1. 写在前面
今天是本系列的第四篇文章特征工程部分,特征工程和数据清洗转换是比赛中至关重要的一块, 因为数据和特征决定了机器学习的上限,而算法和模型只是逼近这个上限而已,
所以特征工程的好坏往往决定着最后的结果。 特征工程和数据清洗,我用了四天的进行整理总结,就是尝试把尽可能多的方法和技巧都尝试一下,当然可能有些细节在这个比赛中不一定适用, 但以全面为主,毕竟是为了学习知识。特征工程一般包括特征构造, 特征选择, 降维等步骤, 但是它一般是和数据清洗转换放在一块,也有的把这两块统称为特征工程,因为两者联系实在是密切(你中有我,我中有你的景象)。
通过数据清洗和转换,我们能够更好地表示出潜在问题的特征,使得数据的表达清晰一些,比如处理异常值清除噪声,填充缺失值可以加入先验知识等。而特征工程又进一步增强数据的表达能力,通过构造新特征,我们可以挖掘出数据的更多信息,使得数据的表达能力进一步放大,当然如果特征过多,又往往会造成冗余,这时候我们又得根据相关性等进行特征的选择和降维操作。 所以这就是特征工程这块的逻辑。
这次整理,首先从特征构造入手,整理不同类型的特征(数值型,类别型,时间型)在特征构造的时候用到的一些方法(肯定不全, 后面会跟着学习慢慢补充), 然后介绍一些特征筛选的方式(过滤式,包裹式,嵌入式),毕竟特征过多会造成冗余,影响模型判断, 最后会介绍降维的技术, 通过把特征进行某种加权组合,可以在保留尽可能多的信息熵把特征的维度进行缩减,当然缩减后的特征我们已不知其具体含义。
大纲如下:
- 特征构造(这里会以这个比赛为背景,提供时间字段,类别字段和数值字段的特征构造方法)
- 特征筛选(这里会对上面构造的特征进行筛选,去除冗余和相关,介绍过滤式,包裹式,嵌入式等筛选方法)
- PCA降维技术
- 对特征工程部分整理总结
Ok, Let’s go!
2. 特征构造
特征工程这块, 在特征构造的时候,我们需要借助一些背景知识,遵循的一般原则就是我们需要发挥想象力,尽可能多的创造特征,不用先考虑哪些特征可能好,可能不好,先弥补这个广度,而特征构造的时候数值特征,类别特征,时间特征又得分开处理
对于数值特征,我们一般会尝试一些它们之间的加减组合(当然不要乱来,根据特征表达的含义)或者提取一些统计特征
对于类别特征,我们一般会尝试之间的交叉组合,embedding也是一种思路
对于时间特征,这一块又可以作为一个大专题来学习,在时间序列的预测中这一块非常重要,也会非常复杂,需要就尽可能多的挖掘时间信息,会有不同的方式技巧。 当然在这个比赛中涉及的实际序列数据有一点点,不会那么复杂。
好了,我们从这个比赛开始,看看这几种类型的特征如何进行构造新特征出来, 首先给出一份二手车的背景资料信息,这个感谢来自于Datawhale某大佬的分享整理, 这个在做特征工程的时候非常有用,试想如果连背景都不了解,连目标变量与哪些因素相关,我们怎么下手去做特征工程?
