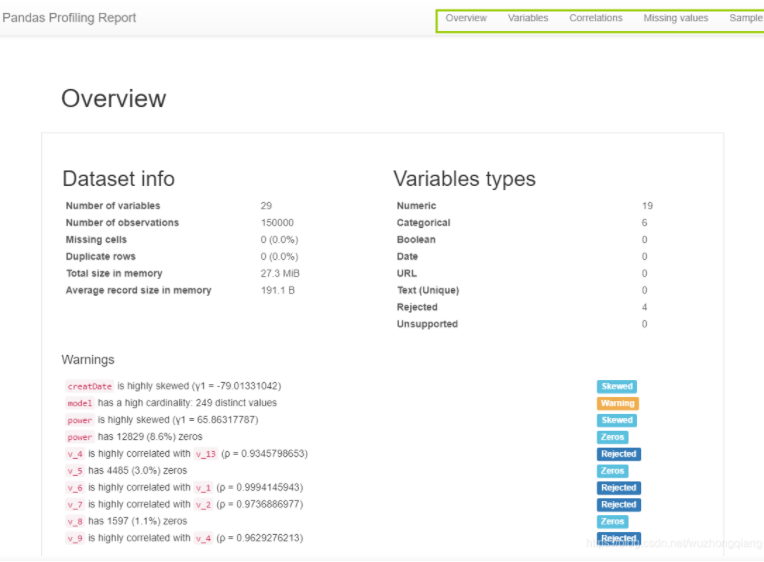
会有数据的总信息,警告信息(通过这些警告信息可以看到相关,缺失,偏斜等情况), 后面会是各个字段的统计说明信息,相关性信息,缺失值信息等都概况了。
6. 总结
今天通过围绕着二手车价格预测的比赛,从五个维度整理了一下数据探索性分析的相关知识,下面我们根据思维导图进行回顾一下:
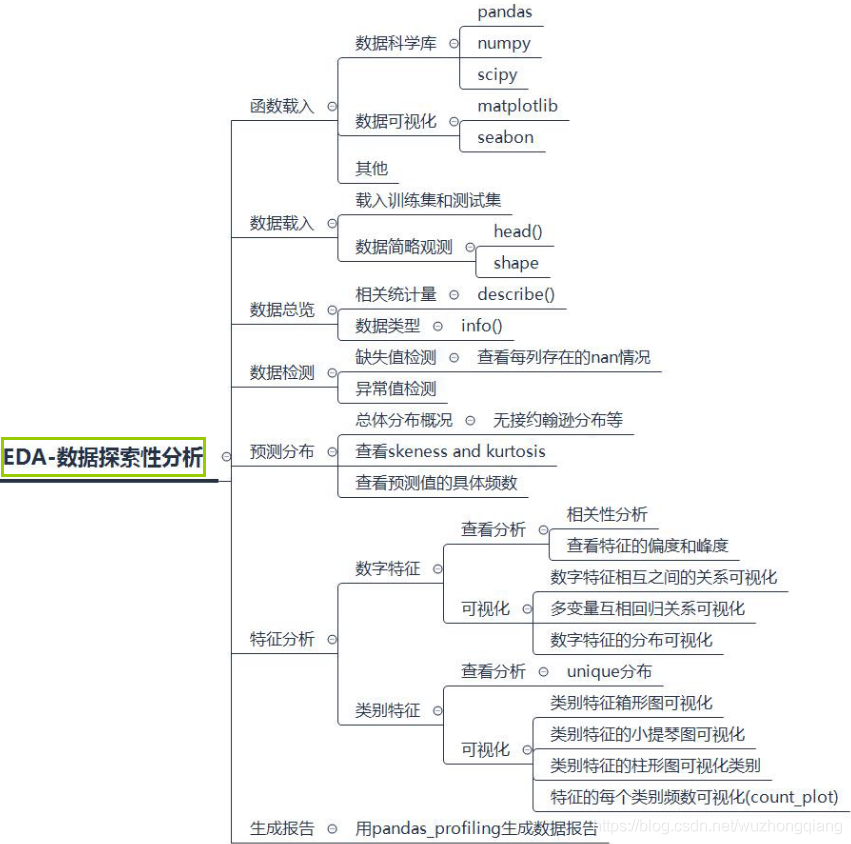
这些探索性分析的技巧当然不只是限于这个比赛,从数据挖掘的角度来讲,这些技巧可以迁移到其他的数据挖掘任务中,思路还是相通的,所以这里才借助这个机会在这里做一个总结,后面也会给出关于探索性分析这块之前学习过的知识链接,做一个知识的整合。或许上面写的这些可视化技巧有些杂乱,或许有些在这个比赛里面并不一定需要用到,但是我们学习的不仅是这个比赛,更重要的应该是数据挖掘的技巧和思想,所以这篇文章与其说针对这个比赛,不如说是针对数据挖掘,更想当做一份资料来查阅。
对了,通过数据的探索性分析之后,我们可以发现一些类别偏斜的特征列,可以删除掉,然后通过分析预测值的分布,也会发现把预测值转成log的形式要好些,从原来baseline的基础上修改一下,成绩会提高一点, 上次是658.5030, 这次是657.2422。当然,看到这个成绩发现没有提高的这么明显,哈哈,心里有点失望吧, 但是别忘了,我们基本上没有改啥东西啊,能有点提高就很不错了,不过我们已经更加熟悉了我们的数据,接下来会是数据清洗和特征工程部分,这才是提高成绩的关键所在,后面这两块我会分开进行描述,放一块可能有点多。 敬请期待吧 😉
下面依然是技巧总结(依然来自Datawhale团队车哥的总结):
所给出的EDA步骤为广为普遍的步骤,在实际的不管是工程还是比赛过程中,这只是最开始的一步,也是最基本 的一步。
接下来一般要结合模型的效果以及特征工程等来分析数据的实际建模情况,根据自己的一些理解,查阅文献,对实际问题做出判断和深入的理解。
最后不断进行EDA与数据处理和挖掘,来到达更好的数据结构和分布以及较为强势相关的特征
数据探索有利于我们发现数据的一些特性, 数据之间的关联性,对后续的特征构建还是很有帮助的。
对于数据的初步分析:(直接查看数据,或.sum(), .mean(),.descirbe()等统计函数)可以从:样本数量,训练集数量,是否有时间特征,是否是时许问题,特征所表示的含义(非匿名特征),特征类型(字符类似, int,float,time),特征的缺失情况(注意缺失的在数据中的表现形式,有些是空的有些是”NAN”符号 等),特征的均值方差情况。
分析记录某些特征值缺失占比30%以上样本的缺失处理,有助于后续的模型验证和调节,分析特征应该是填充(填充方式是什么,均值填充,0填充,众数填充等),还是舍去,还是先做样本分类用不同的特征模型去预测。
对于异常值做专门的分析,分析特征异常的label是否为异常值(或者偏离均值较远或者事特殊符号),异常值是否应该剔除,还是用正常值填充,是记录异常,还是机器本身异常等。
对于Label做专门的分析,分析标签的分布情况等。
进一步分析可以通过对特征作图,特征和label联合做图(统计图,离散图),直观了解特征的分布情况,通过这一步也可以发现数据之中的一些异常值等,通过箱型图分析一些特征值的偏离情况,对于特征和特征联合作图,对于特征和label联合作图,分析其中的一些关联性。
还有一些tricks穿插在了上面的部分中,也是一些不错的tricks哟!
对了, 你知道吗?

参考: