1. 写在前面
今天是数据挖掘入门系列的最后一篇文章模型融合技术大总结和结果部署, 一般来说,通过融合多个不同的模型,可能提升机器学习的性能,这一方法在各种机器学习比赛中广泛应用, 也是在比赛的攻坚时刻冲刺Top的关键,而融合模型往往又可以从模型结果,模型自身,样本集等不同的角度进行融合。 所以今天会从不同的角度介绍模型融合的技术,今天整理的这些技术在今后的比赛或者项目里面会非常的有用,既然是这个系列的最后一篇文章,就想着把这些技术整理的详细一些作为最后的压轴了,通过这篇文章,希望你能真正的理解模型结果层面的融合方式Voting和Averaging的原理、从样本集角度出发把模型进行集成的Boosting和Bagging的区别,以及更为强大的模型自身融合方法Stacking和Blending的原理和区别(其实后面这两个才是真正的模型融合,即将多个已经有较好效果的模型融合成更好的模型)。 在这个比赛中, 我尝试把baseline里面的xgb和lgb作为第一层, 然后把LinearRegressor作为第二层进行Stacking,最后再进行结果层面加权融合,效果又会有一个提升。所以今天的这些技术可以让模型发挥更大的作用, 当然这些技术不会仅适用于这个比赛。
首先,会针对不同的任务(分类/回归)从简单的加权融合开始, 介绍一下分类里面的投票方式(Voting)的原理和具体实现, 然后是回归里面的平均融合机制(Averaging), 其次简单的介绍一下Boosting和Bagging以及两者的关联,当然这个在这次不是重点,毕竟xgboost或者随机森林就已经用到了这种机制, 最后会整理这次的重头戏Stacking/Blending的原理,具体实现和两者的比较,Stacking方法在机器学习比赛中被誉为“七条龙神技”。听这个名字也知道这个技术的重要性了吧。这一块是这次融合技术的重点, 也是目前最常用的效果比较好的方式。 在收尾的时候,简单的介绍一下结果部署的问题,即如何保存辛辛苦苦训练好的模型,毕竟模型的训练是花费很长时间的,总不能每一次预测的时候都重新训练吧, 所以这也是比较重要的一步。
PS: 这次这个系列有一个特点就是层次性很强,毕竟是围绕着一个比赛进行展开。后面的每一篇都是基于前一篇文章过来的, 所以今天的整理是基于我们已经有了调参好的几个模型的基础之上,研究如何对这几个模型进行整合以发挥更大的性能,如果还没有对模型进行调参, 建议先学习一下前面的知识零基础数据挖掘入门系列(五) - 模型建立与调参,这里面通过实验也证明了一下调参对最后的结果影响也是很大。作为压轴, 这篇文章会很长,因为有些东西想借这个机会整理的详细些后面查阅的时候方便(很多知识面试的时候会涉及到),所以根据目录各取所需即可
大纲如下:
- 回归任务中的加权融合与分类任务中的Voting
- Boosting和Bagging的原理与对比
- Stacking/Blending构建多层模型(原理,实现和比较)
- 简单的结果部署方式
- 对本篇文章和整个系列的总结
Ok, let’s go!
开始之前,依然是先导入之前保存好的数据:
1 | # 导入数据, 并构造一个线下测试集 |
2. 回归任务中的加权融合与分类任务中的Voting(模型的结果层面的融合技术)
2.1 回归任务中的加权融合
给出的baseline里面最后的lgb和xgb的融合就使用了这种方式,当然这种方式也比较好理解,就是根据各个模型的最终预测表现分配不同的权重以改变其对最终结果影响的大小。对于正确率低的模型给予更低的权重,而正确率更高的模型给予更高的权重。 所以为了更简单的说明这个原理,这里给出了简单的例子,没有再用baseline的模型跑出结果再加权融合, 那样速度太慢了。 重点是get思想。
1 | #生成一些简单的样本数据, test_prei代表第i个模型的预测值 |
下面我们进行上面三个模型的加权融合,看看最终的效果:
1 | # 下面我们进行加权融合 |
其实这种加权融合的技术是从模型结果的层面进行的, 就是让每个模型跑一遍结果,然后把这个结果想办法融合起来, 当然融合起来的方式也不止有加权平均,还有一些特殊的方式,比如结果取平均, 取中位数等。 这里也给出取平均和中位数的方式,但是这个效果一般不如加权平均的效果好。
1 | ## 定义结果的mean平均函数 |
加权融合这个一般适用于回归任务中模型的结果层面, 那么分类任务中我们有没有类似的结果融合的方式呢? 那就是投票法voting了。
2.2 分类任务中的Voting
投票法(Voting)是集成学习里面针对分类问题的一种结果结合策略。基本思想是选择所有机器学习算法当中输出最多的那个类。 机器学习的算法有很多,对于每一种机器学习算法,考虑问题的方式都略微有所不同,所以对于同一个问题,不同的算法可能会给出不同的结果,那么在这种情况下,我们选择哪个算法的结果作为最终结果呢?那么此时,我们完全可以把多种算法集中起来,让不同算法对同一种问题都进行预测,最终少数服从多数,这就是集成学习的思路。
在不改变模型的情况下,直接对各个不同的模型预测的结果,进行投票或者平均,这是一种简单却行之有效的融合方式。比如对于分类问题,假设有三个相互独立的模型,每个正确率都是70%,采用少数服从多数的方式进行投票。那么最终的正确率将是:
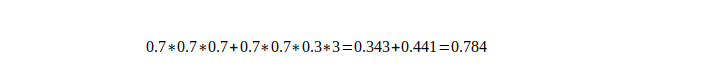
即结果经过简单的投票,使得正确率提升了8%。这是一个简单的概率学问题——如果进行投票的模型越多,那么显然其结果将会更好。但是其前提条件是模型之间相互独立,结果之间没有相关性。越相近的模型进行融合,融合效果也会越差。 有人问这个是怎么算的?其实就是在少数服从多数算正确率 (三个0.7相乘,就是我三个模型都预测对的概率, 后面的那部分就是我有两个模型预测对了,一个预测错了,那我还是挺预测对了的,这个概率就是后面那个,是因为这种情况有三种), 具体详情可以参考这篇博客:模型融合方法学习总结, 这里就不对原理部分解释太多了,少数服从多数的投票方式也比较好理解,关键我们怎么实现这种方式呢?
sklearn中的VotingClassifier是投票法的实现, 投票法的输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用前者进行投票叫做硬投票(Majority/Hard voting),使用后者进行分类叫做软投票(Soft voting)。 这个是通过voting参数进行控制。硬投票其实就是少数服从多数的原则, 但是有时候少数服从多数并不适用,那么更加合理的投票方式,应该是有权值的投票方式,在现实生活中也有这样的例子,比如在唱歌比赛中,专业的评审的投票分值就应该比观众的投票分值高。
我们简单的理解一下硬投票和软投票,详情参考集成学习voting Classifier在sklearn中的实现:


下面我们就以鸢尾花数据集简单的看一下投票算法和单个模型的效果对比:
1 | from sklearn.datasets import load_iris |
是不是投票的方式也挺简单的啊, 但是这种方法其实有一点风险,就是万一融合的模型中有些结果并不是很好,那么会整体把结果往下拉,即可能得不到最好的结果。 这个按照我们投票的方式其实也是有这样的一个风险啊, 投的最多的那个结果一定是一个好的结果吗? 不一定吧!
所以这就是模型结果层面融合的两种方式了, 回归任务上一般就是将多个模型的结果进行加权融合或者取平均等已获得更好的效果,而分类任务上可以采用投票表决的方式获取最终的结果。
3. Boosting和Bagging的原理与对比
介绍完了模型结果层面的两种方式之后,再介绍一下Boosting和Bagging, 这两个都是从样本集的角度考虑把多个弱模型集成起来的一种方式, 只不过两者在集成的时候还是有些区别的。这两个其实不是那么神秘了,我们使用的xgb,lgb就属于Boosting方法,而随机森林就是Bagging方式, 所以下面重点看看细节和原理,关于数学和公式推导这些底层的东西,下面不会涉及到。
3.1 Boosting
Boosting是一种将各种弱分类器串联起来的集成学习方式,每一个分类器的训练都依赖于前一个分类器的结果,顺序运行的方式导致了运行速度慢。和所有融合方式一样,它不会考虑各个弱分类器模型本身结构为何,而是对训练数据(样本集)和连接方式进行操纵以获得更小的误差。但是为了将最终的强分类器的误差均衡,之前所选取的分类器一般都是相对比较弱的分类器,因为一旦某个分类器较强将使得后续结果受到影响太大。所以多用于集成学习而非模型融合(将多个已经有较好效果的模型融合成更好的模型)。
这里拿一张图片来简单的看一下(摘自知乎专栏 《【机器学习】模型融合方法概述》③处引用的加州大学欧文分校Alex Ihler教授PPT)
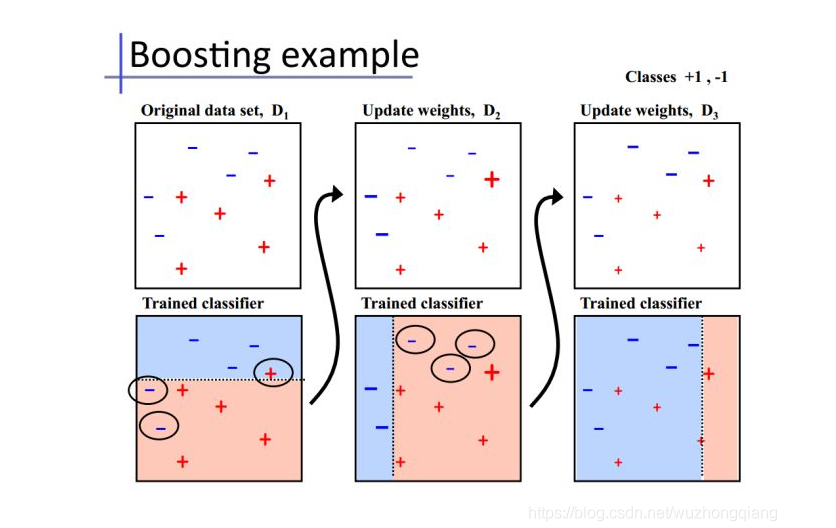
oosing方式理解起来,比如我想用很多个模型M1, M2, …Mn去预测二手车的价格, 但是我这些模型具体工作是这样安排的, 我让M1先去训练然后对价格进行预测, 等M1预测完了之后, M2训练的时候是对M1训练的改进和提升,即优化M1没有做好的事情, 同样M3会基于M2的结果再次进行优化,这样一直到Mn。 看到这个串联的关系了吗? 其实就是在训练的过程中这 K 个模型之间是有依赖性的,当引入第 K 个模型的时候,实际上是对前 K-1 个模型的优化。最终的预测结果是这K个模型结果的一个大组合。 这样形成了预测结果的增强。
这里再多说一句吧, 我们知道Boosting家族里面有代表的像AdaBoost, GBDT, xgboost, lightgbm等,但是这些模型虽然都是串联集成多个弱分类器但是之间还是有区别的,又可以分成AdaBoost流派和GBDT流派, 比如AdaBoost,在引入M2的时候,其实它关注的是M1预测不好的那些样本, 这些样本如果M2在训练的时候,就会加大权重。 后面的模型引入也都是这个道理,即关注前面模型预测不好的那些样本。 而GBDT,包括后面的xgboost这些,他们是更加聚焦于残差,即M2引入的时候,它关注的是M1的预测结果与标准结果之间的那个差距, 它想减少的是这个差距,后面的模型引入也是这个道理,即关注前面模型预测结果与标准答案之间的差距,然后一步一步的进行缩小。xgboost其实也是聚焦残差,只不过和GBDT的不同是减小这个残差的这种策略,GBDT是用模型在数据上的负梯度作为残差的近似值,从而拟合残差。XGBoost也是拟合数据残差,并用泰勒展开式(二阶泰勒展开式)对模型损失残差的近似,同时在损失函数上添加了正则化项。 lgb的话和xgboost的原理是一样的,只不过又在模型的训练速度上进行了优化,采用了直方图的决策树算法使得收敛更快。 这个在这里只是梳理一下它们之间的这种逻辑关系,详细原理就不在这里讨论了。因为每一个模型都是一个很长的故事了。
3.2 Bagging
Bagging是Bootstrap Aggregating的缩写。这种方法同样不对模型本身进行操作,而是作用于样本集上。采用的是随机有放回的选择训练数据然后构造分类器,最后进行组合。与Boosting方法中各分类器之间的相互依赖和串行运行不同,Bagging方法中基学习器之间不存在强依赖关系,且同时生成并行运行。
其基本思路为:
- 在样本集中进行K轮有放回的抽样,每次抽取n个样本,得到K个训练集;
- 分别用K个训练集训练得到K个模型。
- 对得到的K个模型预测结果用投票或平均的方式进行融合。
在这里,训练集的选取可能不会包含所有样本集,未被包含的数据成为包/袋外数据,可用来进行包外误差的泛化估计。每个模型的训练过程中,每次训练集可以取全部的特征进行训练,也可以随机选取部分特征训练,例如极有代表性的随机森林算法就是每次随机选取部分特征。
下面仅从思想层面介绍随机森林算法:
- 在样本集中进行K轮有放回的抽样,每次抽取n个样本,得到K个训练集,其中n一般远小于样本集总数;
- 选取训练集,在整体特征集M中选取部分特征集m构建决策树,其中m一般远小于M;
- 在构造每棵决策树的过程中,按照选取最小的基尼指数进行分裂节点的选取进行决策树的构建。决策树的其他结点都采取相同的分裂规则进行构建,直到该节点的所有训练样例都属于同一类或者达到树的最大深度;
- 重复上述步骤,得到随机森林;
- 多棵决策树同时进行预测,对结果进行投票或平均得到最终的分类结果。
多次随机选择的过程,使得随机森林不容易过拟合且有很好的抗干扰能力。
3.3 Boosting和Bagging的比较
下面我们就从不同的角度看看Boosting和Bagging的比较(这个在面试中经常会被问到)

Bagging方法主要通过降低Variance来降低error, Boosting方法主要通过降低Bias来降低error


坏了, 感觉这个地方写多了, 毕竟本来想简单整理这个地方来,下面才是重点,所以这个就到此为止吧, 详情可参考博客:模型融合方法学习总结
下面就是重头戏了 😉
4. Stacking/Blending构建多层模型(原理,实现和比较)
接下来介绍在各种机器学习比赛中被誉为“七头龙神技”的stacking方法, 但因其模型的庞大程度与效果的提升程度往往不成正比, 所以一般很难应用于实际生产中。
4.1 Stacking
Stacking模型的本质是一种分层的结构,用了大量的基分类器,将其预测的结果作为下一层输入的特征,这样的结构使得它比相互独立训练模型能够获得更多的特征。