看完之后,我想我们应该能剖析出一些信息, 我这里只是给出一些构造思路(可能还有潜在的信息,如果你发现了也欢迎互相交流,互相帮助哈 😉)

所以根据上面的描述, 我们下面可以着手进行构造特征了,由于我在数据清洗的时候就根据字段的类型不同把数据进行了划分,所以这里我直接就可以构造了(如何划分,可以看入门系列三)
2.1 时间特征的构造(time_data)
根据上面的分析,我们可以构造的时间特征如下:
- 汽车的上线日期与汽车的注册日期之差就是汽车的使用时间,一般来说与价格成反比
- 对汽车的使用时间进行分箱,使用了3年以下,3-7年,7-10年和10年以上,分为四个等级, 10年之后就是报废车了,应该会影响价格
- 淡旺季也会影响价格,所以可以从汽车的上线日期上提取一下淡旺季信息
2.1.1 汽车的使用时间特征
createDate-regDate, 反应汽车使用时间,一般来说与价格成反比, 但是要注意这一块中的问题就是时间格式, regDateFalse这个字段有些是0月,如果忽略错误计算的话,使用时间有一些会是空值, 当然可以考虑删除这些空值,但是因为训练集和测试集合并了,那么就不轻易删除了, 我采取的办法,把错误字段都给他加1个月,然后计算出天数之后在加上30天(这个有不同的处理方式, 但是我一般不喜欢删除或者置为空,因为删除和空值都有潜在的副作用)
1 | # 这里是为了标记一下哪些字段有错误 |
样,一个特征构造完毕, used_time字段,表示汽车的使用时间。全部构造完毕之后,我们再看一下结果。
2.1.2 汽车是不是符合报废
时间特征还可以继续提取,我们假设用了10年的车作为报废车的话, 那么我们可以根据使用天数计算出年数, 然后根据年数构造出一个特征是不是报废
1 | # 使用时间换成年来表示 |
我们还可以对used_time进行分享,这个是根据背景估价的方法可以发现, 汽车的使用时间3年,3-7年,10年以上的估价会有不同,所以分一下箱
1 | bins = [0, 3, 7, 10, 20, 30] |
这样就又构造了两个时间特征。Is_scrap表示是否报废, estivalue表示使用时间的分箱。
2.1.3 是不是淡旺季
这个是根据汽车的上线售卖时间看, 每年的2, 3月份及6,7,8月份是整个汽车行业的低谷, 年初和年末及9月份是二手车销售的黄金时期, 所以根据上线时间选出淡旺季。
1 | # 选出淡旺季 |
我们看一下最后的构造结果, 报废特征我没有构造,因为我发现了一个特点就是这里的数据10年以上的车会偏斜,所以感觉这个用10年作为分界线不太合适,只是提供一种思路。
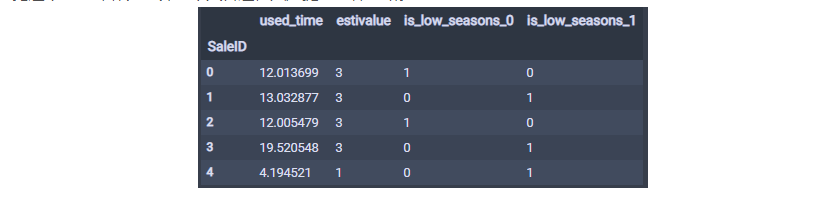
2.1.4 还可以根据汽车的使用时间或者淡旺季分桶进行统计特征的构造
1 | # 构造统计特征的话需要在训练集上先计算 |
这样, 时间特征就基本构造完毕,最后的结果如下:

这样,时间特征这块就构造了10个特征出来, 当然还可以更多, 由于篇幅原因,其他的可以自行尝试。
2.2 类别特征的构造(cat_data)
经过上面的分析,可以构造的类别特征如下:
- 从邮编中提取城市信息, 因为是德国的数据,所以参考德国的邮编,加入先验知识, 但是感觉这个没有用,可以先试一下
- 最好是从regioncode中提取出是不是华东地区,因为华东地区是二手车交易的主要地区(这个没弄出来,不知道这些编码到底指的哪跟哪)
