1. 写在前面
今天是本系列的第三篇文章数据的清晰和转换技巧,依然是围绕着上面的比赛进行展开。数据清洗和转换在数据挖掘中也非常重要,毕竟数据探索我们发现了问题之后,下一步就是要解决问题,通过数据清洗和转换,可以让数据变得更加整洁和干净,才能进一步帮助我们做特征工程,也有利于模型更好的完成任务。
- 有异常值, 可以用箱线图锁定异常, 但是有时候不建议直接把样本删除,截尾的方式可能会更好一些
- 有缺失值,尤其是类别的那些特征(bodyType, gearbox, fullType, notRepaired的那个)
- 类别倾斜的现象(seller, offtype), 考虑删除
- 类别型数据需要编码
- 数值型数据或许可以尝试归一化和标准化的操作
- 预测值需要对数转换
7 power高度偏斜,这个处理异常之后对数转换试试 - 隐匿特征的相关性
- 存在高势集model, 及类别特征取值非常多, 可以考虑使用聚类的方式,然后在独热编码
所以今天的重点是在处理上面的问题上,整理数据清洗和转换的技巧,以方便日后查阅迁移。首先是处理异常数据,通过箱线图捕获异常点,然后截尾处理, 然后是整理一些处理缺失的技巧, 然后是数据分桶和数据转换的一些技巧, 下面我们开始。
大纲如下:
- 异常值处理(箱线图分析删除,截尾,box-cox转换技术)
- 缺失值处理(不处理, 删除,插值补全, 分箱)
- 数据分桶(等频, 等距, Best-KS分桶,卡方分桶)
- 数据转换(归一化标准化, 对数变换,转换数据类型,编码等)
- 知识总结
Ok, let’s go!
准备工作:数据清洗的时候,我这里先把数据训练集和测试集放在一块进行处理,因为我后面的操作不做删除样本的处理, 如果后面有删除样本的处理,可别这么做。 数据合并处理也是一个trick, 一般是在特征构造的时候合并起来,而我发现这个问题中,数据清洗里面训练集和测试集的操作也基本一致,所以在这里先合起来, 然后分成数值型、类别型还有时间型数据,然后分别清洗。
1 | """把train_data的price先保存好""" |
trick1: 就是如果发现处理数据集的时候,需要训练集和测试集进行同样的处理,不放将它们合并到一块处理。
trick2: 如果发现特征字段中有数值型,类别型,时间型的数据等,也不妨试试将它们分开,因为数值型,类别型,时间型数据不管是在数据清洗还是后面的特征工程上, 都是会有不同的处理方式, 所以这里将训练集合测试集合并起来之后,根据特征类型把数据分开, 等做完特征工程之后再进行统一的整合(set_index把它们的索引弄成一样的,整合的时候就非常简单了)。
2. 异常值处理
常用的异常值处理操作包括箱线图分析删除异常值, BOX-COX转换(处理有偏分布), 长尾截断的方式, 当然这些操作一般都是处理数值型的数据。

在一些情况下(P值<0.003)上述方法很难实现正态化处理,所以优先使用Box-Cox转换,但是当P值>0.003时两种方法均可,优先考虑普通的平方变换。