下面以一种易于理解但不会实际使用的两层的stacking方法为例,简要说明其结构和工作原理:(这种模型问题将在后续说明), 详细内容参考博客:模型融合方法学习总结

假设我们有三个基模型M1,M2,M3和一个元模型M4, 有训练集train和测试集test,我们进行下面的操作(为了便于理解,我这里还给出了代码的形式):
用训练集train训练基模型M1(M1.fit(train)), 然后分别在train和test上做预测, 得到P1(M1.predict(train))和T1(M1.predict(test)
用训练集train训练基模型M2(M2.fit(train)), 然后分别在train和test上做预测, 得到P2(M2.predict(train))和T2(M2.predict(test)
用训练集train训练基模型M3(M3.fit(train)), 然后分别在train和test上做预测, 得到P3(M3.predict(train))和T3(M3.predict(test)
这样第一层的模型训练完毕。 接下来:
- 把P1, P2, P3进行合并组成新的训练集train2, 把T1, T2, T3进行合并组成新的测试集test2
- 用新的训练集train2训练元模型M4(M4.fit(train2)), 然后再test2上进行预测得到最终的预测结果Y_pre(M4.predict(test2))
这样第二层训练预测得到了最终的预测结果。(可以结合着上面这张图来看更加清晰),这就是我们两层堆叠的一种基本的原始思路想法。在不同模型预测的结果基础上再加一层模型,进行再训练,从而得到模型最终的预测。
Stacking本质上就是这么直接的思路, 但是直接这样有时对于如果训练集和测试集分布不那么一致的情况下是有一点问题的, 其问题在于我们用训练集训练原始模型, 又接着用训练的模型去预测训练集,这不明摆着会过拟合训练集吗? 因此现在的问题变成如何降低再训练的过拟合性, 这里一般有两种方式:
- 次级模型尽量选择简单的线性模型
- 利用第一层训练模型使用交叉验证的方式
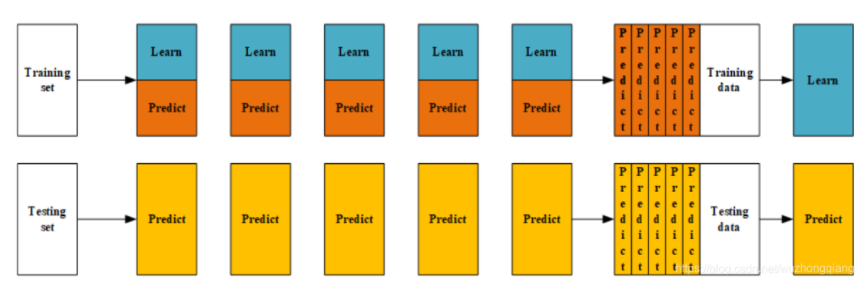
第一种方式比较容易理解, 我们重点来看看第二种方式到底是怎么做的, 先来一个图体会一下:
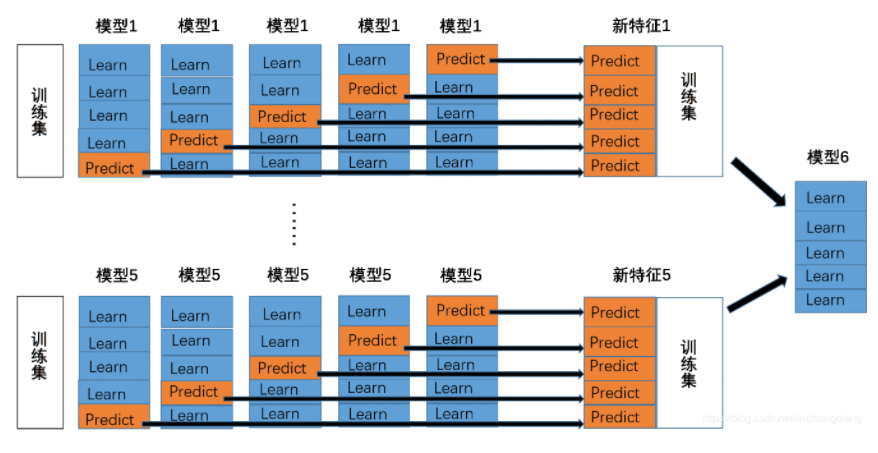
我们就拿5折交叉验证为例, 其实在做这样的事情:
首先我们将训练集分成5份(5折交叉验证)
对于每一个基模型i来说, 我们用其中的四份进行训练, 然后用另一份训练集作为验证集进行预测得到Pi的一部分, 然后再用测试集进行预测得到Ti的一部分,这样当五轮下来之后,验证集的预测值就会拼接成一个完整的Pi, 测试集的label值取个平均就会得到一个Ti(看下面的预测示意图)。
这些Pi进行合并就会得到下一层的训练集train2, Ti进行合并就得到了下一层的测试集test2。
利用train2训练第二层的模型, 然后再test2上得到预测结果,就是最终的结果。
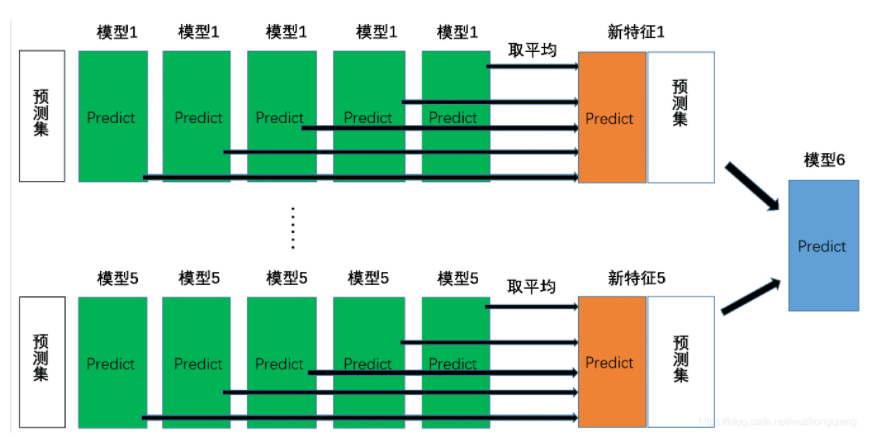
所以, Stacking的整理过程原理其实可以用下面的图进行表示(是不是和某些博客记录的不太一样? 看了Blending的那个图就明白了)
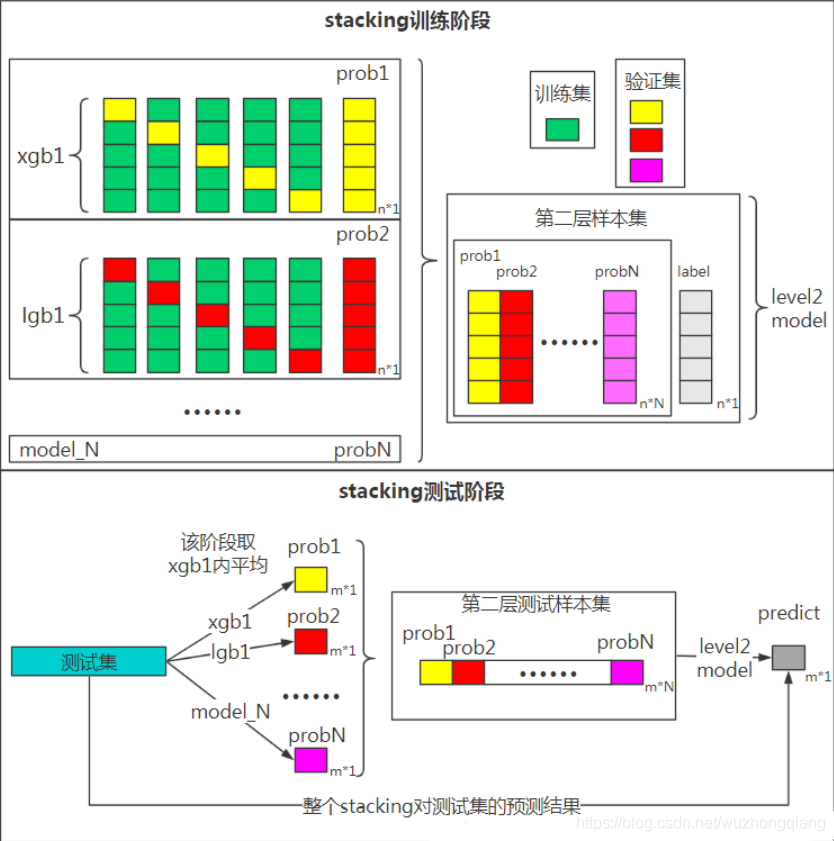
关于Stacking的原理部分就整理这么多吧,希望上面的这个图能给你眼前一亮的感觉, 当然这些原理部分都来自于上面给出的链接,详细情况可以看看那里面的描述, 我觉得这个图就能说明一切了。 明白了原理之后,我主要讲如何实现。毕竟理论到处有, 但实践是王道
那么具体实现应该如何实现呢? 首先我会拿上面加权平均的那个回归例子来看一下stacking具体应该怎么实现,然后我会介绍一款强大的stacking利器mlxtend库里面的StackingCVRegressor并使用它融合我们调参好的xgb和lgb用于我们的这个比赛。 然后我们再看看stacking怎么用于分类的任务中,依然是同样的逻辑,先自己实现stacking, 然后使用mlxtend里面的StackingClassifier实现stacking,所以这是下面这一块的逻辑, stacking分别用于回归和分类任务,在每一个任务中先基于原理自己实现,然后学会掉包,前者为了更加深入理解stacking,后者便于实际应用。
4.1.1 回归中的Stacking
我们先拿上面那个回归的例子来看看Stacking的效果,
1 | # 生成一些简单的样本数据, test_prei代表第i个模型的预测值 |
这里的逻辑就是把第一层模型的在训练集上的预测值当做第二层训练集的特征, 第一层模型在测试集上的预测值当做第二层测试集的特征, 然后建立第二层的逻辑回归模型进行训练。
以发现模型结果相对于之前有进一步的提升, 这时候我们需要注意的是,对于第二层的Stacking的模型不宜选取的过于复杂, 否则会导致模型在训练集上过拟合, 从而使得在测试集上并不能取得很好地效果。
接下来介绍一款强大的stacking工具StackingCVRegressor, 这是一种集成学习的元回归器, 首先导入:
from mxltend.regressor import StackingCVRegressor
在标准 stacking程序中,拟合一级回归器的时候,我们如果使用第二级回归器的输入的相同训练集,这很可能会导致过度拟合。 然而,StackingCVRegressor使用了‘非折叠预测’的概念:数据集被分成k个折叠,并且在k个连续的循环中,使用k-1折叠来拟合第一级回归器(即k折交叉验证的stackingRegressor)。在每一轮中(一共K轮),一级回归器然后被应用于在每次迭代中还未用过的模型拟合的剩余1个子集。然后将得到的预测叠加起来并作为输入数据提供给二级回归器。在StackingCVRegressor的训练完之后,一级回归器拟合整个数据集以获得最佳预测。这其实就是上面我们介绍的原理。
那么关键是怎么用呢?好使的的要哭, 直接调用API接口:

下面就是针对这个比赛,我们进行模型的融合:
1 | # 使用lgb和xgb那两个模型 |
这样我们就定义好了xgb, lgb,以及融合的模型, 我们下面跑一些看看效果:
1 | # LGB |
可以发现, 经过融合, 使得模型的效果有了提升, 这时候如果再考虑加权融合,或许效果会更好。
下面看看Stacking如何用到分类的任务中。
4.1.2 分类中的Stacking
这里依然是以鸢尾花数据集分类为例, 首先自己先实现一下stacking加深理解,然后使用mlxtend.classifier.StackingClassifier实现模型的融合。
1 | from sklearn.ensemble import RandomForestClassifier |
上面这个是自己实现的两层模型的融合, 可以发现写起来还是挺麻烦的,关键就是那个两层循环。 下面看看用工具来实现会不会代码量会少一些。
StackingClassifierAPI及参数如下:

