1. Redis的并发竞争问题
1、面试题
redis的并发竞争问题是什么?如何解决这个问题?了解Redis事务的CAS方案吗?
2、面试官心里分析
这个也是线上非常常见的一个问题,就是多客户端同时并发写一个key,可能本来应该先到的数据后到了,导致数据版本错了。或者是多客户端同时获取一个key,修改值之后再写回去,只要顺序错了,数据就错了。
写代码是热爱,写到世界充满爱
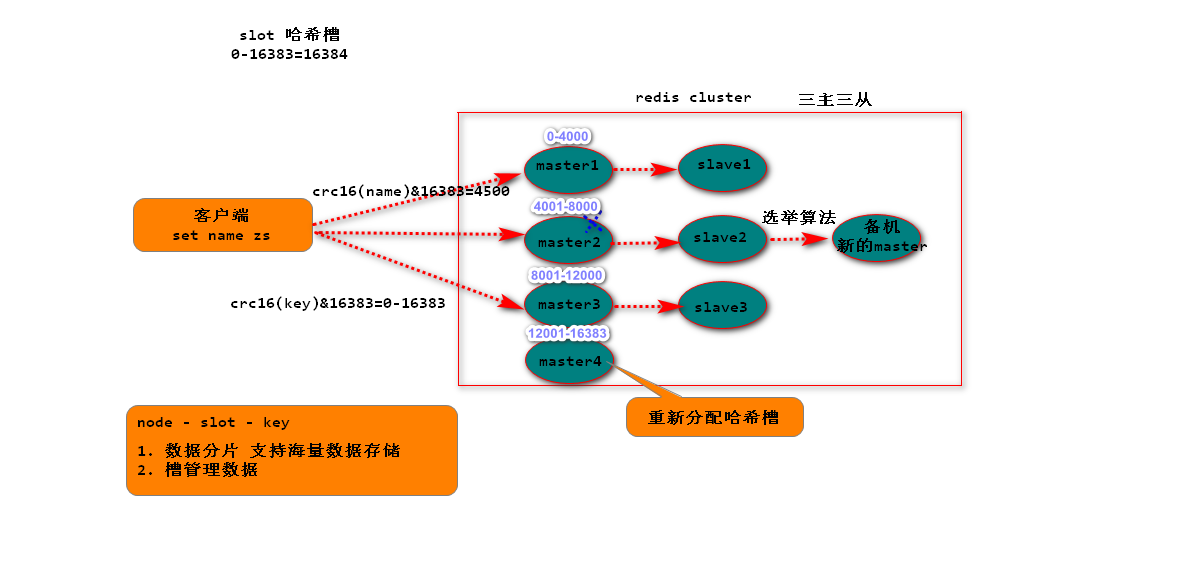
redis集群模式的工作原理能说一下么?在集群模式下,redis的key是如何寻址的?分布式寻址都有哪些算法?了解一致性hash算法吗?
在以前,如果前几年的时候,一般来说,redis如果要搞几个节点,每个节点存储一部分的数据,得借助一些中间件来实现,比如说有codis,或者twemproxy,都有。有一些redis中间件,你读写redis中间件,redis中间件负责将你的数据分布式存储在多台机器上的redis实例中。
这两年,redis不断在发展,redis也不断的有新的版本,redis cluster,redis集群模式,你可以做到在多台机器上,部署多个redis实例,每个实例存储一部分的数据,同时每个redis实例可以挂redis从实例,自动确保说,如果redis主实例挂了,会自动切换到redis从实例顶上来。
现在redis的新版本,大家都是用redis cluster的,也就是redis原生支持的redis集群模式,那么面试官肯定会就redis cluster对你来个几连炮。要是你没用过redis cluster,正常,以前很多人用codis之类的客户端来支持集群,但是起码你得研究一下redis cluster吧。
1、故障发生的时候会怎么样
2、如何应对故障的发生
很多同学,自己也看过一些redis的资料和书籍,当然可能也看过一些redis视频课程
所有的资料,其实都会讲解redis持久化,但是有个问题,我到目前为止,没有看到有人很仔细的去讲解,redis的持久化意义
redis的持久化,RDB,AOF,区别,各自的特点是什么,适合什么场景
redis的企业级的持久化方案是什么,是用来跟哪些企业级的场景结合起来使用的???
redis持久化的意义,在于故障恢复
比如你部署了一个redis,作为cache缓存,当然也可以保存一些较为重要的数据
如果没有持久化的话,redis遇到灾难性故障的时候,就会丢失所有的数据
如果通过持久化将数据搞一份儿在磁盘上去,然后定期比如说同步和备份到一些云存储服务上去,那么就可以保证数据不丢失全部,还是可以恢复一部分数据回来的
redis和memcached有什么区别?redis的线程模型是什么?为什么单线程的redis比多线程的memcached效率要高得多(为什么redis是单线程的但是还可以支撑高并发)?
这个是问redis的时候,最基本的问题吧,redis最基本的一个内部原理和特点,就是redis实际上是个单线程工作模型,你要是这个都不知道,那后面玩儿redis的时候,出了问题岂不是什么都不知道?
还有可能面试官会问问你redis和memcached的区别,不过说实话,最近这两年,作为面试官都不太喜欢这么问了,memched是早些年各大互联网公司常用的缓存方案,但是现在近几年基本都是redis,没什么公司用memcached了。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true