- 私用车和商用车分开(bodyType提取)
- 是不是微型车单独处理,所以感觉那些车的类型OneHot的时候有点分散了(bodyType这个提取,然后one-hot)
- 新能源车和燃油车分开(在fuelType中提取,然后进行OneHot)
- 地区编码还是有影响的, 不同的地区汽车的保率不同
- 品牌这块可以提取一些统计量, 统计特征的话上面这些新构造的特征其实也可以提取
注意,OneHot不要太早,否则有些特征就没法提取潜在信息了。
2.2.1 邮编特征
从邮编中提取城市信息, 因为是德国的数据,所以参考德国的邮编,加入先验知识
1 | cat_data['city'] = cat_data['regionCode'].apply(lambda x: str(x)[0]) |
邮编特征构造完毕,依然是最后看结果。
2.2.2 私用车和商务车分开(bodyType)
1 | com_car = [2.0, 3.0, 6.0] # 商用车 |
2.2.3 新能源车和燃油车分开(fuelType)
1 | # 是否是新能源 |
2.2.4 构造统计特征
这一块依然是可以构造很多统计特征,可以根据brand, 燃油类型, gearbox类型,车型等,都可以,这里只拿一个举例,其他的类似,可以封装成一个函数处理。
以gearbox构建统计特征:
1 | train_data_gearbox = train_data.copy() # 不要动train_data |
当然下面就可以把bodyType和fuelType删除,因为该提取的信息也提取完了,该独热的独热
1 | # 删掉bodyType和fuelType,然后把gearbox, car_class is_fuel独热一下, 这个不能太早,构造晚了统计特征之后再独热 |
这样,就可以把类别特征构造完毕。最终结果如下:

我这边是构造了41个特征,当然可以更多, 也是自己尝试。
2.3 数值特征的构造(num_data)
数值特征这块,由于大部分都是匿名特征,处理起来不是太好处理,只能尝试一些加减组合和统计特征
2.3.1 对里程进行一个分箱操作
一部车有效寿命30万公里,将其分为5段,每段6万公里,每段价值依序为新车价的5/15、4/15、3/15、2/15、1/15。假设新车价12万元,已行驶7.5万公里(5年左右),那么该车估值为12万元×(3+3+2+1)÷15=7.2万元。
1 | # 分成三段 |
2.3.2 V系列特征的统计特征
平均值, 总和和标准差
1 | v_features = ['v_' + str(i) for i in range(15)] |
这样,数值特征构造完毕,最终构造的结果特征如下:
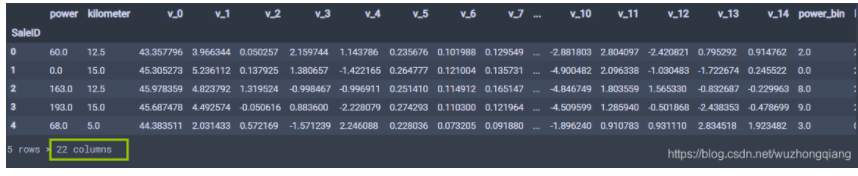
好了,通过上面的步骤,我们已经把特征工程这块做完了,简单的梳理一下, 我们是基于二手车的背景信息进行特征构造的,首先是构造的时间特征, 构造了使用时间,是否报废,使用时间分箱, 是否淡旺季等特征。然后是类别特征,我们构造了邮编特征,是否私用,是否新能源,是否微型车,并且还提取了大量统计特征, 最后是数值特征,我们给kilometer分箱, 对V特征进行了统计等。
最后我们合并一下所有的数据
1 | final_data = pd.concat([num_data, cat_data, time_data], axis=1) |
特征构造后的最终数据:

好了,特征我们已经发挥自己的想象力构造完毕,最终有74个特征, 当然还可以更多,但是太多了也不是个好事,毕竟会造成冗余,特征相关等特征,对后面的模型造成一些负担,所以,我们还得进行特征筛选才可以,毕竟上面的74个特征不可能都是有用的,甚至有些还会造成负面影响。
trick: 数据在清洗完毕或者构造完毕之后,最好是保存一下到文件,这样后面处理的时候导入直接用就可以,不用重新再跑,节省时间。
3. 特征选择
特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。但是拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,我们经常不管三七二十一,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的), 但是真的好使吗? 哈哈,不知道, 也不好说,有时候暴力会出奇迹。
特征选择主要有两个功能:
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合
- 增强对特征和特征值之间的理解
通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
首先,导入我备份的数据:
1 | # 导入最后的数据 |
还是上面的final_data, 看一下构造的特征:
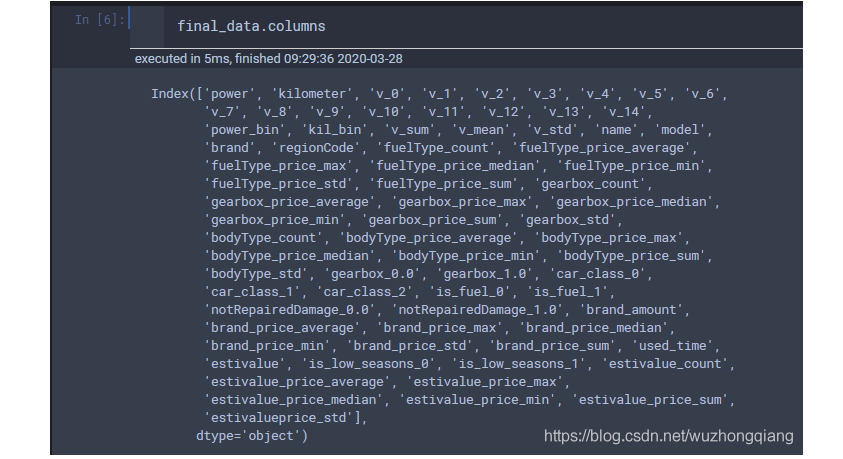
3.1 过滤式
主要思想: 对每一维特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该特征的重要性,然后依据权重排序。先进行特征选择,然后去训练学习器,所以特征选择的过程与学习器无关。相当于先对特征进行过滤操作,然后用特征子集来训练分类器。
主要方法:
- 移除低方差的特征;
- 相关系数排序,分别计算每个特征与输出值之间的相关系数,设定一个阈值,选择相关系数大于阈值的部分特征;
- 利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t检验、F检验等。
- 互信息,利用互信息从信息熵的角度分析相关性。
trick1: 对于数值型特征,方差很小的特征可以不要,因为太小没有什么区分度,提供不了太多的信息,对于分类特征,也是同理,取值个数高度偏斜的那种可以先去掉。
trick2:根据与目标的相关性等选出比较相关的特征(当然有时候根据字段含义也可以选)
trick3: 卡方检验一般是检查离散变量与离散变量的相关性,当然离散变量的相关性信息增益和信息增益比也是不错的选择(可以通过决策树模型来评估来看), person系数一般是查看连续变量与连续变量的线性相关关系。
3.1.1 去掉取值变化小的特征
这应该是最简单的特征选择方法了:假设某特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的的特征选择方法中选择合适的进行进一步的特征选择。例如,我们前面的seller和offerType特征。
1 | # 对方差的大小排序 |
根据这个,可以把方差非常小的特征作为备选的删除特征(备选,可别先盲目删除)
3.1.2 单变量特征选择
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
这种方法比较简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。
下面重点介绍一下pearson相关系数,皮尔森相关系数是一种最简单的,比较常用的方式。能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的pearsonr方法能够同时计算相关系数和p-value, 当然pandas的corr也可以计算。
直接根据pearson系数画出图像:
1 | corr = select_data.corr('pearson') # .corr('spearman') |
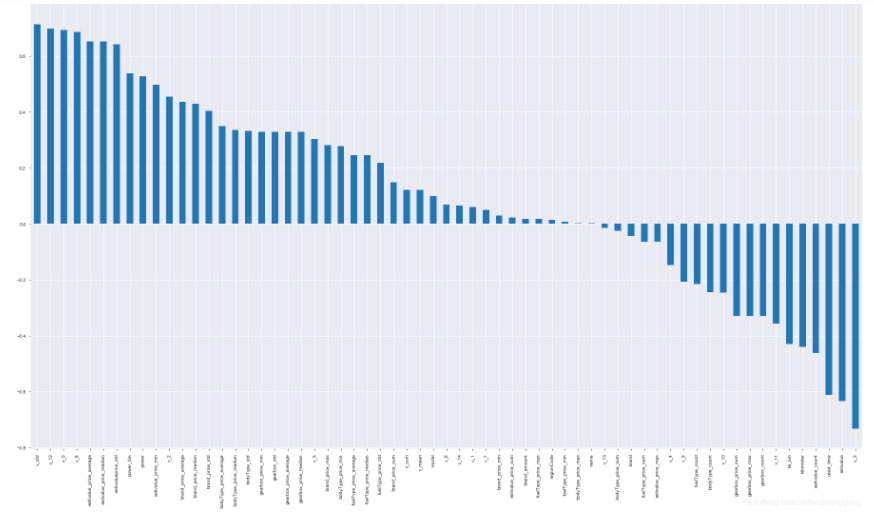
结果如下:
当然,这个数据用pearson系数可能不是那么合理,可以使用spearman系数,这个被认为是排列后的变量的pearson的相关系数, 具体的可以看(Pearson)皮尔逊相关系数和spearman相关系数, 这里只整理两者的区别和使用场景, 区别如下。
连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用spearman相关系数也可以,效率没有pearson相关系数高。
上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
两个定序测量数据(顺序变量)之间也用spearman相关系数,不能用pearson相关系数。
Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。
当然还可以画出热力图来,这个不陌生了吧, 这个的目的是可以看变量之间的关系, 相关性大的,可以考虑保留其中一个:
1 | # 下面看一下互相之间的关系 |
结果如下:
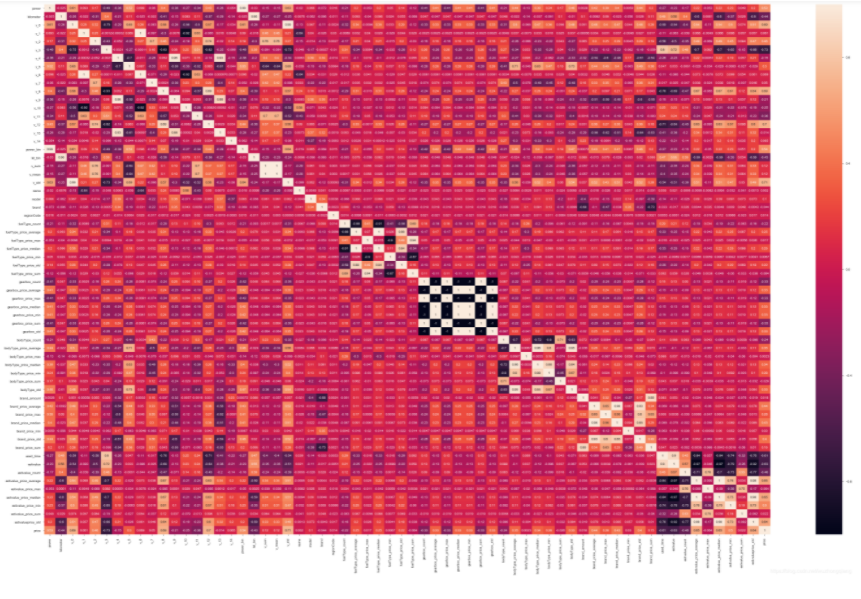
从上面两个步骤中,就可以发现一些结论:
根据与price的线性相关关系来看的话,我们可以考虑正负相关0.6以上的特征, v_std, v_12, v_0, v_8, estivalue_price_average, estivalue_price_median, estivalue_price_std, kil_bin, kilmoeter, estivalue_count, used_time, estivalue, v_3
某些变量之间有很强的的关联性,比如v_mean和v_sum,这俩的相关性是1,所以可以删掉其中一个。
当然,依然是备选删除选项和备选保留选项(这些都先别做), 因为我们有时候不能盲目,就比如上面的相关性,我们明明知道pearson的缺陷是无法捕捉非线性相关,所以得出的这个结论也是片面的结论, 所以这些都是备选,先做个心中有数,后面再用一些别的方式看看再说(如果现在就删除了,后面的方法就不好判断了)
3.2 包裹式
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。 详细介绍见:特征选择,我们真的学会了吗?
主要思想:包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。包裹式特征选择直接针对给定学习器进行优化。
主要方法:递归特征消除算法, 基于机器学习模型的特征排序
优缺点:
- 优点:从最终学习器的性能来看,包裹式比过滤式更好;
- 缺点:由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择要大得多。
下面,这里整理基于学习模型的特征排序方法,这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。其实Pearson相关系数等价于线性回归里的标准化回归系数。假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。
我们可以用随机森林来跑一下,看看随机森林比较喜欢特征:
1 | from sklearn.model_selection import cross_val_score, ShuffleSplit |
这里对喜欢的特征排序并打分,结果如下:

这里就可以看出随机森林有用的特征排序,如果我们后面选择随机森林作为模型,就可以根据这个特征重要度选择特征。 当然,如果你是xgboost,xgboost里面有个画特征重要性的函数,可以这样做:
1 | # 下面再用xgboost跑一下 |
这样,直接把xgboost感兴趣的特征画出来:
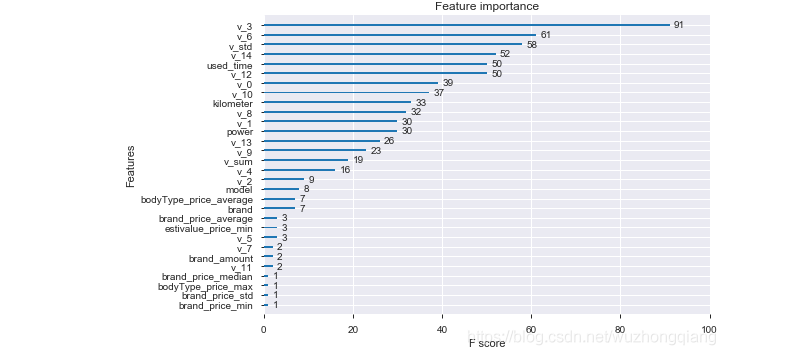
最后,我们把上面的这两种方式封装起来, 还可以画出边际效应:
1 | from mlxtend.feature_selection import SequentialFeatureSelector as SFS |
结果如下:
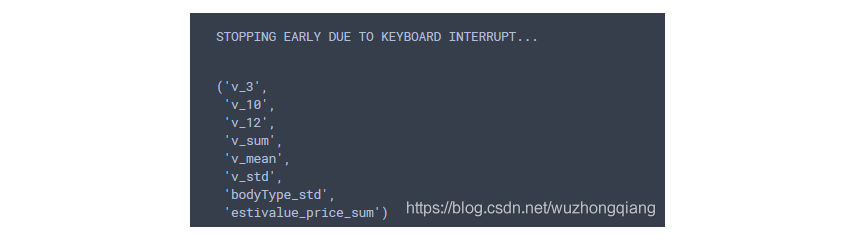
画出边际效应:
1 | # 画出边际效应 |
这个也是看选出的特征的重要性:
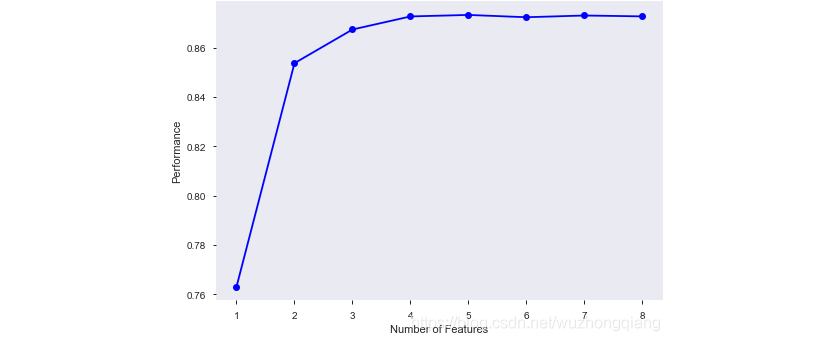
这样,根据我们使用的模型,我们可以对特征进行一个选择,综合上面的这几种方式,我们就可以把保留和删除的特征给选出来了,该删除的可以删除了。
如果真的这样尝试一下,就会发现保留的特征里面, v_std, v_3, used_time, power, kilometer, estivalue等这些特征都在,虽然我们不知道v系列特征的含义,但是汽车使用时间,发动机功率,行驶公里, 汽车使用时间的分箱特征其实对price的影响都是比较大的。
下面在介绍一种嵌入式的方式, 当然这里我没用,因为我不打算后面的模型用线性模型来做。但这种思路得知道