当然这里我为了有个交叉验证的效果,用的StackingCVClassifier,参数和上面基本一样,不过有个cv参数,可以实现交叉验证的效果。
1 | from mlxtend.classifier import StackingCVClassifier |
是不是代码量少了很多了? 好了,到这里就把Stacking的原理和基本实现都整理完了, 趁着热乎,下面再介绍一个和Stacking很相似的一种方式, 叫做Blending,有人说Blending的融合是弱化版的Stacking,是切分样本集为不相交的子样本然后用各个算法生成结果再融合,并且不适用交叉验证,这种方法不能够最大限度的利用数据,而Stacking是得到各个算法训练全样本的结果再用一个元算法融合这些结果,效果会比较好一些,它可以选择使用网格搜索和交叉验证。
是不是有点好奇了呢? 我们下面看看具体细节吧。
4.2 Blending
Blending是一种和Stacking很相像的模型融合方式,它与Stacking的区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集(留出集),例如30%的训练数据(类似于把原始的训练集先分成两部分, 比如70%的数据作为新的训练集, 剩下的30%的数据作为测试集), 但是通过查看资料,好像是有两个版本, 下面分别介绍一下。
4.2.1 Blending版本一(单纯的Holdout)
一个版本就是单纯的Holdout集,就是我直接把训练集分成两部分,70%作为新的训练集, 30%作为测试集,然后用这70%的训练集分别训练第一层的模型,然后在30%的测试集上进行预测, 把预测的结果作为第二层模型的训练集特征,这是训练部分。 预测部分就是把真正的测试集先用第一层的模型预测,把预测结过作为第二层测试集的特征进行第二层的预测。 过程图长下面这个样子:
看这个图应该很容易理解这个意思了。 这种方法实现起来也比较容易。基本上和stacking的代码差不多,只不过少了内层的循环而已,毕竟每个模型不用交叉验证了。
1 | #创建训练的数据集 |
4.2.2 Blending版本二(Holdout交叉)
第二个版本的话依然是有一个Holdout集合,但是引入了交叉验证的那种思想,也就是每个模型看到的Holdout集合并不一样。即每个模型会看到这个30%的数据会不一样,说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。第二阶段的stacker模型就基于第一阶段模型对这30%训练数据的预测值进行拟合。
我们在第一层中, 用70%的训练集训练多个模型, 然后去预测那30%的数据得到预测值Pi, 同时也预测test集得到预测值Ti。 这里注意,那30%的数据每个模型并不是一样,也是类似于交叉验证的那种划分方式,只不过stacking那里是每个模型都会经历K折交叉验证,也就是有多少模型,就会有多少次K折交叉验证,而blending这里是所有模型合起来只经历了一次K折交叉验证(说的有点绕,看下图就容易懂了)
第二层中,我们就直接用30%数据在第一层预测的结果Pi进行合并, 作为新的训练集train2, test集的预测值Ti合并作为新的测试集test2, 然后训练第二层的模型。
Blending的过程训练和预测过程可以使用下图来表示:
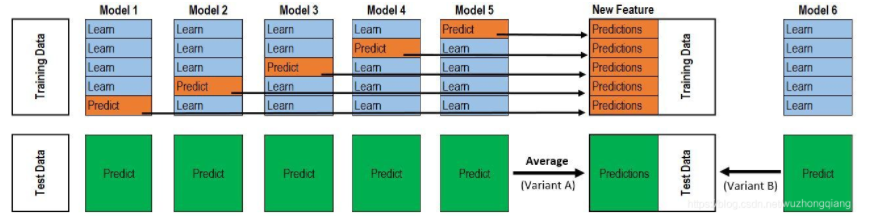
这个图有没有点似曾相识的感觉呢? 这个能看出和stacking之间的区别来吗? 需要注意的是,网上很多文章在介绍Stacking的时候其实用的是Blending的图, 所以这里要看好了,两者还是有些区别的。
那么究竟有什么区别呢?

有文章说这两种技术所得的结果都相差不多,如何选择取决于个人喜好。如果难以抉择的话,可以同时使用两种技术并来个第三层将其结果合并起来。当然,Blending没有找到实现好的工具,得需要自己写。
1 | # 模型融合中用到的单个模型 |
到这里, 基本上就把模型融合的重头戏整理完了, 这部分内容还是有点多的, 最后总结部分会再次梳理逻辑。 其实理清楚逻辑这部分的知识就容易拎起来了, 以后需要的时候再回来查相应的部分知识就可以了。下面再介绍一些其他的方法。
5. 一些其他方法(Stacking变化)
模型融合的方式已经整理完了,在结束之前,还有一种比较好的训练思路也介绍一下,就是将特征放进模型中预测, 并将预测结果变化作为新的特征加入原有的特征中, 再经过模型预测结果(Stacking变化), 可以反复预测多次将结果加入最后的特征中。
1 | def Ensemble_add_feature(train,test,target,clfs): |
好了,关于模型的融合技巧和思路就基本上搞定了, 马上就到了尾声, 再坚持一会, 在结束之前,还想介绍一点结果的部署相关的知识,说白了,就是保存模型和导入模型。 因为我们训练一次模型也挺不容易的,尤其是这个比赛中, 数据量很大,模型如果很复杂,稍微训练一次就需要5-6个小时, 这时候我们最好是保存一下我们的模型, 以防下一次用的时候可以直接用。
5. 简单的结果部署
结果部署这块介绍两种方式,一种是通过pickle序列化和反序列化机器学习模型,一种是joblib序列化和反序列化。
1.通过pickle序列化和反序列化机器学习的模型
pickle是标准的Python序列化的方法, 可以通过它来序列化机器学习算法生成的模型。并且将其保存到文件当中,当需要对新数据进行预测时,将保存在文件中的模型发序列化,并用其来预测新数据的结果。
1 | import pickle |
2.通过joblib序列化和反序列化机器学习的模型
joblib是SciPy生态环境的一部分, 提供了通用的工具来序列化Python的对象和反序列化Python的对象。通过joblib序列化对象时采用Numpy的格式保存数据,对某些保存数据到模型的算法非常有效。
1 | #第二种模型的存储与导入方式 - sklearn的joblib |
6. 总结
终于到总结了, 这篇文章作为数据挖掘入门系列的压轴, 内容还是很多的,先总的梳理一下这篇文章的内容, 这篇文章是基于已经调参好的模型去研究如何发挥出模型更大的性能。 从模型的结果, 样本集的集成和模型自身融合三个方面去整理, 模型的结果方面,对于回归问题,我们可以对模型的结果进行加权融合等方式使得结果更好, 对于分类问题,我们可以使用Voting的方式去得到最终的结果。 样本集的集成技术方面,我们学了Boosting和Bagging方式, 都是把多个弱分类器进行集成的技术, 但是两者是不同的。 模型自身的融合方面, 我们学习了Stacking和Blending的原理及具体实现方法,介绍了mlxtend库里面的模型融合工具。 最后又介绍了点模型保存的知识。 下面依然是一张导图把知识拎起来:
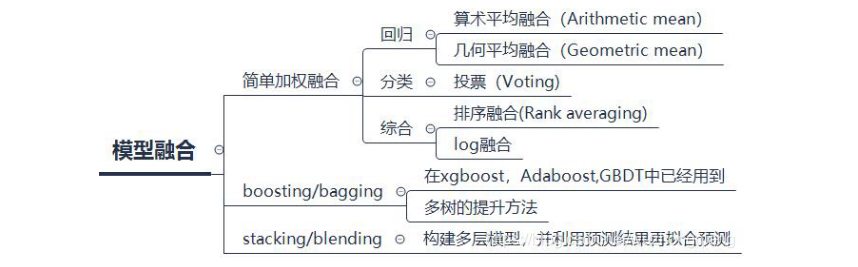
今天的这部分内容很多,不要奢望于读一遍就能把它记住, 即使我这样整理一遍,我再回想,依然是只有一个框架和大体的原理知识,细节部分也没法掌握住。 所以如果想熟记于心,我觉得最好的方式还是得不停的去用, 去实践和思考。 然后遇到不理解知识的回来查,查完再去用,这样反复多遍,这些知识就可以变成自己的了。
下面是关于这部分的经验总结(来自Datawhale团队ML67大神)
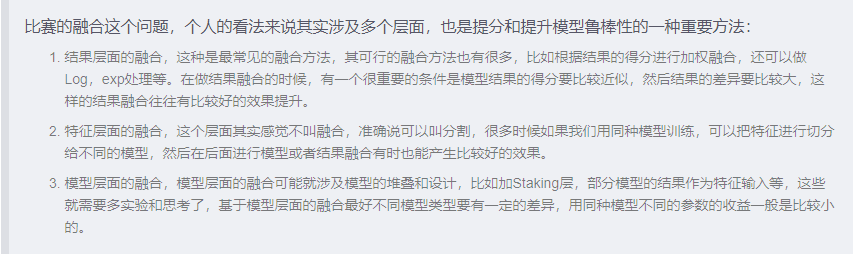
参考:
PS: 本次数据挖掘学习,专题知识将在天池分享,详情可关注公众号Datawhale。
历经15天,围绕着一个二手车价格预测的比赛,终于把数据挖掘入门系列的知识点整理完毕, 这次多亏了Datawhale举办的数据挖掘这次专题学习,才让我有这样一个机会学习和整理,因为数据挖掘知识点很杂, 所以之前就一直想着抽出时间来整理整理所学的知识,结果总是拖延和告诉自己没有时间,这次终于在Datawhale组织下把这块知识整理完毕, 至少有了一个基本的框架在这里。 这15天走来,收获很大,不仅是知识层面,比赛层面那么简单,更有幸认识了很多伙伴和志同道合的朋友, 依然是那句话一个人或许会走的很快,但一群人可以走的更远, 所以这次意识到组队学习的重要性和有趣性。
关于本次系列, 我在这里稍微的梳理一下逻辑,这个系列我称之为零基础数据挖掘入门系列,围绕着一个比赛进行展开的, 第一篇文章叫做赛题的理解,其实是一个热身,只是熟悉了一下这个赛题在做什么事情,如何分析一个赛题等。 第二篇文章叫做数据探索性分析, 从这里开始进入正题,这一块从数据初识,感知,不惑,洞玄,知命五个角度去认识我们的数据,和数据交朋友,目的就是发现数据存在的一些问题。 第三篇文章叫做数据的清洗和转换,这一块的任务是解决数据存在的一些问题, 比如缺失,异常,偏斜等。 第四篇文章叫做特征工程,这一块主要是基于清洗好的数据进一步挖掘信息,基于背景知识,对特征进行各种组合和挖掘,这一块是非常重要的部分。 第五篇文章叫做模型的建立和调参,这一块任务是基于已经处理好的数据进行模型的建立和分析,选出优秀的模型并且调好参数,技巧也是很多,也是非常重要的一部分。 第六篇文章叫做模型的融合和结果部署,是基于调参好的模型去研究如何进一步发挥模型的性能,通过各种组合的方式。 这就是这个系列的逻辑关系了,可以帮助更好的理解每一篇到底是干什么的以及每一篇之间的关系。
通过这六篇文章,应该是可以走进数据挖掘的大门并且去尝试一个数据比赛了,当然,我们不能奢求简单的读一遍就可以记住这些知识,因为每一篇都是万字长文,每一篇都蕴含着丰富的知识点和细节,即使我这样整理一遍,我也没法全部熟记于心, 但我希望伙伴们读完之后能有一个框架在自己的脑海中, 然后通过后面不断的学习和锻炼, 不断的查阅和思考,去弥补这个框架中的模糊,只有多动手,多尝试才能最终变成自己的知识。 这些知识如果想记住,依然是那简单的六个字无它, 唯手熟尔。
当然,这个系列对我来说也并不意味着结束, 反而算是一个新的开始,学习这个东西是没有止境的, 这个系列也只是整理了一些皮毛并且只涉及到了回归的一些内容且不全,还会继续更新(后面有机会,还想着围绕一个分类的比赛再整理一波分类的知识,这个看情况和时间)。 关于数据挖掘,后面还有更好玩的东西等着我们探索, 由于我目前也是小白,上面的知识点理解上难免会有疏漏和误解, 如果伙伴们发现了,希望帮我指出来。 也希望能帮助到更多的伙伴, 如果对这些东西感兴趣,也欢迎私信或者加V交流(学习知识是一方面, 多个朋友或者同路的人岂不是更好 😉)。
这个比赛的知识点就整理到这里了, 由于这些天一直忙着整理这个系列知识, 二手车价格预测的比赛倒是没好好研究呢,只是粗略的做了些东西,不过像我说的,掌握了这些知识之后并用到这个比赛,进前100是没有问题的, 接下来的时间,就打算拿着这些知识去好好的实战一波了, 也欢迎留言交流,咱们一起Rush! 😉
关于这个系列的代码,我后期整理完毕会放上来!