Box-Cox的变换公式:
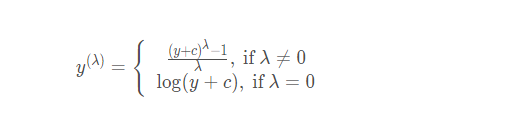
具体实现:
1 | from scipy.stats import boxcox |
当然,也给出一个使用案例:使用scipy.stats.boxcox完成BoxCox变换
好了,BOX-COX就介绍这些吧, 因为这里处理数据先不涉及这个变换,我们回到这个比赛中来,通过这次的数据介绍一下箱线图筛选异常并进行截尾:
从上面的探索中发现,某些数值型字段有异常点,可以看一下power这个字段:
1 | # power属性是有异常点的 |
结果如下:
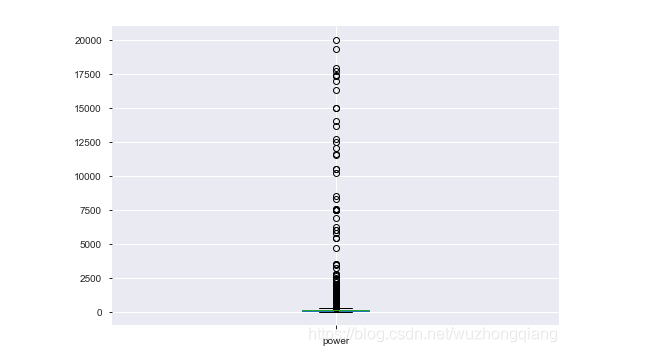
所以,我们下面用箱线图去捕获异常,然后进行截尾, 这里不想用删除,一个原因是我已经合并了训练集和测试集,如果删除的话肯定会删除测试集的数据,这个是不行的, 另一个原因就是删除有时候会改变数据的分布等,所以这里考虑使用截尾的方式:
1 | """这里包装了一个异常值处理的代码,可以随便调用""" |
我们再看一下数据:
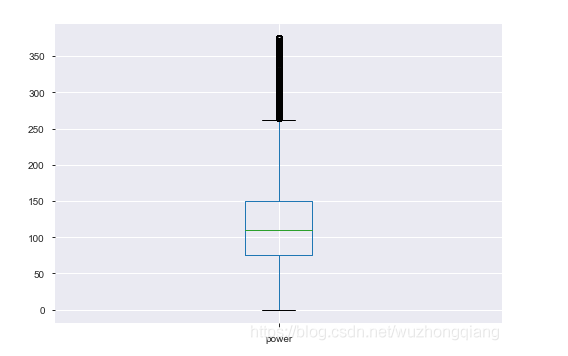
是不是比上面的效果好多了?当然,如果想删除这些异常点,这里是来自Datawhale团队的分享代码,后面会给出链接,也是一个模板:
1 | def outliers_proc(data, col_name, scale=3): |
这个代码是直接删除数据,这个如果要使用,不要对测试集用哈。下面看看power这个特征的分布:
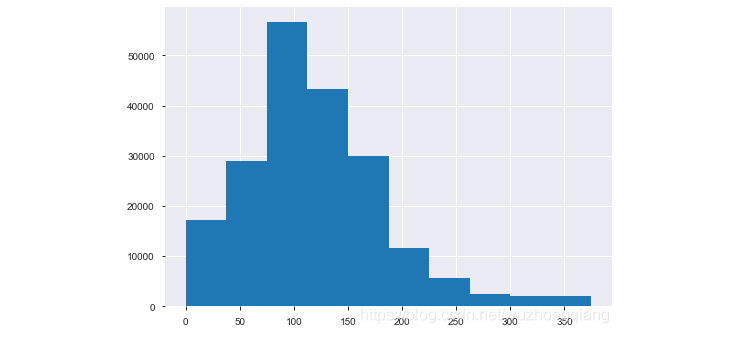
也不错了,所以就没再进一步处理power,至于其他的数值型是不是需要截尾,这个看自己吧。
3. 缺失值处理
关于缺失值处理的方式,这里也是先上方法, 有几种情况:不处理(这是针对xgboost等树模型), 有些模型有处理缺失的机制,所以可以不处理,如果缺失的太多,可以考虑删除该列, 另外还有插值补全(均值,中位数,众数,建模预测,多重插补等), 还可以分箱处理,缺失值一个箱。
下面整理几种填充值的方式:
1 | # 删除重复值 |
再回到这个比赛中,我们在数据探索中已经看到了缺失值的情况:
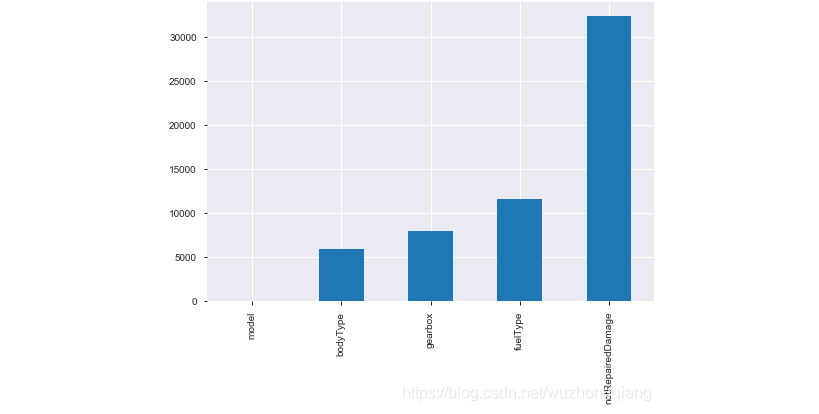
上图可以看到缺失情况, 都是类别特征的缺失,notRepaired这个特征的缺失比较严重, 可以尝试填充, 但目前关于类别缺失,感觉上面的方式都不太好,所以这个也是一个比较困难的地方,感觉用模型预测填充比较不错,后期再说吧,因为后面的树模型可以自行处理缺失。 当然OneHot的时候,会把空值处理成全0的一种表示,类似于一种新类型了。
4. 数据分桶
连续值经常离散化或者分离成“箱子”进行分析, 为什么要做数据分桶呢?
离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
当然还有很多原因,LightGBM 在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性
数据分桶的方式:
- 等频分桶
- 等距分桶
- Best-KS分桶(类似利用基尼指数进行二分类)
- 卡方分桶
最好是数据分桶的特征作为新一列的特征,不要把原来的数据给替换掉, 所以在这里通过分桶的方式做一个特征出来看看,以power为例
1 | """下面以power为例进行分桶, 当然构造一列新特征了""" |
当然这里的新特征会有缺失。
这里也放一个数据分桶的其他例子(迁移之用)
1 | # 连续值经常离散化或者分离成“箱子”进行分析。 |
结果如下:

5. 数据转换
数据转换的方式, 数据归一化(MinMaxScaler), 标准化(StandardScaler), 对数变换(log1p), 转换数据类型(astype), 独热编码(OneHotEncoder),标签编码(LabelEncoder), 修复偏斜特征(boxcox1p)等。关于这里面的一些操作,我有几篇博客已经描述过了,后面会给出链接, 这里只针对这个问题进行阐述:
1.数值特征这里归一化一下, 因为我发现数值的取值范围相差很大
1 | minmax = MinMaxScaler() |
2.别特征独热一下
1 | # 类别特征某些需要独热编码一下 |
3.关于高势集特征model,也就是类别中取值个1\数非常多的, 一般可以使用聚类的方式,然后独热,这里就采用了这种方式
1 | from scipy.cluster.hierarchy import linkage, dendrogram |
效果如下:
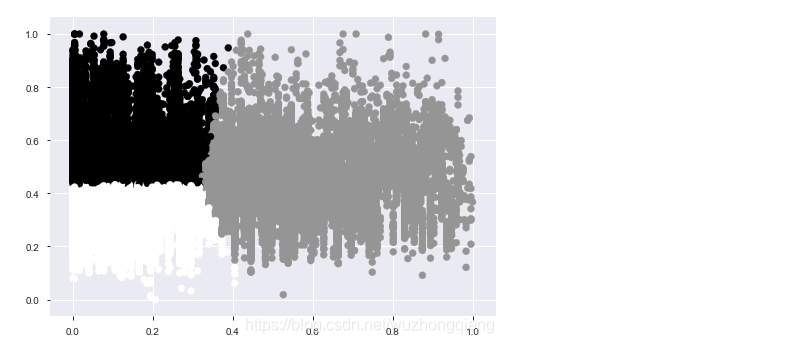
但是我发现KMeans聚类不好,可以尝试层次聚类试试,并且这个聚类数量啥的应该也会有影响,这里只是提供一个思路,我觉得这个特征做的并不是太好,还需改进。
数据清洗和转换的技巧就描述到这里,但是不能说是结束,因为这一块的知识没有什么固定的套路,我们得学会发散思维,然后不断的试错探索,这里只整理的部分方法。
trick3: 通过上面的方式处理完了数据之后,我们要记得保存一份数据到文件,这样下次再用的时候,就不用再花功夫处理,直接导入清洗后的数据,进行后面的特征工程部分即可。一定要养成保存数据到文件的习惯。
6. 总结
今天主要是整理一些数据清洗和转换的技巧,包括异常处理,缺失处理,数据分箱和数据转换操作, 这些技巧也同样不仅适用于这个比赛,还可以做迁移。依然是利用思维导图把知识进行串联:
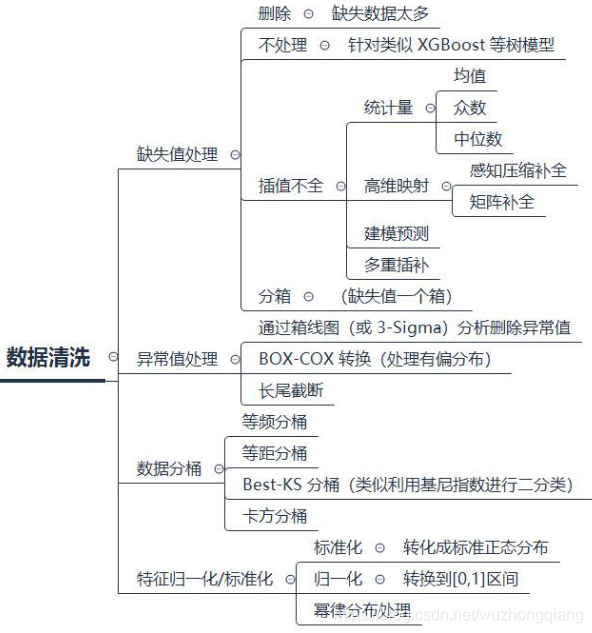
关于经验的话,数据清洗和转换这一块只能整理一些方法,然后需要针对具体的数据不断的尝试, 只有亲自尝试才能获得更多的成长,没有什么固定的套路或者说方式,没有什么循规蹈矩的规定,当然也希望不要把思维限定在上面的这些方法中,因为毕竟目前我也是小白,这些只是我目前接触到的一些,所以肯定不会包括所有的方式,希望有大佬继续补充和交流。
另外,我觉得分享本身就是一种成长,因为分享知识在帮助自己加深记忆的同时,也是和别人进行思维碰撞的机会,这个过程中会遇到很多志同道合的人一起努力,一起进步,这样比一个人要好的多。 一个人或许会走的很快,但是一群人才能走的更远,所以希望这个系列能帮助更多的伙伴,也希望学习路上可以遇到更多的伙伴, 你看,天上太阳正晴,我们一起吧 😉
对了,上面的数据清洗过程,再做几个特征,可以让误差降低60多,也算是有点用吧,不过不是太理想,还需要进一步探索这块, 希望和更多的小伙伴一起试错,一起交流,然后一起成长。
参考: