1. 写在前面
很多高级的机器学习模型(xgboost, lgb, cat)和神经网络模型, 它们相对于普通线性模型在进行预测时往往有更好的精度,但是同时也失去了线性模型的可解释性, 所以这些模型也往往看作是黑箱模型, 在2017年,Lundberg和Lee的论文提出了SHAP值这一广泛适用的方法用来解释各种模型(分类以及回归), 使得前面的黑箱模型变得可解释了,这篇文章主要整理一下SHAP的使用, 这个在特征选择的时候特别好用。
这次整理, 主要是在xgboost和lgb等树模型上的使用方式, 并且用一个真实的数据集进行演示, 详细的内容参考SHAP的原地址:https://github.com/slundberg/shap
2. 简单回忆特征选择
一般在机器学习中, 我们想看哪些特征对目标变量有重要作用的时候, 常用的有下面几种方式:
求相关性
这个往往可以判别出某些特征和目标变量之间是否有线性相关关系, 从而去看某些特征的重要性程度, 一般我们喜欢保留线性相关关系大的一些特征。包裹式
这个说白了, 就是直接把数据放到像xgboost和lgb这种模型中训练, 训练完了之后, 再用feature importance可视化每个特征的重要性, 从而看哪些特征对最终的模型影响较大, But, 这种方式无法判断特征与最终预测结果的关系是如何的, 即不知道怎么影响的,待会给出真实例子来演示。permutation importance
这是在kaggle比赛中学习到的一种特征筛选的方式, 所以也借机整理一下, 这个方式还是很不错的, 这个思路就是用所有的特征训练模型, 然后再在验证集上得到验证误差, 然后遍历每一个特征, 随机打乱这个特征的值, 再计算验证误差, 用后面的验证误差和前面的验证误差进行对比, 就可以看出该特征对于减少误差的贡献程度, 也就能看出特征的重要性。这里整理一下这种方式(思路):
1 | # 首先我们先建立一个模型, 然后写一个训练模型的函数 |
这个方式,其实就能够既判断出特征的重要性, 也能判断出特征是怎么影响模型的。
而有了SHAP之后, 貌似是这一切变得更加简单。
下面通过一个真实的例子, 来看一下之前的Feature importance和SHAP的具体使用, 这里用的数据集是一个数据竞赛的数据集
3. Feature importance VS SHAP
3.1 Feature importance
在SHAP被广泛使用之前,我们通常用feature importance或者partial dependence plot来解释xgboost等机器学习模型。 feature importance是用来衡量数据集中每个特征的重要性。每个特征对于提升整个模型的预测能力的贡献程度就是特征的重要性。
下面根据这个案例来看看, 先导入包和数据, 然后训练xgb和lgb。
1 | import xgboost as xgb |
下面我们可以画出每个特征的重要性程度:
1 | # 获取feature importance |
结果如下:
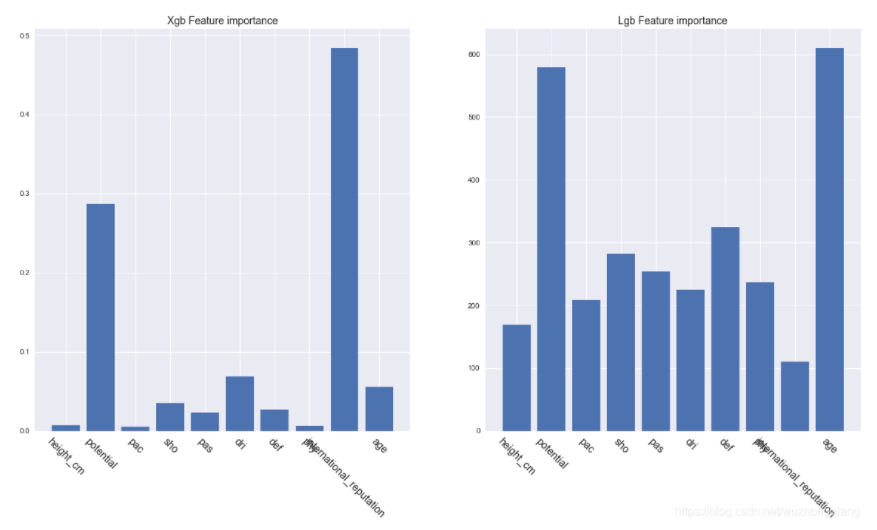
对于xgboost来说,我们可以看出国际知名度、潜力和年龄是影响球员身价最重要的三个因素。而LGB来说, 潜力和年龄很重要, 但是这些因素和身价是正相关、负相关还是其他更复杂的相关性,我们无法从上图得知。我们也无法解读每个特征对每个个体的预测值的影响。
3.2 SHAP value
SHAP的名称来源于SHapley Additive exPlanation。
Shapley value起源于合作博弈论。比如说甲乙丙丁四个工人一起打工,甲和乙完成了价值100元的工件,甲、乙、丙完成了价值120元的工件,乙、丙、丁完成了价值150元的工件,甲、丁完成了价值90元的工件,那么该如何公平、合理地分配这四个人的工钱呢?Shapley提出了一个合理的计算方法(有兴趣地可以查看原论文),我们称每个参与者分配到的数额为Shapley value。

那么怎么用呢?