3.3 嵌入式
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。而嵌入式特征选择在学习器 训练过程中自动地进行特征选择。嵌入式选择最常用的是L1正则化与L2正则化。在对线性回归模型加入两种正则化方法后,他们分别变成了岭回归与Lasso回归。
主要思想:在模型既定的情况下学习出对提高模型准确性最好的特征。也就是在确定模型的过程中,挑选出那些对模型的训练有重要意义的特征。
主要方法:简单易学的机器学习算法–岭回归(Ridge Regression),就是线性回归过程加入了L2正则项。
L2正则化在拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参 数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性 回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移 得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』
L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择
这里简单介绍一下怎么使用,其实和上面机器学习模型的使用方法一样, 所以有时候这些方法没有必要严格的区分开:
1 | from sklearn.linear_model import LinearRegression, Ridge,Lasso |
4. PCA降维技术
我们通过上面的特征选择部分,可以选出更好的分析特征,但是如果这些特征维度仍然很高怎么办?
如果我们的数据特征维度太高,首先计算很麻烦,其次增加了问题的复杂程度,分析起来也不方便。这时候我们就会想是不是再去掉一些特征就好了呢? 但是这个特征也不是凭自己的意愿去掉的,因为盲目减少数据的特征会损失掉数据包含的关键信息,容易产生错误的结论,对分析不利。
所以我们想找到一个合理的方式,既可以减少我们需要分析的指标,而且尽可能多的保持原来数据的信息,PCA就是这个合理的方式之一。 关于PCA降维技术的原理,可以参考我的另一篇博客白话机器学习算法理论+实战之PCA降维, 这里只整理如何用, 但要注意一点, 特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,而PCA,将已存在的特征压缩,降维完毕后不是原来特征的任何一个,也就是PCA降维之后的特征我们根本不知道什么含义了
当然,针对这个比赛,也不打算使用PCA降维技术,因为如果做完了特征选择之后,就会发现特征的量不是那么多, 但我在这里用了一下,可以看看效果:
1 | from sklearn.decomposition import PCA |
上面假设我保留了10个特征,然后运行代码,一下子就成了10维的矩阵, 我们可以看一下X_new
这些数已经只能说尽可能的保留原有的数据信息,但是是什么含义,我们也不知道了,哈哈, 让模型自己估摸去吧。
特征工程之后,一定要记得保存结果到文件, 后面建立模型跑数据的话直接导入处理好的这份数据即可
5. 总结
终于到了总结这块, 今天整理了特征工程,特征工程是比赛中最至关重要的的一块,特别的传统的比赛,大家的模型可能都差不多,调参带来的效果增幅是非常有限的,但特征工程的好坏往往会决定了最终的排名和成绩。
下面来梳理一下上面的知识: 特征工程和数据清洗分不开, 特征工程部分包括特征构造, 特征筛选和降维等技术, 特征构造部分,我们需要发散思维,根据背景尽可能的构造特征出来,挖掘数据的潜在信息,当然,构造的时候,不同字段的特征得分开处理,毕竟处理方式不一样。 特征筛选部分,我们常用的技术有过滤式,包裹式和嵌入式筛选,过滤式就是在喂入模型之前,先根据变化程度和相关程度对特征进行一个剔除, 包裹式就是用模型的方式自己筛选特征,这个基于后面的模型, 嵌入式方式和包裹式差不多。 降维技术的话常用的PCA降维,降维的好处就是可以使数据尽量保留信息且维度变小,但失去了特征的可解释性,有利有弊吧。 最后来一张导图把知识拎起来:
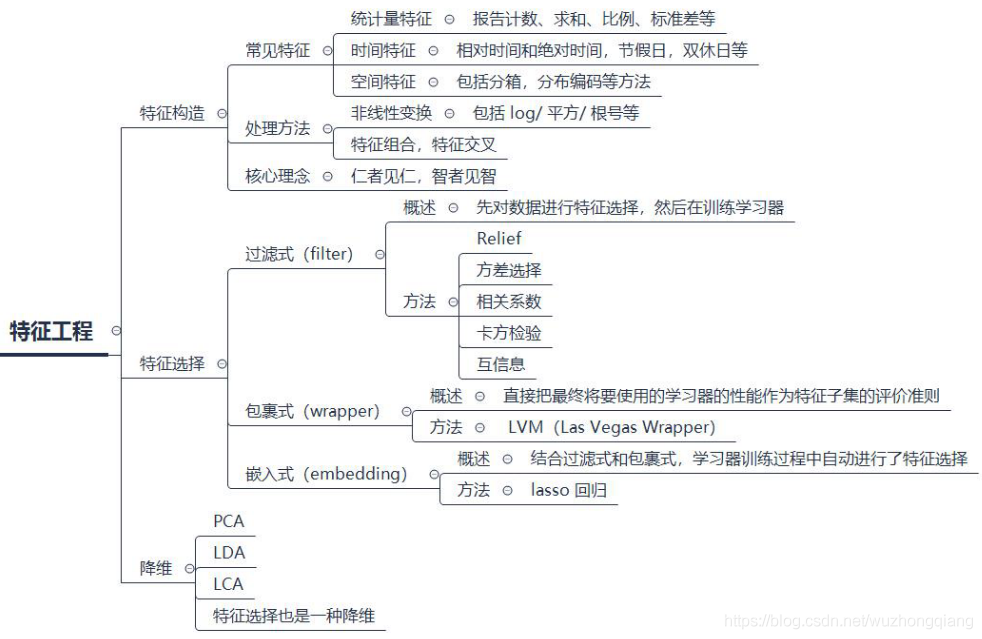
总的来说, 特征工程入门简单,但精通不容易。
一些tricks(来自Datawhale团队阿泽哥的分享):
- 有些比赛的特征是匿名特征,这导致我们并不清楚特征相互直接的关联性,这时我们就只有单纯基于特征进行处 理,比如装箱,groupby,agg 等这样一些操作进行一些特征统计,此外还可以对特征进行进一步的 log,exp 等 变换,或者对多个特征进行四则运算(如上面我们算出的使用时长),多项式组合等然后进行筛选。由于特性的 匿名性其实限制了很多对于特征的处理,当然有些时候用 NN 去提取一些特征也会达到意想不到的良好效果。
- 对于知道特征含义(非匿名)的特征工程,特别是在工业类型比赛中,会基于信号处理,频域提取,丰度,偏度 等构建更为有实际意义的特征,这就是结合背景的特征构建,在推荐系统中也是这样的,各种类型点击率统计, 各时段统计,加用户属性的统计等等,这样一种特征构建往往要深入分析背后的业务逻辑或者说物理原理,从而 才能更好的找到 magic。
- 当然特征工程其实是和模型结合在一起的,这就是为什么要为 LR NN 做分桶和特征归一化的原因,而对于特征 的处理效果和特征重要性等往往要通过模型来验证。
参考: