转载自纯洁的微笑
前言
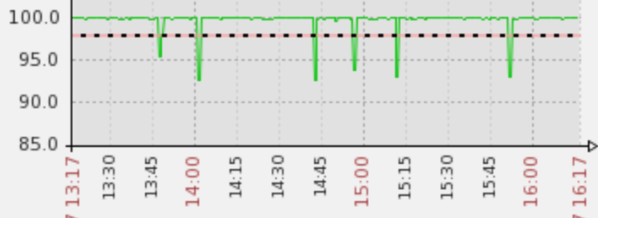
本文介绍了一次生产环境的JVM GC相关参数的调优过程,通过参数的调整避免了GC卡顿对JAVA服务成功率的影响。我们的Java HTTP服务属于OLTP类型,对成功率和响应时间的要求比较高,在生产环境中出现偶现的成功率突然下降然后又自动恢复的情况,如图所示:
写代码是热爱,写到世界充满爱
转载自纯洁的微笑
本文介绍了一次生产环境的JVM GC相关参数的调优过程,通过参数的调整避免了GC卡顿对JAVA服务成功率的影响。我们的Java HTTP服务属于OLTP类型,对成功率和响应时间的要求比较高,在生产环境中出现偶现的成功率突然下降然后又自动恢复的情况,如图所示:
转载自纯洁的微笑
Java GC就是JVM记录仪,书画了JVM各个分区的表演。
ava GC(Garbage Collection,垃圾收集,垃圾回收)机制,是Java与C++/C的主要区别之一,作为Java开发者,一般不需要专门编写内存回收和垃圾清理代码,对内存泄露和溢出的问题,也不需要像C程序员那样战战兢兢。这是因为在Java虚拟机中,存在自动内存管理和垃圾清扫机制。概括地说,该机制对JVM(Java Virtual Machine)中的内存进行标记,并确定哪些内存需要回收,根据一定的回收策略,自动的回收内存,永不停息(Nerver Stop)的保证JVM中的内存空间,防止出现内存泄露和溢出问题。
在Java语言出现之前,就有GC机制的存在,如Lisp语言),Java GC机制已经日臻完善,几乎可以自动的为我们做绝大多数的事情。然而,如果我们从事较大型的应用软件开发,曾经出现过内存优化的需求,就必定要研究Java GC机制。
简单总结一下,Java GC就是通过GC收集器回收不再存活的对象,保证JVM更加高效的运转。
转载自纯洁的微笑
运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题!虽然jvm调优成熟的工具已经有很多:jconsole、大名鼎鼎的VisualVM,IBM的Memory Analyzer等等,但是在生产环境出现问题的时候,一方面工具的使用会有所限制,另一方面喜欢装X的我们,总喜欢在出现问题的时候在终端输入一些命令来解决。所有的工具几乎都是依赖于jdk的接口和底层的这些命令,研究这些命令的使用也让我们更能了解jvm构成和特性。
Sun JDK监控和故障处理命令有jps jstat jmap jhat jstack jinfo下面做一一介绍
转载自纯洁的微笑
垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了。 jvm 中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于 java 堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的.
Author: haoransun
Wechat: SHR—97
学习来源:极客时间-算法之美,本人购买课程后依据图文讲解汇总成个人见解。
搜索引擎的热门搜索排行榜功能你用过吗?你知道这个功能是如何实现的吗?实际上,它的实现并不复杂。搜索引擎每天会接收大量的用户搜索请求,它会把这些用户输入的搜索关键词记录下来,然后再离线地统计分析,得到最热门的 Top 10 搜索关键词。
那请你思考下,假设现在我们有一个包含 10 亿个搜索关键词的日志文件,如何能快速获取到热门榜 Top 10 的搜索关键词呢?
这个问题就可以用堆来解决,这也是堆这种数据结构一个非常典型的应用。上一节我们讲了堆和堆排序的一些理论知识,今天我们就来讲一讲,堆这种数据结构几个非常重要的应用:优先级队列、求 Top K 和求中位数。
Author: haoransun
Wechat: SHR—97
学习来源:极客时间-算法之美,本人购买课程后依据图文讲解汇总成个人见解。
我们今天讲另外一种特殊的树,“堆”(Heap)。堆这种数据结构的应用场景非常多,最经典的莫过于堆排序了。堆排序是一种原地的、时间复杂度为 O(nlogn) 的排序算法。
前面我们学过快速排序,平均情况下,它的时间复杂度为 O(nlogn)。尽管这两种排序算法的时间复杂度都是 O(nlogn),甚至堆排序比快速排序的时间复杂度还要稳定,但是,在实际的软件开发中,快速排序的性能要比堆排序好,这是为什么呢?
现在,你可能还无法回答,甚至对问题本身还有点疑惑。没关系,带着这个问题,我们来学习今天的内容。
Author: haoransun
Wechat: SHR—97
学习来源:极客时间-算法之美,本人购买课程后依据图文讲解汇总成个人见解。
红黑树是一个让我又爱又恨的数据结构,“爱”是因为它稳定、高效的性能,“恨”是因为实现起来实在太难了。我今天讲的红黑树的实现,对于基础不太好的同学,理解起来可能会有些困难。但是,我觉得没必要去死磕它。
我为什么这么说呢?因为,即便你将左右旋背得滚瓜烂熟,我保证你过不几天就忘光了。因为,学习红黑树的代码实现,对于你平时做项目开发没有太大帮助。对于绝大部分开发工程师来说,这辈子你可能都用不着亲手写一个红黑树。除此之外,它对于算法面试也几乎没什么用,一般情况下,靠谱的面试官也不会让你手写红黑树的。
如果你对数据结构和算法很感兴趣,想要开拓眼界、训练思维,我还是很推荐你看一看这节的内容。但是如果学完今天的内容你还觉得懵懵懂懂的话,也不要纠结。我们要有的放矢去学习。你先把平时要用的、基础的东西都搞会了,如果有余力了,再来深入地研究这节内容。
好,我们现在就进入正式的内容。上一节,我们讲到红黑树定义的时候,提到红黑树的叶子节点都是黑色的空节点。当时我只是粗略地解释了,这是为了代码实现方便,那更加确切的原因是什么呢? 我们这节就来说一说。
Author: haoransun
Wechat: SHR—97
学习来源:极客时间-算法之美,本人购买课程后依据图文讲解汇总成个人见解。
上两节,我们依次讲了树、二叉树、二叉查找树。二叉查找树是最常用的一种二叉树,它支持快速插入、删除、查找操作,各个操作的时间复杂度跟树的高度成正比,理想情况下,时间复杂度是 O(logn)。
不过,二叉查找树在频繁的动态更新过程中,可能会出现树的高度远大于 log2n 的情况,从而导致各个操作的效率下降。极端情况下,二叉树会退化为链表,时间复杂度会退化到 O(n)。我上一节说了,要解决这个复杂度退化的问题,我们需要设计一种平衡二叉查找树,也就是今天要讲的这种数据结构。
很多书籍里,但凡讲到平衡二叉查找树,就会拿红黑树作为例子。不仅如此,如果你有一定的开发经验,你会发现,在工程中,很多用到平衡二叉查找树的地方都会用红黑树。你有没有想过,为什么工程中都喜欢用红黑树,而不是其他平衡二叉查找树呢?
带着这个问题,让我们一起来学习今天的内容吧!
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true