3.3 SHAP的python实现
Python中SHAP值的计算由shap这个package实现,可以通过pip install shap安装。
1 | import shap |
3.3.1 单个样本的SHAP的值
可以随机检查某一个球员身价的预测值以及各个特征对其预测值的影响。
1 | j = 30 |
结果如下:
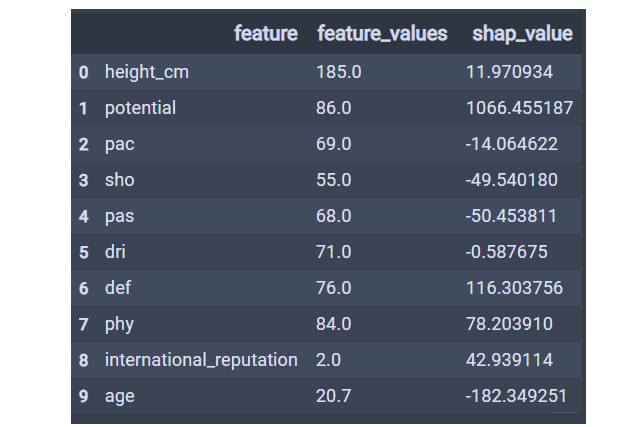
1 | # 一个样本中各个特征SHAP的值的和加上基线值应该等于该样本的预测值 |
shap还提供了强大的数据可视化功能。
1 | shap.initjs() |
结果如下:
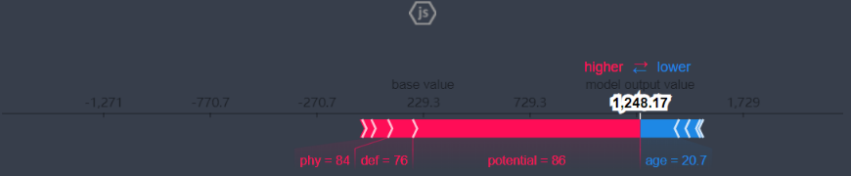
蓝色表示该特征的贡献是负数, 红色表示该特征的贡献是正数。
3.3.2 对特征的总体分析
除了能对单个样本的SHAP值进行可视化之外,还能对特征进行整体的可视化。
1 | shap.summary_plot(shape_values, data[cols]) |
结果如下:
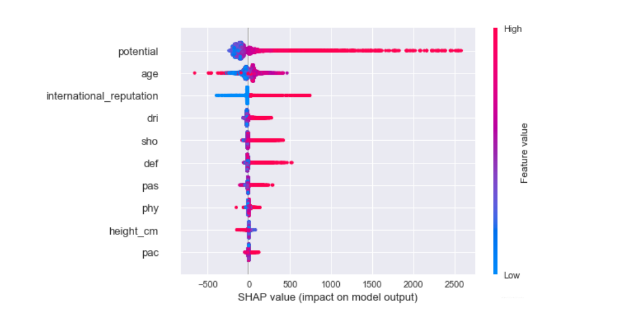
图中每一行代表一个特征,横坐标为SHAP值。一个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝说明特征本身数值越小。
我们可以直观地看出潜力potential是一个很重要的特征,而且基本上是与身价成正相关的。年龄age也会明显影响身价,蓝色点主要集中在SHAP小于0的区域,可见年纪小会降低身价估值,另一方面如果年纪很大,也会降低估值,甚至降低得更明显,因为age这一行最左端的点基本上都是红色的。
我们也可以把一个特征对目标变量影响程度的绝对值的均值作为这个特征的重要性。因为SHAP和feature_importance的计算方法不同,所以我们这里也得到了与前面不同的重要性排序。
1 | shap.summary_plot(shape_values, data[cols], plot_type='bar') |
结果如下:

3.3.3 部分依赖图
SHAP也提供了部分依赖图的功能,与传统的部分依赖图不同的是,这里纵坐标不是目标变量y的数值而是SHAP值。
1 | shap.dependence_plot('age', shape_values, data[cols], interaction_index=None, show=False) |
结果如下:
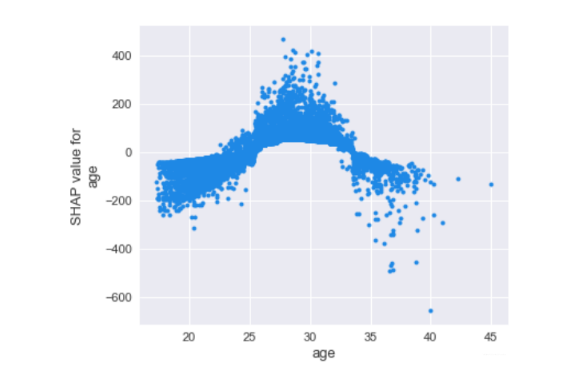
年纪大概呈现出金字塔分布,也就是25到32岁这个年纪对球员的身价是拉抬作用,小于25以及大于32岁的球员身价则会被年纪所累。
3.3.4 对多个变量的交互进行分析
可以多个变量的交互作用进行分析。
1 | shap_interaction_values = shap.TreeExplainer(model1).shap_interaction_values(data[cols]) |
结果如下:
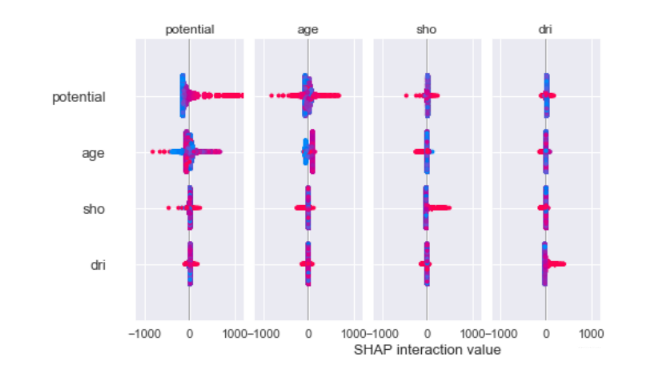
3.3.5 两个变量交互下的变量对目标值的影响
1 | shap.dependence_plot('potential', shape_values, data[cols], interaction_index='international_reputation', show=False) |
结果如下:
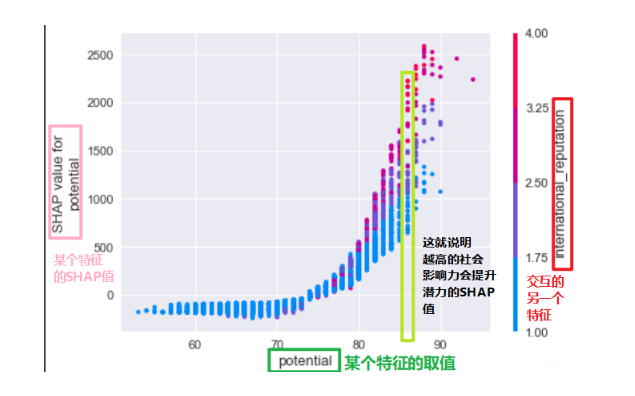
4. 小结
小总一下, SHAP在特征选择里面挺常用的, 让很多模型变得有了可解释性。当然, 也不仅适用于机器学习模型, 同样也适用于深度学习的一些模型, 这个具体的可以看下面的GitHub链接。
参考: